Deep Learning: как это работает? Часть 1
В этой статье вы узнаете
-В чем суть глубокого обучения
-Для чего нужны функции активации
-Какие задачи может решать FCNN
-Каковы недостатки FCNN и с помощью чего с ними бороться
Небольшое вступление
Это начало цикла статей о том, какие задачи есть в DL, сети, архитектуры, принципы работы, как решаются те или иные задачи и почему одно лучше другого.
Какие предварительные навыки для понимания всего нужны? Сказать сложно, но если вы умеете гуглить или правильно задавать вопросы, то, я уверен, мой цикл статей поможет разобраться во многом.
В чем вообще суть глубокого обучения?
Суть в том, чтобы построить некий алгоритм, который принимал бы на вход X и предсказывал Y. Если мы пишем алгоритм Евклида для поиска НОД, то мы просто напишем циклы, условия, присваивания и вот это вот все — мы знаем как построить такой алгоритм. А как построить алгоритм, который на вход принимает изображение и говорит собака там или кошка? Или вовсе ничего? А алгоритм, на вход которого мы подаем текст и хотим узнать — какого он жанра? Вот так просто ручками написать циклы и условия тут не выйдет — тут на помощь и приходят нейронные сети, глубокое обучение и все вот эти модные слова.
Более формально и чуть-чуть о функциях активации
Выражаясь формально, мы хотим построить функцию от функции от функции…от входного параметра X и весов нашей сети W, которая выдавала бы нам некий результат. Тут важно отметить, что мы не можем взять просто много линейных функций, т.к. суперпозиция линейных функций — линейная функция. Тогда любая глубокая сеть аналогична сети с двумя слоями (входом и выходом). Для чего нам нелинейность? Наши параметры, которые мы хотим научиться предсказывать, могут нелинейно зависеть от входных данных. Нелинейность достигается путем использования различных функций активаций на каждом слое.
Fully-connected neural networks(FCNN)
Просто полносвязная нейронная сеть. Выглядит как-то так:
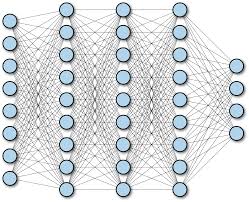
Суть в том, что каждый нейрон одного слоя связан с каждым нейроном следующего и предыдущего (если они есть).
Первый слой — входной. Например, если мы хотим подать изображение 256x256x3 на вход такой сети, то ровно 256x256x3 нейронов во входном слое нам и понадобится (каждый нейрон будет принимать 1 компоненту (R, G или B) пикселя). Если хотим подать рост человека, его вес и еще 23 признака, то понадобится 25 нейронов во входном слое. Кол-во нейронов на выходе — кол-во признаков, которые мы хотим предсказать. Это может быть как 1 признак, так и все 100. В общем случае по выходному слою сети можно почти наверняка сказать — какую задачу она решает.
Каждая связь между нейронами — вес, который тренируется алгоритмом backpropagation, о котором я писал тут.
Какие задачи может решать FCNN
-Задача регрессии. Например, предсказание стоимости магазина по каким-то входным критериям типа страны, города, улицы, проходимости и т.п.
-Задача классификации. Например, классика — MNIST classification.
-Насчет задачи сегментации и обнаружения объектов с помощью FCNN я сказать не возьмусь. Быть может, кто-то поделится в комментариях 🙂
Недостатки FCNN
Искусственный интеллект, машинное обучение и глубокое обучение: в чём разница
Компьютер запросто диагностирует рак, управляет автомобилем и умеет обучаться. Почему же машины пока не захватили власть над человечеством?


Мы пользуемся Google-картами, позволяем сайтам подбирать для нас интересные фильмы и советовать, что купить. И, в общем-то, слышали, что под капотом всех этих умных вещей — искусственный интеллект, машинное обучение и deep learning. Но сможете ли вы с ходу отличить одно от другого? Разбираемся на примерах.
Что такое искусственный интеллект
Искусственный интеллект (англ. artificial intelligence) — это способность компьютера обучаться, принимать решения и выполнять действия, свойственные человеческому интеллекту.
Кроме того, ИИ — это наука на стыке математики, биологии, психологии, кибернетики и ещё кучи всего. Она изучает технологии, которые позволяют человеку писать «интеллектуальные» программы и учить компьютеры решать задачи самостоятельно. Главная задача ИИ — понять, как устроен человеческий интеллект, и смоделировать его.
В области искусственного интеллекта есть подразделы. К ним относятся робототехника, наука о компьютерном зрении, обработка естественного языка и машинное обучение.
Хотите знать, может ли машина мыслить и чувствовать как человек? Приходите на курс «Философия искусственного интеллекта». Здесь вы получите новые знания об ИИ, обсудите актуальные вопросы с преподавателями и однокурсниками и прокачаете навык публичных выступлений.

Пишет про digital и машинное обучение для корпоративных блогов. Топ-автор в категории «Искусственный интеллект» на Medium. Kaggle-эксперт.
Каким бывает искусственный интеллект
Исследователи обычно делят ИИ на три группы:
Слабый ИИ (Weak, или Narrow AI)
Слабый интеллект — тот, что нам уже удалось создать. Такой ИИ способен решать определённую задачу. Зачастую даже лучше, чем человек. Например, как Deep Blue — компьютерная программа, которая обыграла Гарри Каспарова в шахматы ещё в 1996 году. Но такая Deep Blue не умеет делать ничего другого и никогда этому не научится. Слабый ИИ используют в медицине, логистике, банковском деле, бизнесе:
Это несколько примеров, в реальности применений намного больше.
Сильный ИИ (Strong, или General AI)
Как выглядел бы сильный искусственный интеллект, можно увидеть в игре Detroit: Become Human.
Во вселенной Detroit роботы способны учиться, мыслить, чувствовать, осознавать себя и принимать решения. Одним словом, становятся похожи на человека. А в обычной жизни ближе всего к General AI чат-боты и виртуальные ассистенты, которые имитируют человеческое общение. Здесь ключевое слово — имитируют. Siri или Алиса не думают — и неспособны принимать решения в ситуациях, которым их не обучили. Сильный искусственный интеллект пока остаётся мечтой.
Суперинтеллект (Superintelligence)
Мы не только не создали суперинтеллект, но и не имеем пока что ни малейшего представления, как это сделать и можно ли вообще. Это не просто умные машины, а компьютеры, которые во всём превосходят людей. Проще говоря, что-то из области фантастики.
Машинное обучение: как учится ИИ
Машинное обучение (англ. machine learning) — это один из разделов науки об ИИ. Здесь используются алгоритмы для анализа данных, получения выводов или предсказаний в отношении чего-либо. Вместо того чтобы кодировать набор команд вручную, машину обучают и дают ей возможность научиться выполнять поставленную задачу самостоятельно.
Чтобы машина могла принимать решения, необходимы три вещи:
В машинном обучении много разных алгоритмов. Один из самых простых — линейная регрессия. Её применяют, если есть линейная зависимость между переменными. Пример: чем больше сумма заказа, тем больше вы оставите чаевых. По имеющимся данным можно предсказать сумму чаевых в будущем. В общем-то, простая математика.
Есть байесовские алгоритмы. В их основе применение теоремы Байеса и теории вероятности. Эти алгоритмы используют для работы с текстовыми документами — например, для спам-фильтрации. Программе нужно дать наборы данных по категориям «спам» и «не спам». Дальше алгоритм будет самостоятельно оценивать вероятность того, что слова «Бесплатные туры для пенсионеров» и «Закажи маме тур, пожалуйста» относятся к той или иной категории.
А ещё есть нейронные сети, о них вы наверняка слышали. Они относятся к методам глубокого машинного обучения, и об этом чуть подробнее.
Deep learning: глубокое обучение для разных целей
Глубокое обучение — подраздел машинного обучения. Алгоритмам глубокого обучения не нужен учитель, только заранее подготовленные (размеченные) данные.
Самый популярный, но не единственный метод глубокого обучения, — искусственные нейронные сети (ИНС). Они больше всего похожи на то, как устроен человеческий мозг.
Нейронные сети — это набор связанных единиц (нейронов) и нейронных связей (синапсов). Каждое соединение передаёт сигнал от одного нейрона к другому, как в мозге человека. Обычно нейроны и синапсы организованы в слои, чтобы обрабатывать информацию. Первый слой нейросети — это вход, который получает данные. Последний — выход, результат работы. Например, несколько категорий, к одной из которых мы просим отнести то, что было отправлено на вход. И между ними — скрытые слои, которые выполняют преобразование.
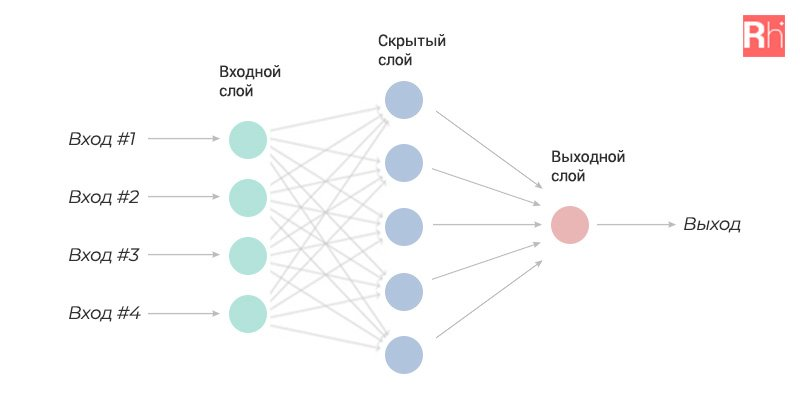
По сути, скрытые слои выполняют какую-то математическую функцию. Мы её не задаём, программа сама учится выводить результат. Можно научить нейросеть классифицировать изображения или находить на изображении нужный объект. Помните, как reCAPTCHA просит найти все изображения грузовиков или светофоров, чтобы доказать, что вы не робот? Нейронная сеть выполняет то же самое, что и наш мозг, — видит знакомые элементы и понимает: «О, кажется, это грузовик!»
А ещё нейросети могут генерировать объекты: музыку, тексты, изображения. Например, компания Botnik скормила нейросети все книги про Гарри Поттера и попросила написать свою. Получился «Гарри Поттер и портрет того, что выглядит как огромная куча пепла». Звучит немного странно, но как минимум с точки зрения грамматики это сочинение имеет смысл.
Сегодня нейронные сети могут применяться практически для любой задачи. Например, при диагностике рака, прогнозировании продаж, идентификации лиц в системах безопасности, машинных переводах, обработке фотографий и музыки.
Чтобы обучить нейросеть, нужны гигантские наборы тщательно отобранных данных. Например, для распознавания сортов огурцов нужно обработать 1,5 млн разных фотографий. Не получится просто слить рандомные картинки или текст из интернета — их нужно подготовить: привести к одному формату и удалить то, что точно не подходит (например, мы классифицируем пиццу, а в наборе данных у нас фото грузовика). На разметку данных — подготовку и систематизацию — уходят тысячи человеко-часов.
Чтобы создать новую нейросеть, требуется задать алгоритм, прогнать через него все данные, протестировать и неоднократно оптимизировать. Это сложно и долго. Поэтому иногда проще воспользоваться более простыми алгоритмами — например, регрессией.
Подведём итоги
Искусственный интеллект — одновременно и наука, которая помогает создавать «умные» машины, и способность компьютера обучаться и принимать решения.
Машинное обучение — одна из областей искусственного интеллекта. МО использует алгоритмы для анализа данных и получения выводов.
А глубокое обучение — лишь один из методов машинного обучения, в рамках которого компьютер учится без учителя подспудно, с помощью данных.
Если чувствуете, что вас привлекает проектирование машинного интеллекта, продолжить образование можно на нашем курсе. Вы научитесь писать алгоритмы, собирать и сортировать данные и получите престижную профессию Data Scientist — специалист по машинному обучению.
Первичное, обычно регулярное, обследование тех, у кого нет клинических симптомов. Проводится с целью ранней диагностики заболевания.
До покупки Google, Waymo cars была самостоятельной компанией по производству самопилотируемых автомобилей.
Умный облачный помощник для устройств Apple.
Виртуальный голосовой помощник, созданный компанией «Яндекс».
Одна из основных теорем элементарной теории вероятностей. Позволяет переставить причину и следствие: по известному факту события вычислить вероятность того, что оно было вызвано этой причиной.
Deep learning & Machine learning: в чем разница?
В чем разница между Deep learning и Machine learning? Насколько они похожи или отличаются друг от друга? Насколько они выгодны для бизнеса? Давайте разберемся!
Machine learning и Deep learning – это 2 подмножества искусственного интеллекта (ИИ), которые активно привлекают к себе внимание уже на протяжении двух лет. Если вы хотите получить простое объяснение их различий, то вы в правильном месте!
Прежде всего, давайте посмотрим на некоторые интересные факты и статистику Deep learning и Machine learning:
Любопытно? Теперь попытаемся разобраться, в чем на самом деле разница между Deep learning и Machine learning, и как можно использовать их для новых бизнес-возможностей.
Deep learning & Machine learning
Должно быть, вы имеете элементарное представление о Deep learning и Machine learning. Для чайников представляем несложные определения:
Machine learning для чайников:
Deep learning для чайников:
Подмножество машинного обучения, где алгоритмы создаются и функционируют аналогично машинному обучению, но существует множество уровней этих алгоритмов, каждый из которых обеспечивает различную интерпретацию данных, которые он передает. Такая сеть алгоритмов называется искусственными нейронными сетями. Простыми словами, это напоминает нейронные связи, которые имеются в человеческом мозге.

Взгляните на изображение выше. Это коллекция фотографий кошек и собак. Теперь предположим, что вы хотите идентифицировать изображения собак и кошек отдельно с помощью алгоритмов Machine learning и нейронных сетей Deep learning.
Deep learning & Machine learning: в каких случаях используется Machine learning
Чтобы помочь алгоритму ML классифицировать изображения в коллекции в соответствии с двумя категориями (собаки и кошки), ему необходимо сначала представить эти изображения. Но как алгоритм узнает, какой из них какой?
Deep learning & Machine learning: в каких случаях используется Deep learning
Нейронные сети Deep learning будут использовать другой подход для решения этой проблемы. Основным преимуществом Deep learning является то, что тут не обязательно нужны структурированные / помеченные данные изображений для классификации двух животных. В данном случае, входные данные (данные изображений) отправляются через различные уровни нейронных сетей, причем каждая сеть иерархически определяет специфические особенности изображений.
После обработки данных через различные уровни нейронных сетях система находит соответствующие идентификаторы для классификации обоих животных по их изображениям.

Таким образом, в этом примере мы увидели, что алгоритм машинного обучения требует маркированных/структурированных данных, чтобы понять различия между изображениями кошек и собак, изучить классификацию и затем произвести вывод.
С другой стороны, сеть глубокого обучения смогла классифицировать изображения обоих животных по данным, обработанным в слоях сети. Для этого не потребовались какие-либо маркированные/структурированные данные, поскольку она опиралась на различные выходные данные, обрабатываемые каждым слоем, которые объединялись для формирования единого способа классификации изображений.
Что мы узнали:
То, чего не было в примере, но стоит отметить:

Надеемся, приведенный пример и его объяснение позволили вам понять различия между Machine learning и Deep learning. Т.к. это объяснение для чайников, то здесь не употреблялись профессиональные термины.
Теперь пришло время забить последний гвоздь. Когда следует использовать глубокое обучение или машинное обучение в своем бизнесе?
Когда использовать Deep learning в бизнесе?
Когда использовать Machine learning в бизнесе?

Подведем итоги:
В связи с ростом различных технологий, предприятия в настоящее время ищут компании, занимающиеся технологическим консалтингом, чтобы найти то, что лучше для их бизнеса.
Развитие искусственного интеллекта также порождает рост услуг по разработке программного обеспечения, приложений IoT и блокчейна. В настоящее время разработчики программного обеспечения изучают новые способы программирования, которые более склонны к глубокому обучению и машинному обучению.
Глубокое обучение (Deep Learning): обзор
Всем привет. Уже в этом месяце в ОТУС стартует новый курс — «Математика для Data Science». В преддверии старта данного курса традиционно делимся с вами переводом интересного материала.

Аннотация. Глубокое обучение является передовой областью исследований машинного обучения (machine learning — ML). Оно представляет из себя нескольких скрытых слоев искусственных нейронных сетей. Методология глубокого обучения применяет нелинейные преобразования и модельные абстракции высокого уровня на больших базах данных. Последние достижения во внедрении архитектуры глубокого обучения в многочисленных областях уже внесли значительный вклад в развитие искусственного интеллекта. В этой статье представлено современное исследование о вкладе и новых применениях глубокого обучения. Следующий обзор в хронологическом порядке представляет, как и в каких наиболее значимых приложениях использовались алгоритмы глубокого обучения. Кроме того, представлены выгода и преимущества методологии глубокого обучения в ее многослойной иерархии и нелинейных операциях, которые сравниваются с более традиционными алгоритмами в обычных приложениях. Обзор последних достижений в области далее раскрывает общие концепции, постоянно растущие преимущества и популярность глубокого обучения.
1. Введение
Искусственный интеллект (ИИ) как интеллект, демонстрируемый машинами, является эффективным подходом к пониманию человеческого обучения и формирования рассуждений [1]. В 1950 году «Тест Тьюринга» был предложен как удовлетворительное объяснение того, как компьютер может воспроизводить когнитивные рассуждения человека [2]. Как область исследований, ИИ делится на более конкретные подобласти. Например: обработка естественного языка (Natural Language Processing — NLP) [3] может улучшить качество письма в различных приложениях [4,17]. Самым классическим подразделением в NLP является машинный перевод, под которым понимают переводом между языками. Алгоритмы машинного перевода способствовали появлению различных приложений, которые учитывают грамматическую структуру и орфографические ошибки. Более того, набор слов и словарный запас, относящиеся к теме материала, автоматически используются в качестве основного источника, когда компьютер предлагает изменения для автора или редактора [5]. На рис. 1 подробно показано, как ИИ охватывает семь областей компьютерных наук.
В последнее время машинное обучение и интеллектуальный анализ данных попали в центр внимания и стали наиболее популярными темами среди исследовательского сообщества. Совокупность этих областей исследования анализируют множество возможностей характеризации баз данных [9]. На протяжении многих лет базы данных собирались в статистических целях. Статистические кривые могут описывать прошлое и настоящее, чтобы предсказывать будущие модели поведения. Тем не менее, в течение последних десятилетий для обработки этих данных использовались только классические методы и алгоритмы, тогда как оптимизация этих алгоритмов могла бы лечь в основу эффективного самообучения [19]. Улучшенный процесс принятия решений может быть реализован на основе существующих значений, нескольких критериев и расширенных методов статистики. Таким образом, одним из наиболее важных применений этой оптимизации является медицина, где симптомы, причины и медицинские решения создают большие базы данных, которые можно использовать для определения лучшего лечения [11].
Рис. 1. Исследования в области искусственного интеллекта (ИИ) Источник: [1].
Поскольку ML охватывает широкий спектр исследований, на данный момент уже разработано множество подходов. Кластеризация, байесовская сеть, глубокое обучение и анализ дерева решений — это только их часть. Следующий обзор в основном фокусируется на глубоком обучении, его основных понятиях, проверенных и современных применениях в различных областях. Кроме того, в нем представлены несколько рисунков, отражающих стремительный рост публикаций с исследованиями в области глубокого обучения за последние годы в научных базах данных.
2. Теоретические основы
Концепция глубокого обучения (Deep Learning — DL) впервые появилась в 2006 году как новая область исследований в машинном обучении. Вначале оно было известно как иерархическое обучение в [2], и как правило оно включало в себя множество областей исследований, связанных с распознаванием образов. Глубокое обучение в основном принимает в расчет два ключевых фактора: нелинейная обработка в нескольких слоях или стадиях и обучение под наблюдением или без него [4]. Нелинейная обработка в нескольких слоях относится к алгоритму, в котором текущий слой принимает в качестве входных данных выходные данные предыдущего слоя. Иерархия устанавливается между слоями, чтобы упорядочить важность данных, полезность которых следует установить. С другой стороны, контролируемое и неконтролируемое обучение связано с меткой классов целей: ее присутствие подразумевает контролируемую систему, а отсутствие — неконтролируемую.
3. Применения
Глубокое обучение подразумевает слои абстрактного анализа и иерархические методы. Тем не менее, оно может быть использовано в многочисленных реальных приложениях. Как пример, в цифровой обработке изображений; раскраска черно-белых изображений раньше выполнялась вручную пользователями, которым приходилось выбирать каждый цвет на основе своего собственного суждения. Применяя алгоритм глубокого обучения, раскраска может выполняться автоматически с помощью компьютера [10]. Точно так же звук может быть добавлен в видео с игрой на барабанах без звука с использованием рекуррентных нейронных сетей (Recurrent Neural Networks — RNN), которые являются частью методов глубокого обучения [18].
Глубокое обучение может быть представлено как метод улучшения результатов и оптимизации времени обработки в нескольких вычислительных процессах. В области обработки естественного языка методы глубокого обучения были применены для создания подписей к изображениям [20] и генерации рукописного текста [6]. Следующие применения детальнее классифицированы в таких областях как цифровая обработка изображений, медицина и биометрия.
3.1 Обработка изображений
До того, как глубокое обучение официально утвердилось в качестве нового исследовательского подхода, некоторые приложения были реализованы в рамках концепции распознавания образов посредством обработки слоев. В 2003 году был разработан интересный пример с применением фильтрации частиц и алгоритма распространения доверия (Bayesian – belief propagation). Основная концепция этого приложения полагает, что человек может распознавать лицо другого человека, наблюдая только половину изображения лица [14], поэтому компьютер может восстановить изображение лица из обрезанного изображения.
Позже в 2006 году жадный алгоритм и иерархия были объединены в приложение, способное обрабатывать рукописные цифры [7]. Недавние исследования применили глубокое обучение в качестве основного инструмента для цифровой обработки изображений. Например, применение сверточных нейронных сетей (Convolutional Neural Networks — CNN) для распознавания радужной оболочки может быть более эффективным, чем использование привычных датчиков. Эффективность CNN может достигать 99,35% точности [16].
Мобильное распознавание местоположения в настоящее время позволяет пользователю узнать определенный адрес на основе изображения. Алгоритм SSPDH (Supervised Semantics – Preserving Deep Hashing) оказался значительным улучшением по сравнению VHB (Visual Hash Bit) и SSFS (Space – Saliency Fingerprint Selection). Точность SSPDH аж на 70% эффективнее [15].
Наконец, еще одно замечательное применение в цифровой обработке изображений с использованием метода глубокого обучения — распознавание лиц. Google, Facebook и Microsoft имеют уникальные модели распознавания лиц с глубоким обучением [8]. В последнее время идентификация на основе изображения лица изменилась на автоматическое распознавание путем определения возраста и пола в качестве исходных параметров. Sighthound Inc., например, тестировали алгоритм глубокой сверточной нейронной сети, способный распознавать не только возраст и пол, но даже эмоции [3]. Кроме того, была разработана надежная система для точного определения возраста и пола человека по одному изображению путем применения архитектуры глубокого многозадачного обучения [21].
3.2 Медицина
Цифровая обработка изображений, несомненно, является важной частью исследовательских областей, где может применяться метод глубокого обучения. Таким же образом, недавно тестировались клинические приложения. Например, сравнение между малослойным обучением и глубоким обучением в нейронных сетях привело к лучшей эффективности в прогнозировании заболеваний. Изображение, полученное с помощью магнитно-резонансной томографии (МРТ) [22] из головного мозга человека, было обработано, чтобы предсказать возможную болезнь Альцгеймера [3]. Не смотря на быстрый успех этой процедуры, некоторые проблемы должны быть серьезно рассмотрены для будущих применений. Одними из ограничений являются тренировка и зависимость от высокого качества. Объем, качество и сложность данных являются сложными аспектами, однако интеграция разнородных типов данных является потенциальным аспектом архитектуры глубокого обучения [17, 23].
Оптическая когерентная томография (ОКТ) является еще одним примером, где методы глубокого обучения показывают весомые результаты. Традиционно изображения обрабатываются путем ручной разработки сверточных матриц [12]. К сожалению, отсутствие учебных наборов ограничивает метод глубокого обучения. Тем не менее, в течение нескольких лет внедрение улучшенных тренировочных наборов будет эффективно предсказывать патологии сетчатки и уменьшать стоимость технологии ОКТ [24].
3.3 Биометрия
В 2009 году было применено приложение для автоматического распознавания речи, чтобы уменьшить частоту телефонных ошибок (Phone Error Rate — PER) с использованием двух разных архитектур сетей глубокого доверия [18]. В 2012 году метод CNN [25] был применен в рамках гибридной нейронной сети — скрытой модели маркова (Hybrid Neural Network — Hidden Markov Model — NN — HMM). В результате был достигнут PER на уровне 20,07%. Полученный PER лучше по сравнению с ранее применяемым 3-слойным методом базовой линии нейронной сети [26]. Смартфоны и разрешение их камер были протестированы для распознавания радужной оболочки. При использовании мобильных телефонов, разработанных различными компаниями, точность распознавания радужной оболочки может достигать до 87% эффективности [22,28].
С точки зрения безопасности, особенно контроля доступа; глубокое обучение используется в сочетании с биометрическими характеристиками. DL был использован для ускорения разработки и оптимизации устройств распознавания лиц FaceSentinel. По словам этого производителя, их устройства могут расширить процесс идентификации с одного-к-одному до одного-к-многим за девять месяцев [27]. Это усовершенствование движка могло бы занять 10 человеко-лет без внедрения DL. Что ускорило производство и запуск оборудования. Эти устройства используются в лондонском аэропорту Хитроу, а также могут использоваться для учета рабочего времени и посещаемости, и в банковском секторе [3, 29].
4. Обзор
Таблица 1 подытоживает несколько применений, реализованных в течение предыдущих лет относительно глубокого обучения. В основном упоминаются распознавание речи и обработка изображений. В этом обзоре рассматриваются только некоторые из большого списка применений.
Таблица 1. Применения глубокого обучения, 2003–2017 гг.
(Применение: 2003 — Иерархический байесовский вывод в зрительной коре; 2006 — Классификация цифр; 2006 — Глубокая сеть доверия для телефонного распознавания; 2012 — Распознавание речи из множественных источников; 2015 — Распознавание радужки глаза с помощью камер смартфонов; 2016 — Освоение игры Го глубокими нейронными сетями с поиском по дереву; 2017 — Модель сенсорного распознавания радужки).
4.1 Анализ публикаций за год
На рис. 1 приведено количество публикаций по глубокому обучению из базы данных ScienceDirect в год с 2006 по июнь 2017 года. Очевидно, что постепенное увеличение числа публикаций мог бы описать экспоненциальный рост.
На рис. 2 представлено общее количество публикаций по глубокому обучению в Springer в год с января 2006 года по июнь 2017 года. В 2016 году наблюдается внезапный рост публикаций, достигающий 706 публикаций, что доказывает, что глубокое обучение действительно в центре внимания современных исследований.
На рис. 3 показано количество публикаций на конференциях, в журналах и изданиях IEEE с января 2006 года по июнь 2017 года. Примечательно, что с 2015 года количество публикаций значительно увеличилось. Разница между 2016 и 2015 годами составляет более 200% прироста.
Рис. 1. Рост количества публикаций по глубокому обучению в базе данных Sciencedirect (январь 2006 г. — июнь 2017 г.)
Рис. 2. Рост количества публикаций по глубокому обучению из базы данных Springer. (январь 2006 г. — июнь 2017 г.)
Рис. 3. Рост публикаций в по глубокому обучению из базы данных IEEE. (январь 2006 г. — июнь 2017 г.)
5. Выводы
Глубокое обучение — действительно быстро растущее применение машинного обучения. Многочисленные приложения, описанные выше, доказывают его стремительное развитие всего за несколько лет. Использование этих алгоритмов в разных областях показывает его универсальность. Анализ публикаций, выполненный в этом исследовании, ясно демонстрирует актуальность этой технологии и дает четкую иллюстрацию роста глубокого обучения и тенденций в отношении будущих исследований в этой области.
Кроме того, важно отметить, что иерархия уровней и контроль в обучении являются ключевыми факторами для разработки успешного приложения в отношении глубокого обучения. Иерархия важна для соответствующей классификации данных, в то время как контроль учитывает важность самой базы данных как части процесса. Основная ценность глубокого обучения заключается в оптимизации существующих приложений в машинном обучении благодаря инновационности иерархической обработки. Глубокое обучение может обеспечить эффективные результаты при цифровой обработке изображений и распознавании речи. Снижение процента ошибок (от 10 до 20%) явно подтверждает улучшение по сравнению с существующими и проверенными методами.
В нынешнюю эпоху и в будущем глубокое обучение может стать полезным инструментом безопасности благодаря сочетанию распознавания лиц и речи. Помимо этого, цифровая обработка изображений является областью исследований, которая может применяться в множестве других областей. По этой причине и доказав истинную оптимизацию, глубокое обучение является современным и интересным предметом развития искусственного интеллекта.



