Продвинутое использование robots.txt без ошибок — руководство для SEO
1 сентября 2019 года Google прекратит поддержку нескольких директив в robots.txt. В список попали: noindex, crawl-delay и nofollow. Вместо них рекомендуется использовать:
404 и 410 коды ответа сервера. В ряде случаев, 410 отрабатывает значительно быстрей для удаления URL из индекса.
Защита паролем. Страницы, требующие авторизации, также обычно удаляются из индекса (важно — именно страницы, полностью скрытые под логином, а не часть контента).
Временное удаление страницы из индекса с помощью инструмента в Search Console.
Disallow в robots.txt.
Тем не менее, robots.txt по-прежнему остаётся одним из главных файлов для SEO-специалиста. Давайте вспомним самые полезные директивы от простых, до менее очевидных.
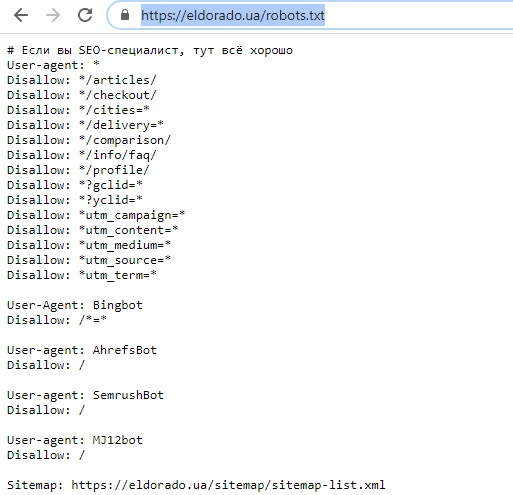
robots.txt
Это простой текстовый файл, который содержит инструкции для поисковых краулеров — какие страницы сайта не следует посещать, где лежит наш Sitemap.xml и для каких поисковых роботов распространяются правила.
Файл размещается в корневой директории сайта. Например:
Прежде чем начать сканирование сайта, краулеры проверяют наличие robots.txt и находят правила специфичные для их User-Agent, например Googlebot. Если таких нет — следуют общим инструкциям.
Действующие правила robots.txt
User-Agent
У каждой поисковой системы есть свои «агенты пользователя». По сути, это имя краулера, которое помогает дать определённые указания конкретному ему.
Если брать шире, то User-Agent — клиентское приложение на стороне поисковой системы, в некотором смысле имитирующее браузер или, например, мобильное устройство.
User-agent: * — символ астериск используются для обозначения сразу же всех краулеров.
User-agent: Yandex — основной краулер Яндекс-поиска.
User-agent: Google-Image — робот поиска Google по картинкам.
User-agent: AhrefsBot — краулер сервиса Ahrefs.
Важно: если в файле указаны правила для конкретных User-Agent, то роботы будут следовать только своим инструкциям, игнорируя общие правила.
Disallow
Директива, которая позволяет блокировать от индексации полностью весь сайт или определённые разделы.
Может быть полезно для закрытия от сканирования служебных, динамических или временных страниц (символ # отвечает за комментарии в коде и игнорируется краулерами).
Упростить инструкции помогают операторы:
* — любая последовательность символов в URL. По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *.
$ — символ в конце URL-адреса, он используется чтобы отменить использование * на конце правила.
Важно: в robots.txt не нужно закрывать JS и CSS-файлы, они понадобятся поисковым роботом для правильного отображения (рендеринга) контента.
Allow
С помощью этой директивы можно, напротив, разрешить каталог или конкретный адрес к индексации. В некоторых случаях проще запретить к сканированию весь сайт и с помощью Allow открыть нужные разделы.
Также Allow можно использовать для отдельных User-Agent.
Crawl-delay
Директива, теряющая актуальность в случае Goolge, но полезная для работы с другими поисковиками.
Позволяет замедлить сканирование, если сервер бывает перегружен. Устанавливает интервал времени для обхода страниц в секундах (для Яндекса). Чем выше значение, тем медленнее краулер ходит по сайту.
Несмотря на то, что Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Интересно, что китайский Baidu также не обращает внимание на Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт только один раз.
Важно: если установлено высокое значение Crawl-delay, убедитесь, что ваш сайт своевременно индексируется. В сутках 86 400 секунд, при Crawl-delay: 30 будет просканировано не более 2880 страниц в день, что мало для крупных сайтов.
Sitemap
Одно из ключевых применений robots.txt в SEO — указание на расположение карты сайты. Обратите внимание, используется полный URL-адрес (их может быть несколько).
Нужно иметь в виду:
Директива Sitemap указывается с заглавной S.
Sitemap не зависит от инструкций User-Agent.
Нельзя использовать относительный адрес карты сайта, только полный URL.
Файл XML-карты сайта должен располагаться на том же домене.
Также убедитесь, что ссылка возвращает статус 200 OK без редиректов. Проверить можно с помощью инструмента, определяющего ответ сервера или анализа XML-карты сайта.
Типичный robots.txt
Ниже представлены простые и распространенные шаблоны команд для поисковых роботов.
Разрешить полный доступ
Обратите внимание, правило для Disallow в этом случае не заполняется.
Полная блокировка доступа к хосту
Запрет конкретного раздела сайта
Запрет сканирования определенного файла
Распространенная ошибка
Установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent, соответствующий краулер будет следовать только тем правилам, что установлены именно для него. Не забывайте дублировать общие директивы для всех User-Agent.
В примере ниже — слегка измененный robots.txt сайта IMDB. Общие правила Disallow не будут распространяться на бот ScoutJet. А вот Crawl-delay, напротив, установлена только для него.
Противоречия директив
Список распространенных User-Agent
| User-Agent | # |
|---|---|
| Googlebot | Основной краулер Google |
| Googlebot-Image | Робот поиска по картинкам |
| Bing | |
| Bingbot | Основной краулер Bing |
| MSNBot | Старый, но всё ещё использующийся краулер Bing |
| MSNBot-Media | Краулер Bing для изображений |
| BingPreview | Отдельный краулер Bing для Snapshot-изображений |
| Яндекс | |
| YandexBot | Основной индексирующий бот Яндекса |
| YandexImages | Бот Яндеса для поиска по изображениям |
| Baidu | |
| Baiduspider | Главный поисковый робот Baidu |
| Baiduspider-image | Бот Baidu для картинок |
| Applebot | Краулер для Apple. Используется для Siri поиска и Spotlight |
| SEO-инструменты | |
| AhrefsBot | Краулер сервиса Ahrefs |
| MJ12Bot | Краулер сервиса Majestic |
| rogerbot | Краулер сервиса MOZ |
| PixelTools | Краулер «Пиксель Тулс» |
| Другое | |
| DuckDuckBot | Бот поисковой системы DuckDuckGo |
Советы по использованию операторов
1. Заблокировать определённые типы файлов.
Этот приём активно используется, если у проекта настроено ЧПУ для всех страниц и документы с GET-параметрами точно являются дублями.
Заблокировать результаты поиска, но не саму страницу поиска.
Имеет ли значение регистр?
Определённо да. При указании правил Disallow / Allow, URL адреса могут быть относительными, но обязаны сохранять регистр.
Но сами директивы могут объявляться как с заглавной, так и с прописной: Disallow: или disallow: — без разницы. Исключение — Sitemap: всегда указывается с заглавной.
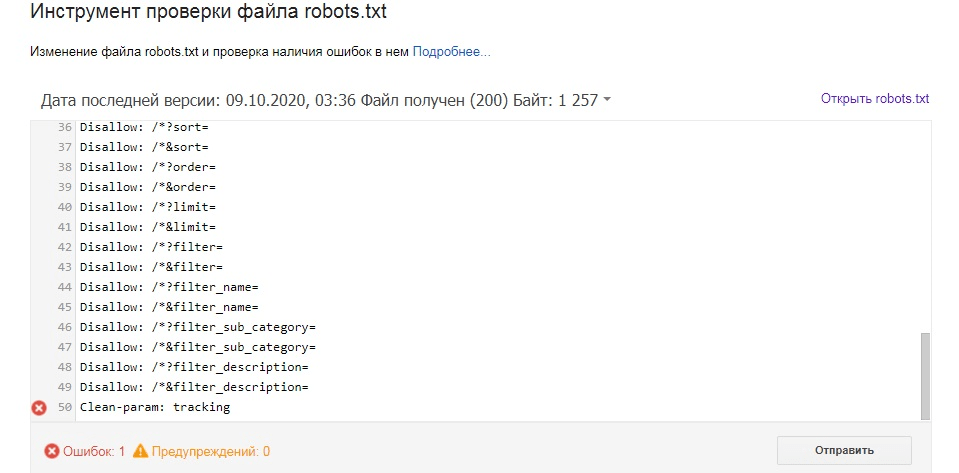
Как проверить robots.txt?
Есть множество сервисов проверки корректности файлов robots.txt, но, пожалуй, самые надёжные: Google Search Console и Яндекс.Вебмастер.
Для мониторинга изменений, как всегда, незаменим «Модуль ведения проектов»:
Контроль индексации на вкладке «Аудит» — динамика сканирования страниц сайта в Яндексе и Google.
Для чего нужен файл robots.txt? Как его настроить и проверить
Файл robots.txt — это текстовый документ в корневом каталоге сайта с информацией для поисковых роботов о том, какие URL (на которых расположены страницы, файлы, папки, прочее) стоит сканировать, а какие — нет. Наличие этого файла не является обязательным условием для работы ресурса, но в то же время правильное его заполнение лежит в основе SEO.
Решение об использовании robots.txt было принято еще в 1994 году в рамках «Стандарта исключений для роботов». Согласно справке Google, файл предназначен не для запрета показа веб-страниц в результатах поиска, а для ограничения количества запросов роботов к сайту и снижения нагрузки на сервер.
В целом содержимое robots.txt стоит отнести к разряду рекомендаций поисковым ботам, задающих правила сканирования страниц сайта. Чтобы увидеть содержимое robots.txt на любом сайте, нужно добавить к имени домена в браузере /robots.txt.
Для чего используют robots.txt?
К основным функциям документа можно отнести закрытие от сканирования страниц и файлов ресурса в целях рационального расхода краулингового бюджета. Чаще всего закрывают информацию, которая не несет ценности для пользователя и не влияет на позиции сайта в поиске.
| Примечание. Краулинговый бюджет — количество страниц сайта, которое может просканировать поисковый робот. Для его экономии стоит направлять робота только к самому важному содержимому ресурса, закрывая доступ к малополезной информации. |
Какие страницы и файлы закрывают с помощью robots.txt
1. Страницы с персональными данными.
Это могут быть имена и телефоны, которые посетители указывают при регистрации, страницы личного кабинета, номера платежных карт. В целях безопасности доступ к этой информации стоит дополнительно защищать паролем.
2. Вспомогательные страницы, которые появляются только при определенных действиях пользователя.
К ним можно отнести сообщения об успешно оформленном заказе, клиентские формы, страницы авторизации или восстановления пароля.
3. Админпанель и системные файлы.
Внутренние и служебные файлы, с которыми взаимодействует администратор сайта или вебмастер.
4. Страницы поиска и сортировки.
На страницы, которые отображаются по запросу, указанному в окне поиска на сайте, как правило, ставят запрет сканирования. Это же относится к результатам сортировки товаров по цене, рейтингу и другим критериям. Исключением могут быть сайты-агрегаторы.
5. Страницы фильтров.
Результаты, которые отображаются после применения фильтров (размер, цвет, производитель и т.д.), являются отдельными страницами и могут быть расценены как дубли контента. SEO-специалисты, как правило, ограничивают их сканирование, за исключением ситуаций, когда они приносят трафик по брендовым и другим целевым запросам.
6. Файлы определенного формата.
К ним могут относиться фото, видео, PDF-документы, JS-скрипты. С помощью robots.txt можно ограничивать сканирование файлов как по отдельности, так и по определенному расширению.
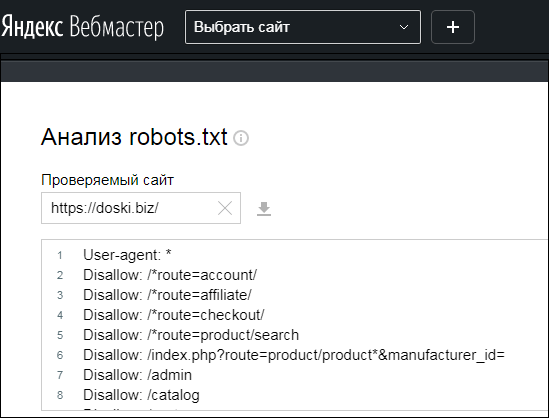
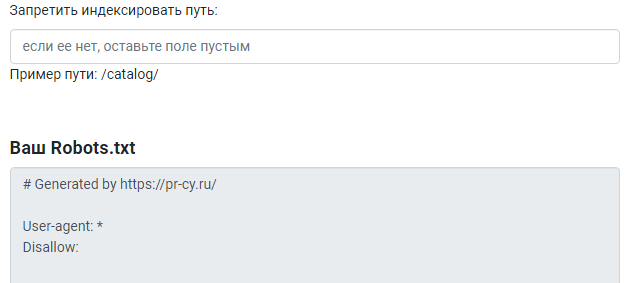
Как создать и где разместить robots.txt?
Инструменты для настройки robots txt
Также можно использовать генератор robots.txt. Некоторые сайты предоставляют бесплатные инструменты создания на основании заданных вами условий.
Название и размер документа
Имя файла robots.txt должно выглядеть именно так, без использования заглавных букв. Допустимый размер документа согласно рекомендациям Google и Яндекса — 500 КиБ. При превышении лимита робот может обработать документ частично, воспринять как полный запрет сканирования или, наоборот, пройтись по всему содержимому ресурса.
Где разместить файл
Документ находится в корневом каталоге на хостинге и доступ к нему возможен через FTP. Перед внесением изменений рекомендуется сначала скачать robots.txt в исходном виде.
Синтаксис и директивы robots.txt
Теперь разберем синтаксис robots.txt, состоящий из директив (правил), параметров (страниц, файлов, каталогов) и специальных символов, а также функции, которые они выполняют.
Общие требования к содержимому файла
1. Каждая директива должна начинаться с новой строки и формироваться по принципу: одна строка = одна директива + один параметр.
| Ошибка | User-agent: * Disallow: /folder-1/ Disallow: /folder-2/ | |||||||||||||||||||||||||||||||||||||||||||||||
| Правильно | User-agent: * 2. Названия файлов с использованием кириллицы и других алфавитов, отличных от латинского, следует преобразовать с помощью конвертера Punycode.
3. В синтаксисе параметров необходимо придерживаться соответствующего регистра. Если имя папки начинается с большой буквы, название с маленькой буквы дезориентирует робота. И наоборот.
4. Недопустимо использование пробела в начале строки, кавычек для директив или точек с запятой после них.
|