ETL и ELT: разница в том, как…
В течение последних нескольких десятилетий ETL (извлечение, преобразование, загрузка) был традиционным подходом, который использовался в хранилищах данных и аналитике. Подход ELT (извлечение, загрузка, преобразование) меняет старую парадигму. Но что на самом деле происходит, когда меняются местами буквы «T» и «L»?
ETL и ELT решают одну и ту же задачу:
Компаниям необходимо собирать, обрабатывать и анализировать гигабайты данных и событий. Данные должны быть чистыми, управляемыми и готовыми к анализу. Их нужно обогатить, формировать и трансформировать, прежде чем они станут значимыми.
Но то «как» это сделано в этих подходах отличается. Новый подход открывает новые возможности во многих современных проектах обработки данных. Есть определенные различия в том, как обрабатываются необработанные данные, когда выполняется обработка и как анализ.
В этой статье мы покажем технологические различия ETL и ELT, покажем примеры инженерии данных и анализа двух подходов и рассмотрим 10 плюсов и минусов ETL и ELT.
Технологические различия: давайте сначала разберем три ключевых этапа E, T, L:
ETL и ELT: что такое ETL?
ETL требует управления необработанными данными, включая извлечение необходимой информации и выполнение правильных преобразований, чтобы в конечном итоге удовлетворить потребности бизнеса. Каждый этап: извлечение, преобразование и загрузка, требует взаимодействия инженеров и разработчиков данных и работы с ограничениями емкости традиционных хранилищ данных. Используя ETL, аналитики и другие пользователи BI привыкли ждать, поскольку простой доступ к информации невозможен до тех пор, пока не будет завершен весь процесс ETL.
Что такое ELT?
При ELT после завершения извлечения данных вы сразу же начинаете этап загрузки – перемещение всех источников данных в единое централизованное хранилище данных. Благодаря сегодняшним инфраструктурным технологиям, в которых используются облака, системы могут поддерживать большие хранилища и масштабируемые вычисления. Следовательно, большой, расширяющийся пул данных и быстрая обработка практически бесконечны для сохранения всех извлеченных необработанных данных.
Таким образом, подход ELT представляет собой современную альтернативу ETL. Однако он все еще на этапе развития. Поэтому структуры и инструменты для поддержки процесса ELT не всегда подходят для облегчения загрузки и обработки больших объемов данных. Потенциал роста очень многообещающий – предоставление неограниченного доступа ко всем вашим данным в любое время и экономия усилий и времени разработчиков для пользователей и аналитиков BI.
Практический пример
Вот пример, который показывает технологические различия между ETL и ELT, он поможет нам вникнуть в детали.
В нашей демо-версии будут использоваться две таблицы данных: одна для покупок, а другая для валют, как показано ниже:
ТАБЛИЦА ПОКУПОК
Сумма
валюта
ТАБЛИЦА ВАЛЮТ
валюта
Курс
Чтобы разобрать основы, мы рассмотрим, как эти данные обрабатывается в ETL и ELT. Для каждого из них мы покажем, как рассчитать единую сводную таблицу с использованием этих двух таблиц, включая среднюю покупку в каждой стране (на основе предоставленного IP-адреса).
Преобразование ETL в извлеченных данных
В процессе ETL к ряду правил или функций для извлеченных данных и создания таблицы, которая будет загружена применяется этап преобразования.
Вот код, который показывает процесс предварительного преобразования данных для ETL:
Используя этот скрипт, мы сопоставляем IP-адреса с соответствующей страной. Мы выводим новое рассчитанное значение «сумма», умножая значения обеих исходных таблиц в группе на атрибут валюты. Затем мы сортируем данные по столбцу страны, объединяем данные из таблиц покупок и валют и суммируем средние значения по странам.
Это преобразование данных приводит к новой таблице со средней суммой по стране:
СРЕДНЯЯ СУММА ПО СТРАНЕ
страна
сумма
Преобразование данных ELT во время выполнения запроса
В отличие от ETL, в ELT все данные уже загружены и могут использоваться в любой момент времени.
Следовательно, преобразование выполняется во время выполнения запроса:
В запросе мы выбираем IP-адрес по стране, умножая сумму из таблицы покупок на курс из таблицы валют, чтобы вычислить среднюю сумму. Затем объединение обеих таблиц на основе общих столбцов обеих таблиц и группировка по странам.
Это приведет к той же самой выходной таблице, что и в описанном выше процессе ETL. Однако в этом случае, поскольку все необработанные данные уже загружены, нам будет проще продолжить выполнение других запросов в той же среде для тестирования и определения лучших возможных преобразований данных, соответствующих бизнес-требованиям.
Итог этого практического примера
В разработке кода ELT более эффективен, чем ETL. Кроме того, ELT более гибок, чем ETL. С помощью ELT пользователи могут запускать новые преобразования, тестировать и улучшать запросы непосредственно на необработанных данных по мере необходимости – без лишних времени и сложности, к которым мы привыкли с ETL.
Управление хранилищами данных и озерами данных
Согласно Gartner, потребности компаний в управлении данными и интеграции данных сегодня требуют как малых, так и больших, неструктурированных и структурированных объемов данных. Вот что они предлагают изменить в способе работы:
«Традиционная команда бизнес-аналитики должна продолжать разрабатывать четкие передовые практики с хорошо понятными бизнес-целями… существует второй режим бизнес-аналитики, который является более гибким и. очень итеративным, с непредвиденным обнаружением данных, допускающим быстрый сбой».
Такие мысли вызвали много разговоров о хранилищах и озерах данных. Концепция озера данных – это новый взгляд на большие объемы неструктурированных данных, предназначенный для бесконечного масштабирования с использованием таких инструментов, как Hadoop, для реализации второго режима работы бизнес-аналитики, описанного Gartner. Хотя компании по-прежнему используют хранилища данных для поддержки традиционной парадигмы, такой как ETL, масштабируемые современные хранилища данных, такие как Redshift и BigQuery, могут использоваться для реализации современной парадигмы ELT со всеми присущими ей преимуществами, упомянутыми выше.
IBM рассказывает о 5 вещах, которые требуются для современных проектов на основе больших данных, о необходимости новых концепций данных, таких как озеро данных. Это «5 V»:
ETL по-прежнему хорошо подходит для работы с устаревшими хранилищами данных, при рассмотрении более мелких подмножеств и их перемещении в хранилище данных. Но трудно предоставить решение с ETL для «5 V», когда вы идете вниз по списку – как работать с объемами? Неструктурированными данными? Скорость? и т.п.
Подход ELT открывает возможности для работы в более гибкой итеративной среде бизнес-аналитики благодаря своей эффективности и гибкости. ELT позволяет реализовать множество концепций хранилищ данных и распространяется на концепции озера данных, что позволяет включать неструктурированные данные в свое решение бизнес-аналитики.
Подводя итоги: 10 плюсов и минусов ETL и ELT
Обобщая эти два подхода, мы сгруппировали различия по 10 критериям:
1. Время – Загрузка
ETL: использует промежуточную область и систему, дополнительное время для загрузки данных
ELT: все в одной системе, загрузка только один раз
2. Время – Преобразование
ETL: нужно подождать, особенно для больших объемов данных – по мере роста данных время преобразования увеличивается
ELT: все в одной системе, скорость не зависит от размера данных
3. Время – Обслуживание
ETL: высокий уровень обслуживания – выбор данных для загрузки и преобразования; необходимо сделать все снова, если данные удалены или вы хотите улучшить основное хранилище данных.
ELT: низкие эксплуатационные расходы – все данные всегда доступны
4. Сложность реализации
ETL: на ранней стадии требует меньше места, и результат будет чистый
ELT: требует глубоких знаний инструментов и экспертного проектирования основного большого хранилища.
5. Анализ и стиль обработки
ETL: основан на нескольких сценариях для создания представлений – удаление представления означает удаление данных
ELT: создание специальных представлений – низкие затраты на создание и обслуживание
6. Ограничение данных или ограничение на поставку
ETL: предполагая и выбирая данные априори
ELT: По HW (нет) и политике хранения данных
7. Поддержка хранилищ данных
ETL: преобладающая устаревшая модель, используемая для локальных и реляционных структурированных данных.
ELT: адаптировано для использования в масштабируемой облачной инфраструктуре для поддержки структурированных и неструктурированных источников больших данных.
8. Поддержка озера данных
ETL: не является частью подхода
ELT: позволяет использовать озеро с поддержкой неструктурированных данных
9. Удобство использования
ETL: фиксированные таблицы, фиксированная временная шкала, используется в основном ИТ
ELT: ситуативность, гибкость, доступность для всех, от разработчика до гражданского интегратора
10. Рентабельность
ETL: нерентабельно для малого и среднего бизнеса
ELT: масштабируемость и доступность для бизнеса любого размера с использованием онлайн-решений SaaS
Заключительные мысли об ETL и ELT
ETL устарел. Он помог справиться с ограничениями традиционных жестких инфраструктур центров обработки данных, но сегодня это больше не является проблемой. В организациях с большими наборами данных, в масштабе нескольких терабайт, время загрузки может занять часы, в зависимости от сложности правил преобразования.
ELT – важная часть будущего хранилищ данных. С ELT компании любого размера могут извлечь выгоду из современных технологий. Анализируя большие пулы данных с большей гибкостью и меньшими затратами на обслуживание, компании получают ключевые идеи для создания реальных конкурентных преимуществ в своем бизнесе.
Основные функции ETL-систем
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
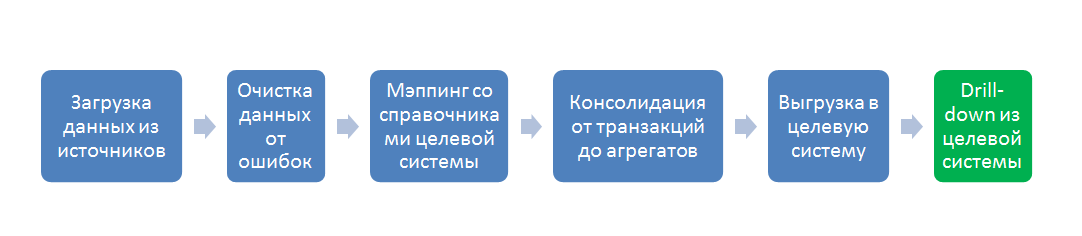
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
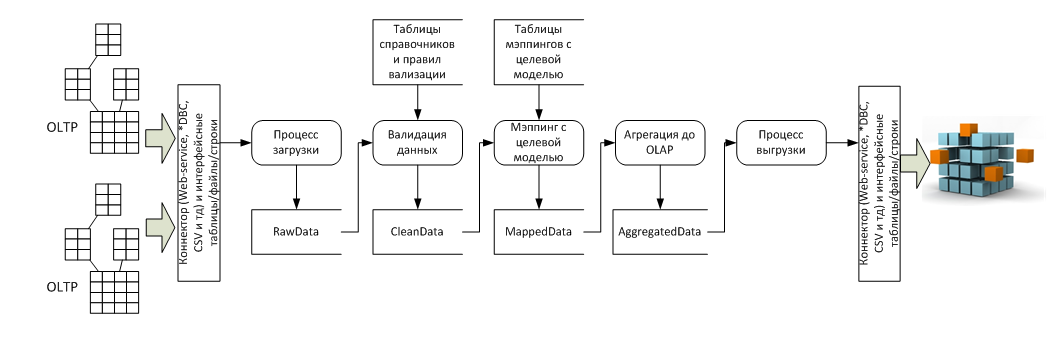
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
Процесс валидации
Данный процесс отвечает за выявление ошибок и пробелов в данных, переданных в ETL.
Само программирование или настройка формул проверки не вызывает вопросов, главный вопрос – как вычислить возможные виды ошибок в данных, и по каким признакам их идентифицировать?
Возможные виды ошибок в данных зависят от того какого рода шкалы применимы для этих данных. (Ссылка на прекрасный пост, объясняющий, какие существуют виды шкал — http://habrahabr.ru/post/246983/).
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
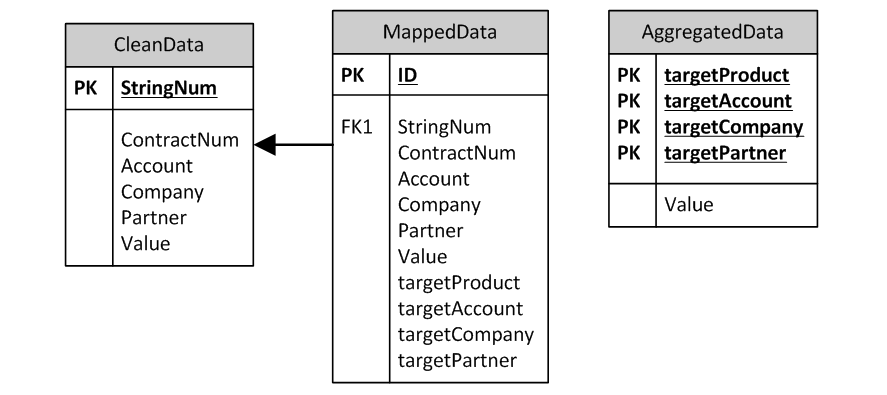
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
Snowflake, Anchor Model, ELT и как с этим жить
Привет! Меня зовут Антон Поляков, и я разрабатываю аналитическое хранилище данных и ELT-процессы в ManyChat. В настоящий момент в мире больших данных существуют несколько основных игроков, на которых обращают внимание при выборе инструментария и подходов к работе аналитических систем. Сегодня я расскажу вам, как мы решили отклониться от скучных классических OLAP-решений в виде Vertica или Exasol и попробовать редкую, но очень привлекательную облачную DWaaS (Data Warehouse as a Service) Snowflake в качестве основы для нашего хранилища.
С самого начала перед нами встал вопрос о выборе инструментов для работы с БД и построении ELT-процессов. Мы не хотели использовать громоздкие и привычные всем готовые решения вроде Airflow или NiFi и пошли по пути тонкой кастомизации. Это был затяжной прыжок в неизвестность, который пока продолжается и вполне успешно.
Под катом я расскажу про архитектуру нашего аналитического хранилища и покажу, каким образом мы производим загрузку, обработку и трансформацию данных.
Описание данных ManyChat
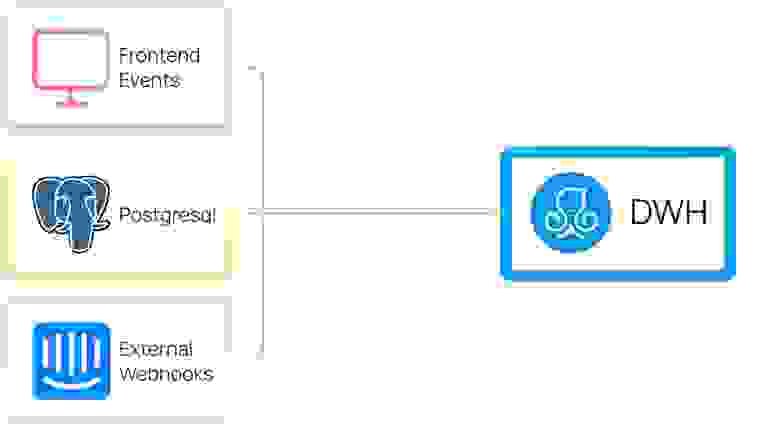
ManyChat — это платформа для общения компаний с клиентами через мессенджеры. Нашим продуктом пользуется более 1.8 млн бизнесов по всему миру, которые общаются c 1.5 млрд подписчиков.
Моя команда занимается разработкой хранилища и ELT-платформы для сбора и обработки всех доступных данных для последующей аналитики и принятия решений.
Большую часть данных мы получаем из собственного приложения: нажатия пользователями кнопок, попапов, события и изменения моделей бэкэнда (пользователя/подписчика/темплейтов/взаимодействия с нашим апи и десятки других). Также получаем информацию из логов и исторических данных из Postgres-баз.
Некоторые данные мы принимаем от внешних сервисов, взаимодействие с которыми происходит посредством вебхуков. Пока это Intercom и Wistia, но список постепенно пополняется.
Данные для аналитиков
Аналитики ManyChat для своей работы пользуются данными из слоя DDS (Data Distribution Storage / Service), где они хранятся в шестой нормальной форме (6 нф). По сути, аналитики хорошо осведомлены о структуре данных в Snowflake и сами выбирают способы объединения и обработки множеств с помощью SQL.
В своей ежедневной работе аналитики пишут запросы к десяткам таблиц разного размера, на обработку которых у СУБД уходит определенное время. За счет своей архитектуры Snowflake хорошо подходит для аналитики больших данных и работы со сложными SQL запросами. Приведу конкретные цифры:
| Объектов в запросе | Количество запросов | AVG Время выполнения (сек) | MED Время выполнения (сек) |
|---|---|---|---|
| 1 — 3 | 15149 | 33 | 1.27 |
| 4 — 10 | 3123 | 48 | 8 |
| 11 + | 729 | 188 | 38 |
Запросы, выполняемые быстрее, чем за 1 секунду, вынесены в отдельную группу. Это позволяет разделить запросы, использующие SSD (локальный кэш и сохраненные данные), от тех, которым приходится основную часть данных читать с медленных HDD.
| Объектов в запросе | Количество запросов | AVG Время выполнения (сек) | MED Время выполнения (сек) |
|---|---|---|---|
| 1 — 3 | 5747 | 71 | 9 |
| 4 — 10 | 2301 | 61 | 15 |
| 11 + | 659 | 201 | 52 |
Увеличение количества объектов в запросе усложняет его процессинг.
В этом примере анализ запросов производился с помощью поиска названий существующих таблиц в SQL-коде запросов аналитиков. Таким образом мы находим приблизительное количество использованных объектов.
Anchor Model
При раскладке данных в хранилище мы используем классическую якорную модель (Anchor Model). Эта модель позволяет гибко реагировать на изменение уже хранимых или добавление новых данных. Также благодаря ей можно эффективнее сжимать данные и быстрее работать с ними.
Для примера, чтобы добавить новый атрибут к имеющейся сущности, достаточно создать еще одну таблицу и сообщить аналитикам о необходимости делать join’ы на нее.
Подробнее про Anchor Model, сущности, атрибуты и отношения вы можете почитать у Николая Голова aka @azazoth (здесь и здесь).
Немного о Snowflake

Размеры кластеров на примере цветных квадратов с текстом
СУБД выделяет расчетные мощности on-demand, как и во многих других продуктах AWS. Бюджет расходуется только если вы используете предоставленные для расчетов мощности — тарифицируется каждая секунда работы кластера. То есть, при отсутствии запросов, вы тратите деньги только на хранение данных.
Для простых запросов можно использовать самый дешёвый кластер (warehouse). Для ELT-процессов, в зависимости от объема обрабатываемых данных, поднимаем подходящий по размеру кластер: XS / S / M / L / XL / 2XL / 3XL / 4XL – прямо как размеры одежды. После загрузки и / или обработки выключаем его, дабы не тратить деньги. Время выключения кластера можно настраивать: от «тушим сразу, как закончили расчет запроса» до «никогда не выключать».

Выделяемое на каждый размер кластера железо и цена за секунду работы
Подробнее про кластеры Snowflake читайте тут. А так же в последней статье Николая Голова.
В настоящий момент ManyСhat использует 9 различных кластеров:
Особенности Snowflake
Архитектура
Все кластеры в системе работают изолированно. Архитектура решения Snowflake представляется тремя слоями:
Snowflake работает с «горячими» и «холодными» данными. «Холодными» считаются данные, лежащие в S3 на обычных HDD (Remote Disk). При запросе они дольше считываются и загружаются в быстрые SSD отдельно для каждого кластера. Пока кластер работает, данные доступны на локальном SSD (Local Disk), что ускоряет запросы в несколько раз по сравнению с работой на «холодную».
Помимо этого, существует общий для всех кластеров кэш результата запроса (Result Cache) за последние 24 часа. Если данные за это время не изменились, при повторном запуске одного и того же запроса на любом из кластеров они не будут считаны повторно. Подробнее можно почитать тут.
Микро-партиции
Одной из интересных фичей Snowflake является работа с динамическими микро-партициями. Обычно в базах данных используются статические, но в ряде случаев, например, при перекосе данных (data skew), данные между партициями распределяются неравномерно что усложняет / замедляет обработку запросов.
В Snowflake все таблицы хранятся в очень маленьких партициях, содержащих от 50 до 500 Мбайт данных без сжатия. СУБД хранит в метаданных информацию обо всех строках в каждой микро-партиции, включая:
ELT Pipelines
Потоки данных и слои их хранения и обработки в ManyChat выглядят примерно так: 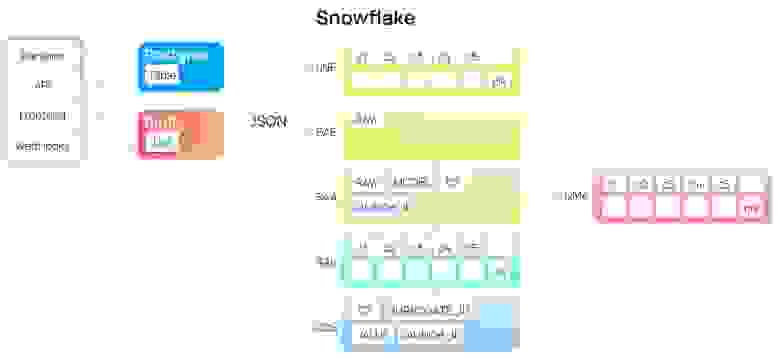
Данные поступают в DWH из нескольких источников:
| Схема | Количество объектов | Количество представлений | AVG строк (млн) | AVG объём GB |
|---|---|---|---|---|
| SNP | 3337 | 2 | 2 | 0.2 |
| SAA | 52 | 2 | 590 | 60 |
| SAL | 124 | 121 | 25 | 2.2 |
| DDS | 954 | 6 | 164 | 2.5 |
| DMA | 57 | 290 | 746 | 15 |
Используя 6 нф, DDS позволяет хранить достаточно большие объемы данных очень компактно. Все связи между сущностями осуществляются через целочисленные суррогатные ключи, которые отлично жмутся и очень быстро обрабатываются даже самым слабым XS-кластером.
SAA занимает более 80% объема хранилища из-за неструктурированных данных типа variant (сырой JSON). Раз в месяц SAA-слой скидывает данные в историческую схему.
В настоящий момент мы храним более 11 Тбайт данных в Snowflake с фактором сжатия х5, ежедневно получая сотни миллионов новых строк. Но это только начало пути, и мы планируем увеличивать количество источников, а значит и поступающих данных кратно год к году.
Redis
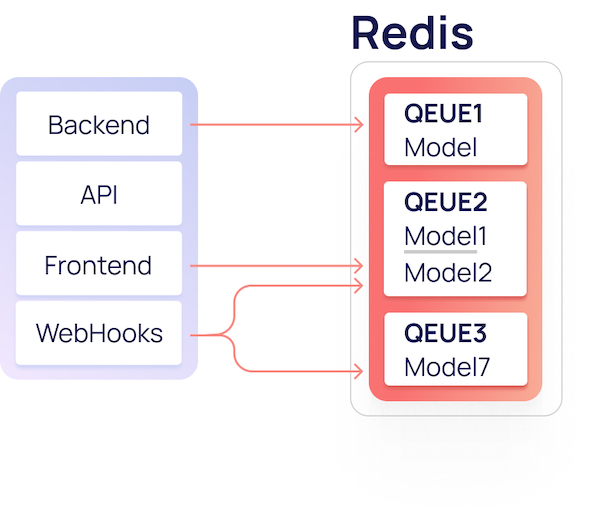
В ManyChat активно используется Redis, и наш проект не стал исключением: он является шиной для обмена данными. Для быстрого и безболезненного старта в качестве языка написания ELT-движка был выбран python, а для хранения логов и статистики — Postgres. Redis выступает в нашей архитектуре местом для временного хранения поступающей информации от всех источников. Данные в Redis хранятся в виде списка (List) JSON’ов.

Структура хранения данных в Redis
В каждом списке могут находится от 1 до N разнообразных моделей данных. Модели объединяются в списки методом дедукции. Например, все клики пользователей в независимости от источника кладутся в один список, но могут иметь разные модели данных (список полей).
Ключами для списков в Redis являются придуманные названия, которые описывают находящиеся в нем модели.
Пример некоторых названий списков и моделей в нем:
Первый подход
Первым подходом к построению ELT-процесса для нас стала простая загрузка данных, выполняющаяся в несколько шагов в одном скрипте по cron’у.
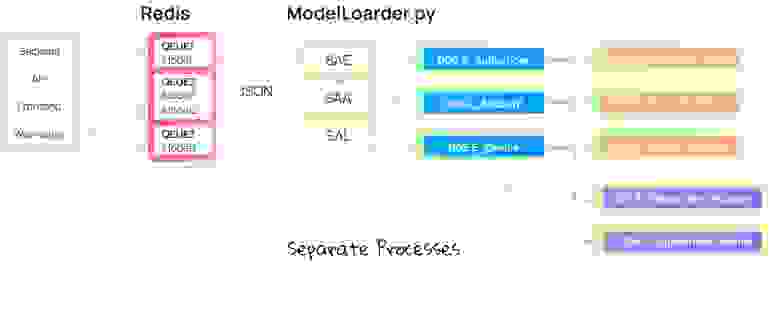
Каждая очередь в Redis вычитывается своим собственным лоадером, запускаемым по расписанию в cron.
Лоадеры для загрузки данных. Названия лоадеров совпадают с названиями загружаемых очередей.
Псевдокод цикла считывания данных из Redis в JSON:
Вся последующая загрузка данных поделена на этапы:
Второй подход
Весь код наших интеграций был написан быстро и без оглядки на стандарты/практики. Мы запустили MVP, который показывал результат, но работать с ним не всегда было удобно. Именно поэтому мы решились на допиливание и переписывание нашего инструментария.
Главной задачей было, как и всегда, взять все самое лучшее из предыдущей реализации, сделать быстрее и надежнее и ничего не сломать по пути.
Мы произвели декомпозицию всего кода на несколько важных независимых частей.
Чтение данных из Redis
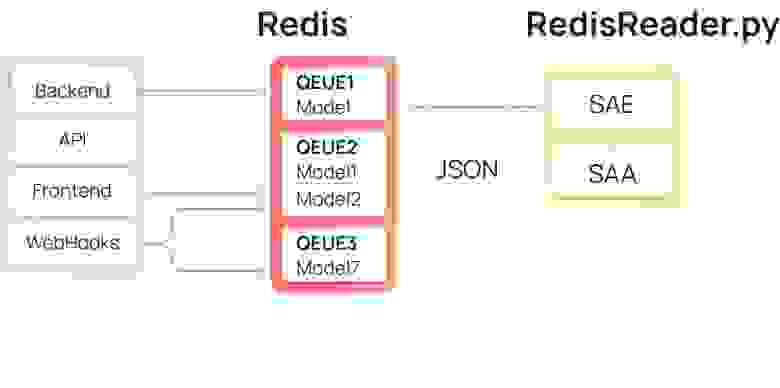
RedisReader — скрипт для непрерывного вычитывания шины Redis. Conf-файл для supervisord создан под каждую очередь и постоянно держит запущенным необходимый ридер.
Пример conf-файла для одной из очередей email_event :
Полученные данные сперва параллельно загружаются в таблицы
SAE.
Все действия в RedisReader являются multiprocessing-safe и призваны сделать загрузку наиболее безопасной при одновременном использовании множества процессов для вычитки одной очереди Redis.
После внедрения RedisReader исчезла проблема с неконтролируемым расходованием памяти Redis. При появлении в очереди, данные практически моментально считываются и складываются в Snowflake-слое SAA по следующим колонкам:
Трансформация данных внутри Snowflake
SAA-слой является DataLake в нашей архитектуре. Дальнейшая загрузка данных из него в SAL сопровождается логированием, получением статистики по всем полям и созданием новой SAL-таблицы при необходимости.

Сборка DDS
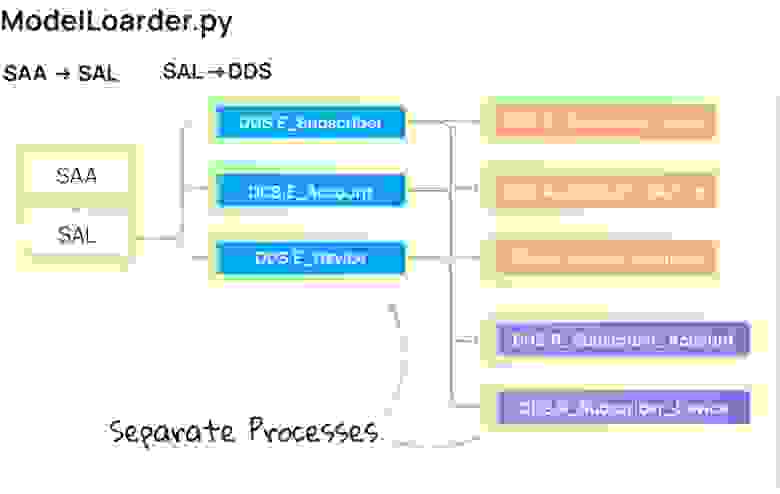
Сборка таблиц для слоя DDS происходит на основе данных из SAL-схемы. Она изменилась меньше всего с момента первой реализации. Мы добавили полезные фичи: выбор типа отслеживания изменений данных (Slowly Changing Dimension) в виде SCD1 / SCD0, а также более быстрые неблокирующие вставки в таблицы.
Данные в каждую таблицу в DDS-слое загружаются отдельным процессом. Это позволяет параллельно работать со множеством таблиц и не тратить время на последовательную обработку данных.
Загрузка в DDS разделена на 2 этапа:
Загрузка сущностей
Загрузка сущностей подразумевает загрузку только уникальных значений в таблицы типа DDS.E_
Поскольку сущности никак не связаны между собой, можно вполне законно загружать их параллельно друг другу, используя встроенный multiprocessing.
Загрузка Отношений и Атрибутов
Загрузка отношений и атрибутов реализована похожим образом, единственное отличие – при вставке данных в DDS-схему происходит больше join’ов и проверок данных на актуальность.
Отношения и атрибуты не связаны между собой и зависят только от уже загруженных сущностей, поэтому мы без сомнений можем загружать их параллельно друг другу.
Сейчас метаданные по каждому лоадеру хранятся в Google Sheet, и у любого инженера есть возможность исправить значение и сгенерировать код лоадера путем простого запуска скрипта в консоли.
RedisReader в свою очередь работает независимо от всей остальной системы, ежесекундно опрашивая очереди в Redis. Загрузка данных SAA ⇒ SAL и далее в DDS тоже может работать абсолютно независимо, но запускается в одном скрипте.
Так мы смогли избавиться от прежних проблем:
Количество полученных данных. Каждый цвет отвечает за отдельный поток данных.
Заключение
Сейчас мы занимаемся тюнингом и поиском бутылочных горлышек при загрузке данных в Snowflake. Наш новый пайплайн позволил сократить количество ручной работы инженеров до минимума и наладить процессы разработки и взаимодействия со всей компанией.
При этом было реализовано множество сторонних процессов, например Data Quality, Data Governance и материализация представлений.
Фактически добавление нового лоадера теперь сводится к заполнению полей в Google Sheet и построению модели будущих таблиц в схеме DDS.
Про нюансы работы наших ELT-процессов или аспекты работы со Snowflake спрашивайте меня в комментариях – обязательно отвечу.



