Сервисная сеть, «Плоскость данных» и «Плоскости управления» (Service mesh data plane vs. control plane)
Привет, Хабр! Представляю вашему вниманию перевод статьи «Service mesh data plane vs control plane» автора Matt Klein.

В этот раз «захотелось и перевелось» описание обоих компонентов service mesh, data plane и control plane. Это описание мне показалось самым понятным и интересным, а главное подводящим к пониманию «А нужно ли оно вообще?».
Поскольку идея «Сервисной сети (Service mesh)» становится все более популярной в течение последних двух лет (Оригинальная статья от 10 октября 2017), а число участников в пространстве возросло, я увидел соразмерный рост путаницы среди всего технического сообщества в отношении того, как сравнивать и противопоставлять разные решения.
Ситуацию лучше всего описать следующими сериями твитов, которые я написал в июле:
Путаница с сервисной сетью (service mesh) № 1: Linkerd
= Envoy. Ни один из них не равен Istio. Istio — это нечто совсем другое. 1 /
Первые просто плоскости данных (data planes). Сами по себе они ничего не делают. Они должны быть настроены на что-то большее. 2 /
Istio является примером плоскости управления (control plane), которая связывает части вместе вместе. Это другой слой. /конец
В предыдущих твитах упоминается несколько разных проектов (Linkerd, NGINX, HAProxy, Envoy и Istio), но, что более важно, вводятся общие понятия плоскости данных (data plane), сервисной сети (service mesh) и плоскости управления (control plane). В этом посте я сделаю шаг назад и расскажу, что я имею в виду под терминами «плоскость данных (data plane)» и «плоскость управления (control plane)» на очень высоком уровне, а затем расскажу, как термины относятся к проектам, упомянутым в твитах.
Что такое сервисная сеть (What is a service mesh, really)?
Рисунок 1: Обзор сервисной сети (Service mesh overview)
Рисунок 1 иллюстрирует концепцию сервисной сети (service mesh) на самом базовом уровне. Есть четыре сервисных кластера (A-D). Каждый экземпляр сервиса связан с локальным прокси сервером. Весь сетевой трафик (HTTP, REST, gRPC, Redis и т. Д.) от отдельного экземпляра приложения передается через локальный прокси-сервер в соответствующие внешние сервисные кластеры. Таким образом, экземпляр приложения не знает о сети в целом и знает только о своем локальном прокси. Фактически, сеть распределенной системы была удалена от сервиса.
Плоскость данных (Data plane)
В сервисной сети (service mesh) прокси-сервер, расположенный локально для приложения, выполняет следующие задачи:
Плоскость управления (The control plane)
Сетевая абстракция, которую обеспечивает локальный прокси в плоскости данных (data plane), является волшебной (?). Тем не менее, как прокси-сервер на самом деле узнает о маршруте «/foo» к сервису B? Как данные обнаружения сервисов (service discovery), которые заполняются прокси-запросами, могут быть использованы? Как настроены параметры балансировки нагрузки, таймаута (timeout), обрыва цепи (circuit breaking) и т.д.? Как осуществляется развертывание приложения с использованием синего/зеленого (blue/green) метода или метода постепенного перевода трафика? Кто настраивает параметры общесистемной аутентификации и авторизации?
Все вышеперечисленные пункты находятся в ведении плоскости управления (control plane) сервисной сети (service mesh). Плоскость управления (control plane) принимает набор изолированных прокси-серверов без состояния и превращает их в распределенную систему.
Я думаю, что причина, по которой многие технологи находят запутанными разделенные понятия плоскости данных (data plane) и плоскости управления (control plane), заключается в том, что для большинства людей плоскость данных знакома, в то время как плоскость управления чужеродна/непонятна. Мы уже давно работаем с физическими сетевыми маршрутизаторами и коммутаторами. Мы понимаем, что пакеты/запросы должны идти из пункта А в пункт Б, и что мы можем использовать для этого аппаратное и программное обеспечение. Новое поколение программных прокси — это просто модные версии инструментов, которые мы использовали в течение долгого времени.
Рисунок 2: Человеческая плоскость управления (Human control plane)
На рисунке 2 показано то, что я называю «Человеческой плоскостью управления (Human control plane)». В этом типе развертывания, которое все еще встречается очень часто, человек-оператор, вероятно сварливый, создает статические конфигурации — потенциально, с помощью скриптов — и развертывает их с помощью какого-то специального процесса на всех прокси-серверах. Затем прокси начинают использовать эту конфигурацию и приступают к обработке плоскости данных (data plane) с использованием обновленных настроек.
Рисунок 3: Расширенная плоскость управления сервисной сетью (Advanced service mesh control plane)
На рисунке 3 показана «расширенная» плоскость управления (control plane) сервисной сети (service mesh). Она состоит из следующих частей:
Плоскость данных и плоскость управления. Сводка (Data plane vs. control plane summary)
Текущее состояние проекта (Current project landscape)
Разобравшись с объяснением выше, давайте посмотрим на текущее состояние проекта «сервисной сети (service mesh)».
В начале 2016 года Linkerd был одним из первых прокси-серверов плоскости данных (data plane) для сервисной сети (service mesh) и проделал фантастическую работу по повышению осведомленности и увеличению внимания к модели проектирования «сервисная сеть» (service mesh). Примерно через 6 месяцев после этого Envoy присоединился к Linkerd (хотя работал в Lyft с конца 2015 года). Линкерд и Envoy — это два проекта, которые чаще всего упоминаются при обсуждении сервисных сетей (service mesh).
Istio было объявлено в мае 2017 года. Цели проекта Istio очень похожи на расширенную плоскость управления (control plane), показанную на рисунке 3. Envoy для Istio является прокси-сервером «по умолчанию». Таким образом, Istio является плоскостью управления (control plane), а Envoy — плоскостью данных (data plane). За короткое время Istio вызвало много волнений, и другие плоскости данных (data plane) начали интеграцию в качестве замены Envoy (и Linkerd, и NGINX продемонстрировали интеграцию с Istio). Тот факт, что в одной плоскости управления (control plane) можно использовать разные плоскости данных (data plane), означает, что плоскость управления (control plane) и плоскость данных (data plane) не обязательно тесно связаны. Такой API как универсальный API плоскости данных (data plane) Envoy может образовывать мост между двумя частями системы.
Nelson и SmartStack помогают дополнительно проиллюстрировать разделение плоскости управления (control plane) и плоскости данных (data plane). Nelson использует Envoy в качестве своего прокси и строит надежную плоскость управления (control plane) сервисной сетью (service mesh) на базе стека HashiCorp, т.е. Nomad и т.д. SmartStack стал, пожалуй, первым из новой волны сервисных сетей (service mesh). SmartStack формирует плоскость управления (control plane) вокруг HAProxy или NGINX, демонстрируя возможность развязки плоскости управления (control plane) сервисной сетью (service mesh) и плоскости данных (data plane).
Микросервисная архитектура с сервисной сетью (service mesh) привлекает к себе все больше внимания (правильно!), и все больше проектов и вендоров начинают работать в этом направлении. В течение следующих нескольких лет мы увидим много инноваций как в плоскостях данных (data plane), так и в плоскостях управления (control plane), а также дальнейшее смешивание различных компонентов. В конечным счете микросервисная архитектура должна стать более прозрачной и волшебной (?) для оператора.
Надеюсь, все менее и менее раздраженного.
Data Plane Development Kit (DPDK): приступая к работе
Для быстрой обработки пакетов требуется обнаруживать битовые шаблоны и быстро (со скоростью работы канала) принимать решения о нужных действиях на основе наличных битовых шаблонов. Эти битовые шаблоны могут принадлежать одному из нескольких заголовков, присутствующих в пакете, которые, в свою очередь, могут находиться на одном из нескольких уровней, например Ethernet, VLAN, IP, MPLS или TCP/UDP. Действия, определяемые по битовым шаблонам, могут различаться — от простого перенаправления пакетов в другой порт до сложных операций перезаписи, для которых требуется сопоставление заголовка пакета из одного набора протоколов с другими. К этому следует добавить функции управления трафика и политик трафика, брандмауэры, виртуальные частные сети и т. п., вследствие чего сложность операций, которые необходимо выполнять с каждым пакетом, многократно возрастает.
Чтобы добиться работы на ожидаемом уровне производительности при скорости канала 10 Гбит/с и размере пакета в 84 байта, процессор должен обрабатывать 14,88 миллиона пакетов в секунду. Оборудование общего назначения было недостаточно мощным для обработки пакетов с такой скоростью. Поэтому в большинстве рабочих сетевых систем обработкой пакетов в каналах данных занимаются контроллеры ASIC и сетевые процессоры NPU. К очевидным недостаткам такого подхода относятся: недостаточная гибкость, высокая стоимость, длительные циклы разработки, зависимость от определенного поставщика. Тем не менее, благодаря доступности более быстрых и дешевых ЦП и программных ускорителей, таких как Data Plane Development Kit (DPDK), можно переложить эту нагрузку на оборудование общего назначения.
Что такое Data Plane Development Kit?
DPDK — это набор библиотек и драйверов для быстрой обработки пакетов. Можно превратить процессор общего назначения в собственный сервер пересылки пакетов, не приобретая дорогостоящие коммутаторы и маршрутизаторы.
DPDK обычно работает под управлением Linux*, хотя существует версия некоторых компонентов DPDK для FreeBSD*. DPDK — это проект с открытым исходным кодом, распространяющийся по лицензии BSD. Самые поздние исправления и дополнения, предоставленные сообществом, доступны в основной ветви.
Использование Data Plane Development Kit
Чтобы приступить к работе с DPDK, выполните следующие действия:
1. Если у вас нет Linux, загрузите virtual box и установите машину Linux.
2. Загрузите последнюю версию DPDK с помощью одной из команд в зависимости от используемого ядра Linux.
или
или
3. Распакуйте ZIP-файл DPDK.
4. Изучите исходный код.
Чтобы ознакомиться с содержанием каталогов, посмотрите видео Глава 1: структура каталогов DPDK, сценарии и настройка DPDK в курсе Network Builder University Введение в DPDK.
5. Проверьте конфигурацию ЦП.
Образец вывода 
6. Проверьте конфигурацию сетевых адаптеров.
7. Настройте DPDK:
setup.sh — полезная программа, помогающая скомпилировать DPDK и настроить систему. Для запуска этой программы нужны права root. В каталоге tools введите:
В результате вы получите примерно следующее:
Нужно выбрать параметр и настроить.
1. На шаге 1 требуется выбрать сборку среды DPDK. Можно выбрать x86_64-native-linuxapp-gcc; это вариант 10.
2. На шаге 2 нужно настроить среду приложения Linux. Параметр 13 — загрузка последней версии модуля IGB UIO и компиляция последней версии драйвера IGB UIO. IGB UIO — это модуль ядра DPDK, работающий с перечислением PCI и обрабатывающий прерывания состояния ссылок в пользовательском режиме (вместо ядра). Также требуется поддержка выделения сверхкрупных страниц, например страниц 2 МБ для NUMA, параметр 17. Параметр 18 — отображение текущих параметров Ethernet, как на шаге 6 выше. С помощью параметра 19 удалите привязку нужного сетевого адаптера от драйвера ядра Linux и привяжите его к установленному модулю IGB UIO с помощью параметра 13.
Внимание! Не привязывайте к DPDK сетевой адаптер, используемый для внешних подключений, поскольку в этом случае будет утрачено подключение к устройству.
Сведения об установке см. в видеоролике Глава 2: настройка DPDK в составе курса Network Builder University Введение в DPDK.
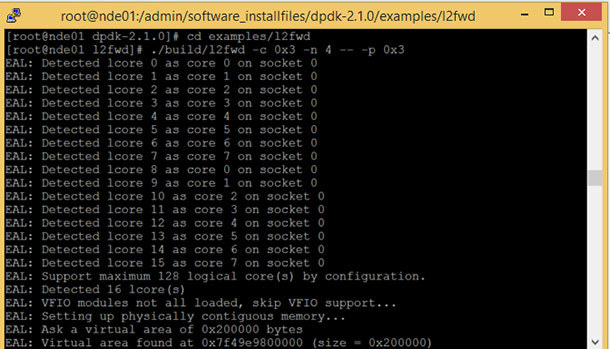
8. Скомпилируйте образец приложения l2fwd. Это приложение перенаправления уровня 2, оно перенаправляет пакеты на основе MAC-адресов, а не IP-адресов.
9. Запустите образец приложения.
-c (шестнадцатеричная битовая маска ядер, нужно запустить одно), например –c Ox3 означает запуск на обоих ядрах, поскольку двоичное 11 = 0x3
-n (количество каналов памяти), например –n 4, означает запуск на всех четырех каналах, доступных на процессоре Intel Xeon
-p (маска порта)
-p 0x3 означает запуск на обоих портах, привязанных к dpdk, поскольку двоичное 11 = 0x3
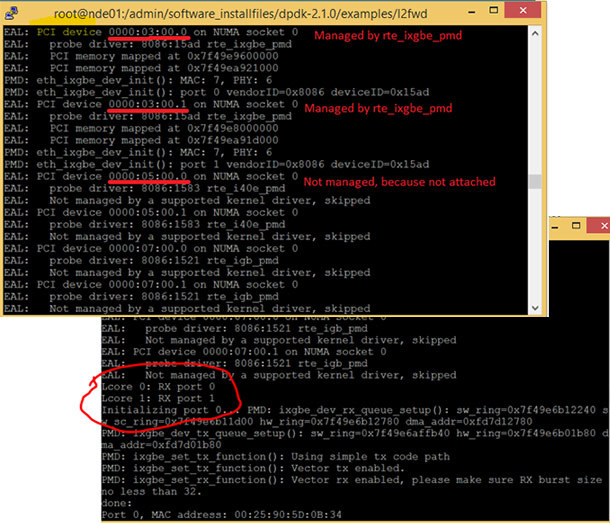
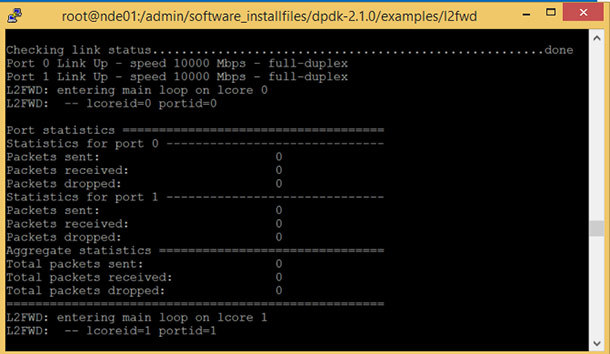
Подробные сведения о вариантах выполнения см. в разделе Глава 3: компиляция и запуск образца приложения в курсе Network Builder University Введение в DPDK.
В образце приложения показана базовая функциональность перенаправления уровня 2. Если нужно измерить производительность DPDK, ознакомьтесь с курсом Intel Network Builder University Использование DPPD PROX, в котором Люк Провост, технический руководитель отдела Network Platforms Group корпорации Intel, измеряет производительность виртуальной сети с помощью DPPD (Data Plane Performance Demonstrator) Prox, чтобы помочь разработчикам программного обеспечения понять и использовать эти инструменты.
Заключение
DPDK — программный ускоритель, работающий в пользовательском пространстве в обход ядра Linux и предоставляющий доступ к сетевым адаптерам, ЦП и памяти для приложений, обрабатывающих пакеты. В этой статье приводится пошаговая инструкция по загрузке DPDK 2.1.0 на платформе Linux с компиляцией, настройкой и запуском образца приложения.
Есть вопрос? Задайте его на форуме SDN/NFV.
IP routing and forwarding
Доброго времени! Перед тем как рассматривать тему MPLS, давайте уясним для себя как работает маршрутизатор.
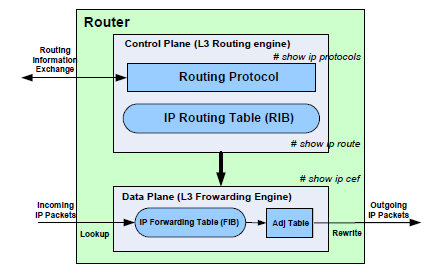
В маршрутизаторе различают два разных процесса, это routing (маршрутизация) и forwarding (коммутация пакетов).
В архитектуре маршрутизатора выделяют две плоскости:
Data Plane обрабатывается с помощью forwarding engine. В зависимости от платформы, этот forwarding engine может быть централизованным (объединенным с route process) или распределенным (разносятся по процессорам на интерфейсах).
Как происходит передача пакета?
Сначала происходить этап маршрутизации (routing), на этом этапе находится next hop, а так же интерфейс через который нужно передать пакет. Это все делается в Control Plane.
Определение пути коммутации и формирование Layer 2. Этим занимается Data Plane.
Теперь давайте рассмотрим режимы коммутации:
1. Process Switching (процессорная коммутация) — это режим, при котором каждый пакет обрабатывается центральным процессором, тем самым очень сильно нагружая его.
2. Fast Switching — идея этого режима заключается в использовании cache таблиц. Первый пакет потока идет через route process, затем создается кеш и все последующие пакеты этого потока идут путем подставления этого кеша в пакет (вместо того чтоб делать Layer 2 rewrite для каждого пакета потока).
Основной проблемой здесь является то, что каждый новый поток в начале будет «тормозиться», так как первый пакет у нас по прежнему идет через Process Switching.
К слову сказать, если в сети используется Policy Base Routing, то все пакеты идут в режиме Process Switching и тем самым сильно нагружают маршрутизатор. Для того что бы этого избежать, необходимо в route-map для этого PBR прописать: ip route-cache policy.
3. Cisco Express Forwarding — этот режим создан для того чтобы избавиться от недостатков с первым пакетом, как у Fast Switching, засчет того, что роутер сразу создает кеш для каждого маршрута, еще до начала того когда начался поток. И при приходе первого пакета маршрутизатор «достает» сразу заготовку и подставляет ее, минуя Route Process.
В CEF есть две таблицы:
— таблица соседей (adj-table) в ней содержатся готовые заголовки второго уровня.
— FIB (Forwarding Information Base) — таблица в которой указывается то, как происходит коммутация пакета. Эту таблицу можно посмотреть show ip cef.
CEF по умолчанию включен (ip cef).
Если у нас платформа выше 7500, там используется распределенная архитектура, для того чтобы скопировать этот CEF на каждый интерфейс (либо line card), необходимо дать команду ip cef distrebuted.
Это существенно ускоряет процесс коммутации.
Стоит для себя хорошо уяснить, то что, пакеты коммутируются на основании CEF. Значит нам нужно понять, из чего может наполняться этот самый CEF:
— PBR (Policy Base Routing)
Первые два нам знакомы, последнее мы рассмотрим еще, но позже.
Это знание нам очень хорошо поможет, когда мы будем делать траблшутинг.
Смотрим show ip route, определяем что трафик должен идти через один роутер, смотрим traceroute видим совсем другую картину.
Здесь нам и нужно смотреть то, как коммутируется пакет, сделать это можно так: sh ip cef exact-route
Так мы сможем четко посмотреть как пакет будет скоммутирован.
Как устроены сервисы управляемых баз данных в Яндекс.Облаке
Когда ты доверяешь кому-то самое дорогое, что у тебя есть, – данные своего приложения или сервиса – хочется представлять, как этот кто-то будет обращаться с твоей самой большой ценностью.
Меня зовут Владимир Бородин, я руководитель платформы данных Яндекс.Облака. Сегодня я хочу рассказать вам, как всё устроено и работает внутри сервисов Yandex Managed Databases, почему всё сделано именно так и в чём преимущества – с точки зрения пользователей – тех или иных наших решений. И конечно, вы обязательно узнаете, что мы планируем доработать в ближайшее время, чтобы сервис стал лучше и удобнее для всех, кому он нужен.
Управляемые базы данных (Yandex Managed Databases) – один из самых востребованных сервисов Яндекс.Облака. Точнее, это целая группа сервисов, которая по популярности сейчас уступает только виртуальным машинам Yandex Compute Cloud.
Yandex Managed Databases даёт возможность достаточно быстро получить работающую базу данных и берет на себя вот такие задачи:
Как устроены сервисы управляемых баз данных: вид сверху
Сервис состоит из двух основных частей: Control Plane и Data Plane. Control Plane – это, упрощенно говоря, API для управления базами данных, который позволяет создать, изменить или удалить БД. Data Plane – это уровень непосредственного хранения данных.
У пользователей сервиса есть, по сути, две точки входа:
Data Plane
Прежде чем рассматривать компоненты Control Plane, рассмотрим происходящее в Data Plane.
Внутри виртуальной машины
MDB запускает базы данных в таких же виртуальных машинах, которые предоставляются в Yandex Compute Cloud.
Прежде всего там развёрнут движок базы данных, допустим, PostgreSQL. Параллельно могут быть запущены различные вспомогательные программы. Для PostgreSQL это будет Odyssey – пулер соединений к базе данных.
Также внутри виртуальной машины запускается некий стандартный набор сервисов, свой для каждой СУБД:
Сетевая топология
Каждый хост Data Plane имеет два сетевых интерфейса:
Безопасность Data Plane
Раз уж речь зашла про безопасность, надо сказать, что сервис мы изначально проектировали из расчёта получения злоумышленником root на виртуальной̆ машине кластера.
В итоге мы вложили много сил, чтобы сделать следующее:
Control Plane
Internal API
Internal API – первая точка входа в Control Plane. Давайте посмотрим, как тут все работает.
Допустим, в Internal API поступает запрос на создание кластера базы данных.
В первую очередь Internal API обращается к сервису облака Access service, который отвечает за проверку аутентификации и авторизации пользователя. Если пользователь проходит проверку, Internal API проверяет на валидность сам запрос. Например, запрос на создание кластера без указания его имени или с уже занятым именем проверку не пройдет.
А еще Internal API умеет отправлять запросы в API других сервисов. Если вы хотите создать кластер в некой сети А, а конкретный хост в определённой подсети B, Internal API должен удостовериться, что у вас есть права и на сеть A, и на указанную подсеть B. Заодно будет проведена проверка, что подсеть B принадлежит сети A. Для этого и нужен доступ к API инфраструктуры.
Если запрос валиден, информация про создаваемый кластер будет сохранена в метабазу. Мы называем её MetaDB, она развёрнута на PostgreSQL. В MetaDB есть таблица с очередью операций. Internal API сохраняет информацию об операции и ставит задачу транзакционно. После этого пользователю возвращается информация об операции.
В общем-то для обработки большинства запросов Internal API достаточно походов в MetaDB и API смежных сервисов. Но есть ещё два компонента, в которые Internal API ходит для ответов на некоторые запросы – LogsDB, где лежат логи пользовательских кластеров, и MDB Health. Про каждый из них будет подробнее написано ниже.
Worker
Workers – это просто набор процессов, которые опрашивают очередь операций в MetaDB, хватают их и выполняют.
Что именно делает worker в случае создания кластера? Сначала обращается к API инфраструктуры для создания виртуальных машин из наших образов (в них уже установлены все необходимые пакеты и настроено большинство вещей, образы обновляются раз в сутки). Когда виртуальные машины созданы и в них взлетела сеть, worker обращается к Deploy-инфраструктуре (подробнее про неё расскажем дальше), чтобы она развернула на виртуальных машинах то, что нужно пользователю.
Помимо этого worker обращается и к другим сервисам Облака. Например, к Yandex Object Storage для создания бакета, в который будут сохраняться резервные копии кластера. К сервису Yandex Monitoring, который будет собирать и визуализировать метрики БД. Worker должен создать там метаинформацию про кластер. К DNS API, если пользователь хочет назначить публичные IP-адреса хостам кластера.
В целом worker работает очень просто. Он получает задачу из очереди метабазы и обращается к нужному сервису. После выполнения каждого шага worker сохраняет в метабазу информацию о прогрессе операции. Если происходит сбой, задача просто перезапускается и выполняется с того места, на котором остановилась. Но даже перезапустить её с самого начала – не проблема, потому что практически все типы задач для workers написаны идемпотентно. Так сделано потому, что worker может тот или иной шаг операции выполнить, но в MetaDB информацию про это не донести.
Deploy-инфраструктура
В самом низу используется SaltStack, довольно распространённая система управления конфигурациями с открытым исходным кодом, написанная на Python. Система очень расширяемая, за что мы её и любим.
Основными компонентами salt являются salt master, хранящий информацию о том, что и куда должно быть применено, и salt minion – агент, который ставится на каждый хост, взаимодействует с мастером и умеет непосредственно применять к хосту полученное с salt-мастера. Для целей этой статьи нам этого знания хватит, а подробнее можно почитать в документации SaltStack.
Один salt master не отказоустойчив и не масштабируется на тысячи миньонов, мастеров нужно несколько. Взаимодействовать с этим напрямую из worker’а неудобно, и мы написали свою обвязку над Salt, которую мы называем инфраструктурой Deploy.
Для worker единственной точкой входа является Deploy API, который реализует методы вида «Примени весь state целиком или отдельные его кусочки на такие-то миньоны» и «Расскажи статус вот такой-то выкатки». Deploy API сохраняет информацию про все выкатки и конкретные её шаги в DeployDB, где мы тоже используем PostgreSQL. Там же хранится информация обо всех миньонах и мастерах и о принадлежности первых ко вторым.
На salt-мастерах устанавливаются два дополнительных компонента:
Отдельно заметим, что pillar содержит в том числе и конфиденциальную информацию (пароли пользователей, TLS-сертификаты, GPG-ключи для шифрования бэкапов), а потому, во-первых, всё взаимодействие между всеми компонентами осуществляется с шифрованием (ни в одну нашу базу нельзя прийти без TLS, HTTPS повсюду, миньон с мастером тоже шифруют весь трафик). А во-вторых, все указанные секреты лежат в MetaDB зашифрованными, и мы применяем разделение секретов – на машинах Internal API лежит публичный ключ, которым шифруются все секреты перед сохранением в MetaDB, а на salt-мастерах лежит приватная его часть и только они могут получить секреты в открытом виде для передачи в качестве pillar на миньон (опять же по зашифрованному каналу).
MDB Health
При работе с базами данных полезно знать их состояние. Для этого у нас есть микросервис MDB Health. Он получает от внутреннего компонента виртуальной машины MDB metrics информацию о статусе хоста и сохраняет в собственной базе (в данном случае Redis). А когда в Internal API приходит запрос о состоянии конкретного кластера, Internal API использует данные из MetaDB и MDB Health.
Информация по всем хостам обрабатывается и отдаётся в понятном виде в API. Помимо состояния хостов и кластеров для некоторых СУБД MDB Health дополнительно возвращает, является ли конкретный хост мастером или репликой.
MDB DNS
Микросервис MDB DNS нужен для управления CNAME-записями. Если драйвер для подключения к базе данных не позволяет передавать несколько хостов в строке подключения, можно подключаться на специальный CNAME, который всегда указывает на текущий мастер в кластере. Если мастер переключается, CNAME меняется.
Как это происходит? Как мы уже говорили выше, внутри виртуальной машины есть MDB cron, который периодически передает в MDB DNS heartbeat примерно следующего содержания: «В данном кластере CNAME-запись должна указывать на меня». MDB DNS принимает такие сообщения со всех виртуальных машин и принимает решение о необходимости смены CNAME-записей. Если необходимость есть, он через DNS API меняет запись.
Почему мы сделали отдельный сервис для этого? Потому что у DNS API управление доступом разграничивается только на уровне зон. Потенциальный злоумышленник, получив доступ к отдельной виртуальной машине, мог бы менять CNAME-записи других пользователей. MDB DNS исключает такой сценарий, потому что проверяет авторизацию.
Доставка и отображение логов базы данных
Когда база данных на виртуальной машине делает запись в лог, специальный компонент push client читает эту запись и отправляет только что появившуюся строку в Logbroker (про него на Хабре уже писали). Взаимодействие push client с LogBroker построено с семантикой exactly-onсe: обязательно отправим и обязательно строго один раз.
Отдельный пул машин – LogConsumers – забирает логи из очереди LogBroker и сохраняет в базе данных LogsDB. Для базы данных логов используется СУБД ClickHouse.
Когда в Internal API приходит запрос на вывод логов за определенный интервал времени для конкретного кластера, Internal API проверяет авторизацию и отправляет запрос в LogsDB. Таким образом, контур доставки логов полностью независим от контура отображения логов.
Биллинг
Схема биллинга построена похожим образом. Внутри виртуальной машины есть компонент, который с определенной периодичностью проверяет, что с базой данных всё в порядке. Если всё хорошо, можно проводить биллинг за этот интервал времени с момента последнего запуска. В этом случае делается запись в billing log, а дальше push client отправляет запись в LogBroker. Данные из Logbroker передаются в систему биллинга и там проводятся расчёты. Это схема биллинга для запущенных кластеров.
Если же кластер выключен, перестаёт тарифицироваться использование вычислительных ресурсов, однако взимается плата за дисковое пространство. В этом случае биллить из виртуальной машины невозможно и задействуется второй контур – контур offline-биллинга. Существует отдельный пул машин, выгребающих список выключенных кластеров из MetaDB и пишущих лог в том же формате в Logbroker.
Offline-биллинг можно было бы использовать для биллинга и включенных кластеров тоже, но тогда мы будем биллить хосты, даже если они запущены, но не работают. Например, когда вы добавляете хост в кластер, он разворачивается из бэкапа и догоняется репликацией. Неправильно биллить пользователя за это, потому что хост для него в этот период времени неработоспособен.
Создание резервных копий
Схема создания резервных копий может несколько отличаться для разных СУБД, но общий принцип всегда одинаков.
Для каждого движка базы данных используется свой собственный инструмент создания бэкапов. Для PostgreSQL и MySQL это WAL-G. Он создаёт резервные копии, сжимает их, шифрует и складывает в Yandex Object Storage. При этом каждый кластер размещается в отдельном бакете (во-первых, для изоляции, а во-вторых, чтобы было проще биллить место под бэкапы) и шифруется своим собственным ключом шифрования.
Вот так устроены Control Plane и Data Plane. Из всего это и складывается сервис управляемых баз данных Яндекс.Облака.
Почему всё устроено именно таким образом
Безусловно, на глобальном уровне что-то можно было реализовать по более простым схемам. Но у нас были свои причины, чтобы не идти по пути наименьшего сопротивления.
Прежде всего, мы хотели иметь общий Control Plane для всех типов СУБД. Неважно, какую вы выбрали, в конце концов ваш запрос приходит в один и тот же Internal API и все компоненты под ним тоже общие для всех СУБД. Это несколько усложняет нам жизнь с точки зрения технологий. С другой стороны, так намного проще вводить новые функции и возможности, затрагивающие все СУБД. Это делается один раз, а не шесть.
Второй важный для нас момент – мы хотели обеспечить независимость Data Plane от Control Plane настолько, насколько это возможно. И сегодня, даже если Control Plane будет полностью недоступен, все базы данных продолжат работать. Сервис будет обеспечивать их надёжность и доступность.
В-третьих, разработка практически любого сервиса – всегда компромисс. В общем смысле, если говорить грубо, где-то важнее скорость выпуска релизов, а где-то дополнительная надёжность. При этом сейчас никто не может позволить себе делать один или два релиза в год, это очевидно. Если посмотреть на Control Plane, здесь мы делаем упор на скорость разработки, на быстрый ввод новых возможностей, выкатывая обновления несколько раз в неделю. А Data Plane отвечает за сохранность ваших баз данных, за отказоустойчивость, поэтому здесь совсем другой цикл выпуска релизов, измеряемый уже неделями. И вот эту гибкость в плане разработки тоже обеспечивает нам их взаимная независимость.
Ещё один пример: обычно сервисы управляемых баз данных предоставляют пользователям только сетевые диски. Яндекс.Облако предлагает ещё и локальные диски. Причина проста: их скорость работы намного выше. С сетевыми дисками, например, проще масштабировать виртуальную машину вверх и вниз. Проще делать бэкапы в виде снапшотов (snapshots) сетевых хранилищ. Но многим пользователям нужна высокая скорость, поэтому мы делаем средства резервного копирования уровнем выше.
Планы на будущее
И пару слов о планах по улучшению сервиса на среднесрочную перспективу. Это планы, которые затрагивают весь Yandex Managed Databases в целом, а не отдельные СУБД.
В первую очередь мы хотим дать больше гибкости по настройке периодичности создания бэкапов. Бывают сценарии, когда необходимо, чтобы в течение дня резервные копии делались раз в несколько часов, в течение недели – раз в сутки, в течение месяца – раз в неделю, в течение года – раз в месяц. Для этого мы разрабатываем отдельный компонент между Internal API и Yandex Object Storage.
Другой важный момент, важный и для пользователей, и для нас, – скорость выполнения операций. Недавно мы провели серьёзные изменения в Deploy-инфраструктуре и сократили время выполнения почти всех операций до нескольких секунд. Не охваченными остались только операции создания кластера и добавления хоста в кластер. Время выполнения второй операции зависит от объёма данных. А вот первую мы и будем ускорять в ближайшее время, потому что пользователи часто хотят создавать и удалять кластеры в своих CI/CD пайплайнах.
В нашем списке важных дел числится и добавление функции автоматического увеличения размера диска. Сейчас это делается вручную, что не очень удобно и не очень хорошо.
Наконец, мы предлагаем пользователям огромное количество графиков, показывающих, что происходит с базой данных. Даём доступ к логам. При этом мы видим, что данных временами недостаточно. Нужны другие графики, другие срезы. Здесь мы тоже планируем улучшения.
Наш рассказ про сервис управляемых баз данных получился длинным и, вероятно, довольно утомительным. Лучше любых слов и описаний только реальная практика. Поэтому, если хотите, вы можете самостоятельно оценить возможности наших сервисов:



