Чем отличаются наука о данных, анализ данных и машинное обучение
Перевод статьи Клеофаса Мулонго «Difference Between Data Science, Analytics And Machine Learning».

Наука о данных, машинное обучение и анализ данных это три главные сферы деятельности, получившие в последние годы огромную популярность. Для профессионалов в этих областях настал их звездный час. Спрос на них на рынке труда высок. Предсказывают, что к 2020 году в этих сферах деятельности будет много открытых вакансий.
Так что же означают эти названия? Чем отличаются эти сферы деятельности? Чтобы ответить на эти и другие вопросы, мы сравнили науку о данных, машинное обучение и анализ данных.
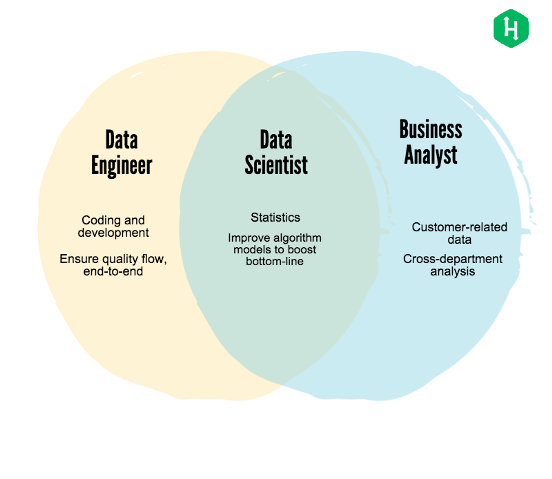
Наука о данных
Что такое наука о данных?
Хотя этот предмет имеет множество определений, мы воспользуемся самым распространенным, которое будет понятно всем. Наука о данных это концепция, которая используется для работы с большими данными. Эта концепция включает аспекты подготовки данных, очистки данных и анализа данных.
В нормальных обстоятельствах человек, занимающийся наукой о данных, собирает данные из различных источников и применяет различные техники для того чтобы извлечь из этих наборов данных осмысленную информацию. Среди часто используемых при этом методов можно назвать предикативную аналитику, анализ настроений и даже машинное обучение.
Люди, занимающиеся наукой о данных, рассматривают эти данные с точки зрения бизнеса. Они стараются делать прогнозы максимально точно, поскольку на их основе могут приниматься решения.
Навыки, необходимые, чтобы заниматься наукой о данных
Вы хотите быть профессиональным data scientist? Есть несколько ключевых областей специализации, на которых вам нужно будет сфокусироваться. Это программирование, аналитика и предметная область (узкоспециальные знания).
Вам нужно будет приобрести следующие знания и навыки:
Машинное обучение
Начнем с главного. Что такое машинное обучение?
Машинное обучение можно описать как процесс использования алгоритмов для тщательного исследования данных и извлечения из них осмысленной информации. Машинное обучение также может использовать заданные наборы данных для предсказания будущих тенденций. Годами программное обеспечение для машинного обучения использует статистический и предикативный анализ для определения шаблонов и выявления в них скрытых, но имеющих значение знаний.
Прекрасным примером реализации машинного обучения в жизни является алгоритм Facebook. Этот алгоритм создан для изучения вашего поведения в этой социальной сети. Полученные знания он затем использует для формирования вашей ленты. Amazon изучит ваше поведение в браузере, чтобы рекомендовать вам продукты, которые вы, вероятно, захотите купить. То же самое касается Netflix. Он будет рекомендовать вам фильмы, исходя из ваших привычек браузинга.
Что нужно, чтобы стать экспертом в машинном обучении?
Если рассматривать строго, то машинное обучение можно считать ответвлением как информатики, так и статистики. Если вы планируете остановить свой выбор на этой карьере, вам следует:

Чем отличаются наука о данных и машинное обучение?
Наука о данных это широкое поле деятельности, которое включает в себя многие дисциплины. Машинное обучение подпадает под понятие науки о данных, ведь оно применяет несколько техник, обычно используемых в этой сфере.
А вот наука о данных может быть производной машинного обучения, а может и не быть. Она включает в себя много дисциплин, в отличие от машинного обучения, которое концентрируется на одном предмете.
Анализ данных
Анализ данных, чтобы прийти к какому-то выводу, влечет за собой появление описательной статистики и визуализации данных. Он очень связан со статистикой. Аналитик должен уметь работать с числами. В большинстве случаев анализ данных рассматривается как базовая версия науки о данных.
Если вы занимаетесь анализом данных, вы должны хорошо уметь объяснять разнообразные причины, почему данные именно такие, какие есть. Вы должны уметь представлять данные таким образом, чтобы они были понятны каждому, а не только экспертам.
Какие навыки нужны, чтобы работать в сфере анализа данных?
Вы должны хорошо разбираться в следующих областях знаний:
Как видите, все три сферы деятельности тесно связаны друг с другом. Однако между ними существуют различия, о которых мы вам и рассказали в нашей статье. Надеемся, теперь вы сможете лучше различать науку о данных, машинное обучение и анализ данных.
В чем разница между наукой о данных, анализом данных, большими данными, аналитикой, дата майнингом и машинным обучением
В последнее время слово big data звучит отовсюду и в некотором роде это понятие стало мейнстримом. С большими данными тесно связаны такие термины как наука о данных (data science), анализ данных (data analysis), аналитика данных (data analytics), сбор данных (data mining) и машинное обучение (machine learning).
Почему все стали так помешаны на больших данных и что значат все эти слова?

Почему все молятся на биг дату
Чем больше данных, тем сложнее с ними работать и анализировать. Математические модели, применимые к небольшим массивам данных скорее всего не сработают при анализе биг даты. Тем не менее в науке о данных большие данные занимают важное место. Чем больше массив, тем интересней будут результаты, извлеченные из глубоких недр большой кучи данных.

Преимущества больших данных:
Наука о данных
Наука о данных это глубокие познания о выводимых данных. Чтобы заниматься наукой о данных необходимо знать математику на высоком уровне, алгоритмические техники, бизнес-аналитику и даже психологию. Все это нужно чтобы перелопатить огромную кучу инфы и обнаружить полезный инсайт или интересные закономерности.
Наука о данных базируется вокруг строгих аналитических доказательств и работает со структурированными и не структурированными данными. В принципе все, что связано с отбором, подготовкой и анализом, лежит в пределах науки о данных.
Примеры применения науки о данных:

Аналитика
Аналитика — это наука об анализе, применении анализа данных для принятия решений.
Аналитика данных предназначена для внедрения инсайтов в массив данных и предполагает использование информационных запросов и процедур объединения данных. Она представляет различные зависимости между входными параметрами. Например, автоматически выявленные, не очевидные связи между покупками.
В науке о данных для построения прогнозируемой модели используются сырые данные. В аналитике зачастую данные уже подготовлены, а отчеты может интерпретировать практически любой юзер. Аналитику не нужны глубокие знания высшей математики, достаточно хорошо оперировать данными и строить удачные прогнозы.
Анализ данных
Анализ данных — это деятельность специалиста, которая направлена на получение информации о массиве данных. Аналитик может использовать различные инструменты для анализа, а может строить умозаключения и прогнозы полагаясь на накопленный опыт. Например, трейдер Forex может открывать и закрывать трейдерские позиции, основываясь на простых наблюдениях и интуиции.
Машинное обучение
Машинное обучение тесно связано с наукой о данных. Это техника искусственного обучения, которую применяют для сбора больших данных. По-простому это возможность обучить систему или алгоритм получать различные представления из массива.
При машинном обучении для построения модели прогнозирования целевых переменных используется некий первичный набор знаний. Машинное обучение применимо к различным типам сложных систем: от регрессионных моделей и метода опорных векторов до нейронных сетей. Здесь центром является компьютер, который обучается распознавать и прогнозировать.
Примеры алгоритмов:

Отбор данных
Сырые данные изначально беспорядочны и запутаны, собраны из различных источников и непроверенных записей. Не очищенные данные могут скрыть правду, зарытую глубоко в биг дате, и ввести в заблуждение аналитика.
Дата майнинг — это процесс очистки больших данных и подготовки их последующему анализу или использованию в алгоритмах машинного обучения. Дата майнеру нужно обладать исключительными распознавательными качествами, чудесной интуицией и техническими умениями для объединения и трансформирования огромного количества данных.
Data Science и Machine Learning: с чего начать и где учиться
Меня зовут Ольга Мажара, я преподаю «Искусственный интеллект» в КПИ им. Игоря Сикорского и являюсь Senior Java Developer в Intellias.
Я училась в КПИ на теплоэнергетическом факультете по специальности программист. В то далекое время Data Science и ML не были мейнстримом и изучались фрагментарно в рамках других курсов, таких как ИИ или математические методы. Позже, после окончания аспирантуры, преподавала машинное обучение на этой же кафедре. Параллельно работала в Samsung R&D Institute Ukraine. Многие кухонные разговоры на работе были посвящены подходам к изучению Data Science, и мне было интересно сравнивать мнение коллег и студентов.
Сейчас я преподаю на факультете информатики и вычислительной техники. Сегодня Data Science и Machine Learning стали довольно популярны — четверть дисциплин и половина дипломных работ на курсе посвящены этому направлению. Однако, если раньше была проблема в недостатке информации, сейчас есть запрос на структуризацию и помощь в выборе курса, который даст необходимый для работы минимум навыков.
Данная статья написана для тех, кто хочет попробовать себя в Data Science и машинном обучении, но не знает, с чего начать и какие знания для этого нужны.
Что такое Data Science и Machine Learning
Прежде чем говорить об обучении, начнем с разбора терминологии. Data Science — это общее наименование дисциплин по изучению данных, а Machine Learning — это подразделение Data Science, которое занимается построением умных моделей. Такие модели могут использоваться для предсказания покупки товара пользователем, рекомендаций в соцсетях (рекомендательные системы), распознавания изображений и так далее.
Data Science специалисты занимаются исследованиями. В иностранных компаниях такой должности соответствуют позиции research-инженеров — это в большей мере математики, которые работают с теоретической частью алгоритмов и исследуют разнообразные закономерности. Machine Learning инженеры, в свою очередь, занимаются построением моделей на основе полученных данных. Но такое разделение существует лишь в теории или же только в некоторых странах.
В Украине Data Science и Machine Learning ранее использовались как слова-синонимы, сейчас же эти понятия уже начинают разделять. В наших реалиях вакансии, где необходимо знание Machine Learning, зачастую называются Data Scientist и наоборот. Поэтому, если вы хотите работать с данными, вам следует изучить и то, и другое.
Процесс обучения Data Science и Machine Learning можно разбить на пять блоков:
Рассмотрим каждый из них более детально.
Математика
Для начала давайте разберемся, нужна ли вообще математика в работе с Data Science и Machine Learning. Коротким ответом будет: да, нужна. Безусловно, есть много примеров того, как успешные Data Scientists занимают призовые места на Кaggle-соревнованиях, не имея при этом технического образования. Но даже они согласятся, что знание математики дает значительное преимущество в работе с Data Science.
Несмотря на то, что почти все алгоритмы реализуются в библиотеках Python и R, понимание базовых математических концепций значительно упростит вашу учебу и выполнение прикладных задач. Кроме того, в большинстве статей о машинном обучении содержатся математические выкладки, читать которые без знаний математики будет затруднительно.
Для успешной работы минимально нужно понимать три раздела математики:
Язык программирования
Для работы с данными вы должны уметь программировать. Например, чтобы загрузить данные, распарсить, синтезировать новые признаки или воплотить в жизнь любую другую вашу идею. Основным языком программирования большинства Data Science специалистов является Python.
Python сам по себе очень простой язык, в нем реализовано множество библиотек для обработки и анализа данных. Популярные ранее R и Matlab сегодня встречается все реже и реже, поэтому, если вы только начинаете осваивать Data Science, сосредоточьтесь на изучении Python.
Базовые алгоритмы машинного обучения
Для того чтобы начать свой профессиональный путь в машинном обучении, вам необходимо знать основные классы задач Machine Learning, какие существуют алгоритмы и какие подходы позволяют решить тот или иной класс задач. Вы также должны различать алгоритмы разных специализаций, понимать их преимущества и недостатки.
На Coursera есть хороший курс с легкой и наглядной подачей материала, который поможет разобраться во всех этих аспектах. Несмотря на то, что в этом курсе используется Octave, а не Python, вам стоит его пройти. Здесь изучите основы и принципы машинного обучения, а также получите необходимые знания по линейной алгебре. Курс не требует какой-либо предварительной подготовки и подходит всем, кто собирается изучать Data Science.
Теоретическая часть курсов на Coursera бесплатная, а практическая — платная. Но, если у вас нет возможности заплатить за практику, вы можете поискать решения других студентов и специалистов на гитхабе. Кроме того, есть различные специализированные курсы от университетов — Стэнфорда, Гарварда, Мичигана, Университета Дюка и так далее.
Также не забывайте, что машинное обучение — практическая дисциплина, поэтому очень важно применять полученные знания на реальных данных. Возьмите за правило заходить на Kaggle — это платформа для соревнований по Data Science. Здесь вы найдете множество датасетов, на которых сможете разобрать решения других участников и попрактиковать свои аналитические навыки. И со временем сможете попытать счастья в каком-нибудь открытом конкурсе.
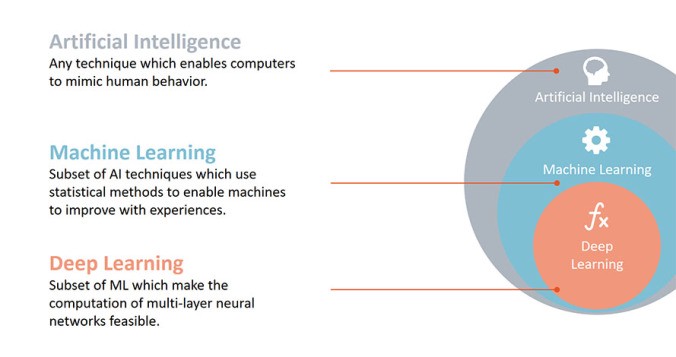
Deep Learning
Имея базовое понимание принципов машинного обучения и знание Python, можно приступить к изучению Deep Learning. Это один из разделов машинного обучения, в основе которого лежит использование нейронных сетей. Тут я рекомендую к изучению курс Deep Learning Specialization.
Отдельные специализации
Отдельные специализации в машинном обучении можно проходить, когда вы изучили и материалы и решили несколько прикладных кейсов. Если подытожить, ваше обучение может выглядеть следующим образом:

Сложно ли выучить Data Science
Все зависит от вашего бэкграунда и склада ума. С хорошо развитыми аналитическими способностями и знанием математики ваш путь в Data Science будет довольно простым. Если вы на данный момент учитесь в школе или в университете, старайтесь участвовать в математических олимпиадах. Они помогут сформировать базис аналитического мышления и значительно облегчат освоение профессии в будущем.
Если же решили перейти в Data Science из другой сферы, я бы рекомендовала решать практические задачи на Kaggle. Решайте их самостоятельно, разбирайте решения других людей — все это помогает развивать логику и аналитику. Обратите внимание на блоги различных Data Scientists, YouTube-каналы с разбором и описанием того, как они строили модель, какую логику вкладывали в решение.
Кроме того, в свободном доступе есть много данных, на которых можно практиковаться. Возьмите, к примеру, статистику по заболеваемости COVID-19 и попробуйте найти закономерности (такой конкурс недавно проводили на Kaggle). Вы можете посмотреть на чужие хорошие решения, разобрать логику и постепенно улучшать свои знания алгоритмов. При постоянной практике и наличии аналитического мышления очень скоро вы начнете делать первые успехи в Data Science.
Что почитать
Хотя профильная литература может помочь в вашем обучении, не забывайте, что технологии развиваются очень быстро, а информация в книгах устаревает. Для успеха в Data Science важна практика, понимание предметной области, задач и инструментов, которыми владеете.
И все же советую почитать:
 Підписуйтеся на Telegram-канал редакції DOU, щоб не пропустити найважливіші статті.
Підписуйтеся на Telegram-канал редакції DOU, щоб не пропустити найважливіші статті.
Распространенные мифы, которых следует опасаться в Data Science и машинном обучении
Что такое машинное обучение: Data Science или искусственный интеллект? Это один из самых распространенных вопросов, который мне задают. Этот вопрос ставит в тупик и начинающих пользователей, и специалистов по подбору персонала, и даже руководителей.
Начинающих пользователей волнует, как стать специалистом по обработке и анализу данных; руководители задаются вопросом, насколько важное влияние оказывает Data Science на бизнес. Люди, работающие в этой сфере, не могут определиться, как себя называть: Data Scientist, Data Engineer или Data Analyst.
В этом посте я попытаюсь прояснить некоторые мифы и дать общее понятие о том, что такое Data Science, и как ее интерпретируют в деловом мире.
Миф 1: Data Scientist/Engineer/Analyst – это одно и то же.
Это искаженный миф, с которым я сталкивался много раз в своей карьере и который вредит как сотруднику, так и компании. Это все равно, что QA-инженера (специалиста по функциональному тестированию программного обеспечения на этапе разработки) называть инженером-программистом.
В широком смысле Data Scientist – это тот, кто имеет опыт и знания, как минимум, в двух из трех областей: статистики, программирования и машинного обучения. Такой сотрудник хочет работать над сложной бизнес-задачей, где он может использовать свои знания для поиска решений. Он стремится потратить бóльшую часть своей работы для создания предиктивных моделей и проведения статистических экспериментов, чтобы получить бизнес-решение. Это смесь исследовательской работы и программирования, а характер работы и нагрузка различаются в зависимости от размера компании/команды.
Data Engineering – это работа, в которой человек сосредотачивается на создании инфраструктуры для запуска приложений, выполняющих такие задания, как: предиктивное моделирование, обновление панелей потоковой передачи данных, выполнение ежедневных заданий для создания отчетов и поддержание непрерывного потока данных. Хороший инженер данных должен знать SQL (язык структурированных запросов) и Spark (программную платформу распределенной обработки данных).
Data Analyst – это человек, который больше склонен к интерпретации и анализу бизнес-результатов, а не к процессу их создания. Такой человек предпочитает использовать инструменты для получения этих результатов и будет тратить бóльшую часть своего времени на интерпретацию и извлечение из них ценности для бизнеса. Аналитики данных были в этой отрасли задолго до того, как туда пришли исследователи данных, и основным инструментом выбора тогда был Excel. На самом деле, даже сегодня для небольшого объема данных Excel является наиболее эффективным инструментом. В настоящее время также используются такие инструменты, как PowerBI, Azure, которые предоставляют возможность выполнять аналитику большого объема данных. Основное внимание, однако, уделяется точному сообщению ежедневных результатов, а также результатов новой проверяемой гипотезы. Эти входные данные и формируют основание для важного принятия решений в бизнесе.
Миф 2: Глубокое обучение – это машинное обучение или искусственный интеллект
Благодаря маркетингу и шумихе вокруг него, о глубоком обучении сегодня знают многие. Как следствие, люди считают, что глубокое обучение может решить любую проблему в области Data Science или машинного обучения.
Глубокое обучение, несомненно, является одним из самых сложных понятий в современном машинном обучении, которые следует уяснить. Глубокое обучение получило свое название из-за того, что «нейронная сеть», подразумеваемая в его структуре, имеет несколько уровней и поэтому называется «глубокой» сетью. То, что предлагается через tensorflow, pytorch или keras, – просто основа для применения этой концепции.
Фреймворк достаточно сложен для изучения. Он эффективен, но не эквивалентен опыту, полученному в машинном обучении. Машинное обучение – это огромное поле, в котором используются концепции и алгоритмы из целого ряда областей: статистики, теории информации, оптимизации, поиска информации, нейронных сетей и т.д., и имеет множество алгоритмов, каждый из которых может быть полезен в конкретных случаях его использования.
Глубокое обучение, например, было очень эффективно в машинном зрении и распознавании речи, но его использование в анализе тональности высказываний или простой задаче прогнозирования, которая может быть решена с помощью линейной регрессии, является абсолютно лишним.
Разумно потратить время на исследовательский анализ и понимание масштабов проблемы до того, как использовать алгоритм, для решения конкретной проблемы.
Миф 3: Data Science нельзя изучить за 3 месяца
Как бы мне ни хотелось, чтобы это было неправдой, но это не так. Чтобы стать Data Scientist, нужно знать гораздо больше импортирования библиотеки через «scikit-learn» и «tensorflow».
Это одна из тех областей, где результаты не детерминированы, то есть одна и та же последовательность шагов не всегда ведет к одному и тому же результату. Все зависит от качества и количества предоставленных данных, а перед вызовом функции «train» следует совершить много действий.
Конечно, вы можете научиться импортировать библиотеки и записывать последовательность шагов для создания модели, но эта модель не всегда будет эффективной. Однако нужно понимать принцип работы и зависимости применяемого алгоритма. Крайне важно это знать, иначе настройка моделей или объяснение результатов руководству будет сопряжено с рядом проблем.
Вот так я всегда объясняю, когда меня спрашивают, как научиться кодированию за одну ночь.
Это небольшая попытка подчеркнуть и прояснить распространенные мифы в области машинного обучения и Data Science. Надеюсь, поможет.
Разбираемся в чем разница между Machine Learning, Statistical Inference, AI, Data Science и т.п.
Неплохая статья на тему сабжа вот здесь. В общем, многие скептичны настроены к разным новым buzzwords и правильно делают. Я там тоже не со всем согласен и объясню внизу на примере. Все эти ML, AI (Artificial Intelengence), Big Data вот это вот всё. Ну и конечно отпускают разного рода шуточки. Ну типа вот внизу под катом.

Если попытаться сформулировать разницу максимально коротко, то она будет такая:
Machine Learning (ML) vs Statistics (Statistical Inference).
Цитата из выше указанной статьи:
«The major difference between machine learning and statistics is their purpose. Machine learning models are designed to make the most accurate predictions possible. Statistical models are designed for inference about the relationships between variables.«

Могут быть зоны, где ML и Statistical Inference сливаются. К примеру, вы на примере конкретного исследования в отдельно взятом регионе России изучили влияние неких факторов на bird species abundance. Выработали какую-то там GLM. Она валидируется ОК. Далее опубликовали. К примеру, вероятность гнездования сапсанов в уезде N зависит от
сезона (вид мигрирующий) + плотности голубей (еда) + плотности обрывов на берегах водоемов (удобные для гнездования места) + плотности ЛЭП (последние снижают численность из-за риска для жизни). Далее к вам приходят bioconsulting company и вы вместе делаете следующую работу, где вы оцениваете, на основе первой работы (вот вам и training sample), численность вида в бОльшем регионе (test sample) и кросс-валидируете это реальными подсчетами на местах. Т.е. в данной линии вы по сути начали как statistical inference study, а закончили в концепции типичного ML.
Шутка в тему для отвлечения:




