Что такое DWH и почему без них данные компании почти бесполезны
Тем, кто работает в крупном бизнесе, периодически приходится слышать три магические буквы — DWH. Узнав расшифровку этой аббревиатуры — data warehouse, можно догадаться, что это имеет отношение к данным. А вот чем DWH отличается от простых баз данных, почему вокруг них снуют рои бизнес-аналитиков и зачем вашей компании иметь такую штуку — это всё еще непонятно. Разбираемся в статье.
DWH — что это и в чем отличие от баз данных
Data warehouse — склад всех нужных и важных для принятия решений данных компании.
Но есть же всякие базы данных внутри фирмы, разве они не DWH? Например, СУБД с клиентами, складскими запасами или покупками. Где разница между обычной базой данных и DWH?
Короче говоря, DWH — это система данных, отдельная от оперативной системы обработки данных. В корпоративных хранилищах в удобном для анализа виде хранятся архивные данные из разных, иногда очень разнородных источников. Эти данные предварительно обрабатываются и загружаются в хранилище в ходе процессов извлечения, преобразования и загрузки, называемых ETL. Решения ETL и DWH — это (упрощенно) одна система для работы с корпоративной информацией и ее хранения.
Что дают DWH-решения для BI и принятия решений в компании
Понятное дело, что просто так тратить деньги и время на консервирование кучи разных записей, которые и так можно накопать в других базах данных, никто не станет. Ответ заключается в том, что DWH необходима для того, чтобы делать BI — business intelligence.
Что такое BI с DWH? Бизнес-аналитика (BI) — это процесс анализа данных и получения информации, помогающей компаниям принимать решения.
Если бы такого аналитического отчета не было — управленцам пришлось бы искать проблему наугад.
Логичный вопрос: казалось бы, зачем держать для этого всего DWH? Аналитики вполне могут ходить в базы данных разных систем и просто выдергивать оттуда то, что им надо.
Ответ: так, конечно, тоже можно делать. Но — не нужно. И вот почему:
Для работы с большими данными используют различные решения, обрабатывающие информацию из DWH. SAS, VK Cloud Solutions (бывш. MCS) и другие компании предлагают различные варианты коробочных и облачных решений под такие задачи.
Основные функции ETL-систем
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
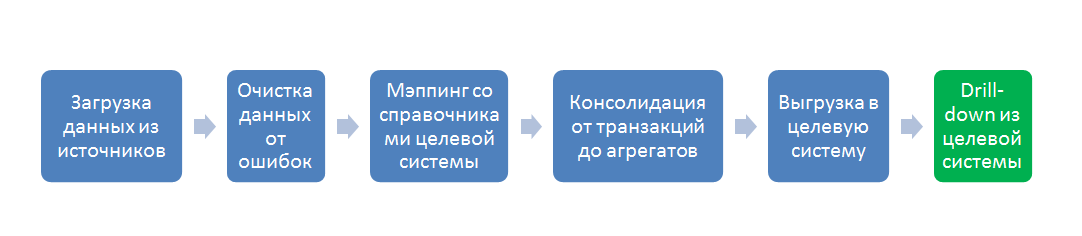
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
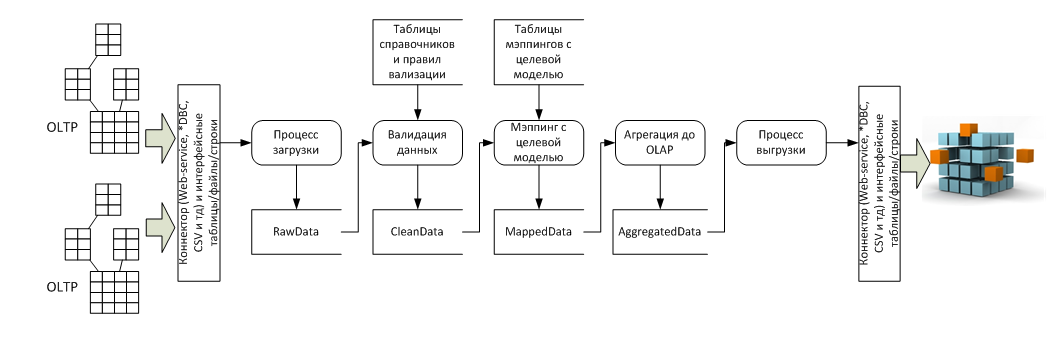
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
Процесс валидации
Данный процесс отвечает за выявление ошибок и пробелов в данных, переданных в ETL.
