Deep Learning: в чем суть метода глубокого обучения?
В данной статье мы рассмотрим суть работы глубокого обучения нейронных связей в сравнении с машинным обучением и поговорим о том, как применять глубокое обучение на практике.
Понятия «Machine learning» и «Deep learning» часто считают синонимами, что является ошибочным суждением. Оба термина можно встретить в СМИ или технических статьях, но важно понимать, что это две отдельные области искусственного интеллекта, каждая из которых имеет свой смысл и значение. Прежде чем перейти к их подробному изучению, рассмотрим значение понятия «Искусственный интеллект».
Коротко об искусственном интеллекте
В середине 20-го столетия специалисты начали разработку компьютерных систем, которым по силам решение различных задач и вопросов. Ранее считалось, что на это способен только человек, т.е. для совершения подобных умственных операций необходим интеллект. Одним словом, искусственный интеллект – интеллектуальная система, способная решать творческие задачи, по традиции, считавшиеся прерогативой человека.
Всем известный пример совершенствования искусственного интеллекта – компьютерные игры. Их первые версии были упрощенными по своему функционалу, например, игры в шахматы или шашки, где основными действиями являются ход фигуры игрока и считывание комбинаций соперника. С развитием новых технологий машины начали приобретать совершенно иное значение и наполнение. Теперь искусственный интеллект способен анализировать обстановку, просчитывать шаги наперед и даже побеждать людей в компьютерных играх, что раньше было недоступно.
Практически не осталось тех областей, где искусственный интеллект не нашел еще свое применение, благодаря чему стремительно развивается медицина, наука, образование и т.д.
Давайте рассмотрим подробнее значение Machine learning для искусственного интеллекта.
Machine learning
Изначально те методы, которые были созданы для работы с искусственным интеллектом, не подходили для решения сложных вопросов. Например, для распознавания изображения или видео, текста или эмоций не подходят жесткие алгоритмы. Для этого на помощь пришло машинное обучение – область искусственного интеллекта, которая отвечает за разработку алгоритмов, способных преобразовывать себя без помощи человека.
Проще говоря, это методы, повторяющие систему обучения человека по принципу «от простого к сложному». Например, как школьник, который учится читать: сначала он изучает алфавит, потом слоги, слова, фразы и уже в итоге – тексты.
Приблизительно по такому же принципу специалисты разрабатывают алгоритмы Machine learning и предоставляют им огромное количество данных. Алгоритмы рассматривают информацию и приходят к выводам, на основе которых модернизируется искусственный интеллект. Если алгоритму предоставить признаки нападения кибермошенников на банковскую платформу, то система, обучившись на данном примере, сможет в дальнейшем вычислять подобные действия самостоятельно.
Важно понимать, что алгоритмы сами по себе не могут анализировать более точную информацию, для этого существуют нейронные сети, о которых мы поговорим далее.
Глубокое обучение нейронных сетей
Искусственные нейронные сети – это математические модели, повторяющие структуру человеческого мозга. Они были созданы для того, чтобы искусственный интеллект мог анализировать образы, текст, речь человека и т.д.
Простые нейронные сети способны распознать несложные предметы, отличить одного от другого или посчитать, сколько объектов изображено на картине. Более сложные сети решают те задачи, с которыми раньше компьютеры справиться не могли.
Чтобы искусственный интеллект научился различать животных, ему необходимо предоставлять их размеченные изображения. Вероятность безошибочной идентификации становиться выше, если предоставлять как можно больше размеченных изображений.
Но, как выяснилось, этого оказалось недостаточно, чтобы система смогла анализировать видеоматериал и распознавать голоса. Для этого специалисты начали работать над более глубоким обучением нейронных сетей.
Deep learning
Глубокое обучение нейронных связей – это одна из разновидностей машинного обучения, новая ступень развития науки, где нейросети включают в себя различные составные элементы, которые коммуницируют между собой в расширенных границах. В этом случае искусственный интеллект может решать самые нестандартные задачи.
Функционал компьютерных игр, который мы рассматривали ранее, стал реален благодаря Deep learning. Подобные глубинные нейронные сети могут распознать сложные изображения в режиме реального времени, например, самолет в нестандартном ракурсе, на любом фоне и даже в замаскированном виде.
Данные, полученные системой, анализируются разными слоями нейронной сети одновременно. Каждый слой идентифицирует картинку со своего положения.
Существует три типа слоев нейросетей:
Распознание изображения происходит в скрытом слое.
Глубокое обучение играет особую роль в анализе речи. Многослойная нейросеть способна справиться с подобной задачей: «Франция является моей родиной, я жил в Перу и Англии. Каким языком я владею свободно?» Нейронная сеть проанализирует данную фразу, сформирует список языков, которые, вероятно, знает автор, и в итоге определит, что правильный ответ – французский.
Deep learning стало реальностью после разработки производительных компьютерных систем, без которых невозможно распознавание и анализ видео.
Какие задачи способны решить машинное и глубокое обучение?
Обе дисциплины предназначены для решения разного типа задач. С точки зрения бизнес-процессов, Machine learning предназначено для:
Для применения Deep learning необходимы следующие условия:
Из сказанного можно сделать вывод, что без искусственного интеллекта, машинного и глубокого обучения многие компьютерные функции были бы недоступны. Например, такие как распознавание речи и изображении и даже игры в шашки. Благодаря обработке большого объема информации и выявлению в ней связей и закономерностей машины способны выполнять задачи различной сложности.
Первоначальная информация всегда содержит ответы, необходимые профессионалам разных сфер деятельности. Главная задача – научиться находить решения при помощи новейших технологий.
Сегодня миром управляют информация и компьютерные технологии. А победителем является тот, кто имеет самый совершенный искусственный интеллект.
Желаем вам удачи в применении искусственного интеллекта в повседневной жизни и не забывайте про развитие собственного, ведь любую машину, в первую очередь, создаем мы – люди!
Кстати, в продолжение темы о развитии интеллекта советуем пройти онлайн-программу «Лучшие техники самообразования», после которой вы сможете учиться быстрее, эффективнее и сделаете свое самообучение максимально интересным.
Введение в глубокое обучение: пошаговое руководство
Вы когда-нибудь задумывались, как работает Amazon Alexa или Google Translate? В основе работы этих и многих других систем лежит глубокое обучение.
Глубокое обучение (англ. Deep Learning, DL), будучи разновидностью машинного обучения (англ. Machine Learning, ML), произвело революцию в мире технологий и нашло свое применение во всех сферах бизнеса.
В этом вступлении в глубокое обучение мы рассмотрим следующие темы:
Что такое глубокое обучение?
Прежде чем мы углубимся в глубокое обучение, его приложения и платформы, нам сперва нужно понять, что вообще из себя представляет глубокое обучение.
Глубокое обучение — это подраздел машинного обучения, который занимается алгоритмами, основанными на структуре и функциях мозга. Глубокое обучение — это разновидность машинного обучения, которое, в свою очередь, является частью сферы искусственного интеллекта (ИИ).
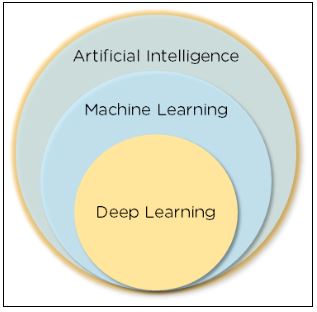
Искусственный интеллект — это способность машины имитировать разумное поведение человека. Машинное обучение позволяет системе автоматически обучаться и улучшать свой собственный опыт. Глубокое обучение — это разновидность машинного обучения, которая использует сложные алгоритмы и глубокие нейронные сети для обучения моделей.
Применение глубокого обучения
Теперь давайте познакомимся с несколькими вариантами применения глубокого обучения на практике.
Глубокое обучение vs. машинное обучение
Что такое нейронные сети?
Теперь, когда вы знаете, что такое глубокое обучение, где оно применяется и чем отличается от машинного обучения, давайте рассмотрим нейронные сети и их работу.
Нейронная сеть — это система, смоделированная на основе человеческого мозга, состоящая из входного слоя, нескольких скрытых слоев и выходного слоя. Данные поступают на вход нейронной сети. Далее информация передается на следующий уровень с применением соответствующих весов и смещений. На выходе сети оказывается окончательное значение, предсказанное искусственным нейроном.
Каждый нейрон в нейронной сети выполняет следующие операции:
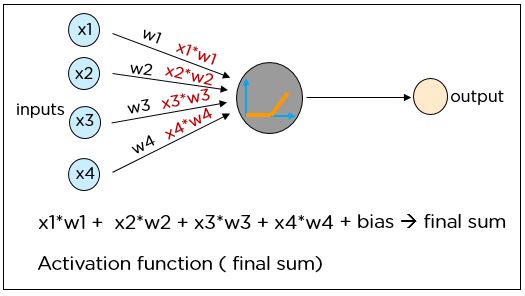
Функция потерь
Функция потерь — один из важнейших компонентов нейронной сети. Потери — это разность между полученным результатом нейронной сети и правильным ответом из размеченного набора обучающих данных. Минимизация функции потерь посредством корректировки весов и смещений производится на протяжении всего процесса обучения.
Как работают нейронные сети?
В этом разделе мы рассмотрим, как нейронная сеть обучается распознавать различные формы. Формы представляют собой изображения размером 28 х 28 пикселей.
![]()
Каждый пиксель подается на вход нейронов первого слоя, а скрытые слои будут повышать точность вывода. Данные передаются от слоя к слою по каналам, где они умножаются на разные веса. Причем каждый нейрон в одном слое имеет разные веса по отношению к каждому нейрону в следующем слое.
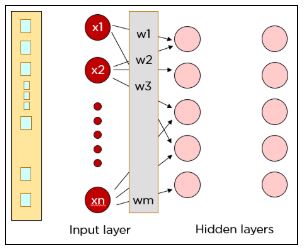
Каждый нейрон в первом скрытом слое принимает подмножество входных данных и обрабатывает их. Все входные данные умножаются на соответствующие веса и к ним еще добавляется смещение. Результаты функции активации определяют, данные из каких нейронов будут переданы в следующий слой.
Шаг 1: x1*w1 + x2*w2 + b1
Шаг 2: Φ(x1* w1 + x2*w2 + b1)
(Ф — это функция активации).
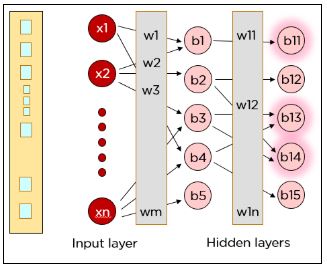
Вышеупомянутые шаги выполняются снова во втором скрытом слое, после чего информация достигает выходного слоя. А затем один из нейронов в выходном слое должен активироваться (в зависимости от значения функции активации).
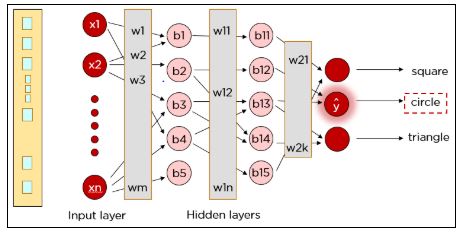
Как видите, наш правильный результат был квадратом, но нейронная сеть предсказала круг. Итак, что-то пошло не так?
Нейронную сеть необходимо обучать до тех пор, пока прогнозируемые выходные данные не будут совпадать с правильными. Сравнение осуществляется путем вычисления функции потерь.
Функция потерь определяет ошибку прогноза и сообщает об этом нейронной сети. Это называется алгоритмом обратного распространения ошибки (backpropagation).
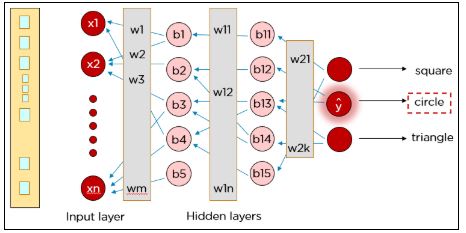
Чтобы уменьшить ошибку, мы корректируем веса, и сеть продолжает обучение с ними.
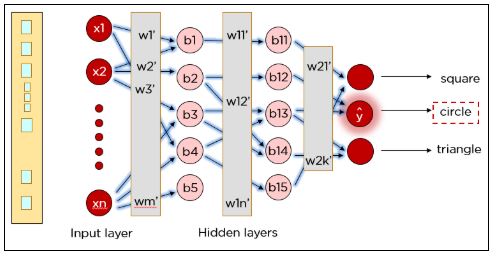
Снова вычисляется функция потерь, и процедура обратного распространения ошибки запускается вновь — до тех пор, пока ошибки не перестанут уменьшаться.
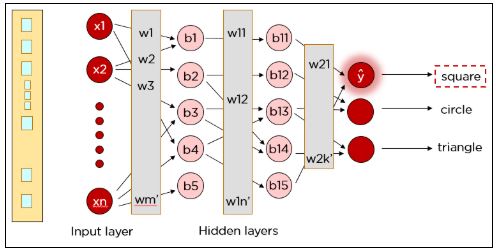
Точно так же нашу сеть можно обучить предсказывать круги и треугольники.
Марк Лутц «Изучаем Python»
Скачивайте книгу у нас в телеграм
Платформы глубокого обучения
Теперь, когда вы хорошо понимаете, как работают нейронные сети, давайте кратко рассмотрим некоторые из основных платформ глубокого обучения.
Torch
Torch был разработан с использованием языка LUA и реализован на языке C. Реализация на языке Python называется PyTorch.
Keras
Keras — это фреймворк Python для глубокого обучения. Его большим плюсом является возможность использовать код как на CPU, так и на GPU.
TensorFlow
TensorFlow — это библиотека глубокого обучения с открытым исходным кодом, созданная Google. Она разработана на C++ и реализована на Python. Keras можно запускать поверх TensorFlow.
Deep Learning for Java (DL4J) — первая библиотека глубокого обучения, написанная для Java и Scala. Она интегрирована с Hadoop и Apache Spark.
Введение в TensorFlow
TensorFlow от Google в настоящее время является самой популярной библиотекой глубокого обучения в мире. Она основана на концепции тензоров, которые являются векторами или матрицами в n-мерном пространстве.
Ниже приведен пример одномерного, двухмерного и трехмерного тензоров.
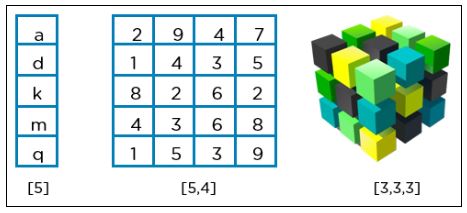
Все вычисления, выполняемые с использованием TensorFlow, включают в себя тензоры.
Ниже представлена простая архитектура работы TensorFlow:
Реализация кейса при помощи TensorFlow
Давайте воспользуемся набором данных из репозитория машинного обучения UCI и предскажем (на основе определенных критериев), превышает ли доход человека 50 тысяч долларов в год.
Этот набор данных имеет следующие атрибуты:
Приступим к демонстрации:

2. Определим пути, где расположены наши данные, а также зададим переменные столбцов.

3. При помощи библиотеки Pandas создадим тестовый и обучающий набор данных:

4. Выведем на экран размер тестового и обучающего набора данных:

5. Установим для столбца label значение 0 — если оно = 50 000.
6. Подсчитаем общее количество уникальных значений в наборах данных:

7. Проверим типы данных в наших столбцах:

8. Разделим переменные на категориальные и числовые (непрерывные):

9. Создадим непрерывные переменные:
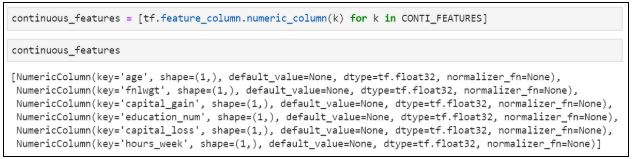

11. Создаем модель с двумя классами и непрерывными и категориальными переменными:
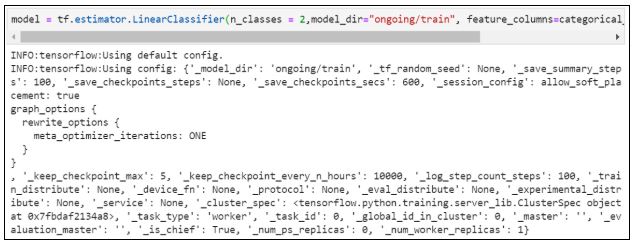
12. Присваиваем значения и определяем функцию:
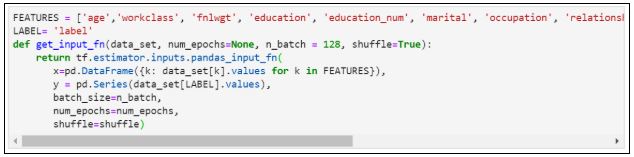

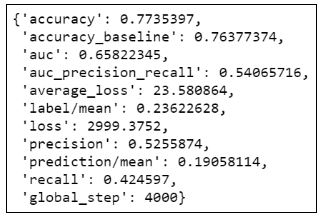
14. Оцениваем модель:

15. Возводим переменную age в квадрат:

16. Создаем новый датафрейм, состоящий из обучающих и тестовых данных:

17. Заново определяем категориальные и непрерывные переменные:

18. Создаем модель с линейным классификатором:
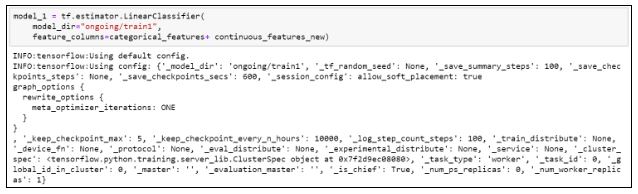
19. Присваиваем новые значения и заново определяем функцию:
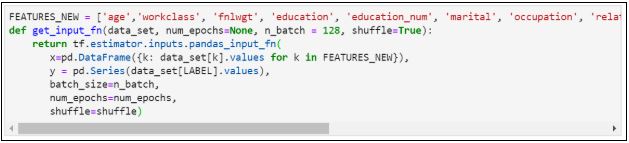
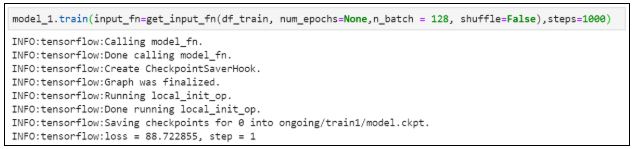
21. Оцениваем модель:
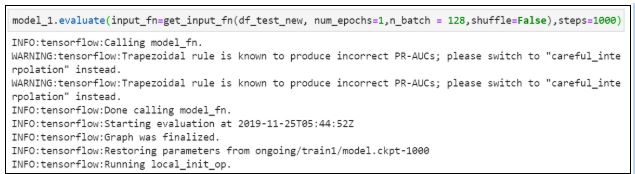
22. Осуществляем предсказание при помощи обученной модели:
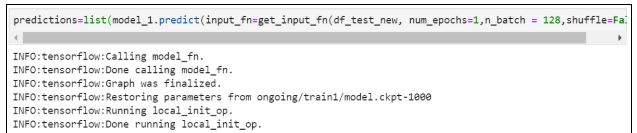
23. Проверяем предсказание на тестовом наборе данных:
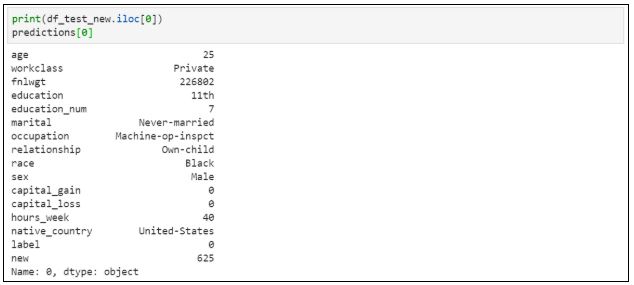
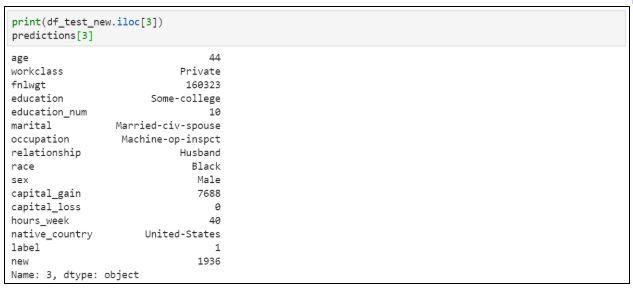
Как видите, модель успешно смогла предсказать два результата из набора тестовых данных.
Заключение
Надеемся, что после прочтения этой статьи вы уже лучше понимаете, как работают нейронные сети, что такое веса, смещения и функции активации. Также вы узнали о TensorFlow и о том, как работают тензоры. Наконец, вы знаете, как использовать TensorFlow для классификации людей по их заработной плате на основе конкретных характеристик.
Deep Learning: Transfer learning и тонкая настройка глубоких сверточных нейронных сетей
В предыдущей статье из цикла «Deep Learning» вы узнали о сравнении фреймворков для символьного глубокого обучения. В этом материале речь пойдет о глубокой настройке сверточных нейронных сетей для повышения средней точности и эффективности классификации медицинских изображений.

Цикл статей «Deep Learning»
Примечание: далее повествование будет вестись от имени автора.
Введение
Распространенной причиной потери зрения является диабетическая ретинопатия (ДР) — заболевание глаз при диабете. Исследование пациентов с помощью флюоресцентной ангиографии потенциально способно снизить риск слепоты. Существующие тенденции исследований показывают, что глубокие сверточные нейросети (ГСНС) весьма эффективны для автоматического анализа больших наборов изображений и для выявления отличительных признаков, по которым можно распределить изображения на разные категории практически без ошибок. Обучение ГСНС редко происходит с нуля из-за отсутствия заранее заданных наборов с достаточным количеством изображений, относящихся к определенной области. Поскольку для обучения современных ГСНС требуется 2–3 недели, центр Berkley Vision and Learning Center (BVLC) выпустил итоговые контрольные точки для ГСНС. В этой публикации мы используем заранее обученную сеть: GoogLeNet. Сеть GoogLeNet обучена на большом наборе естественных изображений ImageNet. Мы передаем распознанные весов ImageNet в качестве начальных для сети, затем настраиваем заранее обученную универсальную сеть для распознавания изображений флюоресцентной ангиографии глаз и повышения точности предсказания ДР.
Использование явного выделения отличительных признаков для предсказания диабетической ретинопатии
В настоящий момент уже проделана обширная работа по разработке алгоритмов и методик обработки изображений для явного выделения отличительных признаков, характерных для пациентов с ДР. В стандартной классификации изображений применяется следующий универсальный рабочий процесс:
Тем не менее все эти процессы связаны со значительными затратами времени и усилий. Для дальнейшего повышения точности предсказаний требуются огромные объемы маркированных данных. Обработка изображений и выделение отличительных признаков в наборах данных изображений — весьма сложный и длительный процесс. Поэтому мы решили автоматизировать обработку изображений и этап выделения отличительных признаков, используя ГСНС.
Глубокая сверточная нейросеть (ГСНС)
Для выделения отличительных признаков в изображениях требуются экспертные знания. Функции выделения в ГСНС автоматически формируют изображения для определенных областей, не используя никакие функции обработки отличительных признаков. Благодаря этому процессу ГСНС пригодны для анализа изображений:

Слои C — свертки, слои S — пулы и выборки
Свертка. Сверточные слои состоят из прямоугольной сети нейронов. Веса при этом одинаковы для каждого нейрона в сверточном слое. Веса сверточного слоя определяют фильтр свертки.
Опрос. Pooling layer берет небольшие прямоугольные блоки из сверточного слоя и проводит подвыборку, чтобы сделать из этого блока один выход.
В этой публикации мы используем ГСНС GoogLeNet, разработанную в Google. Нейросеть GoogLeNet выиграла конкурс ImageNet в 2014 году, поставив рекорд по наилучшим единовременным результатам. Причины выбора этой модели — глубина работы и экономное использование ресурсов архитектуры.
Transfer learning и тонкая настройка глубоких сверточных нейросетей
На практике обучение целых ГСНС обычно не производится с нуля с произвольной инициализацией. Причина состоит в том, что обычно не удается найти набор данных достаточного размера, требуемого для сети нужной глубины. Вместо этого чаще всего происходит предварительное обучение ГСНС на очень крупном наборе данных, а затем использование весов обученной ГСНС либо в качестве инициализации, либо в качестве выделения отличительных признаков для определенной задачи.
Тонкая настройка. Стратегии переноса обучения зависят от разных факторов, но наиболее важными являются два: размер нового набора данных и его схожесть с исходным набором данных. Если учесть, что характер работы ГСНС более универсален на ранних слоях и становится более тесно связанным с конкретным набором данных на последующих слоях, можно выделить четыре основных сценария:
Ограничения transfer learning. Поскольку мы используем заранее обученную сеть, наш выбор архитектуры модели несколько ограничен. Например, мы не можем произвольным образом убрать сверточные слои из заранее обученной модели. Тем не менее благодаря совместному использованию параметров можно с легкостью запустить заранее обученную сеть для изображений разного пространственного размера. Это наиболее очевидно в случае сверточных и выборочных слоев, поскольку их функция перенаправления не зависит от пространственного размера входных данных. В случае с полносвязанными слоями этот принцип сохраняется, поскольку полносвязанные слои можно преобразовать в сверточный слой.
Скорость обучения. Мы используем уменьшенную скорость обучения для весов ГСНС, подвергаемых тонкой настройке, исходя из того, что качество весов заранее обученной ГСНС относительно высоко. Не следует искажать эти данные слишком быстро или слишком сильно, поэтому и скорость обучения, и спад скорости должны быть относительно низкими.
Дополнение данных. Одним из недостатков нерегулярных нейросетей является их чрезмерная гибкость: они одинаково хорошо обучаются распознаванию как деталей одежды, так и помех, из-за чего повышается вероятность чрезмерной подгонки. Мы применяем регуляризацию Тихонова (или L2-регуляризацию), чтобы избежать этого. Впрочем, даже после этого был значительный разрыв в производительности между обучением и проверкой изображений ДР, что указывает на чрезмерную подгонку в процессе тонкой настройки. Чтобы устранить этот эффект, мы применяем дополнение данных для набора данных изображений ДР.
Существует множество способов дополнения данных, например, зеркальное отображение по горизонтали, случайная обрезка, изменение цветов. Поскольку цветовая информация этих изображений очень важна, мы применяем лишь поворот изображений на разные углы: на 0, 90, 180 и 270 градусов.
Замена входного слоя заранее обученной сети GoogLeNet на изображения ДР. Мы проводим тонкую настройку всех слоев, кроме двух верхних заранее обученных слоев, содержащих универсальные веса.
Тонкая настройка GoogLeNet. Используемая нами сеть GoogLeNet изначально была обучена на наборе данных ImageNet. Набор данных ImageNet содержит около 1 млн естественных изображений и 1000 меток/категорий. В нашем размеченном наборе данных ДР содержится около 30 000 изображений, относящихся к рассматриваемой области, и четыре метки/категории. Следовательно, этого набора данных ДР недостаточно для обучения сложной сети, какой является GoogLeNet: мы будем использовать веса из сети GoogLeNet, обученной по ImageNet. Мы проводим тонкую настройку всех слоев, кроме двух верхних заранее обученных слоев, содержащих универсальные веса. Первоначальный слой классификации loss3/classifier выводит предсказания для 1000 классов. Мы заменяем его новым двоичным слоем.
Заключение
Благодаря тонкой настройке можно применять усовершенствованные модели ГСНС в новых областях, где их было бы невозможно использовать иначе из-за недостатка данных или ограничений по времени и стоимости. Такой подход позволяет добиться существенного повышения средней точности и эффективности классификации медицинских изображений.
Если вы увидели неточность перевода, сообщите пожалуйста об этом в личные сообщения.



