Все в сборе: настраиваем Elasticsearch + Logstash + Kibana для сбора, фильтрации и анализа логов на сервере

Содержание статьи
Стек ELK
После установки сервисов логи разбросаны по каталогам и серверам, и максимум, что с ними делают, — это настраивают ротацию (кстати, не всегда). Обращаются к журналам, только когда обнаруживаются видимые сбои. Хотя нередко информация о проблемах появляется чуть раньше, чем падает какой-то сервис. Централизованный сбор и анализ логов позволяет решить сразу несколько проблем. В первую очередь это возможность посмотреть на все одновременно. Ведь сервис часто представляется несколькими подсистемами, которые могут быть расположены на разных узлах, и если проверять журналы по одному, то проблема будет не сразу ясна. Тратится больше времени, и сопоставлять события приходится вручную. Во-вторых, повышаем безопасность, так как не нужно обеспечивать прямой доступ на сервер для просмотра журналов тем, кому он вообще не нужен, и тем более объяснять, что и где искать и куда смотреть. Например, разработчики не будут отвлекать админа, чтобы он нашел нужную информацию. В-третьих, появляется возможность парсить, обрабатывать результат и автоматически отбирать интересующие моменты, да еще и настраивать алерты. Особенно это актуально после ввода сервиса в работу, когда массово всплывают мелкие ошибки и проблемы, которые нужно как можно быстрее устранить. В-четвертых, хранение в отдельном месте позволяет защитить журналы на случай взлома или недоступности сервиса и начать анализ сразу после обнаружения проблемы.
Есть коммерческие и облачные решения для агрегации и анализа журналов — Loggly, Splunk, Logentries и другие. Из open source решений очень популярен стек ELK от Elasticsearch, Logstash, Kibana. В основе ELK лежит построенный на базе библиотеки Apache Lucene поисковый движок Elasticsearch для индексирования и поиска информации в любом типе документов. Для сбора журналов из многочисленных источников и централизованного хранения используется Logstash, который поддерживает множество входных типов данных — это могут быть журналы, метрики разных сервисов и служб. При получении он их структурирует, фильтрует, анализирует, идентифицирует информацию (например, геокоординаты IP-адреса), упрощая тем самым последующий анализ. В дальнейшем нас интересует его работа в связке с Elasticsearch, хотя для Logstash написано большое количество расширений, позволяющих настроить вывод информации практически в любой другой источник.
И наконец, Kibana — это веб-интерфейс для вывода индексированных Elasticsearch логов. Результатом может быть не только текстовая информация, но и, что удобно, диаграммы и графики. Он может визуализировать геоданные, строить отчеты, при установке X-Pack становятся доступными алерты. Здесь уже каждый подстраивает интерфейс под свои задачи. Все продукты выпускаются одной компанией, поэтому их развертывание и совместная работа не представляет проблем, нужно только все правильно соединить.
В зависимости от инфраструктуры в ELK могут участвовать и другие приложения. Так, для передачи логов приложений с серверов на Logstash мы будем использовать Filebeat. Кроме этого, также доступны Winlogbeat (события Windows Event Logs), Metricbeat (метрики), Packetbeat (сетевая информация) и Heartbeat (uptime).
Установка Filebeat
Для установки предлагаются apt- и yum-репозитории, deb- и rpm-файлы. Метод установки зависит от задач и версий. Актуальная версия — 5.х. Если все ставится с нуля, то проблем нет. Но бывает, например, что уже используется Elasticsearch ранних версий и обновление до последней нежелательно. Поэтому установку компонентов ELK + Filebeat приходится выполнять персонально, что-то ставя и обновляя из пакетов, что-то при помощи репозитория. Для удобства лучше все шаги занести в плейбук Ansible, тем более что в Сети уже есть готовые решения. Мы же усложнять не будем и рассмотрим самый простой вариант.
Подключаем репозиторий и ставим пакеты:
В Ubuntu 16.04 с Systemd периодически всплывает небольшая проблема: некоторые сервисы, помеченные мейнтейнером пакета как enable при старте, на самом деле не включаются и при перезагрузке не стартуют. Вот как раз для продуктов Elasticsearch это актуально.
Все настройки производятся в конфигурационном файле /etc/filebeat/filebeat.yml, после установки уже есть шаблон с минимальными настройками. В этом же каталоге лежит файл filebeat.full.yml, в котором прописаны все возможные установки. Если чего-то не хватает, то можно взять за основу его. Файл filebeat.template.json представляет собой шаблон для вывода, используемый по умолчанию. Его при необходимости можно переопределить или изменить.
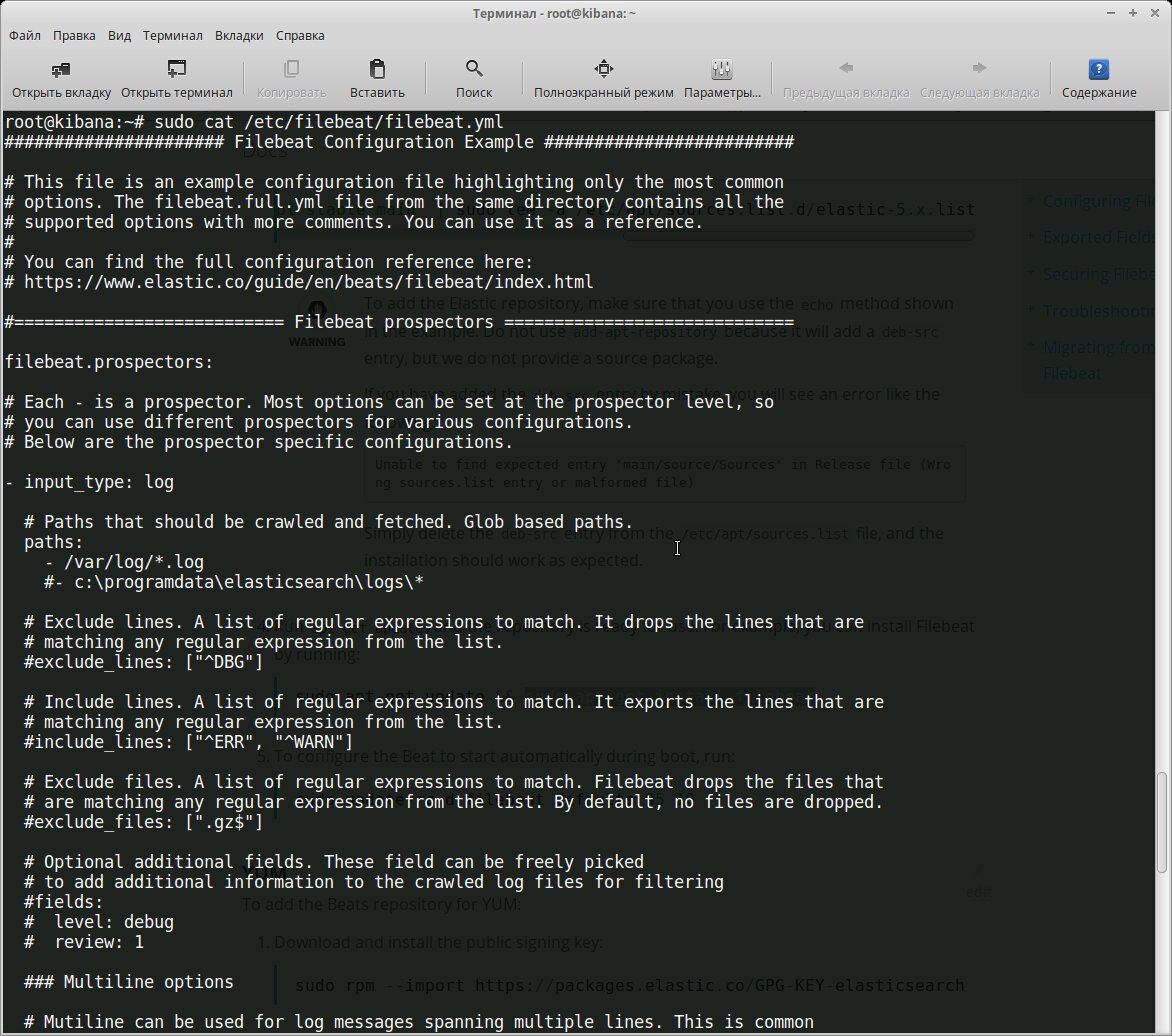 Конфигурационный файл Filebeat
Конфигурационный файл Filebeat
Xakep #218. Смотри во все глаза
Учитывая, что большинство демонов хранят логи в своих подкаталогах, их тоже следует прописать индивидуально или используя общий шаблон:
Источники с одинаковым input_type, log_type и document_type можно указывать по одному в строке. Если они отличаются, то создается отдельная запись.
Поддерживаются все типы, о которых знает Elasticsearch.
Дополнительные опции позволяют отобрать только определенные файлы и события. Например, нам не нужно смотреть архивы внутри каталогов:
По умолчанию экспортируются все строки. Но при помощи регулярных выражений можно включить и исключить вывод определенных данных в Filebeat. Их можно указывать для каждого paths.
Теперь переходим к разделу Outputs. Прописываем, куда будем отдавать данные. В шаблоне уже есть установки для Elasticsearch и Logstash. Нам нужен второй.
Здесь самый простой случай. Если отдаем на другой узел, то желательно использовать авторизацию по ключу. В файле есть шаблон.
Чтобы посмотреть результат, можно выводить его в файл:
Нелишними будут настройки ротации:
Это минимум. На самом деле параметров можно указать больше. Все они есть в full-файле. Проверяем настройки:
Сервис может работать, но это не значит, что все правильно. Лучше посмотреть в журнал /var/log/filebeat/filebeat и убедиться, что там нет ошибок. Проверим:
Еще важный момент. Не всегда журналы по умолчанию содержат нужную информацию, поэтому, вероятно, следует пересмотреть и изменить формат, если есть такая возможность. В анализе работы nginx неплохо помогает статистика по времени запроса.
Ставим Logstash
Для Logstash нужна Java 8. Девятая версия не поддерживается. Это может быть официальная Java SE или OpenJDK, имеющийся в репозиториях дистрибутивов Linux.
 Простая проверка Logstash
Простая проверка Logstash
Подключаемся к Filebeat.
Здесь же при необходимости указываются сертификаты, которые требуются для аутентификации и защиты соединения. Logstash самостоятельно может брать информацию с локального узла.
В примере beats и file — это названия соответствующих плагинов. Полный их список для inputs, outputs и filter и поддерживаемые параметры доступны на сайте.
После установки в систему уже есть некоторые плагины. Их список проще получить при помощи специальной команды:
Сверяем список с сайтом, обновляем имеющиеся и ставим нужный:
Если систем много, то можно использовать logstash-plugin prepare-offline-pack для создания пакета и распространения на другие системы.
Отдаем данные на Elasticsearch.
Для анализа данных в Logstash может использоваться несколько фильтров. Grok, наверное, лучший вариант, позволяющий отобрать любые неструктурированные данные во что-то структурированное и запрашиваемое. По умолчанию Logstash содержит приблизительно 120 шаблонов. Просмотреть их можно в github.com. Если их не хватает, легко добавить свои правила, указав прямо в строке match, что очень неудобно, или прописав все в отдельном файле, задав уникальное имя правилу и сказав Logstash, где их искать (если не установлена переменная patterns_dir):
Для проверки корректности правил можно использовать сайт grokdebug или grokconstructor, там же есть еще готовые паттерны для разных приложений.
Создадим фильтр для отбора события NGINXACCESS для nginx. Формат простой — имя шаблона и соответствующее ему регулярное выражение.
Убеждаемся в журналах, что все работает.
Ставим Elasticsearch и Kibana
Самое время поставить Elasticsearch:
По умолчанию Elasticsearch слушает локальный 9200-й порт. В большинстве случаев лучше так и оставить, чтобы посторонний не мог получить доступ. Если сервис находится внутри сети или доступен по VPN, то можно указать внешний IP и изменить порт, если он уже занят.
С Kibana то же самое:
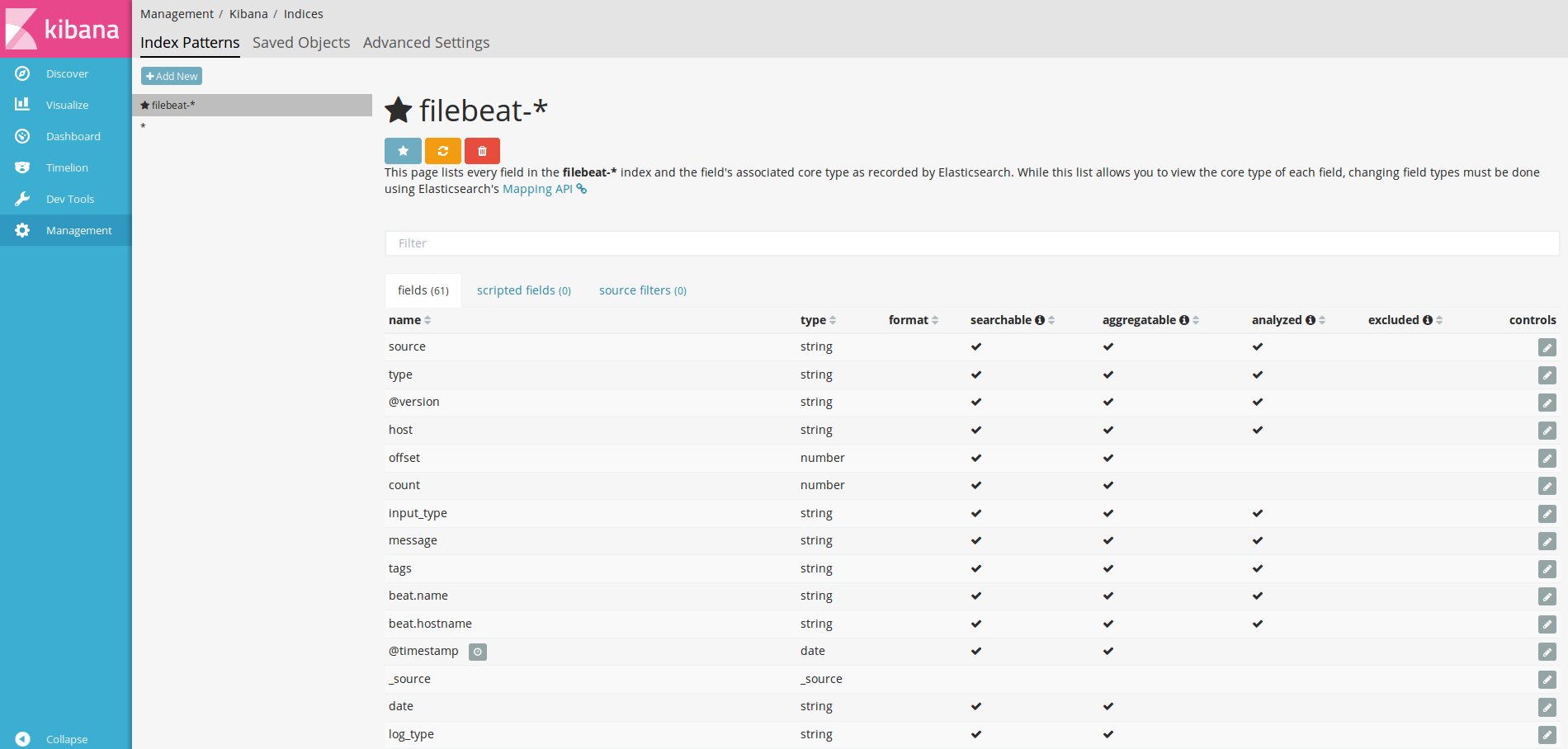 Добавляем шаблон индекса в Kibana
Добавляем шаблон индекса в Kibana
После этого, если агенты подключены нормально, в секции Discover начнут появляться логи.
Далее последовательно переходим по вкладкам, настраиваем графики и Dashboard.
 Меню выбора графиков
Меню выбора графиков
Готовые установки Dashboard можно найти в Сети и импортировать в Kibana.
После импорта переходим в Dashboard, нажимаем Add и выбираем из списка нужный.
 Добавляем Dashboard
Добавляем Dashboard
Вывод
Готово! Минимум у нас уже есть. Дальше Kibana легко подстраивается индивидуально под потребности конкретной сети.
Управляем логами с ELK

Сколько себя помню в IT профессии, анализ и обработка логов — были всегда актуальной задачей. Оборудование и программное обеспечение постоянно генерируют лог записи о своей жизнедеятельности. И чем больше у Вас техники под управлением, тем больше массив данных, который ежедневно генерируется. Раньше были очень дорогие платные решения, типа HP ArcSight Logger, а также бесплатные опенсорсные как Adiscon LogAnalyzer. Но если первый тип продуктов, во-первых, был очень дорогим и недоступным для многих, а во-вторых, крайне «тяжелым» в эксплуатации. То второй тип программного обеспечения давал очень мало нужного функционала, слабо масштабировался и плохо проводил аналитику имеющихся логов. С приходом на IT сцену ELK — картина радикально поменялась. ELK или комплекс продуктов на базе Elastic Stack эффективно позволяет решать любые задачи с обработкой, хранением и визуализацией массивов логов различных устройств и программного обеспечения.
Сам по себе стек Elastic состоит из ряда отдельных продуктов, таких как Elasticsearch, Kibana, Logstash и ряда других. Однако все они взаимодополняют друг друга, работая как одно общее целое. Поэтому, принято говорить о работе всего стека ELK, который обрабатывает массив поступающей информации, позволяя ее эффективно анализировать и визуализировать. Elasticsearch — это ядро всего этого комплекса, которое отвечает за поиск нужной информации во всем массиве данных. Kibana — красивая визуальная среда, которая позволяет комфортно взаимодействовать с системой ELK ее пользователям. Ну а Logstash — это программное обеспечение, ответственное за прием данных из внешних источников и их обработку таким образом, чтобы дальше было легко их искать и анализировать.
Возможности
Процесс установки и первоначальной настройки ELK не сложен и описан во многих мануалах в Интернете. Как пример этого, для системы Centos 7 можно использовать эту статью. После ряда простых шагов, Вы получите установленные сервисы ElasticSearch, Kibana и Logstash. В качестве веб интерфейса всем этим делом используется Kibana. По умолчанию она устанавливается, как веб сервис, доступный по TCP/5601 порту. Для его защиты рекомендую использовать Nginx, настроенный как реверс прокси. Как это сделать, читаем тут.
Сама специфичная настройка стека ELK под нужды пользователей начинается с Logstash. Именно он принимает поток логов от приложений и оборудования, обрабатывает их запрограммированным образом и передает в ElasticSearch. Основная конфигурация Lostash происходит в командной строке в директории /etc/logstash/conf.d/. Именно здесь мы описываем, что принимать, как это обработать и сохранить.
В качестве примера приведу несколько типовых конфигураций. Так конфигурационный файл, который отвечает за прием логов по протоколу syslog в Logstash будет выглядеть следующим образом.
Конфигурационный файл, ответственный за передачу данных из Logstash в ElasticSearch, представлен ниже.
Другие файлы занимаются обработкой полученных логов с помощью плагина фильтрации grok. Этот плагин тема отдельной большой статьи. Он позволяет с помощью regex выражений и соответствующего преобразования совершать практически любые преобразования поступающей информации. Обязательно постараюсь в дальнейшем осветить тему создания и конфигурации фильтров grok в отдельной статье.
Следующий компонент ELK, с которым большую часть времени придется работать пользователю — это Kibana.
Не вдаваясь в этой статье в тонкие технические подробности, хочется показать основной потенциал, который дает эта система своим пользователям. При первоначальной загрузке веб интерфейса Вы попадаете на первую страницу, где показаны главные возможности всей системы. Ниже представлен скриншот из веб интерфейса Kibana.
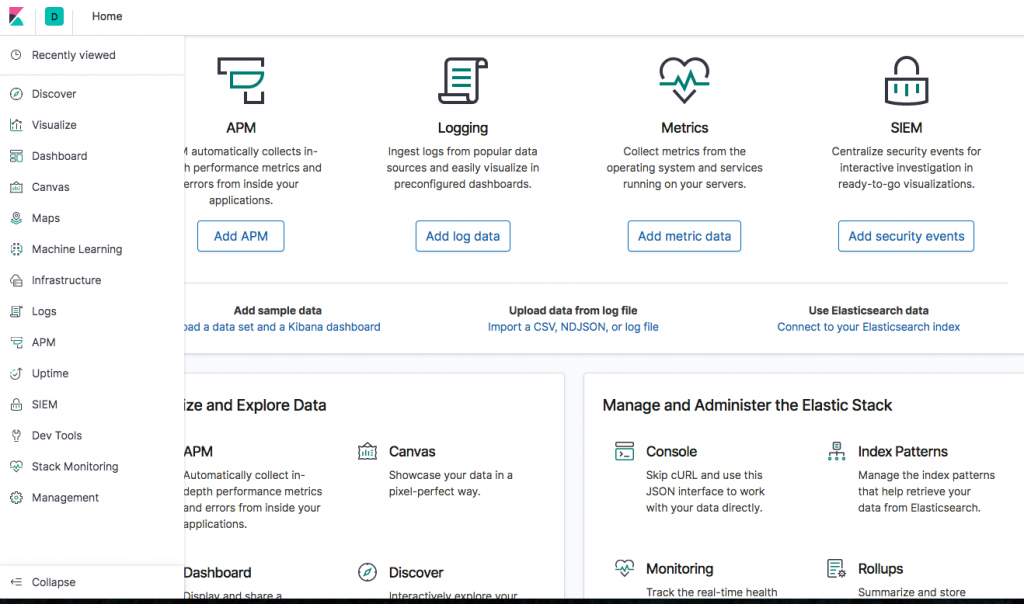
Слева Вы видите основные разделы Kibana. Это своеобразной main menu, которое позволяет быстро обратиться к нужному функционалу. Так в разделе Discover можно найти информацию, которая поступила через logstash в ElasticSearch. С помощью интуитивно понятных фильтров данная информация легко фильтруется и ищется то, что нужно в данный момент. В разеделе Visualize происходит графическое представление поступающей информации. Тут с помощью заданных шаблонов и определеяемых пользователем фильтров можно красиво представить имеющиеся данные. Пример такой визуализации привожу ниже на скриншоте.
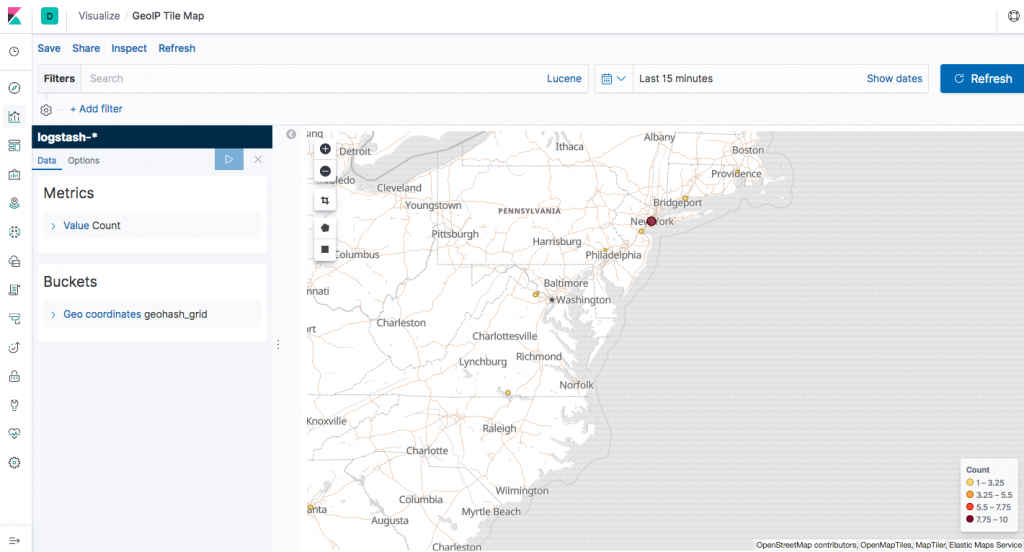
Способов визуализации информации достаточно много в рамках ELK. Это делает Elastic Stack ценнейшим инструментом анализа собираемых данных. По моему мнению, он в своей нише на данный момент вне конкуренции. При этом не важен источник информации. Анализ может производиться, к примеру, как по логам веб сервера Apache, так и по логам межсетевого экрана. Спектр поддерживаемого оборудования и программного обеспечения широчайшний. Что-то будет работать сразу из коробка. Для чего-то придется поработать ручками и головой, создавая необходимые конфигурации.
Остальные разделы в интерфейсе Kibana такие как Dashboards, Canvas, Maps и т.д. дают дополнительные возможности по анализу и систематизации логов. В целом система очень продвинутая с богатым фунционалом. Любому администратору или IT/ИБ директору она позволит эффективно решать вопросы по анализу логов практически от всех IT систем.
Резюме
Эта небольшая статья призвана познакомить моих читателей с проблематикой управления логами в современном мире IT. А также показать как этот вопрос изящно можно решать с помощью программного обеспечения Elastic Stack. В частности, для специалиствов по Информационной Безопасности имеются широкие возможности для выявления подозрительной активности. Последние версии ELK включают в себя функционал SIEM. То есть, Вам можно будет не использовать еще отдельное сложное решение по корреляции логов. Это, а также другие варианты использования делают Elastic одним из незаменимых инструментов ITшника.
3. Elastic stack: анализ security логов. Дашборды

В прошлых статьях мы немного ознакомились со стеком elk и настройкой конфигурационного файла Logstash для парсера логов, в данной статье перейдем к самому важному с точки зрения аналитики, то что вы хотите увидеть от системы и ради чего все создавалось — это графики и таблицы объединенные в дашборды. Сегодня мы поближе ознакомимся с системой визуализации Kibana, рассмотрим как создавать графики, таблицы, и в результате построим простенький дашборд на основе логов с межсетевого экрана Check Point.
Первым шагом работы с kibana — это создание index pattern, логически, это база индексов единых по определенному принципу. Разумеется, это исключительно настройка для того, чтобы Kibana более удобно искала информацию по всем индексам одновременно. Задается она по сопоставлению строки, допустим “checkpoint-*” и названия индекса. Например, «checkpoint-2019.12.05 » подойдет под паттерн, а просто «checkpoint» уже нет. Отдельно стоит упоминания, что в поиске искать информацию по разным паттернам индексов одновременно нельзя, чуть позже в последующих статьях мы увидим что API запросы делаются либо по названию индекса, либо как раз по одной строчке паттерну, картинка кликабельна:
После этого проверяем в меню Discover, что все логи индексируются, и настроен правильный парсер. Если обнаружатся какие либо несоответствия, например, поменять тип данных со строки на целое число, необходимо отредактировать конфигурационный файл Logstash, в результате новые логи будут записываться правильно. Для того, чтобы старые логи до изменения приняли нужный вид, помогает только процесс реиндексации, в последующих статьях эта операция будет рассмотрена более детально. Удостоверимся, что все в порядке, картинка кликабельна:
Логи оказались на месте, значит, можно приступить к построению дашбордов. На основе аналитики дашбордов от security продуктов можно понять состояние ИБ в организации, наглядно увидеть уязвимые места в текущей политике, и в дальнейшем выработать способы по их устранению. Построим небольшой дашборд, используя несколько средств визуализации. Дашборд будет состоять из 5 компонентов:
Таблица для подсчета суммарного количества логов по блейдам
Для этого выберем фигуру Data Table, проваливаемся в оснастку для создания графиков, слева проставляется настройки фигуры, справа то как она будет выглядеть в текущих настройках. Сначала продемонстрирую как будет выглядеть готовая таблица, после этого пройдем по настройкам, картинка кликабельна:
Более детальные настройки фигуры, картинка кликабельна:
Первоначально настраивается метрика, это значение, по которому будут агрегироваться все поля. Метрики вычисляются на основе значений, извлеченных тем или иным способом из документов. Значения обычно извлекаются из полей документа, но также могут быть сгенерированы с использованием скриптов. В данном случае ставим в Aggregation: Count (суммарное количество логов).
После этого делим таблицу по сегментам (полям), по которым будет считаться метрика. Эту функцию выполняет настройка Buckets, которая в свою очередь состоит из 2 вариантов настройки:
Вместо строк в elasticsearch используется 2 типа данных — text и keyword. Если вы хотите выполнить полнотекстовый поиск, вы должны использовать тип text, очень удобная вещь при написании своего поискового сервиса, например, ищете упоминание слова в конкретном значении поля (тексте). Если вы хотите только точное совпадение, вы должны использовать тип keyword. Так же тип данных keyword следует использовать для полей, требующих сортировки или агрегации, то есть, в нашем случае.
В результате Elasticsearch считает количество логов за определенное время с агрегированием по значению в поле product. В Custom Label задаем название колонны, которое будет отображаться в таблице, задаем время за которое собираем логи, запускаем прорисовку — Kibana отправляет запрос в elasticsearch, ждет ответ и после визуализирует полученные данные. Таблица готова!
Круговая диаграмма по событиям Threat Prevention
Определенный интерес представляет информация, а сколько вообще в процентном соотношении реакций detect и prevent на инциденты ИБ в текущей политике безопасности. Для такого случая хорошо подходит круговая диаграмма. Выбираем в Visualize — Pie chart. Также в метрике задаем агрегацию по количеству логов. В buckets ставим Terms => action.
Вроде все правильно, но в результате показываются значения по всем блейдам, нужно отфильтровать только по тем блейдам, которые работают в рамках Threat Prevention. Поэтому обязательно настраиваем фильтр для того, чтобы искать информацию только по блейдам отвечающие за инциденты ИБ — product: («Anti-Bot» OR «New Anti-Virus» OR «DDoS Protector» OR «SmartDefense» OR «Threat Emulation»). Картинка кликабельна:
И более детальные настройки, картинка кликабельна:
Таблица по событиям IPS
Далее очень важным с точки зрения ИБ является просмотр и проверка событий по блейду IPS и Threat Emulation, которые не блокируются текущей политикой, для того чтобы в последующем либо перевести сигнатуру в prevent, либо если трафик валидный — не проверять сигнатуру. Таблицу создаем также как и для первого примера, только с тем отличием, что создаем несколько колонн: protections.keyword, severity.keyword, product.keyword, originsicname.keyword. Обязательно настраиваем фильтр для того, чтобы искать информацию только по блейдам отвечающие за инциденты ИБ — product: ( «SmartDefense» OR «Threat Emulation»). Картинка кликабельна:
Более детальные настройки, картинка кликабельна:
Диаграммы по наиболее популярным посещаемым сайтам
Для этого создаем фигуру — Vertical Bar. Метрику также используем count (ось Y), а на оси X в качестве значений будем использовать название посещенных сайтов — “appi_name”. Тут есть небольшая хитрость, если запустить настройки в текущем варианте, то все сайты будут отмечаться на графике одним цветом, для того чтобы сделать их разноцветными используем дополнительную настройку — “split series”, которая позволяет делить уже готовую колонну на еще несколько значений, в зависимости от выбранного поля конечно! Это самое деление можно либо использовать как одна разноцветная колонна по значениям в режиме stacked, либо в режиме normal для того чтобы создать несколько колонн по определенному значения с оси X. В данном случае здесь мы используем то же значение, что и по оси X, это дает возможность сделать все колонки разноцветными, справа сверху они будут обозначаться цветами. В фильтре задаем — product:«URL Filtering» для того, чтобы увидеть информацию только по посещенным сайтам, картинка кликабельна:
Диаграмма по использованию наиболее опасных приложений
Для этого создаем фигуру — Vertical Bar. Метрику также используем count (ось Y), а на оси X в качестве значений будем использовать название используемых приложений- “appi_name”. Наиболее важным является задание фильтра — product: «Application Control» AND app_risk: (4 OR 5 OR 3 ) AND action:«accept». Фильтруем логи по блэйду Application control, берем только те сайты которые категоризированы как сайты с риском Critical, High, Medium и только в том случае если на эти сайты доступ разрешен. Картинка кликабельна:
Дашборд
Просмотр и создание дашбордов находится в отдельном пункте меню — Dashboard. Здесь все просто, создается новый дашборд, в него добавляется визуализация, расставляется по местам и все!
Создаем дашборд, по которому можно будет понять базовую ситуацию состояния ИБ в организации, понятно, только на уровне Check Point, картинка кликабельна:
На основе этих графиков мы можем понять какие критические сигнатуры не блокируются на межсетевом экране, куда ходят пользователи, какие наиболее опасные приложения они используют.
Заключение
Мы рассмотрели возможности базовой визуализации в Kibana и построили дашборд, но это лишь малая часть. Далее в курсе отдельно рассмотрим настройку карт, работу с системой elasticsearch, познакомимся с API запросами, автоматизацией и много чего еще!



