docker service scale
Description
Scale one or multiple replicated services
API 1.24+ В The client and daemon API must both be at least 1.24 to use this command. Use the docker version command on the client to check your client and daemon API versions.
Swarm This command works with the Swarm orchestrator.
Usage
Extended description
The scale command enables you to scale one or more replicated services either up or down to the desired number of replicas. This command cannot be applied on services which are global mode. The command will return immediately, but the actual scaling of the service may take some time. To stop all replicas of a service while keeping the service active in the swarm you can set the scale to 0.
This is a cluster management command, and must be executed on a swarm manager node. To learn about managers and workers, refer to the Swarm mode section in the documentation.
For example uses of this command, refer to the examples section below.
Options
Examples
Scale a single service
The following command scales the “frontend” service to 50 tasks.
The following command tries to scale a global service to 10 tasks and returns an error.
You can also scale a service using the docker service update command. The following commands are equivalent:
Scale multiple services
The docker service scale command allows you to set the desired number of tasks for multiple services at once. The following example scales both the backend and frontend services:
Конференция DEVOXX UK. Выбираем фреймворк: Docker Swarm, Kubernetes или Mesos. Часть 2
Docker Swarm, Kubernetes и Mesos являются наиболее популярными фреймворками для оркестровки контейнеров. В своем выступлении Арун Гупта сравнивает следующие аспекты работы Docker, Swarm, и Kubernetes:
Арун Гупта — главный технолог open-source продуктов Amazon Web Services, который уже более 10 лет развивает сообщества разработчиков Sun, Oracle, Red Hat и Couchbase. Имеет большой опыт работы в ведущих кросс-функциональных командах, занимающихся разработкой и реализацией стратегии маркетинговых кампаний и программ. Руководил группами инженеров Sun, является одним из основателей команды Java EE и создателем американского отделения Devoxx4Kids. Арун Гупта является автором более 2 тысяч постов в IT-блогах и выступил с докладами более чем в 40 странах.
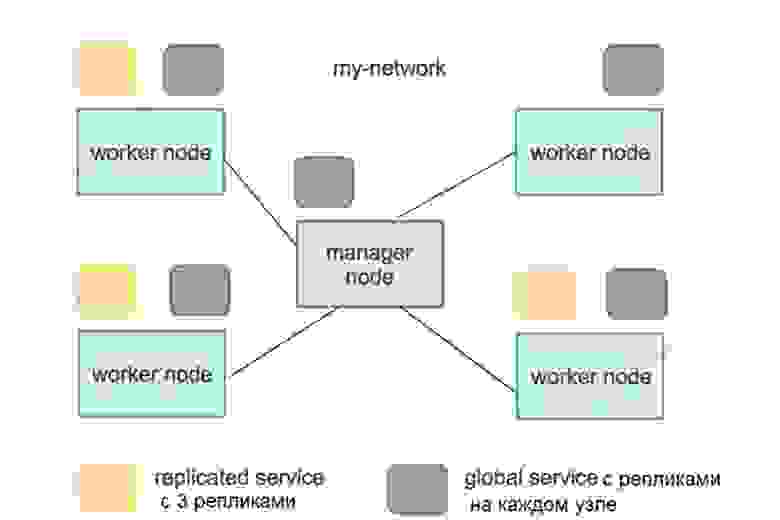
Концепт масштабирования Scale означает возможность управлять количеством реплик, увеличивая или уменьшая число экземпляров приложения.

Для примера: если хотите масштабировать систему до 6 реплик, используйте команду docker service scale web=6.

В результате приложение Prometheus будет запущено на всех узлах кластера без исключения, и если в кластер будут добавлены новые ноды, то оно автоматически запустится в контейнере и в этих нодах. Надеюсь, вы поняли разницу между Replicated Service и Global Service. Обычно Replicated Service это то, с чего вы начинаете.
Итак, мы рассмотрели основные понятия, или основные сущности Docker, а теперь рассмотрим сущности Kubernetes. Kubernetes – это тоже своего рода планировщик, платформа для оркестровки контейнеров. Нужно помнить, что основной концепт планировщика — это знание того, как запланировать работу контейнеров на разных хостах. Если же перейти на более высокий уровень, можно сказать, что оркестровка означает расширение ваших возможностей до управления кластерами, получения сертификатов и т.д. В этом смысле и Docker, и Kubernetes являются платформами оркестровки, причем оба имеют встроенный планировщик.
Оркестровка представляет собой автоматизированное управление связанными сущностями — кластерами виртуальных машин или контейнеров. Kubernetes — это совокупность сервисов, реализующих контейнерный кластер и его оркестровку. Он не заменяет Docker, но серьёзно расширяет его возможности, упрощая управление развертыванием, сетевой маршрутизацией, расходом ресурсов, балансировкой нагрузки и отказоустойчивостью запускаемых приложений.
По сравнению с Kubernetes, Docker ориентирован именно на работу с контейнерами, создавая их образы с помощью docker-файла. Если сравнить объекты Docker и Kubernetes, можно сказать, что Docker управляет контейнерами, в то время как Kubernetes управляет самим Docker.
Кто из вас имел дело с контейнерами Rocket? А кто-нибудь использует Rocket в продакшене? В зале поднял руку всего один человек, это типичная картина. Это альтернатива Docker, которая до сих пор не прижилась в сообществе разработчиков.
Итак, основной сущностью Kubernetes является Pod. Он представляет собой связанную группу контейнеров, которые используют общее пространство имен, общее хранилище и общий IP-адрес. Все контейнеры в поде общаются друг с другом через локальный хост. Это означает, что вы не сможете разместить приложение и базу данных в одном и том же поде. Они должны размещаться в разных подах, поскольку имеют разные требования масштабирования.
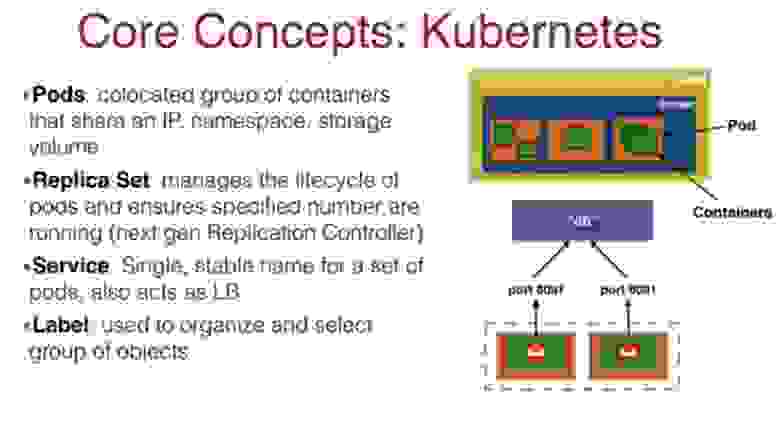
Таким образом, вы можете разместить в одном поде, например, WildFly контейнер, логин-контейнер, прокси-контейнер, или кэш-контейнер, причем вы должны ответственно подходить к составу компонентов контейнера, который собираетесь масштабировать.
Обычно вы «обертываете» свой контейнер в набор реплик Replica Set, поскольку хотите запускать в поде определенное количество экземпляров. Replica Set приказывает запустить столько реплик, сколько требует сервис масштабирования Docker, и указывает, когда и каким образом это проделать.
Поды похожи на контейнеры в том смысле, что если происходит сбой пода на одном хосте, он перезапускается на другом поде с другим IP-адресом. Как Java-разработчик, вы знаете, что когда создаете java-приложение и оно связывается с базой данных, вы не можете полагаться на динамический IP-адрес. В этом случае Kubernetes использует Service – этот компонент публикует приложение как сетевой сервис, создавая статичное постоянное сетевое имя для набора подов, одновременно реализуя балансировку нагрузки между подами. Можно сказать, что это служебное имя базы данных, и java-приложение не полагается на IP-адрес, а взаимодействует только с постоянным именем базы данных.
Это достигается тем, что каждый Pod снабжается определенной меткой Label, которые хранятся в распределенном хранилище etcd, и Service следит за этими метками, обеспечивая связь компонентов. То есть поды и сервисы устойчиво взаимодействуют друг с другом с помощью этих меток.
Теперь давайте рассмотрим, как создать кластер Kubernetes. Для этого, как и в Docker, нам нужен мастер-нод и рабочий нод. Нод в кластере обычно представлен физической или виртуальной машиной. Здесь, как и в Docker, мастер представляет собой центральную управляющую структуру, которая позволяет контролировать весь кластер через планировщик и менеджер контроллеров. По умолчанию мастер-нод существует в единственном числе, но есть множество новых инструментов, позволяющих создавать несколько мастер-нодов.
