Работа со сложными JSON-объектами в Swift (Codable)
Написать эту статью меня сподвиг почти случившийся нервный срыв, причиной которого стало мое желание научиться общаться с сторонними API, а конкретно меня интересовал процесс декодирования JSON-объектов! Нервного срыва я, к счастью, избежал. поэтому теперь настало время сделать вклад в сообщество и попробовать опубликовать свою первую статью на Хабре.
Почему вообще возникли проблемы с такой простой задачей?
Cтоит сделать оговорку, что протокол называется синтезированным тогда, когда часть его методов и свойств имеют дефолтную реализацию. Зачем такие протоколы нужны? Чтобы облегчить работу с их подписанием, как минимум уменьшив количество boilerplate-кода.
Еще такие протоколы позволяют работать с композицией, а не наследованием!
Вот теперь поговорим о проблемах:
Во-первых, как и все новое, этот протокол плохо описан в документации Apple. Что я имею в виду под «плохо описан»? Для примеров использования выбраны простые JSON объекты; кратко описаны методы и свойства протокола.
Во-вторых, проблема языкового барьера. На понимание того, как составить поисковой запрос ушло несколько часов. Нервы в это время кончались с молниеносной скоростью.
В-третьих, то что гуглится простыми методами не рассказывает о сложных случаях
Теперь давайте поговорим о конкретном кейсе. Кейс такой: используя API сервиса Flickr, произвести поиск N-фотографий по ключевому слову (ключевое слово: читай поисковой запрос) и вывести их на экран.
Сначала все стандартно: получаем ключ к API, ищем нужный REST-метод в документации к API, смотрим описание аргументов запроса к ресурсу, cоставляем и отправляем GET-запрос.
И тут видим это в качестве полученного от Flickr JSON объекта:
Что имеем? Имеем ситуацию, где необходимо составить два последовательных GET-запроса к разным ресурсам, причем второй запрос будет использовать информацию первого! Соответственно алгоритм действий: запрос-декодирование-запрос-декодирование. И вот тут. и начались проблемы. От JSON-объекта полученного после первого запроса мне были нужен только массив с информацией о фото и то не всей, а только той, которая репрезентует информацию о его положении на сервере. Эту информацию предоставляют поля объекта «photo»: «id», «owner», «server»
То есть мы хотим, чтобы итог запроса был декодирован и помещен в похожую на эту структуру данных:
Вся остальная «мишура» нам не нужна. Так вот материала, описывающего best practices обработки такого JSON-объекта очень мало.
Давайте разбираться. Сначала предположим, что никакой лишней информации нам не пришло. Таким образом я хочу ввести в курс дела тех, кто не работал с Codable. Представим, что наш объект выглядит вот так.
Здесь все предельно просто. Нужно создать структуру данных, имена свойств которой будут совпадать с ключами JSON-объекта (здесь это «id», «secret», «server»); типы свойств нашей структуры также обязаны удовлетворять типам, которым равны значения ключей (надеюсь, не запутал). Далее нужно просто подписаться на протокол Decodable, который сделает все за нас, потому что он умеет работать с вложенными типами (то есть если типы свойств являются его подписчиками, то и сам объект тоже будет по умолчанию на нее подписан). Что значит подписан? Это значит, что все методы смогут определиться со своей реализацией «по умолчанию». Далее процесс парсинга целиком. (Я декодирую из строки, которую предварительно перевожу в объект типа Data, потому что метод decode(. ) объекта JSONDecoder работает с Data).
Полезные советы:
Вернемся к мучениям. Парсинг:
Обратите внимание на то, что любой ключ JSON-объекта, использующий следующую нотацию «key» : «sometexthere» для Decodable определяется как String, поэтому такой код создаст ошибку в run-time. Decodable не умеет явно coerce-ить (приводить типы).
Усложним задачу. А что если нам пришел такой объект?
Разберем дополнительный функционал доступный из коробки. Следующий вид JSON-объекта:
Теперь разберем последний, обсуждаемый везде функционал, который пригодится в дальнейшем.
Сначала залезем немного «под капот» Decodable и еще раз поймем, что такое JSON.
Decodable может перемещаться по этим контейнерам и забирать оттуда только необходимую нам информацию.
Сначала поймем, каким инструментарием необходимо пользоваться. Протокол Decodable определяет generic enum CodingKeys, который сообщает парсеру (декодеру) то, как именно необходимо соотносить ключ JSON объекта с названием свойства нашей структуры данных, то есть это перечисление является ключевым для декодера объектом, с помощью него он понимает, в какое именно свойство клиентской структуры присваивать следующее значение ключа! Для чего может быть полезна перегрузка этого перечисления в топорных условиях, я думаю всем ясно. Например, для того, чтобы соблюсти стиль кодирования при парсинге: JSON-объект использует snake case для имен ключей, а Swift поощряет camel case. Как это работает?
rawValue перечисления CodingKeys говорят, как выглядят имена наших свойств в JSON-документе!
Отсюда мы и начнем наше путешествие внутрь контейнера! Еще раз посмотрим на JSON который нужно было изначально декодировать!
Первый контейнер определяет объект, состоящий из двух свойств: «photos», «stat»
Контейнер «photos» в свою очередь определяет объект состоящий из пяти свойств: «page», «pages», «perpages», «total», «photo»
Как можно решать задачу в лоб?
Объявить кучу вложенных типов и радоваться жизни. Итог: пишем dummy алгоритмы для маппинга между клиентскими объектами. Об этом случае в послесловии!
Пользоваться функционалом Decodable протокола, а точнее его перегружать дефолтную реализацию инициализатора и переопределять CodingKeys! Это хорошо! Оговорка: к сожалению Swift (по понятным причинам!) не дает определять в extension stored properties, а computed properties не видны Сodable/Encodable/Decodable, поэтому красиво работать с чистыми JSON массивами не получится.
Решая вторым способом, мы прокладываем для декодера маршрут к тем данным, которые нам нужны: говорим ему зайди в контейнера photos и забери массив из свойства photo c выбранными нами свойствами
Сразу приведу код этого решения и уже потом объясню, как он работает!
Common Data Service и Power Apps. Создание мобильного приложения
Всем привет! Сегодня попробуем автоматизировать процесс создания поручений с использованием платформы данных Microsoft Common Data Service и сервисов Power Apps и Power Automate. На базе Common Data Service построим сущности и атрибуты, при помощи Power Apps сделаем несложное мобильное приложение, ну а Power Automate поможет связать все компоненты единой логикой. Не будем терять времени!
Но для начала немного терминологии. Что из себя представляет Power Apps и Power Automate мы уже знаем, но, если вдруг кто не в курсе, рекомендую ознакомиться с моими предыдущими статьями, например, вот тут или тут. Однако, что из себя представляет Common Data Service мы еще не разбирали, поэтому самое время добавить немного теории.

Common Data Service (сокращенно CDS) это платформа хранения данных вроде базы данных. Собственно, это и есть база данных, расположенная в облаке Microsoft 365 и имеющая тесную связь со всеми сервисами Microsoft Power Platform. Также CDS доступна через Microsoft Azure и Microsoft Dynamics 365. Данные в CDS могут попадать различными способами, один из способов, например, создание записей в CDS вручную, по аналогии с SharePoint. Все данные в Common Data Service хранятся в виде таблиц, называемых сущностями. Есть ряд базовых сущностей, которые можно использовать для своих целей, но можно также создавать и свои собственные сущности со своими наборами атрибутов. Аналогично SharePoint, в Common Data Service при создании атрибута можно указать его тип и типов здесь огромное количество. Одной из интересных особенностей является возможность создавать так называемые «Наборы параметров» (аналог вариантов для поля типа Выбор в SharePoint), которые можно переиспользовать в любом поле сущности. Плюс, данные могут быть загружены из различных поддерживаемых источников, а также из приложений Power Apps и из потоков Power Automate. В общем, если кратко, то CDS это система хранения и поиска данных. Преимуществом данной системы является тесная интеграция со всеми сервисами Microsoft Power Platform, что позволяет выстраивать структуры данных различного уровня сложности и использовать их в дальнейшем в Power Apps приложениях и с легкостью подключаться к данным через Power BI для построения отчетности. CDS имеет свой интерфейс для создания сущностей, атрибутов, бизнес-правил, связей, представлений и дашбордов. Интерфейс работы с CDS расположен на сайте make.powerapps.com в разделе «Данные», где собраны все основные возможности для настройки сущностей.
Итак, давайте попробуем что-нибудь настроить. Создадим в Common Data Service новую сущность «Поручение»:
Как Вы можете заметить, при создании новой сущности необходимо указать ее имя в единичном и множественном значении, а также требуется задать ключевое поле. В нашем случае это будет поле «Наименование». Кстати, также можете обратить внимание, что внутренние и отображаемые имена сущностей и полей указываются сразу на одной форме, в отличие от SharePoint, где требуется сначала создать поле на латинице, а потом уже переименовывать его на русский язык.
Также, при создании сущности есть возможность произвести огромное количество различных настроек, но сейчас не будем этого делать. Создаем сущность и переходим к созданию атрибутов.
Создаем поле Статус с типом «Набор параметров» и определяем 4 параметра в разрезе этого поля (Новое, Исполнение, Исполнено, Отклонено):
Аналогичным образом создаем остальные поля, которые потребуются нам для реализации приложения. Кстати, перечень доступных типов полей указан ниже, согласитесь, их явно немало?
Обратите еще внимание на настройку обязательности полей, помимо «Обязательное» и «Необязательное» есть еще вариант «Рекомендуется»:
После того, как мы создали все необходимые поля, можно посмотреть на весь перечень полей текущей сущности в соответствующем разделе:
Настраиваем новую форму для ввода данных через Common Data Service и выстраиваем поля друг за другом, после чего нажимаем кнопку «Опубликовать»:
Форма готова, проверим ее работу. Возвращаемся в Common Data Service и переходим на вкладку «Данные», после чего нажимаем «Добавить запись»:
В открывшемся окне формы вводим все необходимые данные и нажимаем «Сохранить»:
Теперь в разделе «Данные» у нас есть одна запись:
Но отображается мало полей. Это легко исправить. Переходим на вкладку «Представления» и открываем на редактирование самое первое представление. Размещаем нужные поля на форме представления и нажимаем «Опубликовать»:
Проверяем состав полей в разделе «Данные». Всё отлично:
Итак, на стороне Common Data Service готова сущность, поля, представление данных и форма для ручного ввода данных непосредственно из CDS. Теперь давайте сделаем приложение холста Power Apps для нашей новой сущности. Переходим к созданию нового приложения Power Apps:
В новом приложении производим подключение к нашей сущности в Common Data Service:
После всех подключений настраиваем несколько экранов нашего мобильного приложения Power Apps. Делаем первый экран с небольшой статистикой и переходами между представлениями:
Делаем второй экран с перечнем имеющихся поручений в сущности CDS:
И делаем еще один экран для создания поручения:
Сохраняем и публикуем приложение, после чего запускаем его для проверки. Заполняем поля и нажимаем кнопку «Создать»:
Проверим, создалась ли запись в CDS:
Проверим то же самое из приложения:
Все данные на месте. Остался финальный штрих. Сделаем небольшой Power Automate поток, который при создании записи в Common Data Service будет отправлять уведомление исполнителю поручения:
В итоге, мы с Вами сделали сущность и форму на уровне Common Data Service, приложение Power Apps для взаимодействия с данными CDS и поток Power Automate для автоматической рассылки уведомлений исполнителям, при создании нового поручения.
Теперь о ценах. Common Data Service не входит в Power Apps, поставляемый в составе подписки Office 365. Это значит, что если у вас есть подписка Office 365 и в рамках нее есть Power Apps, то Common Data Service, по умолчанию, у вас не будет. Для доступа к CDS необходима покупка отдельной лицензии на Power Apps. Цены на планы и варианты лицензирования указаны ниже и взяты с сайта powerapps.microsoft.com:
В следующих статьях мы с Вами рассмотрим еще больше возможностей Common Data Service и Microsoft Power Platform. Всем хорошего дня!
Data as a Service: что это такое, технические сложности и как их обойти с помощью резидентных прокси

Data as a Service (DaaS) – относительно новая модель дистрибуции данных, которая подразумевает, что информация сбором, управлением и хранением нужной информации компании и пользователи занимаются не самостоятельно, а делегируют эту задачу специализированным провайдерам.
Сегодня мы поговорим о плюсах этой модели, существующих технических трудностях и способах их решения.
Зачем это нужно
Проще всего важность данных и, соответственно, услуг сервисов, которые их дают компаниям, можно понять с помощью цифр. Так по статистике, число поисковых запросов с добавлением фразы «рядом со мной» (near me) выросло на 900%. Это говорит о растущем запросе на персонализацию среди пользователей. А для предоставления персонализированного сервиса необходимо где-то взять данные о пользователей, его предпочтениях, предыдущем опыте, иначе он так и останется частью «серой массы». Но сделать это не так просто.
Согласно различным исследованиям, список распространенных проблем при использовании Big Data состоит из:
Звучит заманчиво – компании, которые умеют работать с данными и обладают соответствующей инфраструктурой, помогают тем, кому нужна информация, и зарабатывают на этом. Но не все так просто, и главная проблема для DaaS-сервисов здесь – недостаточно просто иметь инфраструктуру для сбора данных, нужно еще и уметь собирать корректные данные. Поговорим об этой проблеме подробнее.
Главная проблема DaaS
Как вообще происходит сбор данных DaaS-компаниями? По большому счету, у них просто есть мощная инфраструктура и скрипты для сбора данных в интернете – будь то сайты или поисковые системы. Такие скрипты называют краулерами (от англ. crawl) или скрейперами (англ. scrape).
Например, если компании-заказчику нужна информация для работ по поисковой оптимизации своего сайта, то ей может быть нужна информация о сайтах-конкурентах (какие целевые слова они используют, как выглядит выдача поисковых систем по этим словам и т.п.). Для сбора этих данных бот-скрейпер заходит на нужные сайты из списка и проходит по ним, скачивая нужную информацию.
На этом этапе может оказаться, что владельцы сайта, как и поисковая система, совсем не рады тому факту, что кто-то пытается выкачать данные. Активность такого бота наверняка попытаются заблокировать. Обычно для работы таких скрейперов используют серверные IP-адреса без их регулярной. Вычислить и заблокировать бота в такой ситуации нетрудно – и для этого есть большое количест антибот систем.
И это еще самый лучший вариант, потому что нередки случаи, когда владельцы бизнеса стремятся ввести конкурентов в заблуждение и «подсовывают» их ботам-скрейперам искаженные данные. В итоге собранный таким образом датасет может содержать заведомо некорректные данные. Нетрудно представить себе последствия того, что на основе ошибочной информации будут приняты важные бизнес-решения – в лучшем случае они окажутся бесполезны, в худшем компания может понести огромные убытки.
Решение: резидентные прокси
Решить главную проблему DaaS-сервисов можно с помощью использования резидентных прокси для скрейпинга данных. В отличие от серверных IP, которые предоставляются хостинг-провайдеров, что можно легко автоматически проследить с помощью специального ASN-номера, с резидентными прокси все не так просто.
Резидентные IP выдаются владельцам жилья интернет-провайдерами. Соответствующие отметки ставятся во всех связанных базах данных. Существуют специальные сервисы резидентных прокси, которые позволяют пользоваться резидентными адресами. Infatica – как раз такой сервис.
Запросы, которые краулеры сайтов-агрегаторов отправляют с резидентных IP, выглядят так, будто бы они идут от обычных пользователей из определенного региона. А обычных посетителей никто не блокирует – в случае интернет-магазинов это потенциальные клиенты.
В итоге использование ротируемых прокси от Infatica позволяет гарантировать качество собираемых данных – ведь запросы скрейперов с резидентных адресов никто не будет блокировать.
Трансляция h264 видео без перекодирования и задержки
Не секрет, что при управлении летательными аппаратами часто используется передача видео с самого аппарата на землю. Обычно такую возможность предоставляют производители самих БПЛА. Однако что же делать, если дрон собран своими руками?
Перед нами и нашими швейцарскими партнёрами из компании Helvetis встала задача транслировать видео в режиме реального времени с web-камеры с маломощного embedded-устройства на дроне по WiFi на Windows-планшет. В идеале бы нам хотелось:
Этот подход оказался (почти) работающим. В качестве приложения для просмотра можно было использовать любой web-браузер. Однако мы сразу заметили, что частота кадров была ниже ожидаемой, а уровень загрузки CPU на Minnowboard был постоянно на уровне 100%. Embedded-устройство просто не справлялось с кодированием кадров в режиме реального времени. Из плюсов данного решения стоит отметить очень небольшую задержку при передаче 480p видео с частотой не более 10 кадров в секунду.
В ходе обыска была обнаружена web-камера, которая помимо несжатых YUV-кадров могла выдавать кадры в формате MJPEG. Было решено воспользоваться такой полезной функцией, чтобы уменьшить нагрузку на CPU и найти способ передать видео без перекодирования.
FFmpeg / VLC
Первым делом мы попробовали всеми любимый open-source комбайн ffmpeg, позволяющий, среди прочего, считывать видео-поток с UVC-устройства, кодировать его и передавать. После небольшого погружения в мануал были найдены ключи командной строки, которые позволяли получить и передать сжатый MJPEG видеопоток без перекодирования.
Уровень загрузки CPU был невысок. Обрадовавшись, мы с нетерпением открыли поток в плеере ffplay… К нашему разочарованию, уровень задержки видео был абсолютно неприемлемым (около 2 — 3 секунд). Попробовав все отсюда и прошерстив Интернет, мы так и не смогли добиться положительного результата и решили отказаться от ffmpeg.
После провала с ffmpeg пришла очередь медиаплеера VLC, а точнее консольной утилиты cvlc. VLC по умолчанию использует кучу всяких буферов, которые с одной стороны помогают добиться плавности изображения, но с другой дают серьезную задержку в несколько секунд. Изрядно помучавшись, мы подобрали параметры, с которыми стриминг выглядел достаточно сносно, т.е. задержка была не очень большой (около 0.5 с), не было перекодирования, и клиент показывал видео достаточно плавно (пришлось, правда, на клиенте оставить небольшой буфер в 150 мс).
Так выглядит итоговая строка для cvlc:
К сожалению, видео работало не вполне стабильно, да и задержка в 0.5 с была для нас неприемлема.
Mjpg-streamer
Наткнувшись на статью о практически нашей задаче, решили попробовать mjpg-streamer. Попробовали, понравилось! Абсолютно без изменений получилось использовать mjpg-streamer для наших нужд без существенной задержки видео на разрешении 480p.
На фоне предыдущих неудач мы довольно долго были счастливы, но потом мы захотели большего. А именно: чуть меньше забивать канал и повысить качество видео до 720p.
H264 стриминг
Чтобы уменьшить загрузку канала, мы решили поменять используемый кодек на h264 (найдя в наших запасах подходящую web-камеру). Mjpg-streamer не имел поддержки h264, так что было решено его доработать. Во время разработки мы использовали две камеры со встроенным кодеком h264, производства Logitech и ELP. Как оказалось, содержимое потока h264 у этих камер существенно различалось.
Камеры и структура потока
Поток h264 состоит из пакетов NAL (network abstraction layer) нескольких типов. Наши камеры генерировали 5 типов пакетов:
Non-IDR — пакет, содержащий кодированное изображение, содержащее ссылки на другие кадры. Декодер не в состоянии восстановить изображение по одному Non-IDR кадру без наличия других пакетов.
Помимо IDR-кадра, декодеру нужны пакеты PPS и SPS для декодирования изображения. Эти пакеты содержат метаданные об изображении и потоке кадров.
Основываясь на коде mjpg-streamer, мы воспользовались API V4L2 (video4linux2) для считывания данных от камер. Как выяснилось, один “кадр” видео содержал несколько NAL пакетов.
Именно в содержимом “кадров” обнаружилось существенное различие между камерами. Мы воспользовались библиотекой h264bitstream для парсинга потока. Существуют standalone-утилиты, позволяющие просмотреть содержимое потока.
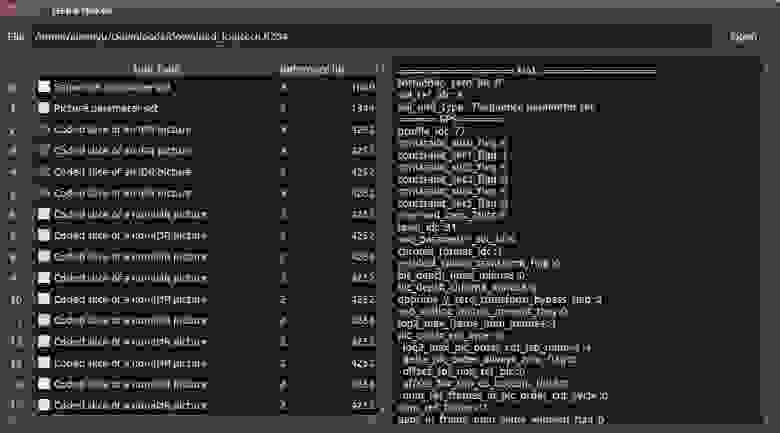
Поток кадров камеры Logitech состоял в основном из non-IDR кадров, к тому же разделенных на несколько data partition. Раз в 30 секунд камера генерировала пакет, содержащий IDR picture, SPS и PPS. Так как декодеру нужен IDR пакет для того, чтобы начать декодировать видео, нас эта ситуация сразу не устроила. К нашему сожалению, оказалось, что нет адекватного способа установить период, с которым камера генерирует IDR пакеты. Поэтому нам пришлось отказаться от использования этой камеры.
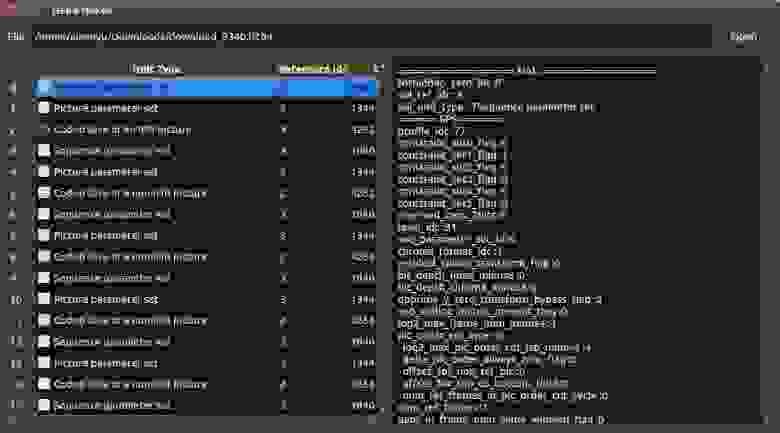
Камера производства ELP оказалась существенно удобнее. Каждый получаемый нами кадр содержал в себе пакеты PPS и SPS. К тому же, камера генерировала IDR пакет раз в 30 кадров (период
1с). Это нас вполне устраивало и мы остановили свой выбор на этой камере.
Реализация сервера вещания на основе mjpg-streamer
За основу серверной части решено было взять вышеупомянутый mjpg-streamer. Его архитектура позволяла легко добавлять новые плагины ввода и вывода. Мы начали с добавления плагина для считывания потока h264 с устройства. В качестве плагина вывода выбрали уже имеющийся плагин http.
В V4L2 достаточно было указать что мы хотим получать кадры в формате V4L2_PIX_FMT_H264, чтобы начать получать поток h264.Так как для декодирования потока необходим IDR-кадр, мы парсили поток и ожидали IDR-кадр. Приложению-клиенту поток отправлялся по HTTP начиная с этого кадра.
На клиентской части решили воспользоваться libavformat и libavcodec из проекта ffmpeg для чтения и декодирования потока h264. В первом тестовом прототипе получение потока по сети, разбиение его на кадры и декодирование было возложено на ffmpeg, конвертирование получаемого декодированного изображения из формата NV12 в RGB и отображение было реализовано на OpenCV.
Первые тесты показали, что данный способ транслирования видео работоспособен, но имеется существенная задержка (около 1 секунды). Наше подозрение пало на протокол http, поэтому было решено использовать для передачи пакетов UDP.
Так как у нас не было необходимости поддержки существующих протоколов вроде RTP, мы реализовали свой простейший велосипед протокол, в котором внутри UDP-датаграмм передавались NAL-пакеты потока h264. После небольшой доработки принимающей части мы были приятно удивлены малой задержкой видео на настольном ПК. Однако первые же тесты на мобильном устройстве показали, что программное декодирование h264 — не конёк мобильных процессоров. Планшет просто не успевал обрабатывать кадры в режиме реального времени.
Так как процессор Atom Z3740, используемый на нашем планшете, поддерживает технологию Quick Sync Video (QSV), мы попробовали использовать QSV h264 декодер из libavcodec. К нашему удивлению, он не только не улучшил ситуацию, но и увеличил задержку до 1.5 секунд даже на мощном настольном ПК! Однако этот подход действительно существенно снизил нагрузку на CPU.
Перепробовав различные варианты конфигурации декодера в ffmpeg, было решено отказаться от libavcodec и использовать Intel Media SDK напрямую.
Первым сюрпризом для нас стал ужас, в который предлагается погрузиться человеку, решившему разрабатывать используя Media SDK. Официальный пример, предлагаемый разработчикам, представляет из себя мощный комбайн, который умеет всё, но в котором трудно разобраться. К счастью, на форумах Intel мы нашли единомышленников, также недовольных примером. Они нашли старые, но более легкоусвояемые туториалы. На основе пример simple_2_decode мы получили следующий код.
После реализации декодирования видео при помощи Media SDK мы столкнулись с аналогичной ситуацией — задержка видео составила 1.5 секунды. Отчаявшись, мы обратились к форумам и нашли советы, которые должны были снизить задержку при декодировании видео.
Декодер h264 из состава Media SDK накапливает кадры прежде чем выдавать декодированное изображение. Было обнаружено, что если в структуре данных, передаваемых в декодер (mfxBitstream), установить флаг “конец потока”, то задержка снижается до
Далее экспериментальным путем было обнаружено, что декодер держит 5 кадров в очереди, даже если установлен флаг окончания потока. В итоге нам пришлось добавить код, который симулировал “окончательное окончание потока” и заставлял декодер выдавать кадры из этой очереди:
После этого уровень задержки опустился до приемлемого, т.е. незаметного взглядом.
Выводы
Приступая к задаче трансляции видео в режиме реального времени, мы очень рассчитывали использовать существующие решения и обойтись без своих велосипедов.
Нашей главной надеждой были такие гиганты работы с видео, как FFmpeg и VLC. Несмотря на то, что вроде бы они умеют делать то, что нам надо (передавать видео без перекодирования), нам не удалось убрать получающуюся при передаче видео задержку.
Практически случайно наткнувшись на проект mjpg-streamer, мы были очарованы его простотой и четкой работой в деле трансляции видео в формате MJPG. Если вам вдруг понадобится передавать именно этот формат, то мы категорически рекомендуем его использовать. Неслучайно, что именно на его основе мы и реализовали свое решение.
В результате разработки мы получили достаточно легковесное решение для передачи видео без задержки, не требовательное к ресурсам ни передающей, ни принимающей стороны. В задаче декодирования видео нам сильно помогла библиотека Intel Media SDK, пусть и пришлось применить немного силы, чтобы заставить отдавать ее кадры без буферизации.



