В чем разница между многоядерным и Многопроцессорным? [дубликат]
в чем разница между MultiCore и MultiProcessor пожалуйста?
7 ответов
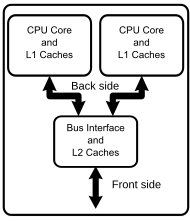
на CPU, или центральный процессор, это то, что обычно называют процессором. Процессор содержит множество отдельных частей, таких как один или несколько кэшей памяти для инструкций и данных, декодеры инструкций и различные типы исполнительных устройств для выполнения арифметических или логических операций.
многопроцессорная система содержит более одного такого процессора, что позволяет им работать параллельно. Это называется SMP или симметричным многопроцессорный.
мультиcore процессор имеет несколько ядер выполнения на одном процессоре. Теперь это может означать разные вещи в зависимости от точной архитектуры, но это в основном означает, что определенное подмножество компонентов процессора дублируется, так что несколько «ядер» могут работать параллельно над отдельными операциями. Это называется CMP, чип-уровень многопроцессорной обработки.
например, многоядерный процессор может иметь отдельный кэш L1 и блок выполнения для каждого ядра, в то время как она имеет общий кэш L2 для всего процессора. Это означает, что, хотя процессор имеет один большой пул медленного кэша, он имеет отдельную быструю память и артитметические/логические блоки для каждого из нескольких ядер. Это позволит каждому ядру выполнять операции одновременно с другими.
есть еще одно подразделение, называемое SMT, Одновременная Многопоточность. Здесь дублируется еще меньшее подмножество компонентов процессора или ядра. Например, ядро SMT может иметь дублирующиеся ресурсы планирования потоков, так что ядро выглядит как два отдельных «процессора» для операционной системы, даже если оно имеет только один набор единиц выполнения. Распространенным решением это гиперпоточность Intel,.
таким образом, вы могли бы многопроцессорных, многоядерных, многопоточных систем. Что-то вроде двух четырехъядерных процессоров, hyperthreaded процессоров даст вам 2x4x2 = 16 логических процессоров с точки зрения операционной система.
различные нагрузки на пользу от различных установок. Однопоточная рабочая нагрузка, выполняемая на основном одноцелевом компьютере, выигрывает от очень быстрой одноядерной / процессорной системы. Нагрузки, которые приносят пользу от высоко-параллельной систем, таких как SMP/СМР/СМТ установок включают те, которые имеют много мелких деталей, которые могут быть одновременно, или системы, которые используются для нескольких вещей одновременно, например, на столе используется для веб-серфинга, играть в флеш игры, смотреть видео-все сразу. В целом, аппаратное обеспечение в наши дни все больше и больше склоняется к высокопараллельным архитектурам, так как большинство одноядерных ЦП/основных необработанных скоростей «достаточно быстры» для общих рабочих нагрузок в большинстве моделей.
мульти-процессор, многоядерный и гипер-поток
может ли кто-нибудь порекомендовать мне некоторые документы, чтобы проиллюстрировать различия между multi-CPU, multi-core и hyper-thread? Я всегда смущен этими различиями и плюсами/минусами каждой архитектуры в разных сценариях.
EDIT: вот мое текущее понимание после обучения в интернете и изучения комментариев других; может ли кто-нибудь просмотреть комментарий, пожалуйста?
спасибо заранее, Джордж!—1—>
3 ответов
Multi-CPU была первая версия: у вас будет одна или несколько материнских плат с одним или несколькими чипами процессора на них. Основная проблема заключалась в том, что процессоры должны были предоставить некоторые из своих внутренних данных другому процессору, чтобы они не мешали им.
следующим шагом была гиперпоточность. Один чип на материнской плате, но у него были некоторые части дважды внутри, поэтому он мог выполнять две инструкции одновременно.
нынешнее развитие многоядерных. Это в основном оригинальная идея (несколько полных процессоров), но в одном чипе. Преимущество: дизайнеры чипов могут легко поместить дополнительные провода для сигналов синхронизации в чип (вместо того, чтобы направлять их на штырь, а затем через переполненную материнскую плату и во второй чип).
супер компьютеры сегодня мульти-процессор, многоядерный: у них есть много материнских плат с обычно 2-4 процессорами на них, каждый процессор многоядерный и каждый имеет свою собственную ОЗУ.
[EDIT] у вас есть это в значительной степени право. Всего несколько незначительных моментов:
Hyper-threading отслеживает два контекста сразу в одном ядре,подвергая больше параллелизма ядру процессора вне порядка. Это поддерживает работу блоков выполнения, даже если один поток застопорился на пропуске кэша, неправильном толковании ветви или ожидании результатов от инструкций с высокой задержкой. Это способ получить большую общую пропускную способность без репликации большого количества оборудования, но если что-то замедляет каждый поток отдельно. см. Этот Q&A для получения более подробной информации, и объяснение того, что было не так с предыдущей формулировкой этого пункта.
основная проблема с multi-CPU заключается в том, что код, запущенный на них, в конечном итоге получит доступ к ОЗУ. Есть N процессоров, но только одна шина для доступа к ОЗУ. Таким образом, у вас должно быть некоторое оборудование, которое гарантирует, что a) каждый процессор получает достаточное количество доступа к ОЗУ, b) доступ к той же части ОЗУ не вызывает проблем и c) большинство важно отметить, что CPU 2 будет уведомлен, когда CPU 1 записывает на некоторый адрес памяти, который CPU 2 имеет во внутреннем кэше. Если этого не произойдет, CPU 2 с радостью использует кэшированное значение, не обращая внимания на то, что оно устарело
просто представьте, что у вас есть задачи в списке и вы хотите распространить их на всех доступных процессорах. Таким образом, CPU 1 получит первый элемент из списка и обновит указатели. CPU 2 сделает то же самое. По соображениям эффективности, оба ЦП не только скопируют немногие байты в кэш, но целая «строка кэша» (что бы это ни было). Предполагается, что, когда вы читаете байт X, Вы тоже скоро прочитаете X+1.
теперь оба процессора имеют копию памяти в своем кэше. Затем CPU 1 получит следующий элемент из списка. Без синхронизации кэша он не заметит, что CPU 2 также изменил список, и он начнет работать над тем же элементом, что и CPU 2.
Это то, что эффективно делает multi-CPU настолько сложным. Побочные эффекты этого могут приведите к производительности, которая хуже того, что вы получите, если весь код будет работать только на одном процессоре. Решение было многоядерные: вы можете легко добавить столько проводов, сколько вам нужно для синхронизации кэшей; вы даже можете скопировать данные из одного кэша в другой (обновление частей строки кэша без необходимости промывать и перезагружать ее) и т. д. Или логика кэша может убедиться, что все процессоры получают одну и ту же строку кэша при доступе к одной и той же части реального ОЗУ, просто блокируя CPU 2 для нескольких наносекунды, пока CPU 1 не внесет свои изменения.
Если у вас есть все внутри одного чипа, сигналы работают намного быстрее, и вы можете иметь столько, сколько хотите (ну, почти :). Кроме того, перекрестные помехи сигнала намного проще контролировать.


СОДЕРЖАНИЕ
Терминология
В отличие от многоядерных систем, термин « многопроцессорность» относится к нескольким физически отдельным процессорам (которые часто содержат специальные схемы для облегчения связи друг с другом).
Термины многоядерный и массовый многоядерный иногда используются для описания многоядерных архитектур с особенно большим количеством ядер (от десятков до тысяч).
Разработка
Коммерческие стимулы
Несколько бизнес-мотивов стимулируют разработку многоядерных архитектур. На протяжении десятилетий можно было улучшить производительность ЦП за счет уменьшения площади интегральной схемы (ИС), что снизило стоимость одного устройства на ИС. В качестве альтернативы, для той же области схемы можно было бы использовать больше транзисторов в конструкции, что повысило бы функциональность, особенно для архитектур со сложным набором команд (CISC). Тактовые частоты также выросли на порядки в десятилетия конца 20-го века, с нескольких мегагерц в 1980-х годах до нескольких гигагерц в начале 2000-х.
Технические факторы
Поскольку производители компьютеров уже давно реализовали конструкции с симметричной многопроцессорной обработкой (SMP) с использованием дискретных ЦП, проблемы, связанные с реализацией архитектуры многоядерных процессоров и ее поддержкой программным обеспечением, хорошо известны.
Преимущества
Предполагая, что кристалл физически может поместиться в корпус, конструкции многоядерных процессоров требуют гораздо меньше места на печатной плате, чем конструкции многочиповых SMP. Кроме того, двухъядерный процессор потребляет немного меньше энергии, чем два связанных одноядерных процессора, в основном из-за меньшей мощности, необходимой для передачи сигналов, внешних по отношению к микросхеме. Кроме того, ядра используют общие схемы, такие как кэш L2 и интерфейс с внешней шиной (FSB). С точки зрения конкурирующих технологий для доступной области кремниевых кристаллов, многоядерная конструкция может использовать проверенные конструкции библиотеки ядер ЦП и производить продукт с меньшим риском ошибки проектирования, чем при разработке новой конструкции с более широким ядром. Кроме того, добавление большего количества кеша страдает от уменьшения отдачи.
Многоядерные чипы также обеспечивают более высокую производительность при меньшем энергопотреблении. Это может быть важным фактором для мобильных устройств, работающих от батарей. Поскольку каждое ядро многоядерного процессора обычно более энергоэффективно, чип становится более эффективным, чем одно большое монолитное ядро. Это обеспечивает более высокую производительность при меньшем потреблении энергии. Однако проблема заключается в дополнительных накладных расходах на написание параллельного кода.
Недостатки
Максимальное использование вычислительных ресурсов, предоставляемых многоядерными процессорами, требует корректировки как поддержки операционной системы (ОС), так и существующего прикладного программного обеспечения. Кроме того, способность многоядерных процессоров увеличивать производительность приложений зависит от использования нескольких потоков в приложениях.
Аппаратное обеспечение
Тенденции
Архитектура
Состав и баланс ядер в многоядерной архитектуре очень разнообразны. В некоторых архитектурах используется один повторяющийся проект ядра («однородный»), в то время как в других используется смесь разных ядер, каждое из которых оптимизировано для своей « разнородной » роли.
Реализация и интеграция нескольких ядер существенно влияет как на навыки программирования разработчика, так и на ожидания потребителей в отношении приложений и интерактивности по сравнению с устройством. Устройство, рекламируемое как восьмиядерное, будет иметь независимые ядра только в том случае, если оно рекламируется как True Octa-core или аналогичный стиль, в отличие от всего лишь двух наборов четырехъядерных процессоров, каждый с фиксированной тактовой частотой.
Статья Рика Мерритта, EE Times 2008, «Разработчики процессоров обсуждают будущее многоядерных процессоров», включает следующие комментарии:
Чак Мур [. ] предположил, что компьютеры должны быть похожи на мобильные телефоны, с использованием различных специализированных ядер для запуска модульного программного обеспечения, запланированного с помощью высокоуровневого интерфейса программирования приложений.
Программные эффекты
Принимая во внимание растущее внимание к конструкции многоядерных микросхем из-за серьезных проблем с тепловым и энергопотреблением, возникающих в результате любого дальнейшего значительного увеличения тактовой частоты процессора, степень, в которой программное обеспечение может быть многопоточным для использования преимуществ этих новых микросхем, вероятно, будет меньше. единственное самое серьезное ограничение производительности компьютеров в будущем. Если разработчики не могут разработать программное обеспечение для полного использования ресурсов, предоставляемых несколькими ядрами, они в конечном итоге достигнут непреодолимого потолка производительности.
Управление параллелизмом приобретает центральную роль в разработке параллельных приложений. Основные этапы разработки параллельных приложений:
Разбиение на разделы Этап разделения проекта предназначен для выявления возможностей параллельного выполнения. Следовательно, основное внимание уделяется определению большого количества небольших задач, чтобы получить то, что называется детальной декомпозицией проблемы. Коммуникация Задачи, сгенерированные разделом, предназначены для одновременного выполнения, но, как правило, не могут выполняться независимо. Вычисления, выполняемые в одной задаче, обычно требуют данных, связанных с другой задачей. Затем данные должны передаваться между задачами, чтобы можно было продолжить вычисления. Этот информационный поток определяется на этапе коммуникации проекта. Агломерация На третьем этапе развитие движется от абстрактного к конкретному. Разработчики пересматривают решения, принятые на этапах разделения и обмена данными, с целью получения алгоритма, который будет эффективно выполняться на некотором классе параллельных компьютеров. В частности, разработчики рассматривают целесообразность объединения или агломерации задач, определенных на этапе разделения, чтобы обеспечить меньшее количество задач, каждая из которых имеет больший размер. Они также определяют, стоит ли копировать данные и вычисления. Картография На четвертом и последнем этапе проектирования параллельных алгоритмов разработчики определяют, где должна выполняться каждая задача. Эта проблема сопоставления не возникает на однопроцессорных компьютерах или компьютерах с общей памятью, которые обеспечивают автоматическое планирование задач.
Лицензирование
Поставщики могут лицензировать некоторое программное обеспечение «на процессор». Это может вызвать двусмысленность, поскольку «процессор» может состоять либо из одного ядра, либо из комбинации ядер.
Встроенные приложения

Встроенные вычисления работают в области процессорной технологии, отличной от таковой для «обычных» ПК. То же самое технологическое стремление к многоядерности применимо и здесь. Действительно, во многих случаях приложение «естественным образом» подходит для многоядерных технологий, если задача может быть легко разделена между различными процессорами.
Сетевые процессоры
Цифровая обработка сигналов
Гетерогенные системы
Примеры оборудования
Коммерческий
Бесплатно
Академический
Контрольные точки
При исследовании и разработке многоядерных процессоров часто сравниваются многие варианты, и для помощи в таких оценках разрабатываются тесты. Существующие тесты включают SPLASH-2, PARSEC и COSMIC для гетерогенных систем.
990x.top
Простой компьютерный блог для души)
ASUS Multicore Enhancement — что это, включать или нет?
 Данный материал расскажет об одной функции BIOS. Без необходимости изменять опции BIOS категорически не рекомендуется — это может привести к проблемам с железом.
Данный материал расскажет об одной функции BIOS. Без необходимости изменять опции BIOS категорически не рекомендуется — это может привести к проблемам с железом.
ASUS Multicore Enhancement — что это?
Включение автоматического увеличения множителя частоты процессора.
Важные моменты
Частота процессора может регулироваться множителем. Это число, на которое умножается частота шины. Простыми словами — частота проца состоит из маленьких частей, чтобы приумножить маленькие части — нужен множитель. Простой пример: проц 3 ГГц состоит из 10 частей по 300 МГц. Значение множителя — x10, так как 300 ГГц умножить на 10 — 3000 МГц (или 3 ГГЦ). Установка значения x12 приведет к частоте 3600 ГГц. Для изменения данного значения может присутствовать специальная функция в BIOS.

Может иметь три значения для множителя:
ASUS Multicore Enhancement — включать или нет?
На практике данная опция позволяет материнской плате автоматически увеличить множитель проца, некий разгон. Принцип работы зависит от материнки, плата может сразу увеличить или только при максимальной нагрузке (некий turbo boost).
Включать или нет? При наличии качественной материнской платы, качественного охлаждения — можно попробовать. Охлаждение лучше водяное или массивный радиатор (например фирмы Noctua). ПК реально может стать работать быстрее, но тепловыделение (TDP) — скорее всего увеличится.
Заключение
Как разогнать процессор Intel на примере Intel Core i9-9900K


Содержание
Содержание
Разгон процессоров от компании Intel в первую очередь связан с выбором процессора с индексом K или KF (К — означает разблокированный множитель) и материнской платы на Z-чипсете (Z490–170). А также от выбора системы охлаждения.
Чтобы понять весь смыл разгона, нужно определиться, что вы хотите получить от разгона. Стабильной работы и быть уверенным, что не вылезет синий экран смерти? Или же вам нужно перед друзьями пощеголять заветной частотой 5000–5500 MHz?
Сегодня будет рассмотрен именно первый вариант. Стабильный разгон на все случаи жизни, однако и тем, кто выбрал второй вариант, будет полезно к прочтению.
Выбор материнской платы
К разгону нужно подходить очень ответственно и не пытаться разогнать Core i9-9900K на материнских платах, которые не рассчитаны на данный процессор (это, к примеру, ASRock Z390 Phantom Gaming 4, Gigabyte Z390 UD, Asus Prime Z390-P, MSI Z390-A Pro и так далее), так как удел этих материнских плат — процессоры Core i5 и, возможно, Core i7 в умеренном разгоне. Intel Core i9-9900K в результате разгона и при серьезной постоянной нагрузке потребляет от 220 до 300 Ватт, что неминуемо вызовет перегрев цепей питания материнских плат начального уровня и, как следствие, выключение компьютера, либо сброс частоты процессора. И хорошо, если просто к перегреву, а не прогару элементов цепей питания.
Выбор материнской платы для разгона — это одно из самых важных занятий. Ведь именно функционал платы ее настройки и качество элементной базы и отвечают за стабильность и успех в разгоне. Ознакомиться со списком пригодных материнских плат можно по ссылке.
Все материнские платы разделены на 4 группы: от начального уровня до продукта для энтузиастов. По большому счету, материнские платы второй и, с большой натяжкой, третьей группы хорошо справятся с разгоном процессора i9-9900K.
Выбор системы охлаждения
Немаловажным фактором успешного разгона является выбор системы охлаждения. Как я уже говорил, если вы будете разгонять на кулере который для этого не предназначен, у вас ничего хорошего не получится. Нам нужна либо качественная башня, способная реально отводить 220–250 TDP, либо жидкостная система охлаждения подобного уровня. Здесь все зависит только от бюджета.
Из воздушных систем охлаждения обратить внимание стоит на Noctua NH-D15 и be quiet! DARK ROCK PRO 4.
Силиконовая лотерея
И третий элемент, который участвует в разгоне — это сам процессор. Разгон является лотереей, и нельзя со 100% уверенностью сказать, что любой процессор с индексом К получится разогнать до частоты 5000 MHz, не говоря уже о 5300–5500 MHz (имеется в виду именно стабильный разгон). Оценить шансы на выигрыш в лотерее можно, пройдя по ссылке, где собрана статистика по разгону различных процессоров.

Приступаем к разгону
Примером в процессе разгона будет выступать материнская плата ASUS ROG MAXIMUS XI HERO и процессор Intel Core i9-9900K. За охлаждение процессора отвечает топовый воздушный кулер Noctua NH-D15.
Первым делом нам потребуется обновить BIOS материнской платы. Сделать это можно как напрямую, из специального раздела BIOS с подгрузкой из интернета, так и через USB-накопитель, предварительно скачав последнюю версию c сайта производителя. Это необходимо, потому как в новых версиях BIOS уменьшается количество багов. BIOS, что прошит в материнской плате при покупке, скорее всего, имеет одну из самых ранних версий.
Тактовая частота процессора формируется из частоты шины BCLK и коэффициента множителя Core Ratio.

Как уже было сказано, разгон будет осуществляться изменением множителя процессора.
Заходим в BIOS и выбираем вкладку Extreme Tweaker. Именно тут и будет происходить вся магия разгона.

Первым делом меняем значение параметра Ai Overclocker Tuner с Auto в Manual. У нас сразу становятся доступны вкладки, отвечающие за частоту шины BCLK Frequency и CPU Core Ratio, отвечающая за возможность настройки множителя процессора.
ASUS MultiCore Enhancement какой-либо роли, когда Ai Overclocker Tuner в режиме Manual, не играет, можно либо не трогать, либо выключить, чтобы глаза не мозолило. Одна из уникальных функций Asus, расширяет лимиты TDP от Intel.
SVID Behavior — обеспечивает взаимосвязь между процессором и контроллером напряжения материнской платы, данный параметр используется при выставлении адаптивного напряжения или при смещении напряжения (Offset voltages). Начать разгон в любом случае лучше с фиксированного напряжения, чтобы понять, что может конкретно ваш экземпляр процессора, ведь все они уникальны. Если используется фиксация напряжения, значение этого параметра просто игнорируется. Установить Best Case Scenario. Но к этому мы еще вернемся чуть позже.
AVX Instruction Core Ratio Negative Offset — устанавливает отрицательный коэффициент при выполнении AVX-инструкций. Программы, использующие AVX-инструкции, создают сильную нагрузку на процессор, и, чтобы не лишаться заветных мегагерц в более простых задачах, придумана эта настройка. Несмотря на все большее распространение AVX-инструкции, в программах и играх они встречаются все еще редко. Все сугубо индивидуально и зависит от задач пользователя. Я использую значение 1.
Наример, если нужно, чтобы частота процессора при исполнении AVX инструкций была не 5100 MHz, а 5000 MHz, нужно указать 1 (51-1=50).
Далее нас интересует пункт CPU Core Ratio. Для процессоров с индексом K/KF выбираем Sync All Cores (для всех ядер).
1-Core Ratio Limit — именно тут и задается множитель для ядер процессора. Начать лучше с 49–50 для 9 серии и 47–48 для 8 серии процессоров Intel соответственно, с учетом шины BCLK 100 мы как раз получаем 4900–5000 MHz и 4700–4800 MHz.

DRAM Frequency — отвечает за установку частоты оперативной памяти. Но это уже совсем другая история.
CPU SVID Support — данный параметр необходим процессору для взаимодействия с регулятором напряжения материнской платы. Блок управления питанием внутри процессора использует SVID для связи с ШИМ-контроллером, который управляет регулятором напряжения. Это позволяет процессору выбирать оптимальное напряжение в зависимости от текущих условий работы. В адаптивном режиме установить в Auto или Enabled. При отключении пропадет мониторинг значений VID и потребляемой мощности.
CPU Core/Cache Current Limit Max — лимит по току в амперах (A) для процессорных ядер и кэша. Выставляем 210–220 A. Этого должно хватить всем даже для 9900к на частоте 5100MHz. Максимальное значение 255.75.
Min/Max CPU Cache Ratio — множитель кольцевой шины или просто частота кэша. Для установки данного параметра есть неофициальное правило, множитель кольцевой шины примерно на два–три пункта меньше, чем множитель для ядер.
Например, если множитель для ядер 51, то искать стабильность кэша нужно от 47. Все очень индивидуально. Начать лучше с разгона только ядер. Если ядро стабильно, можно постепенно повышать частоту кэша на 1 пункт.
Разгон кольцевой шины в значении 1 к 1 с частотой ядер это идеальный вариант, но встречается такое очень редко на частоте 5000 MHz.
Заходим в раздел Internal CPU Power Management для установки лимитов по энергопотреблению.

SpeedStep — во время разгона, выключаем. На мой взгляд, совершенно бесполезная функция в десктопных компьютерах.
Long Duration Packet Power Limit — задает максимальное энергопотребление процессора в ватах (W) во время долгосрочных нагрузок. Выставляем максимум — 4095/6 в зависимости от версии Bios и производителя.
Short Duration Package Power Limit — задает максимальное возможное энергопотребление процессором в ваттах (W) при очень кратковременных нагрузках. Устанавливаем максимум — 4095/6.
Package Power Time Window — максимальное время, в котором процессору разрешено выходить за установленные лимиты. Устанавливаем максимальное значение 127.
Установка максимальных значений у данных параметров отключает все лимиты.
IA AC Load Line/IA DC Load Line — данные параметры используются в адаптивном режиме установки напряжения, они задают точность работы по VID. Установка этих двух значений на 0,01 приведет ближе к тому напряжению, которое установил пользователь, при этом минимизируются пики. Если компьютер, после установки параметра IA DC Load line в значение 0,01, уходит в «синьку», рекомендуется повысить значение до 0,25. Фиксированное напряжение будет игнорировать значения VID процессора, так что установка IA AC Load Line/IA DC Load Line в значение 0,01 не будет иметь никакого влияния на установку ручного напряжения, только при работе с VID. На материских платах от Gigabyte эти параметры необходимо устанавливать в значение 1.
Возвращаемся в меню Extrime Tweaker для выставления напряжения.

BCLK Aware Adaptive Voltage — если разгоняете с изменением значения шины BCLK, — включить.
CPU Core/Cache Voltage (VCore) — отвечает за установку напряжения для ядер и кэша. В зависимости от того, какой режим установки напряжения вы выберете, дальнейшие настройки могут отличаться.
Существует три варианта установки напряжения: адаптивный, фиксированный и смещение. На эту тему много мнений, однако, в моем случае, адаптивный режим получается холоднее. Зачастую для 9 поколения процессоров Intel оптимальным напряжением для использования 24/7 является 1.350–1.375V. Подобное напряжение имеет место выставлять для 9900К при наличии эффективного охлаждения.
Поднимать напряжение выше 1.4V для 8–9 серии процессоров Intel совершенно нецелесообразно и опасно. Рост потребления и температуры не соразмерен с ростом производительности, которую вы получите в результате такого разгона.
Offset mode Sign — устанавливает, в какую сторону будет происходить смещение напряжения, позволяет добавлять (+) или уменьшать (-) значения к выставленному вольтажу.
Additional Turbo Mode CPU Core Voltage — устанавливает максимальное напряжение для процессора в адаптивном режиме. Я использую 1.350V, данное напряжение является некой золотой серединой по соотношению температура/безопасность.
Offset Voltage — величина смещения напряжения. У меня используется 0.001V, все очень индивидуально и подбирается во время тестирования.
DRAM Voltage — устанавливает напряжение для оперативной памяти. Условно безопасное значение при наличии радиаторов на оперативной памяти составляет 1.4–1.45V, без радиаторов до 1.4V.
CPU VCCIO Voltage (VCCIO) — устанавливает напряжение на IMC и IO.
CPU System Agent Voltage (VCCSA) — напряжение кольцевой шины и контроллера кольцевой шины.
Таблица с соотношением частоты оперативной памяти и напряжениями VCCIO и VCCSA:

Однако, по личному опыту, даже для частоты 4000 MHz требуется напряжение примерно 1.15V для VCCIO и 1.2V для VCCSA. На мой взгляд, разумным пределом является для VCCIO 1.20V и VCCSA 1.25V. Все что выше, должно быть оправдано либо частотой разгона оперативной памяти за 4000MHz +, либо желанием получить максимум на свой страх и риск.
Часто при использовании XMP профиля оперативной памяти параметры VCCIO и VCCSA остаются в значении Auto, тем самым могут повыситься до критических показателей, это, в свою очередь, чревато деградацией контроллера памяти с последующим выхода процессора из строя.
Установка LLC
LLC (Load-Line Calibration) В зависимости от степени нагрузки на процессор, напряжение проседает, это называется Vdroop. LLC компенсирует просадку напряжения (vCore) при высокой нагрузке. Но есть определенные особенности работы с LLC.
Например, мы установили фиксированное напряжение в BIOS для ядер 1.35V. После старта компьютера на рабочем столе мы видим уже не 1.35V, а 1.32V. Но, если запустим более требовательное к ресурсам процессора приложение, например Linx, напряжение может провалиться до 1.15V, и мы получим синий экран или «невязки», ошибки или выпадение ядер.
Чтобы напряжение проседало не так сильно и придумана функция LLC c разным уровнем компенсации просадки. Не стоит сразу гнаться за установкой самого высокого/сильного уровня компенсации. В этом нет никакого смысла. Это может быть даже опасно ввиду чрезвычайно завышенного напряжения (overshoot) в момент запуска и прекращения ресурсоемкой нагрузки перед и после Vdroop. Нужно оптимально подобрать выставленное напряжение с уровнем LLC. Напряжение под нагрузкой и должно проседать, но должна оставаться стабильность. Конкретно у меня в BIOS материнской платы стоит 1.35V c LLC 5. Под нагрузкой напряжение опускается до 1.19–1.21V, при этом процессор остается абсолютно стабильным под длительной и серьезной нагрузкой. Завышенное напряжение выливается в большем потреблении и, как следствие, более высоких температурах.
Например, при установке LCC 6 с напряжением 1.35V во время серьезной нагрузки напряжение проседает до 1.26V, при этом справиться с энергопотреблением и температурой с использованием воздушной системы охлаждения уже нет возможности.
Чтобы наглядно изучить процесс работы LLC и то, какое влияние оказывает завышенный LLC на Overshoot’ы, предлагаю ознакомиться с работами elmora, более подробно здесь.
Идеальным вариантом, с точки зрения Overshoot’ов, является использование LLC в значении 1 (самое слабое на платах Asus), однако добиться стабильности с таким режимом работы LLC во время серьезной нагрузки будет сложно, как выход, существенное завышенное напряжение в BIOS. Что тоже не очень хорошо.

Пример использовании LLC в значении 8 (самое сильно на платах Asus)

При появлении нагрузки на процессоре напряжение просело, но потом в работу включается LLC и компенсирует просадку, причем делая это настолько агрессивно, что напряжение на мгновение стало даже выше установленного в BIOS.
В момент прекращения нагрузки мы видим еще больший скачок напряжения (Overshoot), а потом спад, работа LLC прекратилась. Вот именно эти Overshoot’ы, которые значительно превышают установленное напряжение в BIOS, опасны для процессора. Какого-либо вреда на процессор Undershoot и Vdroop не оказывают, они лишь являются виновниками нестабильности работы процессора при слишком сильных просадках.

CPU Current Capability — увеличивает допустимое значение максимального тока, подаваемого на процессор. Сильно не увлекайтесь, с увеличением растет так же и температура. Оптимально на 130–140%
VRM Spread Spectrum — лучше выключить и кактус у компьютера поставить, незначительное уменьшение излучения за счет ухудшения сигналов да и шина BLCK скакать не будет.
Все остальные настройки нужны исключительно для любителей выжимать максимум из своих систем любой ценой.
Проверка стабильности
После внесения всех изменений, если компьютер не загружается, необходимо повысить напряжение на ядре или понизить частоту. Когда все же удалось загрузить Windows, открываем программу HWinfo или HWMonitor для мониторинга за состоянием температуры процессора и запускаем Linx или любую другую программу для проверки стабильности и проверяем, стабильны ли произведенные настройки. Автор пользуется для проверки стабильности разгона процессора программами Linx с AVX и Prime95 Version 29.8 build 6.
Если вдруг выявилась нестабильность, то повышаем напряжение в пределах разумного и пробуем снова. Если стабильности не удается добиться, понижаем частоту. Все значения частоты и напряжения сугубо индивидуальны, и дать на 100 % верные и подходящие всем значения нельзя. Как уже писалось, разгон — это всегда лотерея, однако, купив более качественный продукт, шанс выиграть всегда будет несколько выше.

Резюмируем все выше сказанное
Максимально допустимое напряжение на процессор составляет до 1.4V. Оптимально в пределах 1.35V, со всем что выше, возникают трудности с температурой под нагрузкой.
Существует 3 способа установки напряжения:
Adaptive mode — это предпочтительный способ для установки напряжения.
Он работает с таблицей значений VID вашего процессора и позволяет снижать напряжение в простое.
Оптимально найти стабильное напряжение в фиксированном режиме, потом выставить адаптивный режим и вбить это знание для адаптивного режима, далее выставить величину смещения по необходимости.
При разгоне оперативной памяти и использовании XMP профиля, необходимо контролировать напряжение на CPU VCCIO Voltage (VCCIO) и CPU System Agent Voltage (VCCSA).
Подобрать оптимальный уровень работы LLC, VDROOP ДОЛЖЕН БЫТЬ.
Название и принцип работы LLC у разных производителей



