Директива Crawl-delay: как правильно использовать с примерами
Важно! Сегодня Яндекс уже не следует инструкции Crawl-delay. И теперь скорость обхода регулируется только в Яндекс Вебмастер в разделе “Индексирование – Скорость обхода”.
В Google данная директива тоже не используется о чем было сказано в 2017 году в этом видео.
Видео на английском, поэтому вот перевод:
Crawl-delay — это очень давняя директива в Google. И нужна она была вебмастерам, чтобы указать период между запросами для снижения нагрузки на сервер, которые делает краулер(робот поисковой системы).
Сама по себе идея была хорошей и разумной для того времени. Но дальше стало понятно, что серверы сегодня довольно мощные, так что смыла устанавливать определенный период между запросами попросту нет.
Что же пришло в Google на смену crawl-delay директивы? Робот поисковой системы теперь автоматически регулирует скорость обхода страницы, в зависимости от реакции сервера. Как только она замедлится или появится ошибка, обход может приостановиться.
Итак, учитывая, что замена найдена и успешно нами применяется, поэтому теперь crawl-delay нами не поддерживается. И если мы обнаружим директиву в вашем robots.txt, мы на это укажем.
Стоит также отметить, что на любом сайте обязательно существуют разделы, не нуждающиеся в обходе. Вы можете сообщить нам о них, предоставив информацию в robots.txt с помощью директивы Dissalow.
Хоть и директива Crawl-delay больше не поддерживается Яндекс и Google, но вдруг вы захотите узнать, как она раньше использовалась в этих поисковых машинах, поэтому ниже мы об этом расскажем.
Crawl-delay в файле robots.txt уменьшает нагрузку на сервер, когда поисковые роботы слишком часто посещают ваш ресурс и перегружают сервер, не давая ему полноценно обрабатывать запросы бота.
Зачастую ее используют владельцы сайтов с более тысячи страниц, так как данная проблема зачастую касается крупных веб-проектов.
Посредством директивы мы просим роботов обходить страницы нашего веб-ресурса не чаще, чем один раз в три, пять и т.п. секунд. То есть, правило задает роботу поисковой системы промежуток времени, измеряющийся в секундах, между концом загрузки одной веб-страницы и началом загрузки последующей.
Есть поисковики, которые работают с форматом дробных чисел, являющихся параметром директивы Crawl-delay.
На заметку.Перед указанием новой скорости обхода ресурса роботами следует узнать, какие страницы они посещают чаще остальных.
Для этого необходимо:
Если в результате проверки будет обнаружено, что поисковый бот в основном сканирует служебные страницы, закройте их от индексирования в файле Robots, используя директиву Disallow. Так вы существенно уменьшите количество ненужных посещений роботом.
Правильное написание директивы Crawl-delay
Чтобы роботы поисковых систем, не всегда придерживающиеся стандарта в ходе чтения robots.txt, учитывали данное правило, его нужно включить в группу, начинающуюся с директивы User-agent, после Disallow и Allow.
Основной бот Яндекса работает с дробными значениями указания Crawl-delay, такими как 0.2 и прочими. Нет стопроцентных гарантий, что робот начнет посещать ваш ресурс 20 раз в секунду, однако обеспечить более быстрое сканирование сайта удастся.
Директива не распознается поисковым ботом, отвечающим за обход RSS-канала для создания Турбо-страниц.
На заметку. Максимальное значение директивы для роботов Яндекса – 2.0.
Чтобы выбрать необходимую скорость загрузки страниц веб-сайта, перейдите в меню Скорость обхода сайта.
Примеры:
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
«Вкалывают роботы»: что такое robots.txt и как его настроить

Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Пример:
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Даем рекомендацию, чтобы индексировались категории.
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
Sitemap
Пример:
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
Переходим в инструмент, вводим домен и содержимое вашего файла.

Нажимаем « Проверить » и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
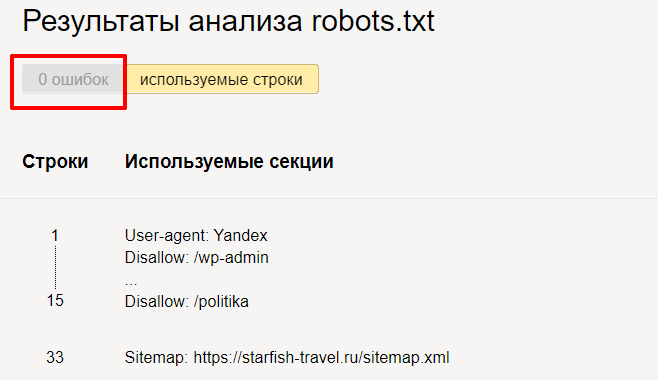
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
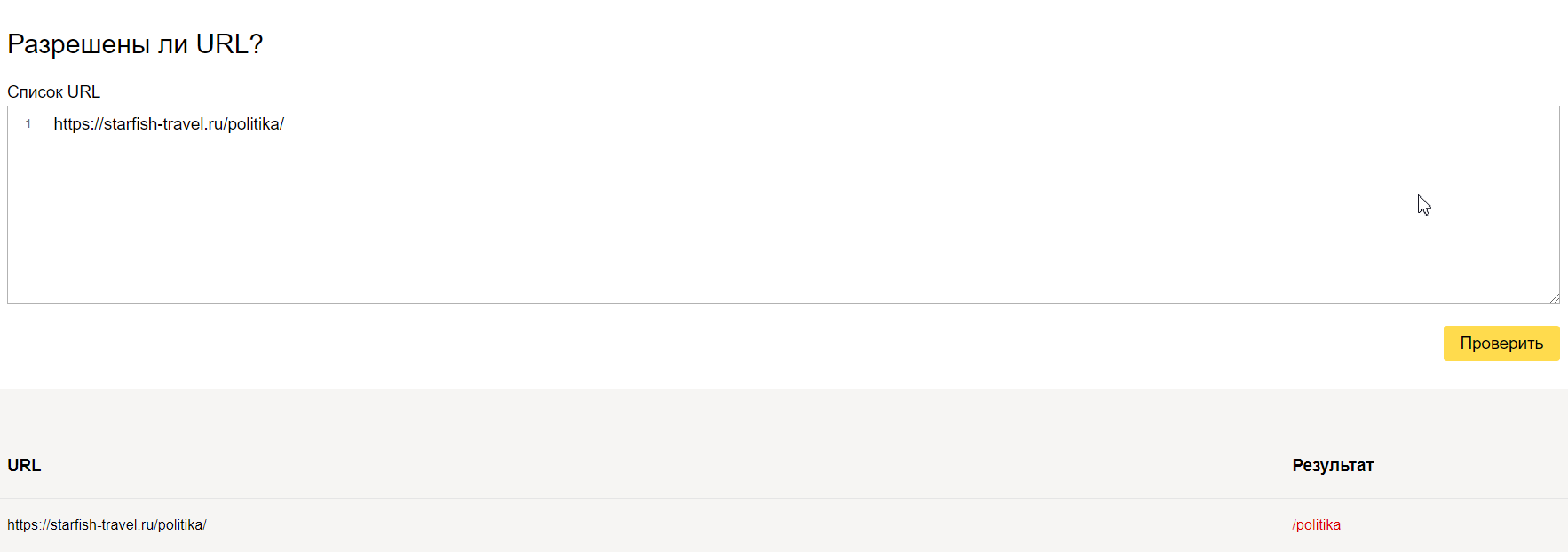
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
Правильный robots.txt для Joomla
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Что такое директива Crawl-delay
25 октября 2017 Опубликовано в разделах: Азбука терминов. 8504



Представьте, что в роли сервера сайта выступает директор фирмы, на проверку которой пришла проверяющая служба — поисковый робот. Работа в компании кипит, директор выполняет свои задачи, отвечает подчиненным, но проверяющие внезапно начинают задавать ему самые разные вопросы. Снижается производительность всей компании.
Сотрудники не могут работать, пока не получат ответ от директора. А он не может им ответить, потому что занят разговором с инспекторами. Чем больше на вашем сайте страниц, тем дольше этот “инспектор” будет проводить допрос, и тем меньше свободного времени будет у сервера на ответы настоящим живым клиентам.
Директива Crawl-delay указывает роботу делать перерывы между “вопросами” к серверу, чтобы в это время он мог отвечать клиентам, не задерживая выполнение внутренних процессов. Поисковый робот после каждого запроса начинает выжидать определенное количество секунд перед следующей страницей по списку.
Как правильно задать директиву Crawl-delay
Правильная конфигурация Crawl-delay даёт возможность существенно разгрузить сервера сайта на время прихода поискового бота, увеличить максимальное количество соединений с живыми клиентами и предотвратить падение сайта при большом наплыве пользователей одновременно с ботами.
Особенность использования директивы
Сколько секунд лучше ставить в Crawl-Delay
В случае, если в момент обхода поисковиками производительность вашего сайта падает, будет полезно попробовать поставить задержку обхода в две-три секунды. Если вам нужно поскорее выгнать бота с сайта, наоборот значение можно уменьшить до одной десятой секунды, что не гарантирует 600 страниц в минуту, но ускорит процесс обработки.
Полезным будет большое значение директивы на слабых тарифах хостингов, чтобы сайт не упал в неподходящий момент. Иногда сервера на небольших тарифах просто не в состоянии обрабатывать в секунду столько запросов, сколько от них требует бот поисковой системы.
После того, как вы внесли директиву в robots.txt. проверьте правильность файла. Воспользуйтесь панелью веб-мастера. В системе Google может возникнуть ошибка о том, что указано неизвестное свойство. Это нормально. На эту директиву смотрят, в основном, только роботы Яндекса.

Специалисты студии SEMANTICA проведут комплексный анализ сайта по следующему плану:
– Технический аудит.
– Оптимизация.
– Коммерческие факторы.
– Внешние факторы.
Мы не просто говорим, в чем проблемы. Мы помогаем их решить
Продвинутое использование robots.txt без ошибок — руководство для SEO
1 сентября 2019 года Google прекратит поддержку нескольких директив в robots.txt. В список попали: noindex, crawl-delay и nofollow. Вместо них рекомендуется использовать:
404 и 410 коды ответа сервера. В ряде случаев, 410 отрабатывает значительно быстрей для удаления URL из индекса.
Защита паролем. Страницы, требующие авторизации, также обычно удаляются из индекса (важно — именно страницы, полностью скрытые под логином, а не часть контента).
Временное удаление страницы из индекса с помощью инструмента в Search Console.
Disallow в robots.txt.
Тем не менее, robots.txt по-прежнему остаётся одним из главных файлов для SEO-специалиста. Давайте вспомним самые полезные директивы от простых, до менее очевидных.
robots.txt
Это простой текстовый файл, который содержит инструкции для поисковых краулеров — какие страницы сайта не следует посещать, где лежит наш Sitemap.xml и для каких поисковых роботов распространяются правила.
Файл размещается в корневой директории сайта. Например:
Прежде чем начать сканирование сайта, краулеры проверяют наличие robots.txt и находят правила специфичные для их User-Agent, например Googlebot. Если таких нет — следуют общим инструкциям.
Действующие правила robots.txt
User-Agent
У каждой поисковой системы есть свои «агенты пользователя». По сути, это имя краулера, которое помогает дать определённые указания конкретному ему.
Если брать шире, то User-Agent — клиентское приложение на стороне поисковой системы, в некотором смысле имитирующее браузер или, например, мобильное устройство.
User-agent: * — символ астериск используются для обозначения сразу же всех краулеров.
User-agent: Yandex — основной краулер Яндекс-поиска.
User-agent: Google-Image — робот поиска Google по картинкам.
User-agent: AhrefsBot — краулер сервиса Ahrefs.
Важно: если в файле указаны правила для конкретных User-Agent, то роботы будут следовать только своим инструкциям, игнорируя общие правила.
Disallow
Директива, которая позволяет блокировать от индексации полностью весь сайт или определённые разделы.
Может быть полезно для закрытия от сканирования служебных, динамических или временных страниц (символ # отвечает за комментарии в коде и игнорируется краулерами).
Упростить инструкции помогают операторы:
* — любая последовательность символов в URL. По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *.
$ — символ в конце URL-адреса, он используется чтобы отменить использование * на конце правила.
Важно: в robots.txt не нужно закрывать JS и CSS-файлы, они понадобятся поисковым роботом для правильного отображения (рендеринга) контента.
Allow
С помощью этой директивы можно, напротив, разрешить каталог или конкретный адрес к индексации. В некоторых случаях проще запретить к сканированию весь сайт и с помощью Allow открыть нужные разделы.
Также Allow можно использовать для отдельных User-Agent.
Crawl-delay
Директива, теряющая актуальность в случае Goolge, но полезная для работы с другими поисковиками.
Позволяет замедлить сканирование, если сервер бывает перегружен. Устанавливает интервал времени для обхода страниц в секундах (для Яндекса). Чем выше значение, тем медленнее краулер ходит по сайту.
Несмотря на то, что Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Интересно, что китайский Baidu также не обращает внимание на Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт только один раз.
Важно: если установлено высокое значение Crawl-delay, убедитесь, что ваш сайт своевременно индексируется. В сутках 86 400 секунд, при Crawl-delay: 30 будет просканировано не более 2880 страниц в день, что мало для крупных сайтов.
Sitemap
Одно из ключевых применений robots.txt в SEO — указание на расположение карты сайты. Обратите внимание, используется полный URL-адрес (их может быть несколько).
Нужно иметь в виду:
Директива Sitemap указывается с заглавной S.
Sitemap не зависит от инструкций User-Agent.
Нельзя использовать относительный адрес карты сайта, только полный URL.
Файл XML-карты сайта должен располагаться на том же домене.
Также убедитесь, что ссылка возвращает статус 200 OK без редиректов. Проверить можно с помощью инструмента, определяющего ответ сервера или анализа XML-карты сайта.
Типичный robots.txt
Ниже представлены простые и распространенные шаблоны команд для поисковых роботов.
Разрешить полный доступ
Обратите внимание, правило для Disallow в этом случае не заполняется.
Полная блокировка доступа к хосту
Запрет конкретного раздела сайта
Запрет сканирования определенного файла
Распространенная ошибка
Установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent, соответствующий краулер будет следовать только тем правилам, что установлены именно для него. Не забывайте дублировать общие директивы для всех User-Agent.
В примере ниже — слегка измененный robots.txt сайта IMDB. Общие правила Disallow не будут распространяться на бот ScoutJet. А вот Crawl-delay, напротив, установлена только для него.
Противоречия директив
Список распространенных User-Agent
| User-Agent | # |
|---|---|
| Googlebot | Основной краулер Google |
| Googlebot-Image | Робот поиска по картинкам |
| Bing | |
| Bingbot | Основной краулер Bing |
| MSNBot | Старый, но всё ещё использующийся краулер Bing |
| MSNBot-Media | Краулер Bing для изображений |
| BingPreview | Отдельный краулер Bing для Snapshot-изображений |
| Яндекс | |
| YandexBot | Основной индексирующий бот Яндекса |
| YandexImages | Бот Яндеса для поиска по изображениям |
| Baidu | |
| Baiduspider | Главный поисковый робот Baidu |
| Baiduspider-image | Бот Baidu для картинок |
| Applebot | Краулер для Apple. Используется для Siri поиска и Spotlight |
| SEO-инструменты | |
| AhrefsBot | Краулер сервиса Ahrefs |
| MJ12Bot | Краулер сервиса Majestic |
| rogerbot | Краулер сервиса MOZ |
| PixelTools | Краулер «Пиксель Тулс» |
| Другое | |
| DuckDuckBot | Бот поисковой системы DuckDuckGo |
Советы по использованию операторов
1. Заблокировать определённые типы файлов.
Этот приём активно используется, если у проекта настроено ЧПУ для всех страниц и документы с GET-параметрами точно являются дублями.
Заблокировать результаты поиска, но не саму страницу поиска.
Имеет ли значение регистр?
Определённо да. При указании правил Disallow / Allow, URL адреса могут быть относительными, но обязаны сохранять регистр.
Но сами директивы могут объявляться как с заглавной, так и с прописной: Disallow: или disallow: — без разницы. Исключение — Sitemap: всегда указывается с заглавной.
Как проверить robots.txt?
Есть множество сервисов проверки корректности файлов robots.txt, но, пожалуй, самые надёжные: Google Search Console и Яндекс.Вебмастер.
Для мониторинга изменений, как всегда, незаменим «Модуль ведения проектов»:
Контроль индексации на вкладке «Аудит» — динамика сканирования страниц сайта в Яндексе и Google.
Robots.txt
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
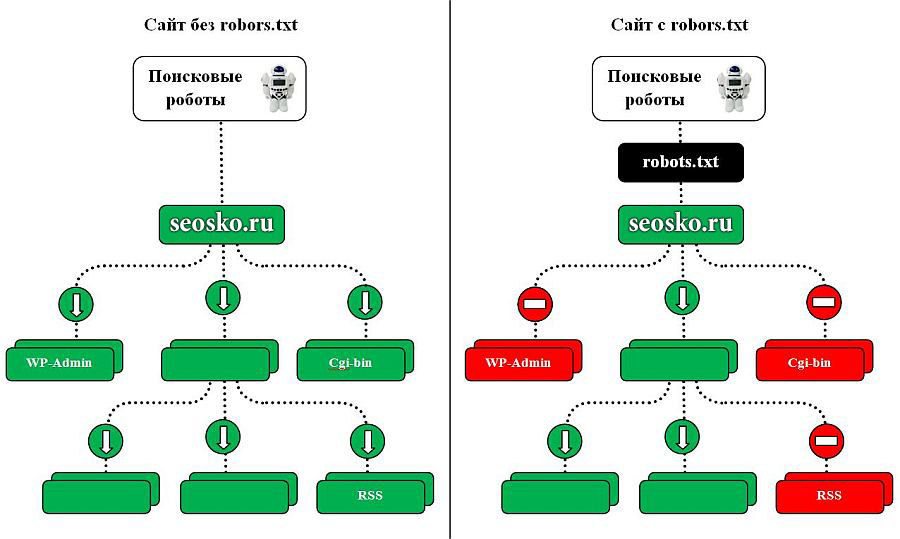
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:
User-agent: *
Для конкретного бота:
User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:
user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Следующие ссылки будут закрыты от индексации:
http://site.ru/?s=
http://site.ru/?s=keyword
http://site.ru/page/?s=keyword
http://site.ru/category/
Следующие ссылки будут открыты для индексации:
http://site.ru/category/cat1/
http://site.ru/category-folder/
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site.ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:
Host: site.ru
Пример 2:
Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:
Crawl-delay: 3
Пример 2:
Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
 Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
Пример robots.txt
Как добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
Типичные ошибки в robots.txt
 В конце статьи приведу несколько типичных ошибок файла robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).



