Среды, код и релизы
Лучшие практики по именованию и разграничению сред в соответствии с их предназначением, взаимному соответствию сред и ветвей кода, и процессу выпуска.
Именование сред
Разработки [dev] — та среда (база данных, сайт, ВМ и т.д.), где развёртываем свежий код и смотрим, что получается.
Демо [demo] — тут промежуточный результат показывается заказчику. Пока развёрнутый здесь полуготовый функционал ждёт внимания заказчика, на [dev] можно всё сломать, работая дальше.
Тестовая [test] — тут тестируется функциональность. Среда наполнена тестовыми данными, которые могут отражать редко возникающие (в рабочей среде) случаи или быть удобными для тестирования. Пока тут идёт тестирование того, что готовится в продакшен, на [dev] уже появляется код следующего релиза.
Промежуточная [stage], она же предпродакшен — тут тестируется развёртывание. Сюда развёртывается последний бэкап системы из продакшена, чтобы проверить обновление на версию.
Продакшен [prod] — тут работают пользователи.
Связь с кодом
В зависимости от системы бывает, что код идёт в развёртывание вместе с конфигурацией (набором переносимых настроек). При этом, сам код ведётся в репозитории, а конфигурация в среде.
Изначально, код, попадающий в ветвь /dev, выкатывается в среду [dev], где настраивается конфигурация к нему. Затем, код и конфигурация (иногда по частям) переносятся в другие среды.
Путь кода
То, что исправляется в /main при тестировании, естественно → /dev.
Путь конфигурации
[dev] → экспорт в репозиторий отдельно от кода.
Ошибки проектирования систем
Рассмотрим, что в архитектуре системы может сделать невозможным гладкий выпуск.
Двусторонняя зависимость
Бывает, что часть конфигурации зависит от кода (нельзя настроить, пока не выкатится какая-либо сборка), но часть кода зависит от конфигурации (это код, который опирается на структуры в базе данных, которые создаются конфигуратором, либо на сборки, которые собираются конфигуратором).
То, что делает путь релиза таким трудным или уникальным — ошибка архитектуры. Её совершают из побуждений «сделать что-то автоматическим», закладывая возможность в единый конфигуратор системы, вместо того, чтобы закладывать в более низко-уровневые инструменты, или «получить быстрый результат», используя такую возможность.
Бывает, что в покупной системе есть несколько путей создания вещей, таких как структуры данных или объекты. Например, в ELMA-BPM есть создание объектов через конфигуратор, а есть через плагин к Visual Studio. Выбирайте более низко-уровневый способ, иначе попадёте на описанную двустороннюю зависимость.
Логика в базе данных
Переразвернуть базу данных гораздо сложнее чем пересобрать код.
Из-за этого, в системах, где много логики в базе, разработчики работают на одном общем экземпляре БД. Обычно они говорят, что им нужна общая БД для разработки, так как: а) там всегда развёрнут последний код от каждого из них и б) там готовы тестовые данные.
Из-за постоянной работы в общей базе (читай «среде»), в свою очередь, теряется смысл ветвления кода в репозитории.
В итоге, от /dev бессмысленно отделять ветви фич, что, в свою очередь, не позволяет выделять длинные работы и делать релизы независящими от них.
Кроме того, поскольку перенос из среды в среду (ибо это из базы в базу) сложнее, количество сред в процессе пытаются сократить, не выходя за [dev] → [stage] → [prod] (а то и [dev] → [prod]). Тестируют и демонстрируют функционал прямо на [dev].
Логика в БД сегодня, это ошибка архитектуры (по многим причинам), которую, наверное, мало кто будет отрицать (хотя случается и такое). В данном случае, это ограничение для повышения качества и сокращения цикла выпуска.
Готовим тестовое окружение, или сколько тестовых инстансов вам нужно
Сколько в вашем проекте тестовых стендов — 5, 10 или больше 10? Навскидку, нужны стенды для каждой команды разработки, стенды для QA под каждый проект, менеджерам проектов тоже нужны стенды, а еще CI — трудно это все точно разграничить и не вызвать конфликтные ситуации. Одним словом, почему бы нам не делать тестовый стенд ровно тогда, когда он нужен? Нужен сейчас тестовый стенд — мы его сделали, не нужен — мы его удалили.
Именно такой подход предложил Александр Дубровин (adbrvn) на Highload++ 2017 в своем докладе, расшифровку которого вы найдете под катом.
О спикере: Александр Дубровин работает в Superjob. Известно, что проекты этой компании высоконагруженные. Но сегодня мы не будем говорить о том, сколько пользователей посещают портал, и сколько данных хранится на серверах, а затронем другие показатели.
Забегая вперед, скажем, что, на самом деле, Superjob не знают, сколько у них тестовых стендов. Но обо всем по порядку. Начнем с небольшой истории.
Немного истории
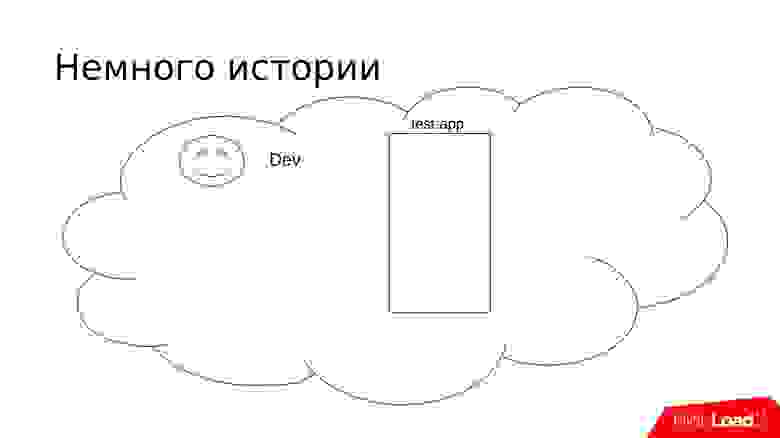
Представим себе небольшой проект S. В нем есть команда разработчиков, которым надо где-то тестировать свой код. Чтобы организовать тестирование, мы поставим тестовую машину, сделаем ее похожей на продакшен, накатим туда код, запустим и разработчики смогут там что-то тестировать.
В какой-то момент команда начинает расти, и необходим штат тестировщиков. Появляются QA-специалисты, и им тоже нужно где-то тестировать.
Можно использовать простой подход — выделить какой-то участок для тестировщиков, накатить туда такую же копию, и вот они уже могут тестировать. Все замечательно и хорошо!
Проект продолжает расти, и появляется дополнительная команда разработки. Им также требуется где-то что-то тестировать. Подход уже знаком — мы отделяем еще одну часть тестового сервера.
Но на самом деле команды тоже растут — по одному тестовому стенду им становится мало. Задач они тоже делают больше, поэтому тестировщикам нужно много тестировать.
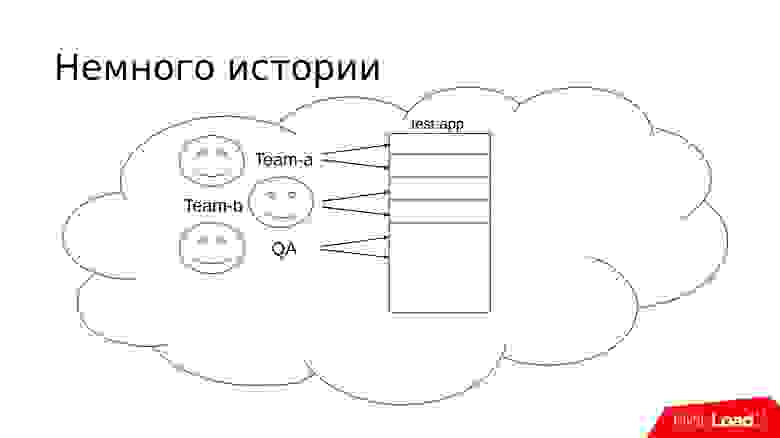
Примерно в такой стадии можно начать замечать интересные истории. Допустим, есть тестировщик Вася, который хочет протестировать какую-то задачу. Он выбирает тестовый стенд, раскатывает туда код и начинает тестировать. Кликает, кликает и понимает, что что-то не то, что-то не работает, и вообще задача не сделана.
В JIRA начинают падать тикеты, возле Васи начинают собираться разработчики со словами: «Да как же так? Все же сделано!» и кто-то наконец спрашивает: «А у тебя какая ветка на тест раскатана?» Вася смотрит — не та. Ветка быстро исправляется, тикеты в JIRA закрываются, все хорошо. Вася продолжает тестировать, у него все работает.
Но в это время в другом конце комнаты разработчик Вова думает: «Странно, а почему у меня не работает?» Но он быстро понимает, что ветка не та. Раскатывает ту, что нужно, и проблемы снова у Васи.
За пару итераций они понимают, что они просто тестируют на одном тестовом стенде и мешают друг другу. В результате время потрачено впустую, Вася и Вова недовольны.
Другая история. Разработчик Коля знает про Васины проблемы, заранее приходит к нему и спрашивает, какой тестовый стенд сейчас свободен. Вася указывает свободный, и все хорошо. Через пару дней они встречаются снова, и Вася спрашивает у Коли: «Ты нам тестовый стенд вернешь? Ты его занимал на часок, а уже 2 дня прошло».
И снова проблема — либо разработчику искать другой стенд, либо все будут бодро ждать, пока он закончит тестирование.
На самом деле на схеме выше отображено не все. Здесь не хватает менеджеров. Иногда менеджеры хотят смотреть еще не протестированный сырой код. Подход стандартный — мы снова выделяем уголок тестового сервера и делаем еще тестовые стенды.
Плавно развивая такую схему, мы получаем бесконтрольное изменение тестовых стендов. Схема плоха тем, что мы действительно не контролируем такие стенды — мы не знаем:
В этот момент мы задумались — что же делать? Зачем нам столько тестовых стендов? Почему бы нам не делать тестовый стенд ровно тогда, когда он нужен? Нужен сейчас тестовый стенд — мы его сделали, не нужен — мы его удалили.
Следующий шаг в этой идее — делать тестовый стенд под каждую ветку кода.
Вроде идея хорошая, но есть технические нюансы. Нам нужны стенды:
Суровая реальность
Еще есть суровая реальность, в которой у нас:
Сказано — сделано!
Docker/docker-compose
Во-первых, мы говорили о том, что тестовые стенды должны быть изолированными и максимально похожими. В наше время это позволяет реализовать docker. Он даст возможность запускать контейнеры. Очевидно, что одним контейнером мы не обойдемся, более того, нам надо запускать кучу похожих стеков. Поэтому нужен docker-compose.
Замечательно — мы будем использовать docker — это стильно, модно, молодежно.
Распиливаем монолит выделяем сервисы
Docker пропогандирует микросервисный подход и здесь мы встаем перед проблемой, потому что у нас монолит.
Вы когда-нибудь пробовали оценить, сколько стоит распилить монолит по микросервисам? Очевидно, что эта цифра измеряется в человеко-годах.
В какой-то момент мы посмотрели на компонентную схему нашей системы и увидели, что здесь у нас есть load-balancing, здесь — приложение на php, здесь — node.js-приложение. Почему бы нам не запускать именно это, как сервис. Давайте найдем то, что мы можем запускать в docker-контейнерах.
Настраиваем сеть
Дальше нам необходимо каким-то образом достучаться до нашего тестового стенда. Естественно, нам необходимо вытащить 80-ый порт наружу, чтобы браузер мог открыть наш тестовый стенд, но если такие стенды будут запускаться в рамках одной машины, нам нужно выдавать IP.
В документации имеется целый огромный раздел про настройку сетей.
Docker умеет использовать различные типы сетей. В нашем случае очень помогла сеть типа macvlan. Это технология, которая позволяет на одном физическом сетевом интерфейсе реализовывать пачку виртуальных сетевых интерфейсов. При этом docker сам будет управлять этими интерфейсами: создавать, добавлять на машину и получать уже внешние, по отношению к хост-машине, IP-адреса.
Таким образом мы можем запустить пачку контейнеров, дать фронт-контейнеру (балансеру) возможность получить внешний IP-адрес и открыть на нем 80-ый порт. Мы уже можем постучаться туда при помощи браузера.
Поднимаем DNS и API
Мы помним, что у нас есть доменные зоны и куча поддоменов. Таким образом, обратиться к тестовому стенду мы можем только по домену 2-го уровня. Здесь есть как колоссальный плюс, так и колоссальный минус:
Минус обходится на самом деле просто. Если нам приходится перекрывать домены, мы просто добавляем префикс и таким образом ограничиваем набор перекрываемых доменов — с этим уже можно мириться.
В нашем случае мы выбрали префикс sj. Получается, нам приходится перекрывать домены только с префиксом sj — таких явно немного.
Еще одна часть DNS — это API. Как уже говорилось, необходимо поднимать тестовые стенды быстро. Поэтому нам нужен DNS-сервер, который позволяет быстро добавлять и быстро убирать запись по API в автоматическом режиме.
Решение — PowerDNS. Этот сервер позволяет достаточно быстро и просто прикрутить к нему API и при помощи скриптов добавлять и удалять тестовые стенды.
Замечательно! Мы подняли и настроили DNS, научили наши контейнеры в него прописывать свои IP, но чего-то не хватает.
Делаем SSL-CA
Мы живем в XXI веке. Очевидно, что весь интернет — SSL и тестовые стенды должны поддерживать SSL. Достаточно много багов специфичны для SSL, и mixed content — только вершина айсберга.
Итого, нам нужен способ быстро получить сертификат и быстро его применить на поднимающийся тестовый стенд. В нашей компании уже был центр сертификации, основанный на OpenSSL. Здесь мы пошли простым методом написания своего велосипеда.
Велосипед пишется за один день и позволяет при помощи GET-запросов получать сертификаты, сгенерированные уже на конкретное имя домена.
Осталось самое малое. Нужно это автоматизировать, потому что мы же хотим все это делать одной кнопкой.
Автоматизируем
Для себя на начальном этапе мы написали консольный скрипт, который позволяет просто поднять тестовый стенд или его удалить.
Очевидно, тестировщикам это не очень удобно. Поэтому можно, например, сделать специальную сборку, которая соберет тестовый стенд и запустит его.
Но на самом деле самый крутой шаг в этом плане — это добавить такую кнопку прямо в JIRA-тикет. Представьте, ваш тестировщик открывает JIRA-тикет, читает требование, нажимает кнопку и получает через пару минут тестовый стенд — здорово же?
Плюсы
Минусы
Но есть и минусы, я бы сказал, нюансы в управлении стендов. Нужно научиться правильно ими управлять.
Первую версию своей системы мы выкатили на старый слабый сервер и настроили создание тестовых стендов под каждую новую ветку. Конечно, где-то через день-полтора сервер не справился — просто потому, что веток появляется очень много.
Тогда, мы перестали их создавать автоматически, а появилась кнопка в JIRA, CI научилась запускать и останавливать тестовые стенды, собирать с них логи.
Определенно есть класс задач, которые эта система не позволит решать. Например, часто всплывающая проблема — это общее время для всех контейнеров. Некоторые задачи было бы удобно тестировать, сдвинув время на сервере. Эта система, к сожалению, не позволяет решать такие задачи. Но такие задачи можно решить, добавив в код специальные ветки для тестирования, чтобы можно было, например, посмотреть, как поведет себя форма через 2 недели.
На входе мы имели систему тестовых стендов, которая заставляла нас искать тестовый стенд и не гарантировала нам то, что никто не будет мешать друг другу на этих тестовых стендах.
Было: «Вася, а какой тестовый свободный — мне свою задачу раскатить потестировать».
На выходе получилась одна кнопка, которую можно нажать и получить через пару минут готовый тестовый стенд под конкретную версию кода. Даже если этим стендом будет пользоваться несколько человек, гарантировано то, что эти люди хотят смотреть именно эту версию кода.
Стало: «Жму кнопку и через полторы минуты получаю новый тестовый стенд под конкретную задачу».
Бонусом мы получили все тесты в один клик. Как я уже говорил, любые тесты на любой ветке прямо из CI выбираются одной кнопкой. Дальше машина все сделает сама: поднимет тестовый стенд, обстреляет его, соберет с него логи и удалит.
Возвращаясь к своему первому вопросу, сколько же тестовых стендов нам нужно? Я не знаю, сколько нам нужно тестовых стендов, потому что сегодня их нужно 20, завтра — 15, послезавтра 25.
Но я точно знаю, что у нас ровно столько тестовых стендов, сколько нужно здесь и сейчас.
Время летит незаметно, и до фестиваля конференций РИТ++ осталось совсем немного, напомним он пройдет 28 и 29 мая в Сколково. Пользуясь случаем, приводим небольшую подборку заявок RootConf для широкого круга слушателей:
Как мы перестали тратить неделю на выдачу dev-стенда
Каждый разработчик хочет свой dev-стенд. Каждый тестировщик хочет свой тестовый стенд. И каждый специалист в препродакшне хочет свой стенд — чтобы все финально проверить и отрепетировать запуск в прод. Когда все эти хотелки сходятся в процессинге — одной из самых крупных и активных систем банка — расходы на инфраструктуру заставляют почесать затылок и поискать «варианты». О том, что нашли мы, расскажем в этом посте.

Объем баз данных процессинга у нас составляет порядка 6 ТБ. На одной копии баз разработчики мешают друг другу, поэтому фактический объем занимаемого базами пространства растет быстро и пропорционально. Хотя как быстро… слишком быстро для службы сопровождения и недостаточно быстро для тех, кому копии баз нужны. И вот почему.
Для тестирования нужно, чтобы тестовый стенд полностью соответствовал текущей версии продакшена (то же самое относится к стенду предпродакшна). Основной бэкап системы копируется в течение целых суток, затем развертывается на стенде. Во время этих длительных операций стенды недоступны, так что копирование переносится на выходные и праздники, когда со стендами никто не работает. Получаем задержку от 1 до 5 дней. Чтобы предварительно согласовать сам процесс копирования, тоже нужно время — ведь тестовых стендов у нас несколько, обычно от трех до шести. Добавляем 2-3 суток на согласование времени простоя стенда. Перед тем, как попасть на согласование к администратору, заявка еще стоит в очереди. В сумме получаем очень большую задержку.
Чем помог Delphix
Что может ускорить процесс и сэкономить место? Виртуализация баз данных. Рассмотрели разные варианты: Oracle SnapClone, NetApp+Oracle Cloud, просто снапшоты на массивах. Всё требует сложной настройки. Решения Oracle, к тому же, работают только с БД Oracle.
Затем присмотрелись к Delphix. Внедрять его просто, он поддерживает разные БД — Oracle, SQL Server, DB2, Sybase ASE. Для всех операций предусмотрен интерфейс. Через него разработчики и тестировщики могут самостоятельно управлять своими копиями — обновлять, сохранять/восстанавливать состояние, останавливать/запускать и т.д. Также есть API и CLI для интеграции с CI/CD системами или своими процессами.
Само развертывание Delphix занимает не очень много времени — несколько часов. Гораздо дольше может подключаться источник, здесь время пропорционально размеру. В нашем случае источником была продовая копия БД, и ее подключение заняло почти сутки. Подготовка источника и серверов для клонов БД особых трудозатрат не требует. На целевом сервере нужно установить подходящий ORACLE_HOME, а еще создать специального пользователя для подключения. Для виртуальных тестовых копий мы используем те же сервера, на которых до этого были физические копии.
Delphix позволяет создавать тестовые стенды практически в реальном времени, без всяких согласований, потому что стенды полностью изолированы друг от друга. Некоторое время тратится лишь на обновление базы данных до актуального состояния — от 20 минут до нескольких часов, ни о каких днях нет и речи.
Мы стараемся проводить нагрузочное тестирование в условиях максимально приближенных к проду. Если прод на физических дисках – то и нагрузочный стенд тоже. В этом случае помогает наличие у Delphix кнопки V2P, которая позволяет сделать «честную» базу из виртуальной.
Что касается экономии дискового пространства, то показания нашего дэшборда Delphix, конечно, привирают — сокращение объема в 73 раза слишком сказочно. У нас в процессинге копия прода с ежедневными снепшотами и архивными журналами транзакций за 2 недели (200 ГБ в сутки) занимает 4,5 ТБ дискового пространства. Еще 1,5 ТБ — девять клонов размеров от 50 до 500 ГБ, каждый из которых тоже хранит историю ежедневных снепшотов. Всего получается 6 ТБ.
Прибавляем еще 15% свободного места (900 ГБ), чтобы Delphix мог нормально работать. Таким образом, затрачивая всего около 7 ТБ, мы можем получить тестовую копию с данными, актуальными на любой момент времени в течение двух последних недель.
Раньше для того, чтобы хранить девять физических копий базы в 6 ТБ, нам требовалось 54 ТБ (или
20 ТБ с учетом сжатия в 2-3 раза на СХД). И, в отличие от новой системы, здесь разработчики не могли управлять этими копиями и восстанавливать предыдущие состояния — при разрушении данных можно было только перезаливать из копии прода.
Также Delphix позволяет быстро делать под разные проекты разные ветки одного и того же контейнера — и все это за минимальное время. Разработчики не боятся повредить данные, они могут откатиться и восстановить предыдущее состояние. Это дает прирост производительности.
Но есть нюансы.
Впечатления от Delphix в основном положительные, хотя идеально не все. Самая большая проблема — с использованием дисков. Каждый блок данных хранится только один раз для всех виртуальных копий, и пока все виртуальные копии не перестанут использовать блок, удалить его невозможно. Здесь могут возникнуть организационные проблемы — не все пользователи готовы поддерживать короткий жизненный цикл своих стендов. Если тестовый стенд живет на старой копии прода, то занимаемое место увеличивается. Мы решаем этот вопрос экстенсивно, расширением дисков, что можно делать без прерывания сервиса. Следим, чтобы всегда сохранялось 15% свободного места. Если его будет меньше, система просто перестанет выполнять любые операции с виртуальными копиями. Хотя сами базы останутся доступны.
Для систем с интенсивным дисковым вводом-выводом пропускная способность сети, скорее всего, будет лимитирующим фактором. В зависимости от конкретного профиля нагрузки система может начать работать лучше при виртуализации. В зависимости от нагрузки среднее время ожидания «db file sequential read» составляет 5-10 мс, что довольно неплохо даже для промышленных систем.
К Delphix «классические» диски подключаются любым способом, который поддерживает ESX, и у вендора есть список рекомендаций, как сделать это с максимальной производительностью. Мы используем SAN. Сама система презентует диски, на которых расположены файлы виртуальных баз, только по протоколу NFS. По этой причине нужно быть внимательными к пропускной способности канала и его загруженности. В нашем случае имеет смысл размещать на дисковых массивах только файлы данных для Delphix, чтобы никакие активности в банке не влияли на скорость ввода/вывода для виртуальных баз.
Сейчас мы работаем на Delphix 5.1.9, но присматриваемся к версии 5.2 — в ней пользовательский интерфейс ушел от флэша и, как утверждает вендор, стал намного удобней. Delphix произвел впечатление на наших коллег, и вслед за процессингом мы подумываем перенести на эту систему разработчиков profile, CRM, интернет-банк.
Стенды разработки без очередей и простоев
Предыстория
В результате, имеющиеся стенды заняты, разработчики простаивают ожидая освобождения одного из стендов.
Создание дополнительных статичных стендов решит проблему, но приведёт к их переизбытку во время снижения активности разработчиков и, как следствие, повысит затраты компании на инфраструктуру.
Задача
Дать возможность разработчикам разворачивать и удалять стенды самостоятельно, исходя из текущих потребностей.
Gitlab CI, Terraform, Bash, любое приватное/публичное облако.
Технические сложности:
Алгоритм
Gitlab CI выполняет pipeline. Связывает все остальные компоненты воедино.
Terraform создаёт и удаляет экземпляры виртуальных машин.
Bash сценарии подготавливают конфигурационные файлы специфичные для каждого стенда.
Структура репозитория
.gitlab-ci.yml:
Остановимся подробнее на каждом шаге нашего пайплайна:
Запуск пайплайна происходит с объявлением переменной NAME_ENV, содержащей имя нового стенда:
Разработчики не имеют доступа к Git репозиторию и могут вносить в него изменения только через запуск pipeline.
modules/base/main.tf:
Чтобы сократить листинг я убрал большую часть обязательных, но, в нашем случае, неважных ресурсов.
Для создания ресурсов, имена которых должны быть уникальными, в рамках нашего облачного аккаунта, мы используем имя окружения.
scripts/env.sh:
При создании нового окружения:
В каталоге DEPLOY_DIR создаётся директория с именем окружения.
Из файла scripts/subnets.txt мы извлекаем одну свободную подсеть.
На основе полученных данных генерируем конфигурационные файлы для Terraform.
Для фиксации результата отправляем каталог с файлами окружения в git репозиторий.
scripts/subnets.txt:
В данном файле мы храним адреса наши подсетей. Размер подсети определяется переменной CIDR в файле scripts/create_env.sh
Результат
Мы получили фундамент который позволяет нам развернуть новый стенд путём запуска pipline’a в Gitlab CI.
Снизили затраты нашей компании на инфраструктуру.
Разработчики не простаивают и могут создавать и удалять стенды когда им это потребуется.
Также получили возможность создания виртуальных машин в любом облаке написав новый модуль Terraform и немного модифицировав сценарий созданиях\удаления окружений
Можем поиграться с триггерами Gitlab и разворачивать новые стенды из пайплайнов команд разработчиков передавая версии сервисов.