Само программирование или настройка формул проверки не вызывает вопросов, главный вопрос – как вычислить возможные виды ошибок в данных, и по каким признакам их идентифицировать?
Возможные виды ошибок в данных зависят от того какого рода шкалы применимы для этих данных. (Ссылка на прекрасный пост, объясняющий, какие существуют виды шкал — http://habrahabr.ru/post/246983/).
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
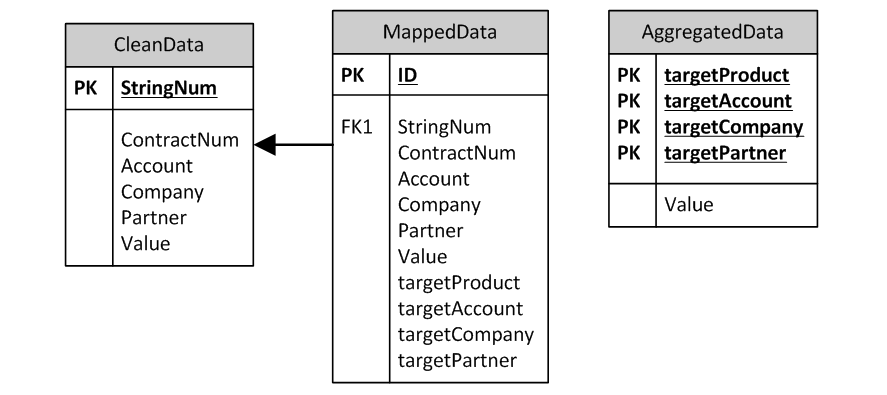
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
ETL: качественные данные для принятия управленческих решений
Организационные изменения, рано или поздно происходящие в жизни любой компании, чаще всего влекут за собой необходимость интеграции различных информационных систем. Для чего нужна интеграция? Она необходима для того, чтобы разные системы могли использовать единое информационное пространство, осуществлять обмен данными, хранить, анализировать и обрабатывать их для последующего принятия управленческих и оперативных решений. Если принимать решения на основании данных, полученных только из одной системы, рано или поздно возникнет хаос, прежде всего по причине разнородного представления и детализации одних и тех же данных в различных системах, наличия ошибок, вызванных человеческим фактором и т.д. Как показывает опыт, наиболее эффективным способом хранения информации для ее последующего анализа и обработки, являются аналитические хранилища с витринами данных, на основе которых пользователь может осуществлять любые аналитические запросы и получать те или иные необходимые показатели.

Интеграционные методы: плюсы и минусы
Существуют различные методы интеграции информационных систем. У каждого из них свои преимущества и недостатки. Так, метод федерализации не предусматривает транспортировку данных, они остаются у владельцев, а доступ к ним осуществляется по запросу. Однако у этого подхода есть и существенные ограничения. Все федеративно распределенные базы, служащие источниками, данных должны находиться в формате одного приложения или СУБД, или требуется специальное ПО для интеграции гетерогенных сред. Кроме того, все источники должны находиться в постоянной доступности, а это не всегда осуществимо. Если обмен данными с одним из источников происходит на низкой скорости, это отразится на работе всего интеграционного механизма. Одновременный обмен данными с двумя различными источниками в момент пользовательского запроса должен осуществляться “на лету”. Это сопряжено с достаточно высокими накладными расходами, поскольку требует загрузки достаточно большого объема информации.
Другой метод интеграции, с применением универсальной шины данных (Universal Serial Bus), также имеет ряд функциональных ограничений. Это, прежде всего, пропускная способность, поскольку шина представляет собой сервис со встроенным механизмом регистрации гарантированной доставки. Если необходимо передать мегабайты данных или осуществить обмен мастер-данными, периодически синхронизировать отдельные документы, то применение универсальной шины будет целесообразно и удобно. Но когда речь идет о постоянном потоке данных, в том числе, генерируемом умными устройствами, пропускной способности шины будет явно недостаточно. К примеру, в реализованном компанией RedSys проекте по развертыванию инфраструктуры для скоростных трамваев в Санкт-Петербурге, с помощью универсальной шины данных осуществляется передача мастер-данных, а также передается информация о сотрудниках из кадровой системы в систему управления движением транспорта.
Свои ограничения накладывает и интеграционный метод на основе репликации. В первую очередь, это требование наличия единой платформы от одного и того же вендора. Для репликации в гетерогенной среде необходимо наличие специального инструментария, выбор которого зависит от используемых в организации СУБД. Разумеется, это не может не отразиться на конечной себестоимости интеграционного проекта.
Мы сегодня живем и работаем в эпоху больших данных, которые генерируют не только информационные системы, с которыми работают люди, но и умные устройства и датчики Интернета вещей, а также множество других неодушевленных машин. Для получения и обработки таких объемов данных лучше всего подходит метод интеграции ETL (Extract, Transform, Load). Он позволяет получать данные, проверять их, унифицировать, сохранять для последующей подготовки на их основе аналитической информации.
В механизме ETL-интеграции источник данных может выступать как в качестве клиента, так и в качестве сервера. Во втором случае целесообразным будет применение модулей извлечения измененных данных CDC (Change Data Capture). В тех случаях, когда источник данных одновременно занят решением других задач, либо с ним работают пользователи, использование CDC позволяет избежать дополнительных нагрузок. Источник данных может быть назначен и в качестве клиента. В этом случае система, которая служит источником данных сама переводит данные в CSV, XML или другой универсальный промышленный формат, а ETL периодически забирает эти файлы для дальнейшей обработки.
Метод ETL-интеграции характеризуется глубоким преобразованием данных. Она осуществляется в хранилище данных, которое включает в себя, в классической модели, три слоя. Первый слой представляет собой копии источников данных с добавлением специальных ключей, обеспечивающих уникальность и историчность информации. Второй слой отвечает за логическую обработку и унификацию. Он формирует из данных объектную модель в аналитическом разрезе. Третий слой осуществляет загрузку витрин данных для анализа, с приведением всех показателей к нужным разрезам, всеми необходимыми расчетами и т.д.
Когда речь идет о нескольких обширных несинхронизированных источниках данных, разрозненных справочниках НСИ, эти данные необходимо привести в унифицированный вид. Здесь на помощь приходят MDM-системы. В разветвленных холдинговых структурах, где могут работать десятки систем от различных производителей, без MDM порой очень сложно, например, подсчитать доходы и расходы по тем или иным статьям доходов и расходов. Некачественные данные способны существенно сузить ценность BI-информации, на основании анализа которой принимаются управленческие решения. Для дальнейшей поддержки качества данных необходима связь с источником, благодаря которой можно было бы передавать информацию для исправления. Также может быть сформирована специальная витрина или “корзина” низкокачественных данных, которые были по тем или иным причинам отвергнуты. Обнаружить такие данные помогают механизмы ETL.
Инструментарий и специалисты
Что касается инструментов для ETL-интеграции, то здесь достаточно широкое поле для выбора. Существуют как специализированные решения для конкретных СУБД, разработанные чаще всего их же разработчиками (Oracle Data Integrator, IBM DataStage, Informatica PC, Integration Services (SSIS) в составе MS SQL Server), а есть универсальные продукты. Лидером “магического квадранта” Gartner в сегменте решений для ETL-интеграции считается компания Informatica с ее продуктами. Все это системы промышленного уровня, которые умеют динамически распределять нагрузку между источниками и BI-хранилищем, поддерживают параллелизм выполнения операций и обладают целым рядом других функций. Как правило, платформа хранилища данных у заказчика уже определена, поэтому целесообразно будет использовать ETL-решение от разработчика платформы, используемой в хранилище. Решения компании Informatica весьма дорогостоящие, однако по техническим возможностям они же и являются наиболее продвинутыми, наиболее производительными и масштабируемыми. Их можно применять интегрировать с хранилищем данных на любой платформе.
В основе реализованного компанией RedSys проекта по построению хранилища данных в Пенсионном Фонде РФ лежат решения компании IBM, а в качестве ETL-инструментария используется IBM DataStage. Для поддержки интеграционных ETL-проектов в организации необходимо наличие трех категорий специалистов: архитекторов, в чьи обязанности входит проектирование хранилища данных; аналитики, как бизнес, так и системные, компетенции которых заключаются в сборе данных и требований бизнеса, составлении спецификаций, а также программисты, занимающиеся отладкой ETL-процессов.
Выгоды для бизнеса
Что дает ETL-интеграция бизнесу? Выгоду можно охарактеризовать двумя словами: “дорого, но эффективно”. Конечно, это весьма затратная составляющая комплексного проекта по построению аналитического хранилища данных. Поэтому все преимущества нужно рассматривать именно в разрезе наличия или отсутствия единого BI-хранилища в компании. Его отсутствие ведет к тому, что бизнес просто не получит оперативно ответы на стратегически важные вопросы. Единый взгляд на картину производства и продажи продуктов и услуг, их доходность и себестоимость, позволяет, в том числе минимизировать разногласия между производственными и финансовыми подразделениями компании, а в случае необходимости — перераспределить ресурсы в пользу более выгодных и эффективных направлений. Нельзя забывать и о снижении затрат. Вместо отдельных департаментов и сотрудников, собирающих данные в рамках своих бизнес-единиц, данные собираются в автоматизированном режиме и гораздо быстрее, при этом их качество несравнимо выше. Наконец, использование ETL-интеграции позволяет заказчику сосредоточить усилия на организационной, а не технической составляющей BI-проекта.
Обзор гибких методологий проектирования DWH
Разработка хранилища — дело долгое и серьезное.
Многое в жизни проекта зависит от того, насколько хорошо продумана объектная модель и структура базы на старте.
Общепринятым подходом были и остаются различные варианты сочетания схемы “звезда” с третьей нормальной формой. Как правило, по принципу: исходные данные — 3NF, витрины — звезда. Этот подход, проверенный временем и подкрепленный большим количеством исследований — первое (а иногда и единственное), что приходит в голову опытному DWH-шнику при мысли о том, как должно выглядеть аналитическое хранилище.
С другой стороны — бизнесу в целом и требованиям заказчика в частности свойственно быстро меняться, а данным — расти как “вглубь”, так и “вширь”. И вот тут проявляется основной недостаток звезды — ограниченная гибкость.
И если в вашей тихой и уютной жизни DWH-разработчика внезапно:

Что значит «гибкость»
Для начала давайте определимся, какими свойствами должна обладать система, чтобы ее можно было назвать “гибкой”.
Отдельно стоит оговориться, что описываемые свойства должны относиться именно к системе, а не к процессу ее разработки. Поэтому если вы хотели почитать про Agile как методологию разработки, лучше ознакомиться с другими статьями. Например, тут же, на Хабре, есть масса интересных материалов (как обзорных и практических, так и проблемных).
Это не значит, что процесс разработки и структура ХД совсем никак не связаны. В целом разрабатывать по Agile хранилище гибкой архитектуры должно быть существенно легче. Однако на практике чаще встречаются варианты и с разработкой по Agile классического DWH по Кимбаллу и DataVault — по вотэрфолу, чем счастливые совпадения гибкости в двух ее ипостасях на одном проекте.
И так, какими же возможностями должно обладать гибкое хранилище? Тут можно выделить три пункта:
Ниже я рассмотрю две самых популярных для ХД методологии гибкого проектирования — Anchor model и Data Vault. За скобками остаются такие прекрасные приемы, как например EAV, 6NF(в чистом виде) и всё, относящееся к NoSQL решениям — не потому, что они чем-то хуже, и даже не потому, что в этом случае статья грозила бы приобрести объем среднестатистического дисера. Просто всё это относится к решениям несколько другого класса — либо к приемам, которые вы можете применять в специфических случаях, независимо от общей архитектуры вашего проекта (как EAV), либо к глобально другим парадигмам хранения информации (как, например, графовые БД и другие варианты NoSQL).
Проблемы “классического” подхода и их решения в гибких методологиях
1. Жесткая кардинальность связей
В основу такой модели закладывается четкое разделение данных на измерения (Dimension) и факты (Fact). И это, черт побери, логично — ведь анализ данных в подавляющем большинстве случаев сводится именно к анализу определенных численных показателей (фактов) в определенных разрезах (измерениях).
При этом связи между объектами закладываются в виде связей между таблицами по внешнему ключу. Это выглядит вполне естественно, но сразу же приводит к первому ограничению гибкости — жесткому определению кардинальности связей.
Это значит, что на этапе проектирования таблиц вы должны точно определить для каждой пары связанных объектов могут ли они относиться как многие-ко-многим, или только 1-ко-многим, и “в какую сторону”. От этого напрямую зависит в какой из таблиц будет первичный ключ а в какой — внешний. Изменение этого отношения при получении новых требований с большой вероятностью приведет к переработке базы.
Например, проектируя объект “кассовый чек” вы, опираясь на клятвенные заверения отдела продаж, заложили возможность действия одной промо-акции на несколько чековых позиций (но не наоборот):
А через некоторое время, коллеги ввели новую маркетинговую стратегию, в которой на одну и ту же позицию могут действовать несколько промо-акций одновременно. И теперь вам надо доработать таблицы, выделив связь в отдельный объект.
(Все производные объекты, в которых происходит джойн чека на промо, теперь тоже нуждаются в доработке).
Связи в Data Vault и Anchor Model
Избежать такой ситуации оказалось довольно просто: не надо верить отделу продаж для этого достаточно все связи изначально хранить в отдельных таблицах и обрабатывать как многие-ко-многим.
Такой подход был предложен Дэном Линстедтом (Dan Linstedt) как часть парадигмы Data Vault и полностью поддержан Ларсом Рённбэком (Lars Rönnbäck) в Якорной Модели (Anchor Model).
В итоге получаем первую отличительную особенность гибких методологий:
Связи между объектами не хранятся в атрибутах родительских сущностей, а представляют собой отдельный тип объектов.
В Data Vault такие таблицы-связки называются Link, а в Якорной Модели — Tie. На первый взгляд они очень похожи, хотя названием их различия не исчерпываются (о чем пойдет разговор ниже). В обеих архитектурах таблицы-связки могут связывать любое количество сущностей (не обязательно 2).
Эта на первый взгляд избыточность дает существенную гибкость при доработках. Такая структура становится толерантной не только к изменению кардинальностей существующих связей, но и к добавлению новых — если теперь у чековой позиции появится ещё и ссылка на пробившего ее кассира, появление такой связки станет просто надстройкой над существующими таблицами без влияния на какие-либо существующие объекты и процессы.
2. Дублирование данных
Вторая проблема, решаемая гибкими архитектурами, менее очевидна и свойственна в первую очередь измерениям типа SCD2 (медленно меняющиеся измерения второго типа), хотя и не только им.
В классическом хранилище измерение обычно представляет собой таблицу, которая содержит суррогатный ключ (в качестве PK) а также набор бизнес-ключей и атрибутов в отдельных колонках.
Если измерение поддерживает версионность, к стандартному набору полей добавляются границы времени действия версии, а на одну строку в источнике появляется несколько версий в хранилище (по одной на каждое изменение версионных атрибутов).
Если измерение содержит хотя бы один часто изменяющийся версионный атрибут, количество версий такого измерения будет внушительным (даже если остальные атрибуты не версионные, или никогда не изменяются), а если таких атрибутов несколько — количество версий может расти в геометрической прогрессии от их количества. Такое измерение может занимать существенный объем дискового пространства, хотя большая часть хранящихся в нем данных — просто дубли значений неизменных атрибутов из других строк.
При этом очень часто применяется ещё и денормализация — часть атрибутов намеренно хранятся в виде значения, а не ссылки на справочник или другое измерение. Такой подход ускоряет доступ к данным, снижая количество джойнов при обращении к измерению.
Как правило, это приводит к тому, что одна и та же информация хранится одновременно в нескольких местах. Например, информация о регионе проживания и принадлежности категории клиента может одновременно храниться в измерениях “Клиент”, и фактах “Покупка”, “Доставка” и “Обращения в колл-центр”, а также в таблице-связке “Клиент — Клиентский менеджер”.
В целом описанное выше относятся и к обычным (не версионным) измерениям, но в версионных могут иметь иной масштаб: появление новой версии объекта (особенно задним числом), приводит не просто к обновлению всех связанных таблиц, а к каскадному появлению новых версий связанных объектов — когда Таблица 1 используется при построении Таблицы 2, а Таблица 2 — при построении Таблицы 3 и т.д. Даже если ни один атрибут Таблицы 1 не участвует в построении Таблицы 3 (а участвуют другие атрибуты Таблицы 2, полученные из иных источников), версионное обновление этой конструкции как минимум приведет к дополнительным накладным расходам, а как максимум — к лишним версиям в Таблице 3, которая тут вообще “не при чем” и далее по цепочке.
3. Нелинейная сложность доработки
При этом каждая новая витрина, строящаяся на основании другой, увеличивает количество мест, в которых данные могут “разойтись” при внесении изменений в ETL. Это, в свою очередь, приводит к возрастанию сложности (и длительности) каждой следующей доработки.
Если вышеописанное касается систем с редко дорабатываемыми ETL-процессами, жить в такой парадигме можно — достаточно просто следить за тем, чтобы новые доработки корректно вносились во все связанные объекты. Если же доработки происходят часто, вероятность случайно “упустить” несколько связей существенно возрастает.
Если вдобавок учесть, что “версионный” ETL существенно сложнее, чем “не версионный”, избежать ошибок при частой доработке всего этого хозяйства становится достаточно сложно.
Хранение объектов и атрибутов в Data Vault и Anchor Model
Необходимо отделить то, что изменяется, от того, что остается неизменным. То есть хранить ключи отдельно от атрибутов.
При этом не стоит путать не версионный атрибут с неизменным: первый не хранит историю своего изменения, но может меняться (например, при исправлении ошибки ввода или получении новых данных) второй — не меняется никогда.
Точки зрения на то, что именно можно считать неизменным в Data Vault и Якорной модели расходятся.
С точки зрения архитектуры Data Vault, неизменным можно считать весь набор ключей — натуральные (ИНН организации, код товара в системе-источнике и т.п) и суррогатные. При этом остальные атрибуты можно разделить по группам по источнику и/или частоте изменений и для каждой группы вести отдельную таблицу с независимым набором версий.
В парадигме же Anchor Model неизменным считается только суррогатный ключ сущности. Всё остальное (включая натуральные ключи) — просто частный случай его атрибутов. При этом все атрибуты по умолчанию независимы друг от друга, поэтому для каждого атрибута должна быть создана отдельная таблица.
В Data Vault таблицы, содержащие ключи сущностей, называются Хабами (Hub). Хабы всегда содержат фиксированный набор полей:
Все остальные атрибуты сущностей хранятся в специальных таблицах, называемых Сателлитами (Satellit). Один хаб может иметь несколько сателлитов, хранящих разные наборы атрибутов.
Распределение атрибутов по сателлитам происходит по принципу совместного изменения — в одном сателлите могут храниться не версионные атрибуты (например, дата рождения и СНИЛС для физ.лица), в другом — редко изменяющиеся версионные (например, фамилия и номер паспорта), в третьем — часто изменяющиеся (например, адрес доставки, категория, дата последнего заказа и.т.п). Версионность при этом ведется на уровне отдельных сателлитов, а не сущности в целом, поэтому распределение атрибутов целесообразно проводить так, чтобы пересечение версий внутри одного сателлита было минимальным (что сокращает общее количество хранимых версий).
Также, для оптимизации процесса загрузки данных, в отдельные сателлиты часто выносятся атрибуты, получаемые из различных источников.
Сателлиты связываются с Хабом по внешнему ключу (что соответствует кардинальности 1-ко-многим). Это значит, что множественные значение атрибутов (например, несколько контактных номеров телефона у одного клиента) поддерживается такой архитектурой “по умолчанию”.
В Якорной модели (Anchor Model) таблицы, хранящие ключи, называются Якорями (Anchor). И хранят они:
Например, если данные об одной и той же сущности могут поступать из разных систем, в каждой из которых используется свой натуральный ключ. В Data Vault это может приводить к достаточно громоздким конструкциям из нескольких хабов (по одному на источник + объединяющая мастер-версия), в Якорной модели же натуральный ключ каждого источника попадает в свой атрибут и может использоваться при загрузке независимо от всех остальных.
Но тут кроется и один коварный момент: если в одной сущности объединяются атрибуты из различных систем, скорее всего существуют некоторые правила “склейки”, по которым система должна понимать, что записи из разных источников соответствуют одному экземпляру сущности.
В Data Vault эти правила скорее всего будут определять формирование “суррогатного хаба” мастер-сущности и никак не влиять на Хабы, хранящие натуральные ключи источников и их исходные атрибуты. Если в какой-то момент правила склейки поменяются (или придет обновление атрибутов, по которым она производится), достаточно будет переформировать суррогатные хабы.
В Якорной модели же такая сущность скорее всего будет храниться в единственном якоре. Это значит, что все атрибуты, независимо от того, из какого источника они получены, будут привязаны к одному и тому же суррогату. Разделить ошибочно слитые записи и в целом отслеживать актуальность склейки в такой системе может оказаться существенно труднее, особенно, если правила достаточно сложные и часто изменяются, а один и тот же атрибут может быть получен из разных источников (хотя точно возможно, т.к. каждая версия атрибута сохраняет ссылку на свой источник).
В любом случае, если в вашей системе предполагается реализация функционала дедубликации, слияния записей и других элементов MDM, стоит особенно внимательно ознакомиться с аспектами хранения натуральных ключей в гибких методологиях. Вероятно, более громоздкая конструкция Data Vault внезапно окажется более безопасной с точки зрения ошибок слияния.
Якорная модель также предусматривает дополнительный тип объекта, называемый Узлом (Knot) по сути это специальный вырожденный вид якоря, который может содержать всего один атрибут. Узлы предполагается использовать для хранения плоских справочников (например пол, семейное положение, категория обслуживания клиентов и т.п). В отличии от Якоря, Узел не имеет связанных таблиц атрибутов, а его единственный атрибут (название) всегда хранится в одной таблице с ключем. Узлы связываются с Якорями таблицами-связями (Tie) также, как якоря друг с другом.
Однозначного мнения по поводу использования Узлов нет. Например, Николай Голов, активно продвигающий применение Якорной модели в России, считает (не безосновательно), что ни для одного справочника нельзя точно утверждать, что он всегда будет статическим и одноуровневым, поэтому для всех объектов лучше сразу использовать полноценный Якорь.
Еще одно важное различие Data Vault и Якорной модели состоит в наличии атрибутов у связей:
В Data Vault Связи являются таким же полноценными объектами, как и Хабы, и могут иметь собственные атрибуты. В Якорной модели Связи используются только для соединения Якорей и собственных атрибутов иметь не могут. Это различие дает существенно разные подходы к моделированию фактов, о чем пойдет речь далее.
Хранение фактов
До этого мы говорили в основном про моделирование измерений. С фактами дело обстоит чуть менее однозначно.
Такой подход выглядит интуитивно понятным. Он дает простой доступ к анализируемым показателям и в целом похож на традиционную таблицу фактов (только показатели хранятся не в самой таблице, а в “соседней”). Но есть и подводные камни: одна из типовых доработок модели — расширение ключа факта — вызывает необходимость добавления в Link нового внешнего ключа. А это в свою очередь “ломает” модульность и потенциально вызывает необходимость доработок других объектов.
В Якорной модели Связь не может иметь собственных атрибутов, поэтому такой подход не прокатит — абсолютно все атрибуты и показатели обязаны иметь привязку к одному конкретному якорю. Вывод из этого простой — для каждого факта тоже нужен свой якорь. Для части того, что мы привыкли воспринимать как факты, это может выглядеть естественно — например, факт покупки прекрасно сводится к объекту “заказ” или “чек”, посещение сайта — к сессии и т.п. Но встречаются и факты, для которых найти такой естественный “объект-носитель” не так просто — например, остатки товаров на складах на начало каждого дня.
Соответственно, проблем с модульностью при расширении ключа факта в Якорной модели не возникает (достаточно просто добавить новую Связь к соответствующему Якорю), но проектирование модели для отображения фактов менее однозначно, могут появляться “искусственные” Якоря, отображающие объектную модель бизнеса не очевидно.
Как достигается гибкость
Получившаяся конструкция в обоих случаях содержит существенно больше таблиц, чем традиционное измерение. Но может занимать существенно меньше дискового пространства при том же наборе версионных атрибутов, что и традиционное измерение. Никакой магии тут, естественно, нет — всё дело в нормализации. Распределяя атрибуты по Сателлитам (в Data Vault) или отдельным таблицам (Anchor Model), мы уменьшаем (или совсем исключаем) дублирование значений одних атрибутов при изменении других.
Для Data Vault выигрыш будет зависеть от распределения атрибутов по Сателлитам, а для Якорной модели — практически прямо пропорционален среднему количеству версий на объект измерения.
Однако выигрыш по занимаемому месту — важное, но не главное преимущество отдельного хранения атрибутов. Вместе с отдельным хранением связей, такой подход делает хранилище модульной конструкцией. Это значит, что добавление как отдельных атрибутов, так и целых новых предметных областей в такой модели выглядит как надстройка над существующим набором объектов без их изменения. И это именно то, что делает описанные методологии гибкими.
Также это напоминает переход от штучного производства к массовому — если в традиционном подходе каждая таблица модели уникальна и требует отдельного внимания, то в гибких методологиях — это уже набор типовых “деталей”. С одной стороны, таблиц становится больше, процессы загрузки и выборки данных должны выглядеть сложнее. С другой — они становятся типовыми. А значит, могут быть автоматизированы и управляться метаданными. Вопрос “как будем укладывать?”, ответ на который мог занимать существенную часть работ по проектированию доработок, теперь просто не стоит (как и вопрос о влиянии изменения модели на работающие процессы).
Это не значит, что аналитики в такой системе совсем не нужны — кто-то все еще должен проработать набор объектов с атрибутами и разобраться откуда и как всё это загружать. Но объем работ, а также вероятность и цена ошибки существенно снижаются. Как на этапе анализа, так и при разработке ETL, которая в существенной части может свестись к редактированию метаданных.
Темная сторона
Всё вышеописанное делает оба подхода действительно гибкими, технологичными и пригодными для итеративной доработки. Разумеется есть и “бочка дегтя”, о которой вы, думаю, уже догадываетесь.
Декомпозиция данных, лежащая в основе модульности гибких архитектур, приводит к увеличению количества таблиц и, соответственно, накладных расходов на джойны при выборке. Для того, чтобы просто получить все атрибуты измерения, в классическом хранилище достаточного одного селекта, а гибкая архитектура потребует целого ряда джойнов. Причем если для отчетов все эти джойны можно написать заранее, то аналитики, привыкшие писать SQL руками, будут страдать вдвойне.
Есть несколько фактов, облегчающих такое положение:
При работе с большими измерениям почти никогда не используются одновременно все его атрибуты. Это значит, что джойнов может быть меньше, чем кажется при первом взгляде на модель. В Data Vault можно также учесть предполагаемую частоту совместного использования при распределении атрибутов по сателлитам. При этом сами Хабы или Якори нужны в первую очередь для генерации и маппинга суррогатов на этапе загрузки и редко используются в запросах (особенно это касается Якорей).
Все джойны — по ключу. Кроме того, более “сжатый” способ хранения данных снижает накладные расходы на сканирование таблиц там, где оно необходимо (например при фильтрации по значению атрибута). Это может приводить к тому, что выборка из нормализованной базы с кучей джойнов будет даже быстрее, чем сканирование одного тяжелого измерения с большим количеством версий на строку.
Например, вот в этой статье есть подробный сравнительный тест производительности Якорной модели с выборкой из одной таблицы.
Многое зависит от движка. У многих современных платформ есть внутренние механизмы оптимизации джойнов. Например, MS SQL и Oracle умеют “пропускать” джойны на таблицы, если их данные не используются нигде, кроме других джойнов и не влияют на финальную выборку (table/join elimination), а MPP Vertica по опыту коллег из Авито, показала себя как прекрасный движок для Якорной модели с учетом некоторой ручной оптимизации плана запроса. С другой стороны, хранить Якорную модель, например, на Click House, имеющем ограниченную поддержку join, пока выглядит не очень хорошей идеей.
Кроме того, для обеих архитектур существуют специальные приемы, облегчающие доступ к данным (как с точки зрения производительности запросов, так и для конечных пользователей). Например, Point-In-Time таблицы в Data Vault или специальные табличные функции в Якорной модели.
Итого
Основная суть рассмотренных гибких архитектур состоит в модульности их “конструкции”.
Именно это свойство позволяет:
Приложения
Типы сущности Data Vault
Типы сущностей Anchor Model
Подробнее про Anchor Model:
Сводная таблица с общими чертами и различиями рассмотренных подходов:



