DMA для новичков или то, что вам нужно знать
Всем привет, сегодня мы с вами поговорим о DMA: именно о той технологии, которая помогает вашему компьютеру воспроизводить для вас музыку, выводить изображение на экран, записывать информацию на жесткий диск, и при этом оказывать на центральный процессор просто мизерную нагрузку.
DMA, что это? О чем вы говорите?
DMA, или Direct Memory Access – технология прямого доступа к памяти, минуя центральный процессор. В эпоху 486-ых и первых Pentium во всю царствовала шина ISA, а также метод обмена данными между устройствами – PIO (Programmed Input/Output).
Когда объемы данных, которыми оперирует процессор начали возрастать, стало понятно, что нужно минимизировать участие процессора в цепочке обмена данными, а то прийдется туго. И вот тогда активное применение нашла технология прямого доступа к памяти.
Кстати говоря, DMA используется не только для обмена данными между устройством и ОЗУ, но также между устройствами в системе, возможен DMA трансфер между двумя участками ОЗУ (хотя данный маневр не применим к x86 архитектуре). Также в своем процессоре Cell, IBM использует DMA как основной механизм обмена данными между синергетическими процессорными элементами (SPE) и центральным процессорным элементом (PPE). Также каждый SPE и PPE может обмениватся данными через DMA с оперативной памятью. Данный прием – на самом деле большое преимущество Cell, ибо избавляет от проблем когерентности кешей при мультипроцессорной обработке данных.
И снова теория
Прежде чем мы перейдем к практике, я бы хотел осветить несколько важных аспектов программирования PCI, PCI-E устройств.
Я вскользь упомянул о регистрах устройства, но как же к ним имеет доступ центральный процессор? Как многие из вас знают, есть такая сущность в компьютерных технологиях, как IO порты (Input/Output ports). Они предназначены для обмена информацией между центральным процессором и периферийными устройствами, а доступ к ним возможен с помощью специальных ассемблерных инструкций — in/out. BIOS (или OpenFirmware на PPC based системах) на ранних этапах инициализации PCI устройств, а также некоторых других (Super IO контроллера, контроллера PS/2 устройств, ACPI timer и т.д.), закрепляет за определенным контроллером собственный диапазон IO портов, куда и отображаются регистры устройства.
Итак, существует два метода утилизации DMA: contiguous DMA и scatter/gather DMA.
Contiguous DMA
Scatter/gather DMA
С ростом скорости Ethernet адаптеров, contiguous DMA показал свою несостоятельность. В основном из-за того, что требовались области памяти достаточно большого размера, которые подчас невозможно было выделить, так как в современных системах фрагментация физической памяти достаточно высока. Во всем виноват механизм виртуальной памяти, без которого нынче никуда 🙂
Решение напрашивается само собой: использовать вместо одного большого участка памяти несколько, но в разных регионах этой самой памяти. Возникает вопрос, но как же сообщить контроллеру устройства, как инициировать DMA трансфер и по какому адресу писать данные? И тут нашли решение, использовать дескрипторы, чтобы описывать каждый вот такой участок в оперативной памяти.
На сегодня пожалуй все, иначе информации станет слишком много. В следующей статье я покажу вам, как с этой уличной магией работает IOKit. Жду отзывов и дополнений 😉
Начальные сведения о DMA
Как и в любой функции копирования данных для запуска обмена с использованием DMA необходимы следующие параметры:
Пересылаемые данные могут быть:
1. Каналы DMA
Для выполнения нескольких «параллельных» задач по пересылке данных в контроллере DMA реализовано 32 независимых канала. Одновременно активен только один канал. Каждый канал настраивается отдельно на выполнение конкретной задачи. Таким образом, возможно одновременно запустить и копирование массивов, и считывание данных из АЦП, и запись данных в ЦАП и многое другое. Все это будет работать как бы «параллельно».
Например, необходимо передать 100 значений из массива в массив. Если выставить параметр R_power = 6 (2 6 = 64), то канал передаст 64-е значения и разрешит провести арбитраж. Далее:
1.1 Источники и приемники данных
В отличие от простого цикла копирования, DMA может не просто выполнять пересылку данных, а делать это по определённому событию.
Например, можно настроить, чтобы одно слово данных копировалось из адреса источника по событию готовности АЦП. Тогда, если адресом источника выбрать регистр «ADC_RESULT», то DMA может без участия ядра считывать готовые значения из АЦП и складывать их, например, в массив. Затем, когда DMA закончит передавать заданное количество данных (цикл DMA), будет сгенерировано прерывание от DMA, и ядро может обработать весь массив полученных данных от АЦП. Отличие от обычного копирования здесь в том, что измерение АЦП занимает некоторое количество времени, поэтому считывать результат с АЦП нужно только по событию готовности.
1.2 Запросы к DMA от периферийных устройств
В МК 1986ВЕ4У, 1986ВЕ9x, 1986ВЕ1Т и 1986ВЕ3Т сигналы dma_req[С] и dma_sreq[С] от определенных периферийных контроллеров жестко привязаны к каналам DMA. Подключение сигналов запросов dma_req[С] и dma_sreq[С] от периферии к каналам DMA для микроконтроллеров серии 1986ВЕ9х приведено в таблице 1.
Таблица 1 – Распределение запросов от периферийных контроллеров по каналам DMA
| Номер канала | Источник dma_sreq | Источник dma_req |
| 0 | UART1_TX | UART1_TX |
| 1 | UART1_RX | UART1_RX |
| 2 | UART2_TX | UART2_TX |
| 3 | UART2_RX | UART2_RX |
| 4 | SSP1_TX | SSP1_TX |
| 5 | SSP1_RX | SSP1_RX |
| 6 | SSP2_RX | SSP2_TX |
| 7 | SSP2_RX | SSP2_RX |
| 8 | ADC1_EC | — |
| 9 | ADC2_EC | — |
| 10 | TIMER1 | — |
| 11 | TIMER2 | — |
| 12 | TIMER3 | — |
| 13 | — | — |
| … | — | — |
| 31 | — | — |
В МК 1986ВЕ8Т, 1923ВК014 и «Электросила» сигналы запросов dma_sreq[C] и dma_req[C] от периферийных устройств могут мультиплексироваться между каналами, что позволяет гибко настроить приоритет работы DMA с периферийными контроллерами.
1.3 Арбитраж каналов DMA
На рисунке 1 показана структурная схема работы каналов DMA с осуществлением арбитража.
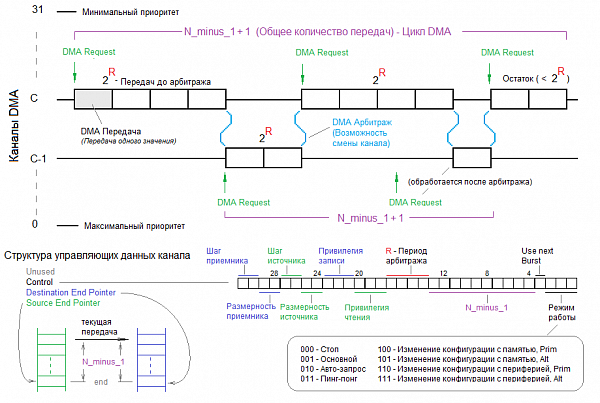
Рисунок 1 – Структурная схема работы каналов DMA с осуществлением арбитража
Пояснения к рисунку 1:
1.4 Управляющие данные канала DMA
Каждый канал управляется своей структурой, которая состоит из 4-х 32-разрядных слов:
Управляющие структуры каналов должны быть расположены в памяти друг за другом и представлять собой массив структур. Когда DMA будет обрабатывать канал, например, 5-й, то он будет считывать и изменять 5-ю структуру в массиве. Указатель на начало массива структур должен быть прописан в регистре CTRL_BASE_PTR.
Альтернативная структура может использоваться, например, в режиме работы ping-pong. В этом режиме по окончании цикла основной структуры DMA переключится на исполнение альтернативной структуры, затем, по окончании цикла альтернативной структуры DMA снова перейдёт к выполнению основной структуры и так далее. Получается, что один и тот же канал работает то с одной управляющей структурой, то с другой. По окончании цикла каждой структуры будет вызвано прерывание, и пока DMA выполняет обмен по текущей структуре, необходимо заново проинициализировать следующую структуру. Такой подход позволяет организовать непрерывную пересылку данных с помощью DMA с минимальными затратами процессорного времени.
Режим ping-pong может пригодиться, например, для вывода сигнала в ЦАП. Пока DMA выводит сигнал по основной структуре, ядро высчитывает и заполняет данные сигнала для альтернативной структуры. По завершении цикла DMA переключится на альтернативную структуру, и ядро может заполнять сигнал для основной структуры и так далее.
2. Регистры блока DMA
3. Пример программного копирования данных в FIFO контроллера Ethernet
3.1 Инициализация DMA
3.2 Функция записи в FIFO через DMA
Адрес FIFO (адрес назначения), как и адрес массива данных (источника), задается вызывающим кодом вместе с количеством передаваемых данных. Функция записи в FIFO контроллера Ethernet приведена во фрагменте кода 2, далее приведена дополнительная информация к коду:
// Доступ к глобальному массиву управляющих данных каналов
extern DMA_CtrlDataTypeDef DMA_ControlTable[DMA_Channels_Number * (1 + DMA_AlternateData)];
void ETH_DMAFrameTx(uint32_t * DstBuf, uint32_t BufferSize, uint32_t * SrcBuf)
<
__IO uint32_t * ptrControltable;
uint32_t tmpval;
// Высший приоритет
MDR_DMA->CHNL_PRIORITY_SET |= 1 CHNL_ENABLE_SET = (1 CHNL_SW_REQUEST = (1 CHNL_ENABLE_CLR = (1
4. Работа с DMA в 1986ВЕ1Т/1986Е3Т
Следует обратить внимание, что в микроконтроллерах 1986ВЕ1Т и 1986ВЕ3Т не вся память ОЗУ доступна для контроллера DMA, а только AHB-Lite SRAM 16KB, начинающаяся с адреса 0x2010_0000 (спецификация, раздел «Организация памяти»). Это необходимо учитывать при выборе источника и приёмника, а также при размещении массива управляющих структур.
В SPL массив управляющих структур DMA_ControlTable[] объявлен с атрибутом __attribute__((section(«EXECUTABLE_MEMORY_SECTION»))), позволяющим разместить данный массив в определённую область памяти МК. Данный атрибут необходимо указать в конфигурационном файле компоновщика для соответствующего региона памяти.
Фрагмент кода 3 – Размещение структуры с атрибутом «EXECUTABLE_MEMORY_SECTION» в регион памяти IRAM2
RW_IRAM2 0x20100000 0x00004000 <
*.o (EXECUTABLE_MEMORY_SECTION)
.ANY (+RW +ZI)
>
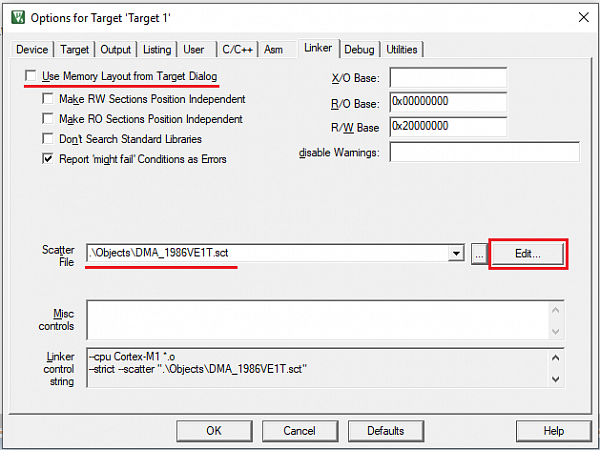
Подробная информация про конфигурационный файл компоновщика приведена на официальном сайте Keil, а также в статье «Расположение функций в ОЗУ, программирование EEPROM».
Переходим с STM32 на российский микроконтроллер К1986ВЕ92QI. Генерируем и воспроизводим звук. Часть вторая: освоение DMA
DMA, или Direct Memory Access – технология прямого доступа к памяти, минуя центральный процессор.
Небольшое отступление.
От идеи использовать DMA до получения первых результатов прошла неделя упорной работы. Первые 3 дня пытался освоить его сам, но никак не получалось получить хоть какой-то результат. Все получилось лишь после того, как на официальном форуме мне дали пример конфигурации DMA под примерно такую же задачу. Через 4 дня его подробного изучения и подробного анализа документации, в голове появилась ясная картина структуры работы DMA.
Первое впечатление.


Правила обмена данными
Контроллер использует правила обмена данными, перечисленные далее в Таблица 376, при соблюдении следующих условий:
— канал DMA включен, что выполняется установкой в состояние логической единицы разрядов управления chnl_enable_set[C] и master_enable;
— флаги запроса dma_req[C] и dma_sreq[C] не замаскированы, что выполняется установкой в состояние логического нуля разряда управления chnl_req_mask_set [C];
— контроллер находится не в тестовом режиме, что выполняется установкой в состояние логического нуля разряда управления int_test_en bit[C].
Разряд [C] = 0 не дает эффекта. Необходимо использовать
chnl_req_mask_clr регистр для разрешения
установки запросов;
После включения канала, нужно определиться с режимом работы DMA.
— недействительный;
— основной;
— авто-запрос;
— «пинг-понг»;
— работа с памятью в режиме «исполнение с изменением конфигурации»;
— работа с периферией в режиме «исполнение с изменением конфигурации».
Основной
В этом режиме контроллер работает только с основными или альтернативными управляющими данными канала. После того, как разрешена работа канала и контроллер получил запрос на обработку, цикл DMA выглядит следующим образом:
1. Контроллер выполняет 2^R передач. Если число оставшихся передач 0, контроллер переходит к шагу 3.
2. Осуществление арбитража:
— если высокоприоритетный канал выдает запрос на обработку, то контроллер начинает обслуживание этого канала;
— если периферийный блок или программное обеспечение выдает запрос на обработку (повторный запрос на обработку по каналу), то контроллер переходит к шагу 1.
3. Контроллер устанавливает dma_done[C] в состояние 1 на один такт сигнала hclk. Это указывает центральному процессору на завершение цикла DMA.
Подробнее мы с ним разберемся когда будем заполнять структуру настройки DMA канала.
Структура работы DMA.
— указатель конца данных источника;
— указатель конца данных приемника;
— разряды управления;
— вычисление адреса.
Заполнение структуры канала DMA
Разрядность данных источника = полуслово:
b11 = нет инкремента. Адрес остается равным значению области памяти dst_data_end_ptr.
Каждый канал может иметь две структуры. Первичную и альтернативную. Альтернативная нас пока не касается (Она нужна для других режимов работы). Нас интересует лишь первичная (правый столбик). Для того, чтобы контроллер увидел нашу структуру конфигурации восьмого канала — она должна быть расположена по адресу 0x20000080 или 0x20000280, или 0x20000480 и т. д. Этой записью я хотел показать, что структура должна быть обязательно в ОЗУ и должна быть выравнена по границе в 1024 байта. Опишем эту структуру.
Еще небольшое пояснение. Главное, чтобы по указанному адресу присутствовала нужная структура. Данные структур 7-го канала или же 9-го DMA никак не волнуют. Их может и не быть. Технически, можно записать в ОЗУ по указанным адресам четыре 32-х битных ячейки и пользоваться. Но есть риск, что контроллер изменит их в процессе выполнения программы. Заполним ее в программе.
Получаем синусоидальный сигнал с помощью DMA.
Далее в прерывании системного таймера нам нужно проверять — передал ли DMA все. Если да — то нужно настроить его структуру заново. Дело в том, что после каждой передачи DMA самостоятельно отнимает от количества передач по единице. Поэтому после всех передач — нужно восстановить изначальное значение для передачи синусоиды повторно. После этого нужно по новой разрешить работу канала (после передачи канал становиться запрещенным) и повторно запустить передачу.
Вместо заключения.
Хоть нам и удалось научиться работать с DMA, но нам все равно еще не удалось разгрузить процессор. В следующей статье я разберу работу таймера и переложу работу с DMA на него, оставив мощности процессора для наших нужд.
Большое спасибо хочу сказать Yurock-у, который на официальном официальном форуме поделился примером кода конфигурации DMA под DAC. Изначально я планировал написать статью о разборе данного примера. Ибо разбирался я с ним около 3-х дней. Уж слишком сложным он для меня оказался. С использованием таймера и различных структур.
DMA вообще и в частности
Знал бы где упадешь, соломки подстелил бы
О существовании DMA (Direct Memory Access) — русскоязычное ПДП (Прямой Доступ к Памяти) многие разработчики встроенных устройств слышали, но вот применяют его гораздо реже, чем он (ПДП) этого заслуживает. Кстати, я буду упоминать именно эту аббревиатуру, но не потому, что я такой упрямый патриот и противник англоязычных заимствований, а всего лишь от того, что мне лень лишний раз переключать раскладку клавиатуры.
Основных причин недостаточного использования ПДП в программах для МК три: 1) относительная сложность данного устройства, которая вместе с 2) непониманием выгод его применения приводит к нежеланию данное устройство изучать и осваивать (как говорят в таких случаях, старшая сестра не велит — для тех, кто в танке — это про лень, котороая раньше нас родилась), отягощенному 3) отсутствием хороших и понятных примеров применения ПДП в поставляемых с МК руководствами. И если первые две причины носят явно субъективный характер, то третья несомненно объективна и внутри меня просыпается параноик и настойчиво утверждает, что это сделано специально с целью не допустить отечественных разработчиков МК на продвинутые уровни, где-то выше 60 (то, что при этом страдают и остальные разработчики по всему миру, параноиком игнорируется, поскольку либо 1) за пределами России распространяются правильные примеры, либо 2) ради великой цели не допустить вставания, сами понимаете кого, с колен буржуины готовы пойти на любые жертвы).
Тем не менее без шуток, действительно, в примерах в лучшем случае лежит модуль настройки отдельно взятого канала ПДП, а увязанную систему с ПДП драйвером Вы в примерах применений не найдете (даже в CMSIS не найдете, ну тут действительно есть объективная причина — напишу пост про него — упомяну). Почему так на самом деле — я не знаю, но разработчикам кристаллов виднее, единственное разумное обоснование, которое мне приходит в голову — это то, что ПДП довольно таки специфичны, поэтому «нельзя просто так взять и » перенести код из другого источника, а ввиду малой востребованности ПДП в реальных разработках отсутствие таких примеров не считается существенным недостатком. Восполнить указанный мной пробел в знаниях и предназначен настоящий пост (нескромное заявление, но если сам себя не похвалишь, весь день ходишь как оплеванный), поэтому те, кого я заинтриговал, могут нажать на кнопочку.
Тем не менее, должен предостеречь нетерпеливого читателя, что он не найдет тут серебряной пули, которую можно смело включать в свои разработки, а всего лишь (но и это немало) обнаружит некоторые мысли и подходы, которые облегчат ему построение своих собственных систем на МК с применением ПДП. То есть я поставлю флажки в тех местах, где точно лежат грабли, но не гарантирую, что непомеченных граблей не останется, что, впрочем, не мешает Вам повыкидывать флажки на фиг и пройтись по граблям самостоятельно. Вообще, те, кто читал мои посты, наверняка обратили внимание, что я делаю упор не на то, ЧТО следует сделать и КАК именно, а на то, ПОЧЕМУ я рекомендую сделать именно так.
Итак, ПДП — это часть аппаратуры МК, которая позволяет производить пересылку данных между различными составными частями данного МК (и системы с его участием) без привлечения ресурсов процессора (точнее говоря, с минимальным привлечением, поскольку делать что либо в МК системе вообще БЕЗ участия процессора — мысль смелая и далеко заводящая).
Основная идея данных устройств состоит в том, что при выполнении программы далеко не каждая команда вызывает обращение по системной шине к внешним устройствам или к оперативной памяти (обращение к памяти программ не рассматривается), поэтому у устройства, обслуживающего системную шину, имеются циклы простоя, которые было бы неплохо как нибудь использовать.
Другой причиной, способствующей созданию ПДП, было появление быстродейтвующих устройств ввода-вывода, обслуживание которых по полингу требовало значительных затрат процессорного времени, а обслуживание по прерываниям было практически невозможно. Предтечей ПДП следует считать так назывемые периферийные процессоры в архитектуре майнфрэймов с локальной памятью, которые потом трансформировались в настоящие ПДП, решающие задачи передачи данных между быстродействующими устройствами ввода-вывода и основной оперативной памятью и являющиеся частью аппаратуры, управляющей конкретным внешним устройством.
Встречалась картина (например в ДВК), когда одно ВУ работало по ПДП, а второе — по прерываниям или даже в цикле опроса (драйвер MX, если кто помнит). Когда появились первые МК, в которых память интегрирована в чип, создание внешних по отношению к кристаллу устройств с ПДП стало весьма нетривиальной задачей и, естественно, ПДП перекочевало внутрь МК и стало частью его архитектуры. Этот процесс не имел линейного поступательного характера и можно встретить как МК на основе 51й архитектуры с поддержкой ПДП, так и МК на основе Cortex-M3 с богатым набором периферии, но без поддержки ПДП (например, Stellaris). Тем не менее, в бОльшей части современных МК на основе ARM ПДП присутствует и можем перейти к их изучению и для начала остановиться на рассмотрению их особенностей.
Как было сказано выше, основное назначение ПДП — передача данных между разными устройствами с минимальным привлечением процессора. Как правило, одним из этих устройств является основная память МК, хотя иногда возможны как передачи между двумя внешними устройствами, так из памяти в память. Некоторые ПДП поддерживают такие возможности, некоторые нет, и это следует учитывать при выборе МК.
Следующей особенностью можно считать механизм обслуживания запросов в одном канале. Остановимся на этом моменте поподробнее и разберем в общих чертах работу одного запроса одного канала ПДП.
Для того, чтобы совершить передачу, нам следует сообщить ПДП о своих намерениях, то есть откуда мы хотим передавать данные, куда их следует направить, сколько именно данных следует передать, режимы передачи (об этом чуть позже), и, возможно, служебная информация. Поместить данную информацию мы можем либо в регистры, ответственные за работу ПДП (устаревший способ и дальше мы поймем, почему) либо в оперативную память системы, причем в последнем случае это должна быть либо специальная выделенная область памяти, чтобы ПДП знал, откуда надо взять информацию, либо в какой то регистр ПДП должна быть помещена информация о том, где именно в оперативной памяти лежат данные (говоря привычным языком, мы должны поместить ссылку). Именно последний метод и используется, поскольку он имеет следующие преимущества: оперативная память МК — ценный ресурс и сегментировать ее на детерминированные блоки не есть хорошая практика.
На практике встречаются разнообразные комбинированные схемы, в основном с целью экономии аппаратуры МК — указатель на область памяти, в которой размещаются 2 или более БУП, циклически переключающиеся по мере исполнения, указатель на следующий БУП в служебном поле текущего БУП, иерархический доступ, когда БУП содержит указания на последовательность БУП, которые собственно и выполняются и так далее.
Теперь перейдем от рассмотрения ПДП вообще к рассмотрению конкретной реализации, а именно к МК фирмы «Миландр» 1986ВЕ1Т.
Почему именно к нему? Ну, во-первых, я с ним работаю, во-вторых, у него достаточно богатый по возможностям ПДП, а в-третьих, у него богато фич (это не баг это фича такая — да да именно из этого разряда), которые делают работу с МК увлекательным занятием, после которого работа с аналогами от известных производителей покажется легкой и простой.
Сначала о хорошем — ПДП поддерживает 32 независимых канала доступа — по одному на каждое внешнее устройство в составе МК и еще один для пересылок память-память. Кроме того, как вы уже поняли из предыдущего предложения, ПДП поддерживает все возможные режимы пересылки, а именно: регистры ВУ-память, регистры ВУ-регистры ВУ, память-память, и если вам кажется, что так и должно быть, то это совсем не так, и разные режимы функционируют слегка по-разному и не везде реализованы.
Далее, ПДП поддерживает разные форматы данных: 1 байт, 2 байта и 4 байта (слово в нашей архитектуре), а также разные виды инкремента адреса отдельно источника и приемника: на 1, на 2 и на 4 (декремент не поддерживается). ПДП имеет систему арбитража обслуживаемых каналов с возможностью назначения гибких приоритетов для каждого канала и настраиваемого размера элементарной транзакции (количества передач одного канала, по выполнению которых производится арбитраж). Кроме того, каждый канал может иметь до 2 БУП, которые могут сменяться по циклической системе, либо работать в иерархическом режиме, вместе с тем возможен и однократный режим.
Чтобы соблюсти баланс, скажем и о менее хорошем. Опять про документацию — если Вы на знаете, как работает ПДП, то из документации фирмы вы об этом точно не узнаете. Документация явно переводная, есть и ошибки перевода, которые сильно искажают смысл, есть и весьма невнятно описанные места, но в целом для подготовленного разработчика ее может и хватить, если вы привыкли домысливать за автора. Из более существенных недостатков (конечно по сравнению с идеальным устройством) — значительные затраты ресурса шины (6 доступов на 1 пересылку, хотя может я чего-то недопонял) и еще ряд фич, о которых чуть позже.
ЗАСАДА №1 от разработчиков — прерывание от окончания передачи не проявляются в внешних устройствах. То есть у нас есть один вектор прерывания по окончанию транзакции от любого из запрограммированных каналов. Более того, нет никакого регистра, в котором хранился бы номер канала, завершившего транзакцию, либо хотя бы битовый регистр с флагами. То есть единственный способ определить номер завершившего передачу канала — перебирать все каналы и смотреть соответствующие поля TCB, и это нам придется делать в обработчике прерывания, который должен занимать минимальное время. Напрашивающееся решение — перенести поиск канала в нижнюю половину драйвера обработки не проходит, поскольку нас ожидает:
ЗАСАДА № 2 от разработчиков — прерывание является потенциальным и прекратить работу верхней половниы, не сбросив его явным образом, мы не можем. Более того, есть еще и
ЗАСАДА № 3 от них же — мы не можем сбросить прерывание путем манипуляции реистрами ПДП, а должны проводить сброс разрешения выработки запросов в регистрах внешнего устройства. Да да, именно так, драйвер ПДП должен что то знать о составе регистров обслуживаемых устройств, более чудовищного нарущения принципа инкапсуляции (а он справедлив и для проектирования аппаратуры) трудно себе представить. Я не знаю, что курили разработчики ПДП, но, как написано у Гайдука, «что то очень интересное». То есть, вы можете не верить, но если мы запретим прохождение запросов соостветствующего канала и запретим его обработку, то прерывание мы все равно НЕ СБРОСИМ.
Что-то получилось больше букв, чем было запланировано, поэтому оставим читателей размышлять о сложной ситуации, в которой оказался главный герой истории, что особенно актуально в пятницу вечером, а сам напишу Продолжение следует…



