Как настроить файл robots.txt для WordPress? Две версии файла
Файл robots.txt необходим роботам поисковых систем, чтобы они могли понять, какие страницы и разделы сайта следует посещать и включать в индекс, а какие – не нужно. Запрещенные для посещения поисковыми ботами страницы не будут индексироваться и появляться в выдаче Яндекса, Google и прочих поисковиков.
Вот наглядный пример того, в чем разница между веб-ресурсом, у которого настроен файл robots, и сайтом без него:
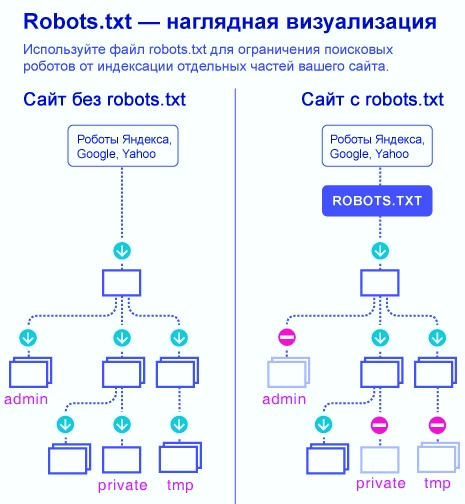
В данной статье я расскажу о нескольких способах правильной настройки robots.txt для популярного движка WordPress.
Оптимальный код файла для WordPress
Важно! Не забудьте поменять “https://domain.ru/sitemap.xml” на свой пусть к файлу sitemap.
Теперь разберем, какие директивы в коде что означают:
1. Директива User-agent: * означает, что все правила, описанные ниже нее, касаются всех роботов поисковых систем. Если вы хотите прописать правила для одного определенного бота, вместо * нужно ввести его имя. Например:
2. Строка Allow: /uploads указывается, чтобы разрешить ботам вносить в индекс страницы, где присутствует /uploads. Нужно обязательно указать данное правило, потому что выше запрещены к индексированию страницы, которые начинаются с /wp-, а проблема в том, что /uploads присутствует в /wp-content/uploads.
Команда Allow: /uploads нужна для перебивания правила Disallow: /wp-, так как по ссылкам типа /wp-content/uploads/ могут располагаться изображения, важные для индексации. Помимо картинок есть вероятность присутствия прочих файлов, которые нет нужды запрещать включать в поиск. Строчку Allow допускается прописывать и до, и после Disallow.
3. Директивы Disallow: запрещают ботам переходить по ссылкам, начинающимся с:
4. Строчка Sitemap: http://domain.ru/sitemap.xml сообщает поисковому боту о XML файле с картой сайта. Если на вашем ресурсе присутствует данный файл, укажите к нему полный путь. Если их несколько, нужно прописать путь отдельно к каждому из них.
Рекомендуется не закрывать от индексации фиды: Disallow: /feed.
У фидов собственный формат в заголовках ответа, что позволяет поисковым системам понять, что это фид, а не HTML документ, и обрабатывать его по-другому.
А если вы не хотите передавать RSS, чтобы например у вас не воровали через него контент, то тогда надежнее отключить его с помощью специальных плагинов, например Disable Feeds.
Сортировка правил перед обработкой
Google и Яндекс обрабатывают правила Disallow и Allow без соблюдения порядка, в котором они прописаны в robots.txt. Поисковики сортируют директивы от коротких к длинным, после чего обрабатывают последнюю подходящую директиву.
Например, данная инструкция:
Поисковые системы обработают следующим образом:
В случае проверки ссылки типа /wp-content/uploads/file.jpg, директива Disallow сначала запретит ссылку с /wp-, а затем Allow разрешит ее индексировать, поэтому ссылка будет доступна для роботов.
На заметку. Запомните главное при сортировке правил: чем директива в файле robots.txt длиннее, тем она приоритетнее. Когда директивы одинаковой длины, приоритетной становится Allow.
Стандартный файл robots для WordPress
Хотя первый метод является более современным и логичным, но я все же пользуюсь вторым файлом robots.txt. Потому что мне так спокойнее, что с помощью директивы Dissalow: /wp- я не запрещу что то нужное, поэтому я прописываю каждую папку отдельно.
Исходя из вышеперечисленных правок, у меня получается вот такой robots.txt:
Важно! Не забудьте поменять “https://domain.ru/sitemap.xml” на свой пусть к файлу sitemap.
Доработка файла под свои цели
Если потребуется заблокировать еще какие-то страницы или разделы веб-ресурса, добавьте директиву Disallow. К примеру, желая скрыть от роботов все публикации в рубрике News, пропишите правило:
Так вы запретите ботам переходить по ссылкам типа http://domain.ru/news и закроете от индексации такие страницы:
Постоянно проверяйте, какие страницы проиндексированы поисковыми системами и находятся в выдаче. Сделать это можно с помощью оператора site:domain.ru.
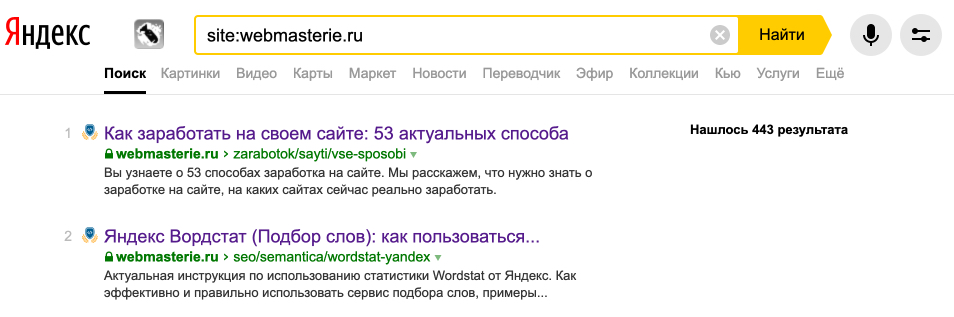
И если заметили мусорные, ненужные страницы, то блокируйте их в robots.txt.
Проверка файла и документация
Проверить корректность директив, прописанных в robots.txt, вы можете по ссылкам:
Динамический robots.txt
В CMS Вордпресс обработка запроса на файл robots производится отдельно. Вебмастеру нет нужды самостоятельно создавать в корневом каталоге сайта файл robots. Это не то что можно не делать, но и нужно, иначе плагины не смогут изменять созданный вебмастером файл, когда в этом появится необходимость.
Для изменения содержания динамического robots налету, через хук do_robotstxt, добавьте данный код в файл funtcions.php:
При переходе по ссылке http://example.com/robots.txt вы увидите следующий код:
Заключение
Обязательно следите за актуальностью своего robots.txt. Проверяйте страницы на индексацию, чтобы там не было мусорных, не нужных страниц. Если такие заметили, то блокируйте их. При внесении изменений в файл robots.txt для уже рабочего веб-сайта результат будет видно не раньше, чем через 2-3 месяца.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Disallow feed что значит


Всего 16% российских IT-специалистов довольны своей текущей карьерой

Кого не любят в арбитражной тусовке и за что?

В robots.txt числится вот такая запись: Disallow: /*?. Она часом не означает исключить все страницы кроме главной?
И посмотрите пожалуйста, нет здесь ничего лишнего:

Я так понимаю CMS WordPress? Запись эта просто закрывает от индексации страницы с результатами поиска на сайте!

Да, это WP поиск закрыт.

Так проще и понятнее 🙂
я как бы «академически» завернул
Понятно, но у меня указано:
Но пришлось доп. прописать:
Ссылки на ответ в комментариях вроде индексирует и создаёт дубли страниц:
это вообще бредовая запись
предыдущее правило (/?*) закрывает и эти страницы /?replytocom=
angr Спасибо, робот.тхт не знаю.
User-agent: *
Disallow: /redirect/
Disallow: /author/
Disallow: /author*
Disallow: /wp-admin/
Disallow: /wp-includes
Disallow: /?s=
Disallow: /xmlrpc.php
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: */comments
Disallow: */comment-page*
Disallow: /comments/
Disallow: /comments/feed/
Disallow: /*trackback
Disallow: /*?
Disallow: /?*
Disallow: /*feed
Disallow: */feed
Disallow: /feed
Disallow: /feeds
Disallow: /feeds/
Disallow: /feed/
Disallow: /?feed=
Disallow: */trackback
Disallow: /?replytocom=
# Google AdSense
User-agent: Mediapartners-Google*
Disallow:
Allow: /*
«Вкалывают роботы»: что такое robots.txt и как его настроить

Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Пример:
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Даем рекомендацию, чтобы индексировались категории.
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
Sitemap
Пример:
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
Переходим в инструмент, вводим домен и содержимое вашего файла.

Нажимаем « Проверить » и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
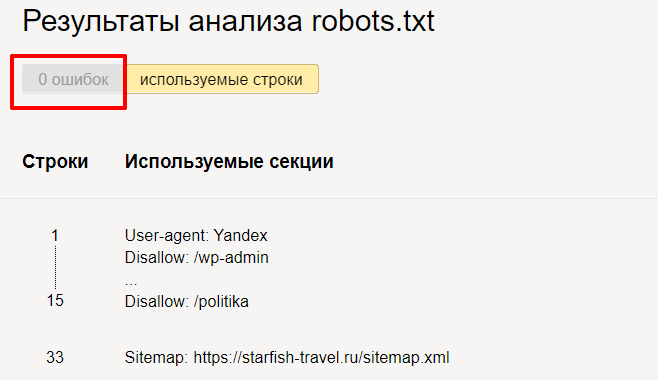
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
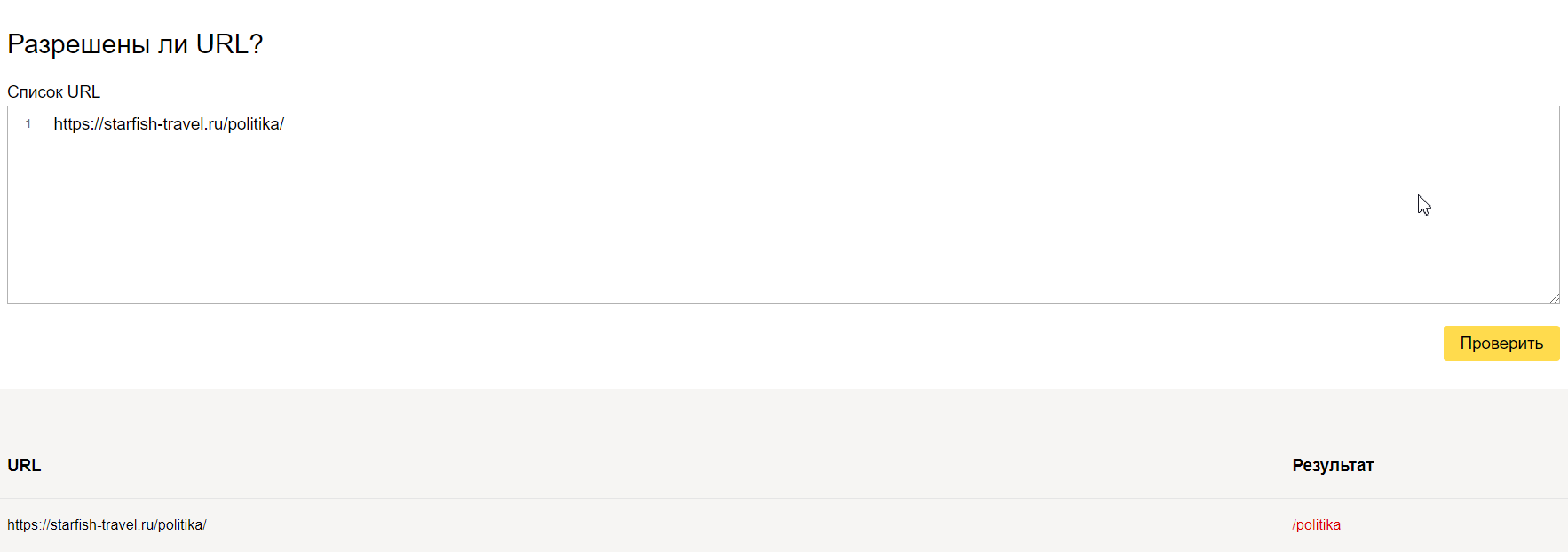
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
Правильный robots.txt для Joomla
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Настраиваем файл robots.txt для WordPress
В этой статье пример оптимального, на мой взгляд, кода для файла robots.txt под WordPress, который вы можете использовать в своих сайтах.
Для начала, вспомним зачем нужен robots.txt — файл robots.txt нужен исключительно для поисковых роботов, чтобы «сказать» им какие разделы/страницы сайта посещать, а какие посещать не нужно. Страницы, которые закрыты от посещения не будут попадать в индекс поисковиков (Yandex, Google и т.д.).

Таким образом, если мы закрыли страницу в robots.txt, робот просто пропустит её не сделав никаких запросов на сервер. А если мы закрыли страницу в заголовке X-Robots-Tag или мета-теге, роботу нужно сначала сделать запрос к серверу, получить ответ, посмотреть что находится в заголовке или метатеге и только потом принять решения индексировать страницу или нет.
Таким образом, файл robots.txt объясняет роботу какие страницы (URL) сайта нужно просто пропускать не делая никаких запросов. Это экономит время обхода роботом всех страниц сайта и экономит ресурсы сервера.
Рассмотрим на примере. Допустим, у нас есть сайт на котором всего 10 000 страниц (не 404 URL). Из них полезных страниц с уникальным контентом всего 3000, остальное это архивы по датам, авторам, страницы пагинации и другие страницы контент на которых дублируется (например фильтры с GET параметрами). Допустим, мы хотим закрыть от индексации эти 7000 неуникальных страниц:
Несложно догадаться, что в этом случае первый вариант гораздо предпочтительнее потому что на обход сайта робот будет тратить гораздо меньше времени, а сервер будет генерировать гораздо меньше страниц.
Оптимальный код robots.txt для WordPress
Версия 1 (не строгая)
Версия 2 (строгая)
В этом варианте мы контролируем все доступы. Сначала глобально запрещаем доступ к почти всему от WP ( Disallow: /wp- ), а затем открываем, там где нужно.
Этот код я пожалуй не рекомендовал бы, потому что тут закрывается все от wp- и нужно будет описать все что разрешено. Так в будущем, когда WP введет что-то новое, это новое может стать недоступно для роботов. Так например получилось с картой сайта WP.
Директивы (разбор кода)
Определяет для какого робота будет работать блок правил, который написан после этой строки. Тут возможны два варианта:
User-agent: * — указывает, что правила после этой строки будут работать для всех поисковых роботов.
Возможные роботы (боты) Яндекса:
Возможные роботы (боты) Google:
Запрещает роботам «ходить» по ссылкам, в которых встречается указанная подстрока:
Пример добавления нового правила. Допустим нам нужно закрыть от индексации все записи в категории news. Для этого добавляем правило:
Оно запретить роботам ходить по ссылками такого вида:
Подробнее изучить директивы robots.txt вы можете на странице помощи Яндекса. Имейте ввиду, что не все правила, которые описаны там, работают для Google.
ВАЖНО о кириллице: роботы не понимают кириллицу, её им нужно предоставлять в кодированном виде. Например:
ВАЖНО: Сортировка правил
Yandex и Google обрабатывает директивы Allow и Disallow не по порядку в котором они указаны, а сначала сортирует их от короткого правила к длинному, а затем обрабатывает последнее подходящее правило:
будет прочитана как:
Чтобы быстро понять и применять особенность сортировки, запомните такое правило: «чем длиннее правило, тем больший приоритет оно имеет. Если длина правил одинаковая, то приоритет отдается директиве Allow.»
Проверка robots.txt и документация
Проверить правильно ли работают правила можно по следующим ссылкам:
Google: https://www.google.com/webmasters/tools/robots-testing-tool Нужна авторизация и наличия сайта в панели веб-мастера.
robots.txt в WordPress
Изменить содержание robots.txt можно через:
Рассмотрим как использовать оба хука.
robots_txt
По умолчанию WP 5.5 создает следующий контент для страницы /robots.txt :
В результате перейдем на страницу /robots.txt и видим:
Обратите внимание, что мы дополнили родные данные ВП, а не заменили их.
do_robotstxt
Теперь, пройдя по ссылке http://site.com/robots.txt увидим:
Рекомендации
Не рекомендуется исключать фиды: Disallow: */feed
Потому что наличие открытых фидов требуется, например, для Яндекс Дзен, когда нужно подключить сайт к каналу (спасибо комментатору «Цифровой»). Возможно открытые фиды нужны где-то еще.
Фиды имеют свой формат в заголовках ответа, благодаря которому поисковики понимают что это не HTML страница, а фид и, очевидно, обрабатывают его иначе.
Ошибочные рекомендации
Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика
Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей.
Спорные рекомендации
Открыть папку uploads только для Googlebot-Image и YandexImages
Совет достаточно сомнительный, т.к. для ранжирования страницы необходима информация о том, какие изображения и файлы на ней размещены.
Нестандартные Директивы
Clean-param
Google не понимаю эту директиву. Указывает роботу, что URL страницы содержит GET-параметры, которые не нужно учитывать при индексировании. Такими параметрами могут быть идентификаторы сессий, пользователей, метки UTM, т.е. все то что не влияет на содержимое страницы.
Заполняйте директиву Clean-param максимально полно и поддерживайте ее актуальность. Новый параметр, не влияющий на контент страницы, может привести к появлению страниц-дублей, которые не должны попасть в поиск. Из-за большого количества таких страниц робот медленнее обходит сайт. А значит, важные изменения дольше не попадут в результаты поиска. Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы, в которых параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница:
Если указать директиву следующим образом:
то робот Яндекса сведет все адреса страницы к одному:
Пример очистки нескольких параметров сразу: ref и sort :
Crawl-delay (устарела)
Google не понимает эту директиву. Таймаут его роботам можно указать в панели вебмастера.
Яндекс перестал учитывать Crawl-delay
Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay в robots.txt […] Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Для чего была нужна директива Crawl-delay
Host (устарела)
Заключение
Важно помнить, что изменения в robots.txt на уже рабочем сайте будут заметны только спустя несколько месяцев (2-3 месяца).
На сервисе avi1.ru Вы можете уже сейчас приобрести продвижение SMM более чем в 7 самых популярных социальных сетях. При этом обратите внимание на достаточно низкую стоимость всех услуг сайта.
И снова про robots.txt для WordPress (шпаргалка начинающим)
Перед каждым блогером (продвинутым, да) рано или поздно встает вопрос: «Чего бы такого написать в robots.txt, чтобы было все в шоколаде?»
Совершенно естественно встал данный вопрос и передо мной, а написать хотелось грамотно и с пользой. Полез гуглить и все что нашел, были неуклюжие примеры robots.txt стянутые с официального сайта, которые некоторыми авторами выдавались за собственные поделки, продиктованные редкой музой веб-строительства.
Думаю не стоит и говорить, что такие примеры слабо подходили под наши с вами реалии (читай ПС Яндекс — прим. автора).
Поэтому собрав воедино всю информацию найденную в сети, а также собственные мысли и понимание того «как должно быть» написал следующий вариант.
Во-первых что важно — разные конструкции для Гугла (и остальных) и для Яндекса.
Обусловлено следующим: Для Гугла в дубликатах прописывается мета-тег canonical (в шаблоне вручную, или при помощи многочисленных сео-плагинов), который должен решать проблему дублирующегося контента, а Яндекс пока этого не понимает, там другие штучки…
Во-вторых у Яндекса прописан Host — что в любом случае не помешает.
В-третьих задача разрешить как можно больше страниц для сапы не стояла, поэтому все лишнее закрыто.
В-четвертых используются более-менее принятые настройки ЧПУ и ссылок. Если у вас иерархия ЧПУ и ссылок другая (например изменены каким-либо плагином) — корректируйте исходя их своих настроек.
Основные ошибки виденные мной:
— зачастую для Яндекса прописывают только директива Host, оставляя Dissalow пустым, но такая конструкция дает право Яндексу опять индексировать все что угодно, несмотря на запреты в первой секции, что, впрочем, логично.
— закрывая категории не закрывают архивы по дате и архив автора.
— не закрывают системные адреса (трекбэки, вход и регистрацию)
Остальное я как мог вынес в комментарии, которые можно смело удалить, если вы со всем разобрались.
Не думаю что он универсален и идеален, но думаю послужит многим хорошей отправной точкой. robots.txt:
User-agent: *
Disallow: /cgi-bin
# запрещаем индексацию системных папок
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
# запрещаем индексацию страницы входа и регистрации
Disallow: /wp-login.php
Disallow: /wp-register.php
# запрещаем индексацию трекбеков, rss-ленты
Disallow: /trackback
Disallow: /feed
Disallow: /rss
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: /xmlrpc.php
# запрещаем индексацию архива автора
Disallow: /author*
# запрещаем индексацию постраничных комментариев
Disallow: */comments
Disallow: */comment-page*
# запрещаем индексацию результатов поиска и другого возможного «мусора»
Disallow: /*?*
Disallow: /*?
# разрешаем индексацию вложений, особо мнительным можно запретить папку wp-content целиком
Allow: /wp-content/uploads
User-agent: Yandex
Disallow: /cgi-bin
# запрещаем индексацию системных папок
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
# запрещаем индексацию категорий
Disallow: /category*
# запрещаем индексацию архивов по датам. Прописываем вручную актуальные года
Disallow: /2008*
Disallow: /2009*
# запрещаем индексацию архива автора
Disallow: /author*
# запрещаем индексацию страницы входа и регистрации
Disallow: /wp-login.php
Disallow: /wp-register.php
# запрещаем индексацию трекбеков, rss-ленты
Disallow: /trackback
Disallow: /feed
Disallow: /rss
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: /xmlrpc.php
# запрещаем индексацию постраничных комментариев
Disallow: */comments
Disallow: */comment-page*
# запрещаем индексацию результатов поиска и другого возможного «мусора»
Disallow: /*?*
Disallow: /*?
# разрешаем индексацию вложений, особо мнительным можно запретить папку wp-content целиком
Allow: /wp-content/uploads
# прописываем директиву Host
Host: mysite.ru
User-agent: Googlebot-Image
Disallow:
Allow: /*
# разрешаем индексировать изображения
User-agent: YandexBlog
Disallow:
Allow: /*
# разрешаем индексировать rss-ленту



