Счетчики производительности для дисковой подсистемы
Дисковая подсистема довольно часто становится узким местом в работе приложений, поэтому очень важно уметь диагностировать проблемы с дисками. Одним из основных инструментов для наблюдения за производительностью дисковой подсистемы являются счетчики производительности, о которых и пойдет сегодня речь.
Для наблюдения за дисками можно выбрать два типа объектов:
• Physical Disk — в качестве объекта мониторинга выступает то, что система определяет как физическое устройство. Это может быть как отдельный жесткий диск, так и несколько дисков, объединенных в RAID-массив. Если физический диск разбит на логические разделы (тома), то счетчики выдают суммарное значение для всех томов, находящихся на диске.
• Logical Disk — здесь в качестве объекта мониторинга выступает логический раздел. Perfmon идентифицирует тома по букве диска или точке монтирования (если том примонтирован как папка). Если физический диск разбит на несколько томов, то счетчики будут выдавать значения для каждого выбранного тома отдельно. Возможна и обратная ситуация, когда при использовании динамических дисков том может быть растянут на несколько физических устройств, тогда счетчики покажут значения сразу для всех физических дисков, входящих в состав логического.
Набор счетчиков для физического и логического диска практически идентичен, за небольшим исключением, о котором чуть позже.

Приступим к описанию счетчиков.
%Disk Time
Показывает процент общей загруженности диска. Представляет из себя сумму значений счетчиков %Disk Read Time (процент загруженности диска операциями чтения) и %Disk Write Time (процент загруженности диска операциями записи). Теоретически его значения должны быть в диапазоне от 0 до 100%, однако это верно только для одиночного диска. При использовании RAID-массивов часто можно увидеть значения этого счетчика больше 100%.
%Idle Time
Показывает время простоя диска, т.е. время, в течении которого диск оставался в состоянии покоя, не обрабатывая запросы чтения\записи. В отличии от %Disk Time лежит строго в диапазоне от 100% (полный покой) до 0 (полная загрузка).
Disk Transfers/sec
Основной показатель интенсивности запросов к диску. Показывает общее количество операций ввода\вывода, обработанных (завершенных) диском в течении 1 секунды (Input/Output Operations Per Second, IOPS). Этот счетчик позволяет примерно оценить, насколько нагрузка на диски близка к предельной. Для дисков, работающих в нормальном режиме, можно ориентироваться на следующие значения: 80-160 IOPS для одиночного жесткого диска SATA или SAS, 1800-5000 IOPS для одиночного SSD диска. Для уточнения можно воспользоваться счетчиками Disk Reads/sec (количество обработанных за секунду запросов на чтение) и Disk Writes/sec (количество обработанных за секунду запросов на запись).
Avg. Disk sec/Transfer
Среднее время в секундах, требуемое для выполнения диском одной операции чтения или записи. Складывается из значений Avg. Disk sec/Read (время на выполнение операции чтения) и Avg. Disk sec/Write (время на выполнение операции записи). Для высоконагруженых систем, таких как сервера БД, значение Avg. Disk sec/Transfer не должно превышать 0,1, для рядовых серверов допустимо значение 0,25.
Эти счетчики стоит отметить особо, так как они позволяют точно определить, сколько времени дисковая подсистема потратила на обслуживание операций ввода\вывода, независимо от используемых аппаратных средств.
Avg. Disk Queue Length
Cредняя длина очереди запросов к диску. Отображает количество запросов к диску, ожидающих обработки в течении определенного интервала времени. Нормальным считается очередь не больше 2 для одиночного диска. Если в очереди больше двух запросов, то возможно диск перегружен и не успевает обрабатывать поступающие запросы. Уточнить, с какими именно операциями не справляется диск, можно с помощью счетчиков Avg. Disk Read Queue Length (очередь запросов на чтение) и Avg. Disk Wright Queue Length (очередь запросов на запись).
Значение Avg. Disk Queue Length не измеряется, а рассчитывается по закону Литтла из математической теории очередей. Согласно этому закону, количество запросов, ожидающих обработки, в среднем равняется частоте поступления запросов, умноженной на время обработки запроса. Т.е. в нашем случае Avg. Disk Queue Length = (Disk Transfers/sec) * (Avg. Disk sec/Transfer).
Avg. Disk Queue Length приводится как один из основных счетчиков для определения загруженности дисковой подсистемы, однако для его адекватной оценки необходимо точно представлять физическую структуру системы хранения. К примеру, для одиночного жесткого диска критическим считается значение больше 2, а если диск располагается на RAID-массиве из 4-х дисков, то волноваться стоит при значении больше 4*2=8.
Current Disk Queue Length
Текущая длина очереди запросов к диску. Показывает количество запросов, ожидающих обработки в данный конкретный момент. По сути это мгновенное значение (срез) текущей очереди запросов.
Disk Bytes/sec
Средняя скорость обмена данными с диском, или скорость чтения\записи. Показывает общее количество байт, отправленных на диск (запись) и с диска (чтение) в течении одной секунды, тем самым позволяя оценить пропускную способность дисковой системы. Складывается из значений Disk Read Bytes/sec (скорость чтения) и Disk Write Bytes/sec (скорость записи). Предельные значения сильно зависят от типа диска: к примеру для одиночного жесткого диска максимальная скорость чтения\записи лежит в пределах 160-250Mb/s, для одиночного SSD — около 550-600Mb/s.
Avg. Disk Bytes/Transfer
Среднее количество байт, передаваемое при выполнении одной операции чтения\записи. Чем больше размер передаваемых блоков, тем меньше нагрузка на диск. При нормальной работе этот параметр должен быть больше 20Kb, значения меньше говорят о большом количестве мелких запросов, т.е. о неэффективном использовании дисковой системы. Более точную информацию можно получить из значений счетчиков Avg. Disk Bytes/Read (количество байт, передаваемое при выполнении одной операции чтения) и Avg. Disk Bytes/Write (количество байт, передаваемое при выполнении одной операции записи).
Split IO/Sec
Частота разделения операций ввода\вывода на несколько операций. Значение, отличное от нуля показывает, что запрашиваются слишком большие блоки данных, которые не могут быть переданы за одну операцию. Это может быть следствием сильной фрагментации диска.
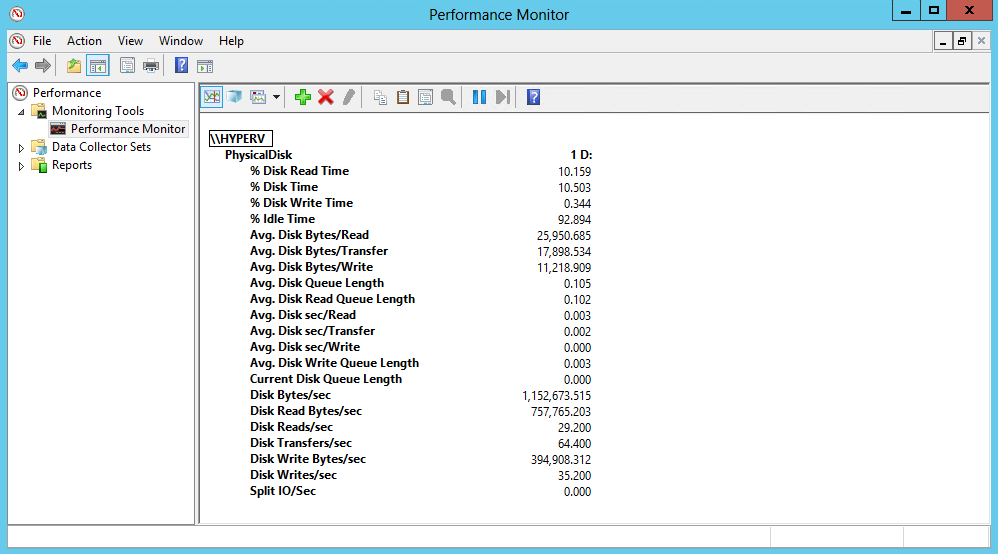
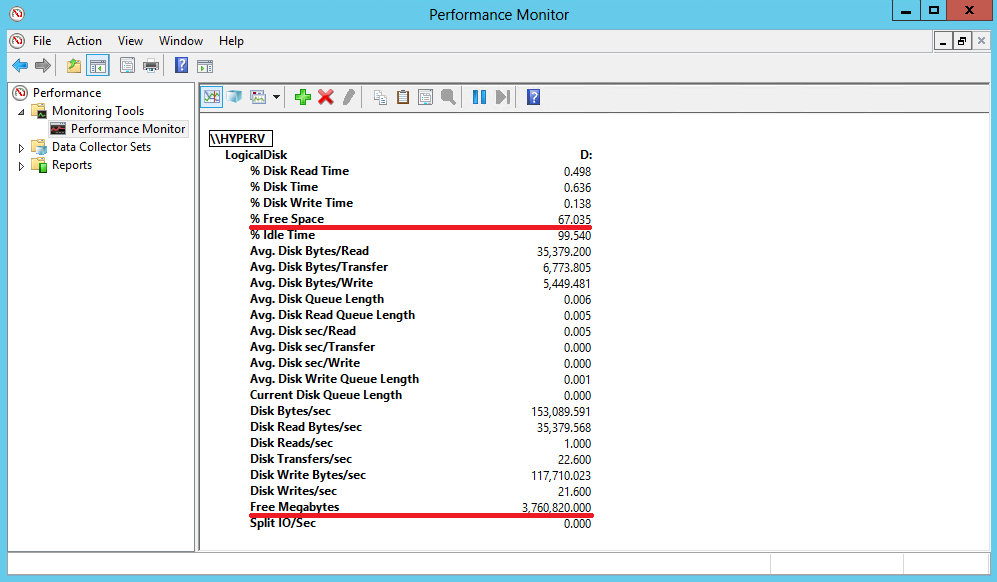
И только для объектов Logical Disk есть еще два счетчика, позволяющие определить наличие свободного места на диске.
%Free Space
Объем свободного дискового пространства на выбранном логическом диске, в процентах.
Free Megabytes
Объем свободного пространства на логическом диске, в мегабайтах.
Заключение
Для того, чтобы адекватно оценить полученные данные, необходимо точно представлять физическую структуру системы хранения. В первую очередь важен тип используемых дисков (HDD, SSD), интерфейс (SATA, SAS, FC, PCIe), скорость вращения HDD (7200, 10k, 15k). При использовании RAID-массивов нужно знать тип массива (0, 1, 5, 10 и т.д.) и количество дисков в массиве.
И еще, при оценке производительности дисковой подсистемы обязательно надо учитывать тип нагрузки, создаваемой приложениями. В идеале есть два типа дисковых нагрузок:
1. Большое количество случайных операций чтения\записи, данные обрабатываются небольшими блоками. Этот тип нагрузки характерен для серверов баз данных. При таком типе нагрузки наиболее важным параметром является количество IOPS-ов. Основные счетчики — Disk Transfers/sec, Avg. Disk sec/Transfer и конечно Avg. Disk Queue Length.
2. Последовательное чтение\запись больших блоков данных. Такая нагрузка характерна, к примеру, для серверов потокового видео. В этом случае наиболее важна пропускная способность дисковой системы, которую показывает Disk Bytes/sec.
Настройка сборки данных в Performance Monitor Windows Server
Каждый опытный сисадмин знает, что лучший показатель ухудшения быстродействия 1С, это главный бухгалтер, движущийся в сторону ИТ отдела со скоростью, превышающей 1.1 м/с. Но только мудрейшие из них настраивают сбор счетчиков, чтобы эта встреча не застала их врасплох. Об этом и поговорим под катом…

Эпиграф:
Существуют две причины, по которым может тормозить компьютер:
1. Вирус.
2. Антивирус.
© советы бывалых сисадминов
Не ошибусь, если скажу, что каждый офисный админ сталкивался с вопросом: Почему тормозит 1С?
И опять же не ошибусь, если первое что он(а) при этом сделает, это откроет диспетчер задач.
Более продвинутые, конечно настроят сбор счетчиков Performance Monitor (Zabbix в данном контексте примерно то же самое).
Тем более, что инструкций, чек-листов по настройке более чем достаточно. Это то и пугает.
Попробую предложить вам обзор основных и свою компиляцию.
Название счетчиков отличается не только в зависимости от языка операционной системы, но и от ее редакции.
Добавим к этому видение и ошибки авторов публикаций и поймем, что простой копипаст может не сработать.
В случае же perfmon это усугубится тем, что никаких ошибок при создании счетчиков в командной строке вам выдано не будет, просто они не будут собираться.
Для того, чтобы увидеть список всех счетчиков производительности, имеющихся на текущем компьютере нужно в командной строке выполнить
\PhysicalDisk(_Total)\Current Disk Queue Length
\PhysicalDisk(*)\Current Disk Queue Length
Рекомендуемый мной путь, это создать bat файл из 3 строк.
А в файл assembled.txt добавлять названия счетчиков. По одному на строку. Рабочий и рекомендуемый мной пример для Windows Server 2012 R2 ENG будет внизу.
\Processor(_Total)\% Processor Time
\Processor(_Total)\% User Time
\Processor(_Total)\% Privileged Time
\Memory\Available MBytes
\Memory\Pages/sec
\Memory\% Committed Bytes In Use
\Paging File(*)\% Usage
\System\Context Switches/sec
\System\Processor Queue Length
\System\Processes
\System\Threads
\PhysicalDisk(_Total)\Current Disk Queue Length
\PhysicalDisk(*)\Current Disk Queue Length
\PhysicalDisk(_Total)\Avg. Disk sec/Read
\PhysicalDisk(_Total)\Avg. Disk sec/Write
\Network interface(_Total)\Bytes Total/sec
\Network interface(_Total)\Current Bandwidth
\Process(1cv8)\% Processor Time
\Process(1cv8)\Private Bytes
\Process(1cv8)\Virtual Bytes
\Process(ragent)\% Processor Time
\Process(ragent)\Private Bytes
\Process(ragent)\Virtual Bytes
\Process(rphost)\% Processor Time
\Process(rphost)\Private Bytes
\Process(rphost)\Virtual Bytes
\Process(rmngr)\% Processor Time
\Process(rmngr)\Private Bytes
\Process(rmngr)\Virtual Bytes
\Process(sqlservr)\% Processor Time
\Process(sqlservr)\Private Bytes
\Process(sqlservr)\Virtual Bytes
\SQLServer:General Statistics\User Connections
\SQLServer:General Statistics\Processes blocked
\SQLServer:Buffer Manager\Buffer cache hit ratio
\SQLServer:Buffer Manager\Page life expectancy
\SQLServer:SQL Statistics\Batch Requests/sec
\SQLServer:SQL Statistics\SQL Compilations/sec
\SQLServer:SQL Statistics\SQL Re-Compilations/sec
\SQLServer:Access Methods\Page Splits/sec
\SQLServer:Access Methods\Forwarded Records/sec
\SQLServer:Access Methods\Full Scans/sec
\SQLServer:Memory Manager\Target Server Memory (KB)
\SQLServer:Memory Manager\Total Server Memory (KB)
\SQLServer:Memory Manager\Free Memory (KB)
\SQLServer:Databases(_Total)\Transactions/sec
\SQLServer:Databases(*)\Transactions/sec
Собственно торопыжки могут дальше и не читать. Да они уже и не читают.
С остальными разберемся с рекомендациями лучших собаководов
Начнем с изучения советов самого вендора: microsoft.com
Публикация Windows VM health
| Группа оборудования | Название счетчика |
| Logical disk | |
| Logical disk average disk seconds per transfer | |
| Logical disk average disk seconds per write | |
| Logical disk current disk queue length | |
| Logical disk free space megabytes low | |
| Logical disk percent idle time | |
| Logical disk free space percent low | |
| File system error or corruption | |
| Operating system | |
| Memory available megabytes | |
| Memory free system page table entries | |
| Memory pages per second | |
| Memory percent committed memory in use | |
| Total CPU utilization percentage | |
| DHCP Client service health | |
| DNS Client Service Health | |
| Event Log service health | |
| Windows Firewall service health | |
| RPC service health | |
| Server service health | |
| Windows Remote Management (WinRM) service health | |
| Network adapter | |
| Network adapter connection health | |
| Network adapter percent bandwidth used read | |
| Network adapter percent bandwidth used total | |
| Network adapter percent bandwidth used write | |
| Disk | |
| Disk current disk queue length | |
| Disk percent idle time | |
| Disk average seconds per read | |
| Disk average disk seconds per transfer | |
| Disk average disk seconds per write |
Используя этот вариант вы точно не ошибетесь, но в нем присутствуют счетчики не совсем нужные для мониторинга именно сервера 1С.
Далее, а скорее и выше, в моем топе вариантов идет рекомендация от Евгения Валерьевича Филиппова
Настольная книга 1С: Эксперта по технологическим вопросам. Издание 2
Список небольшой, но все по делу и видно, что автор его использовал в работе.
| Группа оборудования | Счетчик | Предельные значения |
| Logical disk | ||
| Operating system | ||
| \Memory(_ Total)\%% Committed Bytes In Use | Не должен превышать размер оперативной памяти. | |
| \Memory(_Total)\Available Bytes | Приближение к нулю свидетельствует о недостатке оперативной памяти. | |
| \Memory(_Total)\Pages/sec | ||
| \Processor(_Total)\%% Processor Time | Не более 70 % в течение длительного времени. | |
| \System(_Total)\Processor Queue Length | Не более 2 * количество ядер процессоров в течение длительного времени | |
| Network adapter | ||
| \Network lnterface(*)\Bytes Total/ sec | ||
| Disk | ||
| \PhysicalDisk(*)\Avg. Disk Queue Length | Не более 2 * количество дисков, работающих параллельно | |
| \PhysicalDisk(_Total)\Avg. Disk Queue Length | ||
| \PhysicalDisk(_Total)\Avg. Disk Sec/Read | При работе с дисковым кешем нормальное время на чтение или запись обычно составляет менее 10 мс. В случае работы с дисками время на чтение или запись не должно превышать 50-200 мс. | |
| \PhysicalDisk(_Total)\Avg. Disk Sec/Write |
Список книги Методическое пособие по эксплуатации крупных информационных систем на платформе «1С: Предприятие 8»
А. Асатрян, А. Голиков, А. Морозов, Д. Соломатин, Ю.Федоров
еще лаконичнее, в него добавлен мониторинг 1cv8, ragent, rphost, rmngr его я вынесу в отдельный список, потому что он может и наверное не помешает при любом варианте, кроме разнесенных SQL и 1С серверов.
«\Process(«1cv8*»)\%%Processor Time»
«\Process(«1cv8*»)\Private Bytes»
«\Process(«1cv8*»)\Virtual Bytes»
«\Process(«ragent*»)\%%Processor Time»
«\Process(«ragent*»)\Private Bytes»
«\Process(«ragent*»)\Virtual Bytes»
«\Process(«rphost*»)\%%Processor Time»
«\Process(«rphost*»)\Private Bytes»
«\Process(«rphost*»)\Virtual Bytes»
«\Process(«rmngr*»)\%%Processor Time»
«\Process(«rmngr*»)\Private Bytes»
«\Process(«rmngr*»)\Virtual Bytes»
или как вариант без разбиения
\Process(1cv8)\% Processor Time
\Process(1cv8)\Private Bytes
\Process(1cv8)\Virtual Bytes
\Process(ragent)\% Processor Time
\Process(ragent)\Private Bytes
\Process(ragent)\Virtual Bytes
\Process(rphost)\% Processor Time
\Process(rphost)\Private Bytes
\Process(rphost)\Virtual Bytes
\Process(rmngr)\% Processor Time
\Process(rmngr)\Private Bytes
\Process(rmngr)\Virtual Bytes
\Process(sqlservr)\% Processor Time
\Process(sqlservr)\Private Bytes
\Process(sqlservr)\Virtual Bytes
Список счетчиков оборудования.
| Группа оборудования | Счетчик |
| Logical disk | |
| \LogicalDisk(_Total)\Free Megabytes | |
| Operating system | |
| \Memory(_Total)\Pages/sec | |
| \Memory\Available Mbytes | |
| \Processor(_Total)\%% Processor Time | |
| \System(_Total)\Processor Queue Length | |
| Network adapter | |
| \Network lnterface(*)\Bytes Total/ sec | |
| Disk | |
| \PhysicalDisk(*)\Avg. Disk Bytes/Read | |
| \PhysicalDisk(*)\Avg. Disk Bytes/Write | |
| \PhysicalDisk(*)\Avg. Disk Queue Length | |
| \PhysicalDisk(_Total)\Avg. Disk Queue Length |
Далее идет статья с ИТС Анализ загруженности оборудования для Windows Елена Скворцова и ее полная копия на kb у кого есть туда доступ, в ней подробно и с картинками описан весь процесс настройки. Для первой настройки это очень полезно.
При всей полезности и доступности статьи не покидает ощущение, что ее писали как знаменитое письмо Матроскина: «ваш сын дядя Шарик», разные люди. Например текст не совпадает с картинками, для некоторых счетчиков описаны пороговые значения, но в списке их нет, некоторые счетчики в списке двоятся, из-за этого не получится копипастом в командной строке запустить logman. Это как раз начинающих немного обескураживает.

Лирическое отступление: Не прошло и месяца с регионального тура конкурса ИТС, где один из вопросов был именно так составлен, в коде вариант ответа один, а в картинке и математически верный совсем другой. Организаторы опирались именно на корректность кода. Хотя понятно, код проверяют слабо, во всех научных книгах об этом предупреждают заранее.
| Группа оборудования | Счетчик | Предельные значения |
| Logical disk | ||
| \LogicalDisk(_Total)\% Free Space | ||
| Operating system | ||
| \Memory\Available Mbytes | ||
| \Processor(_Total)\% Idle Time | ||
| \Processor(_Total)\% Processor Time | Не более 70% в течение длительного времени | |
| \Processor(_Total)\% User Time | ||
| \Processor(_Total)\Interrupts/sec | ||
| \System\Context Switches/sec | ||
| \System\File Read Bytes/sec | ||
| \System\File Write Bytes/sec | ||
| \System\Processes | ||
| \System\Processor Queue Length | Не более 2 * количество ядер процессоров в течение длительного времени | |
| \System\Threads | ||
| Memory Pages/sec Интенсивность обмена между дисковой подсистемой и оперативной памятью Среднее: около 0 Максимальное: не более 20 | ||
| Network adapter | Не более 65% от пропускной способности сетевого адаптера | |
| Disk | ||
| \PhysicalDisk(_Total)\Avg. Disk Queue Length | Не более 2 * количество дисков, работающих параллельно | |
| \PhysicalDisk(_Total)\Avg. Disk Sec/Read | ||
| \PhysicalDisk(_Total)\Avg. Disk Sec/Write |
Понятно, что про 1С они и слыхом не слыхивали, но то, что серверов они видели на порядок более, это факт.
| Группа оборудования | Счетчик | Предельные значения |
| Logical disk | ||
| Operating system | ||
| Memory: Available Bytes | Этот показатель должен быть выше 25% установленной памяти. Обратите внимание, что это значение является динамическим и отображает только последнее проверенное значение, а не среднее | |
| Memory: Cache Faults /sec | ||
| Memory: Page Faults /sec | ||
| Memory: Page Input /sec | не должно превышать 15 | |
| Memory: Page Reads /sec | постоянные значения выше 5 указывают на более пристальный взгляд на Физический диск | |
| Memory: Pages/sec | В среднем 20 или меньше — это нормально | |
| Paging File: % Usage | ||
| Processor: % Processor Time_Total | Не превышать 80% в течение 10+ минут в течение 24 часов | |
| System: Processor Queue Length | Не должно превышать 2 на процессор в течение 10+ минут в течение 24 часов. Например, если сервер содержит 4 процессора, количество не должно превышать 8 за 10-минутный период. | |
| Network adapter | ||
| Network Interface: Bytes Received/sec | ||
| Network Interface: Bytes Sent/sec | ||
| Network Interface: Bytes/sec | ||
| Network Interface: Output Queue Length | всегда должна быть 0, но может достигать 2 на мгновение | |
| Disk | ||
| Physical Disk: Disk Writes/sec | ||
| Physical Disk: Disk Reads/sec | должно быть меньше 20 мс, если более 50 мс указывает на серьезное узкое место | |
| Physical Disk: Avg. Disk Write Queue Length | Длина очереди диска (не должна быть больше, чем количество шпинделей плюс 2) | |
| Physical Disk: Avg. Disk Write /sec | ||
| Physical Disk: Avg. Disk Read Queue Length | ||
| Physical Disk: Avg. Disk Read /sec | ||
| Physical Disk: Avg. Disk Queue Length | Превышение 2 на диск (3 дисковых массива = 6) на 10+ минут в течение 24 часов указывает на узкое место диска. |
| Группа оборудования | Счетчик | Предельные значения |
| Logical disk | ||
| Logical Disk: Avg. Disk Queue Length | Из-за изменений в технологиях, таких как виртуализация, технология дисков и контроллеров, SAN и многое другое, этот счетчик больше не является хорошим индикатором узких мест ввода-вывода. Лучшим показателем узких мест ввода-вывода является Disk avg. время чтения и средн. время записи | |
| Logical Disk: Avg. Disk sec/Read | Для дисков с файлами MDF и NDF и загрузкой OLTP средняя задержка чтения в идеале должна быть ниже 20 мс. Для дисков с нагрузкой OLAP приемлемой считается задержка до 30 мс. Для дисков с файлами LDF задержка в идеале должна составлять 5 мс или меньше. В общем, все, что превышает 50 мс, является медленным и предполагает потенциально серьезное узкое место ввода-вывода. | |
| Logical Disk: Avg. Disk sec/Write | Для дисков с файлами MDF и NDF и загрузкой OLTP средняя задержка записи в идеале должна быть ниже 20 мс. Для дисков с нагрузкой OLAP приемлемой считается задержка до 30 мс. Для дисков с файлами LDF задержка в идеале должна составлять 5 мс или меньше. В общем, все, что превышает 50 мс, является медленным и предполагает потенциально серьезное узкое место ввода-вывода. | |
| Logical Disk: Disk Transfers/sec | Число передач диска в секунду не должно превышать пропускную способность дисковой подсистемы IOPS | |
| LogicalDisk: Free Megabytes | ||
| Operating system | ||
| Memory: Pages/sec | Если количество страниц памяти в секунду превышает 1000, а количество доступных байтов меньше 100 МБ на постоянной основе, это явный признак нехватки памяти | |
| Memory: Available Bytes | ||
| Processor: % Processor Time (_Total) | Если время « Машина: процессор» превышает в среднем 80% в течение длительного времени (пять минут или более), то в это время существует узкое место ЦП | |
| System: Processor Queue Length | Число, превышающее 10 потоков на процессор, указывает на узкое место ЦП | |
| Network adapter | ||
| Network Interface: Bytes Received/sec | 8 * ((Сетевой интерфейс: получено байтов / сек) + (Сетевой интерфейс: отправлено байтов / сек)) / (Сетевой интерфейс: текущая пропускная способность) * 100 | |
| Network Interface: Bytes Sent/sec | ||
| Disk |
Что касается, счетчиков для MS SQL, то мой список был в начале публикации.
Вариантов невероятное множество как и экспертов (не факт, что сейчас один из них не съехал тихо под стол при виде его).
Впрочем, настоящий скульный админ никогда не покажет своего отношения, максимум поиграет бровями и пойдет слушать музыку сервера.
Желающие могут провести пару зимних (летних) вечеров разбирая полный список.
— Штурман, приборы!
— Четырнадцать.
— Что четырнадцать?
— А что, приборы!?
©www.anekdot.ru
Бдительный читатель скажет: Мало собрать счетчики оборудования, надо их еще и проанализировать.
А я покажу ему вот эту таблицу.
Техническое отступление: Хотя ней выражено мнение уважаемых экспертов, относиться к нему надо с пониманием.
Например, многие вспомнят времена, когда они умоляли директора докупить планку 32 Мб в сервер упомянутой выше бухгалтерии. То же касается и скорости дисков. Эти значения устаревают.
Что означает словосочетание «Предельные значения». То что их превышение требует вашего внимания и сервер работает не совсем штатно по мнению собравшихся. Не более того. Более того, может быть как раз для вашего варианта работы это нормально.



