Data Mart vs Data Warehouse
Некоторое время назад я начал разбираться в OLAP и в данном посте хочу проверить правильность собственных мыслей на счет этих двух понятий.
Терминология
Data Mart — витрина данных, в переводе.
Data Warehouse — хранилище данных.
Но дело в том, что оба эти термина могут переводится как Хранилище данных…
Data Mart — срез Data Warehouse.

(кликабельно)
Есть два подхода к построению хранилищ данных:
Первый проще, по Кимбелу (Kimball)
Тут информация от OLTP системы напрямую попадает в data mart, откуда уже OLAP берет необходимые ему данные. Первый случай очевидно иллюстрирует подход М. Демареста (M.Demarest), который, как говорит Wikipedia:
в 1994 году предложил объединить две концепции и использовать хранилище данных в качестве единого интегрированного источника данных для витрин данных.
Второй, по Инману (Inman), см. книгу.
Здесь информация от OLTP сначала попадает в хранилище данных (data warehouse), потом только в data mart, откуда OLAP снова берет необходимую ему информацию.
Мы же адаптируем подход Инмана, который называет хранилищем данных настоящую релиционную бд, тогда как Кимбел — смесь data mart`ов.
Data mart — это база данных, созданная по требованиям моделирования измерений (dimensional modelling) и состоит из таблиц фактов и таблиц измерений.
Data Mart
При реализации системы по методологии Кимбела, фронтендом бд должен выступать data mart, который использует Analysis Services для куба в качестве источника данных
Data Warehouse
(кликабельно)
таким образом является сложнее data mart`a, включает в себя не только бд, но и систему поддержки принятия решений и клиент-серверную архитектуру, тогда как data mart по сути является бд, созданной с учетом требований будущих кубов.
Источники:
http://ru.wikipedia.org/wiki/Витрина_данных
http://ru.wikipedia.org/wiki/Хранилище_Данных
Книга Expert Cube Development with Microsoft SQL Server 2008 Analysis Services, на английском

которую я перевожу у себя в блоге.
Озеро, хранилище и витрина данных
Рассмотрим три типа облачных хранилищ данных, их различия и области применения.
Озеро данных
Озеро данных (data lake) — это большой репозиторий необработанных исходных данных, как неструктурированных, так и частично структурированных. Данные собираются из различных источников и просто хранятся. Они не модифицируются под определенную цель и не преобразуются в какой-либо формат. Для анализа этих данных требуется длительная предварительная подготовка, очистка и форматирование для придания им однородности. Озера данных — отличные ресурсы для городских администраций и прочих организаций, которые хранят информацию, связанную с перебоями в работе инфраструктуры, дорожным движением, преступностью или демографией. Данные можно использовать в дальнейшем для внесения изменений в бюджет или пересмотра ресурсов, выделенных коммунальным или экстренным службам.
Хранилище данных
Хранилище данных (data warehouse) представляет собой данные, агрегированные из разных источников в единый центральный репозиторий, который унифицирует их по качеству и формату. Специалисты по работе с данными могут использовать данные из хранилища в таких сферах, как data mining, искусственный интеллект (ИИ), машинное обучение и, конечно, в бизнес-аналитике. Хранилища данных можно использовать в больших городах для сбора информации об электронных транзакциях, поступающей от различных департаментов, включая данные о штрафах за превышение скорости, уплате акцизов и т. д. Хранилища также могут использовать разработчики для сбора терабайтов данных, генерируемых автомобильными датчиками. Это поможет им принимать правильные решения при разработке технологий для автономного вождения.
Витрина данных
Витрина данных (data mart) — это хранилище данных, предназначенное для определенного круга пользователей в компании или ее подразделении. Витрина данных может использоваться отделом маркетинга производственной компании для определения целевой аудитории при разработке маркетинговых планов. Также производственный отдел может применять ее для анализа производительности и количества ошибок, чтобы создать условия для непрерывного совершенствования процессов. Наборы данных в витрине данных часто используются в режиме реального времени для аналитики и получения практических результатов.
Озеро, хранилище и витрина данных: ключевые различия
Все упомянутые репозитории используются для хранения данных, но между ними есть существенные различия. Например, хранилище и озеро данных — крупные репозитории, однако озеро обычно более рентабельно с точки зрения затрат на внедрение и обслуживание, поскольку в нем по большей части хранятся неструктурированные данные.
За последние несколько лет архитектура озер данных эволюционировала, и теперь способна поддерживать бо́льшие объемы данных и облачные вычисления. Большие объемы данных поступают от разных источников в централизованный репозиторий.
Хранилище данных можно организовать одним из трех способов:
Витрина данных содержит небольшой по сравнению с хранилищем и озером объем данных, которые разбиты на категории для применения конкретной группой людей или подразделением компании. Витрина данных может быть представлена в виде различных схем (звезды, снежинки или свода), которые определяются логической структурой данных. Формат свода данных (data vault) является самым гибким, универсальным и масштабируемым.
Существует три типа витрин данных:
IBM предлагает различные решения для облачного хранения и интеллектуального анализа данных.
Логическая витрина для доступа к большим данным
Технологии Big Data создавались в качестве ответа на вопрос «как обработать много данных». А что делать, если объем информации не является единственной проблемой? В промышленности и прочих серьезных применениях часто приходится иметь дело с большими данными сложной и переменной структуры, разрозненными массивами информации. Встречаются задачи, способ решения которых наперед не известен, и аналитику необходимы средства исследования исходных данных или результатов вычислений на их основе без привлечения программиста. Нужны инструменты, сочетающие функциональную мощь систем BI (а лучше – превосходящие ее) со способностью к обработке огромных объемов информации.
Одним из способов получить такой инструмент является создание логической витрины данных. В этой статье мы расскажем о концепции этого решения, а также продемонстрируем программный прототип.
Для рассказа нам понадобится простой пример сложной задачи. Рассмотрим некий промышленный комплекс, обладающий огромным количеством оборудования, обвешанного различными датчиками и сенсорами, регулярно сообщающими сведения о его состоянии. Для простоты рассмотрим только два агрегата, котел и резервуар, и три датчика: температуры котла и резервуара, а также давления в котле. Эти датчики контролируются АСУ разных производителей и выдают информацию в разные хранилища: сведения о температуре и давлении в котле поступают в HBase, а данные о температуре в резервуаре пишутся в лог-файлы, расположенные в HDFS. Следующая схема иллюстрирует процесс сбора данных.
Кроме конкретных показаний датчиков, для анализа необходимо иметь список сенсоров и устройств, на которых они установлены. Оценим порядок числа информационных сущностей, с которыми мы имели бы дело на реальном предприятии:
| Сущность | Порядок числа записей | Тип хранилища |
|---|---|---|
| Единицы оборудования | Тысячи | Мастер-данные |
| Датчики, сенсоры | Сотни тысяч | БД PostgreSQL |
| Показания датчиков | Десятки миллиардов в год (вопрос глубины хранения в этой статье не ставим) | Файлы в HDFS, HBase |
Способы хранения для данных разных типов зависят от их объема, структуры и требуемого режима доступа. В данном случае мы выбрали именно такие средства для создания «разнобоя», но и на реальных предприятиях чаще всего нет возможности свободно их выбирать – все зависит от сложившегося ИТ-ландшафта. Аналитической же системе нужно собрать весь «зоопарк» под одной крышей.
Итак, наш аналитик будет формулировать запросы в привычных ему терминах, и получать в ответ наборы данных – независимо от того, из какого источника эти данные извлечены. Рассмотрим пример простого запроса, на который можно найти ответ в нашем наборе информации. Пусть аналитик интересуется оборудованием, установленные на котором сенсоры одновременно измерили температуру больше 400 0 и давление больше 5 мПа в течение заданного периода времени. В этой фразе мы выделили жирным слова, соответствующие сущностям информационной модели: оборудование, сенсор, измерение. Курсивом выделены атрибуты и связи этих сущностей. Наш запрос можно представить в виде такого графа (под каждым типом данных мы указали хранилище, в котором они находятся):
При взгляде на этот граф становится понятной схема выполнения запроса. Сначала нужно отфильтровать измерения температуры за заданный период со значением больше 400 0 C, и измерения давления со значением больше 5 мПа; затем нужно найти среди них те, которые выполнены сенсорами, установленные на одной и той же единице оборудования, и при этом выполнены одновременно. Именно так и будет действовать витрина данных.
Схема нашей системы будет такой:
1. В хранилище триплетов Apache Jena (можно использовать и любое другое) у нас хранится как сама модель предметной области, так и настройки мэппинга на источники данных. Таким образом, через редактор информационной модели мы задаем и набор терминов, в которых строятся запросы (устройство, сенсор и т.д.), и служебные сведения о том, откуда брать соответствующую им фактическую информацию. На следующем рисунке показано, как в нашем редакторе онтологий выглядит дерево классов модели демонстрационного примера (слева), и одна из форм настройки мэппинга данных с источником (справа).
2. В нашем примере данные одного и того же типа (измерения температуры) хранятся одновременно в двух разных источниках – HBase и текстовом файле HDFS. Однако для выполнения приведенного запроса обращаться к файлу не нужно, т.к. в нем заведомо нет полезной информации: ведь в файле хранятся измерения температуры резервуара, а давление в резервуарах не измеряется. Этот момент дает представление о том, как должен работать оптимизатор выполнения запросов.
3. Витрина данных не только компонует и связывает информацию из различных источников, но и делает логические выводы на ней в соответствии с заданными правилами. Автоматизация получения логических выводов – одно из главных практических преимуществ семантики. В нашем примере с помощью правил решена проблема получения выводов о состоянии устройства на основе данных измерений. Температура и давление содержатся в двух разных сущностях типа «Измерение», а для описания состояния устройства необходимо их объединить. Логические правила применяются к содержимому временного графа результатов, и порождают в нем новую информацию, которая отсутствовала в источниках.
4. В качестве источников данных могут выступать не только хранилища, но и сервисы. В нашем примере мы спрятали за сервисом расчет предпосылок к возникновению аварийного состояния при помощи одного из алгоритмов Spark MLlib. Этот сервис получает на вход информацию о состоянии устройства, и оценивает его с точки зрения наличия предпосылок к аварии (для обучения использованы ретроспективные данные о том, какие условия предшествовали реально случившимся авариям; в качестве исходных данных нужно рассматривать не только мгновенные значения физических характеристик устройства, но и элементы основных данных – например, степень его износа).
Эта возможность очень важна, так как позволяет аналитику самому выполнять запуск расчетных модулей, подготовленных программистами, передавая им на вход различные массивы данных. В этом случае аналитик будет работать уже не с исходными данными, а с результатами вычислений на их основе.
5. Аналитик строит запросы при помощи интерфейсов нашей Системы управления знаниями, среди которых – как несколько вариантов формального конструктора запросов, так и интерфейс поиска на контролируемом естественном языке. На следующем рисунке слева показана форма построения запроса на контролируемом языке, а справа – пример результатов другого запроса.
Конечно, в любой бочке меда найдется ложка дегтя. В данном случае она состоит в том, что на действительно больших данных приведенная архитектура будет работать не так уж быстро. С другой стороны, при работе аналитика в режиме «свободного поиска» решения проблем быстродействие для него обычно не принципиально; в любом случае, витрина будет выдавать результаты куда быстрее, чем программист, к которому при ее отсутствии аналитику придется обращаться за ручным выполнением каждого своего запроса.
Как быстро развернуть хранилище и аналитику данных для бизнеса
Авторизуйтесь
Как быстро развернуть хранилище и аналитику данных для бизнеса

data-аналитик в ГК FINBRIDGE
Сегодня хочу рассказать историю проекта по запуску небольшого хранилища данных DWH одной из известных российских инвестиционных площадок по финансированию малого и среднего бизнеса.
Два года назад в России стал довольно активно развиваться рынок краудлендинга. Краудлендинг — это процесс, при котором группа инвесторов дает займы компаниям. Но изюминка заключается в том, что в роли инвесторов выступают обычные люди, такие как мы с вами. А заемщиками выступают обычные организации типа ИП или ООО, которые в основном управляют либо розничным бизнесом, либо e-commerce. Соответственно была запущена инвестиционная платформа, которая сводила вместе инвесторов и заемщиков.
Не стоит и говорить, что сразу после запуска площадки руководству потребовалась управленческая и аналитическая отчетность для управления бизнесом. Была поставлена цель быстро настроить предоставление ежедневных оперативных ключевых показателей для кампании.
Сам WEB-сайт инвестиционной площадки и все его внутренние процессы, или так называемый «кредитный конвейер», крутились на БД PostgreSQL. Кредитный конвейер — это собирательное понятие, описывающее весь процесс выдачи компаниями кредитов, начиная от подачи заемщиком заявки на займ и заканчивая погашением кредита.
Стек технологий, который был выбран для внедрения этого проекта, был БД MS SQL + SQL Server Analysis Service + сводные таблицы OLAP в Excel (BI система) для разработки ежедневных кубов OLAP.
Перед дальнейшим рассказом хотел бы расшифровать некоторые термины:
Важно понимать, что под сводными таблицами в Excel понимается не просто статичный отчет, а полноценная BI-система для аналитики данных. Набор показателей и фильтров, которыми можно «вращать» в реальном времени. Добавлять/удалять показатели, настраивать фильтры и смотреть статистику в различных разрезах — все это называется общим термином аналитика показателей.
Круг задач, которые нужно решить, был следующим:
Архитектура для данного проекта была принята следующая:
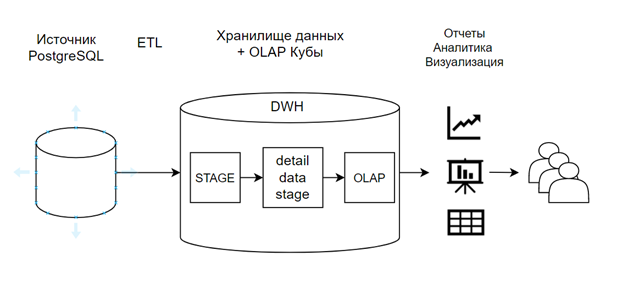
Схема движения потоков данных в DWH
Поскольку во всем проекте было вовлечено минимум сотрудников, то процесс разработки протекал максимально эффективно. Два бизнес-заказчика предоставляли требования к отчетности, а владелец источника предоставлял доступы и описания как к различным таблицам, так и к структурам данных. Я же выполнял роль и разработчика, и аналитика в одном лице. За счет того, что каждый сотрудник выполнял свою роль по максимуму, коммуникация внутри данного круга лиц была очень быстрой и эффективной. А сам процесс разворачивания хранилища протекал очень продуктивно.
Что было сделано в первую очередь?
В первую очередь был настроен обмен данными с хранилищем через ETL-процессы. В MS SQL были созданы коннекторы, которые могли подключаться источнику данных. Под источником понимается другая БД PostgreSQL. Также при создании коннектора установили драйверы для PostgreSQL и настроили системный DSN.
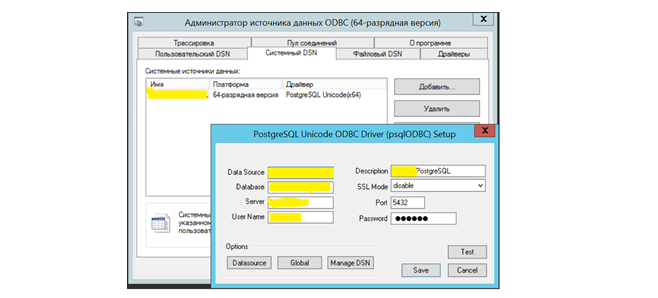
Пример создания подключения к базе
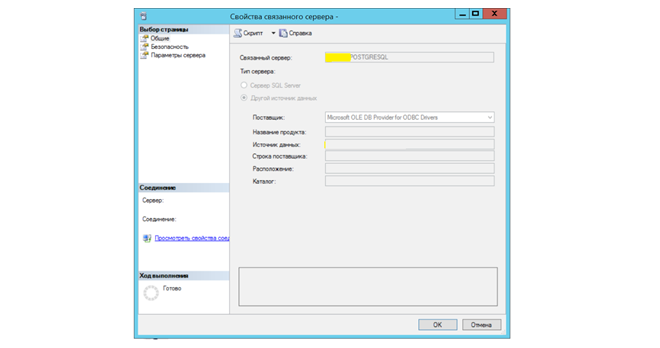
Создание «связного сервиса» в MS SQL
В MS SQL есть возможность прямого подключения к другим БД, так называемый «Связный сервис». В других базах она может называться по-разному (например, в oracle — это db-link), но суть одна и та же. Установив на сервере драйверы для подключения к PostgreSQL можно напрямую из MS SQL выполнять запросы в другую БД и выгружать данные. Соответственно, создав небольшую SQL-процедуру очистки и загрузки данных, как на примере ниже, можно выгружать по линкам любые таблицы из любых источников.

Пример самой простой процедуры полной загрузки таблицы из источника
Также стоит рассказать, про так называемый, сервис «Агент SQL сервер» в MS SQL позволяющий создавать планировщик заданий, запускающийся по расписанию (обычно ночью) и запускающий эти процедуры для загрузки данных в хранилище. Таким образом мы получили набор таблиц, структура которых идентична источнику, на основе которых далее можно выполнять обработку и строить витрины.
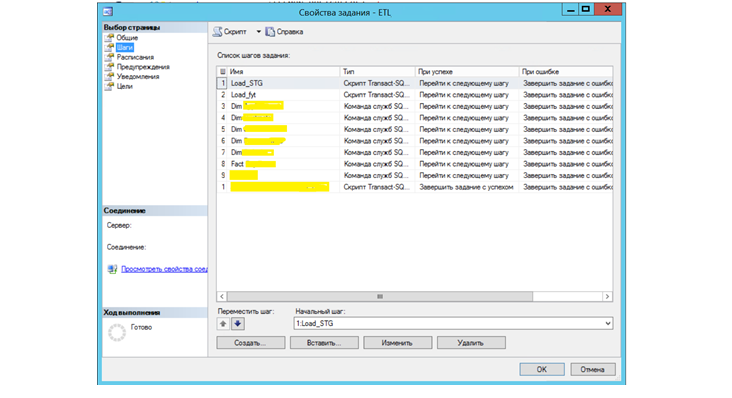
Пример создания планировщика заданий на MS SQL c запуском процедур и кубов OLAP
Витрины данных (Data Marts)
Следующим большим шагом проекта было создание витрин данных. В самой базе было создано всего 3 основные смысловые схемы:
stg — от слова STAGE. В ней лежат таблицы структура данных приближенная к источникам. Туда загружаются данные напрямую из источника.
dim — от слова dimensions. Схема, в которой хранятся справочники.
dds — от слова detail data stage т.е. детальный слой данных. В ней собираются уже обработанные данные взятые из stg.
Для общего понимания обработка dds выглядит как набор процедур и функций порядка 2000 строк чистого SQL кода. Важно заметить, что динамический SQL не использовался, что сильно упрощало жизнь.
Ну и один из последних шагов — создание кубов на MS SQL Analysis Service. Выполнялось все это с помощью инструмента Visual Studio. В них создается физическая и логическая структура сущностей на основе витрин DDS. А также настраиваются показатели и измерения с бизнес понятными переводом для потребителей отчетов.
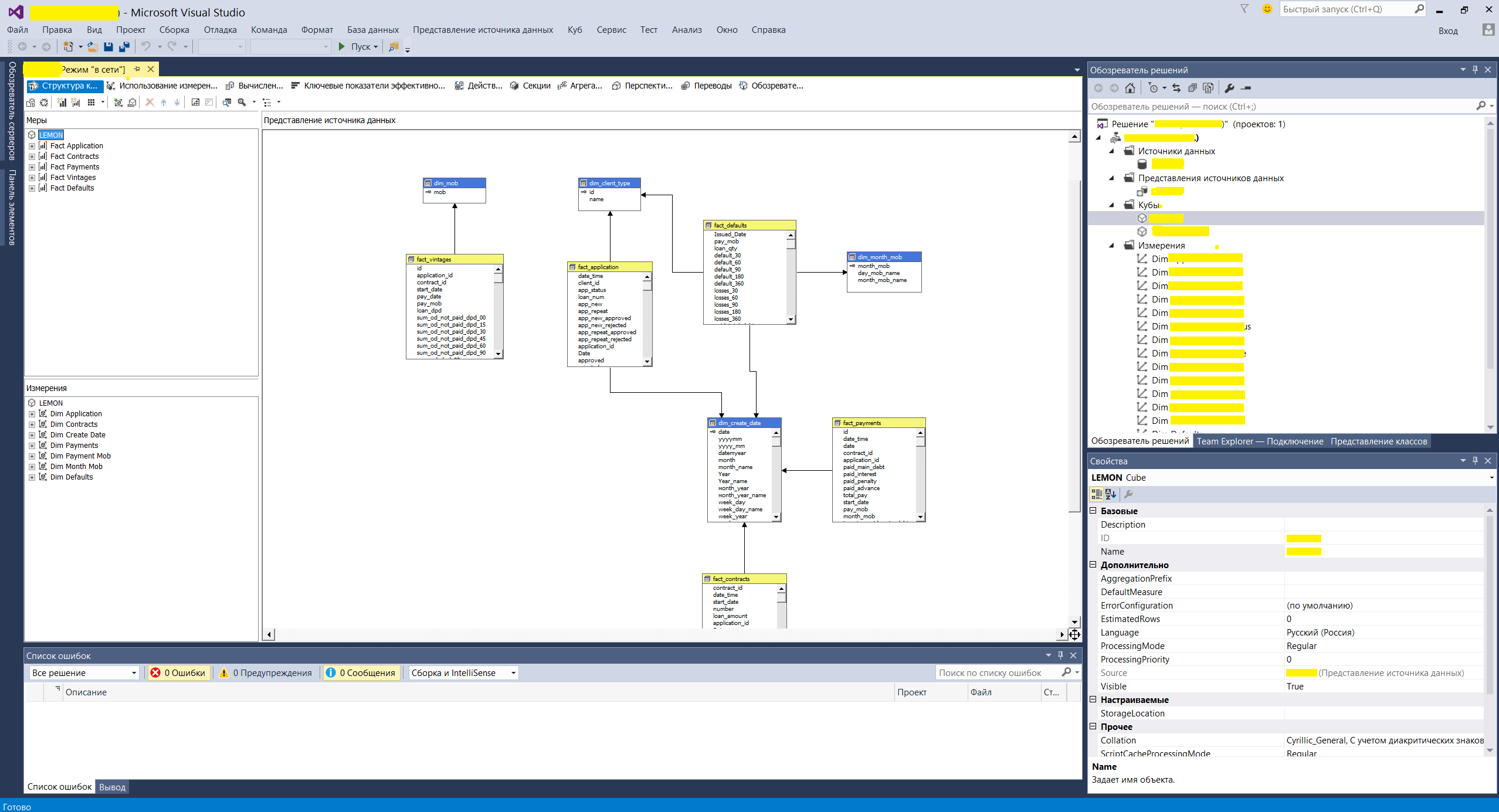
Пример формы создания логической структуры данных OLAP кубов
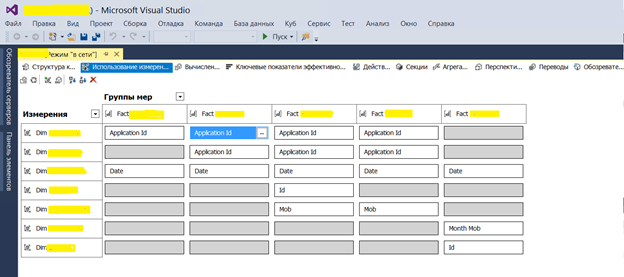
Пример настройки связей для фактовых сущностей в кубах
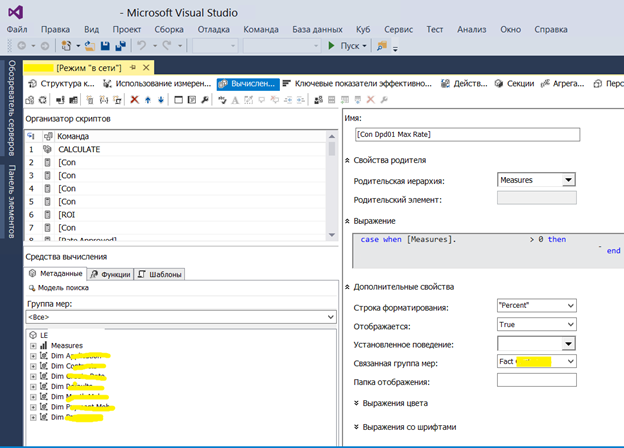
Пример настройки вычисляемых полей в OLAP
Важно заметить, что при построении таких хранилищ и отчетности очень важным моментом является стабилизация отчетности в плане качества данных. Тестирование показателей и устранение расхождений также отнимает большое количество времени и трудозатрат при построении витрин и показателей. Несмотря на тот факт, что вся настройка OLAP выполняется в интерфейсах, сам инструмент является очень простыми и удобным в разработке.
Также очень важно понимать, что кубы OLAP очень удобно использовать на небольших хранилищах не более чем в несколько терабайт. Если речь идет о построении больших хранилищ, например для ритейла, телекоммуникаций или банковской сферы, то объемы данных начинают исчисляться десятками терабайт. Большие объемы требуют полноценные BI-решения с наличием высокопроизводительных серверов. Например, такие продукты как Oracle BI, SAS BI являются полноценными Enterprise решениями стоимость которых начинаются с цифры с нескольким количеством нулей и исчисляется в долларах.
В общем была создана система аналитики на основе OLAP со стартовым набором показателей, которая сильно помогла в принятии дальнейших управленческих решений для развития бизнеса.

Пример сводной таблицы, который подключается к Analysis Service для вращения кубов
В заключение, скажу, что это был только первый этап построения аналитической отчетности. На текущий момент хранилище очень сильно выросло и в объемах, и в количестве источников. Но базис, заложенный в начале, очень сильно помог в развитии дальнейшего бизнеса. А смысл всей истории в том, что не обязательно тратить месяцы на разработку и моделирование архитектуры для построения DWH, как обычно это бывает. При запуске бизнеса или стартапа, можно пожертвовать техническим долгом для быстрого достижения бизнес целей и делать это можно вполне успешно.
Что такое витрина данных? Определение, разновидности и примеры
Что такое хранилище данных? Как правило, это база, в которой хранится вся масса информации по деятельности той или иной компании.
Оглавление

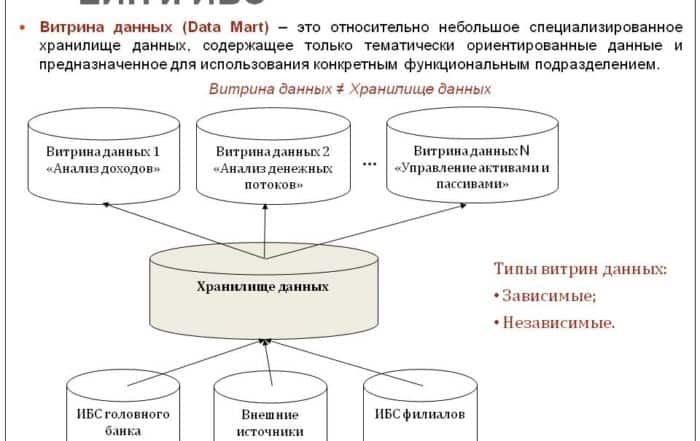
Что такое хранилище данных? Как правило, это база, в которой хранится вся масса информации по деятельности той или иной компании. Но нередко бывает нужным выделить из всего этого масштабного комплекса данные по одному направлению работы организации, подразделению, служебному вопросу. Здесь приходит на помощь иной тип хранилища – так называемые витрины данных. Что это, каковы ее достоинства, недостатки, разновидности, мы с вами будем рассматривать на протяжении статьи.
Что это?
Что такое витрины данных? Английский вариант – Data Mart. Существует несколько синонимов понятия:
Определимся с трактовкой термина “витрина данных”:
Дать объявление в витрину данных не получится. Она является одним из типов хранения внутренней информации организации, а не предоставления сведений широкому кругу пользователей.

Концепция хранилища
Идея создания витрин данных была предложена в 1991 году Forrester Research. Авторы представляли данное хранилище информации как определенное множество специфических баз данных, которые содержат в себе сведения, относящиеся к конкретным векторам деятельности корпорации.
Forrester Research выделяли следующие сильные стороны своего проекта – витрин данных:
Но те же Forrester Research говорили и о слабых сторонах своего изобретения:
Перейдем теперь к новой теме.

Конструирование витрин
Главный пример витрин данных – это тематические подмножества заранее агрегированной информации. Соответственно, такие БД гораздо легче проектировать и настраивать. Создают подобные витрины для поиска конкретных ответов на запросы пользователя. Данные в них адаптируются создателем под определенные группы сотрудников. Подобная оптимизация облегчает процедуру наполнения витрин, способствует повышению производительности подобных БД.
Известно, что конструирование комплексных хранилищ данных – довольно сложный процесс, который может растянуться даже на несколько лет. А вот витрины данных, конкретизированные по отдельным структурам предприятия, фирмы, создавать проще и быстрее. Надо сказать, что несколько витрин могут успешно сосуществовать и с основным хранилищем информации, давая о нем частичное представление.
Как мы упоминали, проектирование витрин данных – технологически облегченный процесс. Но создателям ВД нужно помнить о том, что при построении впоследствии могут возникнуть проблемы с интеграцией информации (в случае, если проектирование производилось без учета комплексной бизнес-модели).

Независимые витрины: примеры
Витрина данных SQL – аналитическая структура, поддерживающая работу одного из приложений, подразделения, бизнес-раздела. Его сотрудники обобщают свои требования к информации, приспосабливают витрину к собственным служебным нуждам. Далее проходит обеспечение персонала, контактирующего с этими данными, определенными средствами интерактивной отчетности.
Независимые витрины данных исторически складываются в крупных организациях, которые имеют большое число самостоятельных подразделений с собственными отделами информационных технологий. Примеры их можно выделить следующие:
Достоинства независимых витрин
Давайте выделим ключевые преимущества витрин данных, которые найдены непосредственными создателями и пользователями:
Недостатки независимых витрин
Давайте определимся с минусами витрин данных, которые выделяют пользователи и проектировщики:

Смешанная концепция
А что будет, если соединить между собой концепции витрин данных и хранилища данных? Таким вопросом задался в 1994 году М. Демарест. Именно он предложил объединить вышеуказанные концепции для дальнейшего использования хранилища (базы) данных в качестве интегрированного единого источника при проектировании витрин данных.
Данное решение объединяет в себе три уровня:
Данная многомерная структура со временем станет стандартной во многих компаниях. Главная причина того – объединение в ней достоинств двух подходов:



