cycle time
machine cycle time — время выполнения станком [машиной\] отдельной операции
Смотреть что такое «cycle time» в других словарях:
cycle time — UK US noun [C or U] PRODUCTION ► the time between the beginning and end of the process of making a product: »We also are working on improving cycle time, quality, efficiency and productivity … Financial and business terms
cycle time — ciklo trukmė statusas T sritis fizika atitikmenys: angl. cycle time; cycling time; duration of cycle vok. Zyklusdauer, f; Zykluslänge, f rus. продолжительность цикла, f pranc. durée du cycle, f … Fizikos terminų žodynas
cycle time — noun The total elapsed time to complete an operation or set of operations. Order cycle time can now be minutes from when the customer starts entering an order to when it is visible to the warehouse … Wiktionary
cycle time — The length of time required from the placing of an order by a customer to the delivery of the product or service. In companies using just in time techniques, this should be equivalent to the time taken from start to finish of the manufacturing… … Accounting dictionary
cycle time — The length of time required from the placing of an order by a customer to the delivery of the product or service. In companies using just in time techniques, this should be equivalent to the time taken from start to finish of the manufacturing… … Big dictionary of business and management
cycle time — noun : the time required to complete a cycle used especially in connection with time and motion studies … Useful english dictionary
cycle time — period of time which passes between repeated actions, period of time which passes between the execution of one command to the execution of another (Computers) … English contemporary dictionary
Cycle time variation — is a proven metric and philosophy for continuous improvement with the aim of driving down the deviations in the time it takes to produce successive units on a production line.[1] It supports organizations application of lean manufacturing or lean … Wikipedia
Interleaved polling with adaptive cycle time — (IPACT) is an algorithm designed by Glen Kramer and others at the University of California, Davis. IPACT is a dynamic bandwidth allocation algorithm for use in Ethernet passive optical networks (EPONs).IPACT uses the Gate and Report messages… … Wikipedia
Cash-to-cash-cycle-time — Unter Kapitalbindungsdauer versteht man die Dauer, in der das für eine Investition benötigte (Finanz )kapital gebunden ist, bis die mit Hilfe der Investition erwirtschafteten Gewinne in Form von Einnahmen bzw. Einzahlungsströmen in die Kasse des… … Deutsch Wikipedia
maximum allowable cycle time — The maximum time that can elapse between consecutive items leaving a production process, if the designated capacity of the process is to be achieved … Big dictionary of business and management
Метрики в Канбане
Чтобы управлять потоком в Канбане, нужны метрики. Их очень много, в этой статье Алексей Пикулев рассмотрит три ключевые: WIP, Cycle Time, Troughtput.
WIP — Work in Progress
Количество незавершённой работы в Канбане обозначают WIP. Проще говоря, это количество всех элементов задач, над которыми работает Команда. Важно понимать, что WIP — это не ограничения для каждой колонки, которые мы пишем на канбан-доске, а количество всех карточек, которые взяты в работу, но ещё не закончены.
Чтобы правильно подсчитать эту метрику, надо ответить на два вопроса:
В компании по производству мебели началом работы считают момент заключения контракта, а концом — передачу изделий в службу доставки.
Только определив эти два момента, WIP можно подсчитать правильно.
Сycle Time (Lead Time)
Количество времени от идеи до реализации. В основном эта метрика полезна клиентам, которым важно знать, сколько времени пройдёт от их обращения в вашу компанию до получения результата. Измеряя эту метрику, мы начинаем управлять ожиданиями заказчика.
Например, задача по разработке требования занимает восемь часов. Но это не значит, что в процессе у нас не возникнет необходимость уточнить что-то, подождать ответ от вендора, разобраться с зависимостью от других членов Команды. И так на каждом этапе. В результате общее время (Сycle Time) может сильно вырасти.
Troughput
Это пропускная способность Команды, то есть сколько готовых элементов работы мы предоставляем за отрезок времени. Эту метрику можно считать в разных временных разрезах (день, неделя, месяц).
Важно отличать пропускную способность от скорости работы в Скраме. Мы не считаем сторипоинты и другие выдуманные показатели, только готовые элементы работы.
Почему WIP, Сycle Time, Troughtput — ключевые метрики
Эти три метрики связаны с законом Литтла — законом прохождения очередей. Благодаря этому закону можно достоверно предсказать, что произойдёт с системой, компанией или Командой при изменении одной или нескольких метрик. 
Закон Литтла
Команда не успевает сделать все задачи и решает нанять ещё сотрудников, чтобы увеличить скорость своей работы. Но если посмотреть на формулу закона Литтла, то станет ясно, что это решение — ошибка. Чем больше сотрудников, тем больше задач они выполняют одновременно, то есть растёт WIP. Чем больше незавершённой работы, тем больше время реализации фичи, а значит, меньше скорость работы Команды.
| Скорость реализации фичи до найма — 3 недели | После найма дополнительных сотрудников — 6 недель |
|---|---|
| avr. Lead Time = avr. WIP ÷ avr. Throuput = 6 ÷ 2 = 3 | avr. Lead Time = avr. WIP ÷ avr. Throuput = 12 ÷ 2 = 6 |
Алексей Пикулев Аккредитованный тренер по Канбану
Что такое тайминги и как они влияют на скорость оперативной памяти


Содержание
Содержание
Выбор оперативной памяти в игровую сборку может обернуться кошмаром, если начать разбираться в тонкостях ее работы. Требования современных игровых и рабочих задач диктуют свои условия, поэтому память — теперь чуть ли не самая важная и сложная часть в сборке компьютера. Среди многочисленных моделей нужно выбрать единственный подходящий вариант и это пугает. Причем самое сложное в этом — почему память с меньшей частотой работает быстрее и показывает больше кадров в играх, чем та, у которой частота выше. Для этого нужно разобраться, в чем все-таки измеряется скорость памяти и какие параметры влияют на нее.
Мощность компьютера измеряется величиной FLOPS, которая обозначает количество вычислительных операций за секунду. По причине того, что компьютеры могут одновременно выполнять миллионы операций, к флопсам добавляют приставку «гига».
В привычной же обстановке мы можем путать мощность и частоту, поэтому считаем производительность компьютеров не гигафлопсами, а максимальной рабочей частотой. Это проще в рядовых ситуациях, когда говорящие знают тему хорошо и соотносят мощность с герцами в уме автоматически.

В то же время, такое языковое упрощение вносит коррективы в понимание практической части вопроса. Вырывая контекст из форумов, рядовой пользователь и правда думает, что мощность памяти можно выразить в герцах. Просто потому, что гонка за частотой стала трендом среди любителей и энтузиастов. Это и мешает неопытному человеку понять, почему его высокочастотный процессор может проиграть тому, у которого на несколько сотен герц меньше. Все просто — у одного два ядра и четыре потока, а у другого четыре настоящих. И это большая разница.
Оперативная память и ее скорость
Оперативная память состоит из тысяч элементов, связанных между собой в чипах-микросхемах. Их называют банками (bank), которые хранят в себе строчки и столбцы с электрическим зарядом. Сам электрический заряд — это информация (картинки, программы, текст в буфере обмена и много чего еще). Как только системе понадобились данные, банка отдает заряд и ждет команды на заполнение новыми данными. Этим процессом руководит контроллер памяти.
Для аналогии, сравним работу оперативной памяти и работу кафе. Чипы можно представить в виде графинов с томатным соком. Каждый наполнен соком и мякотью спелых помидоров (электрический заряд, информация). В кафе приходит клиент (пользователь компьютера) и заказывает сок (запускает игру). Бармен (контроллер, тот, кто управляет банками) принимает заказ, идет на кухню (запрашивает информацию у банок), наливает сок (забирает игровые файлы) и несет гостю, а затем возвращается и заполняет графин новым соком (новой информацией о том, что запустил пользователь). Так до бесконечности.

Тайминги — качество
Работа памяти, вопреки стереотипу, измеряется не только герцами. Быстроту памяти принято измерять в наносекундах. Все элементы памяти работают в наносекундах. Чем чаще они разряжаются и заряжаются, тем быстрее пользователь получает информацию. Время, за которое банки должны отрабатывать задачи назвали одним словом — тайминг (timing — расчет времени, сроки). Чем меньше тактов (секунд) в тайминге, тем быстрее работают банки.
Такты. Если нам необходимо забраться на вершину по лестнице со 100 ступеньками, мы совершим 100 шагов. Если нам нужно забраться на вершину быстрее, можно идти через ступеньку. Это уже в два раза быстрее. А можно через две ступеньки. Это будет в три раза быстрее. Для каждого человека есть свой предел скорости. Как и для чипов — какие-то позволяют снизить тайминги, какие-то нет.

Частота — количество
Теперь, что касается частоты памяти. В работе ОЗУ частота влияет не на время, а на количество информации, которую контроллер может утащить за один подход. Например, в кафе снова приходит клиент и требует томатный сок, а еще виски со льдом и молочный коктейль. Бармен может принести сначала один напиток, потом второй, третий. Клиент ждать не хочет. Тогда бармену придется нести все сразу за один подход. Если у него нет проблем с координацией, он поставит все три напитка на поднос и выполнит требование капризного клиента.

Аналогично работает частота памяти: увеличивает ширину канала для данных и позволяет принимать или отдавать больший объем информации за один подход.
