Здесь про это:
Выберем две строки и два столбца:
Осуществим выборку строк и столбцов с помощью среза:
Выберем 1 значение из столбца и указанной колонки:
Результат:
Доступ к строкам и колонкам по индексу возможен несколькими способами:



Как выбрать строки из Pandas DataFrame по условию
Собираем тестовый набор данных для иллюстрации работы выборки по условию
| Color | Shape | Price |
| Green | Rectangle | 10 |
| Green | Rectangle | 15 |
| Green | Square | 5 |
| Blue | Rectangle | 5 |
| Blue | Square | 10 |
| Red | Square | 15 |
| Red | Square | 15 |
| Red | Rectangle | 5 |
Пишем скрипт:
Синтаксис выборки строк из Pandas DataFrame по условию
Вы можете использовать следующую логику для выбора строк в Pandas DataFrame по условию:
А вот полный код Python для нашего примера:
Результат:
Выберем строки, где цена равна или больше 10
Чтобы получить все строки, где цена равна или больше 10, Вам нужно применить следующее условие:
Результат:
Выберем строки, в которых цвет зеленый, а форма — прямоугольник
Теперь цель состоит в том, чтобы выбрать строки на основе двух условий:
Мы будем использовать символ & для применения нескольких условий. В нашем примере код будет выглядеть так:
Полный код примера Python для выборки Pandas DataFrame:
Результат:
Выберем строки, где цвет зеленый ИЛИ форма прямоугольная
Для достижения этой цели будем использовать символ | следующим образом:
Полный код Python 3:
Выберем строки, где цена не равна 15
Полный код Pandas DF на питоне:
Результат работы скрипта Python:
Опубликовано Вадим В. Костерин
ст. преп. кафедры ЦЭиИТ. Автор более 130 научных и учебно-методических работ. Лауреат ВДНХ (серебряная медаль). Посмотреть больше записей
How are iloc and loc different?
Can someone explain how these two methods of slicing are different?
I’ve seen the docs, and I’ve seen these answers, but I still find myself unable to understand how the three are different. To me, they seem interchangeable in large part, because they are at the lower levels of slicing.
Can someone present three cases where the distinction in uses are clearer?
Once upon a time, I also wanted to know how these two functions differ from df.ix[:5] but ix has been removed from pandas 1.0, so I don’t care anymore.


5 Answers 5
Label vs. Location
The main distinction between the two methods is:
loc gets rows (and/or columns) with particular labels.
iloc gets rows (and/or columns) at integer locations.
To demonstrate, consider a series s of characters with a non-monotonic integer index:
Here are some of the differences/similarities between s.loc and s.iloc when passed various objects:
| description | s.loc[ ] | s.iloc[ ] | |
|---|---|---|---|
| 0 | single item | Value at index label 0 (the string ‘d’ ) | Value at index location 0 (the string ‘a’ ) |
| 0:1 | slice | Two rows (labels 0 and 1 ) | One row (first row at location 0) |
| 1:47 | slice with out-of-bounds end | Zero rows (empty Series) | Five rows (location 1 onwards) |
| 1:47:-1 | slice with negative step | three rows (labels 1 back to 47 ) | Zero rows (empty Series) |
| [2, 0] | integer list | Two rows with given labels | Two rows with given locations |
| s > ‘e’ | Bool series (indicating which values have the property) | One row (containing ‘f’ ) | NotImplementedError |
| (s>’e’).values | Bool array | One row (containing ‘f’ ) | Same as loc |
| 999 | int object not in index | KeyError | IndexError (out of bounds) |
| -1 | int object not in index | KeyError | Returns last value in s |
| lambda x: x.index[3] | callable applied to series (here returning 3 rd item in index) | s.loc[s.index[3]] | s.iloc[s.index[3]] |
loc ‘s label-querying capabilities extend well-beyond integer indexes and it’s worth highlighting a couple of additional examples.
Here’s a Series where the index contains string objects:
For DateTime indexes, we don’t need to pass the exact date/time to fetch by label. For example:
Then to fetch the row(s) for March/April 2021 we only need:
Rows and Columns
loc and iloc work the same way with DataFrames as they do with Series. It’s useful to note that both methods can address columns and rows together.
When given a tuple, the first element is used to index the rows and, if it exists, the second element is used to index the columns.
Consider the DataFrame defined below:
For example, consider the following DataFrame. How best to slice the rows up to and including ‘c’ and take the first four columns?
We can achieve this result using iloc and the help of another method:
get_loc() is an index method meaning «get the position of the label in this index». Note that since slicing with iloc is exclusive of its endpoint, we must add 1 to this value if we want row ‘c’ as well.

iloc works based on integer positioning. So no matter what your row labels are, you can always, e.g., get the first row by doing
or the last five rows by doing
You can also use it on the columns. This retrieves the 3rd column:
You can combine them to get intersections of rows and columns:
Then we can get the first row by
and the second two rows of the ‘date’ column by
and so on. Now, it’s probably worth pointing out that the default row and column indices for a DataFrame are integers from 0 and in this case iloc and loc would work in the same way. This is why your three examples are equivalent. If you had a non-numeric index such as strings or datetimes, df.loc[:5] would raise an error.
Also, you can do column retrieval just by using the data frame’s __getitem__ :
I think it’s also worth mentioning that you can pass boolean vectors to the loc method as well. For example:
See my extremely detailed blog series on subset selection for more
.ix is deprecated and ambiguous and should never be used
Before we talk about the differences, it is important to understand that DataFrames have labels that help identify each column and each index. Let’s take a look at a sample DataFrame:

.loc selects data only by labels
This returns the row of data as a Series
This returns a DataFrame with the rows in the order specified in the list:

Slice notation is defined by a start, stop and step values. When slicing by label, pandas includes the stop value in the return. The following slices from Aaron to Dean, inclusive. Its step size is not explicitly defined but defaulted to 1.

Complex slices can be taken in the same manner as Python lists.
.iloc selects data only by integer location
This returns the 5th row (integer location 4) as a Series
This returns a DataFrame of the third and second to last rows:


For example, we can select rows Jane, and Dean with just the columns height, score and state like this:

This uses a list of labels for the rows and slice notation for the columns
Simultaneous selection with labels and integer location
.ix was used to make selections simultaneously with labels and integer location which was useful but confusing and ambiguous at times and thankfully it has been deprecated. In the event that you need to make a selection with a mix of labels and integer locations, you will have to make both your selections labels or integer locations.
Or alternatively, convert the index labels to integers with the get_loc index method.
Boolean Selection
Selecting all rows

Most people are familiar with the primary purpose of the DataFrame indexing operator, which is to select columns. A string selects a single column as a Series and a list of strings selects multiple columns as a DataFrame.
Using a list selects multiple columns

What people are less familiar with, is that, when slice notation is used, then selection happens by row labels or by integer location. This is very confusing and something that I almost never use but it does work.


Чем отличаются iloc, ix и loc?
Может ли кто-нибудь представить три случая, когда различие в использовании яснее?
2 ответа
iloc работает на основе целочисленного позиционирования. Поэтому независимо от того, какие у вас метки строк, вы всегда можете, например, получить первый ряд, выполнив
Или последние пять строк, выполнив
Вы также можете использовать его на столбцах. Это возвращает 3-й столбец:
Вы можете объединить их, чтобы получить пересечения строк и столбцов:
Тогда мы можем получить первый ряд
А вторые две строки столбца ‘date’
И так далее. Теперь, вероятно, стоит указать, что индексы строк и столбцов по умолчанию для DataFrame являются целыми числами от 0, и в этом случае iloc и loc будут работать аналогичным образом. Вот почему ваши три примера эквивалентны. Если бы у вас был нечисловой индекс, например, строки или даты и времени, df.loc[:5] возникнет ошибка.
Кроме того, вы можете выполнять извлечение столбцов, используя __getitem__ фрейма данных:
Смотрите мой чрезвычайно подробный сериал блогов по выбору подмножества для большего
.ix устарела и неоднозначна и никогда не должна использоваться
Прежде чем говорить о различиях, важно понять, что в фреймах данных есть метки, которые помогают идентифицировать каждый столбец и каждый индекс. Давайте посмотрим на пример DataFrame:
.loc выбирает данные только по меткам
Это возвращает строку данных в виде серии
Это возвращает DataFrame со строками в порядке, указанном в списке:
Обозначение среза определяется значениями start, stop и step. При разрезании по метке pandas включает в себя значение остановки в возвращаемом значении. Следующие кусочки от Аарона до Дина включительно. Размер шага явно не определен, но по умолчанию равен 1.
Сложные фрагменты могут быть взяты так же, как списки Python.
.iloc выбирает данные только по целому расположению
Это возвращает 5-ую строку (целочисленное расположение 4) как серию
Это возвращает DataFrame третьей и второй до последней строки:
Например, мы можем выбрать строки Джейн и Дина только с высотой, счетом и состоянием столбцов следующим образом:
При этом используется список меток для строк и нотации для столбцов
Одновременный выбор с метками и целочисленным расположением
.ix использовался, чтобы делать выборки одновременно с метками и целочисленным местоположением, что было полезно, но иногда сбивало с толку и неоднозначно, и, к счастью, это не рекомендуется. В случае, если вам нужно сделать выборку с сочетанием меток и целочисленных местоположений, вы должны будете сделать как метки выбора, так и целочисленные местоположения.
Логическое выделение
Выбор всех строк
Оператор индексирования [] также может выбирать строки и столбцы, но не одновременно.
Использование списка выбирает несколько столбцов
Люди менее знакомы с тем, что при использовании обозначения среза выбор происходит по меткам строк или по целочисленному расположению. Это очень сбивает с толку и то, что я почти никогда не использую, но это работает.
loc vs iloc in Pandas
What’s the difference between loc[]and iloc[] in Python and Pandas


Introduction
In today’s article we are going to discuss the difference between these two properties. We’ll also go through a couple of examples to make sure you understand when to use one over the other.
First, let’s create a pandas DataFrame that we’ll use as an example to demonstrate a few concepts.
Slicing using loc[]
loc[] property is used t o slice a pandas DataFrame or Series and access row(s) and column(s) by label. This means that the input label(s) will correspond to the indices of rows that should be returned.
loc also accepts an array of labels:
Slicing using iloc[]
On the other hand, iloc property offers integer-location based indexing where the position is used to retrieve the requested rows.
Therefore, whenever we pass an integer to iloc you should expect to retrieve the row with the corresponding positional index. In the example below, iloc[1] will return the row in position 1 (i.e. the second row):
Again, you can even pass an array of positional indices to retrieve a subset of the original DataFrame. For example,
Or even a slice object of integers:
iloc can also accept a callable function that accepts a single argument of type pd.Series or pd.DataFrame and returns an output which is valid for indexing.
For instance, in order to retrieve only the rows with odd index a simple lambda function should do the trick:
Finally, you can also use iloc to index both axes. For example, in order to fetch the first two records and discard the last column you should call
Final Thoughts
It’s very important to understand the differences between these two properties and be able to use them effectively in order to create the desired output for your specific use-case. loc is used to index a pandas DataFrame or Series using labels. On the other hand, iloc can be used to retrieve records based on their positional index.
How to use loc and iloc for Selecting Data in Pandas (with Python code!)
What is the difference between loc and iloc in Pandas?
Put this down as one of the most common questions you’ll hear from Python newcomers and data science aspirants. There is a high probability you’ll encounter this question in a data scientist or data analyst interview.
Honestly, even I was confused initially when I started learning Python a few years back. But don’t worry! loc vs. iloc in Pandas might be a tricky question – but the answer is quite simple once you get the hang of it.

And that’s what I aim to help you achieve in this article. We will rely on Pandas, the most popular Python library, to answer the loc vs. iloc question.
The Pandas library contains multiple methods for convenient data filtering – loc and iloc among them. Using these, we can do practically any data selection task on Pandas dataframes.
Do check out our two popular Python courses if you’re new to Python programming. They’re free and a great first step in your machine learning journey:
Right, let’s dive in!
loc vs. iloc in Pandas
So, what is loc and iloc in the first place? We need to answer this question before we can understand where to use each of these Pandas functions in Python.
loc in Pandas
loc is label-based, which means that we have to specify the name of the rows and columns that we need to filter out.
For example, let’s say we search for the rows whose index is 1, 2 or 100. We will not get the first, second or the hundredth row here. Instead, we will get the results only if the name of any index is 1, 2 or 100.
So, we can filter the data using the loc function in Pandas even if the indices are not an integer in our dataset.
iloc in Pandas
On the other hand, iloc is integer index-based. So here, we have to specify rows and columns by their integer index.
Let’s say we search for the rows with index 1, 2 or 100. It will return the first, second and hundredth row, regardless of the name or labels we have in the index in our dataset.
We will see multiple examples in this article on how to use loc and iloc for the data selection and data update process in Python.
loc and iloc in Action (using Pandas in Python)
Time to fire up your Jupyter notebook! We’ll dive straight into the code and understand how and where to use loc vs. iloc in Python.
Create a sample dataset
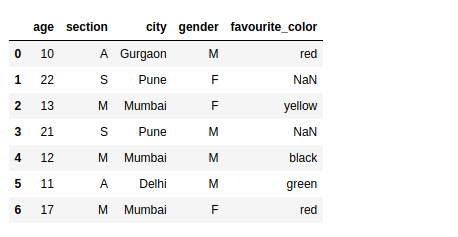
First, we need a dataset to apply loc and iloc, right? Let’s do that.
We will create a sample student dataset consisting of 5 columns – age, section, city, gender, and favorite color. This dataset will contain both numerical as well as categorical variables:

Find all the rows based on any condition in a column
One thing we use almost always when we’re exploring a dataset – filtering the data based on a given condition. For example, we might need to find all the rows in our dataset where age is more than x years, or the city is Delhi, and so on.
We can solve types of queries with a simple line of code using pandas.DataFrame.loc[]. We just need to pass the condition within the loc statement.
Let’s try to find the rows where the value of age is greater than or equal to 15:
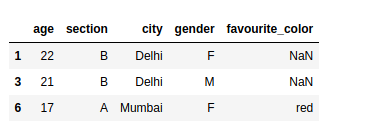
Try out the above code in the live coding window below!!
Find all the rows with more than one condition
Similarly, we can also use multiple conditions to filter our data, such as finding all the rows where the age is greater than or equal to 12 and the gender is also male:

Select a range of rows using loc
Using loc, we can also slice the Pandas dataframe over a range of indices. If the indices are not in the sorted order, it will select only the rows with index 1 and 3 (as you’ll see in the below example). And if the indices are not numbers, then we cannot slice our dataframe.
In that case, we need to use the iloc function to slice our Pandas dataframe.
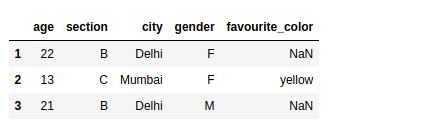
Select only required columns with a condition
We can also select the columns that are required of the rows that satisfy our condition.
For example, if our dataset contains hundreds of columns and we want to view only a few of them, then we can add a list of columns after the condition within the loc statement itself:
Update the values of a particular column on selected rows
This is one of my favorite hacks in Python Pandas!
We often have to update values in our dataset based on a certain condition. For example, if the values in age are greater than equal to 12, then we want to update the values of the column section to be “M”.
We can do this by running a for loop as well but if our dataset is big in size, then it would take forever to complete the task. Using loc in Pandas, we can do this within seconds, even on bigger datasets!
We just need to specify the condition followed by the target column and then assign the value with which we want to update:

Update the values of multiple columns on selected rows
If we want to update multiple columns with different values, then we can use the below syntax.
In this example, if the value in the column age is greater than 20, then the loc function will update the values in the column section with “S” and the values in the column city with Pune:
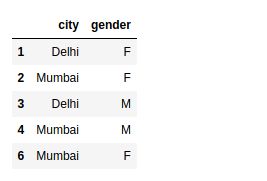
Select rows with indices using iloc
When we are using iloc, we need to specify the rows and columns by their integer index. If we want to select only the first and third row, we simply need to put this into a list in the iloc statement with our dataframe:

Select rows with particular indices and particular columns
Earlier, we selected a few columns from the dataset using the loc function. We can do this using the iloc function. Keep in mind that we need to provide the index number of the column instead of the column name:

Select a range of rows using iloc
We can slice a dataframe using iloc as well. We need to provide the start_index and end_index+1 to slice a given dataframe. If the indices are not the sorted numbers even then it will select the starting_index row number up to the end_index:

Select a range of rows and columns using iloc
Slice the data frame over both rows and columns. In the below example, we selected the rows from (1-2) and columns from (2-3).

loc and iloc are two super useful functions in Pandas that I’ve come to rely on a lot. I’m sure you’ll be using them as well in your machine learning journey. And if you’re an R user switching to Python, I’m sure you’ll find loc and iloc quite intuitive.
I highly recommend taking our Python for Data Science and Pandas for Data Analysis in Python courses if you’re new to Python programming. They’re free and a great first step in your machine learning journey.



