Distributed by postgresql что это
7.2.1. Предложение FROM
Предложение FROM образует таблицу из одной или нескольких ссылок на таблицы, разделённых запятыми.
7.2.1.1. Соединённые таблицы
Соединённая таблица — это таблица, полученная из двух других (реальных или производных от них) таблиц в соответствии с правилами соединения конкретного типа. Общий синтаксис описания соединённой таблицы:
Типы соединений Перекрёстное соединение
Примечание
Возможные типы соединений с сопоставлениями строк:
Для каждой строки R1 из T1 в результирующей таблице содержится строка для каждой строки в T2, удовлетворяющей условию соединения с R1. LEFT OUTER JOIN
Сначала выполняется внутреннее соединение (INNER JOIN). Затем в результат добавляются все строки из T1, которым не соответствуют никакие строки в T2, а вместо значений столбцов T2 вставляются NULL. Таким образом, в результирующей таблице всегда будет минимум одна строка для каждой строки из T1. RIGHT OUTER JOIN
Сначала выполняется внутреннее соединение (INNER JOIN). Затем в результат добавляются все строки из T2, которым не соответствуют никакие строки в T1, а вместо значений столбцов T1 вставляются NULL. Это соединение является обратным к левому (LEFT JOIN): в результирующей таблице всегда будет минимум одна строка для каждой строки из T2. FULL OUTER JOIN
Сначала выполняется внутреннее соединение. Затем в результат добавляются все строки из T1, которым не соответствуют никакие строки в T2, а вместо значений столбцов T2 вставляются NULL. И наконец, в результат включаются все строки из T2, которым не соответствуют никакие строки в T1, а вместо значений столбцов T1 вставляются NULL.
Примечание
Предложение USING разумно защищено от изменений в соединяемых отношениях, так как оно связывает только явно перечисленные столбцы. NATURAL считается более рискованным, так как при любом изменении схемы в одном или другом отношении, когда появляются столбцы с совпадающими именами, при соединении будут связываться и эти новые столбцы.
Для наглядности предположим, что у нас есть таблицы t1 :
С ними для разных типов соединений мы получим следующие результаты:
Условие соединения в предложении ON может также содержать выражения, не связанные непосредственно с соединением. Это может быть полезно в некоторых запросах, но не следует использовать это необдуманно. Рассмотрите следующий запрос:
7.2.1.2. Псевдонимы таблиц и столбцов
Таблицам и ссылкам на сложные таблицы в запросе можно дать временное имя, по которому к ним можно будет обращаться в рамках запроса. Такое имя называется псевдонимом таблицы.
Определить псевдоним таблицы можно, написав
Ключевое слово AS является необязательным. Вместо псевдоним здесь может быть любой идентификатор.
Псевдонимы часто применяются для назначения коротких идентификаторов длинным именам таблиц с целью улучшения читаемости запросов. Например:
Псевдоним становится новым именем таблицы в рамках текущего запроса, т. е. после назначения псевдонима использовать исходное имя таблицы в другом месте запроса нельзя. Таким образом, следующий запрос недопустим:
Хотя в основном псевдонимы используются для удобства, они бывают необходимы, когда таблица соединяется сама с собой, например:
Кроме того, псевдонимы обязательно нужно назначать подзапросам (см. Подраздел 7.2.1.3).
В другой форме назначения псевдонима временные имена даются не только таблицам, но и её столбцам:
Если псевдонимов столбцов оказывается меньше, чем фактически столбцов в таблице, остальные столбцы сохраняют свои исходные имена. Эта запись особенно полезна для замкнутых соединений или подзапросов.
7.2.1.3. Подзапросы
Подзапросы, образующие таблицы, должны заключаться в скобки и им обязательно должны назначаться псевдонимы (как описано в Подразделе 7.2.1.2). Например:
Подзапросом может также быть список VALUES :
Такому подзапросу тоже требуется псевдоним. Назначать псевдонимы столбцам списка VALUES не требуется, но вообще это хороший приём. Подробнее это описано в Разделе 7.7.
7.2.1.4. Табличные функции
Если псевдоним_таблицы не указан, в качестве имени таблицы используется имя функции; в случае с конструкцией ROWS FROM() — имя первой функции.
Если псевдонимы столбцов не указаны, то для функции, возвращающей базовый тип данных, именем столбца будет имя функции. Для функций, возвращающих составной тип, имена результирующих столбцов определяются индивидуальными атрибутами типа.
Взгляните на этот пример:
В этом примере используется конструкция ROWS FROM :
7.2.1.5. Подзапросы LATERAL
LATERAL можно использовать так:
Здесь это не очень полезно, так как тот же результат можно получить более простым и привычным способом:
Применять LATERAL имеет смысл в основном, когда для вычисления соединяемых строк необходимо обратиться к столбцам других таблиц. В частности, это полезно, когда нужно передать значение функции, возвращающей набор данных. Например, если предположить, что vertices(polygon) возвращает набор вершин многоугольника, близкие вершины многоугольников из таблицы polygons можно получить так:
Этот запрос можно записать и так:
или переформулировать другими способами. (Как уже упоминалось, в данном примере ключевое слово LATERAL не требуется, но мы добавили его для ясности.)
7.2.2. Предложение WHERE
Примечание
и возможно, даже этому:
Несколько примеров запросов с WHERE :
7.2.3. Предложения GROUP BY и HAVING
Предложение GROUP BY группирует строки таблицы, объединяя их в одну группу при совпадении значений во всех перечисленных столбцах. Порядок, в котором указаны столбцы, не имеет значения. В результате наборы строк с одинаковыми значениями преобразуются в отдельные строки, представляющие все строки группы. Это может быть полезно для устранения избыточности выходных данных и/или для вычисления агрегатных функций, применённых к этим группам. Например:
Здесь sum — агрегатная функция, вычисляющая единственное значение для всей группы. Подробную информацию о существующих агрегатных функциях можно найти в Разделе 9.20.
Подсказка
Группировка без агрегатных выражений по сути выдаёт набор различающихся значений столбцов. Этот же результат можно получить с помощью предложения DISTINCT (см. Подраздел 7.3.3).
Взгляните на следующий пример: в нём вычисляется общая сумма продаж по каждому продукту (а не общая сумма по всем продуктам):
В стандарте SQL GROUP BY может группировать только по столбцам исходной таблицы, но расширение PostgreSQL позволяет использовать в GROUP BY столбцы из списка выборки. Также возможна группировка по выражениям, а не просто именам столбцов.
В предложении HAVING могут использоваться и группирующие выражения, и выражения, не участвующие в группировке (в этом случае это должны быть агрегирующие функции).
И ещё один более реалистичный пример:
В данном примере предложение WHERE выбирает строки по столбцу, не включённому в группировку (выражение истинно только для продаж за последние четыре недели), тогда как предложение HAVING отфильтровывает группы с общей суммой продаж больше 5000. Заметьте, что агрегатные выражения не обязательно должны быть одинаковыми во всех частях запроса.
Ссылки на группирующие столбцы или выражения заменяются в результирующих строках значениями NULL для тех группирующих наборов, в которых эти столбцы отсутствуют. Чтобы можно было понять, результатом какого группирования стала конкретная выходная строка, предназначена функция, описанная в Таблице 9.53.
Для указания двух распространённых видов наборов группирования предусмотрена краткая запись. Предложение формы
представляет заданный список выражений и всех префиксов списка, включая пустой список; то есть оно равнозначно записи
Оно часто применяется для анализа иерархических данных, например, для суммирования зарплаты по отделам, подразделениям и компании в целом.
представляет заданный список и все его возможные подмножества (степень множества). Таким образом, запись
Элементами предложений CUBE и ROLLUP могут быть либо отдельные выражения, либо вложенные списки элементов в скобках. Вложенные списки обрабатываются как атомарные единицы, с которыми формируются отдельные наборы группирования. Например:
Если в одном предложении GROUP BY задаётся несколько элементов группирования, окончательный список наборов группирования образуется как прямое произведение этих элементов. Например:
Примечание
7.2.5. Обработка оконных функций
В настоящее время оконные функции всегда требуют предварительно отсортированных данных, так что результат запроса будет отсортирован согласно тому или иному предложению PARTITION BY / ORDER BY оконных функций. Однако полагаться на это не следует. Если вы хотите, чтобы результаты сортировались определённым образом, явно добавьте предложение ORDER BY на верхнем уровне запроса.
Очень большой Postgres
Так уж случилось, что последнее время приходилось заниматься оптимизацией и масштабированием различных систем. Одной из задач было масштабирование PostgreSQL. Как обычно происходит оптимизация БД? Наверное, в первую очередь смотрят на то, как правильно выбрать оптимальные настройки для работы и какие индексы можно создать. Если обойтись малой кровью не вышло, переходят к наращиванию мощностей сервера, выносу файлов журнала на отдельный диск, балансировке нагрузки, разбиению таблиц на партиции и к всякого рода рефакторингу и перепроектированию модели. И вот уже все идеально настроено, но наступает момент, когда всех этих телодвижения оказывается недостаточно. Что делать дальше? Горизонтальное масштабирование и шардинг данных.

Хочу поделиться опытом развертывания горизонтально масштабируемого кластера на СУБД Postgres-XL.
Postgres-XL — прекрасный инструмент, который позволяет объединить несколько кластеров PostgreSQL таким образом, чтоб они работали как один инстанс БД. Для клиента, который подключается в базе, нет никакой разницы, работает он с единственным инстансом PostgreSQL или с кластером Postgres-XL. Postgres-XL предлагает 2 режима распределения таблиц по кластеру: репликация и шардинг. При репликации все узлы содержат одинаковую копию таблицы, а при шардинге данные равномерно распределяются среди членов кластера. Текущая реализация основана на PostgreSQL-9.2. Так что вам будут доступны почти все фичи версии 9.2.
Терминология
Postgres-XL состоит из трех типов компонентов: глобальный монитор транзакций (GTM ), координатор (coordinator) и узел данных (datanode).
Координатор — центральная часть кластера. Именно с ним взаимодействует клиентское приложение. Управляет пользовательскими сессиями и взаимодействует с GTM и узлами данных. Парсит запросы, строит план выполнения запросов и отсылает его на каждый из компонентов участвующий в запросе, собирает результаты и отсылает их обратно клиенту Координатор не хранит никаких пользовательских данных. Он хранит только служебные данные, чтобы определить как обрабатывать запросы, где находятся узлы данных. При выходе из строя одного из координаторов можно просто переключиться на другой.
Узел данных — место где хранятся пользовательские данные и индексы. Связь с узлами данных осуществляется только через координаторы. Для обеспечения высокой доступности можно подпереть каждый из узлов stanby сервером.
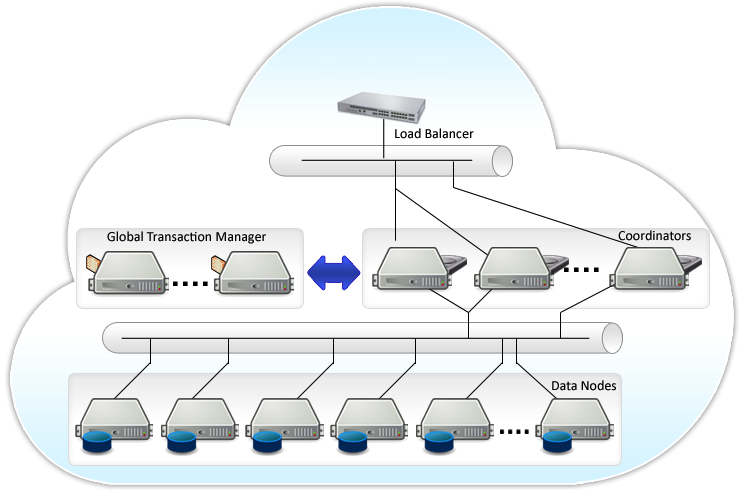
В качестве балансировщика нагрузки можно использовать pgpool-II. О его настройке уже много рассказывалось на хабре, например, тут и тут Хорошей практикой является установка координатора и узла данных на одной машине, так как нам не нужно заботиться о балансировке нагрузке между ними и данные из реплицируемых таблиц можно получить на месте без отправки дополнительного запроса по сети.
Схема тестового кластера

Каждый узел это виртуальная машина со скромным аппаратным обеспечением: MemTotal: 501284 kB, cpu MHz: 2604.
Установка
Тут все стандартно: качаем исходники с офсайта, доставляем зависимости, компилируем. Собирал на Ubuntu server 14.10.
После того как пакет собран заливаем его на узлы кластера и переходим к настройке компонентов.
Настройка GTM
Для обеспечения отказоустойчивости рассмотрим пример с настройкой двух GTM серверов. На обоих серверах создаем рабочий каталог для GTM и инициализируем его.
После чего переходим к настройке конфигов:
В логах наблюдаем записи:
LOG: Started to run as GTM-Active.
LOG: Started to run as GTM-Standby.
Настройка GTM-Proxy
После правки конфига можно запускать:
Настройка координаторов
Настройка узла данных
Для остальных узлов настройка отличается только указанием другого имени.
Теперь правим pg_hba.conf:
Запуск и донастройка
Все готово и можно запускать.
Заходим на координатор:
Запрос показывает как текущей сервер видит наш кластер.
Пример вывода:
Эти настройки неверны и их можно смело удалять.
Создаем новое отображение нашего кластера:
На остальных узлах нужно выполнить тоже самое.
Узел данных не позволит полностью очистить информацию, но ее можно перезаписать:
Тестирование кластера
Теперь все настроено и работает. Создадим несколько тестовых таблиц.
Было создано 4 таблицы с одинаковой структурой, но разной логикой распределения по кластеру.
Данные таблицы test1 будут храниться только на 2х узлах данных — datanode1 и datanode2, а распределятся они будут по алгоритму roundrobin. Остальные таблицы задействуют все узлы. Таблица test2 работает в режиме репликации. Для определения на каком сервере будут храниться данные таблицы test3 используется хеш-функция по полю id, а для определения логики распределения test4 берется модуль по полю status. Попробуем теперь заполнить их:
Запросим теперь эти данные и посмотрим, как работает планировщик
Планировщик сообщает нам о том сколько узлов будет участвовать в запросе. Так как table2 реплицируется на все узлы, то просканирован будет только 1 узел. Кстати неясно по какой логике он выбирается. Логично было бы, чтоб он запрашивал данные с того же узла на котором и координатор.
Подключившись к узлу данных (на порт 25432) можно увидеть как были распределены данные.
Теперь давайте попробуем заполнить таблицы большим объемом данных и сравнить производительность запросов со standalone PostgreSQL.
Запрос в кластере Postgres-XL:
Этот же запрос на сервере с PostgreSQL:
Наблюдаем двукратное увеличение скорости. Не так уж и плохо, если у вас в распоряжении есть достаточное количество машин, то такое масштабирование выглядит довольно перспективно.
Как было замечено в комментариях интересно было бы посмотреть на join таблиц распределенных по нескольким узлам. Давайте попробуем:
Запрос на тех же объемах данных, но на standalone сервере:
5 лайфхаков оптимизации SQL-запросов в Greenplum

Любые процессы, связанные с базой, рано или поздно сталкиваются с проблемами производительности запросов к этой базе.
Хранилище данных Ростелекома построено на Greenplum, большая часть вычислений (transform) производится sql-запросами, которые запускает (либо генерирует и запускает) ETL-механизм. СУБД имеет свои нюансы, существенно влияющие на производительность. Данная статья — попытка выделить наиболее критичные, с точки зрения производительности, аспекты работы с Greenplum и поделиться опытом.
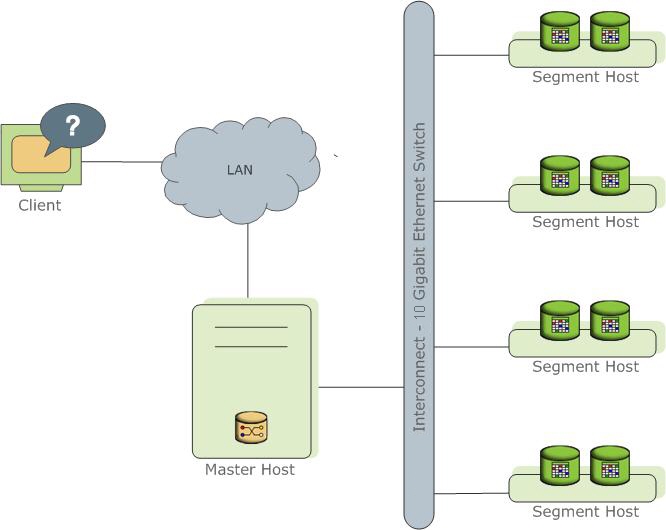
Представляет собой несколько разных экземпляров процесса PostgreSql (инстансы). Один из них является точкой входа для клиента и называется master instance (master), все остальные — Segment instanсe (segment, Независимые инстансы, на каждом из которых хранится своя порция данных). На каждом сервере (segment host) может быть запущено от одного до нескольких сервисов (segment). Делается это для того, чтобы лучше утилизировать ресурсы серверов и в первую очередь процессоры. Мастер хранит метаданные, отвечает за связь клиентов с данными, а также распределяет работу между сегментами.
Далее в статье будет много отсылок к плану запроса. Информацию для Greenplum можно получить тут.
Как писать хорошие запросы на Greenplum (ну или хотя бы не совсем печальные)
Поскольку мы имеем дело с распределенной базой данных, важно не только то, как написан sql-запрос, но и то, как хранятся данные.
1. Распределение (Distribution)
Данные физически хранятся на разных сегментах. Разделять данные по сегментам можно случайным образом или по значению хэш-функции от поля или набора полей.
Синтаксис (при создании таблицы):
Поле дистрибуции должно иметь хорошую селективность и не иметь null-значений (или иметь минимум таких значений), так как записи с такими полями будут распределены на один сегмент, что может привести к перекосам данных.
Тип поля желательно integer. Поле используется для соединения таблиц. Hash join — один из лучших способов соединения таблиц (в плане выполнения запроса), лучше всего работает с этим типом данных.
Для дистрибуции желательно выбирать не больше двух полей, и, конечно, лучше одно, чем два. Дополнительные поля в ключах дистрибуции, во-первых, требуют дополнительное время на хэширование, во-вторых, (в большинстве случаев) потребуют пересылку данных между сегментами, при выполнении джойнов.
Использовать случайное распределение можно, если не получилось подобрать одно или два подходящих поля, а также для небольших табличек. Но надо учесть, что такое распределение лучше всего работает при массовой вставке данных, а не по одной записи. GreenPlum распределяет данные по циклическому алгоритму, причем запускает новый цикл для каждой операции вставки, начиная с первого сегмента, что при частых мелких вставках приводит к перекосам (data skew).
С хорошо подобранным полем распределения все вычисления будут производиться на сегменте, без пересылок данных на другие сегменты. Также для оптимального соединения таблиц (join) одинаковые значения должны быть расположены на одном сегменте.
Хороший ключ распределения: 
Плохо подобранный ключ распределения:
Случайное распределение:
Тип полей, используемых в join, должен быть одинаков во всех таблицах.
Важно: не использовать в качестве полей распределения те, что используются при фильтрации запросов в where, поскольку в этом случае нагрузка при выполнении запроса будет также распределена не равномерно.
2. Секционирование (partitioning)
Секционирование позволяет разделить большие таблицы, например, факты, на логически разделенные куски. Greenplum физически делит вашу таблицу на отдельные таблицы, каждую из которых распределяет по сегментам на основании настроек из п. 1.
Таблицы следует разделять на секции логически, выбирать для этих целей поле, часто используемое в блоке where. В фактовых таблицах это будет период. Таким образом, при правильном обращении к таблице в запросах вы будете работать только с частью всей большой таблицы.
В общем-то, партиционирование достаточно известная тема, и я хотел подчеркнуть, что не стоит выбирать одно и то же поле для партиционирования и распределения. Это приведет к тому, что запрос будет выполняться целиком на одном сегменте.
Пора переходить, собственно, к запросам. Запрос будет выполняться на сегментах по определенному плану:
3. Оптимизатор
В Greenplum есть два оптимизатора, встроенный legacy optimizer и сторонний оптимизатор Orca: GPORCA — Orca — Pivotal Query Optimizer.
Включить GPORCA на запрос:
Как правило, оптимизатор GPORCA лучше встроенного. Он адекватнее работает с подзапросами и CTE (подробнее тут ).
Вынесенное обращение к большой таблице в CTE с максимальной фильтрацией данных (не забываем про partition pruning) и явно указанным списком полей — работает очень хорошо.
Он немного видоизменяет план запроса, например, иначе отображает сканируемые партиции:
Каким бы хорошим оптимизатор ни был, плохо написанный запрос даже Orca не вытянет:
4. Манипуляции с полями в блоке where или условиях соединений (join condition)
Важно помнить, функция, применяемая к полю фильтра или условия джойна, применяется к каждой записи.
В случае с полем партиционирования (например, date_trunc к полю партиционирования — дате), даже GPORCA не умеет корректно отработать в таком случае, отсечение партиций работать не будет.
Обращаю также внимание на отображение партиций. Встроенный оптимизатор будет отображать партиции списком:
С осторожностью применять функции к константам в тех же фильтрах по партиции. Пример — все та же date_trunc:
GPORCA вполне справится с таким финтом и корректно отработает, стандартный оптимизатор уже не справится. Впрочем, сделав явное преобразование типа, можно заставить работать и его:
А если все сделать не так?
5. Motions
Еще один тип операций, который можно наблюдать в плане запроса — motions. Так отмечены движения данных между сегментами:
Данный список не является исчерпывающим и основан преимущественно на опыте автора. Не получилось найти все и сразу в интернете в свое время. Здесь я постарался выявить наиболее критичные факторы, влияющие на производительность запроса, и разобраться, почему и зачем так происходит.
Статья подготовлена командой управления данными «Ростелекома»
Greenplum DB
Продолжаем цикл статей о технологиях, использующихся в работе хранилища данных (Data Warehouse, DWH) нашего банка. В этой статье я постараюсь кратко и немного поверхностно рассказать о Greenplum — СУБД, основанной на postgreSQL, и являющейся ядром нашего DWH. В статье не будут приводиться логи установки, конфиги и прочее — и без этого заметка получилась достаточно объёмной. Вместо этого я расскажу про общую архитектуру СУБД, способы хранения и заливки данных, бекапы, а также перечислю несколько проблем, с которыми мы столкнулись в ходе эксплуатации.
Немного о наших инсталляциях:
1. Общая Архитектура
Итак, Greenplum (GP) – реляционная СУБД, имеющая массово-параллельную (massive parallel processing) архитектуру без разделения ресурсов (Shared Nothing). Для подробного понимания принципов работы GP необходимо обозначить основные термины:
Master instance (он же просто «мастер») – инстанс Postgres, являющийся одновременно координатором и входной точкой для пользователей в кластере;
Master host («сервер-мастер») – сервер, на котором работает Master instance;
Secondary master instance — инстанс Postgres, являющийся резервным мастером, включается в работу в случае недоступности основного мастера (переключение происходит вручную);
Primary segment instance («сегмент») — инстанс Postgres, являющийся одним из сегментов. Именно сегменты непосредственно хранят данные, выполняют с ними операции и отдают результаты мастеру (в общем случае). По сути сегмент – самый обычный инстанс PostgreSQL 8.2.15 с настроенной WAL-репликацией в своё зеркало на другом сервере:
Mirror segment instance («зеркало») — инстанс Postgres, являющийся зеркалом одного из primary сегментов, автоматически принимает на себя роль primary в случае падения оного:
GP поддерживает только 1-to-1 репликацию сегментов: для каждого из primary может быть только одно зеркало.
Segment host («сервер-сегмент») – сервер, на котором работает один или несколько сегментов и/или зеркал.
В общем случае кластер GP состоит из нескольких серверов-сегментов, одного сервера-мастера, и одного сервера-секондари-мастера, соединённых между собой одной или несколькими быстрыми (10g, infiniband) сетями, обычно обособленными (interconnect):

Рис. 1. Состав кластера и сетевое взаимодействие элементов. Здесь — зелёная и красная линии — обособленные сети interconnect, синяя линия — внешняя, клиентская сеть.
Использование нескольких interconnect-сетей позволяет, во-первых, повысить пропускную способность канала взаимодействия сегментов между собой, и во-вторых, обеспечить отказоустойчивость кластера (в случае отказа одной из сетей весь трафик перераспределяется между оставшимися).
При выборе числа серверов-сегментов важно правильно выбрать соотношение кластера «число процессоров/Тб данных» в зависимости от планируемого профиля нагрузки на БД — чем больше процессорных ядер приходится на единицу данных, тем быстрее кластер будет выполнять «тяжёлые» операции, а также работать со сжатыми таблицами.
При выборе числа сегментов в кластере (которое в общем случае к числу серверов никак не привязано) необходимо помнить следующее:
2. Хранение данных
В Greenplum реализуется классическая схема шардирования данных. Каждая таблица представляет из себя N+1 таблиц на всех сегментах кластера, где N – число сегментов (+1 в этом случае — это таблица на мастере, данных в ней нет). На каждом сегменте хранится 1/N строк таблицы. Логика разбиения таблицы на сегменты задаётся ключом (полем) дистрибуции – таким полем, на основе данных которого любую строку можно отнести к одному из сегментов.
Ключ (поле или набор полей) дистрибуции – очень важное понятие в GP. Как было сказано выше, Greenplum работает со скоростью самого медленного сегмента, это означает, что любой перекос в количестве данных (как в рамках одной таблицы, так и в рамках всей базы) между сегментами ведёт к деградации производительности кластера, а также к другим проблемам. Именно поэтому следует тщательно выбирать поле для дистрибуции – распределение количества вхождений значений в нём должно быть как можно более равномерным. Правильно ли вы выбрали ключ дистрибуции вам подскажет служебное поле gp_segment_id, существующее в каждой таблице – оно содержит номер сегмента, на котором хранится конкретная строка.
Важный нюанс: GP не поддерживает UPDATE поля, по которому распределена таблица.
В обоих случаях мы распределили таблицу по полю num_field. В первом случае мы вставили в это поле 20 уникальных значений, и, как видно, GP разложил все строки на разные сегменты. Во втором случае в поле было вставлено 20 одинаковых значений, и все строки были помещены на один сегмент.
В случае, если в таблице нет подходящих полей для использования в качестве ключа дистрибуции, можно воспользоваться случайной дистрибуцией (DISTRIBUTED RANDOMLY). Поле для дистрибуции можно менять в уже созданной таблице, однако после этого её необходимо перераспределить.
Именно по полю дистрибуции Greenplum совершает самые оптимальные JOIN’ы: в случае, если в обоих таблицах поля, по которым совершается JOIN, являются ключами дистрибуции, JOIN выполняется локально на сегменте. Если же это условие не верно, GP придётся или перераспределить обе таблицы по искомому полю, или закинуть одну из таблиц целиком на каждый сегмент (операция BROADCAST) и уже затем джойнить таблицы локально на сегментах.
Как видно, во втором случае в плане запроса появляются два дополнительных шага (по одному для каждой из участвующих в запросе таблиц): Redistribute Motion. По сути, перед выполнением запроса GP перераспределяет обе таблицы по сегментам, используя логику поля num_field_2, а не изначального ключа дистрибуции — поля num_field.
3. Взаимодействие с клиентами
В общем случае всё взаимодействие клиентов с кластером ведётся только через мастер — именно он отвечает клиентам, выдаёт им результат запроса и т.д. Обычные клиенты-пользователи не имеют сетевого доступа к серверам-сегментам.
Для ускорения загрузки данных в кластер используется bulk load — параллельная загрузка данных с/на клиент одновременно с нескольких сегментов. Bulk load возможен только с клиентов, имеющих доступ в интерконнекты. Обычно в роли таких клиентов выступают ETL-сервера и другие системы, которым необходима загрузка большого объёма данных (на рис.1 они обозначены как ETL/Pro client).
Для параллельной загрузки данных на сегменты используется утилита gpfdist. По сути, утилита поднимает на удалённом сервере web-сервер, который предоставляет доступ по протоколам gpfdist и http к указанной папке:
После запуска директория и все файлы в ней становятся доступны обычным wget’ом. Создадим для примера файл в директории, обслуживаемой gpfdist’ом, и обратимся к нему как к обычной таблице.
Также, но с немного другим синтаксисом, создаются внешние web-таблицы. Их особенность заключается в том, что они ссылаются на http протокол, и могут работать с данными, предоставляемыми сторонними web-серверами (apache и тд).
Особняком стоит возможность создавать внешние таблицы на данные, лежащие на распределённой ФС Hadoop (hdfs) – за это в GP ответственна отдельная компонента gphdfs. Для обеспечения её работы на каждый сервер, входящий в состав кластера GP, необходимо установить библиотеки Hadoop и прописать к ним путь в одной из системных переменных базы. Создание внешней таблицы, обращающейся к данным на hdfs, будет выглядеть примерно так:
Здесь hadoop_name_node – адрес хоста неймноды, /tmp/test_file.csv – путь до искомого файла на hdfs.
При обращении к такой таблице Greenplum выясняет у неймноды Hadoop расположение нужных блоков данных на датанодах, к которым затем обращается с серверов-сегментов параллельно. Естественно, все ноды кластера Hadoop должны быть в сетях интерконнекта кластера Greenplum. Такая схема работы позволяет достичь значительного прироста скорости даже по сравнению с gpfdist. Что интересно, логика выбора сегментов для чтения данных с датанод hdfs является весьма нетривиальной. Например, GP может начать тянуть данные со всех датанод только двумя сегмент-серверами, причём при повторном аналогичном запросе схема взаимодействия может поменяться.
Также есть тип внешних таблиц, которые ссылаются на файлы на сегмент-серверах или файл на мастере, а также на результат выполнения команды на сегмент-серверах или на мастере. К слову сказать, старый добрый COPY from никуда не делся и также может использоваться, однако по сравнению с описанным выше работает он медленней.
4. Надёжность и резервирование
4.1. Резервирование мастера
Как было сказано ранее, в кластере GP используется полное резервирование мастера с помощью механизма репликации транзакционных логов, контролируемого специальным агентом (gpsyncagent). При этом автоматическое переключение роли мастера на резервный инстанс не поддерживается. Для переключения на резервный мастер необходимо:
4.2. Резервирование сегментов
Схема резервирования сегментов похожа на таковую для мастера, отличия совсем небольшие. В случае падения одного из сегментов (инстанс postgres перестаёт отвечать мастеру в течении таймаута) сегмент помечается как сбойный, и вместо него автоматически запускается его зеркало (по сути, абсолютно аналогичный инстанс postgres). Репликация данных сегмента в его зеркало происходит на основе WAL (Wright Ahead Log).
Cтоит отметить, что довольно важное место в процессе планирования архитектуры кластера GP занимает вопрос расположения зеркал сегментов на серверах, благо GP даёт полную свободу в вопросе выбора мест расположения сегментов и их зеркал: с помощью специальной карты расположения сегментов их можно разместить на разных серверах, в разных директориях и заставить использовать разные порты. Рассмотрим два граничных варианта:

Вариант 1: все зеркала сегментов, располагающихся на хосте N, находятся на хосте N+1
В таком случае при отказе одного из серверов на сервере-соседе оказывается в два раза больше работающих сегментов. Как было сказано выше, производительность кластера равняется производительности самого медленного из сегментов, а значит, в случае отказа одного сервера производительность базы снижается минимум вдвое.
Однако, такая схема имеет и положительные стороны: при работе с отказавшим сервером уязвимым местом кластера становится только один сервер – тот самый, куда переехали сегменты.
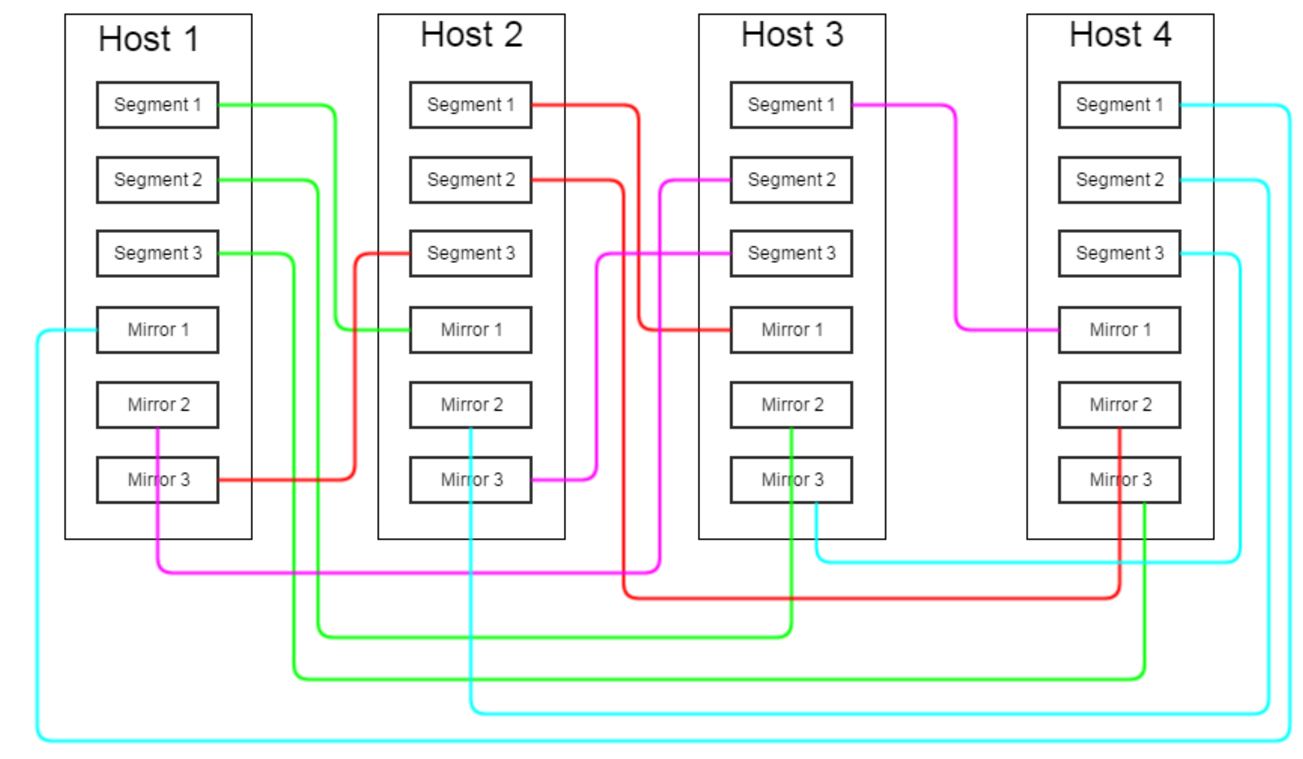
Вариант 2: все зеркала сегментов, располагающихся на хосте N, равномерно «мажутся» на сервера N+1, N+2 … N+M, где M – число сегментов на сервере
В таком случае в случае отказа сервера возросшая нагрузка равномерно распределяется между несколькими серверами, не сильно влияя на общую производительность кластера. Однако, существенно повышается риск выхода из строя всего кластера – достаточно выйти из строя одному из M серверов, соседствующих с вышедшим из строя изначально.
Истина, как это часто бывает, где-то посередине – можно расположить по несколько зеркал сегментов одного сервера на нескольких других серверах, можно объединять сервера в группы отказоустойчивости, и так далее. Оптимальную конфигурацию зеркал следует подбирать исходя из конкретных аппаратных данных кластера, критичности простоя и так далее.
Также в механизме резервирования сегментов есть ещё один нюанс, влияющий на производительность кластера. В случае выхода из строя зеркала одного из сегментов последний переходит в режим change tracking – сегмент логирует все изменения, чтобы затем при восстановлении упавшего зеркала применить их к нему, и получить свежую, консистентную копию данных. Другими словами, при падении зеркала нагрузка, создаваемая на дисковую подсистему сервера сегментом, оставшимся без зеркала, существенно возрастает.
При устранении причины отказа сегмента (аппаратные проблемы, кончившееся место на устройстве хранения и тд) его необходимо вернуть в работу вручную, с помощью специальной утилиты gprecoverseg (даунтайм СУБД не требуется). По факту эта утилита скопирует скопившиеся на сегменте WA-логи на зеркало и поднимет упавший сегмент/зеркало. В случае, если речь идёт о primary-сегменте, изначально он включится в работу как зеркало для своего зеркала, ставшего primary (зеркало и основной сегмент будут работать поменявшись ролями). Для того, чтобы вернуть всё на круги своя, потребуется процедура ребаланса – смены ролей. Такая процедура также не требует даунтайма СУБД, однако на время ребаланса все сессии в БД подвиснут.
В случае, если повреждения упавшего сегмента настолько серьёзны, что простым копированием данных из WA-логов не обойтись, есть возможность использовать полное восстановление упавшего сегмента – в таком случае, по факту, инстанс postgresql будет создан заново, однако за счёт того, что восстановление будет не инкрементальным, процесс восстановления может занять продолжительное время.
5. Производительность
Оценка производительности кластера Greenplum – понятие довольно растяжимое. Я решил начать с тестов, проведённых в этой статье: habrahabr.ru/post/253017, так как рассматриваемые системы во многом похожи. Так как тестируемый кластер значительно (в 8 раз только по числу серверов) мощнее приведённого в статье выше, данных для теста будем брать в 10 раз больше. Если вы бы хотели увидеть в этой статье результаты других кейсов, пишите в комментариях, по возможности постараюсь провести тестирование.
Исходные данные: кластер из 24 сегмент-серверов, каждый сервер – 192 Гб памяти, 40 ядер. Число primary-сегментов в кластере: 96.
Итак, в первом примере мы создаём таблицу с 4-я полями + первичный ключ по одному из полей. Затем мы наполняем таблицу данными (10 000 000 строк) и пробуем выполнить простой SELECT с несколькими условиями. Напоминаю, тест целиком взят из статьи про Postgres-XL.
Как видно, время выполнения запроса составило 175 мс. Теперь попробуем пример с джойном по ключу дистрибуции одной таблицы и по обычному полю другой таблицы.
Время выполнения запроса составило 4.6 секунды. Много это или мало для такого объёма данных – вопрос спорный и лежащий вне этой статьи.
6. Расширение кластера
В жизненном цикле распределённой аналитической БД рано или поздно возникает ситуация, когда объём доступного дискового пространства уже не может вместить всех необходимых данных, а доустановка устройств хранения в имеющиеся сервера либо невозможна, либо слишком дорога и сложна (потребуется, как минимум, расширение существующих разделов). Кроме того, добавление одних лишь дисковых мощностей негативно скажется на соотношении «число процессоров/Тб данных», о котором мы говорили в п.1. Говоря простым языком, в кластер рано или поздно понадобится вводить новые сервера.
Greenplum позволяет добавлять как новые сервера, так и новые сегменты практически без простоя СУБД. Последовательность этого действа примерно такая:
7. Особенности эксплуатации
Как обычно, практика вносит в красивую теорию свои коррективы. Поделюсь некоторыми нюансами эксплуатации, выявленными нами за долгое время использования GP. Сразу оговорюсь, что стандартные нюансы postgresql (необходимость vacuum’а, особенности WAL-репликации) в этот перечень не попали.
8. Заключение
Greenplum — мощный и гибкий инструмент для аналитической обработки больших объёмов данных. Он требует к себе немного другого подхода, чем остальные enterprise-level решения для Data Warehouse (напильник — любимый инструмент администратора GP). Однако при достаточно низком пороге вхождения и большой унифицированности с postgresql Greenplum является сильным игроком на поле Data Warehouse DB.
И, наконец, небольшой бонус — 17 февраля 2015 года Pivotal заявили, что в ближайшем будущем Greenplum станет open source проектом, войдя в Big Data Product Suite.
UPD 28.10.2015. Исходный код БД доступен на github: github.com/greenplum-db/gpdb
Ну и рубрика «срочно в номер»: 12 октября стало известно о покупке компанией Dell корпорации EMC, являющейся владельцем Pivotal.