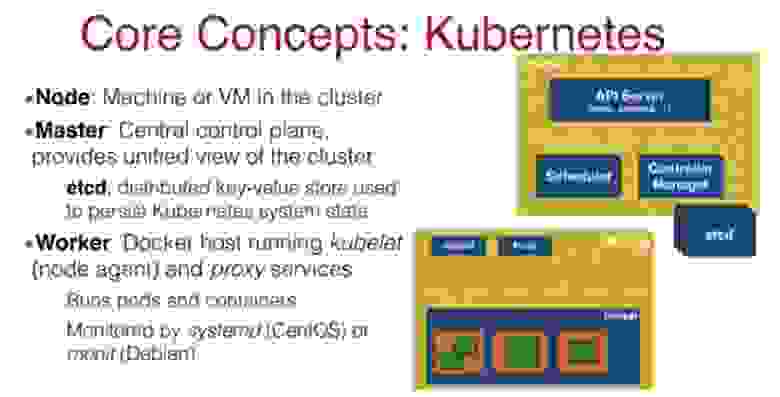
Master-node обеспечивает взаимодействие с пользователем при помощи API-сервера и содержит распределенное хранилище etcd, в котором находится конфигурация кластера, статусы его объектов и метаданные.
Рабочие узлы Worker-node предназначены исключительно для запуска контейнеров, для этого в них установлены два сервиса Kubernetes — сетевой маршрутизатор proxy service и агент планировщика kubelet. Во время работы этих узлов Docker выполняет их мониторинг с помощью systemd (CentOS) или monit (Debian) в зависимости от того, какой операционной системой вы пользуетесь.
Рассмотрим архитектуру Kubernetes более широко. У нас имеется Master, в составе которого присутствуют API –сервер (поды, сервисы и т.д.), управляемый с помощью CLI kubectl. Kubectl позволяет создавать ресурсы Kubernetes. Он передает API-серверу команды типа «создать под», «создать сервис», «создать набор реплик».
Далее здесь имеется планировщик Scheduler, менеджер контроллеров Controller Manager и хранилище etcd. Менеджер контроллеров, получив указания API-сервера, сопоставляет метки реплик с метками подов, обеспечивая устойчивое взаимодействие компонентов. Планировщик, получив задание создать под, просматривает рабочие ноды и создает его там, где это предусмотрено. Естественно, что он получает эту информацию из etcd.
Далее у нас имеется несколько рабочих нодов, и API-сервер общается с содержащимися в них Kubelet-агентами, сообщая им, как должны создаваться поды. Здесь расположен прокси, который предоставляет вам доступ к приложению, использующему эти поды. Справа на слайде показан мой клиент – это запрос интернета, который поступает в балансировщик нагрузки, тот обращается к прокси, который распределяет запрос по подам и направляет ответ обратно.
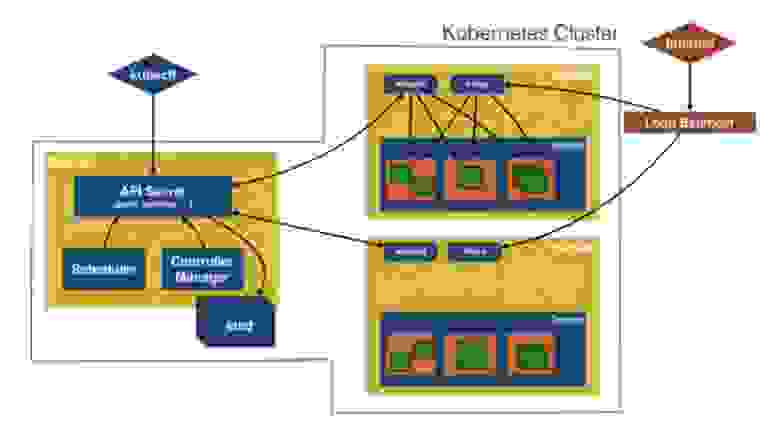
Вы видите итоговый слайд, который изображает кластер Kubernetes и то, как работают все его компоненты.
Давайте подробнее поговорим о Service Discovery и балансировщике нагрузки Docker. Когда вы запускаете свое Java-приложение, обычно это происходит в нескольких контейнерах на нескольких хостах. Существует компонент Docker Compose, который позволяет с легкостью запускать мультиконтейнерные приложения. Он описывает мультиконтейнерные приложения и запускает их при помощи одного или нескольких yaml-файлов конфигурации.

По умолчанию это файлы docker-compose.yaml и docker-compose.override.yaml, при этом множества файлов указываются с помощью – f. В первой файле вы прописываете сервис, образы, реплики, метки и т.д. Второй файл используется для перезаписи конфигурации. После создания docker-compose.yaml он развертывается в мультихостовом кластере, который ранее создал Docker Swarm. Вы можете создать один базовый файл конфигурации docker-compose.yaml, в который будете добавлять файлы специфических конфигураций для разных задач с указанием определенных портов, образов и т.д., позже мы поговорим об этом.
На этом слайде вы видите простой пример файла Service Discovery. В первой строке указывается версия, а строка 2 показывает, что он касается сервисов db и web.

Я добиваюсь того, чтобы после «поднятия» мой web-сервис мог общаться с db-сервисом. Это простые java-приложения, развертываемые в контейнерах WildFly. В 11 строке я прописываю среду couchbase_URI=db. Это означает, что мой db-сервис использует эту базу данных. В строке 4 указан образ couchbase, а в строках 5-9 и 15-16 соответственно порты, необходимые для обеспечения работы моих сервисов.
Ключом к пониманию процесса обнаружения сервисов служит то, что вы создаете некоторого рода зависимости. Вы указываете, что web-контейнер должен запуститься раньше db-контейнера, но это только на уровне контейнеров. Как реагирует ваше приложение, как оно стартует – это совершенно другие вещи. Например, обычно контейнер «поднимается» за 3-4 секунды, однако запуск контейнера базы данных занимает гораздо больше времени. Так что логика запуска вашего приложения должна быть «запечена» в вашем java-приложении. То есть приложение должно пинговать базу данных, чтобы убедиться в ее готовности. Поскольку база данных couchbase – это REST API, вы должны вызвать этот API и спросить: «Эй, ты готов? Если да, то я готов присылать тебе запросы»!

Рассмотрим, как работает балансировщик нагрузки Load balancer. В приведенном примере я с помощью команды docker service create создал сервис – WildFly контейнер, указав номер порта в виде 8080:8080. Это означает, что порт 8080 на хосте – локальной машине — будет увязан с портом 8080 внутри контейнера, так что вы сможете получить доступ к приложению через localhost:8080. Это будет порт доступа ко всем рабочим узлам.

Помните, что балансировщик нагрузки ориентирован на хост, а не на контейнеры. Он использует порты 8080 каждого хоста, независимо от того, запущены ли на хосте контейнеры или нет, потому что сейчас контейнер работает на одном хосте, а после выполнения задачи может быть перенесен на другой хост.
Итак, запросы клиента поступают балансировщику нагрузки, он перенаправляет их на любой из хостов, и если, используя таблицу IP-адресов, попадает на хост с незапущенным контейнером, то автоматически перенаправляет запрос хосту, на котором запущен контейнер.
Одиночный хоп обходится не дорого, но он полностью «бесшовный» в отношении масштабирования ваших сервисов в сторону увеличения или уменьшения. Благодаря этому вы можете быть уверены, что ваш запрос попадет именно тому хосту, где запущен контейнер.
Теперь давайте рассмотрим, как работает Service Discovery в Kubernetes. Как я говорил, сервис – это абстракция в виде набора подов с одинаковым IP-адресом и номером порта и простым TCP/UDP балансировщиком нагрузки. На следующем слайде показан файл конфигурации Service Discovery.

Посмотрим сначала на строку 39 – в ней значится kind: ReplicaSet, то есть то, что мы создаем. В строках 40-43 расположены метаданные, с 44 строки указывается спецификация для нашего набора реплик. В строке 45 указано, что у меня имеется 1 реплика, ниже указаны ее метки Labels, в данном случае это имя wildfly. Еще ниже, начиная с 50 строки, указывается, в каких контейнерах должна запускаться данная реплика – это wildfly-rs-pod, а строки 53-58 содержат спецификацию этого контейнера.
Немного рекламы 🙂
Краткое введение в Docker Swarm mode
Docker — прекрасен. С ним можно упаковать приложение по контейнерам, забросить их на случайный хост, и всё будет просто работать. Но на одном хосте особо не отмасштабируешься. Да и если хост прикажет долго жить, всё приложение отправится на тот свет вместе с ним. Конечно, для масштабирования можно завести сразу несколько хостов, объединить их при помощи overlay сети, так что и места больше будет, и возможность для контейнеров общаться останется.
Но опять же, как всем этим управлять? Хосты всё ещё могут отмирать. Как быстро определить, какой именно? Какие контейнеры на нём были? Куда теперь их переносить?
Начиная с версии 1.12.0 Docker может работать в режиме Swarm («Рой». В старых версиях был просто Docker Swarm, но тот работал по-другому), и потому способен решать все эти проблемы самостоятельно.
Что такое режим Swarm
Docker в Swarm режиме это просто Docker Engine, работающий в кластере. Кроме того, что он считает все кластерные хосты единым контейнерным пространством, он получает в нагрузку несколько новых команд (вроде docker node и docker service ) и концепцию сервисов.
Сервисы — это ещё один уровень абстракции над контейнерами. Как и у контейнера, у сервиса будет имя, базовый образ, опубликованные порты и тома (volumes). В отличие от контейнера, сервису можно задать требования к хосту (constraints), на которых его можно запускать. Да и вообще, сервис можно масштабировать прямо в момент создания, указав, сколько именно контейнеров для него нужно запустить.
Но важно понимать одну большую разницу. Сама по себе команда docker service create не создаёт никаких контейнеров. Она описывает желаемое состояние сервиса, а дальше уже Swarm менеджер будет искать способы это состояние достигнуть. Найдёт подходящие хосты, запустит контейнеры, будет следить, чтобы с ними (и хостами под ними) всё было хорошо, и перезапустит контейнер, если «хорошо» закончится. Иногда желаемое состояние сервиса так и не будет достигнуто. Например, если в кластере закончились доступные хосты. В таком случае сервис будет висеть в режиме ожидания до тех пор, пока что-нибудь не изменится.
План на сегодня
Будем играться. Пользы от абстрактной и непонятной теории — ноль, так что создадим-ка свой собственный уютный Docker кластер на три виртуальные машины. Запустим в нём один сервис для визуализации кластера, и ещё один, например web, чтобы масштабировался и заодно демонстрировал, как он успешно восстанавливается от внезапно упавшего хоста.
Что понадобится
Нам понадобится установленный Docker версии 1.12.0 и новее, docker-machine и VirtualBox. Первые два обычно устанавливаются вместе c Docker Toolbox на Маке и Windows. На Linux, ЕМНИП, docker-machine устанавливается отдельно, но всё ещё достаточно понятно. С установкой же VirtualBox проблем вообще не бывает. Обычно.
Я буду использовать Docker 17.03.1-ce для Mac и VirtualBox 5.1.20
Шаг 0. Создаём три виртуальные машины
Создавать машины при помощи именно docker-machine имеет смысл хотя бы потому, что они сразу будут идти с предустановленным Docker. Из трёх хостов на одном мы поселим менеджера Swarm, а на двух других — обычных рабочих. Собственно, создание виртуальных машин — удивительно безболезненное занятие:
How to scale services using Docker Compose
Share
Docker Compose tool is used to define and start running multi-container Docker applications. Configuration is as easy,there would be YAML file to configure your application’s services/networks/volumes etc., Then, with a single command, you can create and start all the services from the compose configuration.
Here are the key steps :
This quickstart assumes basic understanding of Docker concepts, please refer to earlier posts for understanding on Docker & how to install and containerize applications. In this post, we can look at how to use existing Docker compose file and scale services.
A docker-compose.yml looks like this:

Key Features of Docker Compose
For more information on Docker Compose, check out here. You can also refer previous posts on Docker here & here.
In the next section, we can look at how to use existing Docker compose file and scale services.
Scale service instances
Each service defined in Docker compose configuration can be scaled using below command

docker-compose scale redis-master=3
Although services can be scaled but you could get an arbitrary range of ports assigned since the ports are randomly assigned by the Docker engine. This can be controlled by assigning port range on the ports section of the compose YAML file.
Alternatively, in Compose file version 3.x, you can also specify replicas under the deploy section as part of a service configuration for Swarm mode.
Congrats! today we have learned how to scale services using scale command.
Like this post? Don’t forget to share it!
Docker: запуск 1000 контейнеров в Swarm кластере в Облаке КРОК
По заверениям разработчиков на сегодняшний день Docker Swarm легко и просто позволяет масштабировать ваши приложения на множество хостов с десятков до тысяч контейнеров. Но выполняется ли это обещание в реальности?
Давайте проверим запуск 1000 контейнеров на трех виртуальных серверах в Облаке КРОК и узнаем об этом наверняка.
Запуск виртуальных машин
Весь эксперимент мы будем проводить на трех виртуальных серверах Ubuntu 16.04 размером m1.large (2 vCPU, 8 Gb RAM). Все серверы подключены к единой виртуальной сети и имеют следующие имена:
Разрешаем доступ к виртуальной сети по SSH (22/TCP) и 2376/TCP для управления хостами с Docker Machine.
Установим Docker на каждый из серверов следующими командами:
Инициализируем Swarm кластер. На master узле выполним команду:
Команда для выполнения на node-1 и node-2 будет в выводе предыдущей команды. Не забудьте переключить переменные окружения для клиента docker:
Проверим состояние Swarm кластера:
Создадим для запуска тестовых контейнеров отдельную сеть:
Эта сеть будет использоваться всеми контейнерами для коммуникации друг с другом. Сетевая маска /20 даст нам возможность запускать в этой сети до 4 тысяч контейнеров. Ключ —attachable дает нам возможность запускать в этой сети не управляемые Docker Swarm (обычные) контейнеры, запускаемые при помощи команды docker run.
Из-за того, что на каждом хосте будет запущено очень большое количество контейнеров (а это в свою очередь означает запуск очень большого количества системных процессов Docker), нам нужно немного настроить некоторые sysctl параметры, чтобы избежать нестабильности работы нашего сервиса.
Самое первое сообщение, которое вы увидите в выводе dmesg, если оставить sysctl настройки по умолчанию — neighbour: arp_cache: neighbor table overflow!. Эта проблема вызвана слишком маленьким ARP кешом по умолчанию, который будет не успевать очищаться.
Каждый запускаемый вами контейнер подключается к трем сетям:
Т.к. в этих сетях для каждого контейнера будут назначены несколько IP-адресов, то суммарно получается порядка 5000 IP адресов для работы запускаемого нами сервиса.
ARP кешем управляют следующие настройки:
Вообще говоря, работа с ARP кешем документирована слабо, поэтому обычно эти значения подбирают, умножая предыдущие значения на 2, до тех пор, пока система не начнет чувствовать себя нормально.
Другие важные настройки
Также вам определенно понадобятся и другие sysctl настройки, которые касаются главным образом того, сколько соединений может быть открыто в данный момент времени, какие порты используются для соединений, как быстро перерабатываются соединения и т.д.
Запуск реплицированного сервиса
После того, как был произведен тюнинг хостов, давайте попробуем запустить наш сервис на 1000 контейнеров в Docker Swarm кластере. В качестве сервиса будет использоваться очень маленький образ titpetric/sonyflake, предназначенный для генерации ID-шников и отдачи их по HTTP. Исходный код сервиса доступен на GitHub
Пара минут и все контейнеры запустились!
В качестве теста будет использоваться Wrk — современный инструмент тестирования производительности HTTP, способный генерировать значительную нагрузку при работе даже с одним многоядерным процессором. Он сочетает в себе многопоточный дизайн с масштабируемыми системами уведомления о событиях, такими как epoll и kqueue.
Уменьшим количество запущенных контейнеров до 30.
Проверить статус операции можно командой
Как только количество контейнеров в статусе «Removal in Progress» станет равно нулю и docker service ls будет показывать 30/30, проведем тест еще раз
Результаты теста показывают примерно 30% увеличение времени ответа каждого отдельного контейнера при увеличении количества запускаемых контейнеров в 30 раз (с 30 до 1000), обуславливаемое контекстным переключением CPU каждого сервера кластера, затрачиваемое на обслуживание работы каждого отдельного docker процесса.
Мы успешно протестировали возможности Docker Swarm кластера и запустили в нем 1000 контейнеров. Создать и запустить для этого теста виртуальную инфраструктуру в Облаке КРОК заняло у меня считанные минуты, а производительности даже таких небольших виртуальных серверов с лихвой хватило на обслуживание работы такого количества контейнеров. Само собой, чтобы запустить еще большее количество микросервисных контейнеров на одном виртуальном сервере, нужно еще чуть-чуть увеличить параметры sysctl.