Тайминги плюс частота — скорость
Соответственно, частота и тайминги связаны между собой и задают общую скорость работы оперативной памяти. Чтобы не путаться в сложных формулах, представим работу тандема частота/тайминги в виде графического примера:

Разберем схему. На торговом центре есть два отдела с техникой. Один продает видеокарты, другой — игровые приставки. Дефицит игровой техники довел клиентов до сумасшествия, и они готовы купить видеокарту или приставку, только чтобы поиграть в новый Assassin’s Creed. Условия торговли такие: зона ожидания в отделе первого продавца позволяет обслуживать только одного клиента за раз, а второй может разместить сразу двух. Но у первого склад с видеокартами находится в два раза ближе, чем у второго с приставками. Поэтому он приносит товар быстрее, чем второй. Однако, второй продавец будет обслуживать сразу двух клиентов, хотя ему и придется ходить за товаром в два раза дальше. В таком случае, скорость работы обоих будет одинакова. А теперь представим, что склад с приставками находится на том же расстоянии, что и у первого с видеокартами. Теперь продавец консолей начнет работать в два раза быстрее первого и заберет себе большую часть прибыли. И, чем ближе склад и больше клиентов в отделе, тем быстрее он зарабатывает деньги.
Так, мы понимаем, как взаимодействует частота с таймингами в скорости работы памяти.
Соответственно, чем меньше метров проходит контроллер до банок с электрическим зарядом, тем быстрее пользователь получает информацию. Если частота памяти позволяет доставить больше информации при том же расстоянии, то скорость памяти возрастает. Если частота памяти тянет за собой увеличение расстояния до банок (высокие тайминги), то общая скорость работы памяти упадет.
Сравнить скорость разных модулей ОЗУ в наносекундах можно с помощью формулы: тайминг*2000/частоту памяти. Так, ОЗУ с частотой 3600 и таймингами CL14 будет работать со скоростью 14*2000/3600 = 7,8 нс. А 4000 на CL16 покажет ровно 8 нс. Выходит, что оба варианта примерно одинаковы по скорости, но второй предпочтительнее из-за большей пропускной способности. В то же время, если взять память с частотой 4000 при CL14, то это будет уже 7 нс. При этом пропускная способность станет еще выше, а время доставки информации снизится на 1 нс.
Строение чипа памяти и тайминги
В теории, оперативная память имеет скорость в наносекундах и мегабайтах в секунду. Однако, на практике существует не один десяток таймингов, и каждый задает время на определенную работу в микросхеме.
Они делятся на первичные, вторичные и третичные. В основном, для маркетинговых целей используется группа первичных таймингов. Их можно встретить в характеристиках модулей. Например:

Вот, как выглядят тайминги на самом деле:

Их намного больше и каждый за что-то отвечает. Здесь бармен с томатным соком не поможет, но попробуем разобраться в таймингах максимально просто.
Схематика чипов
Микросхемы памяти можно представить в виде поля для игры в морской бой или так:

В самом упрощенном виде иерархия чипа это: Rank — Bank — Row — Column. В ранках (рангах) хранятся банки. Банки состоят из строк (row) и столбцов (column). Чтобы найти информацию, контроллеру необходимо иметь координаты точки на пересечении строк и столбцов. По запросу, он активирует нужные строки и находит информацию. Скорость такой работы зависит от таймингов.
Первичные
CAS Latency (tCL) — главный тайминг в работе памяти. Указывает время между командой на чтение/запись информации и началом ее выполнения.
RAS to CAS Delay (tRCD) — время активации строки.
Row Precharge Time (tRP) — прежде чем перейти к следующей строке в этом же банке, предыдущую необходимо зарядить и закрыть. Тайминг обозначает время, за которое контроллер должен это сделать.
Row Active Time (tRAS) — минимальное время, которое дается контроллеру для работы со строкой (время, в течение которого она может быть открыта для чтения или записи), после чего она закроется.
Command Rate (CR) — время до активации новой строки.
Вторичные
Второстепенные тайминги не так сильно влияют на производительность, за исключением пары штук. Однако, их неправильная настройка может влиять на стабильность памяти.
Write Recovery (tWR) — время, необходимое для окончания записи данных и подачи команды на перезарядку строки.
Refresh Cycle (tRFC) — период времени, когда банки памяти активно перезаряжаются после работы. Чем ниже тайминг, тем быстрее память перезарядится.
Row Activation to Row Activation delay (tRRD) — время между активацией разных строк банков в пределах одного чипа памяти.
Write to Read delay (tWTR) — минимальное время для перехода от чтения к записи.
Read to Precharge (tRTP) — минимальное время между чтением данных и перезарядкой.
Four bank Activation Window (tFAW) — минимальное время между первой и пятой командой на активацию строки, выполненных подряд.
Write Latency (tCWL) — время между командой на запись и самой записью.
Refresh Interval (tREFI) — чтобы банки памяти работали без ошибок, их необходимо перезаряжать после каждого обращения. Но, можно заставить их работать дольше без отдыха, а перезарядку отложить на потом. Этот тайминг определяет количество времени, которое банки памяти могут работать без перезарядки. За ним следует tRFC — время, которое необходимо памяти, чтобы зарядиться.
Третичные
Эти тайминги отвечают за пропускную способность памяти в МБ/с, как это делает частота в герцах.
Эти отвечают за скорость чтения:
Эти отвечают за скорость копирования в памяти (tWTR):
Скорость чтения после записи (tRTP):
А эти влияют на скорость записи:
Скорость памяти во времени
Итак, мы разобрались, что задача хорошей подсистемы памяти не только в хранении и копировании данных, но и в быстрой доставке этих данных процессору (пользователю). Будь у компьютера хоть тысяча гигабайт оперативной памяти, но с очень высокими таймингами и низкой частотой работы, по скорости получится уровень неплохого SSD-накопителя. Но это в теории. На самом деле, любая доступная память на рынке как минимум соответствует требованиям JEDEC. А это организация, которая знает, как должна работать память, и делает это стандартом для всех. Аналогично ГОСТу для колбасы или сгущенки.

Стандарты JEDEC демократичны и современные игровые системы редко работают на таких низких настройках. Производители оставляют запас прочности для чипов памяти, чтобы компании, которые выпускают готовые планки оперативной памяти могли немного «раздушить» железо с помощью разгона. Так, появились заводские профили разгона XMP для Intel и DOHCP для AMD. Это «официальный» разгон, который даже покрывается гарантией производителя.

Профили разгона включают в себя информацию о максимальной частоте и минимальных для нее таймингах. Так, в характеристиках часто пишут именно возможности работы памяти в XMP режимах. Например, частоте 3600 МГц и CL16. Чаще всего указывают самый первый тайминг как главный.
Чем выше частота и ниже тайминги, тем круче память и выше производительность всей системы.
Так работает оперативная память с момента ее создания и до нашего времени.
Синхронизация продуктовых команд в Sportmaster Lab (часть 2)
Вторая часть поста про то, как сделать, чтобы продуктовая agile-команда выполнила задачу к определенному сроку, но при этом не изменила принципам работы по потоку. Первая часть поста посвящена описанию нашего подхода к работе продуктовых команд, а также тому, что в вытягивающей системе основными инструментами управления сроками становятся не перенос ответственности за сроки на исполнителя (команду), а прозрачность и прогнозируемость работы этой команды. Ниже остановимся на метриках команд и их использовании при прогнозировании сроков и синхронизации исполнения задач.
Метрики
Основной тип событий в нашей модели — перемещение задачи из одной области нашей карты в другую, их мы и будем оцифровывать в метриках.
Наша самая главная метрика — Lead Time: это характерное время, за которое задача доходит от одной из четырех контрольных точек (появление идеи, ТПР, Х и ТПО) до установки на продуктив.
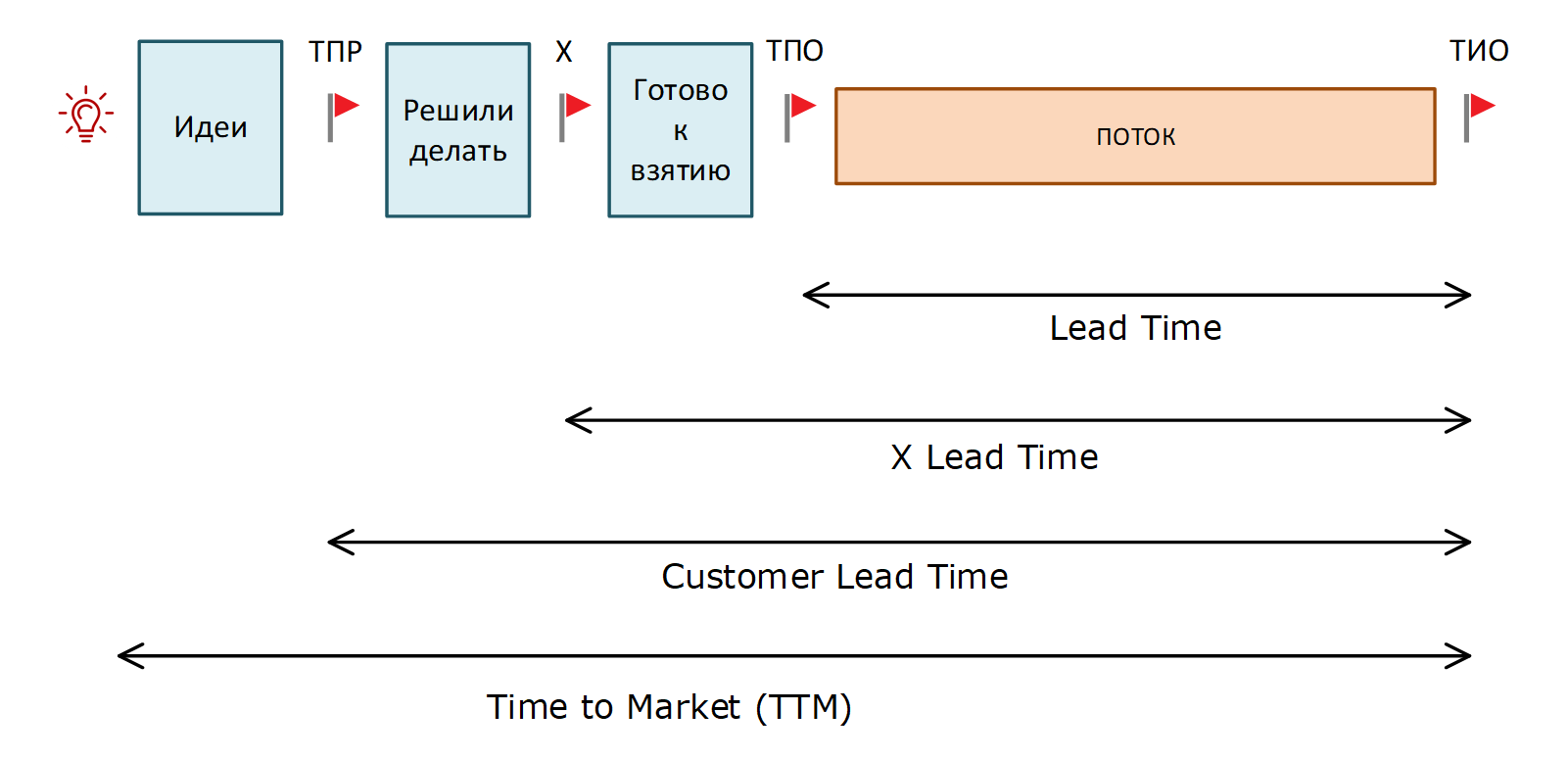 .
.
Как видим, они образуют иерархию вложенности. Мы используем величины Lead Time, выраженные в рабочих, а не календарных днях. Если над одним продуктом работает больше одной команды, то TTM, Customer Lead Time и Х Lead Time относятся к продукту в целом, а Lead Time для потока у каждой команды может быть свой.
Устоявшейся терминологии для разных Lead Time пока нет, поэтому аналогичные по смыслу показатели у других авторов можно встретить под другими названиями, например, для потокового Lead Time (тот, который самый короткий) часто используется термин Cycle Time. Здесь буду придерживаться нашего варианта «жаргона», извините, если что.
Также часто используются метрики потока — количество задач, входящих и выходящих из области за период времени, и количество задач, находящихся в области на определенный момент. Эти показатели можно видеть на CFD-диаграмме или на диаграмме потока задач (которая, на наш взгляд, легче читается). Например, для области «Поток» диаграмма потока задач с шагом в неделю выглядит так:
 Потоковая диаграмма
Потоковая диаграмма
Прогнозирование с использованием показателей Lead Time разных уровней
В нашей визуализации движения по этапам жизненного цикла мы можем видеть текущее положение технических и бизнес-эпиков (серые) и входящих в них задач (персиковые, кажется, так этот цвет называется).
Если заглядывать сюда регулярно, то сможем отследить и их перемещение между областями.
 Визуализация эпиков и задач продуктовой команды на карте жизненного цикла
Визуализация эпиков и задач продуктовой команды на карте жизненного цикла
Предположим, нас интересует один конкретный эпик, который уже находится в реализации, в области «Поток». Оставим на рисунке только его и подчиненные ему задачи:

В эпик входят четыре задачи, одна из которых уже завершена, две в работе и одна еще не взята в поток и находится в области «Готово к взятию», на вершине бэклога. Исходя из ситуации, дата завершения эпика будет определяться, скорее всего, выполнением задачи, которая еще не взята в поток. Эпики переводятся в область «Поток» после того, как хотя бы одна из вложенных задач попала в поток, и считаются завершенными, когда все вложенные задачи завершены.
Чтобы понять, сколько времени обычно нужно, чтобы провести задачу через поток, рассмотрим спектральную диаграмму Lead Time для потока этой команды за последние три месяца:
Спектральная диаграмма LeadTime
Спектральная диаграммы для отдельных типов задач
Таким образом, мы получаем достаточно обоснованный прогноз, что с вероятностью немного менее 85% эта задача и, как следствие, весь эпик будут выполнены за шесть рабочих дней. Меньше 85% получается из-за того, что есть небольшая вероятность, что какая-то из двух задач в потоке застрянет там больше, чем на шесть дней.
Теперь посмотрим, как можно мониторить движение эпика на всем жизненном цикле, от идеи до реализации при помощи статистики Lead Time разных уровней:
Представим себе руководителя проекта (РП), у которого есть план, содержащий несколько задач для разных команд, которые нужно выполнить к определенным датам. РП – не agile-роль, он может использовать дедлайны, более того, он не может их не использовать :). Вопрос в том, как он добьется выполнения этих сроков продуктовыми командами, которые не горят желанием брать на себя обязательства по достижению дедлайна.
Рассмотрим одну из таких задач. Плановую дату ее исполнения обозначим как день «Д». Построим «LeadTime-профиль» продукта/команды, которая будет ее выполнять, в виде таблицы:
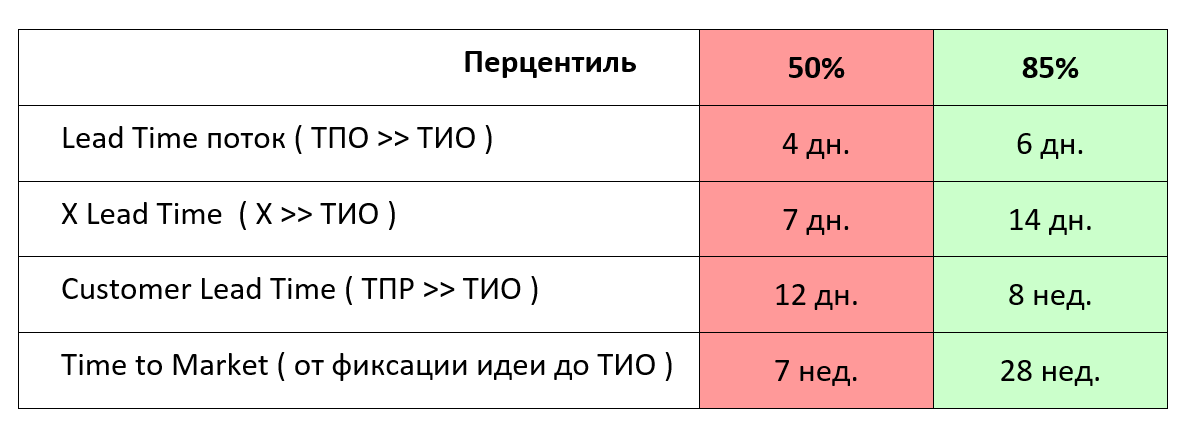 Пример «LeadTime-профиля»
Пример «LeadTime-профиля»
Дни – рабочие, неделя соответствует 5 рабочим дням. 85% вероятность выполнения РП считает приемлемой.
Далее имеет смысл отслеживать задачи, входящие в эпик, по отдельности. Предположим, что их три, в области «Готово к взятию» они расположены на втором, пятом и шестом месте по приоритетам (см. рисунок ниже). Мы уже знаем, что если задача находится на самом верху области «Готово к взятию», то с вероятностью 85% она будет выполнена не позже, чем через 6 дней. Остается понять, сколько нужно времени, чтобы все три задачи эпика попали в поток. Посмотрев на потоковую диаграмму, мы увидим, что команда берет в поток в среднем 15 задач в неделю, то есть примерно по три задачи в рабочий день. Шесть задач будут взяты в работу, скорее всего, не позднее, чем за два дня. Поскольку день «Д» близко, РП стоит проследить, чтобы в бэклог поверх «его» задач не были помещены дополнительные задачи. Не стоит забывать, что команда принимает обязательства выполнить задачу только в момент ее взятия в поток, а до этого возможны изменения приоритетов.
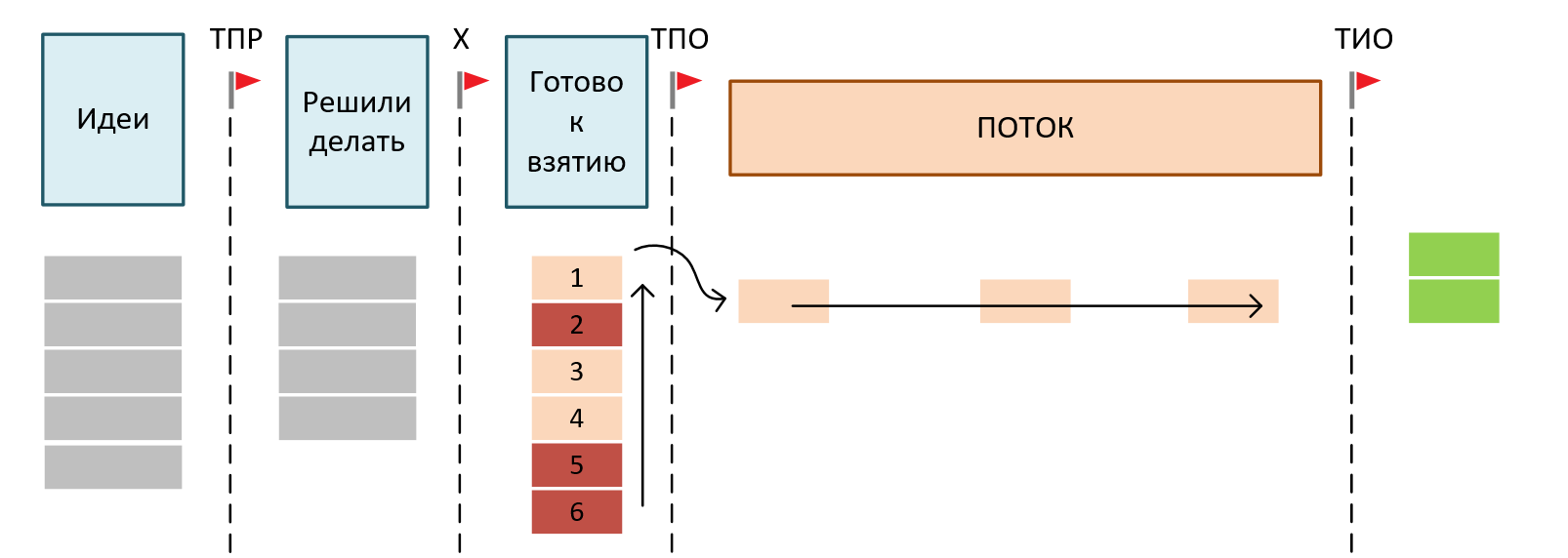 Когда задачи 2, 5 и 6 попадут в поток?
Когда задачи 2, 5 и 6 попадут в поток?
После того как все три задачи попали в поток команды, можно считать, что они вышли на баллистическую траекторию, ускорить их уже не получится, и РП остается только ожидать результата.
Если РП пришел со своей задачей не заранее, а со словами «Надо сделать вчера», то задача изначально находится в «красной зоне». В этом случае РП будет отказано в реализации задачи к этому сроку. Если у РП есть достаточный административный ресурс, продуктовая команда может быть временно переведена из штатного режима «работы по потоку» в режим «подвиг», с принудительным управлением работами по критической задаче. Эта конкретная задача, возможно, будет выполнена, но общая мотивация, производительность и качество работы команды пострадают и потребуют времени на восстановление.
Важно: при движении эпика по жизненному циклу все виды Lead Time нужно измерять для той части эпика, которая дошла до продуктива.
В процессе проработки от первоначальной идеи могут отделяться куски, которые предполагается сделать позже, а может быть, и никогда. Плохая практика, когда в одном эпике копятся все задачи по этой теме – первой, второй, … семнадцатой очереди реализации, просто чтобы их не забыть. Это делает эпик вечно незавершенным и непригодным к отслеживанию как отдельного элемента работ и ценности. В исходном эпике нужно оставлять только задачи первого приоритета, задачи всех остальных приоритетов надо выносить в отдельные эпики, которые переносятся обратно в область идей. В дальнейшем с ними работают как с новыми идеями по общим правилам. При этом информационно можно указать, какой эпик для него является родительским, или объединить их общей меткой, чтобы можно было отследить историю реализации первоначальной идеи.
Нужно ли автоматизировать прогнозирование сроков исполнения задач?
Посмотрим еще раз на нашу визуализацию. Возникает подозрение, что движение эпиков и задач внутри каждой области более или менее упорядочено: большинство эпиков и задач движутся слева направо по областям жизненного цикла и снизу вверх по приоритетам внутри области.

Мы с командой портала метрик (особенная благодарность Диме Новикову!) попробовали сделать такой автоматический прогноз для задач в области «Готово к взятию». Идея была в следующем: для каждой задачи, которая сейчас находится в бэклоге, рассмотрим количество и типы задач, расположенных в бэклоге выше нее. В исторических данных по работе этой команды ищем похожие ситуации — когда выше некоторой задачи в бэклоге находился примерно такой же набор задач по количеству и типам. Смотрим, сколько времени у команды занимало выполнение такого набора задач в прошлом, получаем вероятностное распределение, из которого можно с разной степенью вероятности сделать прогноз дат, когда интересующая нас задача попадет на продуктив,
Полученные нами оценки сроков оказались весьма расплывчаты и малополезны. Сначала мы, естественно, пытались найти и исправить недостатки в прогнозной модели или подборе параметров, но существенного улучшения не происходило. Одной из основных причин этого было то, что задачи в бэклоге не двигались упорядоченно, как патроны в обойме, снизу вверх, а меняли приоритеты и перемещались вверх и вниз. В бэклог поступали новые задачи, которые брались в работу быстрее, чем те, что лежали в бкэлоге до них. В результате некоторые задачи «пролетали» существенно быстрее, а другие «зависали», и их положение в бэклоге на момент прогноза влияло на их судьбу гораздо меньше, чем мы ожидали. То есть наше базовое предположение, что задачи в бэклоге движутся в основном снизу вверх, не оправдалось.
Поэтому теперь мне кажется, что в данном случае применять такого рода способы прогнозирования нет смысла.
«Самосбывающийся прогноз»
Автоматизированное прогнозирование обычно применяют для тех событий, на которые потребитель прогноза повлиять не может – погода, покупательский спрос, движение автобуса в пробках, etc… А на движение продуктовых задач потребители прогноза (команда и заказчики) имеют большое влияние. Если прогноз не устраивает заказчика и/или команду, то есть как минимум три инструмента для исправления ситуации:
Договориться об изменении приоритета задачи.
Сократить скоуп и требования, реализовать сначала ту часть, которая дает наибольший эффект при меньших затратах.
Реализовать сначала менее трудоемкое, временное решение с образованием.
Достижение необходимого срока возможно без штурмовщины, если:
Задача действительно нужна, кто-то ждет ее выполнения и прилагает периодические усилия для поддержания ее приоритета.
Продуктовая команда работает в штатном режиме: осуществляет регулярное управление техническим долгом; большая часть задач команды не имеет жестких дедлайнов и их можно «подвинуть» в случае необходимости; команда не работает со 100% напряжением, у нее есть резерв для маневра.
При таких условиях любой реалистичный прогноз становится в некотором смысле самосбывающимся. Реалистичным считается прогноз, который не предполагает, что команда вдруг начнет решать задачи быстрее, чем она обычно это делает на текущей стадии своего развития. Достижение такого «самосбывающегося дедлайна» перестает быть «подвигом» и не несет существенных рисков.
Изменение зон ответственности при работе со сроками
Обратите внимание, как меняется общий подход к достижению определенных сроков в «проектной» и «продуктовой» парадигмах. Под «заказчиком» ниже понимаются все роли, которые заинтересованы в результате, но сами его не производят – заказчики, начальники подразделений, руководители проектов…
В «проектной» парадигме базовый алгоритм работы со сроками следующий.
В «продуктовой» парадигме:
Заказчик проявляет регулярное внимание к задаче, актуализирует ее приоритет и оценку ценности в сравнении с конкурирующими задачами. Команда (исполнитель), как правило, не берет на себя ответственность за выполнение задач к определенному сроку. Вместо приложения усилий для достижения сроков по отдельным задачам команда концентрируется та том, чтобы все свои задачи выполнять одинаково быстро и предсказуемо.
Таким образом в продуктовой парадигме ответственность за достижение сроков в большей степени ложится на сторону заказчика. Рабочая гипотеза состоит в том, что в обмен повышается общая эффективность приложения усилий заказчиком: выше вероятность получить то, что нужно, к нужному сроку, меньше неактуальных задач, сделанных потому, что их забыли отменить. Проверкой этой гипотезы мы сейчас и занимаемся в SM Lab :).
Что может сделать команда для повышения своей прогнозируемости.
Для того чтобы работа команды была прогнозируемой, нужно чтобы у показателей Lead Time разброс (дисперсия распределения) был поменьше. Даже при небольшом разбросе не нужно забывать, что это вероятностный, а не детерминистический прогноз, отклонения всегда возможны, и ни одна команда не может быть на 100% предсказуемой. Но если распределение имеет большую дисперсию, то этот показатель полностью теряет предсказательную силу.
Для внешних интересантов интереснее всего предсказуемость задач как раз в левой части жизненного цикла, в областях «идеи» и «решили делать». От этих прогнозов зависят решения, которые принимаются при формировании дорожных карт и бизнес-планов. Будет ли готова новая функциональность к началу новой коллекции, или надо сразу отложить ее внедрение на полгода, до следующей коллекции? На какой период планировать дополнительные ресурсы, связанные с этим? И множество других важных вопросов. В идеале, заказчик хочет знать, «когда будет готово», сразу же, как только он высказал новую идею — в наших терминах это значит, что дисперсия распределения Time to Market должна быть как можно меньше. К сожалению, обеспечить такую предсказуемость в области идей для команды очень сложно, так как эта область в наименьшей степени подвержена ее влиянию. Если каждую идею прорабатывать сразу до такой степени, чтобы по ней можно было дать обоснованный срок реализации, у команды не останется времени на полезную работу – все уйдет на детальную проработку идей, которые никогда не будут реализованы.
Здесь удобно использовать WiP-лимит не только на максимально допустимое количество задач (эпиков), по которым принято решение начать проработку командой, но и на минимальное их количество в области. Это позволит автоматически включать процедуру пополнения области при достижении нижней границы.
Такой подход позволяет постоянно и предсказуемо работать с новыми идеями, не превращая область в свалку идей.
Предсказуемое поведение Customer Lead Time дает заказчикам хорошую точку опоры, «границу стакана», которую не стоит переходить, и позволяет заботиться о судьбе своих идей и обеспечивать их переход через ТПР раньше, чем они попадут в «красную зону».
Выводы
Ответственность за сроки остается на стороне заказчика, в обмен на повышение вероятности и скорости получения необходимого результата.
Для контроля сроков применяются методы визуализации и прогнозирования. Управление осуществляется через динамическое изменение скоупа и приоритетов.
Условием применимости такого подхода является «антихрупкость» системы в целом, которая обеспечивается регулярным и превентивным применением технических и организационных практик, обязательных для продуктовых команд.



