Введение
Что такое Объектная Модель Документа (DOM)?
Объектная Модель Документа (DOM) – это программный интерфейс (API) для HTML и XML документов. DOM предоставляет структурированное представление документа и определяет то, как эта структура может быть доступна из программ, которые могут изменять содержимое, стиль и структуру документа. Представление DOM состоит из структурированной группы узлов и объектов, которые имеют свойства и методы. По существу, DOM соединяет веб-страницу с языками описания сценариев либо языками программирования.
Веб-страница – это документ. Документ может быть представлен как в окне браузера, так и в самом HTML-коде. В любом случае, это один и тот же документ. DOM предоставляет другой способ представления, хранения и управления этого документа. DOM полностью поддерживает объектно-ориентированное представление веб-страницы, делая возможным её изменение при помощи языка описания сценариев наподобие JavaScript.
Стандарты W3C DOM и WHATWG DOM формируют основы DOM, реализованные в большинстве современных браузеров. Многие браузеры предлагают расширения за пределами данного стандарта, поэтому необходимо проверять работоспособность тех или иных возможностей DOM для каждого конкретного браузера.
Например: стандарт DOM описывает, что метод getElementsByTagName в коде, указанном ниже, должен возвращать список всех элементов
DOM и JavaScript
Вначале JavaScript и DOM были тесно связаны, но впоследствии они развились в различные сущности. Содержимое страницы хранится в DOM и может быть доступно и изменяться с использованием JavaScript, поэтому мы можем записать это в виде приблизительного равенства:
API (веб либо XML страница) = DOM + JS (язык описания скриптов)
DOM спроектирован таким образом, чтобы быть независимым от любого конкретного языка программирования, обеспечивая структурное представление документа согласно единому и последовательному API. Хотя мы всецело сфокусированы на JavaScript в этой справочной документации, реализация DOM может быть построена для любого языка, как в следующем примере на Python:
Для подробной информации о том, какие технологии участвуют в написании JavaScript для веб, смотрите обзорную статью JavaScript technologies overview.
Каким образом доступен DOM?
Вы не должны делать ничего особенного для работы с DOM. Различные браузеры имеют различную реализацию DOM, эти реализации показывают различную степень соответствия с действительным стандартом DOM (это тема, которую мы пытались не затрагивать в данной документации), но каждый браузер использует свой DOM, чтобы сделать веб страницы доступными для взаимодействия с языками сценариев.
При создании сценария с использованием элемента
Dom html что это
DOM — это объектная модель документа, которую браузер создает в памяти компьютера на основании HTML-кода, полученного им от сервера. Иными словами, это представление HTML-документа в виде дерева тегов.
Браузер запрашивает у сервера веб-страницу и получает в ответ ее исходный HTML-код. Браузеру такой код сначала нужно разобрать на элементы. В процессе разбора он строит на основе HTML-кода DOM-дерево. После этого браузер отрисовывает страницу, используя созданное им DOM-дерево, а не исходный HTML-документ.
Такое дерево нужно для правильного отображения сайта и внесения изменений на страницах с помощью JavaScript. JavaScript — это «живой» язык, он может изменять страницу в реальном времени уже после того, как она «пришла» с сервера в браузер. Этим JavaScript принципиально отличается от PHP, который компилирует страницу и только потом посылает в браузер уже готовый HTML-код.

Для чтения и изменения DOM браузеры предоставляют DOM API (программный интерфейс). DOM API — это набор различных объектов, которые разработчик использует для чтения и изменения DOM с помощью JavaScript.
Из чего состоит HTML-код страницы
Страница на HTML состоит из тегов, вложенных в друг друга. Самый общий тег — это HTML. В него вкладываются два дочерних тега head и body.
Тег head используется для подключения информации, которая не будет отображаться непосредственно на странице, но будет использоваться для подключения важных файлов. Тут бывает, например, подключение одного или нескольких CSS-файлов, подключенные шрифты, название сайта, язык, кодировка, скрипты, которые должны выполняться в первую очередь, иконка сайта или базовый фон.
В body находится значимое содержимое. Обычно в body выделяют три части: шапка сайта, основное содержимое и подвал. В шапке обычно содержится верхнее меню сайта, за это отвечает тег header. Для содержимого нет определенного тега, но обычно используется section. Для подвала используется footer, там обычно содержатся контактная информация, ссылки на ключевые страницы сайта и копирайт. Теги header и footer должны быть единственными на странице, а section может бесконечно повторяться.
Как строится DOM-дерево
Для описания структуры DOM потребуются термины: корневой, родительские и дочерние элементы. Корневой элемент находится в основании всей структуры и не имеет родительского элемента. Дочерние элементы не просто находятся внутри родительских, но и наследуют различные свойства от них. На картинке ниже изображено DOM-дерево.

Корневой элемент здесь html — без него страница не будет скомпилирована. Он не имеет родительского (вышестоящего) элемента, но имеет два наследника или дочерних элемента — head и body.
По отношению друг к другу элементы head и body являются сиблингами (братьями и сестрами). В каждый из них можно вложить еще много дочерних элементов. Например, в head обычно находятся link, meta, script или title.
Все эти теги не являются уникальными, и в одном документе может быть по несколько экземпляров каждого из них.
В body могут находиться разнообразные элементы. Например, в родительском body — дочерний элемент header, в элементе header — дочерний элемент section, в родительском section — дочерний div, в div — элемент h3, и наконец, в h3 — элемент span. В этом случае span не имеет дочерних элементов, но их можно добавить в любой момент.
Можно описать это так:

А если бы система была бы более разветвленная и с большим количеством вложений — так:

На схеме изображено довольно большое DOM-дерево, и его сложно воспринимать из-за его размера. Для удобства часто используется система многоуровневых списков. Например, предыдущее дерево можно преобразовать в такой список:

Если преобразовать дерево на предыдущем рисунке в код, то получится так:
Что такое DOM и зачем он нужен?

На этом уроке мы рассмотрим, что такое DOM, зачем он нужен, а также то, как он строится.
Что такое DOM

DOM – это объектная модель документа, которую браузер создаёт в памяти компьютера на основании HTML-кода, полученного им от сервера.
Если сказать по-простому, то HTML-код – это текст страницы, а DOM – это набор связанных объектов, созданных браузером при парсинге её текста.
В Chrome исходный код страницы, который получает браузер, можно посмотреть во вкладке «Source» на панели «Инструменты веб-разработчика».

В Chrome инструмента, с помощью которого можно было бы посмотреть созданное им DOM-дерево нет. Но есть представление этого DOM-дерева в виде HTML-кода, оно доступно на вкладке «Elements». С таким представлением DOM веб-разработчику, конечно, намного удобнее работать. Поэтому инструмента, который DOM представлял бы в виде древовидной структуры нет.

Для работы с DOM в большинстве случаев используется JavaScript, т.к. на сегодняшний день это единственный язык программирования, скрипты на котором могут выполняться в браузере.
Зачем нам нужен DOM API? Он нам нужен для того, чтобы мы могли с помощью JavaScript изменять страницу на «лету», т.е. делать её динамической и интерактивной.
DOM API предоставляет нам (разработчикам) огромное количество методов, с помощью которых мы можем менять всё что есть на странице, а также взаимодействовать с пользователем. Т.е. данный программный интерфейс позволяет нам создавать сложные интерфейсы, формы, выполнять обработку действий пользователей, добавлять и удалять различные элементы на странице, изменять их содержимое, свойства (атрибуты), и многое другое.
Сейчас в вебе практически нет сайтов в сценариях которых отсутствовала бы работа с DOM.
Из чего состоит HTML-код страницы
Перед тем, как перейти к изучению объектной модели документа необходимо сначала вспомнить, что из себя представляет исходный код веб-страницы (HTML-документа).
Исходный код веб-страницы состоит из тегов, атрибутов, комментариев и текста. Теги — это базовая синтаксическая конструкция HTML. Большинство из них являются парными. В этом случае один из них является открывающим, а другой – закрывающим. Одна такая пара тегов образует HTML-элемент. HTML-элементы могут иметь дополнительные параметры – атрибуты.
В документе для создания определённой разметки одни элементы находятся внутри других. В результате HTML-документ можно представить как множество вложенных друг в друга HTML-элементов.
В качестве примера рассмотрим следующий HTML код:
Теперь рассмотрим, как браузер на основании HTML-кода строит DOM-дерево.
Как строится DOM-дерево документа
Как уже было описано выше браузер строит дерево на основе HTML-элементов и других сущностей исходного кода страницы. При выполнении этого процесса он учитывает вложенность элементов друг в друга.
В результате браузер полученное DOM-дерево использует не только в своей работе, но также предоставляет нам API для удобной работы с ним через JavaScript.
При строительстве DOM браузер создаёт из HTML-элементов, текста, комментариев и других сущностей этого языка объекты (узлы DOM-дерева).
В большинстве случаев веб-разработчиков интересуют только объекты (узлы), образованные из HTML-элементов.
При этом браузер не просто создаёт объекты из HTML-элементов, а также связывает их между собой определёнными связями в зависимости от того, как каждый из них относится к другому в коде.
Элементы, которые находятся непосредственно в некотором элементе являются по отношению к нему детьми. А он для каждого из них является родителем. Кроме этого, все эти элементы по отношению друг к другу являются сиблингами (братьями).
Чтобы получить DOM-дерево так как его строит браузер, необходимо просто «выстроить» все элементы в зависимости от их отношения друг к другу.
Создание DOM-дерева выполняется сверху вниз.
При этом корнем DOM-дерева всегда является сам документ (узел document ). Далее дерево строится в зависимости от структуры HTML кода.
Например, HTML-код, который мы рассматривали выше будет иметь следующее DOM-дерево:

Форум
Справочник
Введение. DOM в примерах.
Простейший DOM
Построим, для начала, дерево DOM для следующего документа.
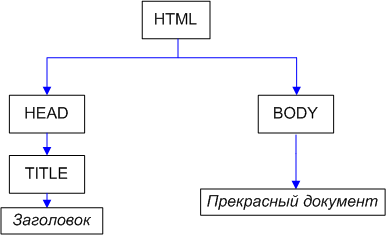
Пример посложнее
Рассмотрим теперь более жизненную страничку:

А вот так выглядит дерево, если изобразить его прямо на HTML-страничке:
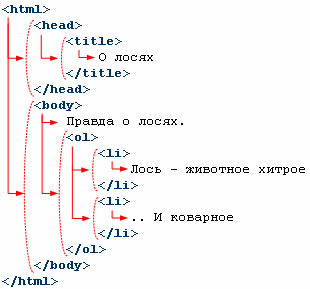
Кстати, дерево на этом рисунке не учитывает текст, состоящий из одних пробельных символов. Например, такой текстовый узел должен идти сразу после
- . DOM, не содержащий таких «пустых» узлов, называют «нормализованным».
Пример с атрибутами и DOCTYPE
Рассмотрим чуть более сложный документ.

Однако, в веб-программировании в эти дебри обычно не лезут, и считают атрибуты просто свойствами DOM-узла, которые, как мы увидим в дальнейшем, можно устанавливать и менять по желанию программиста.
Вообще-то это секрет, но DOCTYPE тоже является DOM-узлом, и находится в дереве DOM слева от HTML (на рисунке этот факт скрыт).
Нормализация в различных браузерах
При разборе HTML Internet Explorer сразу создает нормализованный DOM, в котором не создаются узлы из пустого текста.
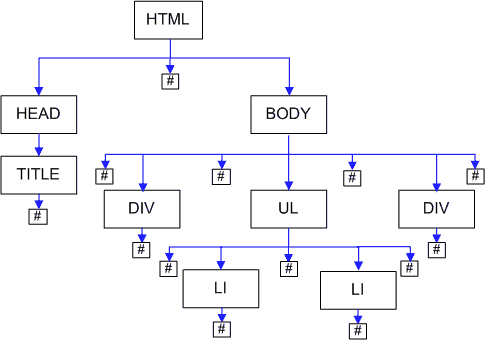
На рисунке для краткости текстовые узлы обозначены просто решеткой. У body вместо 3 появилось 7 детей.
Opera тоже имеет чем похвастаться. Она может добавить лишний пустой элемент «просто от себя».
У меня получается 3 для IE, 7 для Firefox и 8 (!?) для Opera.
На практике эта несовместимость не создает больших проблем, но нужно о ней помнить. Например, разница может проявить себя в случае перебора узлов дерева.
Возможности, которые дает DOM
Зачем, кроме красивых рисунков, нужна иерархическая модель DOM?
Каждый DOM-элемент является объектом и предоставляет свойства для манипуляции своим содержимым, для доступа к родителям и потомкам.
В современных скриптах этот метод почти не используется, случаи его правильного применения можно пересчитать по пальцам.
Разберем подробнее способы доступа и свойства элементов DOM.
Доступ к элементам
Начнем с вершины дерева.
document.documentElement
document.body
Типы DOM-элементов
У каждого элемента в DOM-модели есть тип. Его номер хранится в атрибуте elem.nodeType
Всего в DOM различают 12 типов элементов.
Остальные типы в javascript программировании не используются.
Пример
Например, вот так выглядел бы в браузере документ из примера выше, если каждый видимый элемент обвести рамкой с цифрой nodeType в правом верхнем углу.

Дочерние элементы


Этих свойств вполне хватает для удобного обращения к соседям.
Свойства элементов
Рассмотрим здесь еще некоторые (не все) свойства элементов, полезные при работе с DOM.
tagName
Атрибут есть у элементов-тегов и содержит имя тега в верхнем регистре, только для чтения.
style
Это свойство управляет стилем. Оно аналогично установке стиля в CSS.
Например, можно установить element.style.width :
Исходный код этой кнопки:
Например, для установки свойства z-index в 1000, нужно поставить:
innerHTML
Когда-то это свойство поддерживалось только в IE. Теперь его поддерживают все современные браузеры.
Оно содержит весь HTML-код внутри узла, и его можно менять.
Свойство innerHTML применяется, в основном, для динамического изменения содержания страницы, например:
className
Это свойство задает класс элемента. Оно полностью аналогично html-атрибуту «class».
Что такое DOM?
Объектная модель документа, или «DOM», является программным интерфейсом доступа к элементам веб-страниц. По сути, это API страницы, позволяющий читать и манипулировать содержимым, структурой и стилями страницы. Давайте разберемся как это устроено и как это работает.
Как строится веб-страница?
Процесс преобразования исходного HTML-документа в отображаемую стилизованную и интерактивную страницу, называется “Critical Rendering Path”(«Критическим путем рендеринга»). Хотя этот процесс можно разбить на несколько этапов, как я описал это в статье «Понимание критического пути рендеринга», эти этапы можно условно сгруппировать в два этапа. В первом браузер анализирует документ, чтобы определить, что в конечном итоге будет отображаться на странице, а во второй браузер выполняет рендеринг.

Результатом первого этапа является то, что называется “render tree”(«дерево рендеринга»). Дерево рендеринга — это представление элементов HTML, которые будут отображаться на странице, и связанных с ними стилей. Чтобы построить это дерево, браузеру нужны две вещи:
Из чего состоит DOM?
DOM — это объектное представление исходного HTML-документа. Он имеет некоторые различия, как мы увидим ниже, но по сути это попытка преобразовать структуру и содержание документа HTML в объектную модель, которая может использоваться различными программами.
Давайте рассмотрим этот HTML-документ в качестве примера:
Этот документ может быть представлен в виде следующего дерева узлов:
Чем DOM не является
В приведенном выше примере кажется, что DOM является отображением 1: 1 исходного HTML-документа. Однако, как я уже говорил, есть различия. Чтобы полностью понять, что такое DOM, нам нужно взглянуть на то, чем он не является.
DOM не является копией исходного HTML
Хотя DOM создан из HTML-документа, он не всегда точно такой же. Есть два случая, в которых DOM может отличаться от исходного HTML.
1. Когда HTML содержит ошибки разметки
DOM — это интерфейс доступа к действительных (то есть уже отображаемым) элементам документа HTML. В процессе создания DOM, браузер сам может исправить некоторые ошибки в коде HTML.
Рассмотрим в качестве примера этот HTML-документ:
2. Когда DOM модифицируется кодом Javascript
Помимо того, что DOM является интерфейсом для просмотра содержимого документа HTML, он сам также может быть изменен.
Мы можем, например, создать дополнительные узлы для DOM, используя Javascript.
DOM — это не то, что вы видите в браузере (то есть, дерево рендеринга)
В окне просмотра браузера вы видите дерево рендеринга, которое, как я уже говорил, является комбинацией DOM и CSSOM. Чем отличается DOM от дерева рендеринга, так это то, что последнее состоит только из того, что в конечном итоге будет отображено на экране.
Поскольку дерево рендеринга имеет отношение только к тому, что отображается, оно исключает элементы, которые визуально скрыты. Например, элементы, у которых есть стили с display: none.
DOM будет включать элемент
Однако дерево рендеринга и, следовательно, то, что видно в окне просмотра, не будет включено в этот элемент.
DOM — это не то, что отображается в DevTools
Это различие немного меньше, потому что инспектор элементов DevTools обеспечивает самое близкое приближение к DOM, которое мы имеем в браузере. Однако инспектор DevTools содержит дополнительную информацию, которой нет в DOM.
Лучший пример этого — псевдоэлементы CSS. Псевдоэлементы, созданные с использованием селекторов ::before и ::after, являются частью CSSOM и дерева рендеринга, но технически не являются частью DOM. Это связано с тем, что DOM создается только из исходного HTML-документа, не включая стили, примененные к элементу.
Несмотря на то, что псевдоэлементы не являются частью DOM, они есть в нашем инспекторе элементов devtools.

Резюме
DOM — это интерфейс к HTML-документу. Он используется браузерами как первый шаг к определению того, что визуализировать в окне просмотра, и кодом Javascript для изменения содержимого, структуры или стиля страницы.
Хотя DOM похож на другие формы исходного документа HTML, он отличается по ряду причин:



