Что такое DDL, DML, DCL и TCL в языке SQL
Приветствую всех посетителей сайта Info-Comp.ru! В этом материале я расскажу Вам о том, что такое DDL, DML, DCL и TCL в языке SQL. Если Вы не знаете, что означают эти непонятные наборы букв и при этом работаете с языком SQL, то Вам обязательно необходимо прочитать данный материал.

Для начала давайте вспомним, что такое SQL, и для чего он нужен.
SQL – Structured Query Language
Structured Query Language (SQL) — язык структурированных запросов, с помощью него пишутся специальные запросы (SQL инструкции) к базе данных с целью получения этих данных из базы и для манипулирования этими данными.
Иными словами, язык SQL нужен для работы с базами данных, более подробно о языке SQL можете почитать в отдельной моей статье – Что такое SQL. Назначение и основа.
С точки зрения реализации язык SQL представляет собой набор операторов, которые делятся на определенные группы и у каждой группы есть свое назначение. В сокращенном виде эти группы называются DDL, DML, DCL и TCL.
Таким образом, эти непонятные буквы представляют собой аббревиатуру
названий групп операторов языка SQL.
DDL – Data Definition Language
Data Definition Language (DDL) – это группа операторов определения данных. Другими словами, с помощью операторов, входящих в эту группы, мы определяем структуру базы данных и работаем с объектами этой базы, т.е. создаем, изменяем и удаляем их.
В эту группу входят следующие операторы:
DML – Data Manipulation Language
Data Manipulation Language (DML) – это группа операторов для манипуляции данными. С помощью этих операторов мы можем добавлять, изменять, удалять и выгружать данные из базы, т.е. манипулировать ими.
В эту группу входят самые распространённые операторы языка SQL:
DCL – Data Control Language
Data Control Language (DCL) – группа операторов определения доступа к данным. Иными словами, это операторы для управления разрешениями, с помощью них мы можем разрешать или запрещать выполнение определенных операций над объектами базы данных.
TCL – Transaction Control Language
Transaction Control Language (TCL) – группа операторов для управления транзакциями. Транзакция – это команда или блок команд (инструкций), которые успешно завершаются как единое целое, при этом в базе данных все внесенные изменения фиксируются на постоянной основе или отменяются, т.е. все изменения, внесенные любой командой, входящей в транзакцию, будут отменены.
Группа операторов TCL предназначена как раз для реализации и управления транзакциями. Сюда можно отнести:
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
На сегодня это все, надеюсь, материал был Вам полезен, удачи!
Что такое SQL и как он работает


Википедия гласит, что SQL — это декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных. Не самое удобоваримое определение. Чтобы понять, о чём вообще речь, разберём его.
Декларативный язык программирования говорит, что должно быть сделано, а не как это необходимо сделать. Ещё один пример декларативного языка — HTML. Рассмотрим такой код:
С его помощью мы заявляем (declaration — заявление) браузеру, что хотим увидеть блок с классом className и кнопкой с текстом «Ясно. Понятно.» внутри. Для этого мы не создаём каких-либо переменных, циклов, условий. Мы знаем, что браузер нас понял, сам разберёт команду и вернёт результат или ошибку.
Здесь смысл довольно прост: мы даём команду и получаем результат. Мы не описываем, как эту команду выполнять. Чтобы понять, что такое реляционная база данных, разберём, что такое база данных в принципе. Декомпозируем это понятие на «база» и «данные».
Данные
В контексте баз данных под данными понимают набор значений, который собирается в строки и столбцы, тем самым представляя таблицу. Представим, что у нас есть каталог мебельного магазина. Нам нужно сохранить все данные из раздела «Шкафы» этого каталога в таблицу. Мы решили, что все шкафы отличаются друг от друга характеристиками:
Составим таблицу и вобьём в неё выдуманные данные.

У нас есть таблица с данными. Столбцами мы показываем, как они будут храниться. В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
Добавляя в таблицу строки, я вводил в неё данные, ориентируясь на структуру, заданную в столбцах. Чем больше строк, тем больше данных. Чем больше столбцов, тем подробнее будут эти данные.
Ещё есть такое понятие, как «значение» — это пересечение столбца и строки. Например, у последней строки в столбце «Цвет» написано «хаки». Здесь «хаки» — значение. Если мы начнём группировать таблицы и добавим возможность манипулирования ими, то получим базу данных.
Теперь про базы
Получается, что БД — это совокупность данных, представленных определённым образом (в нашем случае — таблицей), и набор инструментов для манипулирования ими.
Данные могут быть сгруппированы не только в таблицы, но и в коллекции. У каждой базы есть свой инструмент для создания таблиц/коллекций, добавления, удаления или изменения данных, а также для составления выборки. В статье мы рассмотрим базы, которые состоят из таблиц, а инструментом манипулирования данными будет язык SQL.
Таблицы между собой могут объединяться в схемы — в одной базе данных их может быть несколько, а может и не быть деления на схемы вообще. Это зависит от БД.
Вернёмся к определению из Википедии и вспомним про слово «реляционные». Реляционные (от англ. relation — отношения) — это базы данных, таблицы которых могут выстраиваться в различных отношениях. Возьмём предыдущий пример и добавим в него тех самых «отношений». Создадим таблицу «Производитель», а ту, что в примере, обозначим как «Каталог».

Теперь таблицу «Каталог» можно оформить в другом виде:
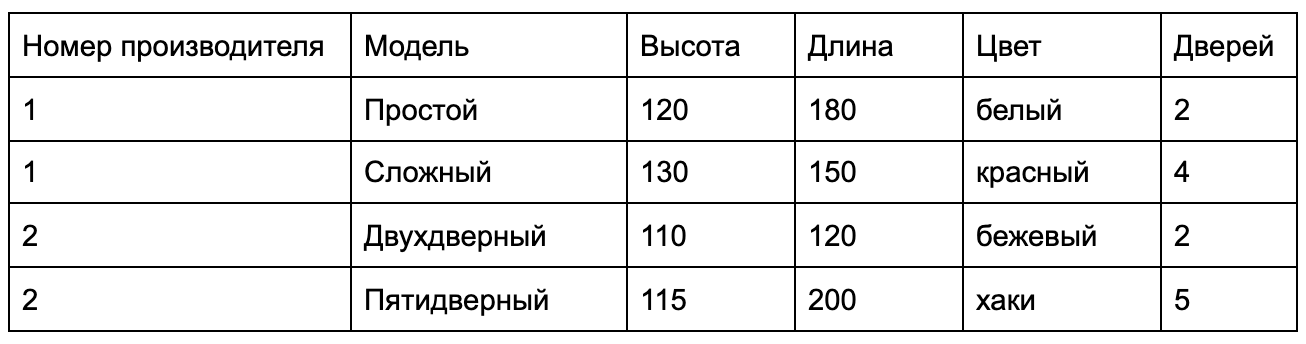
Получилось так, что у таблиц «Каталог» и «Прозводитель» появились отношения. Значения из столбца «Каталог» ссылаются на строки из таблицы «Производитель». Добавлением отношения мы решили нескольких проблем:
Это не все проблемы, которые мы решили добавлением отношений. Для понимания других проблем необходимо углубиться в тему баз данных. Разделение данных на таблицы с отношениями — это процесс нормализации. Так можно достигать различных нормализованных форм данных. При достижении каждой из нормализованных форм мы избавляем данные от дополнительных проблем.
Вернёмся к SQL
Если читателю показалось, что мы ушли в сторону от SQL, так оно и есть. Но очень трудно понять, что такое SQL, не зная, с чем он работает.
Выходит, что SQL — это язык программирования, необходимый для написания команд к БД, после выполнения которых она вернёт результат. Результат будет зависеть от команды, написанной на SQL. Как в любом другом языке программирования, в SQL есть операторы для работы с данными, из которых складываются команды. Операторы распределены по четырём языкам:
DDL (Data Definition Language, язык описания данных) — язык, включающий операторы для работы со структурой данных. Операторы DDL нужны для реализации этих возможностей:
DDL используется, когда нужно создать структуру для хранения данных. Он не отвечает за сами данные — только за то, как они будут разделены по таблицам и схемам.
DML (Data Manipulation Language, язык манипуляции данными) — язык, который нужен для добавления, удаления, изменения данных и для выборки их из базы. Иными словами, для манипулирования данными. Пройдёмся по операторам:
DCL (Data Control Language, язык управления доступом к данным) — набор операторов, необходимых для предоставления доступа к данным. Кроме данных, в БД есть такие сущности, как пользователи. Нужно обязательно иметь возможность ограничить пользователям доступ к данным. Например, мы не хотим, чтобы менеджер проекта мог редактировать данные или их структуру. Для этого есть три группы операторов.
Есть такое понятие, как транзакции. Это набор команд (там может быть и всего одна), который завершается успешно тогда, когда правильно выполнены все команды из него. В случае неудачного завершения одной команды из транзакции, она вся откатывается (отменяются результаты выполнения предыдущих команд), реализуя принцип атомарности. Обычно в транзакцию включаются DML-команды.
Для управления транзакциями существует TCL (Transaction Control Language — язык управления транзакциями). Операторы здесь следующие:
TCL есть только в тех БД, которые поддерживают транзакции. Самое время поговорить о видах БД.
Виды СУБД
Познакомимся с новым понятием — СУБД, системой управления базой данных.
Сергей Кузнецов в книге «Основы баз данных» описал СУБД как комплекс программ, позволяющих создать базу данных (БД) и манипулировать данными (вставлять, обновлять, удалять и выбирать). Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД.
Получается что, СУБД — это SQL плюс комплекс программного обеспечения. Очень часто базы данных путают с системой управления базой данных. Это нормально: понятия неразрывны, сама по себе БД без системы управления мало чем отличается от текстового файла со строчками. Важно не только хранить данные, но и управлять ими. СУБД применяются везде, где нужно структурировано хранить данные — от простого блога до проектов Data Science.
Есть много популярных СУБД, рассмотрим несколько из них.
MySQL
MySQL — свободная реляционная СУБД. Разрабатывалась как легковесная замена тяжёлым СУБД, которую можно было установить на маломощный сервер, без сильных потерь в возможностях. MySQL трудится под капотом таких гигантов, как YouTube, Facebook, Twitter, GitHub.
СУБД написана на C и C++. MySQL породил множество ответвлений, которые сейчас стали самостоятельными СУБД, например Percona и MariaDB.
Oracle Database
История Oracle Database начинается с 1977 года. Это объектно-реляционная система управления данными. Это довольно тяжёлая СУБД, поддерживает системы любой сложности, например, в банковской или финансовой сферах. У неё нет бесплатной лицензии. Процедурный SQL — PL/SQL. Языки написания СУБД — Java/C/С++
Microsoft SQL Server
Microsoft SQL Server — система управления реляционными базами данных, разработанная Microsoft. Первая версия SQL Server появилась 29 апреля 1989 года. Это конкурент Oracle Database. Есть бесплатная лицензия для разработчиков, но не для коммерческого использования. Процедурный SQL — Transact-SQL. СУБД написана на C/C++/C#.
PostgreSQL
PostgreSQL — свободная объектно-реляционная система управления базами данных. Эта СУБД увидела свет 8 июля 1996 года. Конкурент MySQL в веб-разработке проектов любой сложности, также соперничает с базами от Oracle и Microsoft в промышленной разработке. У неё прекрасная русскоязычная документация. Как и MySQL, имеет бесплатную лицензию для коммерческой разработки, за что так же, как и MySQL, горячо любима. Процедурный SQL — PL/pgSQL. Разработана на языке С.
Каждая из приведённых СУБД работает на своём расширении SQL. У каждой — своя ниша применения, плюсы и минусы.
Что после знакомства?
Если вы не знаете, какая конкретно СУБД вам нужна, выбирайте MySQL. Она лишена изысканных возможностей, которые будут только сбивать начинающего разработчика. Большое комьюнити не оставит в беде и уже решило 95% проблем. Разнообразие графических клиентов для всех операционных систем хорошо помогает на ранних этапах. MySQL позволит набраться опыта и понять, чем она хуже или лучше других СУБД. Когда вы поймёте принципы работы MySQL, для вас не составит труда переключиться на работу с PostgreSQL или другой СУБД. Цель работы у всех СУБД одна — рациональное и надёжное хранение данных и быстрое их извлечение или изменение.
После того как вы определитесь с выбором, хорошо будет посмотреть практики других разработчиков на YouTube-каналах «Технострим Mail.ru Group» или HighLoad Channel, почитать замечательный портал ruhighload.com, где, кроме статей про базы данных, рассматриваются проблемы больших нагрузок. А для тех, кто любит почитать больше, подойдёт книга «MySQL по максимуму. 3-е издание» Бэрона Шварца, Петра Зайцева и Вадима Ткаченко. Узнать больше вы, конечно, можете и в GeekBrains — приходите ко мне или моим коллегам на курс «Основы баз данных».
Освоить востребованную профессию в Data Science можно всего за полтора года на курсах GeekBrains. После учёбы вы сможете работать по специальностям Data Scientist, Data Analyst, Machine Learning, Engineer Computer Vision-специалист или NLP-специалист.
Википедия гласит, что SQL — это декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных. Не самое удобоваримое определение. Чтобы понять, о чём вообще речь, разберём его.
Декларативный язык программирования говорит, что должно быть сделано, а не как это необходимо сделать. Ещё один пример декларативного языка — HTML. Рассмотрим такой код:
С его помощью мы заявляем (declaration — заявление) браузеру, что хотим увидеть блок с классом className и кнопкой с текстом «Ясно. Понятно.» внутри. Для этого мы не создаём каких-либо переменных, циклов, условий. Мы знаем, что браузер нас понял, сам разберёт команду и вернёт результат или ошибку.
Здесь смысл довольно прост: мы даём команду и получаем результат. Мы не описываем, как эту команду выполнять. Чтобы понять, что такое реляционная база данных, разберём, что такое база данных в принципе. Декомпозируем это понятие на «база» и «данные».
Данные
В контексте баз данных под данными понимают набор значений, который собирается в строки и столбцы, тем самым представляя таблицу. Представим, что у нас есть каталог мебельного магазина. Нам нужно сохранить все данные из раздела «Шкафы» этого каталога в таблицу. Мы решили, что все шкафы отличаются друг от друга характеристиками:
Составим таблицу и вобьём в неё выдуманные данные.
У нас есть таблица с данными. Столбцами мы показываем, как они будут храниться. В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
Добавляя в таблицу строки, я вводил в неё данные, ориентируясь на структуру, заданную в столбцах. Чем больше строк, тем больше данных. Чем больше столбцов, тем подробнее будут эти данные.
Ещё есть такое понятие, как «значение» — это пересечение столбца и строки. Например, у последней строки в столбце «Цвет» написано «хаки». Здесь «хаки» — значение. Если мы начнём группировать таблицы и добавим возможность манипулирования ими, то получим базу данных.
Теперь про базы
Получается, что БД — это совокупность данных, представленных определённым образом (в нашем случае — таблицей), и набор инструментов для манипулирования ими.
Данные могут быть сгруппированы не только в таблицы, но и в коллекции. У каждой базы есть свой инструмент для создания таблиц/коллекций, добавления, удаления или изменения данных, а также для составления выборки. В статье мы рассмотрим базы, которые состоят из таблиц, а инструментом манипулирования данными будет язык SQL.
Таблицы между собой могут объединяться в схемы — в одной базе данных их может быть несколько, а может и не быть деления на схемы вообще. Это зависит от БД.
Вернёмся к определению из Википедии и вспомним про слово «реляционные». Реляционные (от англ. relation — отношения) — это базы данных, таблицы которых могут выстраиваться в различных отношениях. Возьмём предыдущий пример и добавим в него тех самых «отношений». Создадим таблицу «Производитель», а ту, что в примере, обозначим как «Каталог».
Теперь таблицу «Каталог» можно оформить в другом виде:
Получилось так, что у таблиц «Каталог» и «Прозводитель» появились отношения. Значения из столбца «Каталог» ссылаются на строки из таблицы «Производитель». Добавлением отношения мы решили нескольких проблем:
Это не все проблемы, которые мы решили добавлением отношений. Для понимания других проблем необходимо углубиться в тему баз данных. Разделение данных на таблицы с отношениями — это процесс нормализации. Так можно достигать различных нормализованных форм данных. При достижении каждой из нормализованных форм мы избавляем данные от дополнительных проблем.
Вернёмся к SQL
Если читателю показалось, что мы ушли в сторону от SQL, так оно и есть. Но очень трудно понять, что такое SQL, не зная, с чем он работает.
Выходит, что SQL — это язык программирования, необходимый для написания команд к БД, после выполнения которых она вернёт результат. Результат будет зависеть от команды, написанной на SQL. Как в любом другом языке программирования, в SQL есть операторы для работы с данными, из которых складываются команды. Операторы распределены по четырём языкам:
DDL (Data Definition Language, язык описания данных) — язык, включающий операторы для работы со структурой данных. Операторы DDL нужны для реализации этих возможностей:
DDL используется, когда нужно создать структуру для хранения данных. Он не отвечает за сами данные — только за то, как они будут разделены по таблицам и схемам.
DML (Data Manipulation Language, язык манипуляции данными) — язык, который нужен для добавления, удаления, изменения данных и для выборки их из базы. Иными словами, для манипулирования данными. Пройдёмся по операторам:
DCL (Data Control Language, язык управления доступом к данным) — набор операторов, необходимых для предоставления доступа к данным. Кроме данных, в БД есть такие сущности, как пользователи. Нужно обязательно иметь возможность ограничить пользователям доступ к данным. Например, мы не хотим, чтобы менеджер проекта мог редактировать данные или их структуру. Для этого есть три группы операторов.
Есть такое понятие, как транзакции. Это набор команд (там может быть и всего одна), который завершается успешно тогда, когда правильно выполнены все команды из него. В случае неудачного завершения одной команды из транзакции, она вся откатывается (отменяются результаты выполнения предыдущих команд), реализуя принцип атомарности. Обычно в транзакцию включаются DML-команды.
Для управления транзакциями существует TCL (Transaction Control Language — язык управления транзакциями). Операторы здесь следующие:
TCL есть только в тех БД, которые поддерживают транзакции. Самое время поговорить о видах БД.
Виды СУБД
Познакомимся с новым понятием — СУБД, системой управления базой данных.
Сергей Кузнецов в книге «Основы баз данных» описал СУБД как комплекс программ, позволяющих создать базу данных (БД) и манипулировать данными (вставлять, обновлять, удалять и выбирать). Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД.
Получается что, СУБД — это SQL плюс комплекс программного обеспечения. Очень часто базы данных путают с системой управления базой данных. Это нормально: понятия неразрывны, сама по себе БД без системы управления мало чем отличается от текстового файла со строчками. Важно не только хранить данные, но и управлять ими. СУБД применяются везде, где нужно структурировано хранить данные — от простого блога до проектов Data Science.
Есть много популярных СУБД, рассмотрим несколько из них.
MySQL
MySQL — свободная реляционная СУБД. Разрабатывалась как легковесная замена тяжёлым СУБД, которую можно было установить на маломощный сервер, без сильных потерь в возможностях. MySQL трудится под капотом таких гигантов, как YouTube, Facebook, Twitter, GitHub.
СУБД написана на C и C++. MySQL породил множество ответвлений, которые сейчас стали самостоятельными СУБД, например Percona и MariaDB.
Oracle Database
История Oracle Database начинается с 1977 года. Это объектно-реляционная система управления данными. Это довольно тяжёлая СУБД, поддерживает системы любой сложности, например, в банковской или финансовой сферах. У неё нет бесплатной лицензии. Процедурный SQL — PL/SQL. Языки написания СУБД — Java/C/С++
Microsoft SQL Server
Microsoft SQL Server — система управления реляционными базами данных, разработанная Microsoft. Первая версия SQL Server появилась 29 апреля 1989 года. Это конкурент Oracle Database. Есть бесплатная лицензия для разработчиков, но не для коммерческого использования. Процедурный SQL — Transact-SQL. СУБД написана на C/C++/C#.
PostgreSQL
PostgreSQL — свободная объектно-реляционная система управления базами данных. Эта СУБД увидела свет 8 июля 1996 года. Конкурент MySQL в веб-разработке проектов любой сложности, также соперничает с базами от Oracle и Microsoft в промышленной разработке. У неё прекрасная русскоязычная документация. Как и MySQL, имеет бесплатную лицензию для коммерческой разработки, за что так же, как и MySQL, горячо любима. Процедурный SQL — PL/pgSQL. Разработана на языке С.
Каждая из приведённых СУБД работает на своём расширении SQL. У каждой — своя ниша применения, плюсы и минусы.
Что после знакомства?
Если вы не знаете, какая конкретно СУБД вам нужна, выбирайте MySQL. Она лишена изысканных возможностей, которые будут только сбивать начинающего разработчика. Большое комьюнити не оставит в беде и уже решило 95% проблем. Разнообразие графических клиентов для всех операционных систем хорошо помогает на ранних этапах. MySQL позволит набраться опыта и понять, чем она хуже или лучше других СУБД. Когда вы поймёте принципы работы MySQL, для вас не составит труда переключиться на работу с PostgreSQL или другой СУБД. Цель работы у всех СУБД одна — рациональное и надёжное хранение данных и быстрое их извлечение или изменение.
После того как вы определитесь с выбором, хорошо будет посмотреть практики других разработчиков на YouTube-каналах «Технострим Mail.ru Group» или HighLoad Channel, почитать замечательный портал ruhighload.com, где, кроме статей про базы данных, рассматриваются проблемы больших нагрузок. А для тех, кто любит почитать больше, подойдёт книга «MySQL по максимуму. 3-е издание» Бэрона Шварца, Петра Зайцева и Вадима Ткаченко. Узнать больше вы, конечно, можете и в GeekBrains — приходите ко мне или моим коллегам на курс «Основы баз данных».
Освоить востребованную профессию в Data Science можно всего за полтора года на курсах GeekBrains. После учёбы вы сможете работать по специальностям Data Scientist, Data Analyst, Machine Learning, Engineer Computer Vision-специалист или NLP-специалист.
DDL. Таблицы
Дата добавления: 2015-07-09 ; просмотров: 2286 ; Нарушение авторских прав
DDL (Data Definition Language) – язык описания данных, составная часть SQL. Рассмотрим команды создания базы данных и таблиц.
Для создания базы данных служит команда
CREATE DATABASE имя_БД
Для активизации базы данных служит команда
Выполняйте команду активизации базы данных при каждом запуске SQL Management Studio, поскольку по умолчанию в качестве активной установлена БД master.
Для создания таблиц используется команда CREATE TABLE.
Краткий формат этой команды (квадратные скобки означают необязательные элементы):
CREATE TABLE имя_таблицы(
Более подробно смотрите в MSDN.
Определение поля имеет формат:
Ограничение поля имеет формат
Чаще всего используются типы полей:
VARCHAR – строковый тип переменной длины;
NUMERIC – числовой тип;
DATETIME – тип дата/время.
Какие еще типы полей есть в SQL server? – обращайтесь кMSDN.
NULL – специальное «неопределенное» значение, предусмотренное стандартом SQL. Определение NULL/NOT NULL служит для указания, что данный тип поля допускает/запрещает ввод NULL-значений.
IDENTITY начальное_значение, приращение – определение, указывающее, что данное поле представляет собой счетчик. Это означает, что значения в данное поле вставляются сервером с нарастанием автоматически при вставке строки. Если «начальное_значение» и «приращение» пропущены, они полагаются равными 1.
DEFAULT умолчание – определение, указывающее значение по умолчанию, т.е., значение, которое присваивается данному полю, если при вставке новой строки этому полю не было явно присвоено некоторое значение.
CHECK (условие)- ограничение, содержащее условие на поле, которое будет проверяться при вводе новых строк и при изменении значений в уже существующих строках. Если при добавлении или изменении строки условие оказывается ложным, то строка не добавляется/ не изменяется.
PRIMARY KEY – ограничение, указывающее, что в данной таблице данное поле представляет собой первичный ключ. (Составной первичный ключ таким образом объявлять нельзя!) При использовании этого ограничения создается первичный индекс.
UNIQUE – ограничение, указывающее, что в данном поле могут храниться только уникальные значения. При использовании этого ограничения создается уникальный индекс.
Например, в таблице «Предприятия» номер предприятия будет первичным ключом и счетчиком, название фирмы не допускает значений NULL:
CREATE TABLE k_firm
(firm_num NUMERIC(6) IDENTITY PRIMARY KEY,
firm_name VARCHAR(100) NOT NULL,
В таблице «Договоры» для поля даты договора задается значение по умолчанию – текущая дата, для типа договора задается условие, что он должен принадлежать заданному списку значений.
CREATE TABLE k_contract
contract_num NUMERIC(6) IDENTITY PRIMARY KEY,
contract_date DATETIME DEFAULT GETDATE(),
CHECK (contract_type IN (‘A’,’B’,’C’)),
firm_num NUMERIC(6) NOT NULL,
Декларативная ссылочная целостность требует, чтобы в поле внешнего ключа можно было вводить только такие значения первичного ключа, которые присутствуют в родительской таблице. Например, в таблицу «Сотрудники» мы не можем внести номер несуществующего отдела. Кроме того, из родительской таблицы нельзя удалить строку, если в дочерней таблице имеются строки с таким внешним ключом. Мы не можем удалить отдел, если с ним связаны сотрудники.
CREATE TABLE k_staff
(staff_num NUMERIC(6) IDENTITY,
staff_name VARCHAR(30) NOT NULL,
REFERENCES k_dept (dept_num),
staff_hiredate DATETIME NOT NULL,
Ограничения уровня таблицы задаются после списка определений полей. Каждое из них содержит ключевое слово CONSTRAINT и уникальное имя. Эти ограничения применяются обычно в том случае, если включают в себя несколько полей, например, составной первичный или внешний ключ или условие CHECK, содержащее сразу несколько полей таблицы. Следует заметить, что любое ограничение уровня поля можно переписать как ограничение уровня таблицы.
Ограничение CHECK уровня таблицы может быть определено, например, так:
CREATE TABLE k_bill
(bill_num NUMERIC(6) IDENTITY PRIMARY KEY,
bill_date DATETIME DEFAULT GETDATE(),
bill_term DATETIME DEFAULT GETDATE()+30,
CONSTRAINT ch_bill_date CHECK (bill_term-bill_date



