Сведения о продукте AWS Data Pipeline
AWS Data Pipeline представляет собой управляемый сервис ETL (извлечения, трансформации и загрузки данных); он позволяет задавать принципы перемещения данных между различными сервисами AWS и (или) локальными ресурсами, а также настраивать преобразование данных. С помощью AWS Data Pipeline можно определять зависимые процессы для создания конвейера, компонентами которого являются узлы данных (узлы, где находятся данные), действия или бизнес‑логика (например, последовательно выполняемые задания EMR или SQL‑запросы) и расписание выполнения действий.
Например, если требуется переместить истории посещений, хранящиеся в Amazon S3, в Amazon Redshift, нужно определить конвейер с узлом S3DataNode, в котором хранятся файлы журналов; действие HiveActivity, которое будет преобразовывать файлы журналов в CSV‑файл, используя кластер Amazon EMR, и сохранять его обратно в S3; действие RedshiftCopyActivity, которое будет копировать данные из S3 в Redshift, и узел RedshiftDataNode, который будут подключаться к кластеру Redshift. В завершение можно выбрать расписание, по которому будут выполняться действия.
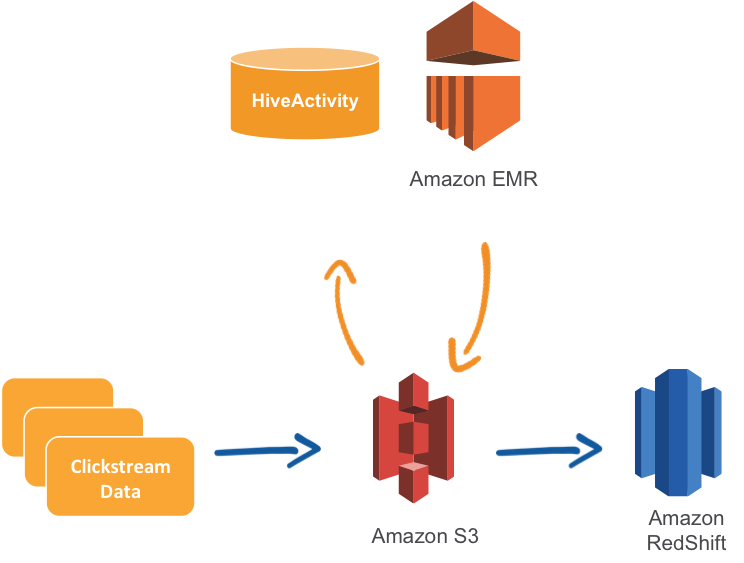
Используйте AWS Data Pipeline для перемещения истории посещений из Amazon S3 в Amazon Redshift.
Начните работу с AWS бесплатно
В рамках сервиса AWS Data Pipeline уровень бесплатного пользования AWS включает 3 предварительных условия и 5 операций с низкой частотой выполнения.
Можно также определить предварительные условия готовности данных, которые будут проверяться перед началом выполнения определенных действий. Для приведенного выше примера можно задать предварительное условие для S3DataNode, которое будет проверять, доступны ли файлы журналов, прежде чем начинать выполнение действия HiveActivity.
Сервис AWS Data Pipeline выполняет следующие операции:

Распространенные примеры использования
Выполнение ETL‑операции с перемещением данных в Amazon Redshift
Копирование таблиц RDS или DynamoDB в S3, преобразование структуры данных, запуск аналитических операций с использованием SQL‑запросов и загрузка данных в Redshift.
ETL‑операции с неструктурированными данными
Анализ неструктурированных данных, например истории посещений, с помощью Hive или Pig на EMR, объединение их со структурированными данными из RDS и загрузка в Redshift для удобного выполнения запросов.
Загрузка данных журналов AWS в Amazon Redshift
Загрузка файлов журналов, например истории выставления счетов AWS или журналов сервисов AWS CloudTrail, Amazon CloudFront и Amazon CloudWatch Logs, из Amazon S3 в Redshift.
Загрузка и извлечение данных
Копируйте данные из таблицы RDS или Redshift в S3 или в обратном направлении.
Перемещение в облако
Просто копируйте данные из локального хранилища данных, например базы данных MySQL, и перемещайте их в хранилище данных AWS, например S3, чтобы сделать данные доступными для различных сервисов AWS, таких как Amazon EMR, Amazon Redshift и Amazon RDS.
Резервное копирование и восстановление в Amazon DynamoDB
Регулярно создавайте резервную копию таблицы DynamoDB в S3 для целей аварийного восстановления.
Вопросы и ответы по AWS Data Pipeline
Общие вопросы
Начните работать с AWS бесплатно
Уровень бесплатного пользования AWS включает 750 часов использования узла кэша типа Micro в Amazon ElastiCache.
Вопрос. Что такое AWS Data Pipeline?
AWS Data Pipeline – это веб-сервис, который упрощает планирование регулярных операций по перемещению и обработке данных в облаке AWS. Сервис AWS Data Pipeline интегрируется с локальными и облачными системами хранилищ данных, позволяя разработчикам использовать данные в любое время, в любом месте и в нужном формате. AWS Data Pipeline позволяет быстро создать цепочку зависимостей из источников данных, целевых объектов, встроенных или настраиваемых операций, называемую конвейером. По определенному вами графику конвейер регулярно выполняет операции обработки данных, например распределенное копирование данных, преобразования SQL, запуск приложений MapReduce или настраиваемых скриптов, с использованием таких сервисов назначения, как Amazon S3, Amazon RDS или Amazon DynamoDB. Полностью управляемый и масштабируемый сервис Data Pipeline гарантирует надежность и высокую доступность конвейеров, контролируя расписание операций, повторные попытки и обработку отказов.
Вопрос. Какие задачи можно выполнять с помощью AWS Data Pipeline?
С помощью AWS Data Pipeline можно легко и быстро создавать конвейеры, выполняющие ежедневные операции с данными. Освободившись от разработки и выполнения рутинных задач по обслуживанию, вы сможете сконцентрироваться на анализе своих данных. От вас требуется только указать для конвейера данных источники, график и нужные операции обработки. AWS Data Pipeline обеспечивает выполнение и мониторинг операций по обработке данных в высоконадежной и отказоустойчивой инфраструктуре. Кроме того, для еще большего упрощения процесса разработки AWS Data Pipeline поддерживает встроенные действия для выполнения стандартных операций, таких как копирование данных между хранилищами Amazon S3 и Amazon RDS или выполнение запросов по данным журналов в Amazon S3.
Вопрос. Чем сервис AWS Data Pipeline отличается от сервиса Amazon Simple Workflow?
Хотя оба сервиса обеспечивают отслеживание выполнения, обработку необходимых повторов и исключений, а также выполнение произвольных действий, AWS Data Pipeline специально создан, чтобы упростить выполнение конкретных шагов – типовых для большинства рабочих процессов, управляемых данными. Примерами могут служить выполнение операций после того, как входные данные начинают соответствовать определенным критериям готовности, копирование данных между различными хранилищами данных и планирование цепочек последовательных преобразований. Такая узкая направленность позволяет быстро создавать в сервисе Data Pipeline определения рабочего процесса без создания кода и изучения программирования.
Вопрос. Что такое конвейер?
Конвейер – это ресурс сервиса AWS Data Pipeline, который содержит определение зависимой цепочки источников и сервисов назначения данных, а также встроенных или настраиваемых операций обработки данных, требуемых для выполнения бизнес-логики.
Вопрос. Что такое узел данных?
Узел данных – это представление ваших бизнес-данных. Например, узел данных может содержать ссылку на некоторый путь Amazon S3. AWS Data Pipeline поддерживает язык выражений, позволяющий легко ссылаться на регулярно генерируемые данные. Например, вы можете задать формат данных Amazon S3 в виде s3://example-bucket/my-logs/logdata-#
Вопрос. Что такое операция?
Операция – это действие, инициируемое сервисом AWS Data Pipeline от вашего имени и входящее в состав конвейера. Примерами операций являются задания EMR или Hive, копирование, запросы SQL или скрипты командной строки.
Вопрос. Что такое предварительное условие?
Предварительное условие – это проверка готовности, которая может быть связана с источником данных или операцией. Если для источника данных определена проверка предварительного условия, то она должна успешно завершиться, прежде чем будут запущены какие-либо операции, использующие этот источник данных. Если для операции определена проверка предварительного условия, то она должна успешно завершиться, прежде чем начнется выполнение операции. Предварительные условия будут полезны при выполнении операций с высокой стоимостью вычислений, которые должны быть выполнены только в случае удовлетворения определенных критериев.
Вопрос. Что такое график?
График определяет время выполнения операций конвейера и частоту, с которой сервисы ожидают поступления данных. Для всех графиков необходимо задать исходную дату и частоту, например «с 1 января 2013 года, ежедневно в 15:00». Для графиков можно также задать конечную дату, после которой сервис AWS Data Pipeline перестанет выполнять любые операции. Когда вы связываете график с операцией, эта операция выполняется в указанные графиком сроки. Когда вы связываете график с источником данных, AWS Data Pipeline ожидает обновления данных источников в соответствии с этим графиком. Например, если для источника данных Amazon S3 установлен ежечасный график, то сервис будет ожидать появления новых файлов в источнике каждый час.
Строим Data Pipeline на Python и Luigi
Введение
В эпоху data-intensive приложений рядовым разработчикам всё чаще приходится сталкиваться с задачами по обработке и анализу данных. Ещё десять лет назад данные большинства проектов могли уместиться на жестком диске одного компьютера в какой-нибудь реляционной базе данных типа MySQL. А задачи по извлечению и обработке хранящихся данных решались за счёт непростых (или простых) SQL запросов. С тех пор мир информационных технологий значительно поменялся. С приходом Internet of Things, мобильных телефонов и дешевого мобильного интернета, объем генерируемых данных вырос в десятки тысяч раз. Ежедневно в мире генерируются эксабайты данных. Анализировать такой поток информации вручную, а тем более извлекать полезные для бизнеса или науки данные, практически невозможно. Но технологии как и время не стоят на месте, появляются новые инструменты, наука двигает прогресс. Если вы хоть чуточку следите за новостями из мира высоких технологий, то фразы «биг дата», «машинное обучение», «глубокое обучение» вас не испугают. С приходом больших данных появились новые профессии и специализации такие как Data Scientist/Analyst (по-русски аналитик данных), Data Engineer. Задачи этих ребят тесно связаны с обработкой, анализом и хранением «нефти 21 века», т.е. информации. Но насколько эффективно они выполняются?
Аббревиатура ETL в последнее время часто мелькает в материалах, посвященных data-driven приложениям. Но не пугайтесь, это всего лишь набор из 3-х простых слов: Extract, Transform, Load. Ничего не напоминает? Тот, кто сталкивался с задачами по обработке данных не раз замечал паттерн в своих действиях, а именно:
сначала данные выгружаются (Extract) из какого-нибудь источника типа базы данных, внешнего сервиса (Facebook Ads, Google Analytics, Yandex Metrics) или, на худой конец, это могут быть логи вашего приложения (например, веб-сервера).
потом они преобразуются (Transform), скажем, необходимо сформировать сводную таблицу или провести сложный когортный анализ ваших пользователей.
и наконец загружаются (Load) для просмотра и дальнейшего анализа в базу данных или на какое-нибудь облако Amazon S3, не суть.
И как ни крути от этого не уйти. Чтобы данные проанализировать, их необходимо подготовить, иначе «мусор на входе — мусор на выходе». Процесс подготовки занимает львиную долю времени, отведенного на работу с данными. До 80% рабочего времени аналитик тратит на сбор и очистку. Поэтому от эффективности ETL-процесса зависит скорость и качество выполненной работы.
Перед тем как перейти к основной идеи этой статьи, я предлагаю кратко рассмотреть самый популярный на сегодняшний день метод построения ETL процесса в компании.
Внимание! Я запустил полноценный курс по разработке дата-пайплайнов на Luigi. Luigi сильно недооценён, и к нему стоит присмотреться поближе. В курсе я рассказываю зачем нужны пайплайны, как их сделать надёжными и отказоустойчивыми. Всё это заправляется практическими примерами! Не забыл я и про тему деплоя, где затрагивается Docker контейнеры, а также облачный деплой дата-пайпланой в AWS с использованием таких технологий как AWS Fargate, Cloud Map, Elastic Container Service и другое.
Серые будни работы с данными
Сложно спорить с утверждением, что Python твердо занял позицию lingua franca в задачах по анализу данных. О его взрывной популярности свидетельствует и недавний пост от ребят из Stack Overflow. Но что же предшествует магическому процессу извлечения ценной информации (непосредственному анализу) из гигабайт структурированных и неструктурированных данных? Сбор. Задачи по анализу данных славятся своими жесткими сроками ведь на их основе часто принимают ключевые бизнес-решения. Это сильно отражается на том как мы, разработчики, подходим к процессу написания скриптов. Нам не стыдно создавать скрипты-однодневки с хрупким кодом и горой «разбитых окон». Хорошо ещё, если в этой массе кода есть хоть какая-нибудь структура или модульность для дальнейшего переиспользования в других скриптах, но обычно и этого нет. Краткосрочный выигрыш в скорости оборачивается головными болями в долгосрочной перспективе. Код обрастает «техническим долгом», и им становится сложно управлять. Ниже пример ETL-скрипта с соблюдением принципа Single Responsibility в каждой функции:
Всё бы хорошо, но у такого подхода есть ряд проблем:
Все они решаемы, но нужно ли изобретать ещё один, когда он давно изобретен и на нём успешно «катаются» специалисты в индустрии?!
Luigi
Luigi это один из немногих инструментов в экосистеме Python для построения т.н. pipeline’ов или, по-простому, выполнения пакетных задач (batch jobs). Разработан был инженерами из Spotify. Мне он понравился за свою простоту и широкий спектр возможностей, а именно:
управление зависимостями между задачами
failover recovery, т.е. если в одной из задач произошла ошибка, не нужно перезапускать цепочку снова
центральный планировщик задач с веб-интерфейсом, статусом выполнения задач и трекингом ошибок
“батарейки” для работы с HDFS, S3, MySQL, PostgreSQL, Redis, MongoDB, Redshift и т.д.
удобное построение CLI (Command Line Interface), в нём очень удобно построена передача параметров из командной строки
Основными строительными блоками Luigi являются 3 объекта: Task, Target и Parameter. Последний используется для взаимодействия с командной строкой и поэтому опционален. Чтобы установить Luigi достаточно выполнить:
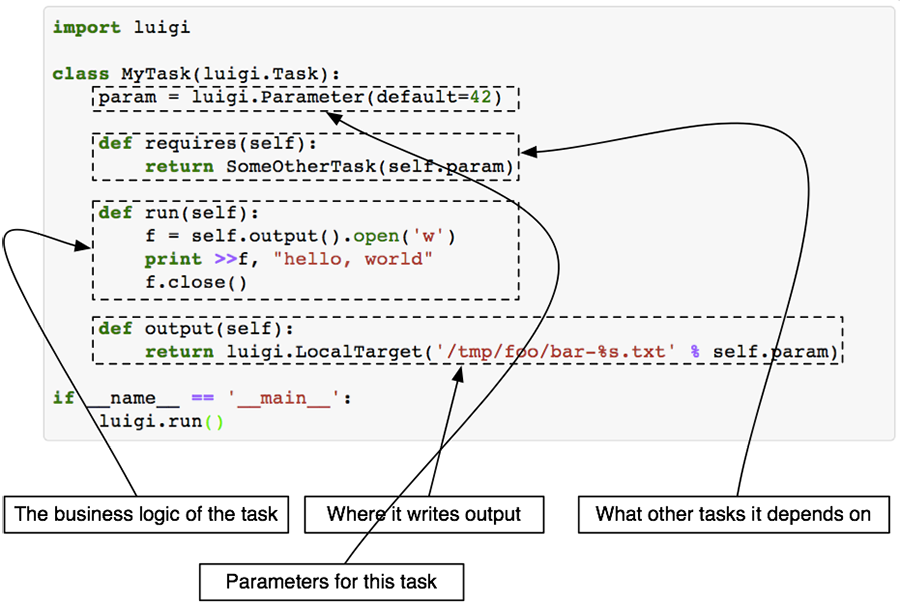
Класс Task это основной блок, где происходит выполнение конкретного таска. Чтобы определить свою собственную задачу, необходимо создать класс, унаследованный от Task, и реализовать несколько методов. Зачастую переопределять нужно только 3 метода: run(), output(), requires().
На сайте с документацией к Luigi есть хорошая иллюстрация что из себя представляет каждый метод и класс в целом:
Task.run
Здесь выполняется вся логика вашей будущей задачи, например, скачивание или парсинг данных с внешнего источника, запрос в базу данных для извлечения информации и т.д. Если задача объёмная, то лучше разбить её на функции и вызывать их внутри метода run(), это поможет избежать путанницы в будущем.
Task.requires
Помните я говорил об управлении зависимостями? В методе requires() необходимо их перечислить. Зависимостями выступают другие luigi.Task классы. Чуть позже я покажу реальный пример задачи с зависимостями.
Task.output
Этот метод должен возвращать 1 или более Target объектов. Target объектом может быть файл на диске, файл внутри HDFS, S3 или файл, лежащий на удалённом FTP сервере и т.д.. В Luigi уже встроено множество полезных Target классов, поэтому ситуация, когда вам понадобится создавать свой, маловероятна. Полный список доступных Target классов смотрите на сайте.
Task.input
Этот метод не нужно переопределять. Он выступает «оберткой» над Task.requires и возвращает Target объекты, полученные от выполнения задач, определенных в Task.requires. Таким образом строится граф зависимостей, когда одна задача зависит от результата выполнения другой. Продемонстрирую на примере кода:
Здесь таск B зависит от выполнения таска A, поэтому перед началом выполнения B выполнится A, результат которого вернётся при вызове метода B.input (объекта файла result.txt).
Target
Ранее я вкратце описал что из себя представляет объект Target и зачем он нужен. Здесь отмечу, что благодаря этому классу Luigi реализует механизм fault tolerance и свойство идемпотентности. Проще говоря, если ваш pipeline аварийно завершается где-то в середине выполнения задач, повторный запуск не приведёт к повторному запуску успешно завершившихся задач, выполнение начнется в месте аварийной остановки скрипта. Это достигается за счёт вызова метода exists() у Target класса.
Parameter
При создании ETL скриптов часто приходится писать код для работы с командной строкой, а именно уметь принимать и обрабатывать аргументы. Даже наличие в стандартной библиотеке Python модулей для работы с консолью не уменьшает количество boilerplate кода. Luigi решил эту проблему по-своему.
Чтобы принимать аргументы из командной строки достаточно присвоить переменной объект класса Parameter или его наследников на уровне класса.
Пример запуска такого скрипта:
Luigid
Задача демона Luigi заключается в следующем:
Следить за выполнением задач, чтобы исключить ситуацию одновременного исполнения одного и того же таска
Визуализация работы скрипта: построение графа зависимостей, просмотр статусов у текущих задач, мониторинг ошибок
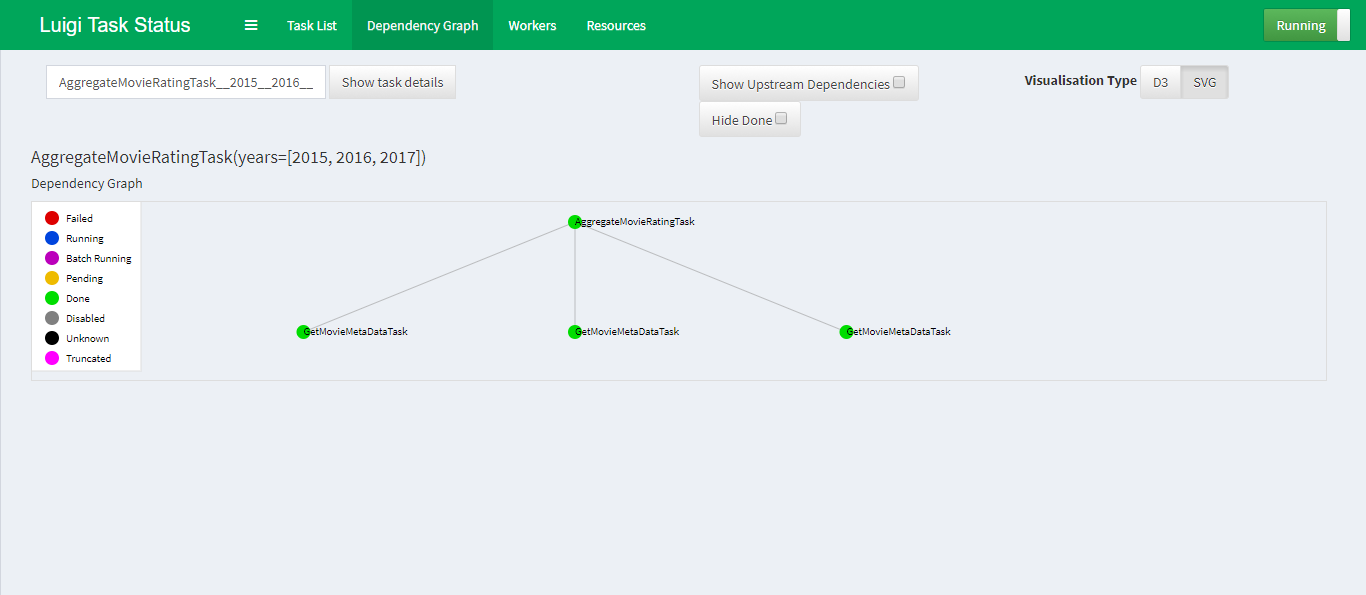
Ниже скриншот графа зависимостей внутри демона Luigi на примере простого скрипта о котором расскажу чуть ниже.
По умолчанию демон слушает 8082 порт и запускается командой:
Пример пайплайна
Человек лучше всего запоминает информацию на практических примерах, поэтому я придумал скрипт в задачу которого входит:
Вот как выглядит решение этой задачи в Luigi:
Скачать скрипт можно по ссылке. Для корректной работы необходимо помимо luigi также установить requests, pandas и beautifulsoup4:
Запускайте в терминале демон luigid, а сам скрипт вот таким образом:
Отправной точкой будет класс AggregateMovieRatingTask которому передается список интересующих нас лет. В методе requires() определяется зависимость от GetMovieMetaDataTask, поэтому до тех пор пока не будет получен результат от GetMovieMetaDataTask, код в методе run() у класса AggregateMovieRatingTask не будет исполнен.
При удачном раскладе AggregateMovieRatingTask.input вернёт список, содержащий объекты LocalTarget, полученные от выполнения GetMovieMetaDataTaskпо каждому году. Дальше необходимо пробежаться по списку, сформировать DataFrame и отсортировать его по убыванию.
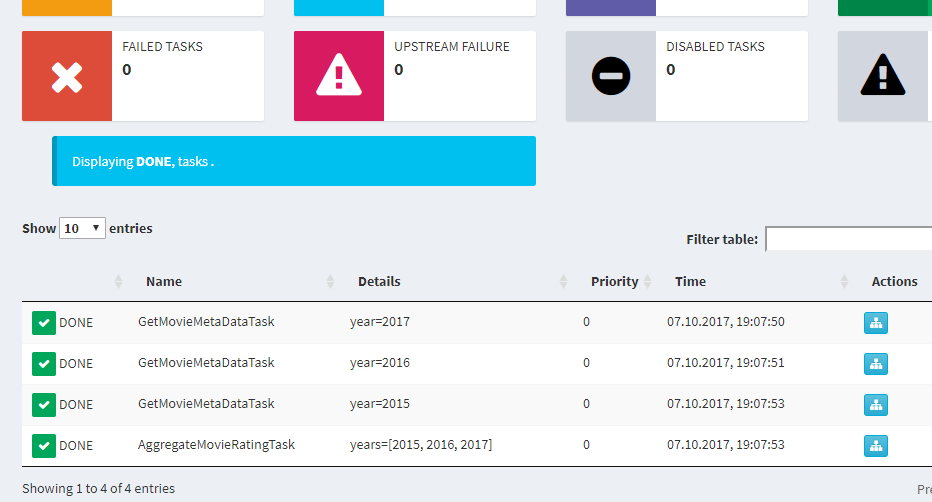
Полученных знаний достаточнот для построения сложных пайплайнов с зависимостями.
Ограничения Luigi
Как и у любого другого инструмента, у Luigi есть свои ограничения с которыми приходится мириться в зависимости от ситуаций.
Отсутствие механизма запуска задач по расписанию. Если такая потребность имеется, то можно использовать crontab.
Luigi не предназначен для real-time обработки, его стихия это batch processing.
Сложность масштабирования. Luigi не умеет распределять задачи между воркерами на разных узлах/нодах как это умеет делать Celery, используя единый брокер сообщений (например, Redis или RabbitMQ). Без серьёзного ручного вмешательства тут не обойтись.
Заключение
Моей главной задачей в статье было рассказать про основные возможности Luigi. Вероятно те из вас, кто до сих пор мучается с boilerplate кодом при написании ETL скриптов взглянут на свою работу иначе, и полученная информация сделает вашу работу эффективной и приятной. За более подробным описанием стоит сходить на сайт с документацией. Отмечу, что Luigi не единственный инструмент в своём роде, обратите внимание на продукт под названием Airflow, разработанный в стенах Airbnb и с недавних пор перешедший в «руки» Apache Foundation (на момент написания статьи проект находится в статусе «incubating»).
Использование Pipeline в работе с данными
В своей работе Data Scientist используют различные модели для улучшения качества метрик. Чтобы применить модель, предварительно необходимо затратить существенные ресурсы на обработку всего массива необработанных данных. Мы расскажем об инструменте, которым пользуемся для оптимизации этого процесса. Инструмент Pipeline позволяет объединить несколько операций обработки данных в единую модель библиотеки Python «Scikit-learn».
Рассмотрим его применение более подробно.
Класс Pipeline предусматривает методы fit, predict и score, имеющие свойства, аналогичные свойствам модели в библиотеке «Sckit-learn». В Машинном обучении чаще всего класс Pipeline используется для объединения операций предварительной обработки (например, масштабирования данных или one-hot-encoding) с моделью машинного обучения типа классификаторов. Его использование позволяет избежать ошибок и сокращает временные издержки.
Вот как это выглядит схематически.

Другими словами, применяется определённая последовательность действий к необработанным данным (в первую очередь осуществляется трансформирование данных, а уже после: масштабирование числовых переменных, one-hot-encoding и так далее). В принципе в T1(), T2() …Tn() может быть любой код по предобработке данных.
Основное преимущество Pipeline:
Рассмотрим абстрактный датасет, в котором содержатся численные и категориальные значения для последующей обработки (для того чтобы можно было применить различные модели).
Такой код, чаще всего можно увидеть на различных соревновательных платформах:
На данном примере видно, что код дублируется. Для исключения дублирования кода, можно написать функцию, которая будет проделывать вышеперечисленные операции. Но нужно помнить, что масштабировать данные нужно только на обучающей выборке, а применять масштабирование как на обучающей, так и на тестовой выборке, что будет способствовать наличию дополнительных условий.
Теперь рассмотрим инструмент Pipeline с дополнительным набором функций:
Таким образом код с использованием Pipeline будет выглядеть следующим образом:
Отметим, что Pipline можно вкладывать в другие pipeline, что позволяет осуществлять сложную обработку данных с помощью одной абстракции.
Вот так, применение инструментов Pipeline позволяет оптимизировать работу Data Scientist, что способствует повышению качества и скорости работы в целом.
Airbyte для управления потоками данных – репликация Яндекс.Метрика в S3

Современные Data Pipelines – это как вода в кране
Если она есть – всё замечательно, можно мыть руки, приготовить еду и постирать вещи. Как только вода отключается, либо идёт слабый напор – проблема становится весьма ощутима. Ту же аналогию сегодня можно провести относительно потоков интеграции данных.
Data Integration / Data Pipelines сегодня стали commodity – они просто должны быть и функционировать, обеспечивая базовые потребности, при этом основной фокус работы Аналитиков и Инженеров приходится на моделирование данных, трансформацию, обогащение, агрегирование, а также визуальную подачу выводов.
Второй важной особенностью является смена парадигмы от ETL к EL(T). Я попробую изложить ключевые идеи в паре тезисов.
Исторический подход ETL предполагал последовательность Extract – Transform – Load, что выявило ряд проблем:
Нет прозрачности – в Хранилище попадают уже трансформированные данные, без возможности восстановить историю и исходные данные
Отсутствие гибкости – трансформации должны быть известны и разработаны заранее, любые изменения и дополнительные требования могли стоить дорого
Зависимость Аналитиков от Инженеров (иногда очень скилованных) – сложные варианты интеграции с рядом источников, высокий порог сложности решений
Современный подход EL(T) предполагает независимые этапы Extract – Load и Transform:
Гибкость – из сырых исходных данных можно собрать что угодно, какие бы идеи у вас не возникали, даже если они часто меняются
Вычислительные ресурсы и хранение данных доступны как никогда – Облачные сервисы хранить все данные без необходимости экономить
Разделение этапов EL и T – вы больше не завязаны на один инструмент, но вправе использовать любые тулзы для трансформации данных, такие как dbt, Airflow.
EL(T) в архитектура аналитических приложений Wheely
Множество компаний сегодня предоставляют Data Pipelines / Integration как сервис. Перечислю те, с которыми мне доводилось сталкиваться: Fivetran, Hevo, Alooma, Stitch.
Их основные преимущества:
Надежность и поддержка от вендора
Полностью управляемый сервис – минимум забот на вашей стороне
Легкая конфигурация pipelines – все стремятся упростить настройку
Но есть и ряд недостатков:
Это закрытый код – вы ограничены возможностями которые поддерживает вендор
Могут найтись специфические коннекторы (или способы подключения), которые вендор не поддерживает
И конечно это стоимость – чек может быть очень большим
Схема работы сервиса Fivetran
Альтернативно, существуют класс современных и удобных решений для управления потоками интеграции данных с открытым исходным кодом: Airbyte, Meltano, Singer. И вот одно из таких решений сегодня я и предлагаю рассмотреть.
И да, честь и хвала разработчикам и контрибьюторам таких решений.
Airbyte – простота и гибкость в интеграции данных
Airbyte – это проект с открытым исходным кодом, который стремительно набирает популярность. Проект доступен на GitHub (3.800+ stars), а сообщество в Slack насчитывает 2.500+ человек. По сути это современный стандарт для выстраивания потоков интеграции данных из всевозможных приложений, баз данных и API в аналитические хранилища данных, озера данных. Ниже я коротко рассмотрю ключевые преимущества инструмента.
Обширный набор коннекторов, доступных для подключения в считанные минуты. В списке все самые популярные СУБД, а также огромное количество популярных сегодня приложений: Intercom, Zendesk, Stripe, Salesforce, Jira. Усилиями сообщества пользователей список коннекторов постоянно растет. Добавление новых коннекторов сведено к простому конфигурированию – оркестрацией и спосбоами репликации займется Airbyte.
Интерфейс Airbyte – инструмент для Data Integration
Понятная и масштабируемая архитектура. Хранилище метаданных, в качестве которого можно использовать внешнюю СУБД (Postgres), веб-интерфейс, набор рабочих лошадок (Workers), число которых можно гибко регулировать, а также полноценный scheduler с возможностью гибко регулировать частоту репликации данных.
Архитектурная схема компонент Airbyte
Различные варианты установки приложения: AWS, Azure, GCP, K8s, Docker. Подходящий вариант для компаний, которым необходимо разместить приложение на своих мощностях в связи с требованиями к безопасности и compliance. При размещении в облаке – данные хранятся в вашем облаке и стоимость ресурсов остается прозрачной.
Опции развертывания Airbyte
Различные стратегии синхронизации данных – Sync strategies:
Full Refresh Overwrite: полная выгрузка всего объема данных и перезапись на приемнике
Full Refresh Append: полная выгрузка всего объема данных и добавление на приемнике
Incremental Append: инкрементальное чтение записей и добавление на приемнике
Incremental Deduped History: инкрементальное чтение записей, добавление на приемнике, а также формирование дедуплицированной версии представления
Manual full refresh: в случае необходимости провести полную репликацию данных из источника
Нормализация данных и преобразование типов. Также Airbyte может быть полезен в переводе массивов и вложенных (nested) коллекций в плоские структуры.
Правила преобразования типов и нормализации данных Airbyte
И, пожалуй, одно из самых главных – вы платите только за используемые вычислительные мощности (в случае использования облака). Никакой платы за количество коннекторов и объем реплицируемых строк, как в сервисах типа Hevo, Fivetran.
Развертывание Airbyte в Yandex.Cloud
Предлагаю попробовать пощупать Airbyte своими руками, развернув приложение в Яндекс.Облаке. Для этого нам понадобится проделать ряд шагов:
Регистрация в Облаке
Создание виртуальной машины
Создание пары ключей и подключение по SSH
Установка Docker + Docker compose
Конфигурирование Yandex Object Storage (S3) – опционально
Развертывание Airbyte в Yandex.Cloud
В случае необходимости, Airbyte можно масштабировать (Scaling) следующими способами:
Увеличение количества Workers – scaling out
Использование более мощного типа VM (CPU, Memory, Disk) – scaling up
Подключим источник данных – Yandex.Metrika
В качестве источника интересных данных для нашего пайплайна я предложу использовать API сервиса Яндекс.Метрика. Это веб-счетчик который позволяет собирать огромное количество поведенческой информации с вашего сайта. У Я.Метрики есть демо-счётчик, который не требует аутентификации при обращении; им мы и воспользуемся.
Интерфейс позволяет выбрать интересующие метрики, разрезы и сегменты (фильтры) и представить данные в наглядном виде в интерактивном режиме (под капотом Clickhouse, который не тормозит!). Ознакомиться с ним можно по ссылке Metrika Live Demo.
Веб-интерфейс Яндекс.Метрики
Но прелесть в том, что все исходные данные доступны к выгрузке в сыром виде через API сервиса. То есть у вас появляется возможность собрать из этих данных что-то своё, например Сквозную аналитику.
Итак, в базовом виде обращение к API конфигурируется следующим образом:
Тип выгружаемого отчета – таблица, drill-down, time-series
Набор интересующих измерений, метрик, сегментов
Формат ответа и семплирование
Параметризация (валюта, атрибуция, цели)
Синтаксис запроса к API Яндекс.Метрики
Для этого в Airbyte необходимо создать новый источник (source):
Конфигурирование источника Яндекс.Метрика
Конфигурируем простой pipeline и устанавливаем расписание
В качестве приемника данных будем использовать объектное хранилище Yandex Object Storage (совместимое с S3).
Для конфигурации бакета проделаем следующие шаги:
Конфигурация S3 в Яндекс.Облаке
Настроим Destination в Airbyte:
Destination type – S3
S3 Key Id & Access Key полученные при настройке технической учетной записи
Конфигурирование приемника данных S3
Обратите внимание на то, что помимо JSON из коробки доступен ряд других файловых форматов:
AVRO (binary) – гибкий, для schema evolution
Parquet – бинарный, колоночный, оптимизированный под чтение
Доступные форматы файлов для записи данных в S3
Для финализации пайплайна выберем расписание и тип репликации:
Full refresh – Append
После сохраним и запустим репликацию.
Формирование пайплайна source + target + sync mode and frequency
Изучим выгруженные данные
Выгрузка представляет собой JSON-документ с:
метаданными о выгрузке
Ради интереса можно попытаться найти соответствие чисел в веб-интерфейсе Я.Метрики и выгрузке через API.
Понравилось – хочу еще
Браво! Поздравляю с первым потоком интеграции на реальных данных и использованием Modern Data Stack.
Еще больше современных инструментов мы изучаем на занятиях курсов Data Engineer и Analytics Engineer в OTUS: dbt, Clickhouse, Dataproc, Airflow. Но главное – то, что я и мои коллеги стремимся дать полноценную картинку и практические навыки, так необходимые для работы.
Главные преимущества такого подхода:
Живое общение на регулярных вебинарах
Пошаговые практические инструкции и домашние задания
Обратная связь и возможность получить консультации к своим решениям
Data Engineer – один из самых успешных тиражных курсов, в запусках которого я участвую уже более 2-х лет. К новому старту готовы кардинальные обновления по содержанию, используемым инструментам, инфраструктуре, включая выделенные вебинары на разбор домашних заданий.
Analytics Engineer – попытка закрыть потребность на людей-мультиинструменталистов, которые сильны и в понимании специфики бизнеса, моделировании и в инженерной части. Львиная доля курса посвящена современным аналитическим СУБД, BI-инструментам, практикам продвинутой аналитики и моделирования в dbt.



