Эмбеддинги признаков и повышение точности ML-моделей
Прим. Wunder Fund: короткая статья о том, как эмбеддинги могут помочь при работе с категориальными признаками и сетками. А если вы и так умеете в сетки — то мы скоро открываем набор рисерчеров и будем рады с вами пообщаться, stay tuned.

Создание эмбеддингов признаков (feature embeddings) — это один из важнейших этапов подготовки табличных данных, используемых для обучения нейросетевых моделей. Об этом подходе к подготовке данных, к сожалению, редко говорят в сферах, не связанных с обработкой естественных языков. И, как следствие, его почти полностью обходят стороной при работе со структурированными наборами данных. Но то, что его, при работе с такими данными, не применяют, ведёт к значительному ухудшению точности моделей. Это стало причиной появления заблуждения, которое заключается в том, что алгоритмы градиентного бустинга, вроде того, что реализован в библиотеке XGBoost, это всегда — наилучший выбор для решения задач, предусматривающих работу со структурированными наборами данных. Нейросетевые методы моделирования, улучшенные за счёт эмбеддингов, часто дают лучшие результаты, чем методы, основанные на градиентном бустинге. Более того — обе группы методов показывают серьёзные улучшения при использовании эмбеддингов, извлечённых из существующих моделей.
Эта статья направлена на поиск ответов на следующие вопросы:
Что такое эмбеддинги признаков?
Как они используются при работе со структурированными данными?
Если использование эмбеддингов — это столь мощная методика — почему она недостаточно широко распространена?
Как создавать эмбеддинги?
Как использовать существующие эмбеддинги для улучшения других моделей?
Эмбеддинги признаков
Нейросетевые модели испытывают сложности при необходимости работы с разреженными категориальными признаками. Эмбеддинги — это возможность уменьшения размерности таких признаков ради повышения производительности модели. Прежде чем говорить о структурированных наборах данных, полезно будет разобраться с тем, как обычно используются эмбеддинги. В сфере обработки естественных языков (Natural Language Processing, NLP) обычно работают со словарями, состоящими из тысяч слов. Эти словари обычно вводят в модель с использованием методики быстрого кодирования (One-Hot Encoding), что, в математическом смысле, равносильно наличию отдельного столбца для каждого из слов. Когда слово передаётся в модель, в соответствующем столбце оказывается единица, в то время как во всех остальных выводятся нули. Это ведёт к появлению очень сильно разреженных наборов данных. Решение этой проблемы заключается в создании эмбеддинга.
 Визуализация, выполненная с помощью TensorFlow Embedding Projector
Визуализация, выполненная с помощью TensorFlow Embedding Projector
По сути дела, речь идёт о том, что эмбеддинг, на основе обучающего текста, группирует слова со сходным значением и возвращает их местоположение. Например — значение эмбеддинга слова «fun» может быть подобно значениям эмбеддингов слов «humor» и «dancing», или словосочетания «machine learning». На практике нейронные сети демонстрируют значительное улучшение производительности при применении подобных репрезентативных свойств.
Эмбеддинги и структурированные данные
Структурированные наборы данных тоже часто содержат разреженные категориальные признаки. В вышеприведённой таблице, содержащей данные о продажах, имеются столбцы с почтовым индексом и идентификатором магазина. Так как в этих столбцах могут присутствовать сотни или тысячи уникальных значений, использование этих столбцов приведёт к появлению тех же проблем с производительностью, о которых мы говорили ранее в применении к NLP-моделям. Почему бы тут, по вышеописанной схеме, не воспользоваться эмбеддингами?
Проблема заключается в том, что сейчас мы имеем дело более чем с одним признаком. В данном случае это два отдельных разреженных категориальных столбца ( zip_code и store_id ), а так же другие ценные признаки, вроде общего объёма продаж конкретному клиенту. Мы просто не можем заложить все эти признаки в эмбеддинг. Но мы, однако, можем подготовить эмбеддинги в первом слое модели и добавить в модель, вместе с эмбеддингами, и обычные признаки. Это не только приведёт к преобразованию почтового индекса и идентификатора магазина в ценные признаки, но и позволит не «размывать» другие ценные признаки тысячами столбцов.
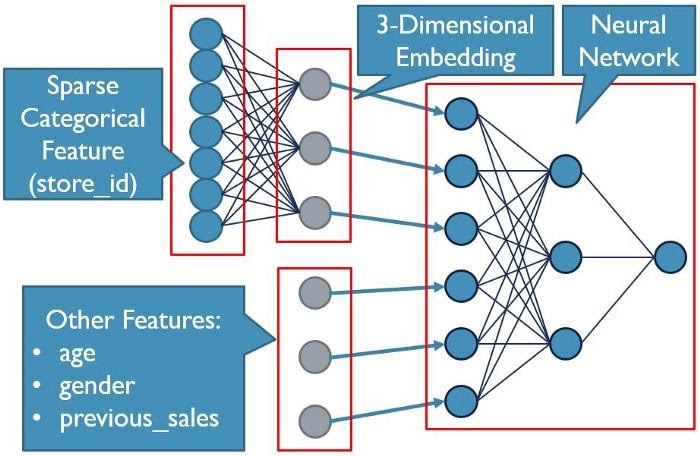 Пример эмбеддинга
Пример эмбеддинга
Почему эмбеддингам не уделяют достаточно внимания?
В крупнейших компаниях, занимающихся машинным обучением (Machine Learning, ML), эта техника работы с данными, бесспорно, применяется. Проблема заключается в том, что подавляющее большинство дата-сайентистов, находящихся за пределами таких компаний, никогда даже и не слышали о таком способе использования эмбеддингов. Почему это так? Хотя я и не сказал бы, что эти методы чрезвычайно сложно реализовать, они сложнее того, чему учат на типичных онлайн-курсах. Большинство начинающих ML-практиков просто не научили тому, как использовать эмбеддинги вместе с другими некатегориальными признаками. В результате признаки вроде почтовых индексов и идентификаторов магазинов просто выбрасывают из модели. Но это — важные данные!
Некоторые значения признака можно включить в модель, воспользовавшись другими техниками, вроде метода среднего кодирования (Mean Encoding), но подобное даёт лишь небольшие улучшения. Это привело к тенденции, когда от нейросетевых моделей полностью отказываются, выбирая методы, задействующие алгоритмы градиентного бустинга, которые способны лучше работать с категориальными признаками. Но, как уже было сказано, эмбеддинги могут улучшить оба метода моделирования. Сейчас мы разовьём эту тему.
Создание эмбеддингов
Самое сложное при работе с эмбеддингами — разобраться с наборами данных TensorFlow. И хотя устроены они совсем не так понятно, как датафреймы Pandas, научиться работать с ними весьма полезно. В частности — полезно для того, кто хотя бы задумывается о том, чтобы его модели работали бы с огромными наборами данных, и для того, кто стремится к созданию более сложных нейросетевых моделей, чем те, которые он уже разрабатывает.
В этом примере мы воспользуемся гипотетической таблицей продаж, фрагмент которой приведён выше. Наша цель заключается в прогнозировании целевых месячных продаж. Мы, ради краткости и простоты, опустим то, что имеет отношение к дата-инжинирингу, и начнём с предварительно подготовленных датафреймов Pandas. При работе с более крупными наборами данных, скорее всего, работа начнётся не с датафреймов, но это — тема для отдельной статьи.
Первый шаг заключается в преобразовании датафреймов Pandas в наборы данных TensorFlow:
Здесь стоит обратить внимание на то, что наборы данных TensorFlow и результаты дальнейших преобразований данных не хранятся в памяти так же, как хранятся датафреймы Pandas. Они, по сути, представляют собой конвейер. Через него, пакет за пакетом, походят данные, что позволяет модели эффективно обучаться на наборах данных, которые слишком велики для размещения их в памяти. Именно поэтому мы преобразуем в наборы данных словари датафреймов, а не реальные данные. Обратите внимание на то, что мы, кроме прочего, задаём сейчас, а не во время обучения модели, размер пакета данных, поступая не так, как обычно поступают при использовании API Keras.
Теперь, пользуясь столбцами признаков TensorFlow, можно определить конвейеры для обработки данных. Существуют разные способы решения этой задачи, выбор конкретного варианта зависит от типов признаков, хранящихся в таблице. Подробности об этом можно узнать в документации TensorFlow по столбцам признаков.
Обратите внимание на то, что при создании эмбеддингов нам нужно указать число измерений. Это определяет то количество признаков, к которому будут сведены признаки из категориальных столбцов. Общее правило заключается в том, что результирующее количество признаков выбирается равным корню четвёртой степени из общего количества категорий (например — 1000 уникальных почтовых индексов сводятся к
6 столбцам эмбеддинга). Но это — один из тех параметров, которые можно настраивать в собственной модели.
Теперь создадим простую модель:
Поздравляю! Вы только что обучили модель, в которой используются эмбеддинги. А как извлечь эмбеддинги из модели для использования их в других моделях? Достаточно просто взять из модели веса:
Обратите внимание на то, что порядок слоёв эмбеддингов может меняться, поэтому проверьте соответствие длины слоя весов количеству уникальных значений, объявленных выше. Это позволит вам убедиться в том, что вы взяли данные из правильного слоя. Теперь веса можно сохранить в датафрейме:
Итоги
Теперь, когда эмбеддинги сохранены, их можно включить в состав исходного набора данных. Можно даже ввести их в другие наборы данных, используя те же категориальные признаки. Я пока не встречался с ситуациями, когда использование расширенных наборов данных не приводило бы к росту точности моделей. Попробуйте эмбеддинги — и я обещаю, что их применение станет частью вашей обычной работы в сфере машинного обучения.
О, а приходите к нам работать? 😏
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
Анализ текстов нейронными сетями. Bag Of Words vs. Embedding.
Анализ текстовой информации — весьма полезный инструмент. Я ранее публиковал уже статьи на тему анализа текстов. Например, анализ авторства текста, генеративные сети с условием (в этих GAN-ах использовался слой embedding), чатботы и пр. Пора систематизировать способы представления текстов в числовой форме и попробовать понять что «под капотом», т.е. как это все работает.
One-hot encoding (OHE)
Самый простой подход :
Например, есть текст «The cat sat on the mat». Чтобы представить каждое слово для обучения нейронной сети, создадим вектор из нулей с длиной равной размеру словаря. Единица будет на позиции соответствующей слову.

Чтобы создать вектор, который кодировал бы всю фразу достаточно объединить (concatenate) one-hot вектор каждого из слов. Очевидно, что при этом полностью теряется информация о последовательности слов в тексте. Остается только информация о наборе слов («bag of words»).
Подход крайне неэффективен. Слово закодированное с помощью one-hot кодирования — это гигантский (длина равна количеству слов в тексте) разреженный (sparse — большая часть 0 и в одной позиции 1-ца) вектор. Под него уходит очень много памяти.
Кодирование словаря уникальными индексами
Другой распространенный подход — кодировать каждое слово некоторым уникальным числом. В примере выше можно было-бы слову «cat» сопоставить с 1, 2-ку присвоить для «mat» и т.д.
В этом случае можно было-бы закодировать фразу «The cat sat on the mat» плотным (dense) вектором, скажем, [5, 1, 4, 3, 5, 2]. Этот подход эффективен с т.з. использования памяти.
Однако, этот подход имеет несколько минусов:
Чтобы нейронная сеть корректно воспринимала выходные значения представленные в числовом виде без предварительного кодирования в OHE используется специальная функция loss: sparse_categorical_crossentropy. Она работает только для выходных значений и вычисляет cross-entropy между реальными и предсказанными сетью значениями.
Bag Of Words
Кодирование входных данных в OHE приводит к серьезной проблемой с нехваткой памяти при обработке данных. Например, рассмотрим для примера задачу эмоционального анализа текстов (sentiment snalysis). Например, есть отзывы клиентов на продукт. Они могут быть положительные, отрицательные и нейтральные.
Типовой механизм преобразования текстов для обработки нейронной сетью будет следующим:
Размерность полученной OHE матрицы:
OHE_shape = 500 * 20000 x 10000 = 10 000 000 x 10000.
Визуализация такого способа подачи текстового представления на нейронную сеть:

Исходная матрица подается на Dense слой и веса этого слоя в процессе обучения принимают значения, которые некоторым образом описывают фразу в слове.
Сравнительно небольшой текст преобразовался в гигантскую матрицу, где каждая фраза представлена вектором из 0 и одной 1. Длина вектора 10 млн. и количество таких векторов 10 000. Под такую матрицу расходовалось бы гигантское количество памяти. На практике для подачи текста на нейронную сеть используют подход Bag of Words [BOW].
Визуализация Bag of Words [BOW]
При Bag Of Words последовательность слов в фразе убирается, поэтому фраза (на картинке Document1, Document2) представляется в виде вектора. Его длина равной размеру общего словаря всех анализируюмых текстов. В полученном векторе на позициях, соответствующих словам присутствующим в тексте стоят 1, а если слово в тексте не встретилось — 0.
В результате размерность матрицы, которая подается на нейронную сеть равна размер словаря х количество фраз (документов) или для нашего примера с отзывами 20000 х 10000.
Embedding
Ранее при обработке текстов, например, при рассмотрении рекуррентных сетей использовалась следующая преобраотка входной последовательности:
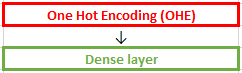
Рассмотрим как это выглядит в коде. Поскольку Dense слой — это матрица весов, сгенерируем такую рандомную матрицу:
На входе dense слоя (матрицы весов) подаются входные данные представленные в виде OHE. Например, для кодирования 10 слов используется следующая матрица OHE — по-сути, единичная квадратная матрица. У неё по диагонали стоят единицы:
Для обратного преобразования из матрицы OHE в порядковый номер слова в словаре (индекс) используется код:
Соответственно, чтобы получить OHE соответствующий произвольному индексу, нужно взять из матрицы строку или столбец по нему:
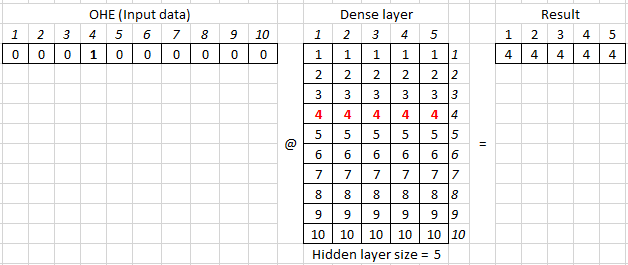 Демонстрация устройства матриц embedding_а.
Демонстрация устройства матриц embedding_а.
где @ — матричное умножение, аналог numpy.dot.
В параметрах dense слоя задается только размерность hidden size (в примере = 5). Вторую размерность (в данном случае = 10) dense слой берет из предыдущего слоя, выступающего для него в качестве входа.
Поскольку перемножение OHE на матрицу весов описывающих dense слой эквивалентно взятию из матрицы весов строки соответствующей индексу, то операция получения вектора (embedding) описыващего слово с выбранным индексом упрощается:
По-сути, получаем словарь где слову с определенным индексом поставлен в соотвествие вектор с размерностью заданной для embedding-а.
Представление слов в виде embedding-ов — способ эффективно с точки зрения использования памяти представить слово в виде понятном для нейронной сети. При этом одинаковые слова имеют одинаковый вектор их представляющий.
Размер вектора задается исследователем и чаще всего варьируется от 8-ми мерного для небольших датасетов (текстов) до 1024 в случае больших текстовых баз. Embedding-и с высокой размерностью позволяют вычленять тонкие нюансы во взаимосвязях между словами, но требуют очень больших баз для обучения.
Физический смысл embedding
Помимо значительно большей эффективности использования оперативной памяти embedding-и обладают ещё одним полезным свойством.
Поскольку каждое слово из словаря раскладывается в виде многомерного вектора размерностью embedding_size, то можно предположить, что величина по каждой из осей что-то означает.
Важный момент, в embedding слову может соотвествовать только один вектор. Т.е. не смысловое значение для слова может быть только одно.
Например, был взят embedding_size = 2 и после тренировки embedding получен словарь двумерных векторов соответствующих слову. Их разместили на графике, отложив по оси X — одну координату вектора, а по Y — другую. После анализа слов получили, например, что ось X определяет определяет степень новизны слова, а по Y — насколько слово эмоционально положительное.
Для вектора работают математические операции сложения и вычитания. Кроме того можно вычислить угол между векторами для определения насколько они сонаправлены или ортогональны.
Но, что важно, вектора в многомерном пространстве можно сравнивать, используя косинусную меру.

