filecheck .ru
Большинство антивирусных программ распознает dce.exe как вирус, в частности, BitDefender определяет файл как Gen:Variant.Adware.Kazy.328874, и Kaspersky определяет файл как not-a-virus:AdWare.Win32.Boogzo.m.
Бесплатный форум с информацией о файлах поможет вам найти информацию, как удалить файл. Если вы знаете что-нибудь об этом файле, пожалуйста, оставьте комментарий для других пользователей.
Вот так, вы сможете исправить ошибки, связанные с dce.exe
Информация о файле dce.exe
Процесс DCEService принадлежит программе DCEService или Distributed Computing Experiment от неизвестно.
Описание: dce.exe не является важным для Windows и часто вызывает проблемы. Dce.exe находится в подпапках «C:\Program Files». Размер файла для Windows 10/8/7/XP составляет 59,392 байт. 
Это не системный процесс Windows. Нет информации о создателе файла. Приложение не видно пользователям. Поэтому технический рейтинг надежности 46% опасности.
Программа Distributed Computing Experiment может быть удалена в Панели управления в разделе программы и компоненты.
Важно: Вы должны проверить файл dce.exe на вашем компьютере, чтобы убедится, что это вредоносный процесс. Если DCEService изменил поиск по умолчанию и начальную страницу в браузере, то вы можете восстановить ваши параметры следующим образом:
Изменение параметров по умолчанию для Internet-Explorer ▾
Комментарий пользователя
Лучшие практики для исправления проблем с dce
Чистый и аккуратный компьютер является ключевым требованием для избежания проблем с ПК. Это означает: проверка на наличие вредоносных программ, очистка жесткого диска, используя cleanmgr и sfc /scannow, удаление программ, которые вам больше не нужны, проверка Автозагрузки (используя msconfig) и активация Автоматического обновления Windows. Всегда помните о создании периодических бэкапов, или как минимум о создании точек восстановления.
Если у вас актуальная проблема, попытайтесь вспомнить последнее, что вы сделали, или последнюю программу, которую вы установили, прежде чем проблема появилась первый раз. Используйте resmon команду, чтобы определить процесс, который вызывает у вас проблему. Даже если у вас серьезные проблемы с компьютером, прежде чем переустанавливать Windows, лучше попробуйте восстановить целостность установки ОС или для Windows 8 и более поздних версий Windows выполнить команду DISM.exe /Online /Cleanup-image /Restorehealth. Это позволит восстановить операционную систему без потери данных.
dce сканер

Security Task Manager показывает все запущенные сервисы Windows, включая внедренные скрытые приложения (например, мониторинг клавиатуры или браузера, авто вход). Уникальный рейтинг надежности указывает на вероятность того, что процесс потенциально может быть вредоносной программой-шпионом, кейлоггером или трояном.
Бесплатный aнтивирус находит и удаляет неактивные программы-шпионы, рекламу, трояны, кейлоггеры, вредоносные и следящие программы с вашего жесткого диска. Идеальное дополнение к Security Task Manager.
Reimage бесплатное сканирование, очистка, восстановление и оптимизация вашей системы.
distributed computing experiment
Can anyone help me?
I have a PUP in my Programs list named «Distributed Computing Experiment». There is no published name nor is it removeable. When I click to uninstall it, a message pops up saying «You do not have sufficient access to uninstall Distributed Computing Experiment» please contact your system administrator». I am the administrator. I have tried various malware removal tools and scanners and they just don’t detect it.
Any help with this will be greatly appreciated.
Many thanks in advance.
BC AdBot (Login to Remove)
The Coolest BC Computer
Please download MiniToolBox and run it.
* Double-click mbam-setup.exe and follow the prompts to install the program.
* At the end, be sure a checkmark is placed next to Update Malwarebytes’ Anti-Malware and Launch Malwarebytes’ Anti-Malware, then click Finish.
* If an update is found, it will download and install the latest version.
* Once the program has loaded, select Perform quick scan, then click Scan.
* When the scan is complete, click OK, then Show Results to view the results.
* Be sure that everything is checked, and click Remove Selected.
* When completed, a log will open in Notepad.
* Post the log back here.
Be sure to restart the computer.
The log can also be found here:
C:\Documents and Settings\Username\Application Data\Malwarebytes\Malwarebytes’ Anti-Malware\Logs\ log-date.txt
Or at C:\Program Files\Malwarebytes’ Anti-Malware\Logs\ log-date.txt
If normal mode still doesn’t work, run the tool from safe mode.
When the scan is done Notepad will open with rKill log.
Post it in your next reply.
NOTE. rKill.txt log will also be present on your desktop.
NOTE Do NOT wrap your logs in «quote» or «code» brackets. Do NOT use spoilers.
My help doesn’t cost a penny, but if you’d like to consider a donation, click DONATE
Распределенные вычисления также относятся к использованию распределенных систем для решения вычислительных задач. В распределенных вычислениях проблема делится на множество задач, каждая из которых решается одним или несколькими компьютерами, которые взаимодействуют друг с другом посредством передачи сообщений.
СОДЕРЖАНИЕ
Вступление
Слово « распределенный» в таких терминах, как «распределенная система», «распределенное программирование» и « распределенный алгоритм » первоначально относилось к компьютерным сетям, в которых отдельные компьютеры были физически распределены в пределах некоторой географической области. В настоящее время эти термины используются в гораздо более широком смысле, даже применительно к автономным процессам, которые выполняются на одном физическом компьютере и взаимодействуют друг с другом посредством передачи сообщений.
Хотя не существует единого определения распределенной системы, обычно используются следующие определяющие свойства:
Другие типичные свойства распределенных систем включают следующее:
Параллельные и распределенные вычисления
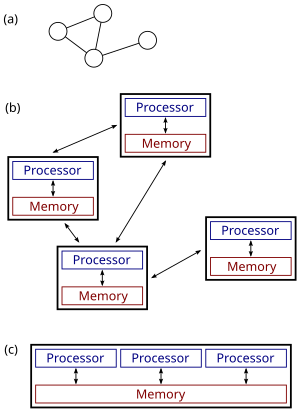
На рисунке справа показана разница между распределенными и параллельными системами. Рисунок (а) представляет собой схематический вид типичной распределенной системы; система представлена в виде сетевой топологии, в которой каждый узел является компьютером, а каждая линия, соединяющая узлы, является каналом связи. На рисунке (b) более подробно показана та же распределенная система: каждый компьютер имеет свою собственную локальную память, и обмен информацией можно осуществлять только путем передачи сообщений от одного узла к другому с использованием доступных каналов связи. На рисунке (c) показана параллельная система, в которой каждый процессор имеет прямой доступ к общей памяти.
Ситуация дополнительно осложняется традиционным использованием терминов параллельный и распределенный алгоритм, которые не совсем соответствуют приведенным выше определениям параллельных и распределенных систем ( более подробное обсуждение см. Ниже ). Тем не менее, как показывает опыт, высокопроизводительные параллельные вычисления в мультипроцессоре с общей памятью используют параллельные алгоритмы, в то время как координация крупномасштабной распределенной системы использует распределенные алгоритмы.
История
Архитектура
Приложения
Причины использования распределенных систем и распределенных вычислений могут включать:
Примеры
Примеры распределенных систем и приложений распределенных вычислений включают следующее:
Теоретические основы
Модели
Область параллельных и распределенных вычислений изучает аналогичные вопросы в случае либо нескольких компьютеров, либо компьютера, который выполняет сеть взаимодействующих процессов: какие вычислительные задачи могут быть решены в такой сети и насколько эффективно? Однако совсем не очевидно, что имеется в виду под «решением проблемы» в случае параллельной или распределенной системы: например, какова задача разработчика алгоритма и что является параллельным или распределенным эквивалентом последовательного универсальный компьютер?
Обсуждение ниже сосредоточено на случае нескольких компьютеров, хотя многие проблемы одинаковы для параллельных процессов, выполняемых на одном компьютере.
Обычно используются три точки зрения:
Пример
Хотя область параллельных алгоритмов имеет другую направленность, чем область распределенных алгоритмов, между этими двумя областями существует много взаимодействия. Например, алгоритм Коула – Вишкина для раскраски графов изначально был представлен как параллельный алгоритм, но тот же метод также может использоваться непосредственно как распределенный алгоритм.
Более того, параллельный алгоритм может быть реализован либо в параллельной системе (с использованием общей памяти), либо в распределенной системе (с использованием передачи сообщений). Традиционная граница между параллельными и распределенными алгоритмами (выбрать подходящую сеть или запускать в любой данной сети) не совпадает с границей между параллельными и распределенными системами (разделяемая память или передача сообщений).
Меры сложности
Другие проблемы
Многие исследования также сосредоточены на понимании асинхронной природы распределенных систем:
Выборы
Узлы сети обмениваются данными между собой, чтобы решить, кто из них перейдет в состояние «координатора». Для этого им нужен какой-то метод, чтобы нарушить симметрию между ними. Например, если каждый узел имеет уникальные и сопоставимые идентификаторы, тогда узлы могут сравнить свои идентификаторы и решить, что узел с наивысшим идентификатором является координатором.
Определение этой проблемы часто приписывается ЛеЛану, который формализовал ее как метод создания нового токена в сети Token Ring, в которой токен был утерян.
Алгоритмы выбора координатора спроектированы так, чтобы быть экономными с точки зрения общего количества переданных байтов и времени. Алгоритм, предложенный Галлагером, Хамблетом и Спирой для общих неориентированных графов, оказал сильное влияние на разработку распределенных алгоритмов в целом и получил премию Дейкстры за влиятельную статью по распределенным вычислениям.
Для выполнения координации в распределенных системах используется концепция координаторов. Проблема выбора координатора состоит в том, чтобы выбрать процесс из группы процессов на разных процессорах в распределенной системе, который будет выступать в качестве центрального координатора. Существует несколько алгоритмов выбора центрального координатора.
Свойства распределенных систем
Edge-ик в тумане и другие приключения периферийных вычислений
Меня зовут Игорь Хапов. Я руководитель разработки в Научно-техническом центре IBM. И сегодня я хотел бы вам помочь окунуться в мир периферийных вычислений, или edge computing, как его ещё называют. Я расскажу о том, что же такое edge computing и как он может повлиять на наш с вами мир. Также хотелось бы пояснить различия между edge computing и fog computing, какие преимущества даёт этот подход. В статье я также описал референсную архитектуру приложения на edge computing. И под конец немного расскажу о проекте с открытым исходным кодом Open Horizon, который совсем недавно присоединился к Linux Foundation.

Что же такое edge computing
Согласно определению Гартнера, edge computing — это подвид распределенных вычислений, в котором обработка информации происходит в непосредственной близости к месту, где данные были получены и будут потребляться. Это основное отличие edge computing от облачных вычислений, при которых информация собирается и обрабатывается в публичных или частных датацентрах. Основным отличием от локальных вычислений является то, что обычно edge computing — это часть большей системы, которая включает в себя сбор статистики, централизованное управление и удаленное обновление приложений на edge устройствах.
Что же такое edge устройство? Многие считают, что edge computing — это когда приложение работает на Raspberry Pi или других микрокомпьютерах. На самом деле edge computing может быть и на мобильных устройствах, персональных ноутбуках, умных камерах и других устройствах, на которых можно запустить приложение по обработке данных.
Edge computing и IoT
Довольно часто звучит вопрос — «Чем же отличается edge computing от IoT». IoT можно назвать дедушкой edge computing. IoT — это множество устройств, связанных между собой, и способных передавать информацию друг другу. А edge computing это скорее подход к организации вычислений и управлению edge устройствами. Как вы отлично понимаете, любое приложение необходимо обновлять, мониторить и осуществлять прочие обслуживающие функции. В результате edge computing подразумевает использование определенных подходов и фреймворков, о которых я расскажу чуть позже.
edge computing vs fog computing
Когда я однажды рассказал коллеге про edge computing, он ответил — ”так это же fog computing”. Давайте попробуем разобраться, в чём же разница. С одной стороны, edge computing и fog computing часто используются как синонимы, однако fog computing, или «туманные вычисления», все-таки немного отличаются.
И edge computing, и fog computing — это вычисления, которые находятся в непосредственной близости к получаемым данным. Различие заключается в том, что при туманных вычислениях обработка осуществляется на устройствах, которые постоянно подключены к сети. В edge computing вычисления осуществляются как на сенсорах, умных устройствах – без передачи на уровень gateway, так и на уровне gateway и на микрокластерах.
Для меня было открытием, что edge computing может работать в кластерах Kubernetes или OpenShift. Оказывается, что существует достаточно много задач, где кроме оконечных устройств необходимо выполнять обработку информации в локальном кластере и передавать в централизованные дата центры только результирующие данные. И такие вычисления — тоже edge computing.
Преимущества и недостатки edge computing
При выборе технологий для своего проекта я в первую очередь основываюсь на двух критериях — «Что я от этого получу?» и «Какие проблемы я от этого получу?».
Начнём с преимуществ:
Хотя, конечно, проектируя систему с edge computing, не стоит забывать, что как и любую другую технологию её стоит использовать в зависимости от требований к системе, которую вам необходимо реализовать.
Среди недостатков edge computing можно выделить следующие:
С одной стороны, последний пункт является наиболее критичным, но, к счастью, консорциум Linux Foundation Edge (LF EDGE) включает в себя всё больше и больше проектов с открытым исходным кодом, а их зрелость стремительно растет.
Принципы компании IBM при создании платформы edge computing
Компания IBM, являясь одним из лидеров в области гибридных облаков, использует определённые принципы при разработке решений для edge computing:
IBM применяет эти принципы при декомпозиции задачи построения фреймворка edge computing.

Как вы можете видеть, всё решение разбито на 4 сегмента использования:
Помимо основных принципов и подходов, IBM разработала референсную архитектуру для решений, основанных на edge computing. Референсная архитектура — это шаблон, показывающий основные элементы системы и детализированный настолько, чтобы иметь возможность адаптировать его под конкретное решение для заказчика. Давайте рассмотрим такую архитектуру более подробно.
Референсная архитектура edge computing
Edge devices
В первую очередь, у нас есть какое-либо встроенное или дискретное edge-устройство, к которому подключены сенсоры, датчики или управляющие механизмы, например, для координации движения роборуки. Из сервисов/данных на таком устройстве могут находиться:
Hybrid multicloud
Если мы говорим об использовании ML-модели, которая будет запускаться на десятках или тысячах устройств, то нам необходимо облако, которое сможет отвечать за обучение такой модели, обработку статистики, отображение сводной информации (правая часть архитектуры).
Edge server and Edge micro data center
Как мы уже говорили, можно встретить промежуточные (близкие) кластеры обработки данных на уровне шлюзов или микро-датацентров с установленной поддержкой кластерных технологий.
Edge framework
Когда мы осознаем, что есть необходимость в управлении большим количеством сервисов на тысячах устройств и сотнями приложений в разных кластерах, наступает понимание, что надо бы использовать какой-то фреймворк для управления всем этим зоопарком и синхронизации между устройствами.
Именно наличие данного фреймворка раскрывает преимущества edge computing перед разнородными разнесёнными вычислениями.
Как мы видим, кроме центральной части по управлению сервисами и моделями в данном фреймворке присутствуют агенты, обеспечивающие контроль за управлением жизненным циклом сервисов на устройствах/кластерах на каждом из уровней использования.
Open Horizon и IBM Edge Application Manager
Именно для решения задач в области edge computing IBM разработала и выложила в open-source проект Open Horizon. Если вы помните, один из принципов, которые IBM заложила в edge computing – все компоненты должны быть основаны на open source технологиях. В мае 2020 года проект Open Horizon вошел в Linux Foundation Edge — Международный фонд open-source технологий для созданий edge-решений. Также Open Horizon является ядром нового продукта от RedHat и IBM — IBM Edge Application Manager, решения для управления приложениями на всех устройствах edge computing: от Raspberry Pi до промежуточных кластеров обработки данных.
Несмотря на то, что проект Open Horizon вошел в консорциум только в мае, он уже достаточно давно развивается как open-source проект. И мы в Научно-техническом центре IBM не только успели его попробовать, но и довести свое решение до промышленного использования. О том, как мы разрабатывали проект с использованием edge computing, и что у нас получилось — будет отдельная статья, которая выйдет в ближайшие несколько недель.
Сценарии использования
С одной стороны, edge computing framework — это специализированное решение для определённого круга задач, но оно нашло применение во многих индустриях.
В своё время, когда я изучал работу московских камер “Стрелка”, я понял, что это в чистом виде edge computing, с вычислениями «прямо на столбе» и промежуточной обработкой данных в раздельных вычислительных кластерах у различных ведомств.
Сценарии нашлись в финансовом секторе, в продажах при самообслуживании, в медицине и секторе страхования, торговле и конечно при производстве. Именно в создании решения для автоматизации и оценки качества произведённого оборудования, основанного на edge computing, мне с коллегами из Научно-технического центра IBM и посчастливилось принять участие. И на своем опыте попробовать, как создаются решения edge computing.
Если Вас заинтересовала данная тематика, следите за обновлениями в хабраблоге компании IBM и смотрите видео в разделе Ссылки. Наши зарубежные коллеги к настоящему моменту уже осветили многие технические вопросы и описали, какие сценарии уже работают и применяются в различных отраслях.
Distributed computing for efficient digital infrastructures
Today, distributed computing is an integral part of both our digital work life and private life. Anyone who goes online and performs a Google search is already using distributed computing. Distributed system architectures are also shaping many areas of business and providing countless services with ample computing and processing power. In the following, we will explain how this method works and introduce the system architectures used and its areas of application. We will also discuss the advantages of distributed computing.
What is distributed computing?
The term “distributed computing” describes a digital infrastructure in which a network of computers solves pending computational tasks. Despite being physically separated, these autonomous computers work together closely in a process where the work is divvied up. The hardware being used is secondary to the method here. In addition to high-performance computers and workstations used by professionals, you can also integrate minicomputers and desktop computers used by private individuals.
Distributed hardware cannot use a shared memory due to being physically separated, so the participating computers exchange messages and data (e.g. computation results) over a network. This inter-machine communication occurs locally over an intranet (e.g. in a data center) or across the country and world via the internet. Messages are transferred using internet protocols such as TCP/IP and UDP.
In line with the principle of transparency, distributed computing strives to present itself externally as a functional unit and to simplify the use of technology as much as possible. For example, users searching for a product in the database of an online shop perceive the shopping experience as a single process and do not have to deal with the modular system architecture being used.
In short, distributed computing is a combination of task distribution and coordinated interactions. The goal is to make task management as efficient as possible and to find practical flexible solutions.
How does distributed computing work?
In distributed computing, a computation starts with a special problem-solving strategy. A single problem is divided up and each part is processed by one of the computing units. Distributed applications running on all the machines in the computer network handle the operational execution.
Distributed applications often use a client-server architecture. Clients and servers share the work and cover certain application functions with the software installed on them. A product search is carried out using the following steps: The client acts as an input instance and a user interface that receives the user request and processes it so that it can be sent on to a server. The remote server then carries out the main part of the search function and searches a database. The search results are prepared on the server-side to be sent back to the client and are communicated to the client over the network. In the end, the results are displayed on the user’s screen.
Middleware services are often integrated into distributed processes. Acting as a special software layer, middleware defines the (logical) interaction patterns between partners and ensures communication, and optimal integration in distributed systems. It provides interfaces and services that bridge gaps between different applications and enables and monitors their communication (e.g. through communication controllers). For operational implementation, middleware provides a proven method for cross-device inter-process communication called remote procedure call (RPC) which is frequently used in client-server architecture for product searches involving database queries.
This integration function, which is in line with the transparency principle, can also be viewed as a translation task. Technically heterogeneous application systems and platforms normally cannot communicate with one another. Middleware helps them to “speak one language” and work together productively. In addition to cross-device and cross-platform interaction, middleware also handles other tasks like data management. It controls distributed applications’ access to functions and processes of operating systems that are available locally on the connected computer.

Distributed applications can solve problems across devices in a computer network. When used in conjunction with middleware, they can optimize operational interactions with locally accessible hardware and software.
In order to protect your privacy, the video will not load until you click on it.
What are the different types of distributed computing?
Distributed computing is a multifaceted field with infrastructures that can vary widely. It is thus nearly impossible to define all types of distributed computing. However, this field of computer science is commonly divided into three subfields:
Cloud computing uses distributed computing to provide customers with highly scalable cost-effective infrastructures and platforms. Cloud providers usually offer their resources through hosted services that can be used over the internet. A number of different service models have established themselves on the market:
Grid computing is based on the idea of a supercomputer with enormous computing power. However, computing tasks are performed by many instances rather than just one. Servers and computers can thus perform different tasks independently of one another. Grid computing can access resources in a very flexible manner when performing tasks. Normally, participants will allocate specific resources to an entire project at night when the technical infrastructure tends to be less heavily used.
One advantage of this is that highly powerful systems can be quickly used and the computing power can be scaled as needed. There is no need to replace or upgrade an expensive supercomputer with another pricey one to improve performance.
Since grid computing can create a virtual supercomputer from a cluster of loosely interconnected computers, it is specialized in solving problems that are particularly computationally intensive. This method is often used for ambitious scientific projects and decrypting cryptographic codes.
Cluster computing cannot be clearly differentiated from cloud and grid computing. It is a more general approach and refers to all the ways in which individual computers and their computing power can be combined together in clusters. Examples of this include server clusters, clusters in big data and in cloud environments, database clusters, and application clusters. Computer networks are also increasingly being used in high-performance computing which can solve particularly demanding computing problems.
Different types of distributed computing can also be defined by looking at the system architectures and interaction models of a distributed infrastructure. Due to the complex system architectures in distributed computing, the term distributed systems is more often used.
The following are some of the more commonly used architecture models in distributed computing:
The client-server model is a simple interaction and communication model in distributed computing. In this model, a server receives a request from a client, performs the necessary processing procedures, and sends back a response (e.g. a message, data, computational results).
A peer-to-peer architecture organizes interaction and communication in distributed computing in a decentralized manner. All computers (also referred to as nodes) have the same rights and perform the same tasks and functions in the network. Each computer is thus able to act as both a client and a server. One example of peer-to-peer architecture is cryptocurrency blockchains.
When designing a multilayered architecture, individual components of a software system are distributed across multiple layers (or tiers), thus increasing the efficiency and flexibility offered by distributed computing. This system architecture can be designed as two-tier, three-tier or n-tier architecture depending on its intended use and is often found in web applications.

In a multilayered architecture, a database request is processed by dividing up the work. The layers are located on different computers that perform specific tasks and act as the client or server.
A service-oriented architecture (SOA) focuses on services and is geared towards addressing the individual needs and processes of company. This allows individual services to be combined into a bespoke business process. For example, an SOA can cover the entire process of “ordering online” which involves the following services: “taking the order”, “credit checks” and “sending the invoice”. Technical components (e.g. servers, databases, etc.) are used as tools but are not the main focus here. In this type of distributed computing, priority is given to ensuring that services are effectively combined, work together well, and are smartly organized with the aim of making business processes as efficient and smooth as possible.
In a service-oriented architecture, extra emphasis is placed on well-defined interfaces that functionally connect the components and increase efficiency. These can also benefit from the system’s flexibility since services can be used in a number of ways in different contexts and reused in business processes. Service-oriented architectures using distributed computing are often based on web services. They are implemented on distributed platforms, such as CORBA, MQSeries, and J2EE.
In order to protect your privacy, the video will not load until you click on it.
The advantages of distributed computing
Distributed computing has many advantages. It allows companies to build an affordable high-performance infrastructure using inexpensive off-the-shelf computers with microprocessors instead of extremely expensive mainframes. Large clusters can even outperform individual supercomputers and handle high-performance computing tasks that are complex and computationally intensive.
Since distributed computing system architectures are comprised of multiple (sometimes redundant) components, it is easier to compensate for the failure of individual components (i.e. increased partition tolerance). Thanks to the high level of task distribution, processes can be outsourced and the computing load can be shared (i.e. load balancing).
Many distributed computing solutions aim to increase flexibility which also usually increases efficiency and cost-effectiveness. To solve specific problems, specialized platforms such as database servers can be integrated. For example, SOA architectures can be used in business fields to create bespoke solutions for optimizing specific business processes. Providers can offer computing resources and infrastructures worldwide, which makes cloud-based work possible. This allows companies to respond to customer demands with scaled and needs-based offers and prices.
Distributed computing’s flexibility also means that temporary idle capacity can be used for particularly ambitious projects. Users and companies can also be flexible in their hardware purchases since they are not restricted to a single manufacturer.
Another major advantage is its scalability. Companies are able to scale quickly and at a moment’s notice or gradually adjust the required computing power to the demand as they grow organically. If you choose to use your own hardware for scaling, you can steadily expand your device fleet in affordable increments.
Despite its many advantages, distributed computing also has some disadvantages, such as the higher cost of implementing and maintaining a complex system architecture. In addition, there are timing and synchronization problems between distributed instances that must be addressed. In terms of partition tolerance, the decentralized approach does have certain advantages over a single processing instance. However, the distributed computing method also gives rise to security problems, such as how data becomes vulnerable to sabotage and hacking when transferred over public networks. Distributed infrastructures are also generally more error-prone since there are more interfaces and potential sources for error at the hardware and software level. Problem and error troubleshooting is also made more difficult by the infrastructure’s complexity.
What is distributed computing used for?
Distributed computing has become an essential basic technology involved in the digitalization of both our private life and work life. The internet and the services it offers would not be possible if it were not for the client-server architectures of distributed systems. Every Google search involves distributed computing with supplier instances around the world working together to generate matching search results. Google Maps and Google Earth also leverage distributed computing for their services.
Distributed computing methods and architectures are also used in email and conferencing systems, airline and hotel reservation systems as well as libraries and navigation systems. In the working world, the primary applications of this technology include automation processes as well as planning, production, and design systems. Social networks, mobile systems, online banking, and online gaming (e.g. multiplayer systems) also use efficient distributed systems.
Additional areas of application for distributed computing include e-learning platforms, artificial intelligence, and e-commerce. Purchases and orders made in online shops are usually carried out by distributed systems. In meteorology, sensor and monitoring systems rely on the computing power of distributed systems to forecast natural disasters. Many digital applications today are based on distributed databases.
Particularly computationally intensive research projects that used to require the use of expensive supercomputers (e.g. the Cray computer) can now be conducted with more cost-effective distributed systems. The volunteer computing project SETI@home has been setting standards in the field of distributed computing since 1999 and still are today in 2020. Countless networked home computers belonging to private individuals have been used to evaluate data from the Arecibo Observatory radio telescope in Puerto Rico and support the University of California, Berkeley in its search for extraterrestrial life.
A unique feature of this project was its resource-saving approach. The analysis software only worked during periods when the user’s computer had nothing to do. After the signal was analyzed, the results were sent back to the headquarters in Berkeley.
On the YouTube channel Education 4u, you can find multiple educational videos that go over the basics of distributed computing.



