Сборка логов в kubernetes. Установка EFK стека с LDAP интеграцией. (Bitnami, opendistro)
Постепенно эволюционируя, каждая организация переходит от ручного grep логов к более современным инструментам для сбора, анализа логов. Если вы работаете с kubernetes, где приложение может масштабироваться горизонтально и вертикально, вас просто вынуждают отказаться от старой парадигмы сбора логов. В текущее время существует большое количество вариантов систем централизованного логирования, причем каждый выбирает наиболее приемлемый вариант для себя. В данной статье пойдет речь о наиболее популярном и зарекомендовавшем себя стэке Elasticsearch + Kibana + Fluentd в связке с плагином OpenDistro Security. Данный стэк полностью open source, что придает ему особую популярность.
Проблематика
Нам необходимо было наладить сборку логов с кластера kubernetes.
Требования:
Использование только открытых решений
Сделать очистку логов.
Аутентификация на базе LDAP
Данный материал предполагает:
Имеется установленный kuberenetes 1.18 или выше (ниже версию не проверяли)
Установленный пакетный менеджер helm версии 3
Немного о helm chart
Наиболее популярным способом установки приложения в kubernetes является helm. Helm это пакетный менеджер, с помощью которого можно подготовить набор компонентов для установки и связать их вместe, дополнив необходимыми метриками и конфигурацией.
Преимущества такого решения:
собраны open source продукты.
стандарты по разработке чатов и докер образов
проект живой и активно поддерживается сообществом
Выбор стека
Во многом выбор стека технологий определило время. С большой долей вероятностью два года назад мы бы деплоили ELK стек вместо EFK и не использовали helm chart.
Fluentd часто упоминается в документации, широко распространен, имеет большое количество плагинов, на все случаи жизни. К тому же у нас есть человек, который после обучение в rebrain и очень хотел внедрить fluentd.
Elasticsearch и kibana поставляются под открытой лицензией, однако плагины безопасности и другие «вкусности» идут под иной лицензией. Компания Amazon выпустила набор плагинов Open Distro, которые покрывают оставшийся функционал под открытой лицензией.
Схема выглядит примерно так
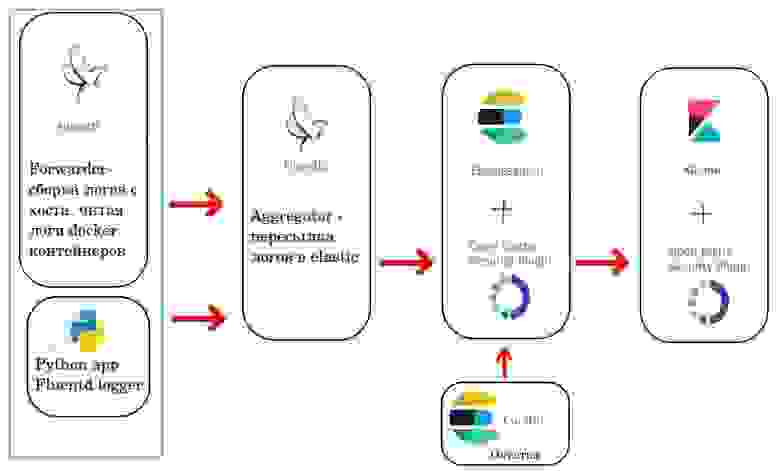
Хорошим тоном является вынесение инфраструктурных компонентов в отдельный кластер, поэтому зеленым прямоугольником выделена та часть, которая должна быть установлена на все кластера в которых должны собираться логи.
Минимальный деплой EFK стека (без Security)
Сборка EFK стека была произведена по статье Collect and Analyze Log Data for a Kubernetes Cluster with Bitnami’s Elasticsearch, Fluentd and Kibana Charts. Компоменты упакованы в отдельный чат. Исходники можно взять здесь и произвести командой
Из исходников values-minimal.yaml
Как видим компонент fluentd forwarder не включен. Перед включением парсинга, я рекомендовал бы настроить на определенные логи, иначе еластику может быть послано слишком большое количество логов. Правила для парсинга описаны в файле apache-log-parser.yaml.
Как отправить логи в EFK
Существует много способов, для начала предлагаем либо включить fluentd forwarder, либо воспользоваться простейшим приложением на python. Ниже пример для bare metal. Исправьте FLUENT_HOST FLUENT_PORT на ваши значения.
По ссылке http://$(minikube ip):30011/ Будет выведено «Hello, world!» И лог уйдет в elastic

Включить fluentd forwarder, он создаст daemon set, т.е. запустится на каждой ноде вашего кубернетеса и будет читать логи docker container-ов.
Добавить в ваш докер контейнер драйвер fluentd, тем более можно добавлять более одного драйвера
Добавить в ваше приложение библиотеку, которая будет напрямую логировать. Пример приложения на python. Используйте его, как отладочное средство при установке EFK.
И как показывает практика, логировать напрямую эффективный, но далеко не самый надежный способ. Даже если вы логируете сразу в fluentd и в консоль. В случае потери конекта, во fluentd часть логов просто не смогут попасть и будут потеряны для него навсегда. Поэтому наиболее надежный способ, это считывать логи с диска для отправки в EFK.
Очистка логов
Для очистки логов используется curator. Его можно включить, добавив в values-minimal.yaml :
По умолчанию его конфигурация уже предусматривает удаление индекса старше 90 дней, это можно увидеть в конфигурации внутри подчата efk/charts/elasticsearch-12.6.1.tgz!/elasticsearch/values.yaml
Security
Как обычно security доставляет основную боль при настройке и использовании. Но если ваша организация чуть подросла, это необходимый шаг. Стандартом де факто при настройке безопасности является интеграция с LDAP. Официальные плагины от еластика выходят не под открытой лицензией, поэтому приходится использовать плагин Open Distro. Далее продемонстрируем, как его можно запустить.
Сборка elasticsearch c плагином opendistro
Вот проект в котором собирали docker images.
Для установки плагина, необходимо, чтобы версия elasticsearch соответствовала версии плагина.
В quickstart плагина рекомендуется установить install_demo_configuration.sh с демо сертификатами.
Есть небольшая магия, ввиду, того что плагин дополняет elasticsearch.yml, а контейнеры bitnami только при старте генерируют этот файл. Дополнительные же настройки они просят передавать через my_elasticsearch.yml
В my_elasticsearch.yml мы изменили настройку, это позволит нам обращаться к рестам elasticsearch по http.
Сделано это в демонстрационных целях, для облегчения запуска плагина. Если вы захотите включить Rest Layer tls придется добавлять соответствующие настройки во все компоненты, которые общаются с elasticsearch.
Запуск docker-compose с LDAP интеграцией
Теперь у нас есть вкладка Security
Можно посмотреть настройку LDAP через интерфейс кибаны

Настройки должны совпадать с файлами конфигурации. Стоит обратить внимание, что плагин хранит свои данные в индексе еластика, и файлы конфигурации применяет при инициализации, т.е. если индекс не создан. Если вы измените файлы позже то вам придется воспользоваться утилитой securityadmin.sh
настройка Ldap
Для настройки интеграции с LDAP необходимо заполнить соответствующие секции в elastisearch-opendistro-sec/config.yml, ссылка на официальную документацию по authentication
В случае с Active Directory, необходимо будет изменить конфигурационный файл примерно так:
Не забудьте воспользоваться securityadmin.sh после изменения конфигурации. Процедура была описана в предыдущем параграфе.
Установка EFK + Opendistro в kubernetes
Вернемся к проекту с kubernetes, установим проект командой
Нам необходимо будет
Для настройка OpenDistro Security plugin мы скопировали файл конфигурации, которые поместим в секреты kubernetes, в values.yaml добавился блок:
Чтобы настройки применялись при команде helm upgrade, мы сделали job, который будет запускаться при каждой команде helm upgrade
Итоги
Если вы собираетесь организовать централизованную сборку логов для приложений под управление kubernetes, данный вариант мог бы стать вполне обоснованным решением. Все продукты поставляются под открытыми лицензиями. В статье приведена заготовка из которой можно создать production ready решение. Спасибо за внимание!
EFK (Elasticsearch + Fluentd + Kibana) или как мы логи собираем
Данная статья будет обзорной и не претендует на авторское решение проблем сбора, доставки, хранения и обработки логов.

Выдумывать велосипеды совершенно не нужно, когда есть отличнейший инструмент, позволяющий жонглировать логами так как нам это удобно — и это Elastic Stack. Данное решение проверено временем и стает еще лучше с каждым релизом, а так он еще и бесплатен. Если интересно — тогда добро пожаловать.
Наш стэк не уникален, все как у всех, кроме разбежности в выборе самого коллектора. Здесь выбор был между классическим и зрелым решением Elastic Stack — Logstash и более новым инструментом Fluentd.
Сейчас время сказать: “Стоп, ты же сам сказал, что выдумывать велосипеды совершенно не нужно”. Верно. Поэтому далее объясню почему мы выбрали Fluentd.
Изначально, естественно на этапе планирования, куда же без него, заглянули в будущее 🕒 и прикинули, что неплохо было бы на K8s перебираться (“а чего такого!?” — стильно, модно, молодежно 😃 ), а если так, то нужно смотреть в сторону инструмента, который используется в нем (де факто) и это — Fluentd.
Ну а пока нету K8s, но есть проекты на Docker, нужно сделать так, чтобы потом было меньше проблем.
Архитектура
Архитектурно сервис собран на одном инстансе. Состоит из клиентской части и коллектора (коллектором будем называть весь EFK стэк). Клиент пересылает, а коллектор, в свою очередь, занимается обработкой логов.
Проект был полностью собран на Docker. Деплоится это все с помощью бережно написанных манифестов Puppet. Вообще он забавно деплоит контейнеры прописывая их в Systemd как сервис, поначалу было непривычно, а потом стало даже удобно, так как за состоянием контейнера начинает следить демон Systemd.
Сам сервис выглядит вот так:
Итак, состав нашего стэка следующий:
Наглядно весь EFK стэк (коллектор) изображен на схеме.

Какие логи мы собираем:
Тут рисуется вопрос: “А как это все работает под капотом?”.
Клиентская часть (Агент)
Рассмотрим пример доставки лога от Docker контейнера.
Есть два варианта (на самом деле их больше тыц) как писать лог Docker контейнеров. В своем дефолтном состоянии, используется Logging Driver — “JSON file”, т.е. пишет классическим методом в файл. Второй способ — это переопределить Logging Driver и слать лог сразу в Fluentd.
Решили мы попробовать второй вариант.
Далее столкнулись с такой проблемой, что если просто сменить Logging Driver и, если вдруг, TCP сокет Fluentd, куда должны сыпаться логи, не доступен, то контейнер вообще не запустится. А если TCP сокет Fluentd пропадет, когда контейнер ранится, то логи начинают копиться в буфер.
Происходит это потому, что у Docker есть два режима доставки сообщений от контейнера к Logging Driver:
direct — является дефолтным. Приложение падает, когда не может записать лог в stdout и/или stderr.
non-blocking — позволяет записывать логи приложения в буфер при недоступности сокета коллектора. При этом, если буфер полон, новые логи начинают вытеснять старые.
Все эти вещи подтянули дополнительными опциями Logging Driver
(—log-opt).
Но, так как нас не устроил ни первый, ни второй вариант, то мы решили не переопределять Logging Driver и оставить его дефолтным.
Итак, первое на что было обращено внимание — это продукт FluentBit.
Настройка FluentBit достаточна проста, но мы столкнулись с несколькими неприятными моментами.
Проблема заключалась в том, что если TCP сокет коллектора не доступен, то FluentBit начинает активно писать в буфер, который находится в памяти и по мере его заполнения, начинает вытеснять (перезаписывать) лог, до тех пор, пока не восстановит соединение с коллектором, а следовательно, мы теряем логи. Это не критикал, но крайне неприятно.
Решили эту проблему следующим образом.
FluentBit в tail плагине имеет следующие параметры:
DB — определяет файл базы данных, в котором будет вестись учет файлов, которые мониторятся, а также позицию в этих файлах (offsets).
DB.Sync — устанавливает дефолтный метод синхронизации (I/O). Данная опция отвечает за то, как внутренний движок SQLite будет синхронизироваться на диск.
И стало все отлично, логи мы не теряли, но столкнулись со следующей проблемой — эта штука очень жутко начала потреблять IOPs. Обратили на это внимание когда заметили, что инстансы начали тупить и упираться в IO, которого раньше хватало за глаза и сейчас объясню почему.
Мы используем EC2 инстансы (AWS) и тип EBS — gp2 (General Purpose SSD). У них есть такая штука, которая называется “Burst performance”. Это когда EBS способен выдерживать некоторые пики возрастающей нагрузки на файловую систему, например запуск какой-нибудь крон задачи, которая требует интенсивного IO и если ему недостаточно “baseline performance”, инстанс начинает потреблять накопленные кредиты на IO т.е. “Burst performance”.
Так вот, наша проблема заключалась в том, что были вычерпаны кредиты IO и EBS начал захлебываться от его недостатка.
Ок. Пройденный этап.
После этого мы решили, а почему бы не использовать тот же Fluentd в качестве агента.
У ELK’и иголки колки: минимизируем потерю сообщений в Logstash, следим за состоянием Elasticsearch

Стек от Elastic — одно из самых распространенных решений для сбора логов. А точнее — две его разновидности: ELK и EFK. В первом случае речь идет про Elasticsearch, Logstash, Kibana (а еще — Beats, который даже не участвует в аббревиатуре, о чем шутят сами создатели: «Do we call it BELK? BLEK? ELKB?»). Вторая связка — Elasticsearch, Fluentd и Kibana (уже без шуточек). У каждого элемента в этих стеках есть своя роль и выход из строя одного из них зачастую нарушает работу остальных. В этой статье поговорим об ELK-стеке, а в частности — о двух его элементах: Logstash и Elasticsearch.
Статья не является исчерпывающим руководством по тонкостям установки и настройки этих элементов. Это скорее обзор некоторых полезных фич и чек-лист по мониторингу не самых очевидных моментов, чтобы минимизировать потерю сообщений, проходящих через ELK. Также стоит упомянуть, что в статье мы не коснемся тем, связанных с программами-коллекторами (посредством чего сообщения попадают в Logstash) из-за их великого разнообразия: речь пойдет только о core-компонентах.
Logstash
Logstash, как правило, выступает для сообщений посредником, трансферной зоной. Он хранит эти сообщения в оперативной памяти, что является эффективным с точки зрения скорости их обработки, но чревато их потерей при перезапуске logstash. Также возможен сценарий, когда сообщений в очереди набирается настолько много (например, Elasticsearch перезапускается и недоступен), что Logstash начинает утекать по памяти, OOM-иться и перезапускается, поднимаясь уже «пустым».
Persistent Queue
Если через Logstash проходят важные сообщения, потеря которых критична (например, когда он выступает в роли consumer’а какого-либо брокера сообщений) или если нам необходимо переждать возможный большой даунтайм — например, во время тех. работ — со стороны получателя сообщений (обычно это Elasticsearch), можно прибегнуть к использованию persistent queue (документация). Это настройка Logstash, позволяющая хранить очереди на диске.
Также обратим внимание на queue.max_bytes — общая емкость очереди. Значение по умолчанию — 1 Гб. При его достижении (т.е. если у нас скопилось файлов очереди на 1 Гб) новые сообщения Logstash не принимает, пока очередь не начнет разбираться и в ней не появятся свободные места. Если мы настроили PV для persistent queue размером, например, 4 Гб, следует не забыть изменить эту переменную.
Еще из интересного: persistent queue хранит очереди в файлах, называемых страницами. Как только страница достигает определенного размера — queue.page_capacity (по умолчанию 64 Мб), — она становится неизменяемой, т.е. блокируется для записи (ждет, пока ее сообщения будут разобраны). После этого создается новая активная страница, которая аналогично ждет, пока не вырастет до размера queue.page_capacity … Каждая страница хранит какое-то количество сообщений и, если хотя бы одно сообщение из этой страницы не было отправлено, страница не будет удалена с диска (и будет занимать место, установленное в queue.max_bytes ). По этой причине выставлять большое значение для queue.page_capacity не рекомендуется.
Подведем краткий итог. Persistent queue отлично подойдет, если вам важно минимизировать потерю сообщений, однако желательно протестировать его перед эксплуатацией в production-окружении, т.к. сохранение сообщений на диске (вместо оперативной памяти) может повлечь за собой небольшую потерю в производительности. Пример теста производительности можно найти в официальном блоге Elastic.
Dead Letter Queue
Раз уж мы заговорили о persistent queue, что позволяет добиться минимизации потери сообщений, стоит рассказать и про dead letter queue (документация). Эта функция позволяет сохранять сообщения с ошибкой маппинга. Часто их оказывается больше, чем ожидалось. Начнем с нескольких «но»:
DLQ работает только с сообщениями, которые изначально адресовались в Elasticsearch, т.е. DLQ будет собирать сообщения с неудачным маппингом только у тех пайплайнов, output которых был настроен на Elasticsearch.
Сообщения с ошибкой маппинга Logstash складывает локально на диск в файлы. Он умеет отправлять эти сообщения в Elasticsearch при помощи input-плагина DLQ, но файлы эти с диска после отправки он не удалит.
1. Мы создаем новый пайплайн dead-letter-queue-main.conf :
2. Мы создали пайплайн, но DLQ еще не включили. Для этого в pipelines.yml для main-пайплайна включаем DLQ и добавляем в список пайплайнов наш dead-letter-queue-main.conf :
Однако стоит обратить внимание на то, что сами сообщения DLQ с диска не удаляются — это еще не реализовано. Есть разные способы того, как с этим справляются пользователи, однако официально решения пока нет.
DLQ будет полезен, если вы стали замечать, что какие-то сообщения не доходят до Elasticsearch или просто хотите обезопаситься от этого. Подобное возможно, если структура сообщений меняется и Elasticsearch не может их обработать. В этом случае DLQ пригодится, однако помните, что эта функция еще не доведена до совершенства и некоторые аспекты применения приходится додумывать самостоятельно (как для случая с удалением DLQ с диска).
Elasticsearch
Elasticsearch можно назвать центром системы — он хранит наши сообщения. В этой части хочется упомянуть несколько моментов, которые позволят следить за его здоровьем.
Мониторинг
Начнем с того, что у Elastic-стека есть расширение X-Pack, которое содержит в себе много дополнительного функционала, платного и бесплатного. Начиная с версии 6.3 бесплатный функционал поставляется в стандартных сборках стека (basic-версия включена по умолчанию).
Весь список функций, предоставляемых X-Pack, можно посмотреть на официальном сайте. В столбце «BASIC — FREE AND OPEN» перечислено то, что доступно бесплатно.
NB. Что касается платных подписок — какой-то конкретной цены нет, она индивидуальна для каждого проекта и строится относительно задействованных ресурсов. Если открыть страницу с ценами, то для кластеров self-hosted вместо цены мы увидим кнопку «Contact us».
Итак, вернемся к бесплатной версии: некоторые функции в ней включены по умолчанию, а некоторые необходимо включить самим.
Мониторинг состояния узла Elasticsearch Подробная информация по конкретному индексу
Аналогичным способом можно включить мониторинг для Logstash, добавив xpack.monitoring.enabled: true и xpack.monitoring.elasticsearch.hosts: «адрес_эластика:9200» (однако является legacy-решением начиная с релиза 7.9.0 от августа прошлого года).
Мониторинг состояния узла logstash
Также мы можем настроить авторизацию для своего кластера, включая окно авторизации для Kibana. Этому посвящен раздел Security. X-Pack содержит в себе много интересного функционала даже в бесплатной версии, однако часто случается так, что какие-то функции бесплатной фичи не работают с basic-лицензией.
Мониторинг, предоставляемый X-Pack’ом, — это просто красивая информативная панель, которая умеет показывать графики, что сможет нарисовать не каждый экспортер. Однако не стоит полностью на него полагаться, т.к. данные о мониторинге Elasticsearch хранятся в индексах, хранящихся в этом же Elasticsearch. Из-за этого система не кажется надежной (если у вас Elasticsearch из одного узла, то и вовсе таковой не является).
В связи с этим в официальной документации упоминается, что правильный подход — когда для production-контура у вас есть отдельный кластер для мониторинга. Для полноценного мониторинга узла необходимо настроить экспортер для самого Elasticsearch, чтобы следить за здоровьем кластера, unassigned-шардами, состоянием узлов. и еще экспортер для самой виртуальной машины для мониторинга нагрузки и свободного места на диске. Тут хочется обратить внимание на watermark.
Watermark
При настройке алертинга о заканчивающемся месте на диске стоит принимать во внимание watermark. Это настройка Elasticsearch, которая следит за свободным местом на диске, на который Elasticsearch складывает данные. В зависимости от объема оставшегося места разворачивается один из сценариев:
Последний вариант (flood_stage) может быть болезненным, т.к. при read_only_allow_delete удалять индексы можно, но документы из них — нет.
Менять настройки индекса, создавать шаблоны можно через запросы к Elasticsearch API прямо curl’ом (подробнее см. ниже) или через специальный UI — Cerebro.
При настройке мониторинга хоста, на котором установлен узел Elasticsearch, обязательно стоит учитывать параметры watermark. Также стоит обратить внимание, что значения у параметров watermark можно устанавливать не только в процентах свободного дискового объема, но и в единицах измерения этого самого объема. Это очень полезно, если используются большие диски: ведь не так критично, если у терабайтного диска занято 85% места, для таких случаев можно выставить и значения вроде 150 Гб.
Cheat sheet
… или просто прописать: NODE_IP=»ip_узла_эластика:9200″
Общие запросы
1. Посмотреть версию Elasticsearch:
2. Проверить здоровье кластера. Если статус green — все отлично. В противном случае, вероятнее всего, у нас есть unassigned shards:
3. Проверить здоровье узлов:
4. Список узлов, их роли и нагрузка на них:
В поле node.role можно увидеть «Поле Чудес» из букв. Расшифровка:
Master eligible node ( m );
5. Статистика по занимаемому месту на узлах и по количеству шардов на них:
6. Посмотреть список плагинов:
7. Посмотреть настройки кластера, включая дефолтные:
8. Проверить значения watermark:
Индексы, шарды
1. Посмотреть список индексов:
2. Список индексов, отсортированный по размеру:
3. Посмотреть настройки индекса:
4. Снять read-only с индекса:
6. Посмотреть список unassigned shards:
7. Проверить, почему не размещаются шарды:
8. Удалить реплика-шард для индекса:
9. Удалить индекс/шард:
Шаблоны
2. Смотреть настройки шаблона:
3. Пример создания шаблона:
Заключение
Logstash выступает посредником в трансфере сообщений. Основная его задача — правильно обработать сообщение ( filter ) и отправить его дальше ( output ). Persistent и Dead Letter Queue помогут эффективно решать эти задачи, однако в первом случае мы заплатим за это производительностью, а во втором — столкнемся с сыростью решения.
Elasticsearch — центр нашей системы. Не важно, собирает он логи или задействован в поисковой системе, — в любом случае необходимо следить за его состоянием. Даже в базовой версии X-Pack можно настроить неплохой сбор статистики о индексах и состоянии узлов. Также обязательно стоит обратить внимание на watermark: часто о нем забывают при настройке алертинга.



