CROSS APPLY / OUTER APPLY стр. 2
А теперь представьте, что нам нужно, помимо максимальной цены, вывести минимальную, среднюю цены и т.д. Поскольку коррелирующий подзапрос в предложении SELECT должен возвращать только одно значение, в первом варианте решения нам придется фактически дублировать код для каждого агрегата:
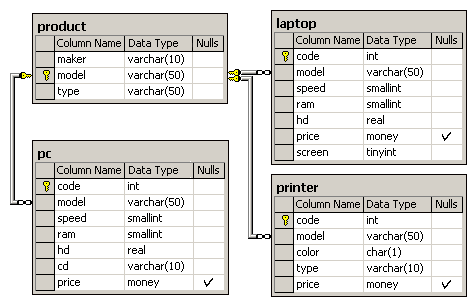
А при использовании CROSS APPLY мы просто добавим в подзапрос требуемую агрегатную функцию:
Рассмотрим еще один пример.
Соединить каждую строку из таблицы Laptop со следующей строкой в порядке, заданном сортировкой (model, code).
Попробуйте решить эту задачу традиционными средствами, чтобы сравнить трудозатраты.
Оператор OUTER APPLY
Как показывают результаты предыдущего запроса, мы «потеряли» последнюю (шестую) строку из таблицы Laptop, поскольку ее не с чем соединять. Другими словами, CROSS APPLY ведет себя как внутренне соединение. Аналогом же внешнего (левого) соединения является оператор OUTER APPLY. Он отличается от CROSS APPLY только тем, что выводит все строки из левой таблицы, заменяя отсутствующие значения из правой таблицы NULL-значениями.
Замена CROSS APPLY на OUTER APPLY в предыдущем запросе иллюстрирует сказанное.
Еще одной популярной задачей является вывод по N строк из каждой группы. Примером может служить вывод 5 наиболее популярных товаров в каждой категории. Рассмотрим следующую задачу.
Вывести из таблицы Product по три модели с наименьшими номерами из каждой группы, характеризуемой типом продукции.
Оператор CROSS APPLY в T-SQL
Всем привет! Сегодня мы поговорим о достаточно полезном операторе CROSS APPLY языка T-SQL, Вы узнаете, что это за оператор и как его использовать на практике. В статье рассмотрено несколько SQL запросов с применением оператора CROSS APPLY, а также OUTER APPLY.

CROSS APPLY в T-SQL
CROSS APPLY – это тип оператора APPLY, который позволяет вызывать табличную функцию для каждой строки внешнего табличного выражения. Вместо табличной функции можно также использовать и вложенный запрос, который возвращает производную таблицу.
Есть еще и другой тип OUTER APPLY, он в отличие от CROSS APPLY возвращает и строки, которые формируют результирующий набор, и те, которые этого не делают, т.е. со значениями NULL в столбцах. Например, табличная функция может не возвращать никаких данных для определенных значений, CROSS APPLY в таких случаях подобные строки не выводит, а OUTER APPLY выводит.
Примеры использования CROSS APPLY в T-SQL
Давайте рассмотрим несколько примеров использования операторов CROSS APPLY и OUTER APPLY в языке T-SQL.
Исходные данные для примеров
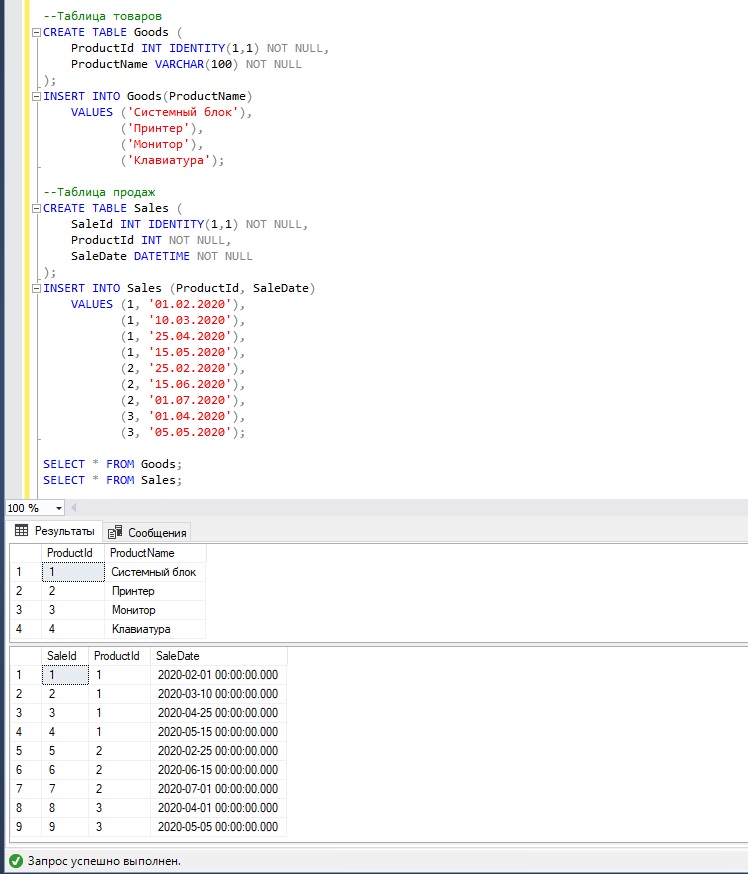
Для начала давайте определимся с исходными данными, которые мы будем использовать в примерах, допустим, у нас есть таблица товаров (Goods) и таблица продаж (Sales).
SQL инструкция ниже создаёт эти таблицы и наполняет их тестовыми данными.
А также у нас есть табличная функция SaleGoods, которая просто выводит список продаж по идентификатору товара.
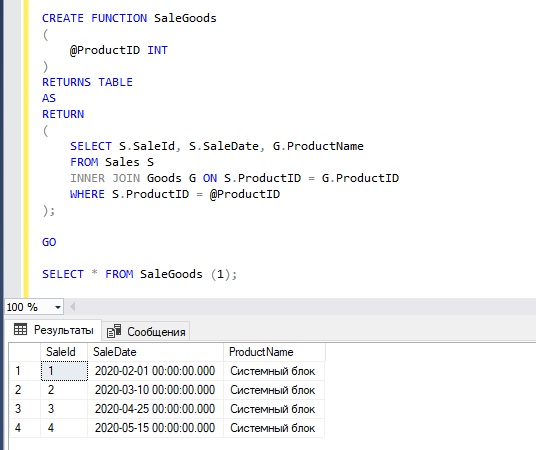
Заметка! Если Вы не знаете, что делает вышеуказанная инструкция, рекомендую посмотреть мой видеокурс «T-SQL. Путь программиста от новичка к профессионалу. Уровень 1 – Новичок», который предназначен для начинающих и в нем подробно рассмотрены все базовые конструкции языка SQL, включая все вышеперечисленные.
Пример использования CROSS APPLY с табличной функцией
Теперь допустим, нам необходимо получить продажи не только одного товара, но и других, для этого мы можем использовать оператор CROSS APPLY.
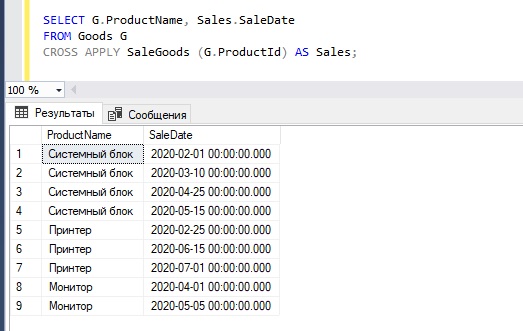
Где, как Вы понимаете, табличная функция SaleGoods была вызвана для каждой строки таблицы Goods.
Пример использования CROSS APPLY с подзапросом
Как уже было сказано выше, CROSS APPLY можно использовать и с подзапросом, для примера давайте представим, что нам нужно получить последнюю дату продажи каждого товара.
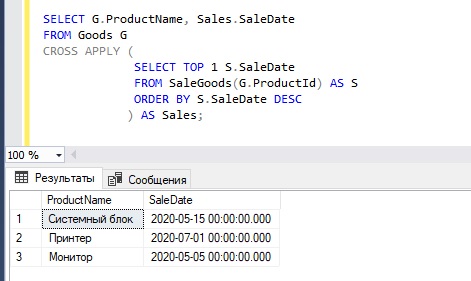
Как видим, после CROSS APPLY у нас идет вложенный запрос, формирующий производную таблицу.
Пример использования OUTER APPLY
Если Вы заметили, у нас в исходных данных есть позиция «Клавиатура», по которой не было продаж. И в случае возникновения необходимости получить последнюю дату продажи, включая товары, по которым не было продаж, т.е. выводить NULL значения, чтобы мы видели, какие товары не продавались вообще, оператор CROSS APPLY можно заменить на OUTER APPLY.
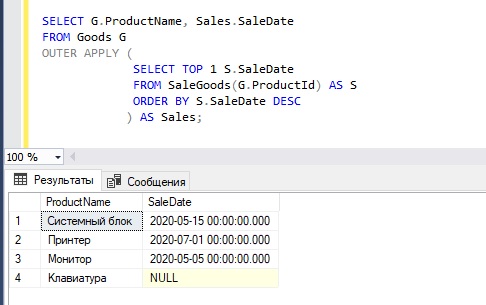
Теперь видно, что некоторые товары продавались и последняя дата их продажи такая-то, а некоторые товары не продавались, т.е. у них отсутствует дата продажи.
Интересные материалы по теме:
Нарастающий итог в SQL
Нарастающий (накопительный) итог долго считался одним из вызовов SQL. Что удивительно, даже после появления оконных функций он продолжает быть пугалом (во всяком случае, для новичков). Сегодня мы рассмотрим механику 10 самых интересных решений этой задачи – от оконных функций до весьма специфических хаков.
В электронных таблицах вроде Excel нарастающий итог вычисляется очень просто: результат в первой записи совпадает с её значением:

… а затем мы суммируем текущее значение и предыдущий итог.


Появление в таблице двух и более групп несколько усложняет задачу: теперь мы считаем несколько итогов (для каждой группы отдельно). Впрочем, и здесь решение лежит на поверхности: необходимо каждый раз проверять, к какой группе принадлежит текущая запись. Click and drag, и работа выполнена:
Как можно заметить, подсчёт нарастающего итога связан с двумя неизменными составляющими:
(а) сортировкой данных по дате и
(б) обращением к предыдущей строке.
Но что SQL? Очень долго в нём не было нужного функционала. Необходимый инструмент – оконные функции – впервые появился только стандарте SQL:2003. К этому моменту они уже были в Oracle (версия 8i). А вот реализация в других СУБД задержалась на 5-10 лет: SQL Server 2012, MySQL 8.0.2 (2018 год), MariaDB 10.2.0 (2017 год), PostgreSQL 8.4 (2009 год), DB2 9 для z/OS (2007 год), и даже SQLite 3.25 (2018 год).
1. Оконные функции
Оконные функции – вероятно, самый простой способ. В базовом случае (таблица без групп) мы рассматриваем данные, отсортированные по дате:
… но нас интересуют только строки до текущей:
В конечном итоге, нам нужна сумма с этими параметрами:
А полный запрос будет выглядеть так:
В случае нарастающего итога по группам (поле grp ) нам требуется только одна небольшая правка. Теперь мы рассматриваем данные как разделённые на «окна» по признаку группы:
Чтобы учесть это разделение необходимо использовать ключевое слово partition by :
И, соответственно, считать сумму по этим окнам:
Тогда весь запрос преобразуется таким образом:
Производительность оконных функций будет зависеть от специфики вашей СУБД (и её версии!), размеров таблицы, и наличия индексов. Но в большинстве случаев этот метод будет самым эффективным. Тем не менее, оконные функции недоступны в старых версиях СУБД (которые ещё в ходу). Кроме того, их нет в таких СУБД как Microsoft Access и SAP/Sybase ASE. Если необходимо вендоро-независимое решение, следует обратить внимание на альтернативы.
2. Подзапрос
Как было сказано выше, оконные функции были очень поздно введены в основных СУБД. Эта задержка не должна удивлять: в реляционной теории данные не упорядочены. Куда больше духу реляционной теории соответствует решение через подзапрос.
Такой подзапрос должен считать сумму значений с датой до текущей (и включая текущую):  .
.
Что в коде выглядит так:
Чуть более эффективным будет решение, в котором подзапрос считает итог до текущей даты (но не включая её), а затем суммирует его со значением в строке:
В случае нарастающего итога по нескольким группам нам необходимо использовать коррелированный подзапрос:
Условие g.grp = t2.grp проверяет строки на вхождение в группу (что, в принципе, сходно с работой partition by grp в оконных функциях).
3. Внутреннее соединение
Поскольку подзапросы и джойны взаимозаменяемы, мы легко можем заменить одно на другое. Для этого необходимо использовать Self Join, соединив два экземпляра одной и той же таблицы:
Точно также можно сделать для случая с разными группами grp :
4. Декартово произведение
Раз уж мы заменили подзапрос на join, то почему бы не попробовать декартово произведение? Это решение потребует только минимальных правок:
Или для случая с группами:
Перечисленные решения (подзапрос, inner join, cartesian join) соответсвуют SQL-92 и SQL:1999, а потому будут доступны практически в любой СУБД. Основная проблема всех этих решений в низкой производительности. Это не велика беда, если мы материализуем таблицу с результатом (но ведь всё равно хочется большей скорости!). Дальнейшие методы куда более эффективны (с поправкой на уже указанные специфику конкретных СУБД и их версий, размер таблицы, индексы).
5. Рекурсивный запрос
Один из более специфических подходов – это рекурсивный запрос в common table expression. Для этого нам необходим «якорь» – запрос, возвращающий самую первую строку:
Часть кода, добавляющая один день, не универсальна. Например, это r.dt = dateadd(day, 1, cte.dt) для SQL Server, r.dt = cte.dt + 1 для Oracle, и т.д.
Совместив «якорь» и основной запрос, мы получим окончательный результат:
Решение для случая с группами будет ненамного сложнее:
6. Рекурсивный запрос с функцией row_number()
Итак, для рекурсивного запроса с row_number() нам понадобится два СТЕ. В первом мы только нумеруем строки:
… и если номер строки уже есть в таблице, то можно без него обойтись. В следующем запросе обращаемся уже к cte1 :
А целиком запрос выглядит так:
… или для случая с группами:
7. Оператор CROSS APPLY / LATERAL
Один из самых экзотических способов расчёта нарастающего итога – это использование оператора CROSS APPLY (SQL Server, Oracle) или эквивалентного ему LATERAL (MySQL, PostgreSQL). Эти операторы появились довольно поздно (например, в Oracle только с версии 12c). А в некоторых СУБД (например, MariaDB) их и вовсе нет. Поэтому это решение представляет чисто эстетический интерес.
Функционально использование CROSS APPLY или LATERAL идентично подзапросу: мы присоединяем к основному запросу результат вычисления:
… что целиком выглядит так:
Похожим будет и решение для случая с группами:
Итого: мы рассмотрели основные платформо-независимые решения. Но остаются решения, специфичные для конкретных СУБД! Поскольку здесь возможно очень много вариантов, остановимся на нескольких наиболее интересных.
8. Оператор MODEL (Oracle)
Оператор MODEL в Oracle даёт одно из самых элегантных решений. В начале статьи мы рассмотрели общую формулу нарастающего итога:
MODEL позволяет реализовать эту формулу буквально один к одному! Для этого мы сначала заполняем поле total значениями текущей строки
Функция cv() здесь отвечает за значение текущей строки. А весь запрос будет выглядеть так:
9. Курсор (SQL Server)
Нарастающий итог – один из немногих случаев, когда курсор в SQL Server не только полезен, но и предпочтителен другим решениям (как минимум до версии 2012, где появились оконные функции).
Реализация через курсор довольно тривиальна. Сначала необходимо создать временную таблицу и заполнить её датами и значениями из основной:
Затем задаём локальные переменные, через которые будет происходить обновление:
После этого обновляем временную таблицу через курсор:
И, наконец, получем нужный результат:
10. Обновление через локальную переменную (SQL Server)
Обновление через локальную переменную в SQL Server основано на недокументированном поведении, поэтому его нельзя считать надёжным. Тем не менее, это едва ли не самое быстрое решение, и этим оно интересно.
Создадим две переменные: одну для нарастающих итогов и табличную переменную:
Сначала заполним @tv данным из основной таблицы
Затем табличную переменную @tv обновим, используя @VarTotal :
… после чего получим окончательный результат:
Резюме: мы рассмотрели топ 10 способов расчёта нарастающего итога в SQL. Как можно заметить, даже без оконных функций эта задача вполне решаема, причём механику решения нельзя назвать сложной.
Учебник по языку SQL (DDL, DML) на примере диалекта MS SQL Server. Часть четвертая
Предыдущие части
В данной части мы рассмотрим
Добавим немного новых данных
Для демонстрационных целей добавим несколько отделов и должностей:
JOIN-соединения – операции горизонтального соединения данных
Здесь нам очень пригодится знание структуры БД, т.е. какие в ней есть таблицы, какие данные хранятся в этих таблицах и по каким полям таблицы связаны между собой. Первым делом всегда досконально изучайте структуру БД, т.к. нормальный запрос можно написать только тогда, когда ты знаешь, что откуда берется. У нас структура состоит из 3-х таблиц Employees, Departments и Positions. Приведу здесь диаграмму из первой части:
Если суть РДБ – разделяй и властвуй, то суть операций объединений снова склеить разбитые по таблицам данные, т.е. привести их обратно в человеческий вид.
Если говорить просто, то операции горизонтального соединения таблицы с другими таблицами используются для того, чтобы получить из них недостающие данные. Вспомните пример с еженедельным отчетом для директора, когда при запросе из таблицы Employees, нам для получения окончательного результата недоставало поля «Название отдела», которое находится в таблице Departments.
Понимание каждого вида соединения очень важно, т.к. от применения того или иного вида, результат запроса может отличаться. Сравните результаты одного и того же запроса с применением разного типа соединения, попробуйте пока просто увидеть разницу и идите дальше (мы сюда еще вернемся):
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 1 | Администрация |
| 1003 | Андреев А.А. | 3 | 1 | Администрация |
| 1004 | Николаев Н.Н. | 3 | 1 | Администрация |
| 1005 | Александров А.А. | NULL | 1 | Администрация |
| 1000 | Иванов И.И. | 1 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 2 | Бухгалтерия |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 2 | Бухгалтерия |
| 1004 | Николаев Н.Н. | 3 | 2 | Бухгалтерия |
| 1005 | Александров А.А. | NULL | 2 | Бухгалтерия |
| 1000 | Иванов И.И. | 1 | 3 | ИТ |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | 3 | ИТ |
| 1000 | Иванов И.И. | 1 | 4 | Маркетинг и реклама |
| 1001 | Петров П.П. | 3 | 4 | Маркетинг и реклама |
| 1002 | Сидоров С.С. | 2 | 4 | Маркетинг и реклама |
| 1003 | Андреев А.А. | 3 | 4 | Маркетинг и реклама |
| 1004 | Николаев Н.Н. | 3 | 4 | Маркетинг и реклама |
| 1005 | Александров А.А. | NULL | 4 | Маркетинг и реклама |
| 1000 | Иванов И.И. | 1 | 5 | Логистика |
| 1001 | Петров П.П. | 3 | 5 | Логистика |
| 1002 | Сидоров С.С. | 2 | 5 | Логистика |
| 1003 | Андреев А.А. | 3 | 5 | Логистика |
| 1004 | Николаев Н.Н. | 3 | 5 | Логистика |
| 1005 | Александров А.А. | NULL | 5 | Логистика |
Настало время вспомнить про псевдонимы таблиц
Пришло время вспомнить про псевдонимы таблиц, о которых я рассказывал в начале второй части.
В многотабличных запросах, псевдоним помогает нам явно указать из какой именно таблицы берется поле. Посмотрим на пример:
В нем поля с именами ID и Name есть в обоих таблицах и в Employees, и в Departments. И чтобы их различать, мы предваряем имя поля псевдонимом и точкой, т.е. «emp.ID», «emp.Name», «dep.ID», «dep.Name».
Вспоминаем почему удобнее пользоваться именно короткими псевдонимами – потому что, без псевдонимов наш запрос бы выглядел следующим образом:
По мне, стало очень длинно и хуже читаемо, т.к. имена полей визуально потерялись среди повторяющихся имен таблиц.
В многотабличных запросах, хоть и можно указать имя без псевдонима, в случае если имя не дублируется во второй таблице, но я бы рекомендовал всегда использовать псевдонимы в случае соединения, т.к. никто не гарантирует, что поле с таким же именем со временем не добавят во вторую таблицу, а тогда ваш запрос просто сломается, ругаясь на то что он не может понять к какой таблице относится данное поле.
Только используя псевдонимы, мы сможем осуществить соединения таблицы самой с собой. Предположим встала задача, получить для каждого сотрудника, данные сотрудника, который был принят прямо до него (табельный номер отличается на единицу меньше). Допустим, что у нас табельные номера выдаются последовательно и без дырок, тогда мы можем это сделать примерно следующим образом:
Т.е. здесь одной таблице Employees, мы дали псевдоним «e1», а второй «e2».
Разбираем каждый вид горизонтального соединения
Для этой цели рассмотрим 2 небольшие абстрактные таблицы, которые так и назовем LeftTable и RightTable:
Посмотрим, что в этих таблицах:
| LCode | LDescr |
|---|---|
| 1 | L-1 |
| 2 | L-2 |
| 3 | L-3 |
| 5 | L-5 |
| RCode | RDescr |
|---|---|
| 2 | B-2 |
| 3 | B-3 |
| 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
Здесь были возвращены объединения строк для которых выполнилось условие (l.LCode=r.RCode)
LEFT JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
Здесь были возвращены все строки LeftTable, которые были дополнены данными строк из RightTable, для которых выполнилось условие (l.LCode=r.RCode)
RIGHT JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Здесь были возвращены все строки RightTable, которые были дополнены данными строк из LeftTable, для которых выполнилось условие (l.LCode=r.RCode)
По сути если мы переставим LeftTable и RightTable местами, то аналогичный результат мы получим при помощи левого соединения:
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Я за собой заметил, что я чаще применяю именно LEFT JOIN, т.е. я сначала думаю, данные какой таблицы мне важны, а потом думаю, какая таблица/таблицы будет играть роль дополняющей таблицы.
FULL JOIN – это по сути одновременный LEFT JOIN + RIGHT JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
Вернулись все строки из LeftTable и RightTable. Строки для которых выполнилось условие (l.LCode=r.RCode) были объединены в одну строку. Отсутствующие в строке данные с левой или правой стороны заполняются NULL-значениями.
CROSS JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | 2 | B-2 |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 2 | B-2 |
| 5 | L-5 | 2 | B-2 |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2 | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2 | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Каждая строка LeftTable соединяется с данными всех строк RightTable.
Возвращаемся к таблицам Employees и Departments
Надеюсь вы поняли принцип работы горизонтальных соединений. Если это так, то возвратитесь на начало раздела «JOIN-соединения – операции горизонтального соединения данных» и попробуйте самостоятельно понять примеры с объединением таблиц Employees и Departments, а потом снова возвращайтесь сюда, обсудим это вместе.
Давайте попробуем вместе подвести резюме для каждого запроса:
| Запрос | Резюме |
|---|---|
| По сути данный запрос вернет только сотрудников, у которых указано значение DepartmentID. Т.е. мы можем использовать данное соединение, в случае, когда нам нужны данные по сотрудникам числящихся за каким-нибудь отделом (без учета внештаткиков). | |
| Вернет всех сотрудников. Для тех сотрудников у которых не указан DepartmentID, поля «dep.ID» и «dep.Name» будут содержать NULL. Вспоминайте, что NULL значения в случае необходимости можно обработать, например, при помощи ISNULL(dep.Name,’вне штата’). Этот вид соединения можно использовать, когда нам важно получить данные по всем сотрудникам, например, чтобы получить список для начисления ЗП. | |
| Здесь мы получили дырки слева, т.е. отдел есть, но сотрудников в этом отделе нет. Такое соединение можно использовать, например, когда нужно выяснить, какие отделы и кем у нас заняты, а какие еще не сформированы. Эту информацию можно использовать для поиска и приема новых работников из которых будет формироваться отдел. | |
| Этот запрос важен, когда нам нужно получить все данные по сотрудникам и все данные по имеющимся отделам. Соответственно получаем дырки (NULL-значения) либо по сотрудникам, либо по отделам (внештатники). Данный запрос, например, может использоваться в целях проверки, все ли сотрудники сидят в правильных отделах, т.к. может у некоторых сотрудников, которые числятся как внештатники, просто забыли указать отдел. | |
| В таком виде даже сложно придумать где это можно применить, поэтому пример с CROSS JOIN я покажу ниже. |
Обратите внимание, что в случае повторения значений DepartmentID в таблице Employees, произошло соединение каждой такой строки со строкой из таблицы Departments с таким же ID, то есть данные Departments объединились со всеми записями для которых выполнилось условие (emp.DepartmentID=dep.ID):
В нашем случае все получилось правильно, т.е. мы дополнили таблицу Employees, данными таблицы Departments. Я специально заострил на этом внимание, т.к. бывают случаи, когда такое поведение нам не нужно. Для демонстрации поставим задачу – для каждого отдела вывести последнего принятого сотрудника, если сотрудников нет, то просто вывести название отдела. Возможно напрашивается такое решение – просто взять предыдущий запрос и поменять условие соединение на RIGHT JOIN, плюс переставить поля местами:
| ID | Name | ID | Name |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1001 | Петров П.П. |
| 3 | ИТ | 1003 | Андреев А.А. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
Но мы для ИТ-отдела получили три строчки, когда нам нужна была только строчка с последним принятым сотрудником, т.е. Николаевым Н.Н.
Задачу такого рода, можно решить, например, при помощи использования подзапроса:
| ID | Name | ID | Name |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
При помощи предварительного объединения Employees с данными подзапроса, мы смогли оставить только нужных нам для соединения с Departments сотрудников.
Здесь мы плавно переходим к использованию подзапросов. Я думаю использование их в таком виде должно быть для вас понятно на интуитивном уровне. То есть подзапрос подставляется на место таблицы и играет ее роль, ничего сложного. К теме подзапросов мы еще вернемся отдельно.
Посмотрите отдельно, что возвращает подзапрос:
| MaxEmployeeID |
|---|
| 1005 |
| 1000 |
| 1002 |
| 1004 |
Т.е. он вернул только идентификаторы последних принятых сотрудников, в разрезе отделов.
Соединения выполняются последовательно сверху-вниз, наращиваясь как снежный ком, который катится с горы. Сначала происходит соединение «Employees emp JOIN (Подзапрос) lastEmp», формируя новый выходной набор:
Потом идет объединение набора, полученного «Employees emp JOIN (Подзапрос) lastEmp» (назовем его условно «ПоследнийРезультат») с Departments, т.е. «ПоследнийРезультат RIGHT JOIN Departments dep»:
Самостоятельная работа для закрепления материала
Если вы новичок, то вам обязательно нужно прорабатывать каждую JOIN-конструкцию, до тех пор, пока вы на 100% не будете понимать, как работает каждый вид соединения и правильно представлять результат какого вида будет получен в итоге.
Для закрепления материала про JOIN-соединения сделаем следующее:
Посмотрим, что в таблицах:
| LCode | LDescr |
|---|---|
| 1 | L-1 |
| 2 | L-2a |
| 2 | L-2b |
| 3 | L-3 |
| 5 | L-5 |
| RCode | RDescr |
|---|---|
| 2 | B-2a |
| 2 | B-2b |
| 3 | B-3 |
| 4 | B-4 |
А теперь попытайтесь сами разобрать, каким образом получилась каждая строчка запроса с каждым видом соединения (Excel вам в помощь):
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | 2 | B-2a |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 3 | L-3 | 2 | B-2a |
| 5 | L-5 | 2 | B-2a |
| 1 | L-1 | 2 | B-2b |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 2 | B-2b |
| 5 | L-5 | 2 | B-2b |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2a | 3 | B-3 |
| 2 | L-2b | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2a | 4 | B-4 |
| 2 | L-2b | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Еще раз про JOIN-соединения
Еще один пример с использованием нескольких последовательных операций соединении. Здесь повтор получился не специально, так получилось – не выбрасывать же материал. 😉 Но ничего «повторение – мать учения».
Если используется несколько операций соединения, то в таком случае они применяются последовательно сверху-вниз. Грубо говоря, после каждого соединения создается новый набор и следующее соединение уже происходит с этим расширенным набором. Рассмотрим простой пример:
Первым делом выбрались все записи таблицы Employees:
Дальше произошло соединение с таблицей Departments:
Дальше уже идет соединение этого набора с таблицей Positions:
Т.е. это выглядит примерно так:
И в последнюю очередь идет возврат тех данных, которые мы просим вывести:
Соответственно, ко всему этому полученному набору можно применить фильтр WHERE и сортировку ORDER BY:
| ID | EmployeeName | PositionName | DepartmentName |
|---|---|---|---|
| 1004 | Николаев Н.Н. | Программист | ИТ |
| 1001 | Петров П.П. | Программист | ИТ |
То есть последний полученный набор – представляет собой такую же таблицу, над которой можно выполнять базовый запрос:
То есть если раньше в роли источника выступала только одна таблица, то теперь на это место мы просто подставляем наше выражение:
В результате чего получаем тот же самый базовый запрос:
А теперь, применим группировку:
Видите, мы все так же крутимся вокруг да около базовых конструкций, теперь надеюсь понятно, почему очень важно в первую очередь хорошо понять их.
И как мы увидели, в запросе на месте любой таблицы может стоять подзапрос. В свою очередь подзапросы могут быть вложены в подзапросы. И все эти подзапросы тоже представляют из себя базовые конструкции. То есть базовая конструкция, это кирпичики, из которых строится любой запрос.
Обещанный пример с CROSS JOIN
Давайте используем соединение CROSS JOIN, чтобы подсчитать сколько сотрудников, в каком отделе и на каких должностях числится. Для каждого отдела перечислим все существующие должности:
В данном случае сначала выполнилось соединение при помощи CROSS JOIN, а затем к полученному набору сделалось соединение с данными из подзапроса при помощи LEFT JOIN. Вместо таблицы в LEFT JOIN мы использовали подзапрос.
Подзапрос заключается в скобки и ему присваивается псевдоним, в данном случае это «e». То есть в данном случае объединение происходит не с таблицей, а с результатом следующего запроса:
| DepartmentID | PositionID | EmplCount |
|---|---|---|
| NULL | NULL | 1 |
| 2 | 1 | 1 |
| 1 | 2 | 1 |
| 3 | 3 | 2 |
| 3 | 4 | 1 |
Вместе с псевдонимом «e» мы можем использовать имена DepartmentID, PositionID и EmplCount. По сути дальше подзапрос ведет себя так же, как если на его месте стояла таблица. Соответственно, как и у таблицы,
все имена колонок, которые возвращает подзапрос, должны быть заданы явно и не должны повторяться.
Связь при помощи WHERE-условия
Для примера перепишем следующий запрос с JOIN-соединением:
Через WHERE-условие он примет следующую форму:
Здесь плохо то, что происходит смешивание условий соединения таблиц (emp.DepartmentID=dep.ID) с условием фильтрации (emp.DepartmentID=3).
Теперь посмотрим, как сделать CROSS JOIN:
Через WHERE-условие он примет следующую форму:
Т.е. в этом случае мы просто не указали условие соединения таблиц Employees и Departments. Чем плох этот запрос? Представьте, что кто-то другой смотрит на ваш запрос и думает «кажется тот, кто писал запрос забыл здесь дописать условие (emp.DepartmentID=dep.ID)» и с радостью, что обнаружил косяк, дописывает это условие. В результате чего задуманное вами может сломаться, т.к. вы подразумевали CROSS JOIN. Так что, если вы делаете декартово соединение, то лучше явно укажите, что это именно оно, используя конструкцию CROSS JOIN.
Для оптимизатора запроса может быть и без разницы как вы реализуете соединение (при помощи WHERE или JOIN), он их может выполнить абсолютно одинаково. Но из соображения понимаемости кода, я бы рекомендовал в современных СУБД стараться никогда не делать соединение таблиц при помощи WHERE-условия. Использовать WHERE-условия для соединения, в том случае, если в СУБД реализованы конструкции JOIN, я бы назвал сейчас моветоном. WHERE-условия служат для фильтрации набора, и не нужно перемешивать условия служащие для соединения, с условиями отвечающими за фильтрацию. Но если вы пришли к выводу, что без реализации соединения через WHERE не обойтись, то конечно приоритет за решеной задачей и «к черту все устои».
UNION-объединения – операции вертикального объединения результатов запросов
Я специально использую словосочетания горизонтальное соединение и вертикальное объединение, т.к. заметил, что новички часто недопонимают и путают суть этих операций.
Давайте первым делом вспомним как мы делали первую версию отчета для директора:
Так вот, если бы мы не знали, что существует операция группировки, но знали бы, что существует операция объединения результатов запроса при помощи UNION ALL, то мы могли бы склеить все эти запросы следующим образом:
Т.е. UNION ALL позволяет склеить результаты, полученные разными запросами в один общий результат.
Соответственно количество колонок в каждом запросе должно быть одинаковым, а также должны быть совместимыми и типы этих колонок, т.е. строка под строкой, число под числом, дата под датой и т.п.
Немного теории
В MS SQL реализованы следующие виды вертикального объединения:
| Операция | Описание |
|---|---|
| UNION ALL | В результат включаются все строки из обоих наборов. (A+B) |
| UNION | В результат включаются только уникальные строки двух наборов. DISTINCT(A+B) |
| EXCEPT | В результат попадают уникальные строки верхнего набора, которые отсутствуют в нижнем наборе. Разница 2-х множеств. DISTINCT(A-B) |
| INTERSECT | В результат включаются только уникальные строки, присутствующие в обоих наборах. Пересечение 2-х множеств. DISTINCT(A&B) |
Все это проще понять на наглядном примере.
Создадим 2 таблицы и наполним их данными:
Посмотрим на содержимое:
| T1 | T2 |
|---|---|
| 1 | Text 1 |
| 1 | Text 1 |
| 2 | Text 2 |
| 3 | Text 3 |
| 4 | Text 4 |
| 5 | Text 5 |
| B1 | B2 |
|---|---|
| 2 | Text 2 |
| 3 | Text 3 |
| 6 | Text 6 |
| 6 | Text 6 |
UNION ALL
UNION
По сути UNION можно представить, как UNION ALL, к которому применена операция DISTINCT:



