Dml sql что это
Язык SQL стал фактически стандартным языком доступа к базам данных. Все СУБД, претендующие на название «реляционные», реализуют тот или иной диалект SQL. Многие нереляционные системы также имеют в настоящее время средства доступа к реляционным данным. Целью стандартизации является переносимость приложений между различными СУБД.
Стандарт языка SQL, хотя и основан на реляционной теории, но во многих местах отходит он нее. Например, отношение в реляционной модели данных не допускает наличия одинаковых кортежей, а таблицы в терминологии SQL могут иметь одинаковые строки. Имеются и другие отличия.
Язык SQL является реляционно полным. Это означает, что любой оператор реляционной алгебры может быть выражен подходящим оператором SQL.
Операторы SQL
Основу языка SQL составляют операторы, условно разбитые не несколько групп по выполняемым функциям.
Можно выделить следующие группы операторов (перечислены не все операторы SQL):
Операторы защиты и управления данными
Кроме того, есть группы операторов установки параметров сеанса, получения информации о базе данных, операторы статического SQL, операторы динамического SQL.
Наиболее важными для пользователя являются операторы манипулирования данными (DML).
Примеры использования операторов манипулирования данными
Пример 1. Вставка одной строки в таблицу:
Пример 2. Вставка в таблицу нескольких строк, выбранных из другой таблицы (в таблицу TMP_TABLE вставляются данные о поставщиках из таблицы P, имеющие номера, большие 2):
Пример 3. Обновление нескольких строк в таблице:
Пример 4. Удаление нескольких строк в таблице:
Пример 5. Удаление всех строк в таблице:
Примеры использования оператора SELECT
Оператор SELECT всегда выполняется над некоторыми таблицами, входящими в базу данных.
Результатом выполнения оператора SELECT всегда является таблица. Таким образом, по результатам действий оператор SELECT похож на операторы реляционной алгебры. Любой оператор реляционной алгебры может быть выражен подходящим образом сформулированным оператором SELECT. Сложность оператора SELECT определяется тем, что он содержит в себе все возможности реляционной алгебры, а также дополнительные возможности, которых в реляционной алгебре нет.
Отбор данных из одной таблицы
Пример 6. Выбрать все данные из таблицы поставщиков (ключевые слова SELECT… FROM…):
Замечание. В результате получим новую таблицу, содержащую полную копию данных из исходной таблицы P.
Пример 7. Выбрать все строки из таблицы поставщиков, удовлетворяющих некоторому условию (ключевое слово WHERE…):
Замечание. В качестве условия в разделе WHERE можно использовать сложные логические выражения, использующие поля таблиц, константы, сравнения (>, | = | <>> Конструктор значений строки
Пример 33. Сравнение поля таблицы и скалярного значения:
Пример 34. Сравнение двух сконструированных строк:
Этот пример эквивалентен условному выражению
Предикат between ::=
Конструктор значений строки [NOT] BETWEEN
Конструктор значений строки AND Конструктор значений строки
Пример 35. PD.VOLUME BETWEEN 10 AND 100
Предикат in ::=
Конструктор значений строки [NOT] IN
<(Select-выражение) | (Выражение для вычисления значения. )>
Предикат like ::=
Выражение для вычисления значения строки-поиска [NOT] LIKE
Выражение для вычисления значения строки-шаблона [ESCAPE Символ]
Предикат null ::=
Конструктор значений строки IS [NOT] NULL
Замечание. Предикат NULL применяется специально для проверки, не равно ли проверяемое выражение null-значению.
Предикат количественного сравнения ::=
Конструктор значений строки <= | | = | <>>
<ANY | SOME | ALL> (Select-выражение)
Замечание. Кванторы ANY и SOME являются синонимами и полностью взаимозаменяемы.
Замечание. Если указан один из кванторов ANY и SOME, то предикат количественного сравнения возвращает TRUE, если сравниваемое значение совпадает хотя бы с одним значением, возвращаемом в подзапросе (select-выражении).
Замечание. Если указан квантор ALL, то предикат количественного сравнения возвращает TRUE, если сравниваемое значение совпадает с каждым значением, возвращаемом в подзапросе (select-выражении).
Предикат exist ::=
EXIST (Select-выражение)
Замечание. Предикат EXIST возвращает значение TRUE, если результат подзапроса (select-выражения) не пуст.
Предикат unique ::=
UNIQUE (Select-выражение)
Замечание. Предикат UNIQUE возвращает TRUE, если в результате подзапроса (select-выражения) нет совпадающих строк.
Предикат match ::=
Конструктор значений строки MATCH [UNIQUE]
[PARTIAL | FULL] (Select-выражение)
Замечание. Предикат MATCH проверяет, будет ли значение, определенное в конструкторе строки совпадать со значением любой строки, полученной в результате подзапроса.
Предикат overlaps ::=
Конструктор значений строки OVERLAPS Конструктор значений строки
Замечание. Предикат OVERLAPS, является специализированным предикатом, позволяющем определить, будет ли указанный период времени перекрывать другой период времени.
Порядок выполнения оператора SELECT
Для того чтобы понять, как получается результат выполнения оператора SELECT, рассмотрим концептуальную схему его выполнения. Эта схема является именно концептуальной, т.к. гарантируется, что результат будет таким, как если бы он выполнялся шаг за шагом в соответствии с этой схемой. На самом деле, реально результат получается более изощренными алгоритмами, которыми «владеет» конкретная СУБД.
Стадия 1. Выполнение одиночного оператора SELECT
Если в операторе присутствуют ключевые слова UNION, EXCEPT и INTERSECT, то запрос разбивается на несколько независимых запросов, каждый из которых выполняется отдельно:
Шаг 1 (FROM). Вычисляется прямое декартовое произведение всех таблиц, указанных в обязательном разделе FROM. В результате шага 1 получаем таблицу A.
Шаг 2 (WHERE). Если в операторе SELECT присутствует раздел WHERE, то сканируется таблица A, полученная при выполнении шага 1. При этом для каждой строки из таблицы A вычисляется условное выражение, приведенное в разделе WHERE. Только те строки, для которых условное выражение возвращает значение TRUE, включаются в результат. Если раздел WHERE опущен, то сразу переходим к шагу 3. Если в условном выражении участвуют вложенные подзапросы, то они вычисляются в соответствии с данной концептуальной схемой. В результате шага 2 получаем таблицу B.
Шаг 3 (GROUP BY). Если в операторе SELECT присутствует раздел GROUP BY, то строки таблицы B, полученной на втором шаге, группируются в соответствии со списком группировки, приведенным в разделе GROUP BY. Если раздел GROUP BY опущен, то сразу переходим к шагу 4. В результате шага 3 получаем таблицу С.
Шаг 4 (HAVING). Если в операторе SELECT присутствует раздел HAVING, то группы, не удовлетворяющие условному выражению, приведенному в разделе HAVING, исключаются. Если раздел HAVING опущен, то сразу переходим к шагу 5. В результате шага 4 получаем таблицу D.
Шаг 5 (SELECT). Каждая группа, полученная на шаге 4, генерирует одну строку результата следующим образом. Вычисляются все скалярные выражения, указанные в разделе SELECT. По правилам использования раздела GROUP BY, такие скалярные выражения должны быть одинаковыми для всех строк внутри каждой группы. Для каждой группы вычисляются значения агрегатных функций, приведенных в разделе SELECT. Если раздел GROUP BY отсутствовал, но в разделе SELECT есть агрегатные функции, то считается, что имеется всего одна группа. Если нет ни раздела GROUP BY, ни агрегатных функций, то считается, что имеется столько групп, сколько строк отобрано к данному моменту. В результате шага 5 получаем таблицу E, содержащую столько колонок, сколько элементов приведено в разделе SELECT и столько строк, сколько отобрано групп.
Стадия 2. Выполнение операций UNION, EXCEPT, INTERSECT
Если в операторе SELECT присутствовали ключевые слова UNION, EXCEPT и INTERSECT, то таблицы, полученные в результате выполнения 1-й стадии, объединяются, вычитаются или пересекаются.
Стадия 3. Упорядочение результата
Если в операторе SELECT присутствует раздел ORDER BY, то строки полученной на предыдущих шагах таблицы упорядочиваются в соответствии со списком упорядочения, приведенном в разделе ORDER BY.
Как на самом деле выполняется оператор SELECT
Если внимательно рассмотреть приведенный выше концептуальный алгоритм вычисления результата оператора SELECT, то сразу понятно, что выполнять его непосредственно в таком виде чрезвычайно накладно. Даже на самом первом шаге, когда вычисляется декартово произведение таблиц, приведенных в разделе FROM, может получиться таблица огромных размеров, причем практически большинство строк и колонок из нее будет отброшено на следующих шагах.
На самом деле в РСУБД имеется оптимизатор, функцией которого является нахождение такого оптимального алгоритма выполнения запроса, который гарантирует получение правильного результата.
Схематично работу оптимизатора можно представить в виде последовательности нескольких шагов:
Шаг 1 (Синтаксический анализ). Поступивший запрос подвергается синтаксическому анализу. На этом шаге определяется, правильно ли вообще (с точки зрения синтаксиса SQL) сформулирован запрос. В ходе синтаксического анализа вырабатывается некоторое внутренне представление запроса, используемое на последующих шагах.
Шаг 2 (Преобразование в каноническую форму). Запрос во внутреннем представлении подвергается преобразованию в некоторую каноническую форму. При преобразовании к канонической форме используются как синтаксические, так и семантические преобразования. Синтаксические преобразования (например, приведения логических выражений к конъюнктивной или дизъюнктивной нормальной форме, замена выражений «x AND NOT x» на «FALSE», и т.п.) позволяют получить новое внутренне представление запроса, синтаксически эквивалентное исходному, но стандартное в некотором смысле. Семантические преобразования используют дополнительные знания, которыми владеет система, например, ограничения целостности. В результате семантических преобразований получается запрос, синтаксически не эквивалентный исходному, но дающий тот же самый результат.
Шаг 3 (Генерация планов выполнения запроса и выбор оптимального плана). На этом шаге оптимизатор генерирует множество возможных планов выполнения запроса. Каждый план строится как комбинация низкоуровневых процедур доступа к данным из таблиц, методам соединения таблиц. Из всех сгенерированных планов выбирается план, обладающий минимальной стоимостью. При этом анализируются данные о наличии индексов у таблиц, статистических данных о распределении значений в таблицах, и т.п. Стоимость плана это, как правило, сумма стоимостей выполнения отдельных низкоуровневых процедур, которые используются для его выполнения. В стоимость выполнения отдельной процедуры могут входить оценки количества обращений к дискам, степень загруженности процессора и другие параметры.
Шаг 4. (Выполнение плана запроса). На этом шаге план, выбранный на предыдущем шаге, передается на реальное выполнение.
Во многом качество конкретной СУБД определяется качеством ее оптимизатора. Хороший оптимизатор может повысить скорость выполнения запроса на несколько порядков. Качество оптимизатора определяется тем, какие методы преобразований он может использовать, какой статистической и иной информацией о таблицах он располагает, какие методы для оценки стоимости выполнения плана он знает.
Реализация реляционной алгебры средствами оператора SELECT (Реляционная полнота SQL)
Для того, чтобы показать, что язык SQL является реляционно полным, нужно показать, что любой реляционный оператор может быть выражен средствами SQL. На самом деле достаточно показать, что средствами SQL можно выразить любой из примитивных реляционных операторов.
Оператор декартового произведения
Реляционная алгебра: 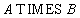
Оператор проекции
Реляционная алгебра: 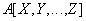
Введение в базы данных
Алексей Федоров, Наталия Елманова
В предыдущих двух статьях данного цикла, опубликованных в № 6 и 7 нашего журнала, мы рассмотрели различные механизмы доступа к данным, включая ADO, BDE и их альтернативы. Теперь мы знаем, как выбрать технологию доступа к данным для той или иной пары «СУБД — средство разработки».
Располагая технологией доступа к данным, можно наконец подумать и о том, каким образом следует манипулировать самими данными и метаданными. Способы манипуляции могут быть специфичными для данной СУБД (например, использование объектов клиентской части этой СУБД для доступа к объектам баз данных) или для данного механизма доступа к данным. Тем не менее существует более или менее универсальный способ манипуляции данными, поддерживаемый почти всеми серверными реляционными СУБД и большинством универсальных механизмов доступа к данным (в том числе при использовании их совместно с настольными СУБД). Этот способ — применение языка SQL (Structured Query Language — язык структурированных запросов). Ниже мы рассмотрим назначение и особенности этого языка, а также изучим, как с его помощью извлекать и суммировать данные, добавлять, удалять и модифицировать записи, защищать данные от несанкционированного доступа, создавать базы данных. Для более подробного изучения SQL мы можем порекомендовать книги Мартина Грабера «Введение в SQL» (М., Лори, 1996) и «SQL. Справочное руководство» (М., Лори, 1997).
Введение
Structured Query Language представляет собой непроцедурный язык, используемый для управления данными реляционных СУБД. Термин «непроцедурный» означает, что на данном языке можно сформулировать, что нужно сделать с данными, но нельзя проинструктировать, как именно это следует сделать. Иными словами, в этом языке отсутствуют алгоритмические конструкции, такие как метки, операторы цикла, условные переходы и др.
Язык SQL был создан в начале 70-х годов в результате исследовательского проекта IBM, целью которого было создание языка манипуляции реляционными данными. Первоначально он назывался SEQUEL (Structured English Query Language), затем — SEQUEL/2, а затем — просто SQL. Официальный стандарт SQL был опубликован ANSI (American National Standards Institute — Национальный институт стандартизации, США) в 1986 году (это наиболее часто используемая ныне реализация SQL). Данный стандарт был расширен в 1989 и 1992 годах, поэтому последний стандарт SQL носит название SQL92. В настоящее время ведется работа над стандартом SQL3, содержащим некоторые объектно-ориентированные расширения.
Существует три уровня соответствия стандарту ANSI — начальный, промежуточный и полный. Многие производители серверных СУБД, такие как IBM, Informix, Microsoft, Oracle и Sybase, применяют собственные реализации SQL, основанные на стандарте ANSI (отвечающие как минимум начальному уровню соответствия стандарту) и содержащие некоторые расширения, специфические для данной СУБД.
Более подробную информацию о соответствии стандарту версии SQL, используемой в конкретной СУБД, можно найти в документации, поставляемой с этой СУБД.
Как работает SQL
Давайте рассмотрим, как работает SQL. Предположим, что имеется база данных, управляемая с помощью какой-либо СУБД. Для извлечения из нее данных используется запрос, сформулированный на языке SQL. СУБД обрабатывает этот запрос, извлекает запрашиваемые данные и возвращает их. Этот процесс схематически изображен на рис. 1.
Как мы увидим позже, SQL позволяет не только извлекать данные, но и определять структуру данных, добавлять и удалять данные, ограничивать или предоставлять доступ к данным, поддерживать ссылочную целостность.
Обратите внимание на то, что SQL сам по себе не является ни СУБД, ни отдельным продуктом. Это язык, применяемый для взаимодействия с СУБД и являющийся в определенном смысле ее неотъемлемой частью.
Операторы SQL
SQL содержит примерно 40 операторов для выполнения различных действий внутри СУБД. Ниже приводится краткое описание категорий этих операторов.
Data Definition Language (DDL)
Data Definition Language содержит операторы, позволяющие создавать, изменять и уничтожать базы данных и объекты внутри них (таблицы, представления и др.). Эти операторы перечислены в табл. 1.
Применяется для добавления новой таблицы к базе данных
Применяется для удаления таблицы из базы данных
Применяется для изменения структуры имеющейся таблицы
Применяется для добавления нового представления к базе данных
Применяется для удаления представления из базы данных
Применяется для создания индекса для данного поля
Применяется для удаления существующего индекса
Применяется для создания новой схемы в базе данных
Применяется для удаления схемы из базы данных
Применяется для создания нового домена
Применяется для переопределения домена
Применяется для удаления домена из базы данных
 |
Иногда оператор SELECT относят к отдельной категории, называемой Data Query Language (DQL).
Transaction Control Language (TCL)
Операторы Transaction Control Language применяются для управления изменениями, выполненными группой операторов DML. Операторы TCL представлены в табл. 3.
Применяется для завершения транзакции и сохранения изменений в базе данных
Применяется для отката транзакции и отмены изменений в базе данных
Применяется для установки параметров доступа к данным в текущей транзакции
|
|
Все операторы SQL имеют вид, показанный на рис. 2.
Каждый оператор SQL начинается с глагола, представляющего собой ключевое слово, определяющее, что именно делает этот оператор (SELECT, INSERT, DELETE. ). В операторе содержатся также предложения, содержащие сведения о том, над какими данными производятся операции. Каждое предложение начинается с ключевого слова, такого как FROM, WHERE и др. Структура предложения зависит от его типа — ряд предложений содержит имена таблиц или полей, некоторые могут содержать дополнительные ключевые слова, константы или выражения.
Ключевые слова ANSI/ISO SQL92
Некоторые ключевые слова, определенные в стандарте ANSI SQL, не могут быть использованы в качестве имен объектов баз данных (таблиц, полей, имен пользователей). Эти ключевые слова приведены в табл. 6.
Стандарт SQL также включает список потенциальных ключевых слов, зарезервированных для последующих версий стандарта SQL. Эти ключевые слова приведены в табл. 7.
С помощью чего можно выполнить SQL-операторы
Все современные серверные СУБД (а также многие популярные настольные СУБД) содержат в своем составе утилиты, позволяющие выполнить SQL-предложение и ознакомиться с его результатом. В частности, клиентская часть Oracle содержит в своем составе утилиту SQL Plus, а Microsoft SQL Server — утилиту SQL Query Analyzer. Именно этой утилитой мы воспользуемся для демонстрации возможностей SQL, а в качестве базы данных, над которой мы будем «экспериментировать», возьмем базу данных NorthWind, входящую в комплект поставки Microsoft SQL Server 7.0. В принципе, можно использовать другую базу данных и любую другую утилиту, способную выполнять в этой базе данных SQL-предложения и отображать результаты (или даже написать свою, используя какое-либо средство разработки — Visual Basic, Delphi, C++Builder и др.). Однако на всякий случай рекомендуется сделать резервную копию этой базы данных.
Учебник по языку SQL (DDL, DML) на примере диалекта MS SQL Server. Часть четвертая
Предыдущие части
В данной части мы рассмотрим
Добавим немного новых данных
Для демонстрационных целей добавим несколько отделов и должностей:
JOIN-соединения – операции горизонтального соединения данных
Здесь нам очень пригодится знание структуры БД, т.е. какие в ней есть таблицы, какие данные хранятся в этих таблицах и по каким полям таблицы связаны между собой. Первым делом всегда досконально изучайте структуру БД, т.к. нормальный запрос можно написать только тогда, когда ты знаешь, что откуда берется. У нас структура состоит из 3-х таблиц Employees, Departments и Positions. Приведу здесь диаграмму из первой части:

Если суть РДБ – разделяй и властвуй, то суть операций объединений снова склеить разбитые по таблицам данные, т.е. привести их обратно в человеческий вид.
Если говорить просто, то операции горизонтального соединения таблицы с другими таблицами используются для того, чтобы получить из них недостающие данные. Вспомните пример с еженедельным отчетом для директора, когда при запросе из таблицы Employees, нам для получения окончательного результата недоставало поля «Название отдела», которое находится в таблице Departments.
Понимание каждого вида соединения очень важно, т.к. от применения того или иного вида, результат запроса может отличаться. Сравните результаты одного и того же запроса с применением разного типа соединения, попробуйте пока просто увидеть разницу и идите дальше (мы сюда еще вернемся):
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 1 | Администрация |
| 1003 | Андреев А.А. | 3 | 1 | Администрация |
| 1004 | Николаев Н.Н. | 3 | 1 | Администрация |
| 1005 | Александров А.А. | NULL | 1 | Администрация |
| 1000 | Иванов И.И. | 1 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 2 | Бухгалтерия |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 2 | Бухгалтерия |
| 1004 | Николаев Н.Н. | 3 | 2 | Бухгалтерия |
| 1005 | Александров А.А. | NULL | 2 | Бухгалтерия |
| 1000 | Иванов И.И. | 1 | 3 | ИТ |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | 3 | ИТ |
| 1000 | Иванов И.И. | 1 | 4 | Маркетинг и реклама |
| 1001 | Петров П.П. | 3 | 4 | Маркетинг и реклама |
| 1002 | Сидоров С.С. | 2 | 4 | Маркетинг и реклама |
| 1003 | Андреев А.А. | 3 | 4 | Маркетинг и реклама |
| 1004 | Николаев Н.Н. | 3 | 4 | Маркетинг и реклама |
| 1005 | Александров А.А. | NULL | 4 | Маркетинг и реклама |
| 1000 | Иванов И.И. | 1 | 5 | Логистика |
| 1001 | Петров П.П. | 3 | 5 | Логистика |
| 1002 | Сидоров С.С. | 2 | 5 | Логистика |
| 1003 | Андреев А.А. | 3 | 5 | Логистика |
| 1004 | Николаев Н.Н. | 3 | 5 | Логистика |
| 1005 | Александров А.А. | NULL | 5 | Логистика |
Настало время вспомнить про псевдонимы таблиц
Пришло время вспомнить про псевдонимы таблиц, о которых я рассказывал в начале второй части.
В многотабличных запросах, псевдоним помогает нам явно указать из какой именно таблицы берется поле. Посмотрим на пример:
В нем поля с именами ID и Name есть в обоих таблицах и в Employees, и в Departments. И чтобы их различать, мы предваряем имя поля псевдонимом и точкой, т.е. «emp.ID», «emp.Name», «dep.ID», «dep.Name».
Вспоминаем почему удобнее пользоваться именно короткими псевдонимами – потому что, без псевдонимов наш запрос бы выглядел следующим образом:
По мне, стало очень длинно и хуже читаемо, т.к. имена полей визуально потерялись среди повторяющихся имен таблиц.
В многотабличных запросах, хоть и можно указать имя без псевдонима, в случае если имя не дублируется во второй таблице, но я бы рекомендовал всегда использовать псевдонимы в случае соединения, т.к. никто не гарантирует, что поле с таким же именем со временем не добавят во вторую таблицу, а тогда ваш запрос просто сломается, ругаясь на то что он не может понять к какой таблице относится данное поле.
Только используя псевдонимы, мы сможем осуществить соединения таблицы самой с собой. Предположим встала задача, получить для каждого сотрудника, данные сотрудника, который был принят прямо до него (табельный номер отличается на единицу меньше). Допустим, что у нас табельные номера выдаются последовательно и без дырок, тогда мы можем это сделать примерно следующим образом:
Т.е. здесь одной таблице Employees, мы дали псевдоним «e1», а второй «e2».
Разбираем каждый вид горизонтального соединения
Для этой цели рассмотрим 2 небольшие абстрактные таблицы, которые так и назовем LeftTable и RightTable:
Посмотрим, что в этих таблицах:
| LCode | LDescr |
|---|---|
| 1 | L-1 |
| 2 | L-2 |
| 3 | L-3 |
| 5 | L-5 |
| RCode | RDescr |
|---|---|
| 2 | B-2 |
| 3 | B-3 |
| 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
Здесь были возвращены объединения строк для которых выполнилось условие (l.LCode=r.RCode)
LEFT JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
Здесь были возвращены все строки LeftTable, которые были дополнены данными строк из RightTable, для которых выполнилось условие (l.LCode=r.RCode)
RIGHT JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Здесь были возвращены все строки RightTable, которые были дополнены данными строк из LeftTable, для которых выполнилось условие (l.LCode=r.RCode)
По сути если мы переставим LeftTable и RightTable местами, то аналогичный результат мы получим при помощи левого соединения:
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Я за собой заметил, что я чаще применяю именно LEFT JOIN, т.е. я сначала думаю, данные какой таблицы мне важны, а потом думаю, какая таблица/таблицы будет играть роль дополняющей таблицы.
FULL JOIN – это по сути одновременный LEFT JOIN + RIGHT JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
Вернулись все строки из LeftTable и RightTable. Строки для которых выполнилось условие (l.LCode=r.RCode) были объединены в одну строку. Отсутствующие в строке данные с левой или правой стороны заполняются NULL-значениями.
CROSS JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | 2 | B-2 |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 2 | B-2 |
| 5 | L-5 | 2 | B-2 |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2 | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2 | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Каждая строка LeftTable соединяется с данными всех строк RightTable.
Возвращаемся к таблицам Employees и Departments
Надеюсь вы поняли принцип работы горизонтальных соединений. Если это так, то возвратитесь на начало раздела «JOIN-соединения – операции горизонтального соединения данных» и попробуйте самостоятельно понять примеры с объединением таблиц Employees и Departments, а потом снова возвращайтесь сюда, обсудим это вместе.
Давайте попробуем вместе подвести резюме для каждого запроса:
| Запрос | Резюме |
|---|---|
| По сути данный запрос вернет только сотрудников, у которых указано значение DepartmentID. Т.е. мы можем использовать данное соединение, в случае, когда нам нужны данные по сотрудникам числящихся за каким-нибудь отделом (без учета внештаткиков). | |
| Вернет всех сотрудников. Для тех сотрудников у которых не указан DepartmentID, поля «dep.ID» и «dep.Name» будут содержать NULL. Вспоминайте, что NULL значения в случае необходимости можно обработать, например, при помощи ISNULL(dep.Name,’вне штата’). Этот вид соединения можно использовать, когда нам важно получить данные по всем сотрудникам, например, чтобы получить список для начисления ЗП. | |
| Здесь мы получили дырки слева, т.е. отдел есть, но сотрудников в этом отделе нет. Такое соединение можно использовать, например, когда нужно выяснить, какие отделы и кем у нас заняты, а какие еще не сформированы. Эту информацию можно использовать для поиска и приема новых работников из которых будет формироваться отдел. | |
| Этот запрос важен, когда нам нужно получить все данные по сотрудникам и все данные по имеющимся отделам. Соответственно получаем дырки (NULL-значения) либо по сотрудникам, либо по отделам (внештатники). Данный запрос, например, может использоваться в целях проверки, все ли сотрудники сидят в правильных отделах, т.к. может у некоторых сотрудников, которые числятся как внештатники, просто забыли указать отдел. | |
| В таком виде даже сложно придумать где это можно применить, поэтому пример с CROSS JOIN я покажу ниже. |
Обратите внимание, что в случае повторения значений DepartmentID в таблице Employees, произошло соединение каждой такой строки со строкой из таблицы Departments с таким же ID, то есть данные Departments объединились со всеми записями для которых выполнилось условие (emp.DepartmentID=dep.ID):
В нашем случае все получилось правильно, т.е. мы дополнили таблицу Employees, данными таблицы Departments. Я специально заострил на этом внимание, т.к. бывают случаи, когда такое поведение нам не нужно. Для демонстрации поставим задачу – для каждого отдела вывести последнего принятого сотрудника, если сотрудников нет, то просто вывести название отдела. Возможно напрашивается такое решение – просто взять предыдущий запрос и поменять условие соединение на RIGHT JOIN, плюс переставить поля местами:
| ID | Name | ID | Name |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1001 | Петров П.П. |
| 3 | ИТ | 1003 | Андреев А.А. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
Но мы для ИТ-отдела получили три строчки, когда нам нужна была только строчка с последним принятым сотрудником, т.е. Николаевым Н.Н.
Задачу такого рода, можно решить, например, при помощи использования подзапроса:
| ID | Name | ID | Name |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
При помощи предварительного объединения Employees с данными подзапроса, мы смогли оставить только нужных нам для соединения с Departments сотрудников.
Здесь мы плавно переходим к использованию подзапросов. Я думаю использование их в таком виде должно быть для вас понятно на интуитивном уровне. То есть подзапрос подставляется на место таблицы и играет ее роль, ничего сложного. К теме подзапросов мы еще вернемся отдельно.
Посмотрите отдельно, что возвращает подзапрос:
| MaxEmployeeID |
|---|
| 1005 |
| 1000 |
| 1002 |
| 1004 |
Т.е. он вернул только идентификаторы последних принятых сотрудников, в разрезе отделов.
Соединения выполняются последовательно сверху-вниз, наращиваясь как снежный ком, который катится с горы. Сначала происходит соединение «Employees emp JOIN (Подзапрос) lastEmp», формируя новый выходной набор:
Потом идет объединение набора, полученного «Employees emp JOIN (Подзапрос) lastEmp» (назовем его условно «ПоследнийРезультат») с Departments, т.е. «ПоследнийРезультат RIGHT JOIN Departments dep»:
Самостоятельная работа для закрепления материала
Если вы новичок, то вам обязательно нужно прорабатывать каждую JOIN-конструкцию, до тех пор, пока вы на 100% не будете понимать, как работает каждый вид соединения и правильно представлять результат какого вида будет получен в итоге.
Для закрепления материала про JOIN-соединения сделаем следующее:
Посмотрим, что в таблицах:
| LCode | LDescr |
|---|---|
| 1 | L-1 |
| 2 | L-2a |
| 2 | L-2b |
| 3 | L-3 |
| 5 | L-5 |
| RCode | RDescr |
|---|---|
| 2 | B-2a |
| 2 | B-2b |
| 3 | B-3 |
| 4 | B-4 |
А теперь попытайтесь сами разобрать, каким образом получилась каждая строчка запроса с каждым видом соединения (Excel вам в помощь):
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | 2 | B-2a |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 3 | L-3 | 2 | B-2a |
| 5 | L-5 | 2 | B-2a |
| 1 | L-1 | 2 | B-2b |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 2 | B-2b |
| 5 | L-5 | 2 | B-2b |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2a | 3 | B-3 |
| 2 | L-2b | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2a | 4 | B-4 |
| 2 | L-2b | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Еще раз про JOIN-соединения
Еще один пример с использованием нескольких последовательных операций соединении. Здесь повтор получился не специально, так получилось – не выбрасывать же материал. 😉 Но ничего «повторение – мать учения».
Если используется несколько операций соединения, то в таком случае они применяются последовательно сверху-вниз. Грубо говоря, после каждого соединения создается новый набор и следующее соединение уже происходит с этим расширенным набором. Рассмотрим простой пример:
Первым делом выбрались все записи таблицы Employees:
Дальше произошло соединение с таблицей Departments:
Дальше уже идет соединение этого набора с таблицей Positions:
Т.е. это выглядит примерно так:
И в последнюю очередь идет возврат тех данных, которые мы просим вывести:
Соответственно, ко всему этому полученному набору можно применить фильтр WHERE и сортировку ORDER BY:
| ID | EmployeeName | PositionName | DepartmentName |
|---|---|---|---|
| 1004 | Николаев Н.Н. | Программист | ИТ |
| 1001 | Петров П.П. | Программист | ИТ |
То есть последний полученный набор – представляет собой такую же таблицу, над которой можно выполнять базовый запрос:
То есть если раньше в роли источника выступала только одна таблица, то теперь на это место мы просто подставляем наше выражение:
В результате чего получаем тот же самый базовый запрос:
А теперь, применим группировку:
Видите, мы все так же крутимся вокруг да около базовых конструкций, теперь надеюсь понятно, почему очень важно в первую очередь хорошо понять их.
И как мы увидели, в запросе на месте любой таблицы может стоять подзапрос. В свою очередь подзапросы могут быть вложены в подзапросы. И все эти подзапросы тоже представляют из себя базовые конструкции. То есть базовая конструкция, это кирпичики, из которых строится любой запрос.
Обещанный пример с CROSS JOIN
Давайте используем соединение CROSS JOIN, чтобы подсчитать сколько сотрудников, в каком отделе и на каких должностях числится. Для каждого отдела перечислим все существующие должности:
В данном случае сначала выполнилось соединение при помощи CROSS JOIN, а затем к полученному набору сделалось соединение с данными из подзапроса при помощи LEFT JOIN. Вместо таблицы в LEFT JOIN мы использовали подзапрос.
Подзапрос заключается в скобки и ему присваивается псевдоним, в данном случае это «e». То есть в данном случае объединение происходит не с таблицей, а с результатом следующего запроса:
| DepartmentID | PositionID | EmplCount |
|---|---|---|
| NULL | NULL | 1 |
| 2 | 1 | 1 |
| 1 | 2 | 1 |
| 3 | 3 | 2 |
| 3 | 4 | 1 |
Вместе с псевдонимом «e» мы можем использовать имена DepartmentID, PositionID и EmplCount. По сути дальше подзапрос ведет себя так же, как если на его месте стояла таблица. Соответственно, как и у таблицы,
все имена колонок, которые возвращает подзапрос, должны быть заданы явно и не должны повторяться.
Связь при помощи WHERE-условия
Для примера перепишем следующий запрос с JOIN-соединением:
Через WHERE-условие он примет следующую форму:
Здесь плохо то, что происходит смешивание условий соединения таблиц (emp.DepartmentID=dep.ID) с условием фильтрации (emp.DepartmentID=3).
Теперь посмотрим, как сделать CROSS JOIN:
Через WHERE-условие он примет следующую форму:
Т.е. в этом случае мы просто не указали условие соединения таблиц Employees и Departments. Чем плох этот запрос? Представьте, что кто-то другой смотрит на ваш запрос и думает «кажется тот, кто писал запрос забыл здесь дописать условие (emp.DepartmentID=dep.ID)» и с радостью, что обнаружил косяк, дописывает это условие. В результате чего задуманное вами может сломаться, т.к. вы подразумевали CROSS JOIN. Так что, если вы делаете декартово соединение, то лучше явно укажите, что это именно оно, используя конструкцию CROSS JOIN.
Для оптимизатора запроса может быть и без разницы как вы реализуете соединение (при помощи WHERE или JOIN), он их может выполнить абсолютно одинаково. Но из соображения понимаемости кода, я бы рекомендовал в современных СУБД стараться никогда не делать соединение таблиц при помощи WHERE-условия. Использовать WHERE-условия для соединения, в том случае, если в СУБД реализованы конструкции JOIN, я бы назвал сейчас моветоном. WHERE-условия служат для фильтрации набора, и не нужно перемешивать условия служащие для соединения, с условиями отвечающими за фильтрацию. Но если вы пришли к выводу, что без реализации соединения через WHERE не обойтись, то конечно приоритет за решеной задачей и «к черту все устои».
UNION-объединения – операции вертикального объединения результатов запросов
Я специально использую словосочетания горизонтальное соединение и вертикальное объединение, т.к. заметил, что новички часто недопонимают и путают суть этих операций.
Давайте первым делом вспомним как мы делали первую версию отчета для директора:
Так вот, если бы мы не знали, что существует операция группировки, но знали бы, что существует операция объединения результатов запроса при помощи UNION ALL, то мы могли бы склеить все эти запросы следующим образом:
Т.е. UNION ALL позволяет склеить результаты, полученные разными запросами в один общий результат.
Соответственно количество колонок в каждом запросе должно быть одинаковым, а также должны быть совместимыми и типы этих колонок, т.е. строка под строкой, число под числом, дата под датой и т.п.
Немного теории
В MS SQL реализованы следующие виды вертикального объединения:
| Операция | Описание |
|---|---|
| UNION ALL | В результат включаются все строки из обоих наборов. (A+B) |
| UNION | В результат включаются только уникальные строки двух наборов. DISTINCT(A+B) |
| EXCEPT | В результат попадают уникальные строки верхнего набора, которые отсутствуют в нижнем наборе. Разница 2-х множеств. DISTINCT(A-B) |
| INTERSECT | В результат включаются только уникальные строки, присутствующие в обоих наборах. Пересечение 2-х множеств. DISTINCT(A&B) |
Все это проще понять на наглядном примере.
Создадим 2 таблицы и наполним их данными:
Посмотрим на содержимое:
| T1 | T2 |
|---|---|
| 1 | Text 1 |
| 1 | Text 1 |
| 2 | Text 2 |
| 3 | Text 3 |
| 4 | Text 4 |
| 5 | Text 5 |
| B1 | B2 |
|---|---|
| 2 | Text 2 |
| 3 | Text 3 |
| 6 | Text 6 |
| 6 | Text 6 |
UNION ALL
UNION
По сути UNION можно представить, как UNION ALL, к которому применена операция DISTINCT:



