Cron Jobs — пособие для начинающих
Авторизуйтесь
Cron Jobs — пособие для начинающих

Cron — один из часто используемых инструментов для Unix-систем. Его используют для планирования выполнения команд на определённое время. Эти «отложенные» команды или задания принято называть «Cron Jobs». Такой инструмент отлично подходит для регулярных бэкапов, мониторинга дискового пространства, удаления файлов (например, логов) и много чего ещё. В этой статье будет рассказано о работе с Cron на Linux.
Введение
Шаблон задания для Cron выглядит примерно так:
Вот иллюстрация этого же шаблона, которую можно сохранить себе:
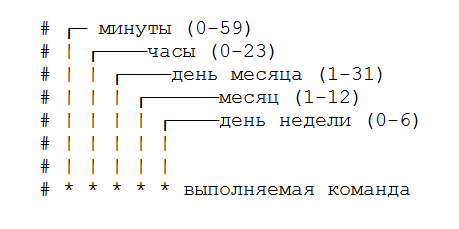
Звёздочками обозначены конкретные блоки времени.
Для отображения содержимого crontab-файла текущего пользователя используйте команду:
Для редактирования заданий пользователя есть команда:
Если эта команда выполняется в первый раз, вам предложат выбрать редактор для Cron:
Выбирайте на своё усмотрение. Вот так изначально выглядит crontab-файл:
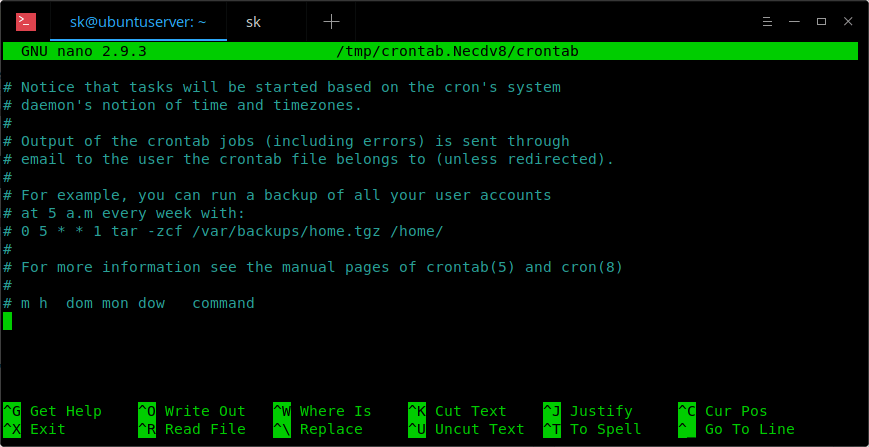
В этом файле как раз нужно перечислять одну за другой все команды.
Чтобы изменить crontab-файл другого пользователя (например, ostechnix):
Ниже приведены несколько примеров cron-заданий:
Ещё существуют готовые задания:
Чтобы выполнять команду каждый раз после перезапуска сервера, используйте это задание:
Команда для очистки всех заданий текущего пользователя:
Чтобы узнать о подробностях, есть команда:
Вышеперечисленного уже должно хватить для базовой работы с Cron и составления заданий.
Синтаксис crontab-генераторов
Процесс написания заданий сильно упрощают веб-инструменты. Они не требуют знаний синтаксиса Cron, потому что у них графический интерфейс, а задания генерируются в соответствии с вводимыми данными. Сайт генерирует задание, которое можно будет просто скопировать и вставить в crontab-файл.
Crontab.guru
crontab.guru — отличный сайт, чтобы изучить различные примеры cron-заданий. Просто введите данные и сайт самостоятельно сгенерирует конечное задание.

На сайте есть разделы, посвящённые примерам и советам.
Crontag Generator
crontab-generator.org — ещё один сайт, который помогает быстро сгенерировать crotab-выражения. Принцип такой же: нужно ввести все необходимые данные в формы и нажать кнопку «Generate Crontab Line» внизу страницы.
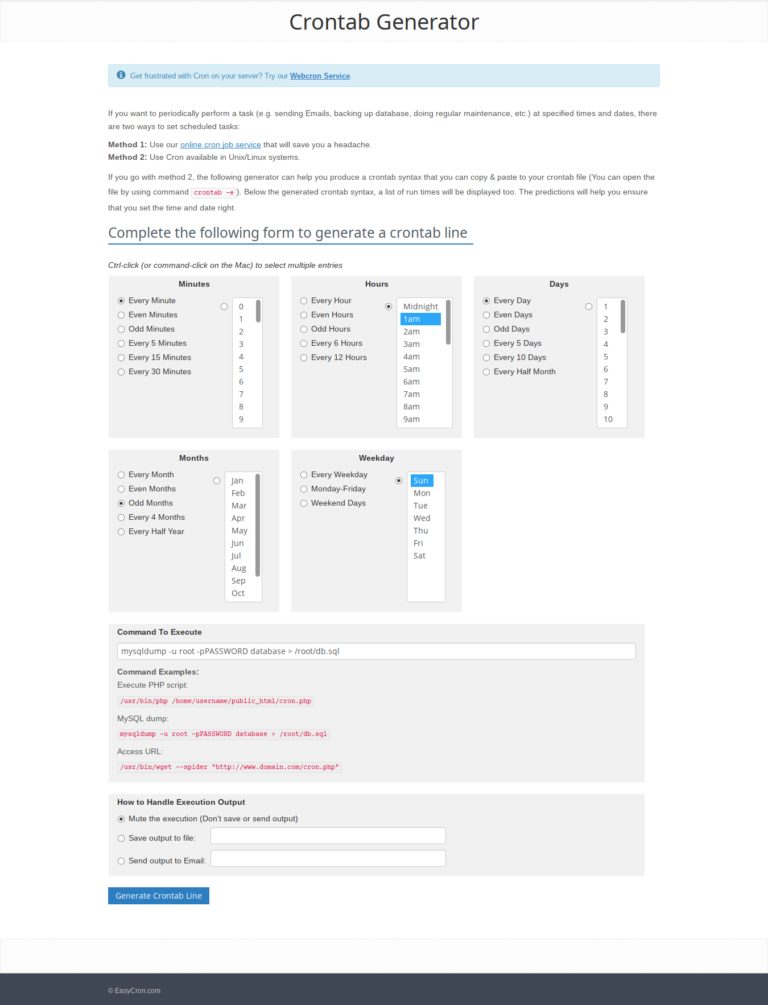
Сайт Crontab Generator
Вот такое конечное выражение вы увидете на сайте:
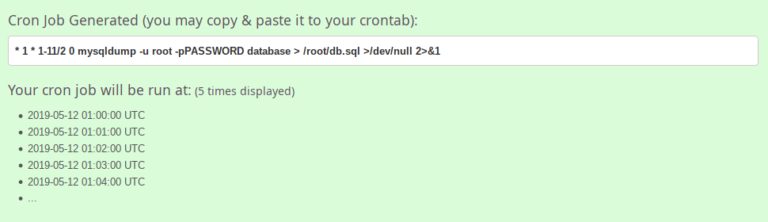
Помимо этого, есть веб-инструмент «Crontab UI», который обеспечивает не только простоту создания crontab-заданий, но и безопасность. Вот статья, посвящённая этому инструменту.
Cron Jobs — пособие для начинающих

Cron — один из часто используемых инструментов для Unix-систем. Его используют для планирования выполнения команд на определённое время. Эти «отложенные» команды или задания принято называть «Cron Jobs». Такой инструмент отлично подходит для регулярных бэкапов, мониторинга дискового пространства, удаления файлов (например, логов) и много чего ещё. Перевод статьи «A Beginners Guide To Cron Jobs» о работе с Cron на Linux опубликовал сайт tproger.ru.
Введение
Шаблон задания для Cron выглядит примерно так:
Вот иллюстрация этого же шаблона, которую можно сохранить себе:

Звёздочками обозначены конкретные блоки времени.
Для отображения содержимого crontab-файла текущего пользователя используйте команду:
Для редактирования заданий пользователя есть команда:
Если эта команда выполняется в первый раз, вам предложат выбрать редактор для Cron:
Выбирайте на своё усмотрение. Вот так изначально выглядит crontab-файл:

В этом файле как раз нужно перечислять одну за другой все команды.
Чтобы изменить crontab-файл другого пользователя (например, ostechnix):
Ниже приведены несколько примеров cron-заданий:
Чтобы выполнять команду каждую минуту, задание должно быть такое:
Похожее задание, только команда будет вызываться каждые пять минут:
Вызывать команду 4 раза в час (каждые 15 минут):
Чтобы выполнить команду каждый час в 30 минут, пишем:
Т. е. команда будет выполняться не каждые 30 минут, а тогда, когда значение минут будет равно 30 (например, 10:30, 11:30, 12:30 и т. д.).
Значения времени можно комбинировать, перечислив их через запятую. Следующий код будет выполнять команду три раза в час: в 0, 5 и 10 минут.
Выполнять команду каждый час будет следующее задание:
Выполнение команды каждые два часа:
Чтобы выполнять команду каждый день (в 00:00):
Выполнение команды каждый день в 03:00:
Выполнение команды каждое воскресенье (sunday):
Другой вариант задания, которое будет выполнять команду каждое воскресенье(естественно, тоже в 00:00):
Выполнение команды каждый день с понедельника по пятницу:
Следующее задание будет выполнять команду каждый месяц, 1-го числа в 00:00:
Выполнять команду в 16:15 каждого первого числа месяца будет это задание:
Выполнение команды каждые три месяца:
Выполнение команды в строго определённое время и месяц:
Задание будет вызывать команду в начале каждого полугодия (в 00:00 1-го дня):
Выполнение команды каждый год 1-го января в 00:00:
Ещё существуют готовые задания:
Чтобы выполнять команду каждый раз после перезапуска сервера, используйте это задание:
Команда для очистки всех заданий текущего пользователя:
Чтобы узнать о подробностях, есть команда:
Вышеперечисленного уже должно хватить для базовой работы с Cron и составления заданий.
Синтаксис crontab-генераторов
Процесс написания заданий сильно упрощают веб-инструменты. Они не требуют знаний синтаксиса Cron, потому что у них графический интерфейс, а задания генерируются в соответствии с вводимыми данными. Сайт генерирует задание, которое можно будет просто скопировать и вставить в crontab-файл.
Crontab.guru
crontab.guru — отличный сайт, чтобы изучить различные примеры cron-заданий. Просто введите данные и сайт самостоятельно сгенерирует конечное задание.

На сайте есть разделы, посвящённые примерам и советам.
Crontag Generator
crontab-generator.org — ещё один сайт, который помогает быстро сгенерировать crotab-выражения. Принцип такой же: нужно ввести все необходимые данные в формы и нажать кнопку «Generate Crontab Line» внизу страницы.

Вот такое конечное выражение вы увидете на сайте:

Помимо этого, есть веб-инструмент «Crontab UI», который обеспечивает не только простоту создания crontab-заданий, но и безопасность. Вот статья, посвящённая этому инструменту.
Job’ы и Cronjob’ы Kubernetes

В Kubernetes есть несколько контроллеров для управления подами: ReplicaSets, DaemonSets, Deployments и StatefulSets. У каждого из них есть свой сценарий использования. Однако их всех объединяет гарантия того, что их поды всегда работают. В случае сбоя пода контроллер перезапускает его или переключает его на другой узел (node), чтобы гарантировать постоянную работу программы, которая размещена на подах.
Варианты использования Job’ов Kubernetes
Наиболее подходящие варианты использования Job’ов Kubernetes:
Пакетная обработка данных: допустим вы запускаете пакетную задачу с периодичностью один раз в день/неделю/месяц или по определенному расписанию. Примером этого может служить чтение файлов из хранилища или базы данных и передача их в сервис для обработки файлов.
Команды/специфические задачи: например, запуск скрипта/кода, который выполняет очистку базы данных.
Job’ы Kubernetes гарантируют, что один или несколько подов выполнят свои команды и успешно завершатся. После завершения всех подов без ошибок, Job завершается. Когда Job удаляется, все созданные поды также удаляются.
Ваш первый Kubernetes Job
Создание Job’а Kubernetes, как и других ресурсов Kubernetes, осуществляется с помощью файла определения (definition file). Откройте новый файл, вы можете назвать его job.yaml. Добавьте в файл следующее:
Как и в случае с другими ресурсами Kubernetes, мы можем применить это определение к работающему кластеру Kubernetes с помощью kubectl. Выглядит это следующим образом:
Давайте посмотрим, какие поды были созданы:
Проверим статус job’а с помощью kubectl:
Подождем несколько секунд и снова запустить ту же команду:
Прежде чем двигаться дальше, давайте убедимся, что job действительно выполнил то, что мы от него хотели:
В логах отображается то, что мы задали, т.е. вывести “Running a hello-world job”. Job успешно выполнен.
Запуск CronJob вручную
Бывают ситуации, когда вам нужно выполнить cronjob на разовой основе. Вы можете сделать это, создав job из существующего cronjob’а.
Например, если вы хотите, чтобы cronjob запускался вручную, вы должны сделать следующее.
—from=cronjob/kubernetes-cron-job скопируйте шаблон cronjob’а и создайте job с именем manual-cron-job
Удаление Job’а Kubernetes и очистка (Cleanup)
Когда Job Kubernetes завершается, ни Job, ни созданные им поды не удаляются автоматически. Вы должны удалить их вручную. Эта особенность гарантирует, что вы по-прежнему сможете просматривать логи, Job и его поды в завершенном статусе.
Job можно удалить с помощью kubectl следующим образом:
kubectl delete jobs job_name
kubectl delete jobs job_name cascade=false
Есть еще несколько ключевых параметров, которые вы можете использовать с job’ами/cronjob’ами kubernetes в зависимости от ваших потребностей. Давайте рассмотрим каждый из них.
1. failedJobHistoryLimit и successfulJobsHistoryLimit: Удаления истории успешных и неудавшихся job’ов основано на заданном Вами количестве сохранений. Это очень удобно для отбрасывания всех вхождений, завершенных неудачей, когда вы пытаетесь вывести список job’ов. Например,
2. backoffLimit: общее количество повторных попыток в случае сбоя пода.
RestartPolicy Job’а Kubernetes
В параметре restartPolic y (политика перезапуска) нельзя установить политику “always” (всегда). Job не должен перезапускать под после успешного завершения по определению. Таким образом, для параметра restartPolicy доступны варианты “Never” (никогда) и “OnFailure” (в случае неудачи).
Ограничение выполнения Job’а Kubernetes по времени
Завершения Job’ов и параллелизм
Мы рассмотрели, как можно выполнить одну задачу, определенную внутри объекта Job, что более известно как шаблон “run-once”. Однако в реальных сценариях используются и другие шаблоны.
Несколько одиночных Job’ов
Мы указываем параметр completions равным 5.
Несколько параллельно запущенных Job’ов (Work Queue)
Другой шаблон может включать в себя необходимость запуска нескольких job’ов, но вместо того, чтобы запускать их один за другим, нам нужно запускать несколько из них параллельно. Параллельная обработка сокращает общее время выполнения и находит применение во многих областях, например в data science и искусственном интеллекте.
Измените файл определения, чтобы он выглядел следующим образом:
Одновременно будут запущены 5 подов, все они будут выполнять один и то же Job. Когда один из подов завершается успехом, это будет означать, что весь Job готов. Поды больше не создаются, и Job в конечном итоге завершается.
В этом сценарии Kubernetes Job одновременно порождает 5 подов. Знать, завершили ли остальные поды свои задачи, в компетенции самих подов. В нашем примере мы предполагаем, что получаем сообщения из очереди сообщений (например, AWS SQS). Когда сообщений для обработки больше нет, Job получает уведомление о том, что он должен завершиться. После успешного завершения первого пода:
Поды больше не создаются.
Существующие поды завершают свою работу и тоже завершаются.
В приведенном выше примере мы изменили команду, которую выполняет под, чтобы перевести его в спящий режим на случайное количество секунд (от 5 до 10), прежде чем он завершится. Таким образом, мы примерно моделируем, как несколько подов могут работать вместе с внешним источником данных, таким как очередь сообщений или API.
Ограничения CronJob’ов
Cronjob создает объект job примерно по одному разу за сеанс выполнения своего расписания (schedule). Мы говорим «примерно», потому что при определенных обстоятельствах могут быть созданы два job’а или ни одного. Мы пытаемся сделать подобные случаи как можно более редкими, но не можем предотвратить их полностью. Следовательно, job’ы должны быть идемпотентными.
Если параметр startingDeadlineSeconds установлен на большое значение или не задан (по умолчанию) и параметр concurrencyPolicy установлен на Allow, job всегда будут запускаться как минимум один раз.
Для каждого CronJob’а контроллер CronJob проверяет, сколько расписаний он пропустил за период с последнего запланированного времени до настоящего момента. Если пропущенных расписаний больше 100, то job не запускается и в логи вносится сообщение об ошибке.
CronJob считается пропущенным, если его не удалось создать в установленное время. Например, если для параметра concurrencyPolicy задано значение Forbid и была предпринята попытка запланировать CronJob во время выполнения предыдущего расписания, оно будет считаться пропущенным.
Чтобы проиллюстрировать эту концепцию с другой стороны, предположим, что CronJob запрограммирован планировать новый Job в расписании каждую минуту начиная с 08:30:00 и его параметр startingDeadlineSeconds устанавливается на 200 секунд. Если контроллер CronJob не работает в течение того же периода, что и в предыдущем примере (с 08:29:00 до 10:21:00 ), Job все равно запустится в 10:22:00. Это происходит, поскольку контроллер теперь проверяет, сколько пропущенных расписаний было за последние 200 секунд (т. е. 3 пропущенных расписания), вместо того, чтобы считать с последнего заданного времени до настоящего момента.
CronJob отвечает только за создание Job’ов, соответствующих его расписанию, а Job, в свою очередь, отвечает за управление представляемыми им подами.
TL;DR (Too Long; Didn’t Read)
Job’ы Kubernetes используются, когда вы хотите создать поды, которые будут выполнять определенную задачу, а затем завершать работу.
Job’ы Kubernetes по умолчанию не нуждаются в селекторах подов; Job автоматически обрабатывает их лейблы и селекторы.
Параметр restartPolicy для Job принимает значения «Never» или «OnFailure»
Job’ы используют параметры completions и parallelism для управления шаблонами, которые определяют порядок работы подов. Поды Job’ов могут выполняться как одна задача, несколько последовательных задач или несколько параллельных задач, в которых первая завершенная задача дает указание остальным подам завершиться.
Продвинутые абстракции Kubernetes: Job, CronJob
Что такое Job и CronJob в Kubernetes, для чего они нужны, а для чего их использовать не стоит.
Эта статья — выжимка из лекции вечерней школы «Слёрм Kubernetes».
Job: сущность для разовых задач
Job (работа, задание) — это yaml-манифест, который создаёт под для выполнения разовой задачи. Если запуск задачи завершается с ошибкой, Job перезапускает поды до успешного выполнения или до истечения таймаутов. Когда задача выполнена, Job считается завершённым и больше никогда в кластере не запускается. Job — это сущность для разовых задач.
Когда используют Job
При установке и настройке окружения. Например, мы построили CI/CD, который при создании новой ветки автоматически создаёт для неё окружение для тестирования. Появилась ветка — в неё пошли коммиты — CI/CD создал в кластере отдельный namespace и запустил Job — тот, в свою очередь, создал базу данных, налил туда данные, все конфиги сохранил в Secret и ConfigMap. То есть Job подготовил цельное окружение, на котором можно тестировать и отлаживать новую функциональность.
При выкатке helm chart. После развёртывания helm chart с помощью хуков (hook) запускается Job, чтобы проверить, как раскатилось приложение и работает ли оно.
Таймауты, ограничивающие время выполнения Job
Job будет создавать поды до тех пор, пока под не завершится с успешным результатом. Это значит, что если в поде есть ошибка, которая приводит к неуспешному результату (exit code не равен 0), то Job будет пересоздавать этот под до бесконечности. Чтобы ограничить перезапуски, в описании Job есть два таймаута: activeDeadlineSeconds и backoffLimit.
activeDeadlineSeconds — это количество секунд, которое отводится всему Job на выполнение. Обратите внимание, это ограничение не для одного пода или одной попытки запуска, а для всего Job.
Например, если указать в Job, что activeDeadlineSeconds равен 200 сек., а наше приложение падает с ошибкой через 5 сек., то Job сделает 40 попыток и только после этого остановится.
backoffLimit — это количество попыток. Если указать 2, то Job дважды попробует запустить под и остановится.
Параметр backoffLimit очень важен, потому что, если его не задать, контроллер будет создавать поды бесконечно. А ведь чем больше объектов в кластере, тем больше ресурсов API нужно серверам, и что самое главное: каждый такой под — это как минимум два контейнера в остановленном состоянии на узлах кластера. При этом поды в состоянии Completed или Failed не учитываются в ограничении 110 подов на узел, и в итоге, когда на узле будет несколько тысяч контейнеров, докер-демону скорее всего будет очень плохо.
Учитывая, что контроллер постоянно увеличивает время между попытками запуска подов, проблемы могут начаться в ночь с пятницы на понедельник. Особенно, если вы не мониторите количество подов в кластере, которые не находятся в статусе Running.
Удаление Job
После успешного завершения задания манифесты Job и подов, созданных им, остаются в кластере навсегда. Все поля Job имеют статус Immutable, то есть «неизменяемый», и поэтому обычно при создании Job из различных автоматических сценариев сначала удаляют Job, который остался от предыдущего запуска. Практика генерации уникальных имен для запуска таких Job может привести к накоплению большого количества ненужных манифестов.
В Kubernetes есть специальный TTL Controller, который умеет удалять завершенные Job вместе с подами. Вот только он появился в версии 1.12 и до сих пор находится в статусе alpha, поэтому его необходимо включать с помощью соответствующего feature gate TTLAfterFinished.
ttlSecondsAfterFinished — указывает, через сколько секунд специальный TimeToLive контроллер должен удалить завершившийся Job вместе с подами и их логами.
Манифест
Посмотрим на пример Job-манифеста.
В начале указаны название api-группы, тип сущности, имя и дальше — спецификация.
В спецификации указаны таймауты и темплейт пода, который будет запускаться. Опции backoffLimit: 2 и activeDeadlineSeconds: 60 значат, что Job будет пытаться выполнить задачу не более двух раз и в общей сложности не дольше 60 секунд.
template — это описание пода, который будет выполнять задачу; в нашем случае запускается простой контейнер busybox, который выводит текущую дату и передаёт привет из Kubernetes.
Практические примеры
И посмотрим, что получилось.
Видим, что контейнер поднялся и завершился в статусе Completed. В отличие от приложений, которые всегда работают и имеют статус Running.
Статистику по Job можно посмотреть следующей командой.
Видим, что завершились все задания, время выполнения — 5 секунд.
Ненужный Job обязательно надо удалять. Потому что, если мы не удалим его руками, Job и под будут висеть в кластере всегда — никакой garbage collector не придёт и не удалит их.
Если у вас запускаются по 10-20 заданий в час, и никто их не удаляет, они копятся и в кластере появляется много абстракций, которые никому не нужны, но место занимают. А как я уже говорил выше, каждый под в состоянии Completed — это, как минимум, два остановленных контейнера на узле. А докер демон начинает притормаживать, если на узле оказывается несколько сотен контейнеров, и не важно, работают они или остановлены.
Команда для удаления:
Что будет, если сломать Job
Job, который выполняется без проблем, не очень интересен. Давайте мы над ним немного поиздеваемся.
Поправим yaml: добавим в темплейт контейнера exit 1. То есть скажем Job’у, чтобы он завершался с кодом завершения 1. Для Kubernetes это будет сигналом о том, что Job завершился неуспешно.
Применяем и смотрим, что происходит: один контейнер создался и упал с ошибкой, затем ещё и ещё один. Больше ничего не создаётся.
В статистике подов видим, что создано три пода, у каждого статус Error. Из статистики Job следует, что у нас создан один Job и он не завершился.
Если посмотреть описание, то увидим, что было создано три пода, и Job завершился, потому что был достигнут backoffLimit.
Обратите внимание! В yaml лимит равен 2. То есть, если следовать документации, Job должен был остановиться после двух раз, но мы видим три пода. В данном случае «после выполнения двух раз» значит 3 попытки. Когда мы проделываем то же самое на интенсиве с сотней студентов, то примерно у половины создаётся два пода, а у оставшихся три. Это надо понять и простить.
Проверка ограничения по времени
Сделаем бесконечный цикл и посмотрим, как работает ограничение по времени — activeDeadlineSeconds.
Ограничения оставим теми же (60 секунд), изменим описание контейнера: сделаем бесконечный цикл.
Если посмотреть в логи, то увидим, что каждую секунду у нас появляется новый «Hello» — всё как надо.
Через 60 секунд под оказывается в статусе Terminating (иногда это происходит через ± 10 сек).
Вспомним, как в Kubernetes реализована концепция остановки подов. Когда приходит время остановить под, то есть все контейнеры в поде, контейнерам посылается sigterm-сигнал и Kubernetes ждёт определённое время, чтобы приложение внутри контейнера отреагировало на этот сигнал.
В нашем случае приложение — это простой bash-скрипт с бесконечным циклом, реагировать на сигнал некому. Kubernetes ждёт время, которое задано в параметре graceful shutdown. По дефолту — 30 секунд. То есть если за 30 секунд приложение на sigterm не среагировало, дальше посылается sigkill и процесс с pid 1 внутри контейнера убивается, контейнер останавливается.
Спустя чуть более 100 секунд под удалился. Причем ничего в кластере не осталось, потому что единственный способ остановить что-то в контейнере — это послать sigterm и sigkill. После этого приходит garbage collector, который удаляет все поды в статусе Terminating, чтобы они не засоряли кластер.
В описании Job мы увидим, что он был остановлен, так как активность превысила допустимую.
Поле restartPolicy
Этот параметр говорит kubelet, что делать с контейнером после того, как он был завершён с ошибкой. По умолчанию стоит политика Always, то есть если у нас контейнер в поде завершился, kubelet этот контейнер перезапускает. Причем, все остальные контейнеры в поде продолжают работать, а перезапускается только упавший контейнер.
Это политика по умолчанию, и если её применить в Job, то Job-контроллер не сможет получить информацию о том, что под был завершён с ошибкой. С его точки зрения под будет очень долго выполняться, а то, что kubelet перезапускает упавший контейнер, Job-контроллер не увидит.
CronJob: создание объектов Job по расписанию
Job позволяет выполнить разовые задачи, но на практике постоянно возникает потребность выполнять что-то по расписанию. И вот здесь Kubernetes предлагает CronJob.
CronJob — это yaml-манифест, на основании которого по расписанию создаются Job’ы, которые в свою очередь создают поды, а те делают полезную работу.
На первый взгляд, всё вроде бы просто, но, как и в предыдущем случае, тут есть куча мест, где можно испытать боль.
В манифесте CronJob указывают расписание и ещё несколько важных параметров.
И два параметра, которые влияют на историю выполнения.
Посмотрим на манифест CronJob и поговорим о каждом параметре подробнее.
schedule — это расписание в виде строчки, которая имеет обычный cron-формат. Строчка в примере говорит о том, что наш Job должен выполняться раз в минуту.
concurrencyPolicy — этот параметр отвечает за одновременное выполнение заданий. Бывает трёх видов: Allow, Forbid, Replace.
Allow позволяет подам запускаться. Если за минуту Job не отработал, все равно будет создан ещё один. Одновременно могут выполняться несколько Job’ов.
Например, если один Job выполняется 100 сек., а Cron выполняется раз в минуту, то запускается Job, выполняется 61 сек., в это время запускается ещё один Job. В итоге в кластере одновременно работают два Job’a, которые выполняют одну и ту же работу. Возникает положительная обратная связь: чем больше Job’ов запущено, тем больше нагрузка на кластер, тем медленнее они работают, тем дольше они работают и тем больше одновременных подов запускается — в итоге всё застывает под бешеной нагрузкой.
Replace заменяет запущенную нагрузку: старый Job убивается, запускается новый. На самом деле это не самый лучший вариант, когда прерываем то, что уже выполнялось, и начинаем ту же самую задачу выполнять заново. В каких-то случаях это возможно, в каких-то неприемлемо.
Forbid запрещает запуск новых Job’ов, пока не отработает предыдущий. С этой политикой можно быть уверенным, что всегда запускается только один экземпляр задачи. Поэтому Forbid используют наиболее часто.
jobTemplate — это шаблон, из которого создаётся объект Job. Ну а всё остальное мы уже видели в манифесте Job.
Посмотрим, что получилось:
Увидим название CronJob, расписание, параметр запуска, количество активных Job’ов и сколько времени они работают.
Раздел Suspend — временная приостановка CronJob. В данном случае указано значение False. Это значит, что CronJob выполняется. Можно отредактировать манифест и поставить опцию True, и тогда он не будет выполняться, пока мы его снова не запустим.
Active — сколько Job’ов создано, Last Schedule — когда последний раз исполнялся.
Теперь можно посмотреть статистику по Job’ам и подам.
Видно, что создан один Job.
Под создан, он выполнил полезную работу.
Что получается: CronJob создал Job, Job создал под, под отработал, завершился — всё здорово.
Ещё раз посмотрим на CronJob:
Last Schedule был 19 секунд назад. Если посмотреть на Job, то увидим, что у нас появился следующий Job и следующий под.
Возникает вопрос: а что будет, если CronJob отработает хотя бы пару недель? Неужели у нас в кластере будет столько же Job’ов и подов в статусе Completed, сколько в этой паре недель минут?
Когда CronJob’ы только появились и были на стадии альфа-тестирования, примерно это и происходило: делали CronJob раз в минуту, смотрели — работает, всё здорово, а через неделю кластер становился неработоспособным, потому что количество остановленных контейнеров на узлах было ошеломляющим. Теперь же ситуация изменилась.
Снова откроем манифест и посмотрим, что было добавлено:
Появились опции failedJobHistorLimit со значением 1 и successfulJobHistoryLimit со значением 3. Они отвечают за количество Job’ов, которые остаются одновременно в кластере. То есть CronJob не только создаёт новые Job’ы, но и удаляет старые.
Когда только контроллер CronJob создавался, эти опции не были установлены по умолчанию и CronJob за собой ничего не удалял. Было много возмущений от пользователей, и тогда поставили дефолтные лимиты.
И на сладкое — про startingDeadlineSeconds
В параметре startingDeadlineSeconds указывают количество секунд, на которое можно просрочить запуск Job. Если по каким-то причинам Job не создался и с момента, когда его надо было создать, прошло больше секунд, чем указано в этом параметре, то он и не будет создан. А если меньше, то хоть и с опозданием, Job будет создан.
Тут есть небольшая ловушка, если concurrencyPolicy разрешают одновременное создание Job, то при большом значении параметра startingDeadlineSeconds возможен одновременный запуск десятков пропущенных Job одновременно. Для уменьшения всплеска нагрузки в код Kubernetes захардкожены лимиты и запрещающие процедуры:
Если параметр startingDeadlineSeconds не указан в манифесте:
CronJob контроллер при создании Job смотрит на время последнего запуска — значение LastscheduleTime в status: и считает, сколько времени прошло с последнего запуска. И если это время достаточно велико, а точнее за этот промежуток времени CronJob должен был отработать 100 раз или больше, но у нее этого не получилось:
В этом случае происходит нечто странное: CronJob перестает работать, новые Job’ы больше не создаются. Сообщение об этом приходит в Events, но хранится там недолго. Для восстановления работы приходится удалять CronJob и создавать его заново.
И еще более странное:
Если установлен параметр startingDeadlineSeconds, то поведение немного меняется. 100 пропущенных запусков должны уложиться в количество секунд, указанных в этом параметре. т. е. если в расписании стоит выполняться раз в минуту, а startingDeadlineSeconds меньше 6000 секунд, тогда CronJob будет работать всегда, но в этом случае при политике Allow возможен одновременный запуск множества Job.
И наконец, любопытный side-эффект:
Если установить опцию startingDeadlineSeconds равной нулю, Job’ы вообще перестают создаваться.
Если вы используете опцию startingDeadlineSeconds, указывайте её значение меньше, чем интервал выполнения в расписании, но не ноль.
Применяйте политику Forbid. Например, если было пропущено 5 вызовов и наступило очередное время исполнения, то контроллер не будет 5 раз запускать пропущенные задачи, а создаст только один Job. Это логичное поведение.
Особенность работы CronJob
A cron job creates a job object about once per execution time of its schedule. We say «about» because there are certain circumstances where two jobs might be created, or no job might be created. We attempt to make these rare, but do not completely prevent them. Therefore, jobs should be idempotent.
Вольный перевод на русский:
CronJob создаёт объект Job примерно один раз на каждое время исполнения по расписанию. Мы говорим «примерно», потому что иногда бывают случаи, когда создаются два Job’а одновременно или ни одного. Мы делаем всё, чтобы сделать подобные случаи как можно более редкими, но полностью избежать этого не получается. Следовательно, Job’ы должны быть идемпотентны.
Идемпотентны — должны выполняться на одной и той же среде несколько раз и всегда возвращать одинаковый результат.
В общем, используйте CronJob на свой страх и риск.
В качестве альтернативы CronJob можно использовать под, в котором запущен самый обычный crond. Без выкрутасов. Старый добрый cron работает без проблем, и мы всегда знаем, что задачи будут выполнены один раз. Надо только побеспокоиться, чтобы внутри пода с кроном не выполнялись одновременно несколько задач.
Изучить продвинутые абстракции и попрактиковаться в работе с Kubernetes можно с помощью видеокурса Kubernetes База. В октябре 2020 мы обновили курс, подробности здесь.
Автор статьи: Сергей Бондарев — практикующий архитектор Southbridge, Certified Kubernetes Administrator, один из разработчиков kubespray с правами на принятие pull request.



