Тестирование IOPS дисков в Linux
В этой статье рассмотрим способы тестирования производительности IOPS дисков или дискового массива в Linux. IOPS (input/output operations per second) – количество операций ввода-вывода, выполняемые системой хранения данных за одну секунду (это может быть как один диск, RAID массив или LUN на системе хранения). Условно IOPS можно считать количество блоков, которые успевает считаться или записаться на носитель.
Для большинства дисков производители указывают номинальные значения IOPS, но такие значение на практике не гарантируются. Для понимания производительности вашей дисковой подсистемы перед запуском проекта желательно получить значения IOPS.
Установка утилиты fio для тестирования IOPS в Linux
Для замера производительности IOPS дисков в Linux можно использовать утилиту fio (утилита доступна для CentOS в репозитории EPEL). Соотвественно для установки fio в RHEL, CentOS используется пакетный менеджер yum (dnf):
Либо apt-get в Debian, Ubuntu :
# apt-get install fio
Затем вам нужно определить диски для тестирования. Тестирование выполняется путев выполнения операций записи/чтения в той директории, в которую примонтирован диск или LUN.
Измерение производительности дисков в IOPS с помощью fio
Выполним несколько видов тестирования производительности IOPS диска в различных сценариях нагрузки на диск (реждим тестирования, который нужон выбрать зависит от логики размещенного приложения и общей архитектуры проекта).
Тест случайных операций на чтение/запись
При запуске такого теста, будет создан файл размером 8 Гб. Затем утилита fio выполнит чтение/запись блока 4КБ (стандартный размер блока) с разделением на 75/25% по количеству операций чтения и записи и замерит производительность. Команда выглядит следующим образом:
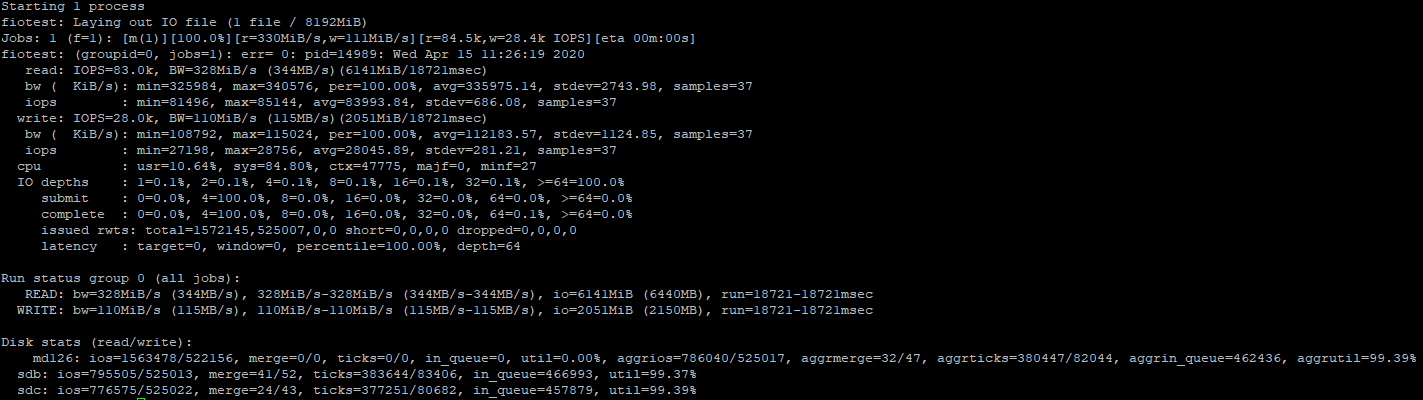
Первую проверку я запустил на массиве из двух SSD дисков и результаты получились хорошие:
110MiB/s, 28000 IOPS
Так как мы запустили тест на чтение/запись, показатели по отдельным проверкам, будут чуть выше.
Для сравнения, я замерил скорость на обычном SATA диске:
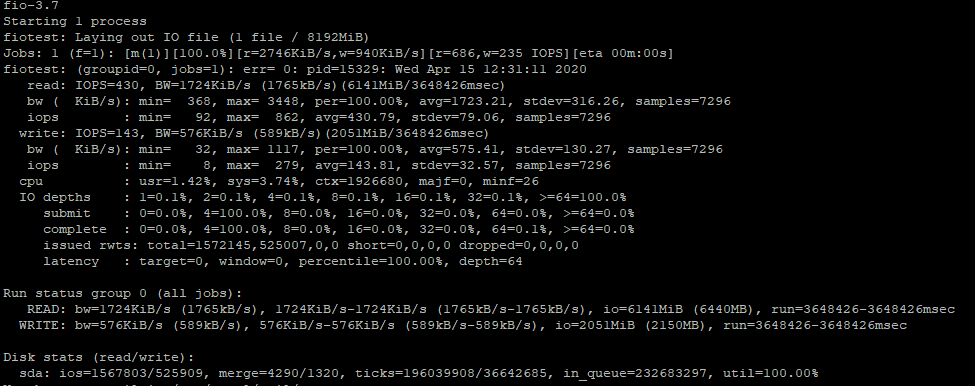
Для HDD диска результаты, конечно гораздо хуже, чем для SSD.
Тест случайных операций на чтение
Чтобы замерить производительность дисков только для случайных операций на чтение, нужно выполнить следующую команду:
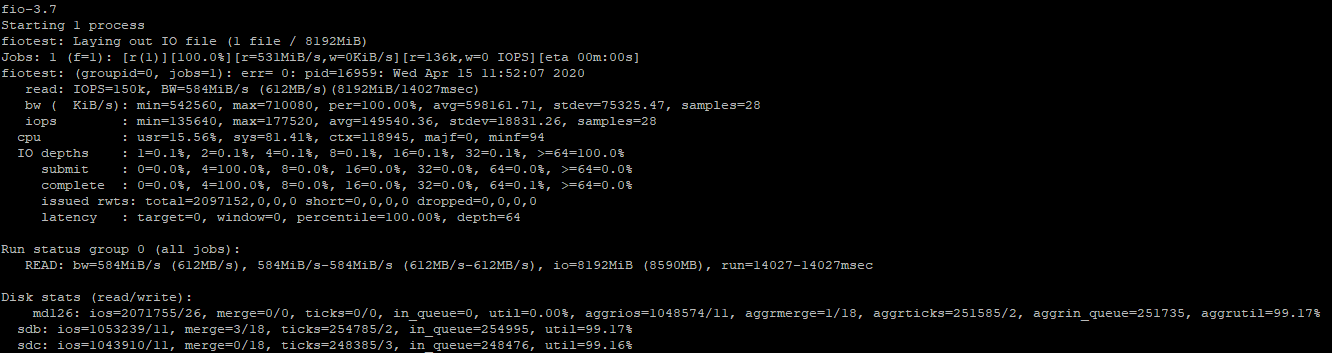
Как ранее я уже говорил, скорость по отдельным замерам будет выше:
Если запустить тест только на чтение, разница со смешанным тестом достигает (200-250 MiB/s и 67000 IOPS), что достаточно ощутимо.
Тест случайных операций на запись
Для замера производительности диска для случайных операций записи, выполните команду:
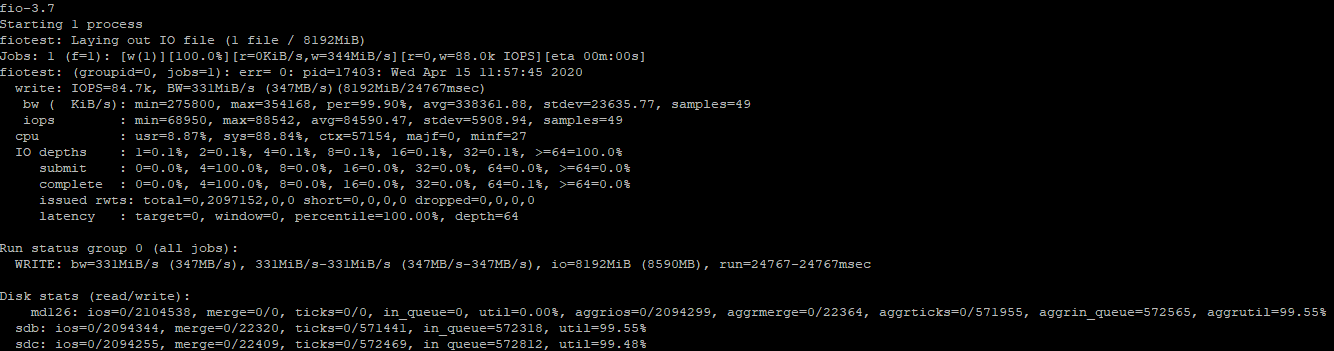
Производительность операций записи на хороших SSD дисках тоже очень высокая. Как и в случае с чтением, разница со смешанным тестом достигает 200-250 MiB/s, а в IOPS 56000.
Если опираться на официальную документацию по дискам от производителя (это SSD диски от Intel), можно смело сказать, что в данном случае они не обманули.
Тестирование производительности дисков с помощью файлов.
Утилита fio позволяет проверять диски не только с помощью интерактивного запуска команд, но и запускать заранее подготовленные конфигурационные файлы для тестов. Чтобы воспользоваться данным вариантом, создайте файл:
И добавьте в него содержимое:
Теперь запустите тест:
Данный тест замерит скорость чтения диска. Чтобы выполнить проверку производительности для операций записи, используйте такой конфиг:
Проверка latency диска с помощью ioping
Помимо IOPS есть еще один важный параметр, характеризующий качество вашей дисковой подсистемы – latency. Latency – это время задержки выполнения запроса ввода/вывода и характеризуют время доступа к системе хранения (измеряется в миллисекундах). Чем выше latency, тем больше приходится ждать вашему приложения данных от дисковой подсистемы. Для типовых систем хранения значения latency более 20 мс считаются плохими.
Для проверки latency диска используется утилита ioping:
# apt-get install ioping
Запустите тест latency для диска (выполняется 20 запросов):
Среднее значение 298.7 us (микросекунд), т.е. средняя latency диска в нашем случае 0.3 ms, что очень хорошо.
Таким образом, вы можете провести нагрузочное тестирование дисковой подсистемы на вашем сервере до запуска проекта и получить максимальную производительность. Конечно такой тест не дает гарантий, что дисковый массив или диск будет постоянно гарантировать такую производительность, но на начальном этапе это тест, который обязательно нужно выполнить. Методика тестирования IOPS в Windows описана в этой статье.
Измерение производительности и IOPS жестких дисков и СХД в Windows
Одной из основных метрик, позволяющих оценить производительность существующей или проектируемой системы хранения данных является IOPS (Input/Output Operations Per Second — количество операций ввода/вывода). Говоря простым языком, IOPS – этой количество блоков, которое успевает считаться или записаться на носитель или файловую систему в единицу времени. Чем это число больше – тем больше производительность данной дисковой подсистемы (откровенно говоря, само по себе значение IOPS стоит рассматривать в комплексе с другими характеристиками СХД, таким как средняя задержка, пропускная способность и т.п.).
В этой статье мы рассмотрим несколько способов измерения производительности используемой системы хранения данных в IOPS под Windows (локальный жесткий, SSD диск, сетевая папка SMB, CSV том или LUN на СХД в сети SAN).
Счетчики производительности дисковой подсистемы Windows
Вы можете оценить текущий уровень нагрузки на дисковую подсистему с помощью встроенных счетчиков производительности Windows из Performance Monitor. Чтобы собрать данные по этим счетчикам:
Как интерпретировать результаты производительности дисков в Perfmon? Для быстрого анализа производительности дисковой подсистемы необходимо посмотреть на значения как минимум следующих 5 счетчиков.
Тестирование IOPS в Windows с помощью DiskSpd
Для генерации нагрузки на дисковую подсистему и измерения ее производительности Microsoft рекомендует использовать утилиту DiskSpd (https://aka.ms/diskspd). Эта консольная утилита, которая в несколько потоков может осуществлять операции I/O с указанным таргетом. Я довольно часто использую эту утилиту чтобы замерить производительность СХД в IOPS и получить максимальную скорость чтения/записи c данного сервера (можно конечно измерить производительность и со стороны СХД, в этом случае diskspd будет использоваться для генерации нагрузки).
Утилита не требует установки, просто скачайте и распакуйте архив на локальный диск. Для x64 битных систем используйте версию diskspd.exe из каталога amd64fre.
Я использую такую команду для тестирования диска:
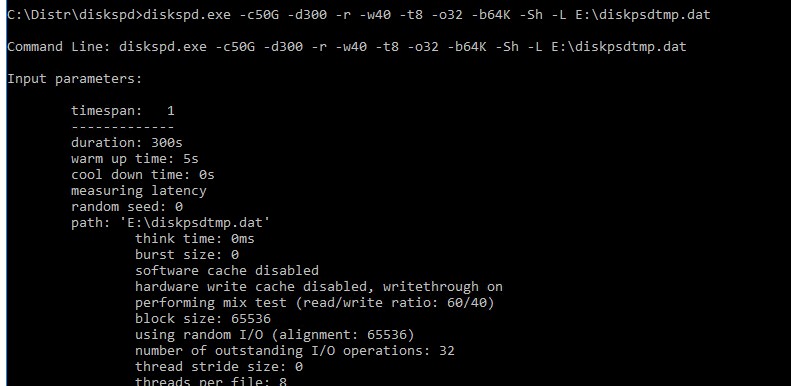
После окончания стресс-теста из полученных таблиц можно получить средние значения производительности.
Например, в моем тесте получены следующие общие данные про производительности (Total IO):
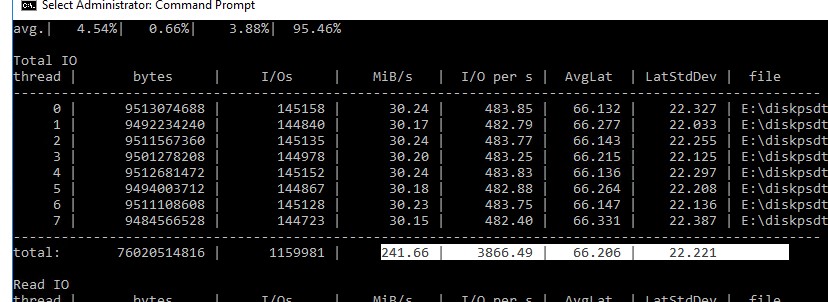
Можно получить отдельные значения только по операциям чтения (секция Read IO ) или записи (секция Write IO ).
Протестировав с помощью diskspd несколько дисков или LUN на СХД, вы сможете сравнить их или выбрать массив с нужной производительностью под свои задачи.
Как получить IOPS и производительность дисковой подсистемы с помощью PowerShell?
Недавно мне на глаза попался PowerShell скрипт (автор Microsoft MVP, Mikael Nystrom), являющийся по сути надстройкой над утилитой SQLIO.exe (набора тестов для расчета производительности файлового хранилища).
Итак, скачайте архив содержащий 2 файла: SQLIO.exe и DiskPerformance.ps1 (disk-perf-iops.ZIP — 73Кб) и распакуйте архив в произвольный каталог.
Пример запуска PowerShell скрипта для определения IOPS:
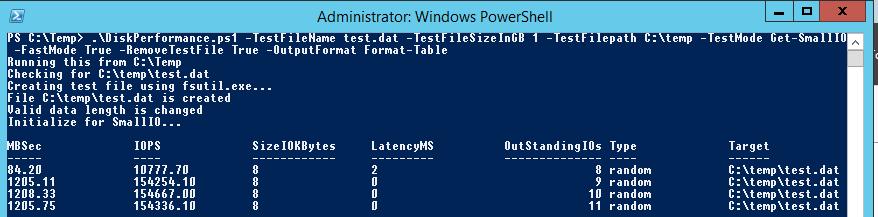
Я использовал в скрипте следующие аргументы:
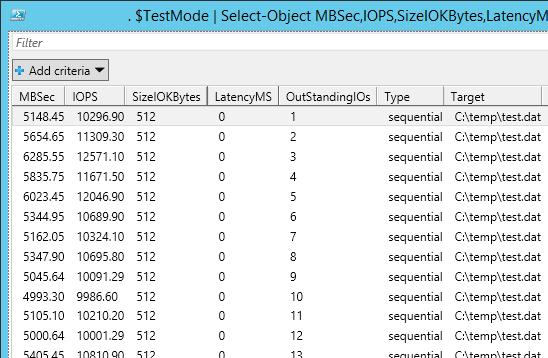
В нашем случае дисковый массив (тестировался виртуальный vmdk диск на VMFS хранилище, расположенном на дисковой полке HP MSA 2040 с доступом через SAN) показал среднее значение IOPS около 15000 и скорости передачи данных (пропускная способность) около 5 Гбит/сек.
В следующей таблице указаны примерные значения IOPS для различных типов дисков:
| Тип | IOPS |
| SSD(SLC) | 6000 |
| SSD(MLC) | 1000 |
| 15K RPM | 175-200 |
| 10K RPM | 125-150 |
| 7.2K RPM | 50-75 |
| RAID5 из 6 дисков с 10000 RPM | 900 |
Ниже приведены ряд рекомендаций по производительности дисков в IOPS для распространенных сервисов:
IOPS — что это такое, и как его считать
 IOPS (количество операций ввода/вывода – от англ. Input/Output Operations Per Second) – один из ключевых параметров при измерении производительности систем хранения данных, жестких дисков (НЖМД), твердотельных диски (SSD) и сетевых хранилища данных (SAN).
IOPS (количество операций ввода/вывода – от англ. Input/Output Operations Per Second) – один из ключевых параметров при измерении производительности систем хранения данных, жестких дисков (НЖМД), твердотельных диски (SSD) и сетевых хранилища данных (SAN).
По сути, IOPS это количество блоков, которое успевает считаться или записаться на носитель. Чем больше размер блока, тем меньше кусков, из которых состоит файл, и тем меньше будет IOPS, так как на чтение куска большего размера будет затрачиваться больше времени.
Значит, для определения IOPS надо знать скорость и размер блока при операции чтения / записи. Параметр IOPS равен скорости, деленной на размер блока при выполнении операции.
Характеристики производительности
Основными измеряемыми величинами являются операции линейного (последовательного) и произвольного (случайного) доступа.
Под линейными операциям чтения/записи, при которых части файлов считываются последовательно, одна за другой, подразумевается передача больших файлов (более 128 К). При произвольных операциях данные читаются случайно из разных областей носителя, обычно они ассоциируются с размером блока 4 Кбайт.
Ниже приведены основные характеристики:
| Параметр | Описание |
| Всего IOPS (Total IOPS) | Суммарное число операций ввода/вывода в секунду (при выполнении как чтения, так и записи) |
| IOPS произвольного чтения (Random Read) | Среднее число операций произвольного чтения в секунду |
| IOPS произвольной записи (Random Write) | Среднее число операций произвольной записи в секунду |
| IOPS последовательного чтения (Sequential Read) | Среднее число операций линейного чтения в секунду |
| IOPS последовательной записи (Sequential Write) | Среднее число операций линейной записи в секунду |
Приблизительные значения IOPS
Приблизительные значения IOPS для жестких дисков.
| Устройство | Тип | IOPS | Интерфейс |
| 7,200 об/мин SATA-диски | HDD | 75-100 IOPS | SATA 3 Гбит/с |
| 10,000 об/мин SATA-диски | HDD | 125-150 IOPS | SATA 3 Гбит/с |
| 10,000 об/мин SAS-диски | HDD | 140 IOPS | SAS |
| 15,000 об/мин SAS-диски | HDD | 175-210 IOPS | SAS |
Приблизительные значения IOPS для SSD.
| Устройство | Тип | IOPS | Интерфейс |
| Intel X25-M G2 MLC | SSD | 8 600 IOPS | SATA 3 Гбит/с |
| OCZ Vertex 3 | SSD | 60 000 IOPS (Произвольная запись 4K) | SATA 6 Гбит/с |
| OCZ RevoDrive 3 X2 | SSD | 200 000 IOPS (Произвольная запись 4K) | PCIe |
| OCZ Z-Drive R4 CloudServ | SSD | 1 400 000 IOPS | PCIe |
RAID пенальти
Любые операции чтения, которые выполняются на дисках, не подвергаются никакому пенальти, поскольку все диски могут использоваться для операций чтения. Но всё на оборот с операциями на запись. Количество пенальти на запись зависят от типа выбранного RAID-а, например.
В RAID 1 чтобы данные записались на диск, происходит две операции на запись (по одной записи на каждый диск), и следовательно RAID 1 имеет два пенальти.
В RAID 5 чтобы записать данные происходит 4 операции (Чтение существующих данных, четность RAID, Запись новых данных, Запись новой четности) тем самым пенальти в RAID 5 составляет 4.
В этой таблице приведено значение пенальти для более часто используемых RAID конфигурации.
| RAID | I/O Пенальти |
| RAID 0 | 1 (Edited by Reader) |
| RAID 1 | 2 |
| RAID 5 | 4 |
| RAID 6 | 6 |
| RAID 10 | 2 |
Характеристика рабочих нагрузок
Характеристика рабочей нагрузки в основном рассматривается как процент операции чтений и записей, которые вырабатывает или требует приложение. Например, в среде VDI процентное соотношение IOPS рассматривается как 80-90% на запись и 10-20% на чтение. Понимание характеристики рабочей нагрузки является наиболее критическим фактором, поскольку от этого и зависит выбор оптимального RAID для среды. Приложения которые интенсивно используют операции на запись являются хорошими кандидатами для RAID 10, тогда как приложения которые интенсивно используют операции на чтение могут быть размещены на RAID 5.
Вычисление IOPS
Есть два сценария вычисления IOPS-ов.
Один из сценариев это когда есть определенное число дисков, и мы хотим знать, сколько IOPS эти диски выдадут?
Второй сценарий, когда мы знаем сколько нам IOPS-ов надо, и хотим вычислить нужное количество дисков?
Сценарий 1: Вычисление IOPS исходя из определенного кол-ва дисков
Представим что у нас есть 20 450GB 15к RPM дисков. Рассмотрим два сценария Рабочей нагрузки 80%Write-20%Read и другой сценарий с 20%Write-80%Read. Также мы вычислим количество IOPS как для RAID5 и RAID 10.
Формула для расчета IOPS:
Total Raw IOPS = Disk Speed IOPS * Number of disks
Functional IOPS =(((Total Raw IOPS×Write %))/(RAID Penalty))+(Total Raw IOPS×Read %)
Есть определение Raw IOPS и Functional IOPS, как раз токи Functional IOPS-ы и есть те IOPS-ы которые включают в себя RAID пенальти, и это и есть “настоявшие” IOPS-ы.
А теперь подставим цифры и посмотрим что получится.
Total Raw IOPS = 170*20 = 3400 IOPS (один 15K RPM диск может выдать в среднем 170 IOPS)
Для RAID-5
Вариант 1 (80%Write 20%Read) Functional IOPS = (((3400*0.8))/(4))+(3400*0.2) = 1360 IOPS
Вариант 2 (20%Write 80%Read) Functional IOPS = (((3400*0.2))/(4))+(3400*0.8) = 2890 IOPS
Для RAID-1
Вариант 1 (80%Write 20%Read) Functional IOPS = (((3400*0.8))/(2))+(3400*0.2) = 2040 IOPS
Вариант 2 (20%Write 80%Read) Functional IOPS = (((3400*0.2))/(2))+(3400*0.8) = 3100 IOPS
Сценарий 2: Подсчет кол-ва дисков для достижения определенного кол-ва IOPS
Рассмотрим ситуацию где нам надо определить тип RAID-а и количества дисков для достижения определенного количества IOPS-ов 5000 и с определенными рабочими нагрузками, например 80%Write20%Read и 20%Write80% Read.
Опять же для начала формула по которой и будем считать:
Total number of Disks required = ((Total Read IOPS + (Total Write IOPS*RAID Penalty))/Disk Speed IOPS)
Теперь подставим цифры.
Заметка: 80% от 5000 IOPS = 4000 IOPS и 20% от 5000 IOPS = 1000 IOPS с этими цифрами и будем оперировать.
Для RAID-5
Вариант 1 (80%Write20%Read) – Total Number of disks required = ((1000+(4000*4))/170) = 100 дисков.
Вариант 2 (20%Write80%Read) – Total Number of disks required = ((4000+(1000*4))/170) = 47 дисков приблизительно.
Для RAID-1
Вариант 1 (80%Write20%Read) – Total Number of disks required = ((1000+(4000*2))/170) = 53 диска приблизительно.
Вариант 2 (20%Write80%Read) – Total Number of disks required = ((4000+(1000*2))/170) = 35 дисков приблизительно.
Понимание и подсчет IOPS, RAID пенальти, и характеристик рабочих нагрузок очень критичны аспект при планировании. Когда нагрузка более интенсивна на запись луче выбирать RAID 10 и наоборот при нагрузках на чтение RAID 5.
Анализ производительности ВМ в VMware vSphere. Часть 3: Storage
Рассказываем, какие метрики помогут отследить проблемы с производительностью дисковой подсистемы VMware vSphere.

Сегодня разберем метрики дисковой подсистемы в vSphere. Проблема со стораджем – самая частая причина медленной работы виртуальной машины. Если в случаях с CPU и RAM траблшутинг заканчивается на уровне гипервизора, то при проблемах с диском, возможно, придется разбираться с сетью передачи данных и СХД.
Предмет буду разбирать на примере блочного доступа к СХД, хотя при файловом доступе счетчики примерно те же.
Немного теории
Когда говорят о производительности дисковой подсистемы виртуальных машин, обычно обращают внимание на три связанных друг с другом параметра:
Количество IOPS обычно важно для нагрузок произвольного характера (random): доступ к блокам на диске, расположенным в разных местах. Примером такой нагрузки могут послужить базы данных, бизнес-приложения (ERP, CRM) и т.д.
Пропускная способность важна для нагрузок последовательного характера: доступ к блокам, расположенным друг за другом. Например, такую нагрузку могут генерировать файловые сервера (но не всегда) и системы видеонаблюдения.
Пропускная способность связана с количеством операций ввода/вывода следующим образом:
Throughput = IOPS * Block size, где Block size – это размер блока.
Размер блока является довольно важной характеристикой. Современные версии ESXi пропускают блоки размером до 32 767 КБ. Если блок еще больше, он делится на несколько. Не все СХД могут эффективно работать с такими большими блоками, поэтому в Advanced Settings ESXi есть параметр DiskMaxIOSize. С помощью него можно уменьшить максимальный размер блока, пропускаемого гипервизором (подробнее здесь). Рекомендую перед изменением данного параметра проконсультироваться с производителем СХД или хотя бы протестировать изменения на лабораторном стенде.
Большой размер блока может пагубно сказываться на производительности СХД. Даже если количество IOPS и throughput относительно невелики, при большом размере блока могут наблюдаться высокие задержки. Поэтому обращайте внимание на этот параметр.
Latency – самый интересный параметр производительности. Задержка операций ввода/вывода для виртуальной машины складывается из:
Общая задержка, которая видна в гостевой ОС (GAVG, Average Guest MilliSec/Command), – это сумма KAVG и DAVG.
GAVG и DAVG измеряются, а KAVG рассчитывается: GAVG–DAVG.
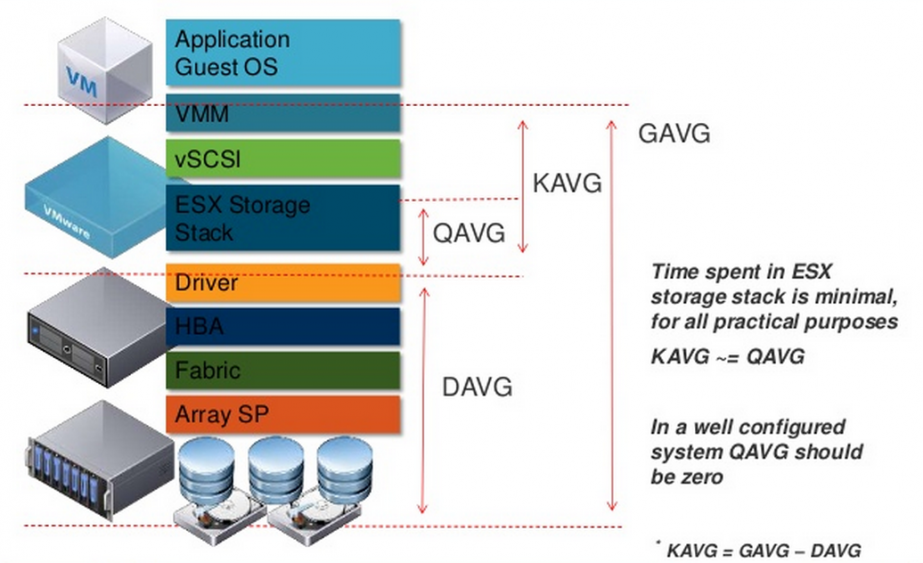
Источник
Остановимся подробнее на KAVG. При нормальной работе KAVG должен стремиться к нулю или, по крайней мере, быть сильно меньше, чем DAVG. Единственный известный мне случай, когда KAVG ожидаемо высокий, – ограничение по IOPS на диске ВМ. В таком случае при попытке превышения лимита будет расти KAVG.
Самой значительной составляющей KAVG является QAVG – время в очереди на обработку внутри гипервизора. Остальные составляющие KAVG пренебрежимо малы.
Размер очереди в драйвере дискового адаптера и очереди к лунам имеет фиксированный размер. Для высоконагруженных сред данный размер бывает полезно увеличить. Здесь описано, как увеличить очереди в драйвере адаптера (помните, что одновременно увеличится очередь к лунам). Данная настройка работает, когда с луном работает только одна ВМ, что бывает редко. Если на луне несколько ВМ, необходимо также увеличить параметр Disk.SchedNumReqOutstanding (инструкция здесь). Увеличив очередь, вы уменьшаете QAVG и KAVG соответственно.
Но, опять же, сначала ознакомьтесь с документацией от вендора HBA и протестируйте изменения на лабораторном стенде.
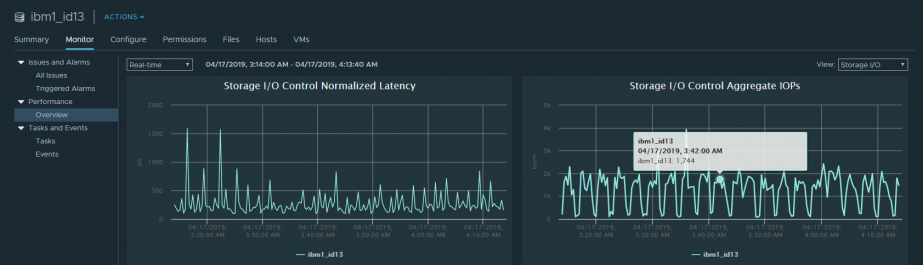
На размер очереди к луну может влиять включение механизма SIOC (Storage I/O Control). Он обеспечивает равномерный доступ к луну со стороны всех серверов кластера за счет динамического изменения очереди к луну на серверах. То есть, если на каком-то из хостов работает ВМ, которая требует непропорционально много производительности (noisy neighbor VM), SIOC уменьшает длину очереди к луну на данном хосте (DQLEN). Подробнее здесь.
С KAVG разобрались, теперь немного о DAVG. Тут все просто: DAVG – это задержка, которую вносит внешняя среда (сеть передачи данных и СХД). В любой современной и не очень СХД есть свои счетчики производительности. Для анализа проблем с DAVG имеет смысл смотреть на них. Если же со стороны ESXi и СХД все нормально, проверяйте сеть передачи данных.
Чтобы не было проблем с производительностью, выбирайте правильную Path Selection Policy (PSP) для вашей СХД. Практически все современные СХД поддерживают PSP Round-Robin (с ALUA, Asymmetric Logical Unit Access, или без). Данная политика позволяет использовать все доступные пути к СХД. В случае с ALUA используются только пути до контроллера, который владеет луном. Не для всех СХД на ESXi есть дефолтные правила, которые устанавливают политику Round-Robin. Если для вашего СХД правила нет, используйте плагин от производителя СХД, который создаст соответствующее правило на всех хостах кластера, или создайте правило самостоятельно. Подробности здесь.
Также часть производителей СХД рекомендуют менять количество IOPS на путь со стандартного значения 1000 на 1. В нашей практике это позволяло «выжать» из СХД больше производительности и значительно сократить время, которое требуется на failover в случае выхода из строя или обновления контроллеров. Сверьтесь с рекомендациями вендора, и если противопоказаний нет, то попробуйте изменить данный параметр. Подробности здесь.
Основные счетчики производительности дисковой подсистемы виртуальной машины
Счетчики производительности дисковой подсистемы в vCenter собраны в разделах Datastore, Disk, Virtual Disk:

В разделе Datastore находятся метрики по дисковым хранилищам vSphere (датасторам), на которых лежат диски ВМ. Здесь вы найдете стандартные счетчики по:
Из названий счетчиков в принципе все понятно. Еще раз обращу внимание, что здесь статистика не по конкретной ВМ (или диску ВМ), а общая по всему датастору. На мой взгляд, данную статистику удобнее смотреть в ESXTOP, хотя бы исходя из того, что минимальный период измерения там 2 секунды.
В разделе Disk находятся метрики по блочным устройствам, которые используются ВМ. Тут есть счетчики по IOPS типа summation (количество операций ввода/вывода за период измерения) и несколько счетчиков, относящихся к блочному доступу (Commands aborted, Bus resets). Данную информацию, на мой взгляд, также удобнее смотреть в ESXTOP.
Раздел Virtual Disk – самый полезный с точки зрения поиска проблем производительности дисковой подсистемы ВМ. Здесь можно посмотреть производительность по каждому виртуальному диску. Именно эта информация нужна, чтобы понять, есть ли проблема у конкретной виртуальной машины. Помимо стандартных счетчиков количества операций ввода/вывода, объема чтения/записи и задержек, в данном разделе присутствуют полезные счетчики, которые показывают размер блока: Read/Write request size.
На картинки ниже график производительности диска ВМ, на котором можно увидеть количество IOPS, задержки и размер блока.
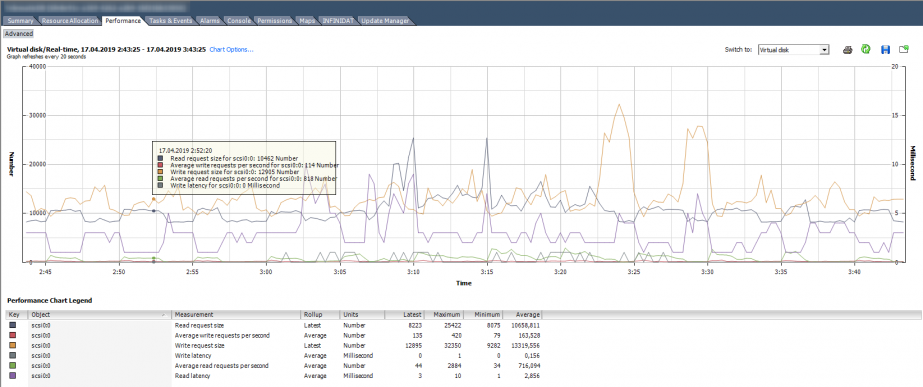
Также метрики производительности можно посмотреть по всему датастору, если включен SIOC. Здесь представлена базовая информация по средней Latency и IOPS’ам. По умолчанию данную информацию можно посмотреть только в реальном времени.
ESXTOP
В ESXTOP несколько экранов, на которых представлена информация по дисковой подсистеме хоста в целом, отдельным виртуальным машинам и их дискам.
Начнем с информации по виртуальным машинам. Экран “Disk VM” вызывается клавишей “v”:

NVDISK – это количество дисков ВМ. Чтобы посмотреть информацию по каждому диску, нажмите “e” и введите GID интересующей ВМ.
Значение остальных параметров на данном экране понятно из их названий.
Еще один полезный при поиске проблем экран – Disk adapter. Вызывается клавишей “d” (на картинке ниже выбраны поля A,B,C,D,E,G):

NPTH – количество путей к лунам, которые видны с данного адаптера. Чтобы получить информацию по каждому пути на адаптере, нажмите “e” и введите название адаптера:
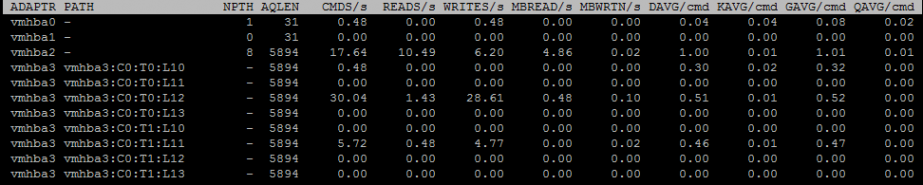
AQLEN – максимальный размер очереди на адаптере.
Также на этом экране представлены счетчики задержек, о которых я рассказывал выше: KAVG/cmd, GAVG/cmd, DAVG/cmd, QAVG/cmd.
На экране Disk device, который вызывается клавишей “u”, представлена информация по отдельным блочным устройствам – лунам (на картинке ниже выбраны поля A, B, F, G, I). Здесь можно увидеть состояние очереди к лунам.

DQLEN – размер очереди для блочного устройства.
ACTV – количество команд ввода/вывода в ядре ESXi.
QUED – количество команд ввода/вывода в очереди.
%USD – ACTV / DQLEN × 100%.
LOAD – (ACTV + QUED) / DQLEN.
Если %USD высокий, стоит рассмотреть возможность увеличения очереди. Чем больше команд в очереди, тем выше QAVG и, соответственно, KAVG.
Также на экране Disk device можно посмотреть, работает ли на СХД VAAI (vStorage API for Array Integration). Для этого нужно выбрать поля A и O.
Механизм VAAI позволяет перенести часть работы из гипервизора непосредственно на СХД, например, зануление, копирование блоков или блокировки.

Как видно на картинке выше, на данной СХД VAAI работает: активно используются примитивы Zero и ATS.



