Data mesh что это
Привет, Хабр! Мы в Dodo Pizza Engineering очень любим данные (а кто их сейчас не любит?). Сейчас будет история о том, как накопить все данные мира Dodo Pizza и дать любому сотруднику компании удобный доступ к этому массиву данных. Задача под звёздочкой: сохранить нервы команды Data Engineering.
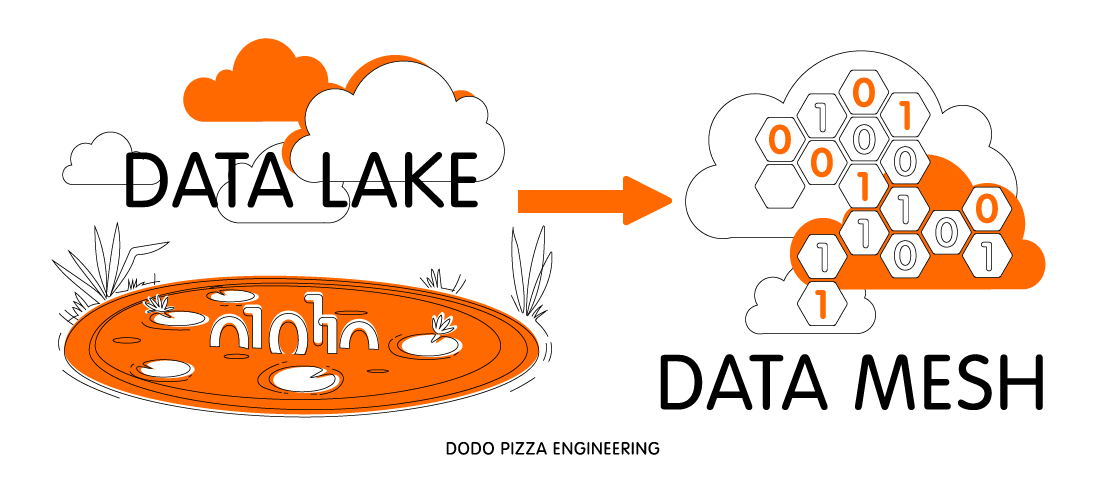

Переход от монолитного Data Lake к распределённой Data Mesh
Привет, Хабр! Представляю вашему вниманию перевод статьи «How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh» автора Zhamak Dehghani (Жамак Дегани)(все изображения взяты из этой же статьи).
Все крупные компании сейчас пытаются строить огромные централизованные хранилища данных. Или же ещё более огромные кластерные Data Lakes (как правило, на хадупе). Но мне не известно ни одного примера успешного построения такой платформы данных. Везде это боль и страдание как для тех, кто строит платформу данных, так и для пользователей. В статье ниже автор (Жамак Дегани) предлагает совершенно новый подход к построению платформы данных. Это архитектура платформы данных четвертого поколения, которая называется Data Mesh. Оригинальная статья на английском весьма объёмна и откровенно тяжело читается. Перевод так же получился немаленьким и текст не очень прост: длинные предложения, суховатая лексика. Я не стал переформулировать мысли автора, дабы сохранить точность формулировок. Но я крайне рекомендую таки продраться через этот непростой текст и ознакомиться со статьёй. Для тех, кто занимается данными, это будет очень полезно и весьма интересно.
Немало компаний инвестируют в следующее поколение Data Lake с надеждой упростить доступ к данным в масштабе всей компании и предоставить бизнесу инсайты и возможность принимать качественные решения автоматически. Но текущие подходы к построению платформ данных имеют схожие проблемы, которые не позволяют достигнуть поставленных целей. Чтобы решить эти проблемы нам необходимо отказаться от парадигмы централизованного Data Lake (или его предшественника – хранилища данных). И перейти к парадигме, основанной на современной распределённой архитектуре: рассматривать бизнес-домены как приоритет первого уровня, применять платформенное мышление для создания инфраструктуры с возможностью самообслуживания и воспринимать данные как продукт.
29 сентября — Hello, conference! mode: on

Привет, Хабр! В следующую среду 29 сентября в 13:00 мы приглашаем вас на 10, юбилейную научно-техническую конференцию Hello, conference! посвященную передовым идеям и решениям в архитектуре приложений, данных и бизнеса. Участие бесплатное, но важно заранее зарегистрироваться, чтобы получить ссылку на трансляцию.
Помимо выступления топовых специалистов MTS Digital, будет доклад из Сбера, а хедлайнером конференции в этот раз выступит эксперт мирового уровня в области разработки ПО, работающий на стыке гибкого проектирования и системной архитектуры — Нил Форд, директор и архитектор в компании Thoughtworks, которого мы специально выписали из штатов.
Wi-Fi Mesh сети для самых маленьких

Недавним постом мы выяснили, что довольно большая часть от аудитории хабра не знает о том, что такое Mesh сети, постараемся это исправить.
Что такое Mesh Wi-Fi

Mesh сеть — это распределенная, одноранговая, ячеистая сеть.
Каждый узел в ней обладает такими же полномочиями как и все остальные, грубо говоря — все узлы в сети равны.
Сети бывают самоорганизующиеся и настраиваемые, первый тип сетей при включении оборудования, которое его поддерживает, автоматически подключаются к существующим участникам, выбирают оптимальные маршруты и самонастраиваются внутри сети.
Настраиваемые же сети, это те сети, которые следует настроить перед использованием.
Полноценная Mesh Wi-Fi сеть
Зачем такие сети нужны
Mesh сети — это вполне осмысленный следующий шаг в развитии беспроводных сетей, в mesh сети вы «сам себе провайдер», вас нельзя отключить от этой сети, с вами нельзя разорвать договор о пользовании интернетом, вас нельзя подслушивать СОРМ’ом спец оборудованием.
Какие проблемы решает эта технология
Плюсы и минусы Mesh сетей
Какие технологии и протоколы используются
Сравнительная таблица Mesh протоколов:
Авто-назначение адреса — клиент сам выбирает себе адрес и может не менять его, переходя из одной под сети в другую, нет единого центра выдачи адресов
Авто-конф. Маршрутизация — нет необходимости вручную настраивать маршрутизацию в сети
Распределенная маршрутизация — узлы обмениваются информацией о маршрутизации
Объединение сетей — умеет объединять сети через обычный интернет
IPv4/v6 — по какому протоколу работает сеть
Авто-настройка — позволяет пользоваться сетью без установки какого-либо другого ПО
Разработка — статус разработки сети
Поддержка OS — какие операционные системы могут быть полноценными участниками сети
Mesh сети и органы власти
Для государства, Mesh сети это двоякое явление, с одной стороны такой тип сетей позволяет за меньшие деньги подключить к сети удаленные регионы с минимальным количеством вложений, с другой стороны — трафик в таких сетях не может быть перехвачен и проанализирован.
Какой стороны будет придерживаться наше правительство — станет известно в будущем, но уже сейчас в мире работают множество Mesh сетей, они построены на разных протоколах, у них разное сообщество, но они работают. en.wikipedia.org/wiki/List_of_wireless_community_networks_by_region
В России нет никаких ограничений для запуска Mesh Wi-Fi сетей в диапазоне 2,4 GHz habrahabr.ru/post/183474
Как будут работать сети в ближайшем будущем
На данный момент, активнее всего разрабатывается набор протоколов cjdns, на таблице выше видно чего он может делать уже сейчас.
Так же сейчас идет разработка DNS системы для cjdns, что позволит сделать доменную систему распределенной, еще нет окончательного стандарта, но, судя по всему, будет выбран Bitcoin как средство для фиксирования регистрации доменов, как только будет утвержден стандарт DNS в cjdns — я непременно расскажу об этом.
Как только две эти части будут реализованы, то можно будет сказать, что у нас есть готовая реализация набора протоколов для организации полноценной Mesh сети.
На данный момент, к сожалению, ни одна из доступных реализаций не может считаться полноценной Mesh сетью из-за отсутствия тех или иных функций.
Пять подходов к построению современной платформы данных

Время + данные = выгода
Любая крупная компания, начинающая работать с данными, которыми обладает, преследует одну первостепенную задачу: получить из них выгоду. При этом ценность данных напрямую зависит от времени, которое требуется на их анализ, обработку. Именно эта зависимость влияет на то, какое архитектурное решение наилучше подойдёт для реализации конкретных задач бизнеса.
Чтобы проследить зависимость ценности данных от времени, рассмотрим абстрактный график (рис. 1). Его левая часть демонстрирует данные, возникающие в режиме реального времени в системах источников. Поскольку это крайне динамичный процесс — речь может идти о миллисекундах и секундах, важно научиться эти данные обрабатывать.
Правая часть графика показывает данные, которые накапливает организация. Именно в ней содержится основная историческая ценность: все паттерны поведения различных клиентов, устройств.
Средняя часть графика представляет наименьший интерес с точки зрения получения выгоды. Данные возникают слишком быстро, и мы не можем реагировать на их обработку оперативно, либо данных недостаточно, и мы не получаем качественную статистическую выборку.
Учитывая зависимость данных от времени, поговорим о пяти подходах к построению платформы данных.
Традиционный подход к построению платформы данных
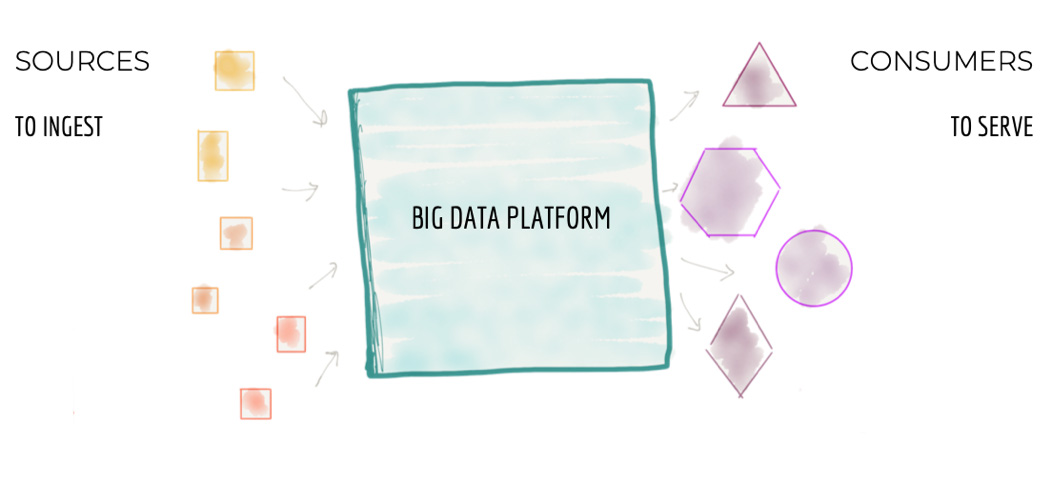
Как работает. ETL-инструмент извлекает данные систем-источников, в процессе чего обрабатывает их, преобразует и загружает в централизованное хранилище данных. На базе этой информации строятся витрины данных, и конечный пользователь в виде BI-систем, процессов Data Mining, OLAP получает какую-то конкретную выгоду.
Основные ограничения. Наиболее актуальная проблема традиционного подхода к построению платформы данных заключается в том, что с момента возникновения данных во front-end системе до момента получения выгоды проходит значительное количество времени. Несмотря на то что в процессе эволюции этот период сократился с 3-4 дней до 1 дня, на текущий момент это всё ещё «очень долго». А любое изменение на источнике или перемены требований со стороны бизнеса влекут «дорогостоящий» процесс по переработке структуры данных хранилища и необходимости получения истории из источников.
Именно поэтому традиционный подход к построению платформы данных редко используется в самых новых проектах (greenfield-проектах). Но многие компании продолжают его эксплуатировать, несмотря на текущие ограничения.
Вторая проблема традиционного подхода к построению хранилища данных заключается в сложности обеспечения отказоустойчивости в случае потери самого ландшафта или инфраструктуры, которые используются под хранение данных. Восстановление системы может занимать несколько дней. Это происходит потому, что помимо основного контура, где наблюдается отставание систем-источников, приходится использовать резервный контур, который ещё больше отстаёт. Поэтому крайне сложно получить актуальные данные в случае выхода из строя каких-то частей основного ЦОД.
Третье ограничение традиционной платформы данных в том, что она может обрабатывать только структурированные данные. Данные другого типа не используются.
В качестве технологий хранения, как правило, использовались Single-Node Processing (SNP) БД: такие как Oracle, SQL Server и их аналоги. В связи с этим масштабирование платформы и архитектуры предполагало Scale-Up подход, когда при достижении пика производительности необходимо было заменять практически всю инфраструктуру.
Пример использования. Традиционная архитектура использовалась практически во всех компаниях на заре работы с Big Data в середине 2000-х годов, особенно в финтехорганизациях. Наиболее крупные хранилища могли исчисляться десятками терабайтов.
Advanced Architecture
Как работает. В ход пошла ELT-технология: сначала данные извлекаются и загружаются в конечную систему, и лишь после этого происходит их преобразование. Advanced Architecture даёт возможность получить копию исходных данных систем-источника и дальше производить над ними любые манипуляции, не нагружая саму систему источника. Это упрощённый процесс с точки зрения подхода к получению исходных данных: не нужно производить какие-то сложные ETL-процессы преобразования, агрегации. Зато можно хранить сырые данные и получать исторические изменения без необходимости заново получать информацию из источника.
Основным драйвером такого подхода стало появление систем класса MPP — массивно-параллельной обработки и возможность использовать pushdown-оптимизацию (рис. 4). Совмещение этих технологических подходов дало возможность переносить данные из систем-источников в мощное технологическое решение MPP (среди них Teradata, Vertica, Greenplum).
Advanced Architecture реализует концепцию распределённой обработки и возможности горизонтального масштабирования. Такой подход позволяет эффективно преобразовать сырые данные в некие различные слои — как детальные данные, так и витрины, отчёты. При этом таких слоёв может быть несколько. За счёт этого время получения результата сократилось в часы вместо 3-4 дней.
Отставание помог сократить не только ELT-подход, но и CDC (change data capture) — технология, позволяющая воспроизвести изменения систем-источников на удалённом целевом решении, в том числе на уровне MPP-платформ. Здесь существует несколько подходов, но основной из них заключается в том, чтобы использовать так называемые логи или trail-файлы, позволяющие воспроизвести полностью весь цикл изменения исходных данных на системе-источнике и целевой системе.
В результате появляется возможность получить изменение систем-источников, например, в пределах 15 минут. Но это в теории: как правило, процесс занимает чуть больше времени из-за существующей нагрузки на источник. Решить эту проблему помогают механизмы, позволяющие использовать холодные копии исходных данных и воспроизводить именно их. В результате можно сократить отставание до 1-2 часов.
При помощи CDC Advanced Architecture позволила решить проблему и аварийного восстановления (Disaster Recovery). Передача данных обеспечивается различными контурами за счёт воспроизведения изменений на системе-источнике. Это позволяет получить консистентное состояние данных на уровне катастрофоустойчивости с точки зрения отставания в несколько десятков минут.
Основные ограничения. Advanced Architecture не позволяет решать задачи, возникающие в режиме реального времени, потому что оперирует интервалом в десятки минут. Этому препятствует необходимость использовать сторонние инструменты для масштабирования потоков данных, да и сами изменения данных происходят с задержкой.
Modern Data Architecture
Основным драйвером развития Modern Data Architecture стало появление на рынке такого технологического решения, как Apache Hadoop. Оно позволило в значительной степени снизить ТСО (total cost of ownership) системы за счёт того, что Hadoop изначально является открытым проектом (open source) и разрабатывался для работы на любом повсеместно используемом (commodity) оборудовании.
Здесь же появились механизмы, позволяющие как упростить процесс аварийного восстановления самого решения, так и обеспечить Disaster Recovery различных решений с помощью сторонних средств, входящих в экосистему Apache Hadoop.
Использование Apache Hadoop привело к появлению в подходе к построению современного хранилища данных такого термина, как озеро данных (Data Lake). Его автором стал Джеймс Диксон, один из основателей Pentaho. Идея Data Lake заключается в том, чтобы интегрировать Hadoop-решения в существующие у заказчиков legacy-архитектуры. Благодаря этому можно ускорить процесс подготовки данных, решить вопрос, связанный с хранением большого объёма информации, и гибко использовать широкую экосистему инструментов для эффективного анализа данных.
Modern Data Architecture позволила обрабатывать неструктурированные данные, а также разгрузить дорогостоящие как front-end системы, так и различные DWH-системы.
Как работает. Концепция Modern Data Architecture описана на рисунке 5. Существует DWH-архитектура, которая изначально была построена компанией. В ней протекают свои ELT-процессы. Рядом появляется уровень Hadoop, а вместе их можно назвать Data Lake. На себя Hadoop забирает всю нагрузку с точки зрения долговременного хранения детальных данных, агрегаторов, аналитических архивов, включая данные, попадающие из неструктурированных и слабоструктурированных источников (clickstream, логи). DWH и Hadoop интегрированы между собой набором решений — коннекторами, жизненным циклом данных (процессы, определяющие, какие данные являются востребованными, а какие архивными).
Основное достоинство Modern Data Architecture заключается в том, что компания может получать данные другой структуры, а их отставание от источников сокращается за счёт использования более технологичных и распределённых инструментов обработки. Для эффективной передачи потоковых данных появились стриминг-технологии (Apache Flink, Apache NiFi), которые дали возможность перейти к нативной обработке потока данных в его явном виде. Благодаря им компании смогли решать задачи, ранее недоступные им, при помощи микробатч-процессов обработки данных и строить совершенно новые архитектуры платформ данных.
Основные ограничения. У Modern Data Architecture отсутствует чёткий дизайн с точки зрения имплементации тех или иных решений. А концепция реализации во многом зависит от видения главного инженера проекта.
Более того, бизнес-потребности компании со временем эволюционируют, и задачи, изначально возложенные на хранилище данных, могут меняться. Поэтому время построения каких-то статичных отчётов может увеличиваться с нескольких минут до нескольких часов. Одна из причин: быстрый рост пользователей и бизнес-кейсов, решаемых на Modern Data Architecture и в некоторых случаях не подходящих по нагрузке и сценарию использования данных.
Не до конца решена в Modern Data Architecture и проблема аварийного восстановления, несмотря на имеющиеся в Hadoop специфические инструменты отказоустойчивости.
Ещё одна проблема Modern Data Architecture выходит на сцену, когда Data Lake превращается в Data Swamp — болото данных. Это происходит тогда, когда компании в лавинообразном порядке начинают складывать в Hadoop все данные, которые у них есть. В результате теряется смысл данных, пропадают связи между ними. К счастью, сейчас появился ряд проектов, позволяющих структурировать этот подход и решить вопрос, связанный с построением общей таксономии данных, которые есть в системе. Делается это автоматически. Типичным представителем таких проектов является Apache Atlas.
Многие компании сейчас разрабатывают общую спецификацию построения концепций стратегического управления данными и их качеством. Например, этот вопрос один из первостепенных для некоммерческих организаций, развивающих Open Source, например Open Data Platform Initiative (ODPi).
Пример использования. Data Lake является эволюционным шагом в развитии архитектуры обработки данных. Например, одна европейская телеком-компания смогла снизить текущую нагрузку на инфраструктуру и решить задачу по удержанию клиентов за счёт обработки неструктурированных данных — лог-файлов, где хранилась уникальная информация по обрывам связи. Причём данные загружались и обрабатывались именно за счёт внедрения архитектуры Data Lake. А благодаря появлению новых инструментов был реализован ряд механизмов, позволяющих совершать предиктивные действия по отношению к клиенту.
Lambda Architecture
Как работает. Lambda Architecture позволила немного «ослабить» CAP-теорему. Согласно ей ни одна техническая система одновременно не может удовлетворять трём условиям: консистентности, доступности и распределённости. Натан Марц предложил разделить технологические уровни на несколько частей и использовать для них различные технологии, закрывающие со своей стороны два из трёх ограничений CAP-теоремы. Основная идея предполагает существование трёх уровней, позволяющих решать вопросы как real-time обработки (speed layer), где данные появляются в течение миллисекунд, так и исторического слоя (batch layer), когда есть данные, которые нужно хранить в долгосрочной перспективе. Для решения этих задач в платформе хранения данных присутствует федеративный уровень, который может получать оба типа данных и решать задачи разного типа, класса в различных режимах (рис. 7).
Основные ограничения. Поскольку Lambda Architecture достаточно сложная с точки зрения имплементации, возникает проблема внедрения и эксплуатации таких решений в legacy-инфраструктуры. Однако, в отличие от Modern Data Architecture, существует много информации, включая книгу, которую написал Натан Марц, как реализовать ту или иную часть платформы.
Но остаются вопросы, как перейти на Lambda Architecture с legacy-инфраструктуры. На помощь здесь приходит бимодальное ИТ: рядом с существующей legacy-инфраструктурой строится новая инфраструктура, которая работает для новых проектов. В процессе эксплуатации на новую архитектуру переносятся и критичные для бизнеса задачи.
Второй подход — итеративная имплементация различных дополнительных решений. Этот подход актуален, если изначально путь построения архитектуры подразумевал переход к задачам, связанным с real-time. Например, компания начала с реляционной базы данных с DWH, затем появился Hadoop как озеро данных, на уровне которого в текущую инфраструктуру интегрируются новые инструменты для работы с задачами в режиме реального времени. Так, воспользовавшись вторым подходом, крупная компания смогла в режиме реального времени получать данные с датчиков, установленных на дорожной технике. Анализируя поступающую информацию, бизнес смог сократить расходы на ремонты автомобилей, вовремя внедряя результаты предиктивной аналитики.
Пример использования. Lambda Architecture получила распространение в производственных компаниях и автомобильной индустрии. Некоторые добывающие компании реализовали такой подход для решения задач предиктивного обслуживания и выявления угроз на производстве. На базе исторического слоя собиралась статистика по работе узлов и агрегатов, строились паттерны, позволяющие выявлять потенциальные проблемы. Эти модели работали на уровне speed layer и позволяли в режиме реального времени выявлять ранее смоделированные события.
Data Mesh Architecture
Что это такое. Data Mesh Architecture придумала Жамак Дегани. По её мнению, новый подход поможет компаниям разработать платформу данных третьего поколения, учтя ошибки двух предыдущих (проприетарные хранилища данных и использование Data Lake в качестве серебряной пули). Data Mesh Architecture активно использует стриминг-технологии, объединяет пакетную и потоковую обработки данных, а хранит данные в облаке. Благодаря этому у компаний появляется возможность анализировать данные в режиме реального времени, снизив при этом затраты на управление инфраструктурой хранилища.
Как работает. Главное отличие Data Mesh Architecture от предыдущих поколений платформ хранения данных заключается в том, что данные не передаются в Data Lake. Они хранятся и используются командами внутри бизнес-доменов в удобном для них виде. При этом данные в разных доменах могут дублироваться, когда происходит их изменение на удобный конечному пользователю формат.
Основные ограничения. Чтобы перейти на Data Mesh Architecture, любой компании предстоит пройти большой путь, и речь тут даже не об использовании технологий. Чтобы масштабировать новые принципы, необходимо серьёзно подойти к ведению бизнес-процессов.
Пример использования. Data Mesh Architecture наиболее востребована в компаниях с высокой динамикой роста бизнеса и направлений: среди них крупные ритейлеры, которые или уже перешли на эту архитектуру, или начинают процесс перехода. Это позволит им быстро включать в процесс обработки и подготовки данных новые филиалы и направления бизнеса за счёт возможности масштабирования команд, отвечающих за свою часть данных.
Какой из пяти перечисленных подходов к построению платформы выбрать — решает каждая компания для себя. Однако важно подойти к этому вопросу, вооружившись практическими знаниями. Поэтому, чтобы получить эффективно работающие хранилище, желательно найти партнёра, который имеет большой опыт в успешной реализации подобных проектов.
Сервисная сеть, «Плоскость данных» и «Плоскости управления» (Service mesh data plane vs. control plane)
Привет, Хабр! Представляю вашему вниманию перевод статьи «Service mesh data plane vs control plane» автора Matt Klein.
В этот раз «захотелось и перевелось» описание обоих компонентов service mesh, data plane и control plane. Это описание мне показалось самым понятным и интересным, а главное подводящим к пониманию «А нужно ли оно вообще?».
Поскольку идея «Сервисной сети (Service mesh)» становится все более популярной в течение последних двух лет (Оригинальная статья от 10 октября 2017), а число участников в пространстве возросло, я увидел соразмерный рост путаницы среди всего технического сообщества в отношении того, как сравнивать и противопоставлять разные решения.
Ситуацию лучше всего описать следующими сериями твитов, которые я написал в июле:
Путаница с сервисной сетью (service mesh) № 1: Linkerd
= Envoy. Ни один из них не равен Istio. Istio — это нечто совсем другое. 1 /
Первые просто плоскости данных (data planes). Сами по себе они ничего не делают. Они должны быть настроены на что-то большее. 2 /
Istio является примером плоскости управления (control plane), которая связывает части вместе вместе. Это другой слой. /конец
В предыдущих твитах упоминается несколько разных проектов (Linkerd, NGINX, HAProxy, Envoy и Istio), но, что более важно, вводятся общие понятия плоскости данных (data plane), сервисной сети (service mesh) и плоскости управления (control plane). В этом посте я сделаю шаг назад и расскажу, что я имею в виду под терминами «плоскость данных (data plane)» и «плоскость управления (control plane)» на очень высоком уровне, а затем расскажу, как термины относятся к проектам, упомянутым в твитах.
Что такое сервисная сеть (What is a service mesh, really)?
Рисунок 1: Обзор сервисной сети (Service mesh overview)
Рисунок 1 иллюстрирует концепцию сервисной сети (service mesh) на самом базовом уровне. Есть четыре сервисных кластера (A-D). Каждый экземпляр сервиса связан с локальным прокси сервером. Весь сетевой трафик (HTTP, REST, gRPC, Redis и т. Д.) от отдельного экземпляра приложения передается через локальный прокси-сервер в соответствующие внешние сервисные кластеры. Таким образом, экземпляр приложения не знает о сети в целом и знает только о своем локальном прокси. Фактически, сеть распределенной системы была удалена от сервиса.
Плоскость данных (Data plane)
В сервисной сети (service mesh) прокси-сервер, расположенный локально для приложения, выполняет следующие задачи:
Плоскость управления (The control plane)
Сетевая абстракция, которую обеспечивает локальный прокси в плоскости данных (data plane), является волшебной (?). Тем не менее, как прокси-сервер на самом деле узнает о маршруте «/foo» к сервису B? Как данные обнаружения сервисов (service discovery), которые заполняются прокси-запросами, могут быть использованы? Как настроены параметры балансировки нагрузки, таймаута (timeout), обрыва цепи (circuit breaking) и т.д.? Как осуществляется развертывание приложения с использованием синего/зеленого (blue/green) метода или метода постепенного перевода трафика? Кто настраивает параметры общесистемной аутентификации и авторизации?
Все вышеперечисленные пункты находятся в ведении плоскости управления (control plane) сервисной сети (service mesh). Плоскость управления (control plane) принимает набор изолированных прокси-серверов без состояния и превращает их в распределенную систему.
Я думаю, что причина, по которой многие технологи находят запутанными разделенные понятия плоскости данных (data plane) и плоскости управления (control plane), заключается в том, что для большинства людей плоскость данных знакома, в то время как плоскость управления чужеродна/непонятна. Мы уже давно работаем с физическими сетевыми маршрутизаторами и коммутаторами. Мы понимаем, что пакеты/запросы должны идти из пункта А в пункт Б, и что мы можем использовать для этого аппаратное и программное обеспечение. Новое поколение программных прокси — это просто модные версии инструментов, которые мы использовали в течение долгого времени.
Рисунок 2: Человеческая плоскость управления (Human control plane)
На рисунке 2 показано то, что я называю «Человеческой плоскостью управления (Human control plane)». В этом типе развертывания, которое все еще встречается очень часто, человек-оператор, вероятно сварливый, создает статические конфигурации — потенциально, с помощью скриптов — и развертывает их с помощью какого-то специального процесса на всех прокси-серверах. Затем прокси начинают использовать эту конфигурацию и приступают к обработке плоскости данных (data plane) с использованием обновленных настроек.
Рисунок 3: Расширенная плоскость управления сервисной сетью (Advanced service mesh control plane)
На рисунке 3 показана «расширенная» плоскость управления (control plane) сервисной сети (service mesh). Она состоит из следующих частей:
Плоскость данных и плоскость управления. Сводка (Data plane vs. control plane summary)
Текущее состояние проекта (Current project landscape)
Разобравшись с объяснением выше, давайте посмотрим на текущее состояние проекта «сервисной сети (service mesh)».
В начале 2016 года Linkerd был одним из первых прокси-серверов плоскости данных (data plane) для сервисной сети (service mesh) и проделал фантастическую работу по повышению осведомленности и увеличению внимания к модели проектирования «сервисная сеть» (service mesh). Примерно через 6 месяцев после этого Envoy присоединился к Linkerd (хотя работал в Lyft с конца 2015 года). Линкерд и Envoy — это два проекта, которые чаще всего упоминаются при обсуждении сервисных сетей (service mesh).
Istio было объявлено в мае 2017 года. Цели проекта Istio очень похожи на расширенную плоскость управления (control plane), показанную на рисунке 3. Envoy для Istio является прокси-сервером «по умолчанию». Таким образом, Istio является плоскостью управления (control plane), а Envoy — плоскостью данных (data plane). За короткое время Istio вызвало много волнений, и другие плоскости данных (data plane) начали интеграцию в качестве замены Envoy (и Linkerd, и NGINX продемонстрировали интеграцию с Istio). Тот факт, что в одной плоскости управления (control plane) можно использовать разные плоскости данных (data plane), означает, что плоскость управления (control plane) и плоскость данных (data plane) не обязательно тесно связаны. Такой API как универсальный API плоскости данных (data plane) Envoy может образовывать мост между двумя частями системы.
Nelson и SmartStack помогают дополнительно проиллюстрировать разделение плоскости управления (control plane) и плоскости данных (data plane). Nelson использует Envoy в качестве своего прокси и строит надежную плоскость управления (control plane) сервисной сетью (service mesh) на базе стека HashiCorp, т.е. Nomad и т.д. SmartStack стал, пожалуй, первым из новой волны сервисных сетей (service mesh). SmartStack формирует плоскость управления (control plane) вокруг HAProxy или NGINX, демонстрируя возможность развязки плоскости управления (control plane) сервисной сетью (service mesh) и плоскости данных (data plane).
Микросервисная архитектура с сервисной сетью (service mesh) привлекает к себе все больше внимания (правильно!), и все больше проектов и вендоров начинают работать в этом направлении. В течение следующих нескольких лет мы увидим много инноваций как в плоскостях данных (data plane), так и в плоскостях управления (control plane), а также дальнейшее смешивание различных компонентов. В конечным счете микросервисная архитектура должна стать более прозрачной и волшебной (?) для оператора.
Надеюсь, все менее и менее раздраженного.



