Data Fabric (ткань данных)
Понятие Data Fabric и основные элементы этой концепции
Введение в понятие Data Fabric для TAdviser подготовила Светлана Вронская, автор телеграм-канала Analytics Now.
Data Fabric, которую почему-то часто неправильно переводят как «фабрику данных», никакого отношения к заводу не имеет. Data Fabric – это ткань данных, и представляет она собой цельную архитектуру управления информацией с полным и гибким доступом для работы с ней.
Это автономная экосистема, которая используется для максимально эффективного доступа к корпоративным данным. При помощи Data Fabric информацию легче искать, обрабатывать, структурировать и интегрировать с другими информационными системами.
Архитектура Data Fabric работает в концепции DataOps. Быстро организуется реагирование на любые изменения в данных, повышается уровень прогнозирования, оптимизируются процессы хранения, обработки и обслуживания ресурсов.
Отличительная характеристика Data Fabric – это активное применение технологий Больших данных и искусственного интеллекта, в частности, машинного обучения для построения и оптимизации алгоритмов управления и практического использования данных. Кроме того, концепция Data Fabric дополнена семантическими графами, которые позволяют определять, стандартизировать и согласовывать значение всех входящих данных в бизнес-терминах, понятных для конечных пользователей.
Говоря просто, ткань данных – это система на уровне всей вашей организации, где всё подчиненно данным и выводам на их основе.
Data fabric что это
Сегодня мы рассмотрим, что такое Data Fabric, почему этот тренд в аналитике больших данных (Big Data) считается одним из самых перспективных в 2020 году, зачем нужна фабрика данных и как она устроена. Читайте в нашей статье, чем Data Fabric отличается от Data Factory, причем тут цифровизация, DataOps и конвейеры по обработке информации.
Что такое Data Fabric
Аналитическое агентство Gartner внесла фабрики данных в ТОП-10 главных трендов 2020 года в области Data Analytics. При этом под фабрикой данных компания подразумевает целую экосистему, которая объединяет повторно используемые сервисы производства данных, конвейеры передачи и обработки информации (data pipelines), а также API-интерфейсы и другие подходов к интеграции данных между различными системами и хранилищами информации для организации беспроблемного доступа и обмен данными в распределенной среде [1].
Отметим различия терминов Data Fabric и Data Factory. Data Factory или фабрика данных от Microsoft Azure — это полностью управляемая облачная ETL-служба с интеграцией данных, которая автоматизирует их перемещение и преобразование, собирая необработанную информацию и трансформируя ее в готовые к использованию сведения с помощью специальных сервисов [2].
В свою очередь, согласно Gartner, Data Fabric – это единая и согласованная архитектура управления данными, которая обеспечивает беспрепятственный доступ к данным и их обработку [3].
Отличительная характеристика современных фабрик данных – это активное применение технологий Big Data и искусственного интеллекта (ИИ), в частности, машинного обучения (Machine Learning) для построения и оптимизации алгоритмов управления и практического использования данных. Таким образом, здесь и далее под Data Fabric мы будем понимать именно технологическую экосистему для эффективного использования корпоративной информации, а не конкретную облачную платформу от Microsoft Azure и не офисный «завод» по ручной разметке данных для ИИ, которые сегодня массово появляются в Китае [4].
Почему современным предприятиям нужны фабрики данных
Концепция Data Fabric возникла благодаря активному использованию больших данных в условиях типовых ограничений традиционных процессов управления информацией. В частности, корпоративные Data Lakes на базе Apache Hadoop отлично справляются с хранением множества разрозненных и разноформатных данных. Но эту информацию не просто искать, анализировать и интегрировать с другими датасетами. Это усложняет аналитику больших данных, снижая ценность информации. В свою очередь, интерактивная аналитика и когнитивные вычисления, в т.ч. с помощью методов Machine Learning, требуют высокой скорости доступа к информации, хранящейся в Data Lake. Таким образом, можно сказать, что основными драйверами развития концепции Data Fabric стали потребности в быстрой аналитике Big Data и необходимость распространения BI-подхода на все информационные активы предприятия [5].
Кроме того, для организации, управляемой данными (data-driven) особенно актуальны вопросы обеспечения информационной безопасности. В этом контексте Data Fabric будет обеспечивать защиту данных, реализуя согласованное управление с помощью унифицированных API и настраиваемого доступа к ресурсам. Также фабрика данных направлена на поддержку гибкости в прозрачных процессах обновления, аудита, интеграции, маршрутизации и трансформации данных для конкретных бизнес-целей [6].
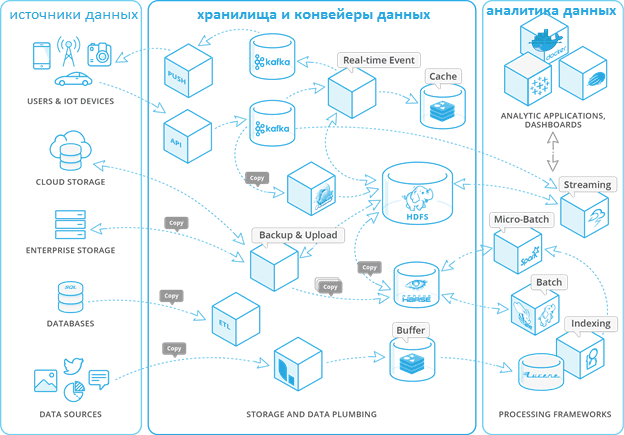 Компоненты фабрики данных
Компоненты фабрики данных
Фабрика данных: цифровизация процессов DataOps
Отметим следующие ключевые характеристики фабрики данных [6]:
Таким образом, можно сделать вывод, что фабрика данных является средством реализации процессов современной концепции DataOps, обеспечивая оперативное реагирование на события, высокий уровень прогнозируемости, оптимизации обработки и обслуживания ресурсов [7]. В свою очередь, DataOps можно рассматривать как один из инструментов цифровизации бизнеса для перевода предприятия в режим data-driven.
Как устроены фабрики данных: Big Data и не только
На текущий момент фабрика данных – это тренд в области Big Data и корпоративного ИТ-сектора, а не готовые технологические решения. На практике сегодня для сквозной интеграции и ETL/ELT-процессов используется вся мощь технологий Big Data: Apache Kafka, Spark, Hadoop, Hive, NiFi, AirFlow и прочие средства для сбора, обработки, маршрутизации и преобразования пакетных и потоковых данных в различных форматах.
Помимо упомянутых и других инструментов Big Data, а также базовых положений DataOps, концепция Data Fabric еще дополнена семантическими графами, которые позволяют определять, стандартизировать и согласовывать значение всех входящих данных в бизнес-терминах, понятных для конечных пользователей [5]. Примечательно, что графовую аналитику Gartner также относит к наиболее перспективным трендам 2020 года [1].
Наконец, фабрика данных по максимуму использует весь потенциал облачных технологий, виртуализируя все компоненты ИТ-инфраструктуры, от наборов информации до программных приложений [8]. Подобная сервисная модель соответствует DevOps-подходу, а потому инструменты контейнеризации (Docker, Kubernetes) также относятся к средствам Data Fabric.
Таким образом, для развертывания уникальной фабрики данных, а также создания непрерывных конвейеров автоматического сбора и обработки информационных пакетов и потоков необходимы совместные усилия всех профильных ИТ-специалистов по большим данным. Потребуется целая команда администраторов Data Lakes, локальных и облачных кластеров, разработчиков распределенных приложений, инженеров и аналитиков данных, а также специалистов по методам Machine Learning.
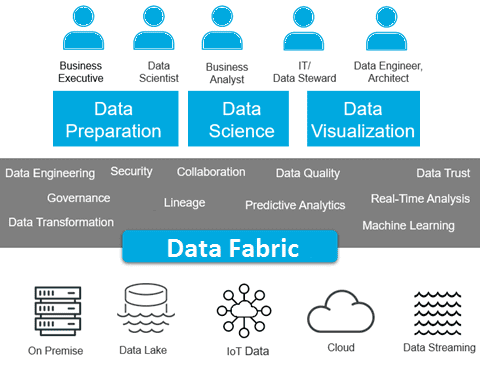 Пользователи и ключевые черты фабрики больших данных
Пользователи и ключевые черты фабрики больших данных
Подробнее о том, как организовать собственную Data Fabric для цифровизации своих бизнес-процессов и аналитики больших данных, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Метаморфоза NetApp: как ведущий поставщик систем хранения превратился в поставщика облачных технологий
На ежегодной конференции NetApp Insight и последовавшей за ней Cloud Field Day 9 (CFD) компания NetApp представила новые продукты и рассказала о стратегии компании на будущее. Кроме прочего, NetApp анонсировала множество новых проектов, связанных с мультиоблачными решениями.

Полноценный переход к Data Fabric
Когда-то компания специализировалась только на решениях, в основе которых была ONTAP — собственная операционная система компании для хранилищ данных, таких как NetApp FAS и AFF. Однако несмотря на то, что система действительно хорошо работает, ее невозможно применить ко всем новым продуктам NetApp. Это мешало развитию новых решений.
В 2019 году NetApp рассказала об изменениях в стратегии развития и выпуске новых продуктов на основе Data Fabric («фабрика данных») — это единый комплекс из технических и программных компонентов, который помогает организациям управлять данными в гибридных и мультиоблаках, объединять локальную и облачную инфраструктуру. Такие решения упрощают управление большими массивами данных и интеграцию облачных технологий для заказчиков.
Это было стало большим шагом вперед для компании. NetApp начала разрабатывать такие продукты, как объектное хранилище StorageGrid, купила компанию Solidfire, интегрировала различные семейства продуктов, чтобы все работало вместе, и добавила дополнительные инструменты, чтобы упростить жизнь своим клиентам. В конце концов, ONTAP перестала быть единственным ответом на все вопросы, и компания стала двигаться вперед.
Облако, построенное на основе Data Fabric
Концепция Data Fabric и год назад включала облако, но в некоторых аспектах она была неполной. Data Fabric была разработана еще до успеха Kubernetes, а о мультиоблаке и речи не шло.
После Insight и CFD, обновление стратегии кажется завершено. Можно сказать, что NetApp сегодня является одним из наиболее развитых провайдеров на рынке гибридных технологий. Проекты Astra или даже новый VDS (Virtual Desktop Service) используют в основе Data Fabric.
NetApp больше нельзя назвать простым поставщиком хранилищ, по крайней мере, не в традиционном смысле. Компания диверсифицируется и становится серьезным игроком на рынке облачных вычислений. Также интересно, что компания делает это таким образом, чтобы не конкурировать с известными поставщиками облачных услуг или их партнерами.
Фактически, NetApp позиционирует семейство своих продуктов как основу для беспрепятственного перемещения данных из локальной среды в облако, а затем — управления ими с единым пользовательским интерфейсом, независимо от используемых облачных платформ. То есть NetApp предоставляет разнообразные возможности для работы с данными в облаках, расширяя для пользователей свободу выбора.
Компания создает набор интересных решений на основе надежных и согласованных методов управления данными. С определенной точки зрения эта стратегия похожа на стратегию VMware: их стек теперь доступен во всех облаках, а на его основе построены дополнительные решения (например, Disaster-Recovery-as-a-Service или «послеаварийное восстановление как услуга», появившийся в результате приобретения Datrium).
Что в итоге
Можно ли по-прежнему классифицировать NetApp как традиционного поставщика систем хранения? Определенно доходы от продажи систем хранения данных по-прежнему составляют львиную долю их доходов (так что они все еще «традиционные» в этом плане), но изменение стратегии здесь весьма заметно, и доходы от облачных вычислений становятся все более внушительными.
Большинство предприятий меняют свое представление об ИТ-инфраструктуре. Гибридные и мультиоблачные решения теперь стали нормой. Пользователи хотят быстро и просто запускать свои приложения там, где этого требует бизнес. Быть просто поставщиком хранилищ уже недостаточно.
Важно отметить, что с этой точки зрения NetApp не одинока (мы уже упоминали VMware). Аналогичной стратегии придерживаются и у других компании, такие как RedHat. Все они хотят создать единый пользовательский интерфейс независимо от того, где клиент развертывает свой бизнес (и данные).
Прогноз
Сможет ли NetApp снова измениться? Будет ли это надежный поставщик облачных услуг и станет ли компания настоящим поставщиком гибридных облачных хранилищ? Компания хорошо справилась с переходом на Data Fabric и находится на правильном пути, чтобы повторить успех. Сравнивая NetApp с некоторыми другими традиционными поставщиками систем хранения, у них действительно хорошие возможности расширить список услуг и закрепится на рынке облачных технологий.
Список Gartner: какие технологии помогут бизнесу в 2022 году
Каждый год Gartner находит технологические тенденции, которые повлияют на бизнес в ближайшие несколько лет. На 2022 год этот список включает 12 стратегических тенденций. Мы перевели и адаптировали пресс-релиз и статью Gartner с разбором наиболее важных технологий и собрали мнения экспертов о том, какие у этих технологий перспективы в России.
1. Фабрика данных (Data Fabric)
За последнее десятилетие выросло количество разрозненных хранилищ данных и приложений. При этом квалифицированных работников в командах, работающих с данными, больше не стало. Решением проблемы становятся фабрики данных — сервисы, которые облегчают обмен данными между платформами и бизнес-пользователями. Их плюсы:
данные становятся доступны в любой точке независимо от места их хранения,
фабрики данных позволяют создать масштабируемую архитектуру,
встроенная аналитика даёт больше возможностей использование данных
сокращается срок окупаемости новых технологий.

Игорь Полянский
Руководитель направления работы с данными в Vivid Money
Любая компания в 2021 поддерживается зоопарком систем: ERP, CRM, HRIS. Каждая из них представлена разными вендорами. Рынок вендоров сегментирован, так как они конкурируют в узкой нише, чтобы поставить максимально качественное решение. Источники и форматы данных сильно отличаются и с трудом совмещаются друг с другом. В итоге хранение и управление данными становятся сложными инженерными задачами.
Фабрика данных упрощает этот процесс и снижает трудозатраты на интеграцию данных. Это важно, потому что специалистов на рынке аналитики, data science и data engineering не хватает. Компании стремятся использовать сотрудников эффективно, сокращая затраты их времени на инженерные процессы.
Отдельный вызов — постоянное увеличение объёма данных. Неправильно спроектированная инфраструктура может остановить бизнес-процесс из-за невозможности дальнейшего масштабирования. Методы проектирования фабрики данных помогают избежать таких ошибок. В России это актуально в первую очередь для IT-сектора. Но в последние несколько лет тот же тренд пришёл в ритейл и тяжёлую промышленность, где многие компании проходят через цифровую трансформацию и начинают решать те же самые задачи, которые IT уже решили 5–10 лет назад.
2. Сеть кибербезопасности (Cybersecurity Mesh)
Сотрудники компаний могут находиться где угодно, а не только в офисе или на производстве — традиционный периметр безопасности исчез. Для безопасности нужна гибкая, компонуемая архитектура, которая объединяет распределённые службы. Сеть кибербезопасности помогает создать интегрированную структуру безопасности и защитить все активы независимо от их местонахождения.
К 2024 году организации, которые внедрят в работу сети кибербезопасности, снизят финансовые потери от нарушений безопасности на 90%.

Нияз Кашапов
Специалист по безопасности приложений в Сбермаркете
Понятие Cybersecurity Mesh введено Gartner. Точного описания или определения этой технологической тенденции нет. Как нет и готовых фреймворков. Gartner выдвинул концепцию без уточнения мер и конкретных технологий. Концепция, конечно же, небезосновательная.
В сфере ИБ есть тенденция к децентрализации безопасности и переносу мер защиты с внешней границы IТ-решений на конечного пользователя. С приходом локдаунов, появлением огромного количества удалённых сотрудников, переноса разработки из офиса в дома многие риски ИБ стали ближе к пользователям систем. Обычный фаервол не защитит от утечки данных с компьютера сотрудника. Да и популярность облачных решений не позволяет контролировать безопасность железа.
Появляется концепция безопасности Zero Trust, когда отсутствует полное доверие кому-либо, даже внутренним пользователям.
Cybersecurity Mesh как раз и является частью концепции Zero Trust. Это набор децентрализованных решений, помогающих организовать защиту конечных пользователей, их компьютеров, а также всех активов во внутренней сети: приложений, баз данных и даже каналов связи.
Разделение доступов, внедрение дополнительных способов аутентификации, контроль устройства, анализ поведения и другие технологии помогут повысить общий уровень безопасности, предотвратить большую часть взломов и утечек информации. Также стоит отметить акцент на децентрализацию — создание решений, помогающих избежать точек отказа, проверять подлинность данных без необходимости постоянной связи. Сюда же относятся комплексные решения с использованием блокчейна.
3. Вычисления, усиливающие защиту конфиденциальности данных (Privacy-Enhancing Computation)
Такие вычисления обеспечивают безопасность обработки персональных данных в ненадёжных средах. Эта тенденция появилась из-за развития законов о конфиденциальности и защите данных, а также растущих опасений потребителей.
Согласно ожиданиям Gartner, к 2025 году 60% крупных организаций станут использовать методы PEC.

Игорь Полянский
Руководитель направления работы с данными в Vivid Money
Хранение личных данных пользователей — необходимая и зачастую очень выгодная для бизнеса мера, но в то же время несущая риски. Утечки персональных данных грозят компаниям как репутационными, так и финансовыми потерями. В Европе и Америке государства давно осознали необходимость регулирования этого вопроса, поэтому компании поставлены в жёсткие рамки. Российский регулятор пока ещё отстаёт от наших западных коллег, давая значительную свободу компаниям, что часто приводит к неприятным последствиям.
Скорость изменения законов связана и с низкой цифровой грамотностью населения, которая не стимулирует регулятор на более активные действия. Исключения —банковский сектор и финтех, где регулирование более жёсткое, а технологии защиты данных более распространены.
Отличия законов можно увидеть в тех случаях, когда российский стартап выходит на европейский рынок. Таким компаниям необходимо пройти GDPR-аудит. Им приходится менять как инфраструктуру данных, так и подходы к их обработке и использованию.
4. Облачные платформы (Cloud-Native Platforms)
Приложения, которые изначально создают для работы в облачных инфраструктурах, позволяют разрабатывать новые отказоустойчивые, эластичные и гибкие архитектуры. В отличие от платформ, стандартный lift-and-shift подход к облаку не позволяет использовать все преимущества облака и усложняет обслуживание.

Алексей Кузьмин
Директор разработки в Домклик
В основе облачных технологий лежит гибкое использование ресурсов, когда выделение инфраструктуры под проект происходит динамично, в зависимости от его реальных потребностей, и перенос поддержки платформенных технологий с плеч компании на плечи облачных провайдеров. Это позволяет создавать IТ-решения быстрее, надёжнее и дешевле, чем при традиционном подходе.

Александр Толмачёв
Консультант по анализу данных и математическому моделированию
В последний год активно используют термины: Cloud First, Cloud Only. Для многих компаний это уже стандарт построения инфраструктуры. Использование облачной инфраструктуры снижает стоимость сопровождения и time-to-market.
Топ-3 провайдеров из года в год:
Amazon Web Services (30% рынка)
Microsoft Azure (20% рынка)
У каждого провайдера есть свои плюсы и минусы, главное — понимать возможности облачных сервисов. Компании, использующие в работе персональные данные российских граждан, не имеют права хранить их вне серверов РФ. Из-за ряда других юридических ограничений компании, для которых основной рынок — Россия, используют self hosted решения.
5. Составные приложения (Composable Applications)
Составные приложения строятся из модульных компонентов, ориентированных на бизнес. Это упрощает использование и повторное применение кода и ускоряет вывод на рынок новых программных решений. Это актуально во время кризисов и быстрого развития технологий.

Никита Харичкин
Руководитель отдела системной аналитики в SberDevices, спикер на профильных конференциях и на курсах по системному анализу и дизайну
Одним из гибких подходов к формированию составного приложения является разработка единой платформы — унифицированного SDK, потенциально совместимого со всей линейкой продуктов компании.
Развитие отдельной платформы как продукта интересно большим компаниям и экосистемам с разветвлённой сетью цифровых продуктов. Если вы владелец заводов, газет, пароходов, то вам невыгодно параллельно создавать и поддерживать одни и те же функции для своих предприятий. Например, конвейер. Гораздо проще однажды его изобрести и тиражировать по своим предприятиям, а там настраивать под нужды конкретного производства.
Такой же принцип и у SDK: его можно встраивать в клиентские приложения и использовать для прошивок физических устройств (конференц-телефонов, телеприставок, устройств умного дома). Уже не нужно в каждой дочерней компании строить с нуля, например, систему телеконференц-связи.
К ключевым принципам построения такой платформы можно отнести следующее:
независимо развивающийся модуль, поставляющий конечную ценность потребителю,
гарантия единого пользовательского опыта на всех устройствах,
расширяемость и модульность решения.
При этом не стоит воспринимать SDK как очередную интеграцию. Будучи автономной частью родительского приложения, SDK гораздо проще в сопровождении и масштабируемости за счёт следующего:
возможности гибкого управления — переключения функций и изменения конфигураций,
единого SDK-механизма сбора метрик, однозначно интерпретируемого среди всех инсталляций,
развития собственного API.
Уверен, что в конкурентной борьбе крупнейших корпораций спрос на такой подход будет только расти.
6. Интеллект для принятия решений (Decision Intelligence)
Это практический подход к принятию решений. Каждое решение рассматривается как набор процессов, при которых используются данные для анализа, получения обратной связи и корректировки действий. При таком подходе процесс принятия решений может даже автоматизироваться за счёт искусственного интеллекта.
Gartner прогнозирует, что в ближайшие два года треть крупных организаций будет использовать ИИ для принятия решений ради конкурентных преимуществ.

Артур Сапрыкин
Data Scientist, предприниматель, исследователь ML/DL, автор и спикер курсов по машинному обучению
Передовые компании уже внедряют такой подход. Это сокращает время на принятие управленческих решений и улучшает их качество. Особенно это полезно в таких областях, где время имеет высокую значимость: медицина, вооружённые силы, службы спасения.

Игорь Полянский
Руководитель направления работы с данными в Vivid Money
Подход к интеллектуальному принятию решений на основе данных стал массовым недавно, 5–10 лет назад, когда компании получили возможность относительно дёшево хранить большие данные. Рынку понадобилось время, чтобы принять тот факт, что машина в некотором классе задач принимает решение значительно эффективнее человека. И этот класс постоянно расширяется, что приводит к изменению и даже исчезновению конкретных ролей в бизнесе.
Для большинства случаев человеческая оценка, которая комбинируется с выводами на основе данных, может повысить качество решений. Решения на основе машинного обучения и ИИ шире всего представлены в IT и банковском секторе. Российские компании не отстают, а во многом даже опережают западных коллег. Это обусловлено большим количеством относительно дешёвых специалистов с хорошим фундаментальным образованием. Многие решения и алгоритмы из России активно используются за рубежом. Главные двигатели этой сферы — ритейл и тяжёлая промышленность, где спрос на специалистов из data science растёт быстрее всего.
7. Гиперавтоматизация (Hyperautomation)
Это упорядоченный ориентированный на бизнес подход, который позволяет быстро определить, проверить и автоматизировать как можно больше процессов. Гиперавтоматизация создаёт возможности для масштабирования, удалённой работы и полной перестройки бизнес-модели.
Гиперавтоматизация стоит на трёх китах:
повышение качества работы,
гибкость принятия решений.

Игорь Полянский
Руководитель направления работы с данными в Vivid Money
Гиперавтоматизация как способ повышения рентабельности набирает обороты. В IT скорость масштабирования — один из ключевых показателей эффективности бизнеса. Человеческий фактор играет роль не только в принятии решений, но и в выполнении задач. Увеличить мощность сервера быстрее, чем нанять дополнительного сотрудника.
Компании необходимо поддерживать целый слой процессов: наём, удержание людей, административные вопросы. Когда компании удаётся заменить человека автоматикой, весь этот слой процессов исчезает. Освобождаются ресурсы компании, ускоряется масштабирование.
Автоматизация растёт во всём мире, но российские компании всё ещё отстают в части административных и операционных процессов вроде документооборота. Обратная ситуация с цифровыми процессами, такими как управление маркетингом или создание IT-продуктов.
8. Разработка искусственного интеллекта (AI Engineering)
Комплексный подход к проектированию автоматизирует обновление данных, моделей и приложений для оптимизации доставки ИИ. Это нужно, чтобы не тратить время и средства на ИИ-проекты, которые никогда не запустятся.
К 2025 году 10% предприятий, которые внедрят передовые методы проектирования ИИ, получат как минимум в три раза больше прибыли, чем конкуренты.

Игорь Полянский
Руководитель направления работы с данными в Vivid Money
Почему-то принято считать, что основные усилия во внедрении ИИ сосредоточены на этапе построения моделей машинного обучения. «Если мы создали модель, которая принимает решения лучше человека, то 99% работы уже сделано». Возможно, такое мнение сформировалось на фоне высоких зарплат в сфере data science.
В реальности дела обстоят по-другому, и есть ещё другие этапы, без которых внедрение ИИ невозможно.
До построения модели необходимо собрать качественные данные. Это трудно реализовать без правильного подхода к проектированию хранилищ и аналитических слоёв данных. После построения модели необходимо внедрить её в текущие процессы, то есть вписать модель в техническую инфраструктуру компании. При неправильном подходе модель может негативно повлиять на конечный результат или даже сломать продукт.
Любые модели устаревают. Без налаженного мониторинга качества в определённый момент результаты такой автоматизации могут стать негативными.
Именно поэтому проектирование процессов по внедрению ИИ должно быть комплексным и включать работу экспертов. В российских компаниях, которые давно используют ИИ-решения, уже накопилось достаточно понимания, как правильно выстраивать ML-проект. Это привело к рождению интересных стартапов, многие из которых вышли за рубеж.
Если говорить про широкий рынок, то понимание ИИ всё ещё недостаточно.
Многие компании смотрят на это со скепсисом, или, наоборот, как на панацею, которая решит все их проблемы. Но тренды говорят, что ситуация стремительно меняется, и в ближайшие 5–10 лет компании без ИИ-технологий будут сильно проигрывать конкурентам.

Александр Толмачёв
Консультант по анализу данных и математическому моделированию.
Бизнес-модели с ИИ делятся на два больших типа:
Старые бизнесы, где ИИ применяется как добавочная стоимость — оптимизирует процессы, улучшает определённые показатели. Это улучшение не фундаментальное, но заметное.
AI based companies — компании, которые ставят в основу интеллектуальные алгоритмы анализа данных как ядро бизнеса. Часто это компании с доменом *.ai.
Есть базовое утверждение — с ИИ будет лучше, чем без него. При этом множество бизнес-задач решается классическими алгоритмами, которые не требовательны к инфраструктурным изменениям и потоковой обработке данных. Поэтому существует много неудачных кейсов внедрения ИИ в бизнесе. Есть конкретные рекомендации для запуска ИИ в компаниях:
всегда в начале использовать baseline без ИИ для сравнения эффективности прироста в показателях,
изучить методологии работы с анализом данных в предприятиях Lean DS и CRISPR.

Артур Сапрыкин
Data Scientist, предприниматель, исследователь ML/DL, автор и спикер курсов по машинному обучению
ИИ-решения будут представлены в виде блоков реализаций небольших задач. Каждый блок связан с другой задачей в виде графа решений, где ответ модели на одном блоке будет составляющей для принятия решения на следующем. Это напоминает то, как люди мыслят. Совершенствуясь в чём-то одном, не нужно будет переучиваться полностью. Такой подход упростит внедрение новых технологий машинного обучения в комплексные решения, и небольшим компаниям не понадобится набирать огромный массив данных, чтобы решать локальные задачи.
9. Распределённые предприятия (Distributed Enterprises)
С развитием удалённых и гибридных схем работы офисы уступают место распределённым предприятиям, сотрудники которых территориально рассредоточены.
Бизнес-модель таких предприятий ориентирована на цифровые технологии и удалённую работу, чтобы улучшить взаимодействие с сотрудниками, партнёрами и потребителями.

Александр Толмачёв
Консультант по анализу данных и математическому моделированию
Удалённый формат работы стал нормой. Сейчас практически не встретишь IT-компанию с обязательным требованием работы из офиса — ещё 2 года назад такое сложно было представить.
Вторая популярная модель работы — гибридная. Сотрудники договариваются 1–2 дня в неделю приходить в офис для брейншторма, ретро, планирования спринтов. В теории это повышает командный дух и уменьшает вероятность того, что сотрудник уйдёт в другую компанию.
Рынок специалистов испытывает дефицит. Работают личные связи, репутация руководителя — и условия. На рынок российских IT зашли зарубежные работодатели с предложениями в долларах и евро не только для разработчиков. Крупные компании, которые могут позволить себе международный формат работы, открывают офисы в Европе, Азии, Америке для привлечения новых специалистов.
10. Совокупный опыт (Total Experience)
Это бизнес-стратегия, которая объединяет опыт сотрудников, клиентский и пользовательский опыт. Всё вместе помогает повысить уровень доверия, удовлетворённости и лояльности клиентов и сотрудников.

Полина Маликова
Руководитель направления Аналитика и Data Science в Нетологии
Жёсткая конкуренция в сфере технологий — как за привлечение талантливых специалистов, так и за привлечение клиентов — уже давно сделала опыт сотрудников и качество обслуживания клиентов приоритетами в этом секторе. Но эти две концепции также традиционно рассматривались как отдельные цели.
В России связь этих концепций как общий опыт (TX) чаще всего поддерживают интуитивно. Главным двигателем этого процесса стал COVID-19. С введением локдауна и ограничений многим компаниям стало жизненно необходимо разрабатывать или улучшать модели распределённой рабочей силы.
Как для сотрудников, так и для клиентов правильные средства коммуникации всегда были ключом к обеспечению оптимального взаимодействия. На внутреннем уровне коммуникационные решения помогают соединить сотрудников в разных географических точках.
С точки зрения клиентов непрерывная многоканальная коммуникация долгое время была важным фактором удовлетворённости и лояльности. Клиенты хотят эффективного и беспрепятственного взаимодействия с брендом. Согласно данным PwC, скорость, удобство, полезное и дружелюбное обслуживание имеют наибольшее значение, и клиенты готовы платить больше — до 16% надбавки — компаниям, которые могут выполнить заказ в срок или быстрее с качественным клиентским сервисом. Между тем, каждый третий покупатель будет искать конкурентов после всего лишь одного неудачного опыта.
11. Автономные системы (Autonomic Systems)
По мере роста предприятий традиционное программирование или простая автоматизация не смогут обеспечить масштабирование.
Автономные системы — это самоуправляемые физические или программные системы, которые учатся на своём окружении и динамически изменяют собственные алгоритмы в режиме реального времени. Они умеют оптимизировать производительность и защищаться от атак без вмешательства человека. В долгосрочной перспективе они станут обычным явлением в роботах, беспилотниках, производственных машинах и умных пространствах.

Артур Сапрыкин
Data Scientist, предприниматель, исследователь ML/DL, автор и спикер курсов по машинному обучению
Автономные системы — это то, что приближает нас к настоящему ИИ. Эти системы очень похожи биологическую среду, уверен, что за ними будущее. Многие задачи решатся даже без «учителя». Системам будет достаточно увидеть данные, и они сами смогут извлекать оттуда паттерны.
12. Генеративный искусственный интеллект (Generative AI)
Один из наиболее заметных и мощных методов ИИ, который выходит на рынок, — это генеративный ИИ. Это метод машинного обучения — нейросети изучают контент или объекты, собирают данные и используют их для создания новых артефактов.
Генеративный ИИ может создавать новые формы контента — например, видео — и ускорять циклы исследований и разработок в самых разных областях, от медицины до маркетинга.
К 2025 году, по прогнозам Gartner, на генеративный ИИ будет приходиться 10% всех производимых данных. Сегодня этот показатель составляет менее 1%.

Михаил Васильковский
Инженер по машинному обучению в Snap
Сейчас значительный интерес представляют задачи условной генерации в разных модальностях: например, сгенерировать картинку или видео по описанию. Если получится хорошо выучить это отображение, такая технология может стать источником вдохновения и полезным инструментом для производителей контента и дизайнеров в будущем. На данный момент одним из самых успешных подходов text-to-image является нейросеть DALL-E от OpenAI. Близость к тексту и разнообразие генерации уже поражают, с нетерпением жду новых работ в этой области.
Как технологические тенденции влияют на цифровой бизнес
Традиционно Gartner считается прекрасным предсказателем трендов, и многие их прогнозы действительно становятся реальностью. Но к любым прогнозам можно относиться критически или даже скептически. Вот что об этом говорит бизнес-архитектор Андрей Макеев.
Андрей Макеев
Бизнес-архитектор в Комус
Существует много различных методик оценки уровни зрелости аналитики в компании, в том числе от компании Gartner. До сих пор многие российские компании, даже крупные, находятся на начальных стадиях, когда полноценно не работает даже старомодная корпоративная аналитика: нет единой версии правды в данных, непонятно откуда брать какую-то информацию, BI системы не используются полноценно.
Это как пирамида потребностей: пока базовые потребности в корпоративной аналитике не закрыты полноценно, задумываться о перспективных технологиях из перечня Gartner может быть рано.



