Исправляем ошибки и правильно настраиваем robots.txt
Файл robots.txt располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Почему robots.txt важен для SEO-продвижения?
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование robots.txt может помочь:
С другой стороны, если robots.txt содержит ошибки, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Эта запись говорят о том, что поисковые системы не смогут увидеть и проиндексировать ваш сайт.
Пустой или недоступный файл robots.txt поисковые роботы воспринимают как разрешение на сканирование всего сайта.
Ниже приведены ссылки на инструкции по использованию файла robots.txt :
Какие директивы используются в robots.txt
User-agent
Для поискового робота Яндекс:
Для поискового робота Google:
Disallow и Allow
Операторы, которые используются с этими директивами: «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки.
Crawl-delay
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере. Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Clean-param
Пример директивы Clean-param :
Данная директива означает, что параметр «s» будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php.
Подробнее прочитать о директиве Clean-param можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap
В robots.txt следует указать полный путь к странице, в которой содержится файл sitemap.
Пример правильно составленного файла robots.txt :
Как найти ошибки в robots.txt с помощью Labrika?
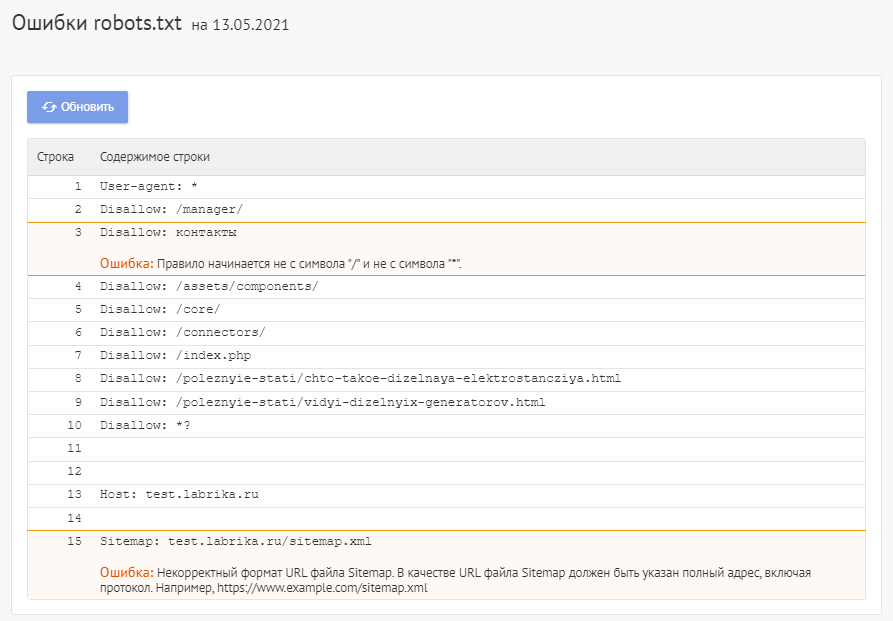
Ошибки robots.txt, которые определяет Labrika
Сервис находит следующие виды ошибок:
Директива должна отделятся от правила символом «:».
Каждая действительная строка в файле robots.txt должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
Пустая директива и пустое правило.
Не указан пользовательский агент.
Пример ошибки в директиве Sitemap:
Не указан путь к карте сайта.
Перед правилом нет директивы User-agent
Найдено несколько правил вида «User-agent: *»
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле robots.txt несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования robots.txt Яндекса).
Причины этого могут быть следующие:
Директивы «Disalow» не существует, допущена ошибка в написании слова.
Количество правил в файле robots.txt превышает максимально допустимое
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к UTF-8. В таком случае правила из файла robots.txt не будут работать.
Использование кириллицы и других национальных языков
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Например:
Директива запрещает индексировать любые php файлы.
Символ «$» прописан в середине значения
Знак «$» можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Правило начинается не с символа «/» и не с символа «*».
Правило может начинаться только с символов «/» и «*».
Если значение пути указывается относительно корневого каталога сайта, оно должно начинаться с символа слэш «/», обозначающего корневой каталог.
Правильным вариантом будет:
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), название домена, путь к файлу карты сайта, а также имя файла.
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
С марта 2018 года Яндекс отказался от директивы Host. Вместо неё используется раздел «Переезд сайта» в Вебмастере и 301 редирект.
Некорректный формат директивы Crawl-delay
При указании в директиве Crawl-delay интервала между загрузками страниц можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды.
Некорректный формат директивы Clean-param
В именах GET-параметров встречается два или более знака амперсанд «&» подряд:
Правило должно соответствовать виду «p0[&p1&p2&..&pn] [path]». В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: «.», «-«, «/», «*», «_».
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
Стандартные редакторы, создавая файл, могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Директивы Disallow и Allow: как использовать совместно и раздельно
В данной статье речь пойдет о самых популярных директивах Dissalow и Allow в файле robots.txt.
Disallow
Disallow – директива, запрещающая индексирование отдельных страниц, групп страниц, их отдельных файлов и разделов сайта(папок). Это наиболее часто используемая директива, которая исключает из индекса:
Примеры директивы Disallow в robots.txt:
Правило Disallow работает с масками, позволяющими проводить операции с группами файлов или папок.
После данной директивы необходимо ставить пробел, а в конце строки пробел недопустим. В одной строке с Disallow через пробел можно написать комментарий после символа “#”.
Allow
В отличие от Disallow, данное указание разрешает индексацию определенных страниц, разделов или файлов сайта. У директивы Allow схожий синтаксис, что и у Disallow.
Хотя окончательное решение о посещении вашего сайта роботами принимает поисковая система, данное правило дополнительно призывает их это делать.
Примеры Allow в robots.txt:
Для директивы применяются аналогичные правила, что и для Disallow.
Совместная интерпретация директив
Поисковые системы используют Allow и Disallow из одного User-agent блока последовательно, сортируя их по длине префикса URL, начиная от меньшего к большему. Если для конкретной страницы веб-сайта подходит применение нескольких правил, поисковый бот выбирает последний из списка. Поэтому порядок написания директив в robots никак не сказывается на их использовании роботами.
На заметку. Если директивы имеют одинаковую длину префиксов и при этом конфликтуют между собой, то предпочтительнее будет Allow.
Пример robots.txt написанный оптимизатором:
Пример отсортированного файл robots.txt поисковой системой:
Пустые Allow и Disallow
Когда в директивах отсутствуют какие-либо параметры, поисковый бот интерпретирует их так:
Специальные символы в директивах
В параметрах запрещающей директивы Disallow и разрешающей директивы Allow можно применять специальные символы “$” и “*”, чтобы задать конкретные регулярные выражения.
Специальный символ “*” разрешает индексировать все страницы с параметром, указанным в директиве. К примеру, параметр /katalog* значит, что для ботов открыты страницы /katalog, /katalog-tovarov, /katalog-1 и прочие. Спецсимвол означает все возможные последовательности символов, даже пустые.
Примеры:
По стандарту в конце любой инструкции, описанной в Robots, указывается специальный символ “*”, но делать это не обязательно.
Пример:
Для отмены данного спецсимвола в конце директивы применяют другой спецсимвол – “$”.
Пример:
На заметку. Символ “$” не запрещает прописанный в конце “*”.
Пример:
Более сложные примеры:
Примеры совместного применения Allow и Disallow
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
«Вкалывают роботы»: что такое robots.txt и как его настроить

Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Пример:
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Даем рекомендацию, чтобы индексировались категории.
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
Sitemap
Пример:
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
Переходим в инструмент, вводим домен и содержимое вашего файла.

Нажимаем « Проверить » и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
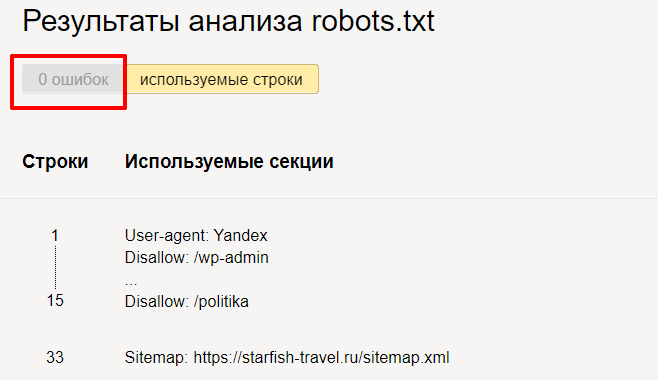
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
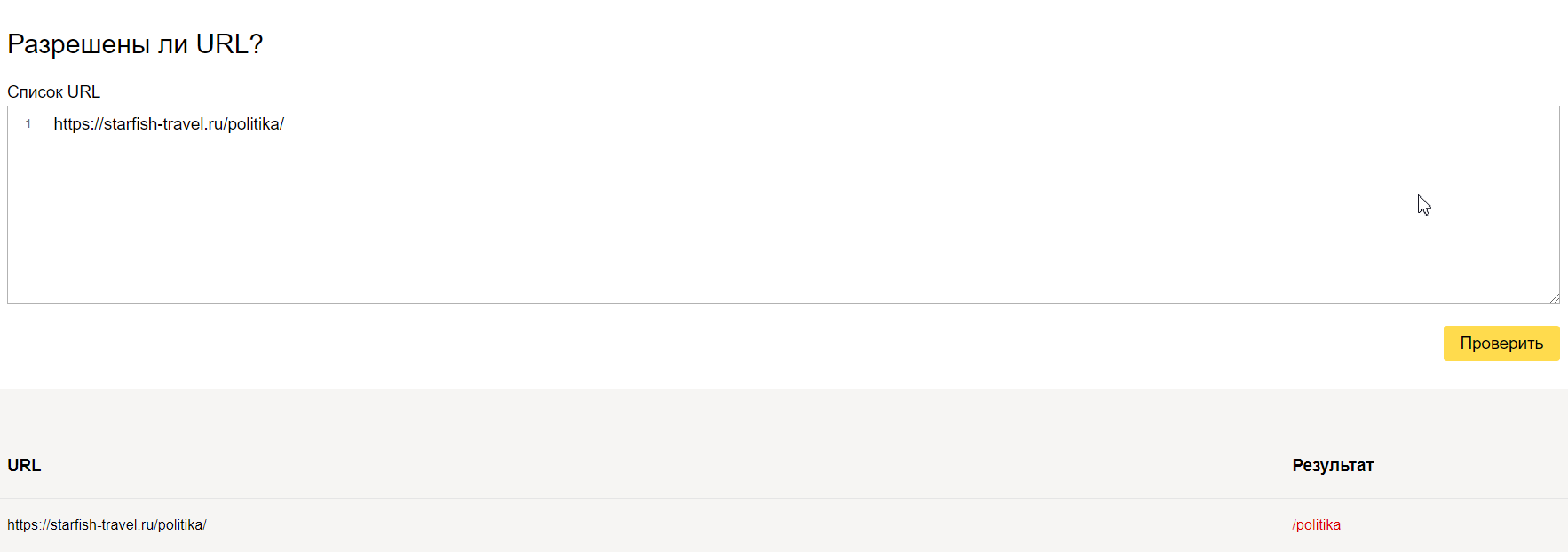
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
Правильный robots.txt для Joomla
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Рекомендации по настройке файла robots txt
Файл robots.txt для сайта
Robots.txt для сайта – это индексный текстовый файл в кодировке UTF-8.
Индексным его назвали потому, что в нем прописываются рекомендации для поисковых роботов – какие страницы нужно просканировать, а какие не нужно.
Если кодировка файла отличается от UTF-8, то поисковые роботы могут неправильно воспринимать находящуюся в нем информацию.
Файл действителен для протоколов http, https, ftp, а также имеет «силу» только в пределах хоста/протокола/номера порта, на котором размещен.
Где находится robots.txt на сайте?
У файла robots.txt может быть только одно расположение – корневой каталог на хостинге. Выглядит это примерно вот так: http://vash-site.xyz/robots.txt
Директивы файла robots txt для сайта
Обязательными составляющими файла robots.txt для сайта являются правило Disallow и инструкция User-agent. Есть и второстепенные правила.
Правило Disallow
Disallow – это правило, с помощью которого поисковому роботу сообщается информация о том, какие страницы сканировать нет смысла. И сразу же несколько конкретных примеров применения этого правила:


Продвижение сайтов в таком случае будет бесполезно. Применение этого примера актуально в том случае, если сайт «закрыт» на доработку (например, неправильно функционирует). В этом случае сайту в поисковой выдаче не место, поэтому его нужно через файл robots txt закрыть от индексации. Разумеется, после того, как сайт будет доработан, запрет на индексирование надо снять, но об этом забывают.
Пример 3 – запрещено сканирование всех документов, находящихся в папке /papka/:

Пример 4 – запретить индексацию страницы с конкретным URL:
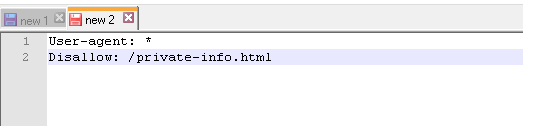
Пример 5 – запрещено индексировать конкретный файл (в данном случае – изображение):


Правило Allow в robots txt
Правило Allow все делает с точностью до наоборот – разрешает индексирование файла/папки/страницы.
И сразу же конкретный пример:
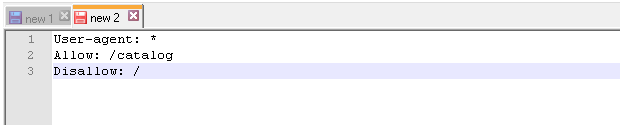
Мы с вами уже знаем, что с помощью директивы Disallow: / мы можем закрыть сайт от индексации robots txt. В то же время у нас есть правило Allow: /catalog, которое разрешает сканирование папки /catalog. Поэтому комбинацию этих двух правил поисковые роботы будут воспринимать как «запрещено сканировать сайт, за исключением папки /catalog»
Сортировка правил и директив Allow и Disallow производится по возрастанию длины префикса URL и применяется последовательно. Если для одной и той же страницы подходит несколько правил, то робот выбирает последнее подходящее из списка.
В данном случае будет приоритетнее директива Allow, т.к. оно находится ниже по списку:
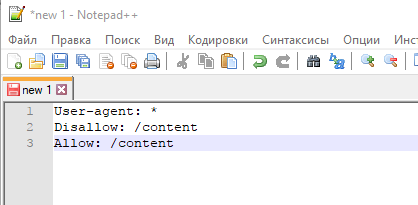
А вот здесь приоритетным является директива Disallow по тем же причинам (ниже по списку):

User-agent в robots txt
User-agent — правило, являющееся «обращением» к поисковому роботу, мол, «список рекомендаций специально для вас» (к слову, списков в robots.txt может быть несколько – для разных поисковых роботов от Google и Яндекс).
Например, в данном случае мы говорим «Эй, Googlebot, иди сюда, тут для тебя специально подготовленный список рекомендаций», а он такой «ОК, специально для меня – значит специально для меня» и другие списки сканировать не будет.
Правильный robots txt для Google (Googlebot)


И последний вариант – рекомендации для всех поисковых роботов (кроме тех, у которых отдельные списки). Через «звездочку» было решено сделать по одной простой причине – чтоб не перечислять «поименно» все 300 с чем-то роботов.

Т.е. если в одном и том же robots.txt есть 3 списка с User-agent: *, User-agent: Googlebot и User-agent: Yandex, это значит, первый является «одним для всех», за исключением Googlebot и Яндекс, т.к. для них есть «личные» списки.
Sitemap
Т.е. каждый раз поисковый робот будет просматривать карту сайта на предмет появления новых адресов, а затем переходить по ним для дальнейшего сканирования, дабы освежить информацию о сайте в базах данных поисковой системы.
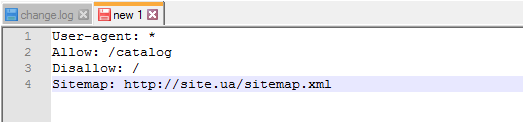
Правило Sitemap должно быть вписано в Robots.txt следующим образом:
Директива Host
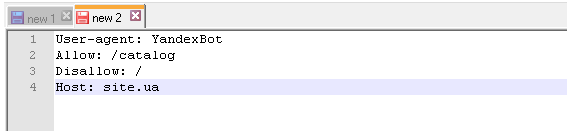
«Зеркалом сайта» принято называть либо точную, либо почти точную «копию» сайта, которая доступна по другому адресу.
Адрес основного зеркала обязательно должно быть указано следующим образом:
— для сайтов, работающих по https – Host: https://site.ua (т.е. https:// прописывается в обязательном порядке)
Пример директивы host в robots txt для сайта на протоколе HTTPS:

Crawl delay
В отличие от предыдущих, параметр Crawl-delay уже не является обязательным. Основная его задача – подсказать поисковому роботу, в течение скольких секунд будут грузиться страницы. Обычно применяется в том случае, если Вы используете слабые сервера. Актуален только для Яндекса.

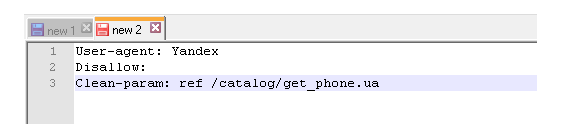
Clean param
С помощью директивы Clean-param можно бороться с get-параметрами, чтобы не происходило дублирование контента, т.к. один и тот же контент бывает доступен по разным динамическим ссылкам (это те, которые со знаками вопроса). Динамические ссылки могут генерироваться сайтом в том случае, когда используются различные сортировки, применяются идентификаторы сессий и т.д.
Например, один и тот же контент может быть доступен по трем адресам:
В таком случае директива Clean-param оформляется вот так:
Самые частые вопросы
Как в robots.txt запретить индексацию?
Для этих целей придумано правило Disallow: т.е. копируем ссылку на документ/файл, который нужно закрыть от индексации, вставляем ее после двоеточия:
Ну а если требуется закрыть от индексирования все файлы с определенным расширением, то правила будут выглядеть следующим образом:
Как в robots.txt указать главное зеркало?
Для этих целей придумана директива Host. Т.е. если адреса http://your-site.xyz и http://yoursite.com являются «зеркалами» одного и того же сайта, то одно из них необходимо указать в директиве Host. Пусть основным зеркалом будет http://your-site.xyz. В этом случае правильными вариантами будут следующие:
— если сайт работает по https-протоколу, то нужно делать только так:
— если сайт работает по http-протоколу, то оба приведенных ниже варианта будут верными:
Однако, следует помнить, директива Host является рекомендацией, а не правилом. Т.е. не исключено, что в Host будет указан один домен, а Яндекс посчитает за основное зеркало другой, если у него в панели вебмастера введены соответствующие настройки.
Простейший пример правильного robots.txt
В таком виде файл robots.txt можно разместить практически на любом сайте (с мельчайшими корректировками).

Давайте теперь разберем, что тут есть.
НО… Это НЕ значит, что нужно оформлять robots.txt именно так. Правила должны быть прописаны строго индивидуально для каждого сайта. Например, нет смысла индексировать «технические» страницы (страницы ввода логина-пароля, либо тестовые страницы, на которых отрабатывается новый дизайн сайта, и т.д.). Правила, кстати, зависят еще и от используемой CMS.
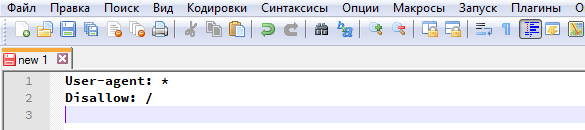
Закрытый от индексации сайт – как выглядит robots.txt?
Даем сразу же готовый код, который позволит запретить индексацию сайта независимо от CMS:
Как указать главное зеркало для сайта на https robots.txt?
ВАЖНО. Для https-сайтов протокол должен указываться строго обязательно!

Наиболее частые ошибки в robots.txt
Специально для Вас мы приготовили подборку самых распространенных ошибок, допускаемых в robots.txt. Почти все эти ошибки объединяет одно – они допускаются по невнимательности.
1. Перепутанные инструкции:


2. В один Disallow вставляется куча папок:

В такой записи робот может запутаться. Какую папку нельзя индексировать? Первую? Последнюю? Или все? Или как? Или что? Одна папка = одно правило Disallow и никак иначе.

4. Правило User-agent запрещено оставлять пустым. Либо указываем имя поискового робота (например, для Яндекса), либо ставим звездочку (для всех остальных).
5. Мусор в файле (лишние слэши, звездочки и т.д.).
6. Добавление в файл полных адресов скрываемых страниц, причем иногда даже без правила Disallow.
Онлайн-проверка файла robots.txt
Существует несколько способов проверки файла robots.txt на соответствие общепринятому в интернете стандарту.
Способ 1. Зарегистрироваться в панелях веб-мастера Яндекс и Google. Единственный минус – придется покопаться, чтоб разобраться с функционалом. Далее вносятся рекомендованные изменения и готовый файл закачивается на хостинг.
Способ 2. Воспользоваться онлайн-сервисами:
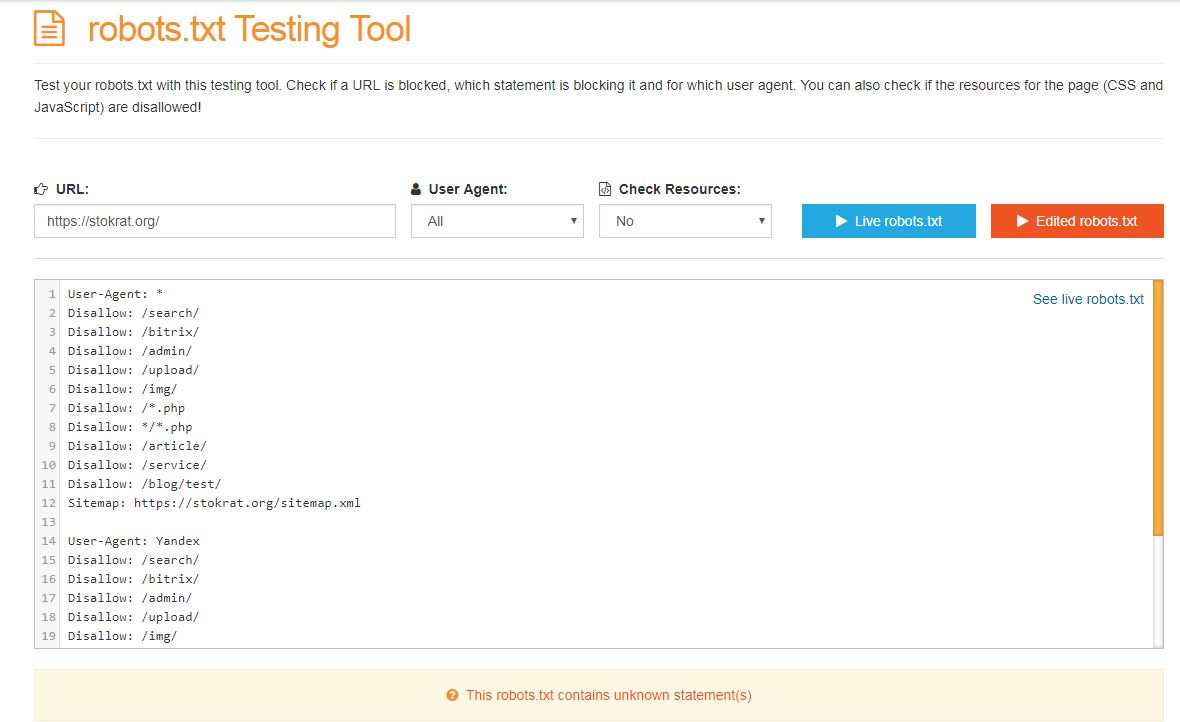
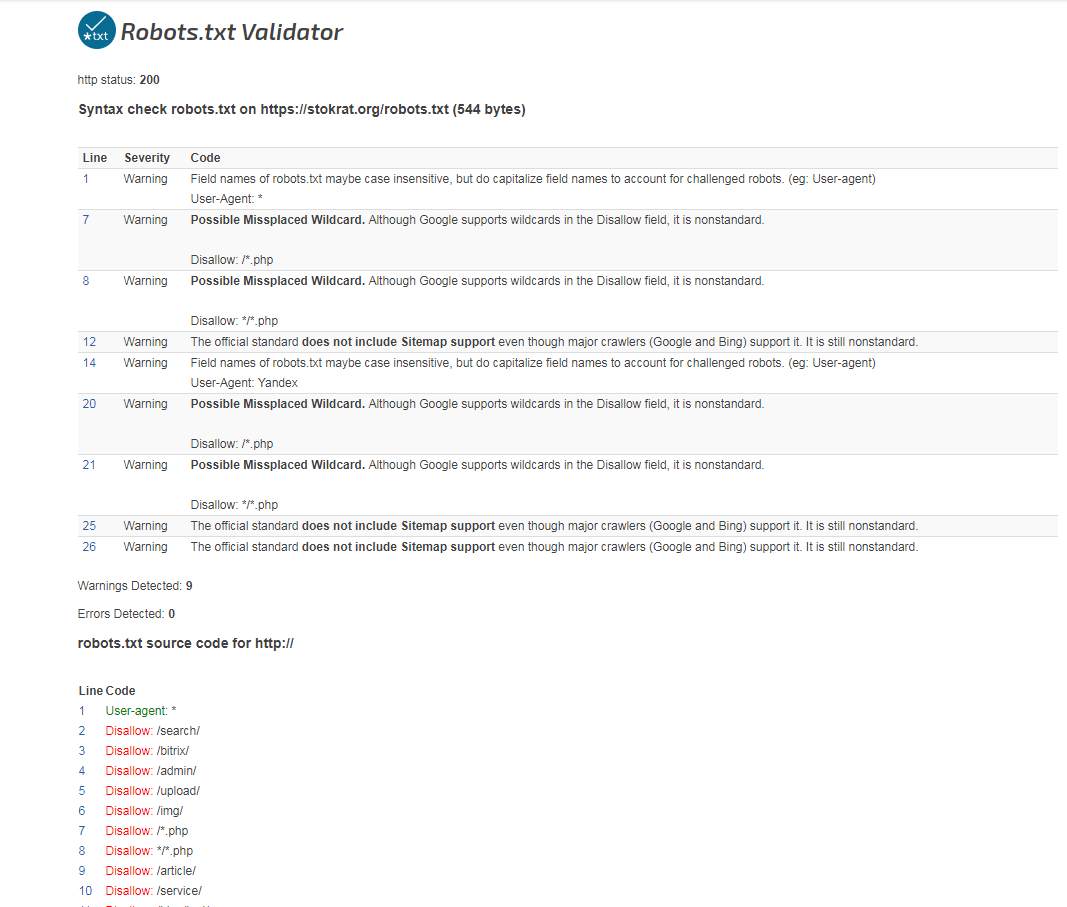
Итак, robots.txt сформирован. Осталось только проверить его на ошибки. Лучше всего использовать для этого инструменты, предлагаемые самими поисковыми системами.
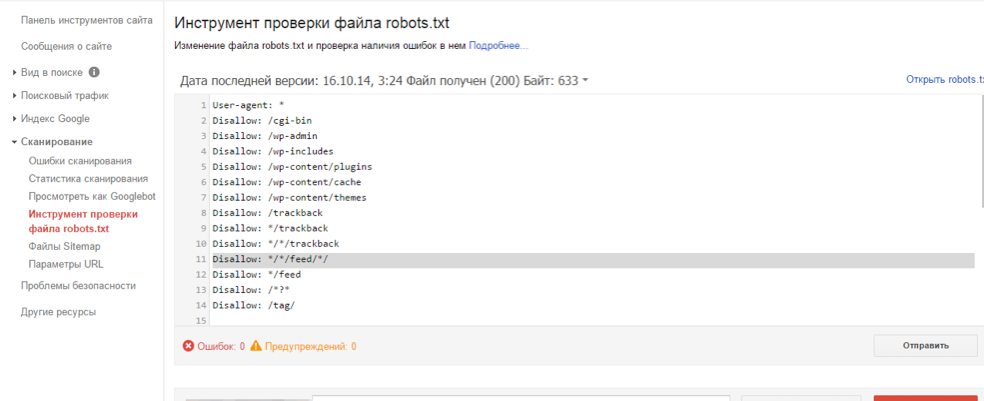
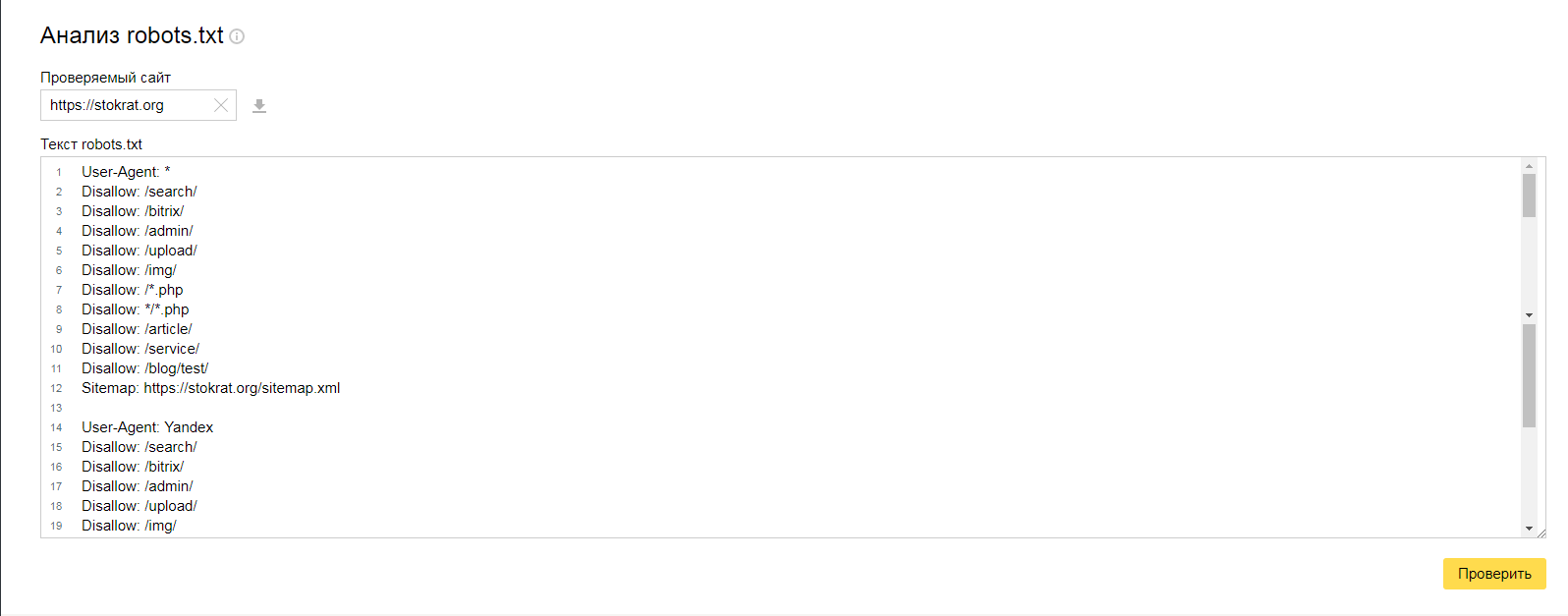
Является аналогом предыдущего, за исключением:
Готовые решения для самых популярных CMS
Правильный robots.txt для WordPress
Disallow: /cgi-bin # классика жанра
Disallow: /? # любые параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /search # поиск
Disallow: /author/ # архив автора
Disallow: *?attachment_id= # страница вложения. Вообще-то на ней редирект.
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */page/ # все виды пагинации
Allow: */uploads # открываем uploads
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д.
#Disallow: /wp/ # когда WP установлен в подкаталог wp
Host: www.site.ru # для Яндекса и Mail.RU. (межсекционная)
# Не забудьте поменять `site.ru` на ваш сайт.
Давайте разберем код файла robots txt для WordPress CMS:
Здесь мы указываем, что все правила актуальны для всех поисковых роботов (за исключением тех, для кого составлены «персональные» списки). Если список составляется для какого-то конкретного робота, то * меняется на имя робота:
Здесь мы осознанно даем добро на индексирование ссылок, в которых содержится /uploads. В данном случае это правило является обязательным, т.к. в движке WordPress есть директория /wp-content/uploads (в которой вполне могут содержаться картинки, либо другой «открытый» контент), индексирование которой запрещено правилом Disallow: /wp-. Поэтому с помощью Allow: */uploads мы делаем исключение из правила Disallow: /wp-.
В остальном просто идут запреты на индексирование:
Disallow: /cgi-bin – запрет на индексирование скриптов
Disallow: /feed – запрет на сканирование RSS-фида
Disallow: /trackback – запрет сканирования уведомлений
Правило Sitemap: http://site.ru/sitemap.xml указывает Яндекс-роботу путь к файлу с xml-картой. Путь должен быть прописан полностью. Если таких файлов несколько – прописываем несколько Sitemap-правил (1 файл = 1 правило).
В строке Host: site.ru мы специально для Яндекса прописали основное зеркало сайта. Оно указывается для того, чтоб остальные зеркала индексировались одинаково. Пустая строка перед Host: является обязательной.
Файл robots.txt для Joomla
Joomla — почти самый популярный движок у вебмастеров, т.к. не смотря на широчайшие возможности и множества готовых решений, он поставляется бесплатно. Однако, штатный robots.txt всегда имеет смысл подправить, т.к. для индексирования открыто слишком много «мусора», но картинки закрыты (это плохо).
Вот так выглядит правильный robots.txt для Joomla :
robots.txt Wix
Платформа Wix автоматически генерирует файлы robots.txt персонально для каждого сайта Wix. Т.е. к Вашему домену добавляете /robots.txt (например: www.domain.com/robots.txt) и можете спокойно изучить содержимое файла robots.txt, находящегося на Вашем сайте.
Отредактировать robots.txt нельзя. Однако с помощью noindex можно закрыть какие-то конкретные страницы от индексирования.
robots.txt для Opencart
Стандартный файл robots.txt для OpenCart:
robots.txt для Битрикс (Bitrix)
1. Папки /bitrix и /cgi-bin должны быть закрыты, т.к. это чисто технический «хлам», который незачем светить в поисковой выдаче.
2. Папка /search тоже не представляет интереса ни для пользователей, ни для поисковых систем. Да и образование дублей никому не нужно. Поэтому тоже ее закрываем.
3. Про формы PHP-аутентификации и авторизации на сайте тоже забывать нельзя – закрываем.
4. Материалы для печати (например, счета на оплату) тоже нет смысла светить в поисковой выдаче. Закрываем.
5. Один из жирных плюсов «Битрикса» в том, что он фиксирует всю историю сайта – кто когда залогинился, кто когда сменил пароль, и прочую конфиденциальную информацию, утечка которой не допустима. Поэтому закрываем:
7. Папку /upload необходимо закрывать строго по обстоятельствам. Если там хранятся фотографии и видеоматериалы, размещенные на страницах, то ее скрывать не нужно, чтоб не срезать дополнительный трафик. Ну а если что-то конфиденциальное – однозначно закрываем:
Готовый файл robots.txt для Битрикс:
robots.txt для Modx и Modx Revo
CMS Modx Revo тоже не лишена проблемы дублей. Однако, она не так сильно обострена, как в Битриксе. Теперь о ее решении.
Disallow: /index.php # т.к. это дубль главной страницы сайта
Disallow: /*? # разом решаем проблему с дублями для всех страниц
Готовый файл robots.txt для Modx и Modx Revo:
Выводы
Без преувеличения файл robots.txt можно назвать «поводырём для поисковых роботов Яндекс и Гугл» (разумеется, если он составлен правильно). Если файл robots txt отсутствует, то его нужно обязательно создать и загрузить на хостинг Вашего сайта. Справка Disallow правил описаны выше в этой статьей и вы можете смело их использоваться в своих целях.
Еще раз резюмируем правила/директивы/инструкции для robots.txt:
Знаки при составлении robots.txt:
Частые вопросы по Robots.txt
► Что такое файл robots.txt?
Robots.txt – это индексный текстовый файл в кодировке UTF-8.
► Как в robots.txt запретить индексацию?
Для этих целей придумано правило Disallow: т.е. копируем ссылку на документ/файл, который нужно закрыть от индексации, вставляем ее после двоеточия.



