Ctl hadoop что это
Hadoop – это свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Эта основополагающая технология хранения и обработки больших данных (Big Data) является проектом верхнего уровня фонда Apache Software Foundation.
Из чего состоит Hadoop: концептуальная архитектура
Изначально проект разработан на Java в рамках вычислительной парадигмы MapReduce, когда приложение разделяется на большое количество одинаковых элементарных заданий, которые выполняются на распределенных компьютерах (узлах) кластера и сводятся в единый результат [1].
Проект состоит из основных 4-х модулей:
Сегодня вокруг Hadoop существует целая экосистема связанных проектов и технологий, которые используются для интеллектуального анализа больших данных (Data Mining), в том числе с помощью машинного обучения (Machine Learning) [2].
Как появился хадуп: история разработки и развития
Технология хадуп появилась почти 15 лет назад и постоянно развивается. Далее показаны основные вехи ее истории:
2005 – публикация сотрудников Google Джеффри Дина и Санжая Гемавата о вычислительной концепции MapReduce сподвигла Дуга Каттинга на инициацию проекта. Разработку в режиме частичной занятости вели Дуг Каттинг и Майк Кафарелла, чтобы построить программную инфраструктуру распределённых вычислений для свободной программной поисковой машины на Java. Свое название проект получил в честь игрушечного слонёнка ребёнка основателя [1]. Именно поэтому хадуп неформально называют “железный слон” и изображают его в виде этого животного.
2006 – корпорация Yahoo пригласила Каттинга возглавить специально выделенную команду разработки инфраструктуры распределённых вычислений, благодаря чему Hadoop выделился в отдельный проект [1].
2008 – Yahoo запустила кластерную поисковую машину на 10 тысяч процессорных ядер под управлением Hadoop, который становится проектом верхнего уровня системы проектов Apache Software Foundation. Достигнут мировой рекорд производительности в сортировке данных: за 209 секунд кластер из 910 узлов обработал 1 Тбайт информации. После этого технологию внедряют Last.fm, Facebook, The New York Times, облачные сервисы Amazon EC2 [1].
2010 – корпорация Google предоставила Apache Software Foundation права на использование технологии MapReduce. Hadoop позиционируется как ключевая технология обработки и хранения больших данных (Big Data). Начала формироваться Hadoop-экосистема: возникли продукты Avro, HBase, Hive, Pig, Zookeeper, облегчающие операции управления данными и распределенными приложениями, а также анализ информации [1].
2013 – появление модуля YARN в релизе Hadoop 2.0 значительно расширяет парадигму MapReduce, повышая надежность и масштабируемость распределенных систем [3].
Где и зачем используется Hadoop
Выделяют несколько областей применения технологии [4]:
Все подробности о распределенной обработке данных, администрировании и применении Hadoop для проектов Big Data и Machine Learning на наших компьютерных курсах обучения разных групп пользователей, от «чайников» до профессионалов – хадуп для инженеров, администраторов и аналитиков больших данных в Москве:
Hadoop
Apache Hadoop — это пакет утилит, библиотек и фреймворков, его используют для построения систем, которые работают с Big Data. Он хранит и обрабатывает данные для выгрузки в другие сервисы. У Hadoop открытый исходный код, написанный на языке Java. Это значит, что пользователи могут работать с ним и модифицировать его бесплатно.
Hadoop разделен на кластеры — группу серверов (узлов), которые используют как единый ресурс. Так данные удобнее и быстрее собирать и обрабатывать. Деление позволяет выполнять множество элементарных заданий на разных серверах кластера и выдавать конечный результат. Это нужно в первую очередь для перегруженных сайтов, например Facebook.
Внутри Hadoop существует несколько проектов, которые превратились в отдельные стартапы: Cloudera, MapR и Hortonworks. Эти проекты — дистрибутивы или установочный пакет программы, которые обрабатывают большие данные.
Архитектура Hadoop

Основные компоненты
Hadoop разделен на четыре модуля: такое деление позволяет эффективно справляться с задачами для анализа больших данных.
Hadoop Common — набор библиотек, сценариев и утилит для создания инфраструктуры, аналог командной строки.
Hadoop HDFS (Hadoop Distributed File System) — иерархическая система хранения файлов большого размера с возможностью потокового доступа. Это значит, что HDFS позволяет легко находить и дублировать данные.
HDFS состоит из NameNode и DataNode — управляющего узла и сервера данных. NameNode отвечает за открытие и закрытие файлов и управляет доступом к каталогам и блокам файлов. DataNode — это стандартный сервер, на котором хранятся данные. Он отвечает за запись и чтение данных и выполняет команды NameNode. Отдельный компонент — это client (пользователь), которому предоставляют доступ к файловой системе.
MapReduce — это модель программирования, которая впервые была использована Google для индексации своих поисковых операций. MapReduce построен по принципу «мастер–подчиненные». Главный в системе — сервер JobTracker, раздающий задания подчиненным узлам кластера и контролирующий их выполнение. Функция Map группирует, сортирует и фильтрует несколько наборов данных. Reduce агрегирует данные для получения желаемого результата.
YARN решает, что должно происходить в каждом узле данных. Центральный узел, который управляет всеми запросами на обработку, называется диспетчером ресурсов. Менеджер ресурсов взаимодействует с менеджерами узлов: каждый подчиненный узел данных имеет свой собственный диспетчер узлов для выполнения задач.
Дополнительные компоненты
Hive: хранилище данных
Система хранения данных, которая помогает запрашивать большие наборы данных в HDFS. До Hive разработчики сталкивались с проблемой создания сложных заданий MapReduce для запроса данных Hadoop. Hive использует HQL (язык запросов Hive), который напоминает синтаксис SQL.
Pig: сценарий преобразований данных
Pig преобразовывает входные данные, чтобы получить выходные данные. Pig полезен на этапе подготовки данных, поскольку он может легко выполнять сложные запросы и хорошо работает с различными форматами данных.
Flume: прием больших данных
Flume — это инструмент для приема больших данных, который действует как курьерская служба между несколькими источниками данных и HDFS. Он собирает, объединяет и отправляет огромные объемы потоковых данных (например файлов журналов, событий, созданных десктопными версиями социальных сетей) в HDFS.
Zookeeper: координатор
Zookeeper это сервис-координатор и администратор Hadoop, который распределяет информацию на разные сервера.
Data Scientist с нуля
Получите востребованные IT-навыки за один год и станьте перспективным профессионалом. Мы поможем в трудоустройстве. Дополнительная скидка 5% по промокоду BLOG.
Apache Hadoop
Платформа с открытым исходным кодом для распределенной обработки огромных объемов больших данных в вычислительных кластерах с помощью простых моделей программирования
Что представляет собой Apache Hadoop?
Apache Hadoop® — это платформа с открытым исходным кодом для надежной, масштабируемой, распределенной обработки больших наборов данных с помощью простых моделей программирования. Hadoop работает в кластерах стандартных компьютеров и представляет собой экономически эффективное решение для хранения и обработки структурированных, частично структурированных и неструктурированных данных без ограничений на их форматы. Благодаря этому Hadoop идеально подходит для создания озер данных в поддержку инициатив в сфере анализа больших данных.
Примеры применения Hadoop
Оптимизация решений на основе данных в реальном времени
Обработка данных в новых форматах (потоковое аудио, видео, настроения в социальных сетях и результаты анализа действий пользователей), частично структурированных и неструктурированных данных, которые, как правило, не применяются в хранилищах. Более полные данные помогают принимать более точные аналитические решения в отношении новых технологий, таких как искусственный интеллект (ИИ) и Интернет вещей (IoT).
Оптимизация доступа к данным и анализа
Hadoop помогает организовать доступ к данным в режиме самообслуживания в реальном времени для экспертов по наукам о данных, ответственных специалистов по направлениям бизнеса (LOB) и разработчиков. Hadoop способствует развитию наук о данных — междисциплинарной области, объединяющей машинное обучение, статистику, расширенную аналитику и программирование.
Выгрузка и консолидация данных
Оптимизируйте и сократите затраты на корпоративное хранилище данных за счет переноса редко используемых («холодных») данных в Hadoop. Также можно консолидировать данные в масштабах всей организации для повышения их доступности, сокращения затрат и повышения точности решений на основе данных.
Hadoop в мире BigData
Сегодня говорим о самом популярном животном в зоопарке BigData — Hadoop. Так зовут “маленького” слоника, который перевернул мир данных и спас мир, когда привычные SQL базы данных спасовали. Итак, знакомьтесь:
Hadoop — это фреймворк, состоящий из набора утилит для разработки и выполнения программ распределенных вычислений.

Идея родилась в 2004 году: Google публикует работу, в которой рассказывает о технологии BigTable и MapReduce (на которой сейчас держатся NoSQL-базы данных). В 2006 Yahoo выпускает открытую реализацию и дает ей имя Hadoop. В 2010 году была создана экосистема технологий, делающая Hadoop применимой и популярной.
Зачем нужен Hadoop?
Объем данных за последние несколько лет растет с большой скоростью и обещает продолжать в том же духе. Именно это и послужило предпосылкой для написания Google вышеупомянутой работы: стандартные базы данных больше не могли поддерживать работоспособность при таком темпе.
Один из многих графиков, отражающих этот стремительный рост:
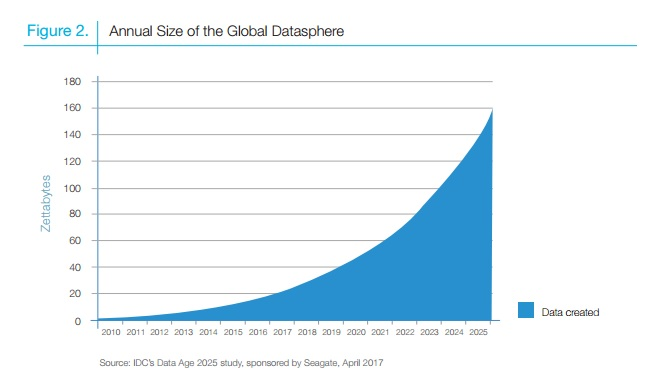
Рост объема мировых данных по годам. Источник: seagate.com
Обработка, хранение и все вытекающие действия с такими объемами данных и есть Big Data. Hadoop — технология работы с BigData.
У Hadoop хороший послужной список: eBay, Amazon, IBM, Facebook и т.д. Нет единой схемы для работы с данными абсолютно любой компании: работа всех сервисов, даже не слишком больших, очень специфична. Поэтому на основной функционал накладываются дополнительные фичи, разработанные специально для конкретных компаний.
Тут мы имеем дело с дистрибутивами. В случае с Hadoop дистрибутив означает набор установочных файлов для различных сервисов экосистемы. Под каждый кейс нужно подбирать свой набор подсистем Hadoop: это обеспечит совместимость всех версий компонентов. Поставляют и настраивают дистрибутивы вендоры дистрибутивов. Самые популярные от Cloudera, MapR, HDP.
А так ли нужно переплачивать за дистрибутив, если можно все установить самостоятельно? Этот вопрос помогает представить Hadoop как экосистему. Да, Hadoop настолько сложен в своем составе и обладает таким большим количеством составляющих, что установка и настройка этих инструментов — вполне надежный хлеб для нескольких компаний.
Разнообразие в экосистеме Hadoop делает этого слона универсальным инструментом, меняющимся вместе со временем.
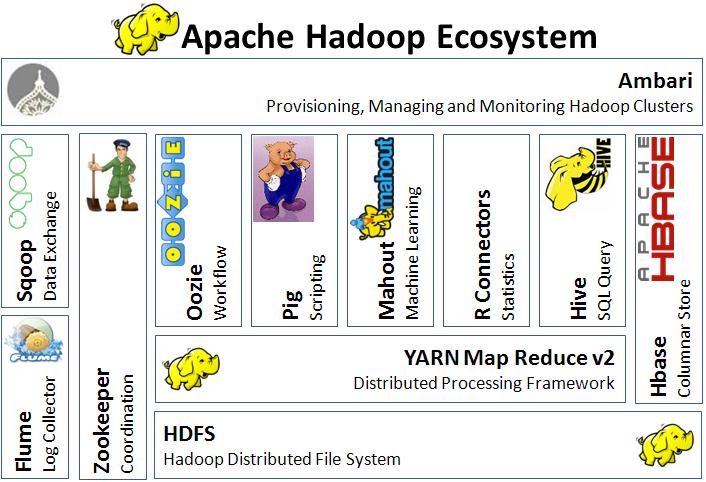
Hadoop — это система, состоящая из нескольких компонентов. Основные: HDFS и MapReduce. Первое — файловая система, второе — фреймворк обработки данных.
Основные принципы Hadoop:
Представим, что в кластере произошли неполадки, не хватает ресурсов имеющихся серверов. Есть две модели поведения:
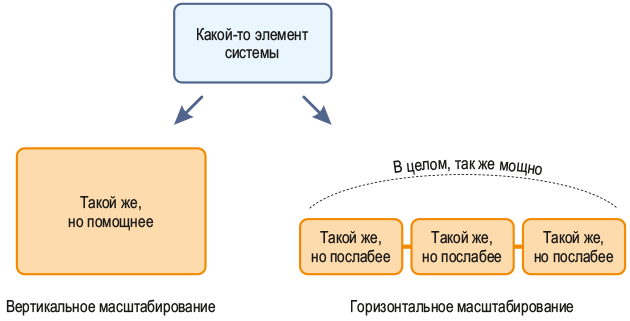
Hadoop заточен под второй вариант. Основная причина — при горизонтальном масштабировании ресурсы кластера практически не ограничены, его можно расширять бесконечно.
II. Код отправляется к данным, а не наоборот
Есть подход, при котором выделяются сервера для хранения данных и их обработки. Поэтому при работе большие объемы данных приходится передавать между этими серверами. Это энергозатратно, тяжело и долго.
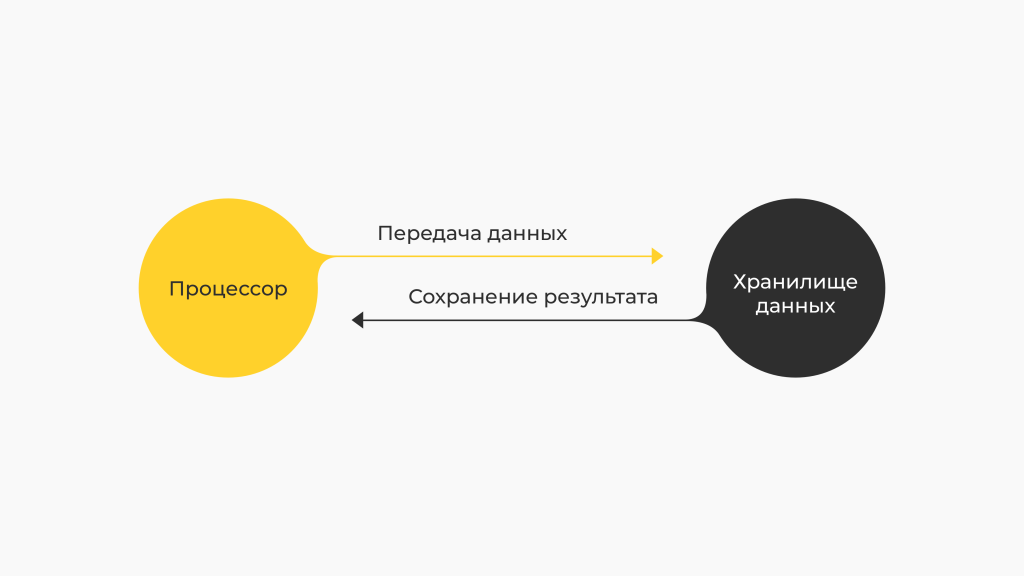
Hadoop поступает умнее:
Когда нам нужно обработать данные, мы не переносим их все на сервер обработки, а копируем нужную часть кода и переносим её к данным. Система работает быстрее, легче.
При работе Hadoop учитывает возможность отказа железа целыми двумя механизмами:
Из принципов I, II и III следует одно из главных преимуществ Hadoop: кластер машин может состоять из обычных серверов без невероятных запросов к отказоустойчивости.
IV. Инкапсуляция сложности реализации

Звучит непонятно. Это значит, что пользователь только продумывает, каким образом он хочет обрабатывать данные, больше фокусируется на бизнес-логике процесса, чем на программной части.
Кто изучает Hadoop?
Те, кто работает с BigData: аналитики и разработчики в этой сфере. Часто это работники банков, IT-компаний, крупные сервисы с большой клиентской базой.
Далее, подключайте все источники!
Hadoop: The Definitive Guide by Tom White
Следует воспринимать её как учебник и обращаться к главам в случае необходимости
Hadoop: введение в системы больших данных
Apache Hadoop – один из важнейших открытых инструментов для хранения и обработки большого количества цифровых данных, накопленных с ростом World Wide Web. Он развился из открытого проекта под названием Nutch, который предназначался для поиска в Интернете. Создатели Nutch были в большой степени подвержены влиянию Google. В конечном итоге функции хранения и обработки были выделены в проект Hadoop, а Nutch разрабатывается как инструмент поиска.
Данная статья расскажет, что такое системы больших данных.
Системы данных
Данные существуют повсюду: на клочках бумаги, в книгах, на фотографиях, в мультимедийных файлах, логах сервера и на веб-сайтах. Когда эти данные собираются целенаправленно, они входят в систему данных.
Представьте себе школьный проект, в котором ученики ежедневно измеряют уровень воды в близлежащем ручье. Они записывают свои измерения, возвращаются в свой класс и вводят эти данные в электронную таблицу. Когда они соберут достаточное количество информации, они будут анализировать ее. Они могут сравнить данные за один тот же месяц в разные годы и определить самый высокий или самый низкий уровень воды. Они могут создать графики для определения тенденций.
Этот проект хорошо иллюстрирует систему данных:
Этот проект – очень простой пример системы данных. Один компьютер может хранить, анализировать и отображать ежедневные измерения уровня воды в одном ручье. А теперь представьте весь контент на всех веб-страницах в мире – несоизмеримо больший набор данных. Это большие данные: столько информации не может поместиться на одном компьютере.
Чем отличаются большие данные?
Статьи Google и реализация этих идей в Hadoop основаны на четырех изменениях в восприятии данных, которые необходимы для учета объема данных:
Выпущенная в 2007 году версия 1.0 основанного на Java фреймвока Hadoop стала первым открытым проектом, который учитывал все эти изменения. Его первая версия состоит из двух уровней:
HDFS 1.0
Распределенная файловая система Hadoop, HDFS, представляет собой уровень хранения, который Hadoop использует для распространения и надлежащего хранения данных для обеспечения высокой доступности.
Как работает HDFS 1.0?
Для надежного хранения очень больших файлов на нескольких компьютерах HDFS использует блочную репликацию на основе двух компонентов программного обеспечения: это сервер NameNode, который управляет пространством имен файловой системы и доступом клиентов, а также DataNodes, ответственный за выполнение запросов на чтение и запись, создание блоков, удаление и репликацию. Базовое понимание шаблона репликации полезно для разработчиков и администраторов кластеров, поскольку дисбаланс в распределении данных может повлиять на производительность кластера и потребовать дополнительной настройки.
HDFS хранит каждый файл в виде последовательности блоков, все они одного размера, за исключением последнего. По умолчанию блоки реплицируются три раза, но размер блоков и количество реплик можно настроить для каждого файла индивидуально. Файлы не перезаписываются.
NameNode принимает все решения о репликации блоков на основе алгоритма пульсации и отчетов, которые он получает от каждого DataNode в кластере. Алгоритм пульсации позволяет убедиться, что DataNode работает, а отчет о блоках предоставляет список всех блоков в DataNode.
Когда создается новый блок, HDFS помещает первую реплику на ноду, где выполняется запись. Вторая реплика сохраняется на случайно выбранной ноде в этом же раке (это не может быть та же нода, где была записана первая реплика). Затем третья реплика помещается на случайно выбранную машину о втором раке. Если в конфигурации указано больше трех реплик (по умолчанию), оставшиеся реплики помещаются случайным образом, при этом действует такое ограничение: не более одной реплики на ноду, не более двух реплик на рак.
Ограничения HDFS 1.0
HDFS 1.0 сделал Hadoop лидером среди открытых инструментов для хранения больших данных. Отчасти этот успех был вызван решениями в архитектуре, которые упростили распределенное хранение. Но при этом ограничения оставались. К основным ограничениям версии 1.0 относятся:
Несмотря на эти ограничения, HDFS сделал большой вклад в работу с большими данными.
MapReduce 1.0
Второй уровень Hadoop – MapReduce – отвечает за пакетную обработку данных, хранящихся на HDFS. Внедрение в Hadoop модели Google MapReduce позволяет разработчикам использовать ресурсы HDFS без параллельных и распределенных систем.
Как работает MapReduce 1.0
Предположим, у вас есть текст, и вы хотите знать, сколько раз в нем появляется каждое слово. Текст распределяется между несколькими серверами, поэтому задачи сопоставления выполняются на всех нодах кластера, в которых есть блоки данных. Каждый маппер загружает соответствующие файлы, обрабатывает их и создает пару ключевых значений для каждого события.
Каждый маппер имеет данные только одной ноды, поэтому их необходимо перетасовать, чтобы отправить на редуктор все значения с одним и тем же ключом. Результат редуктора записывается на его диск. Эта неявная модель взаимодействия освобождает пользователей Hadoop от явного перемещения информации с одной машины на другую.
Давайте рассмотрим, как это работает на таком примере:
Если бы это сопоставление выполнялось последовательно над большим набором данных, это потребовало бы слишком много времени, но благодаря параллельности процессов и сокращению эту процедуру можно масштабировать для больших наборов данных.
Компоненты более высокого уровня могут подключаться к MapReduce для предоставления дополнительных функций. Например, Apache Pig предоставляет разработчикам язык для написания программ анализа данных, абстрагируя идиомы Java MapReduce на более высокий уровень (аналогично тому, что делает SQL для реляционных баз данных). Apache Hive поддерживает анализ данных и отчетность с помощью SQL-подобного интерфейса для HDFS. Он абстрагирует запросы MapReduce Java API для обеспечения функциональности запросов высокого уровня. Для Hadoop 1.x доступно множество дополнительных компонентов, но экосистема MapReduce также имеет некоторые ограничения.
Ограничения MapReduce 1
Улучшения в Hadoop 2.x
Ветка Hadoop 2.х, выпущенная в декабре 2011 года, представила четыре основных усовершенствования и исправила ключевые ограничения версии 1. Hadoop 2.0 устраняет ограничение производительности и единую точку отказа NameNode. Кроме того, он отделяет MapReduce от HDFS с введением YARN (Yet Another Resource Negotiator), открыв экосистему дополнительных продуктов и разрешив моделям обработки взаимодействовать с HDFS и обходить слой MapReduce.
1: Федерация HDFS
Федерация HDFS вводит четкое разделение пространства имен и хранилища, что делает возможным наличие нескольких пространств имен в кластере. Благодаря этому появляются такие улучшения:
Как работает федерация HDFS
Федерация управляет пространством имен файловой системы. NameNodes работают независимо и не координируются друг с другом. DataNodes регистрируются в кластере с каждым NameNode, отправляют пульс и отчеты блоков и обрабатывают входящие команды из NameNode.
Блоки распространяются по всему хранилищу с той же случайной репликацией, что и в Hadoop 1.x. Все блоки, принадлежащие одному пространству имен, называются пулом блоков. Такие пулы управляются независимо, позволяя пространству имен генерировать идентификаторы блоков для новых блоков без согласования с другими пространствами имен. Комбинация пространства имен и пула блоков называется томом пространства имен; том формирует автономный блок, так что когда один из NameNode удаляется, его пул блоков удаляется вместе с ним.
Помимо улучшенной масштабируемости, производительности и изоляции, Hadoop 2.0 также обеспечил высокую доступность NameNodes.
2: Высокая доступность NameNode
Если в предыдущих версиях NameNode прекращал работу, весь кластер был недоступен, пока NameNode не перезапустится или не появится на новом компьютере. Модернизация программного или аппаратного обеспечения NameNode также создавала окна простоя. Чтобы предотвратить это, Hadoop 2.0 реализовал конфигурацию active/passive, чтобы обеспечить быстрый переход на другой ресурс.
Как работает высокая доступность NameNode
Две отдельные машины настроены как NameNodes, одна из них активна, другая находится в режиме ожидания. Они совместно используют каталог на общем устройстве хранения. Когда активная нода вносит изменения, она записывает его в лог, хранящийся в этом общем каталоге. Резервная нода постоянно наблюдает за каталогом и когда происходит редактирование, она применяет эти изменения к собственному пространству имен. Если активная нода выходит из строя, резервная нода читает непримененные изменения из общего хранилища, а затем переходит в режим активной ноды.
3: YARN
Hadoop 2.0 отделяет MapReduce от HDFS. Управление рабочими нагрузками, многоуровневым обслуживанием, безопасностью и функциями высокой доступности было выделено в YARN (Yet Another Resource Negotiator). YARN – это, по сути, крупномасштабная распределенная операционная система для приложений больших данных, которая позволяет использовать Hadoop как для MapReduce, так и для других приложений, которые не могут дождаться завершения пакетной обработки. YARN устранил необходимость работы через инфраструктуру MapReduce с высокой задержкой ввода-вывода, что позволяет использовать новые модели обработки HDFS.
У пользователей Hadoop 2.x есть доступ к таким моделям обработки.
Это лишь несколько альтернативных моделей и инструментов обработки. Подробное руководство по экосистеме Hadoop можно найти здесь.
4: Высокая доступность ResourceManager
В первом релизе YARN было свое узкое место: ResourceManager. Единственный JobTracker в MapReduce 1.x обрабатывал управление ресурсами, планирование задач и мониторинг работы. Ранние релизы YARN улучшили это, разделив обязанности между глобальным ResourceManager и ApplicationMaster для каждого приложения. ResourceManager отслеживал ресурсы кластера и планировал приложения, такие как MapReduce Jobs, но был единственной точкой отказа до версии 2.4, в которой была представлена архитектура Active/Standby.
В Hadoop 2.4 единый ResourceManager был заменен одним активным ResourceManager и одним или несколькими резервными. В случае сбоя активного ResourceManager администраторы могут вручную активировать один из менеджеров. Чтобы обеспечить автоматический переход на другой ресурс, можно добавить в свой стек Apache Zookeeper. Помимо прочих обязанностей по координации задач, Zookeeper может отслеживать состояние нод YARN и в случае сбоя автоматически запускать переход в режим ожидания.



