dd_rescue vs GNU ddrescue: зачем нужен клон, когда есть оригинал
В статье Копирование разделов жёсткого диска средствами GNU/Linux: как обойтись загрузочной флешкой там, где раньше нужен был Акронис, я посоветовал для копирования потенциально испорченных дисков использовать GNU ddrescue, а не оригинал, который назвал устаревшим. Но в комментариях nerfur указал мне, что dd_rescue регулярно обновляется и умеет на лету сжимать данные для последующей передачи по ssh. Так как эта задача GNU ddrescue не под силу, слухи об устаревании dd_rescue как видно сильно преувеличены.
Понятное дело — надо немедленно выяснить, чем современный вариант dd_rescue отличается от GNU ddrescue, что умеет и, возможно, убрать рекомендацию избегать использования оригинала из статьи. А также написать новую статью — про отличия этих двух программ, чем я и занялся.
Для тех, кто хочет побыстрее узнать чем кончилось дело и не интересуется душераздирающими подробностями сразу скажу, что после изучения вопроса моё мнение не изменилось — я всё ещё рекомендую пользоваться GNU ddrescue, но теперь уже по другой, гораздо более вменяемой причине — GNU ddrescue сначала сохраняет хорошо читаемые области диска и уже потом приступает к остальным. dd_rescue этого не умеет by design.
Историческая справка
Традиционно для создания бинарных копий физических накопителей в *nix системах использовалась программа dd, читавшая диск кусками заранее заданного размера. Она хорошо справлялась с задачей, когда речь шла о копировании данных с исправных устройств, но за обращение с частично неисправными дисками dd заслуженно получила прозвище disk destroyer.
dd_rescue
Для снятия данных с повреждённой поверхности Kurt Garloff написал утилиту, которая работала примерно как dd, но при встрече с битыми секторами не зачитывала диск до смерти и не игнорировала ошибки, а, уменьшив скорость до минимально возможной, спасала всё, что можно спасти.
Несмотря на явный прогресс по сравнению с dd, dd_rescue читала весь файл за один проход, мерным солдатским шагом двигаясь от начала к концу. Из за наличия нечитаемой области, процесс получения точной копии мог занять часы, месяцы или даже годы, тогда как время получения копии, достоверной на 99 процентов измерялось в десятках минут.
Кроме того, во время медленного и вдумчивого чтения дышащих на ладан секторов все остальные (нормально читаемые на момент запуска программы) вполне могли отбросить копыта, потому что пришло их время. Если бы их прочитали минутой или двумя раньше — всё бы было хорошо, а так — момент упущен — такое случается.
Оптимальным вариантом было бы сначала сохранить всё, что пока читается без проблем, а потом уже приступить к чтению ненадёжных фрагментов, но из коробки dd_rescue этого не умела, хотя и обладала всем необходимым арсеналом возможностей. Поэтому осуществить описанное выше можно было только вручную.
dd_rhelp
Как известно если гора не идёт к Магомету, то Магомет вполне может подойти к ней самостоятельно. Я думаю, как-то так и рассуждал LAB Valentin, когда принял решение написать баш скрипт, использующий dd_rescue для реализации оптимальной стратегии копирования повреждённых файлов.
В конце концов автор dd_rescue включил этот скрипт, получивший название dd_rhelp, в официальную версию основной программы.
GNU ddrescue
dd_rhelp в связке с dd_rescue существенно упростил процесс, но у него был один фатальный недостаток — он не был написал на C работал ужасно медленно.
Не будучи в силах с этим смириться Антонио Диаз решил запилить свою программу с алгоритмом и константами, которую назвал — сюрприз — GNU ddrescue.
Вот как среагировал на это автор dd_rhelp.
Какое-то время dd_rhelp был единственным инструментом, который мог выполнять работy такого рода, но вот уже несколько лет как это не так: Антонио Диаз написал идеальную замену для моего инструмента: GNU ‘ddrescue’.
Да, назвать инструмент тем же именем, что и ‘dd_rescue’ Курта Гарлоффа было не очень умно (вот вы улавливаете тонкое отличие между ‘GNU ddrescue’ и ‘dd_rescue’?), но кажется это было сделано намерено, поскольку мы предупредили Антонио Диаза, что это наверняка внесёт сумятицу в миниатюрный мир инструментов восстановления жёстких дисков.
Тем не менее, если этот инструмент решает ваши задачи (а так и должно быть) я призываю вас использовать именно его. Почему? Сначала надо разобраться что мы сравниваем:
— dd_rhelp (грязный баш скрипт) + dd_rescue (Си) одной стороны
— GNU ddrescue (Си) с другой /* вообще-то GNU ddrescue написана на С++ */
dd_rhelp был задуман как быстрый хак для реализации того, что dd_rescue не делала и что на тот момент вообще нельзя было осуществить.
Возможно, есть случаи в которых GNU ddrescue не работает и это основная причина по которой я продолжаю поддерживать dd_rhelp. О таких случаях очень важно сообщать мне и Антонио Диазу.
For some times, dd_rhelp was the only tool (AFAIK) that did this type of job, but since a few years, it is not true anymore: Antonio Diaz did write a ideal replacement for my tool: GNU ‘ddrescue’.
Nevertheless, I really encourage you to use this replacement tool if it works for you (and it should be the case). Why? Understand first what we are comparing:
— dd_rhelp (in dirty bash script) + dd_rescue (in C) in one hand
— GNU ddrescue (in C) in the other.
dd_rhelp was meant as a quick hack to implement what dd_rescue didn’t do, and what couldn’t be done at that time (AFAIK).
It could be some cases where GNU ddrescue won’t work, and this is the major reason why I keep maintaining dd_rhelp. It is important to tell me and Antonio Diaz when these cases occur.
Настоящее время
Как уже сказано, dd_rescue и GNU ddrescue до сих пор периодически обновляются, а вот dd_rhelp заморожен на уровне 2008 года и это похоже навсегда. Обновление 2012 года, правда внесло какие-то косметические изменения, но это мало что изменило.
Как же быть простому пользователю
Использовать GNU ddrescue для создания копий заведомо проблемных дисков
Там, где нужна функциональность dd_rhelp, лучше воспользоваться GNU ddrescue. Как показано выше, dd_rescue может заменить GNU ddrescue только в связке с dd_rhelp, автор которого рекомендует своим детищем по возможности не пользоваться.
Использовать dd_rescue когда нужен улучшенный вариант dd
С другой стороны, если для вас функционал dd_rhelp избыточен, то у dd_rescue есть в рукаве пара трюков, которыми GNU ddrescue не владеет. Прежде всего, dd_rescue может перенаправить вывод в пайп, что просто незаменимо например при копировании по ssh. Кроме того там есть плагинный механизм с помощью которого поддерживается сжатие и разжатие на лету, а также различные алгоритмы подсчёта хешей. dd_rescue хорошо подойдёт там, где нужен заменитель простого dd с расширенным функционалом и страховкой на случай наличия ошибок, исправляемых повторным чтением. А ещё в документации сказано, что она рисует прогресс бар :).
Блог о системном администрировании. Статьи о Linux, Windows, СХД NetApp и виртуализации.
 Всем привет. Думаю, что каждый рано или поздно сталкивался с ситуацией, когда необходимо восстановить данные с жесткого диска. На помощь нам приходит утилита ddrescue. Я тоже не обошел данную проблему стороной. Буквально на днях моя домашняя файлопомойка заскрипела диском и начала сыпать ошибками на консоль и в лог. Что-то вроде:
Всем привет. Думаю, что каждый рано или поздно сталкивался с ситуацией, когда необходимо восстановить данные с жесткого диска. На помощь нам приходит утилита ddrescue. Я тоже не обошел данную проблему стороной. Буквально на днях моя домашняя файлопомойка заскрипела диском и начала сыпать ошибками на консоль и в лог. Что-то вроде:
Повезло мне, что : 1. есть бэкап, который успокоил мою душу (хорошо, что не понадобился). 2. Проблема оказалась с поверхностью диска, а не с контроллером\электроникой.
Порядок действий с битым hdd
Типичный порядок действий, которому я стараюсь следовать при наличии таких проблем как ошибки чтения\записи, нетипичный треск диска и другие симптомы выхода из строя жесткого диска:
Восстановление битого hdd с помощью ddrescue
Исторически, для побайтового копирования в Linux существовала утилита dd. Недостаток dd, в данном случае в том, что она может копировать данные только с исправных устройств. Данного недостатка лишена ddrescue. Давайте кратко рассмотрим man ddrescue:
If you use the mapfile feature of ddrescue, the data is rescued very efficiently, (only the needed blocks are read). Also you can interrupt the rescue at any time and resume it later at the same point. The mapfile is an essential part of ddrescue’s effectiveness. Use it unless you know what you are doing.
Что по русски звучит, как:
При своей работе ddrescue не пишет нули в выходной файл, когда он находит бэды на входном файле, и не обрезает выходной файл, если это не задано в параметрах. Таким образом, каждый раз, когда ddrescue натравливается на тот же выходной файл, он пытается заполнить пробелы, не трогая уже спасенные данные. В общем-то все выглядит просто. Послушаемся совета использовать лог файл. Лог файл после определенной версии ddrescue стал называться mabfile.
Рекомендации по восстановлению данных или Будьте бдительны и осторожны
Опять же, взято из мануала:
Формат ddrescue
ddrescue запускается в следующем формате:
При этом, в большинстве случаев, достаточно всего нескольких опций:
Не углубляясь в нюансы работы ddrescue, можно пометить все ошибочные области, как области, которые еще не читались. Рекомендуется использовать опцию, если диск перестает отвечать.
При указании данной опции, ddrescue использует прямой доступ к диску, обходя кэши ядра.
Ключ задает откуда (с какого bytes) начинать чтение с infile. По умолчанию установлен в ноль.
Ограничить размер восстанавливаемого раздела последним блоком, обозначенным в логфайле. Используется для слияния образов восстановления. Например, если диск outfile сломался во время восстановления.
Пропускает т.н. фазу scrape. Уменьшает время восстановления, т.к. снижает время на попытки чтения самых трудных частей файла.
Обратная последовательность выполнения каждой фазы восстановления. То есть ddrescue читает данные в обратной последовательности.
Заставить ddrescue перезаписать диск outfile. Необходим, когда в качестве outfile используется устройство. Используется для защиты от ошибочного повреждения данных.
Давайте теперь рассмотрим данные опции на примерах.
ddrescue примеры
Пример 1: Восстановление целого диска с несколькими разделами ext3 (или любыми другими, хоть NTFS) с /dev/hda на /dev/hdb.
Примечание: Нет необходимости создавать таблицу разделов на /dev/hdb, т.к. данные копируются побайтово вместе со структурой разделов.
Пример 2: Восстановление одного раздела с /dev/hda2 на /dev/hdb2.
Примечание: результирующий раздел должен существовать с тем же типом и размером, что и исходный, либо должен быть создан.
Пример 3: Во время восстановления целого диска /dev/hda на /dev/hdb, /dev/hda остановился и перестал отвечать на позиции 12345678.
Пример 4: Во время восстановления целого диска /dev/hda на /dev/hdb, /dev/hdb выдал ошибку и мы пытаемся восстановить данные на третий диск /dev/hdc
Пример 5: Во время восстановления целого диска /dev/hda на /dev/hdb, /dev/hda перестал отвечать, стал недоступен и невидим в /dev
На этом все. Надеюсь, что данный материал Вам помог. Больше информации можно найти в ссылках ниже. Так же, в ссылках можно найти информацию о Live дистрибутивах, которые я использую для восстановительных работ.
Как с помощью утилиты ddrescue скопировать данные с поврежденной флешки или карты памяти

Восстановление данных с поврежденной флешки или карты памяти не всегда проходит гладко и с положительным результатом. Удастся ли скопировать данные с носителя или нет, зависит от степени его поврежденности, а также от используемых программой алгоритмов. Там, где пасует популярная программа, нередко с возложенной на нее задачей вполне успешно справляется малоизвестная утилита. О такой утилите сегодня как раз и пойдет речь.
Как пользоваться ddrescue
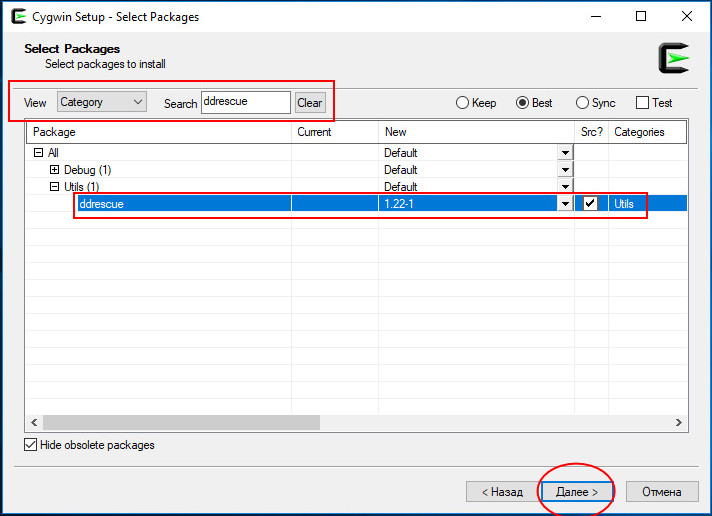
Установка среды занимает некоторое время, поскольку необходимые файлы загружаются с серверов разработчика.
Подключив к компьютеру накопитель, запустите с рабочего стола Cygwin и выполните в открывшейся консоли такую команду:
cat /proc/partitions
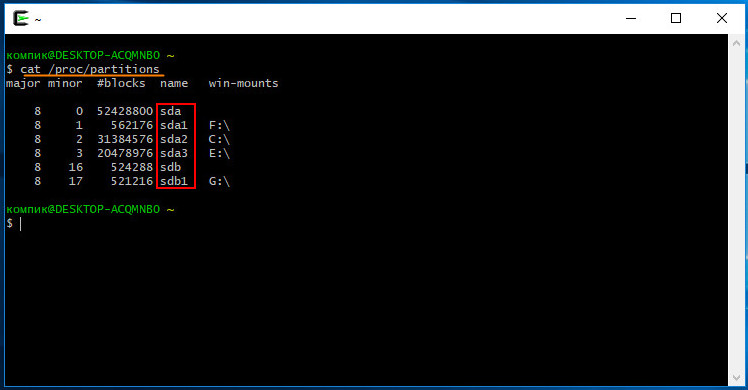
Этой командой вы получите список томов всех подключенных к ПК носителей. Запомнив имя (name) вашей флешки или карты памяти, сформируйте и выполните следующую команду, где XXX — имя проверяемого накопителя.
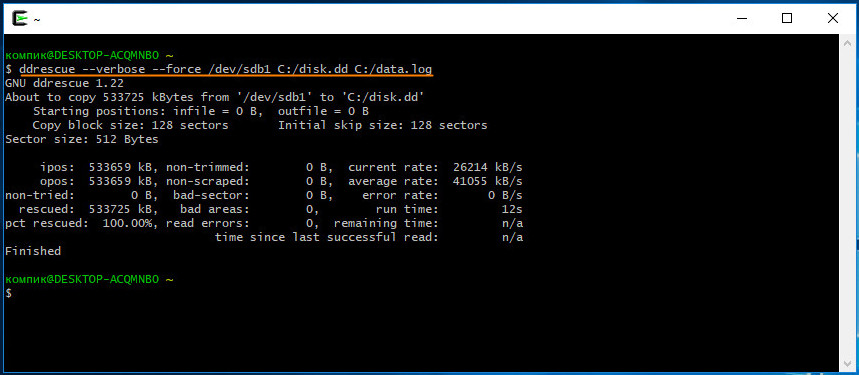
В представленном здесь примере карта памяти не имеет проблемных блоков, поэтому сканирование заняло несколько секунд. Если бы утилита натолкнулась на проблемные участки, процесс затянулся бы на неопределенное время, а в консоли появилось бы сообщение «Scraping failed blocks» — выскабливание плохих блоков. Что означают другие данные?
• non-tried — сколько осталось проверить данных, при полной проверке значение будет равно нулю.
• rescued и pct rescued — успешно прочитанные данные в килобайтах и процентах.
• non-trimmed — предварительный размер блоков, подлежащих усиленной проверке.
• non-scraped — размер блоков, из которых предстоит «выскоблить» данные.
• bad-areas — участки, содержащие проблемные сектора.
• bad-sector — сектора, окончательно признанные плохими.
• read-errors — количество ошибок чтения.
Выглядеть он будет примерно следующим образом:
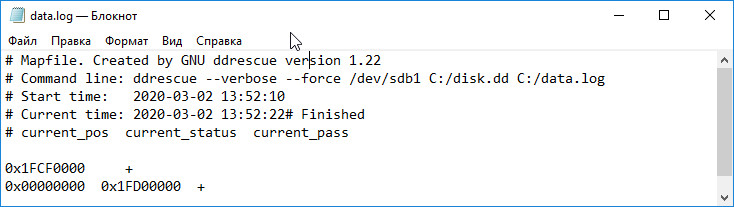
Шестнадцатеричные значения будут соответствовать номерам секторов, а символы — их состоянию. Символ «+» означает успешно прочитанный сектор, «-» — окончательно плохой, «/» — еще не выскобленные, «*» — еще не помеченные как non-scraped, «?» — вообще не проверенные.
Что делать с полученным образом DD?
Скормить его программе для восстановления данных, поддерживающей этот формат.
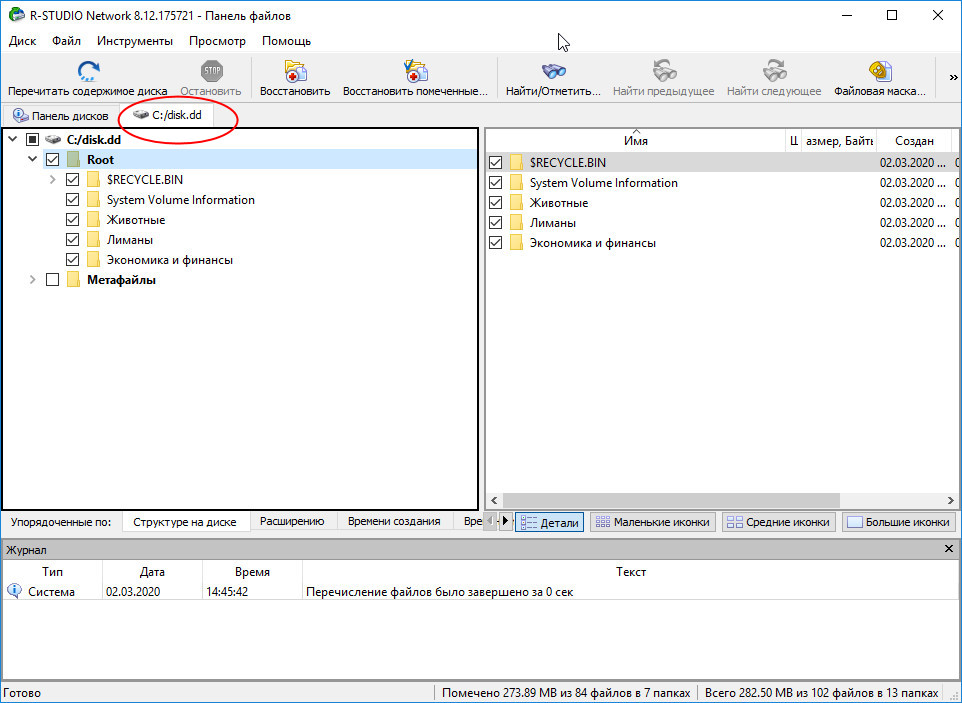
R-Studio с ним, например, прекрасно справляется.
Оригинал: GNU ddrescue – The Best Damaged Drive Rescue
Автор: Carla Schroder
Дата публикации: 2 марта 2017 года
Перевод: А. Кривошей
Дата перевода: апрель 2018 г.
Вместо того, чтобы запускать какие-либо средства восстановления файлов или инструменты анализа на поврежденном томе, лучше всего сначала сделать копию, а затем работать с этой копией.
Мне нравится всегда иметь под рукой SystemRescueCD на компакт-диске, а также на USB-накопителе. SystemRescueCD имеет небольшой объем и специализируется на спасательных операциях. В наши дни большинство дистрибутивов Linux имеют загрузочные версии с live-режимом, поэтому вы можете использовать то, с чем вам удобно работать, при условии, что вы ваш дистрибутив включает GNU ddrescue и другое программное обеспечение для спасения данных, которое вам нужно.
Требуемое оборудование
Вам нужна система Linux с GNU ddrescue (gddrescue в случае Ubuntu), диск, который вы пытаетесь спасти, и устройство с пустым разделом, размером по крайней мере, в 1,5 раза больше, чем тот, который вы спасаете, так как у вас должен быть приличный запас свободного места. Если вы исчерпали свободное место, даже если это всего лишь несколько байтов, GNU ddrescue завершится неудачно в конце операции.
Если у вас недостаточно USB-портов, незамененимым является мощный USB-концентратор.
Идентификация накопителей
Убедитесь, что вы используете правильные имена устройств. Подключите все, а затем запустите lsblk:
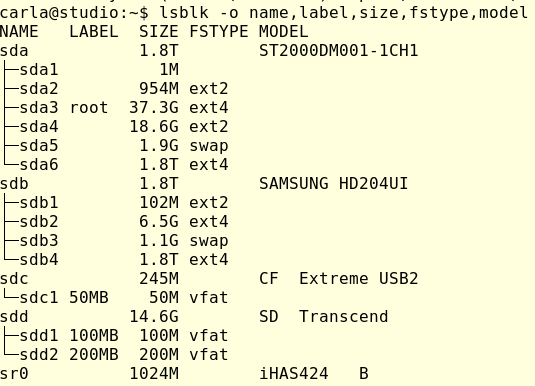
Здесь видно, что корневой файловой системой является /dev/sda3, а все, что находится в папке /media, не относится к корневой файловой системе.
/media/carla/100MB2 и /media/carla/50MB обозначены метками вместо UUID типа /media/carla/8c670f2e-dae3-4594-9063-07e2b36e609e, так как я всегда присваиваю своим USB-накопителям понятные имена. Это можно делать для любой файловой системы, например я могу присвоить имя своей корневой файловой системе:
Запустите sudo e2label [device], чтобы увидеть вашу новую метку. e2label подходит для файловых систем ext2/ext3/ext4, а для XFS, JFS, BtrFS и других файловых систем имеются свои команды. Упростить этот процесс можно с помощью GParted: отключите файловую систему, а затем вы можете присвоить или изменить метку без использования команд для каждой файловой системы.
Основы восстановления данных
Чтобы скопировать весь диск, используйте только имя диска, например /dev/sdb, и не указывайте раздел.
Если у вас есть поврежденные файлы, которые ddrescue не может полностью восстановить, вам понадобятся другие инструменты для их восстановления, такие как Testdisk, Photorec, Foremost или Scalpel. В Arch Linux wiki есть хороший обзор инструментов для восстановления файлов.
В следующих статьях вы найдете описание других средств для восстановления утерянных данных:
Копируем повреждённый накопитель с помощью ddrescue
Добрый день. Сегодня впервые воспользовался программкой ddrescue для создания образа повреждённой карты памяти, остался очень доволен качеством работы, поэтому оставлю небольшую шпаргалку на будущее себе или ещё кому-нибудь, кому понадобится.
Итак, что мы имеем – карта памяти, при попытке копирования данных происходит следующее – часть данных копируется, затем процесс замедляется, оценочное время копирования растёт, скорость падает практически до нуля, затем выдаёт ошибку чтения и всё.
Я попробовал снять образ в R-Studio – но после примерно 4 гигабайт процесс резко останавливался и практически не шёл, при этом в лог вылетало множество ошибок типа “Ошибка на устройстве”… В минуту примерно 3-4 ошибки таких, ну и процесс снятия образа 64Гб флешки оценивался в сутки+… Это не норм.
Оказалось, есть неплохая утилитка под названием ddrescue, которая предназначена специально для подобных мероприятий.
Принцип работы ddrescue
Несмотря на созвучное название, утилита ddrescue не имеет ничего общего с известной линуксовой dd. Это принципиально другой продукт, хотя и способный выполнить схожую задачу, но несколько иными методами.
Программа тесно работает со своим LOG-файлом, в который заносится информация о “плохих” зонах для их последующего уточняющего чтения, поэтому можно в принципе прерваться в любой момент и продолжить вычитку данных, указав тот же самый лог.
Итак, алгоритм такой:
Это примерный алгоритм. Нетрудно заметить, что в двух словах можно описать как последовательное разнонаправленное чтение с постоянным уточнением проблемных зон. Все проблемные места пишутся в специальный LOG-файл для последующего использования.
Установка
В примере ниже вы увидите странное окошко. Это Cygwin – UNIX-подобная среда под Windows с характерными для Unix возможностями (программами и компонентами). То есть если вы хотите себе под Windows например wget, vim, python, diff, а также нормальный терминал с возможностями Linux-ового – это сюда!
Качаем Cygwin нужной архитектуры и ставим. В момент конфигурирования прописываем в поиске ddrescueи отмечаем установку Bin (а попутно поразитесь, сколько там разных компонентов можно поставить):