Косинусную меру можно использовать и как метрику и как loss. Как метрика она используется в исходном виде, как задан по формуле, поскольку метрика должна максимизироваться, т.е. стремится к 1.
В случае с loss его минимизируют, поэтому косинусную меру нужно вычесть из 1. В этом случае при максимальном сходстве векторов значение будет стремится к 0, когда вектора ортогональны, то к 1, а когда противоположно направлены = 2.
Если косинусная мера показывает меру смыслового сходства, то длина вектора дает степень окраски. Например, красивый, прекрасный, прекраснейший и пр. эпитеты ранжируются по степени.
Поскольку embedding может быть предобучен на больших корпусах (объемах) текстов с использованием специальных моделей, а затем выгружен в виде словаря, где слову ставится в соответствие вектор, то появляется возможность получать качественные предобученные embedding-и без необходимости их повторного обучения (веса слоя можно заморозить trainable = False).
Тренировка embedding в зависимости от его размера занимает немало времени, поэтому такая оптимизация крайне полезна.
Word2Vec
Теперь проверим насколько теория о том, что полученные нейронкой вектора embedding-а действительно отражают что-то. Для этого воспользуемся моделью word2vec. При тренировке модели использовалось два подхода. Первый использовал метод continuous bag of words (CBOW), который по контексту пытается предсказать слово. Второй — использовать слово для предсказания контекста — skip-gram.

Word2Vec — это не предобученные эмбеддинги (файл с векторами), а подход к их формированию. Этот подход реализован, например, в библиотеке Gensim. Используя этот подход и большие корпуса текстов разного типа (например, новости) были созданы готовые файлы embedding-ов. Если посмотреть такой файл, то вначале идет слово, а затем набор чисел описывающих его векторное представление. Размерность embedding чаще всего от 100 до 1024.
Выше была дана формула косинусного расстояния. В Python она выглядит следующим образом:
Подгрузим embedding-и. Файл порядка 1,6 Гб, там только английские слова. При желании легко найти предобученные embedding-и для русского языка. В наименовании embedding указано 300 — это размерность векторов в embedding.
Широко известный культовый пример для модели Word2Vec.

Посмотрим косинусное расстояние между
Действительно получаем высокое значение косинусного расстояния. Найдем меру сходства между walking и walked:
или то-же самое вычислим с помощью встроенной функции Word2Vec:
Найдем слово, которое выбивается из ряда слов:
Или найдем слова, наиболее близкие по смыслу с точки зрения нейронной сети:
С русскими словами результат сходный:
Встраивание embedding в нейронную сеть
При работе с готовыми embedding-ами нужно их как-то подать в нейронную сеть. Используется два основных подхода. В первом исходные фразы конвертируются в массив векторов и уже этот массив подается на вход нейронной сети вместо комбинации OHE + Dense. В этом случае полученные вектора не будут тренироваться при тренировки нейронной сети. Они уже подготовлены и считается, что обучение произведено качественно, поскольку для этого использовались гигантские корпуса текстов и тренировка проводилась долго.
Сконвертируем слова в векторное представление:
Обращаю внимание на проверку if word in wv.vocab. Например, в примере частица to является стоп словом (stop-word) с минимальной для модели смысловой нагрузкой. Поэтому эта частица отсуствует в скаченном эмбеддинге.
Если запустить код без этой проверки, то он выпадет с ошибкой, что слово не найдено. Поэтому при трансформации я это слово пропускаю и поэтому в shape-е только 6, а не 7 векторов размерностью 300.
Второй подход — это встроить embedding в качестве слоя в архитектуру нейронной сети Keras. Для этого используется метод:
Чтобы преобразовать слово в индекс в скаченном embedding используется следующий метод:
Встраивание предоубченного embedding в нейронную сетью (Keras)
Есть два способа подать анализируемый текст на нейронку, используя предобученный embedding. В первом подходе входные данные адаптируются под слой embedding-а, а во втором — слой embedding-а подстраивается под входные индексы.
Первый способ состоит в конвертации входного текста с помощью словаря embedding-а и подаче подготовленного текста на слой с весами embedding в модели:
Второй способ состоит в том, чтобы для индексов полученных токенизатором, например, Keras-а, поменять веса в матрице embedding-а, чтобы индекс определенного слова в embedding-е соответствовал индексу слова после токенизатора:
Первый способ подготовки данных я рассмотрю в этой статье, а второй — в следующей.
Слой полученный get_keras_embedding() принимает на вход индексы из скаченного embedding-а. Для преобразования текст в последовательность индексов на которых тренировался скаченный embedding:
В некоторых случаях нужно подгрузить текст убрав лишние символы и пр. Если делать это Keras токенизатором, то для передачи индексов на embedding слой word2vec нужно слегка извратится, поскольку я не нашел нормального метода у Tokenizator для получения списка слов.
Или без использования Tokenizer, взяв функцию text_to_word_sequence:
Если объем текста большой, а памяти GPU мало, то нужно использовать вариант с генератором. В этом случае данные будут подгружаться в нейронку batch-ами:
Делаем прогноз слов рекуррентной сетью Embedding слой
На предыдущем занятии мы с вами построили экспериментальную рекуррентную НС для прогнозирования следующего символа. На этом занятии разовьем эту тему и построим сеть для оценки следующего слова. В целом, сеть будет реализована также как и ранее, а вот подготовка обучающей выборки будет выполняться несколько иначе. В самом простом варианте, нам следует сформировать трехмерный тензор (похожий на тензор из предыдущего занятия):
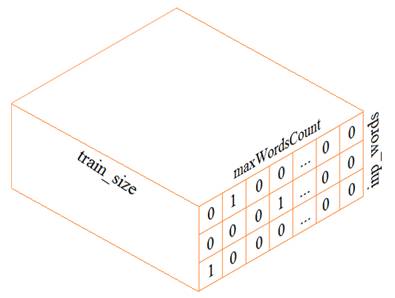
Из текста будем выделять слова целиком (а не отдельные символы, как ранее). Набор уникальных слов будут составлять наш словарь. Размер этого словаря обозначим через переменную
Каждое слово, затем, будет кодироваться one-hot вектором в соответствии с его номером в словаре:
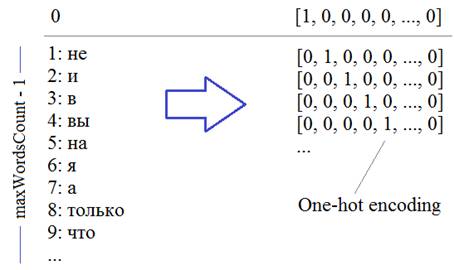
Второй важный параметр – число слов, на основе которых строится прогноз, который определяется переменной:
Давайте теперь посмотрим, как можно сформировать такой тензор. Вначале загрузим тексты с отрицательными высказываниями из файла text:
Теперь нам нужно разбить эти высказывания на слова. Для этого воспользуемся уже знакомым из прошлого занятия инструментом Tokenizer и положим, что максимальное число слов будет равно 1000:
По идее, мы здесь могли бы и не задавать максимальное число слов, тогда эта величина была бы определена автоматически при парсинге текста. Но данный параметр имеет один существенный плюс: из всех найденных слов мы оставляем 999 наиболее часто встречаемых (то есть maxWordsCount-1), то есть, мы имеем возможность отбросить редкие слова, которые особо не нужны при обучении НС.
Конечно, в данном случае, останутся все найденные слова, т.к. их общее число меньше 1000. Вообще, этот параметр устанавливается с позиции «здравого смысла». Например, при большой обучающей выборке, скорее всего, мы будем иметь дело с большинством слов (и их форм) русского языка. Какой лексический запас слов у среднестатистического человека? Около 10 000. Значит, для большой выборки можно указать значение
и это будет хорошим выбором.
Итак, мы разбили текст на слова и для примера выведем их начальный список:
Здесь отображаются кортежи со словом и его частотой встречаемости в тексте.
Далее, мы преобразуем текст в последовательность чисел в соответствии с полученным словарем. Для этого используется специальный метод класса Tokenizer:
На выходе получим массив чисел объекта numpy:

Осталось закодировать числа массива data в one-hot векторы. Для этого мы воспользуемся методом to_categorical пакета Keras:
На выходе получим двумерную матрицу, состоящую из One-hot векторов:

Затем, из этой матрицы сформируем тензор обучающей выборки и соответствующий набор выходных значений. Для начала вычислим размер обучающего множества:
И, далее, сформируем входной тензор и прогнозные значения также, как мы это делали с символами:
Все, у нас есть обучающая выборка и требуемые выходные значения. Осталось создать модель рекуррентной сети. Мы ее возьмем из предыдущего занятия с числом нейронов скрытого слоя 128 и maxWordsCount нейронами на выходе с функцией активации softmax:
Готово. Запускаем процесс обучения:
И давайте теперь посмотрим, что у нас получилось. Запишем функцию для формирования текста из спрогнозированных слов:
И вызовем ее с тремя первыми словами:
Получим вот такой результат:
позитив добавляет годы счастье вашей жизни и двигаться их в вы держись в и мечты успеха свою жизни не меня за не в
Конечно, немного сумбурно, но в целом, что-то в этом есть. Такой результат еще связан с очень маленькой обучающей выборкой. По идее, здесь нужно взять какую-нибудь большую книгу и прогнать ее через сеть. Но цель этого занятия показать общий принцип использования рекуррентных сетей для прогнозирования слов в последовательности.
Embedding-слой
Однако в такой реализации есть один существенный недостаток: входной тензор, что мы получили, занимает в памяти очень много места. Представьте, если решается реальная задача с числом слов 20 000. Тогда тензора будет содержать:
 элементов
элементов
и требовать значительный объем памяти. Поэтому специалисты по нейронным сетям предложили альтернативный подход – использование специального входного слоя, который получил название:
В чем его суть? Смотрите, когда мы подаем вектор с единицей на определенной позиции, то у нас, фактически, используются только связи для этого одного входа, остальные умножаются на 0 и формируют нулевые суммы на всех остальных нейронах скрытого слоя:
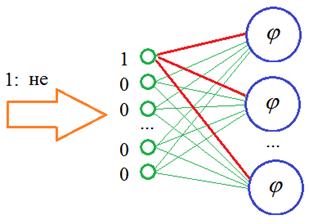
И отсюда хорошо видно, что если передавать на вход не такие расширенные векторы, а последовательность с порядковыми номерами слов в словаре:

То на входе НС можно реализовать простой алгоритм, который бы подавал 1 на нейрон с соответствующим номером этого слова, а остальные суммы приравнивались бы нулю. В итоге, мы существенно экономим память при хранении обучающей выборки, а результат получаем тот же самый. Именно такую операцию и выполняет Embedding слой. На выходах его слоя формируются выходные значения, равные весам связей для переданной 1:
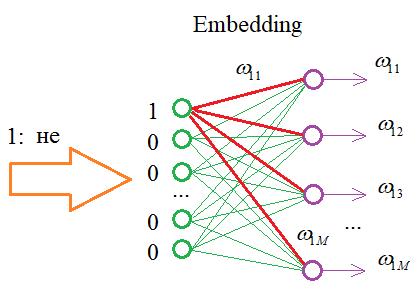
Далее, эти значения весов подаются уже на следующий слой нейронной сети.
В Keras такой слой можно создать с помощью одноименного класса:
Есть и другие параметры, подробно о них можно почитать на странице документации по ссылке:
Этот слой можно создавать только как входной и в нашем случае мы его определим так:
Здесь 256 – это число выходов в Embedding-слое. В качестве входной обучающей выборки мы теперь можем использовать одномерный массив:
А выходные значения остаются прежними – двумерным массивом из One-hot векторов, так как у нас на выходе 1000 нейронов.
Далее, абсолютно также проводим обучение и немного модифицируем функцию buildPhrase:
И запускаем процесс прогнозирования слов. Как видите, использование Embedding слоя значительно упрощает и саму программу и размер используемой памяти.
Видео по теме

Нейронные сети: краткая история триумфа

Структура и принцип работы полносвязных нейронных сетей | #1 нейросети на Python



Ускорение обучения, начальные веса, стандартизация, подготовка выборки | #4 нейросети на Python


Функции активации, критерии качества работы НС | #6 нейросети на Python



Как нейронная сеть распознает цифры | #9 нейросети на Python

Оптимизаторы в Keras, формирование выборки валидации | #10 нейросети на Python


Batch Normalization (батч-нормализация) что это такое? | #12 нейросети на Python

Как работают сверточные нейронные сети | #13 нейросети на Python

Делаем сверточную нейронную сеть в Keras | #14 нейросети на Python

Примеры архитектур сверточных сетей VGG-16 и VGG-19 | #15 нейросети на Python

Теория стилизации изображений (Neural Style Transfer) | #16 нейросети на Python

Делаем перенос стилей изображений с помощью Keras и Tensorflow | #17 нейросети на Python

Как нейронная сеть раскрашивает изображения | #18 нейросети на Python

Введение в рекуррентные нейронные сети | #19 нейросети на Python

Как рекуррентная нейронная сеть прогнозирует символы | #20 нейросети на Python

Делаем прогноз слов рекуррентной сетью Embedding слой | #21 нейросети на Python

Как работают RNN. Глубокие рекуррентные нейросети | #22 нейросети на Python


Как делать сентимент-анализ рекуррентной LSTM сетью | #24 нейросети на Python

Рекуррентные блоки GRU. Пример их реализации в задаче сентимент-анализа | #25 нейросети на Python

Двунаправленные (bidirectional) рекуррентные нейронные сети | #26 нейросети на Python

Автоэнкодеры. Что это и как работают | #27 нейросети на Python

Вариационные автоэнкодеры (VAE). Что это такое? | #28 нейросети на Python

Делаем вариационный автоэнкодер (VAE) в Keras | #29 нейросети на Python

Расширенный вариационный автоэнкодер (CVAE) | #30 нейросети на Python

Что такое генеративно-состязательные сети (GAN) | #31 нейросети на Python

Делаем генеративно-состязательную сеть в Keras и Tensorflow | #32 нейросети на Python
© 2021 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта



