Технология Intel Hyper-Threading — что это и как работает

Впервые технология Hyper-Threading (HT, гиперпоточность) появилась 15 лет назад — в 2002 году, в процессорах Pentium 4 и Xeon, и с тех пор то появлялась в процессорах Intel (в линейке Core i, некоторых Atom, в последнее время еще и в Pentium), то исчезала (ее поддержки не было в линейках Core 2 Duo и Quad). И за это время она обросла мифическими свойствами — дескать ее наличие чуть ли не удваивает производительность процессора, превращая слабые i3 в мощные i5. При этом другие говорят что HT — обычная маркетинговая уловка, и толку от нее мало. Правда как обычно по середине — местами толк от нее есть, но двухкртаного прироста ждать точно не стоит.
Техническое описание технологии
Начнем с определения, данного на сайте Intel:
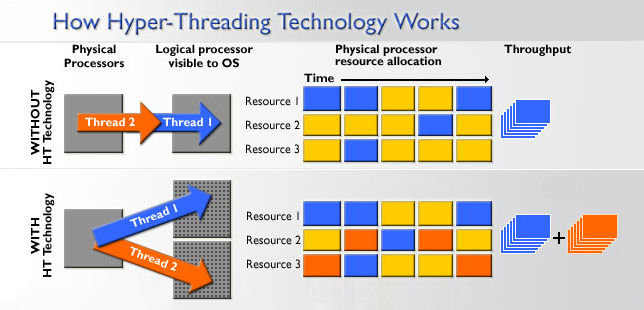
Допустим перед процессором стоят две задачи. Если процессор имеет одно ядро, то он будет выполнять их последовательно, если два — то параллельно на двух ядрах, и время выполнения обеих задач будет равно времени, затраченному на более тяжелую задачу. Но что если процессор одноядерный, но поддерживает гиперпоточность? Как видно на картинке выше при выполнении одной задачи процессор не занят на 100% — какие-то блоки процессора банально не нужны в данной задаче, где-то ошибается модуль предсказания переходов (который нужен для предсказания, будет ли выполнен условный переход в программе), где-то происходит ошибка обращения к кэшу — в общем и целом при выполнении задачи процессор редко бывает занят больше, чем на 70%. А технология HT как раз «подпихивает» незанятым блокам процессора вторую задачу, и получается что одновременно на одном ядре обрабатываются две задачи. Однако удвоения производительности не происходит по понятным причинам — очень часто получается так, что двум задачам нужен один и тот же вычислительный блок в процессоре, и тогда мы видим простой: пока одна задача обрабатывается, выполнение второй на это время просто останавливается (синие квадраты — первая задача, зеленые — вторая, красные — обращение задач к одному и тому же блоку в процессоре):
В итоге время, затраченное процессором с HT на две задачи, оказывается больше времени, требуемого на вычисление самой тяжелой задачи, но меньше того времени, которое нужно для последовательного вычисления обеих задач.
Плюсы и минусы технологии
С учетом того, что кристалл процессора с поддержкой HT физчески больше кристалла процессора без HT в среднем на 5% (именно столько занимают дополнительные блоки регистров и контроллеры прерываний), а поддержка HT позволяет нагрузить процессор на 90-95%, то в сравнении с 70% без HT мы получаем, что прирост в лучшем случае будет 20-30% — цифра достаточно большая.
Программы, плохо работающие с гиперпоточностью
Традиционно это большинство игр — их обычно бывает трудно грамотно распараллелить, поэтому зачастую четырех физических ядер на высоких частотах (i5 K-серии) более чем хватает для игр, распараллелить которые под 8 логических ядер в i7 оказывается непосильной задачей. Однако стоит учитывать и то, что есть фоновые процессы, и если процессор не поддерживает HT, то их обработка ложится на физические ядра, что может замедлить игру. Тут i7 с HT оказывается в выигрыше — все фоновые задачи традиционно имеют пониженный приоритет, поэтому при одновременной работе на одном физическом ядре игры и фоновой задаче игра будет получать повышенный приоритет, и при этом фоновая задача не будет «отвлекать» занятые игрой ядра — именно поэтому для стриминга или записи игр лучше брать i7 с гиперпоточностью.
Итоги
Пожалуй тут остается только один вопрос — так имеет ли смысл брать процессоры с HT или нет? Если вы любите держать одновременно открытыми пяток программ и при этом играть в игры, или же занимаетесь обработкой фото, видео или моделированием — да, разумеется стоит брать. А если вы привыкли перед запуском тяжелой программы закрывать все другие, и не балуетесь обработкой или моделированием, то процессор с HT вам ни к чему.
Технологии многопоточности процессоров: принцип работы и сферы применения


Содержание
Содержание
Физические ядра, логические ядра, технологии многопоточности — все это разрабатывалось инженерами для увеличения производительности компьютерного железа, требования к которому постоянно растут. Программы и игры требуют все больше ресурсов. Как же производители процессоров увеличивают мощность своих детищ? Процессор является «сердцем» компьютера и выполняет вычисления, необходимые для работы софта. Модели CPU отличаются между собой даже в рамках одного семейства. Например, Intel Core i7 отличается от i5 технологией многопоточности под названием «Hyper-Threading», о которой далее пойдет речь (Core i3, i9, и некоторые Pentium также обладают данной технологией).
Принцип работы процессорных ядер и многопоточности
В современных операционных системах одновременно работает множество процессов.
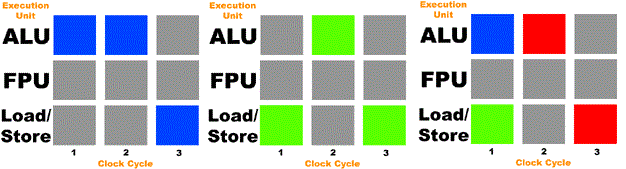
Нагрузка от операционной системы на процессор идет по так называемому конвейеру, на который «выкладываются» нужные задачи для ядра. В качестве примера возьмем одно ядро процессора на частоте 4 ГГц с одним ALU (арифметико-логическое устройство) и одним FPU (математический сопроцеесор). Частота в 4 ГГц означает, что ядро исполняет 4 миллиарда тактов в секунду. К ядру по конвейеру поступают задачи, требующие исполнительной мощности, на которые тратится процессорное время.

Часто происходят случаи, когда для выполнения необходимой операции процессору приходится ждать данные из кеша более низкой скорости (L3 кеш), или же оперативной памяти. Данная ситуация называется кэш-промах. Это происходит, когда в кэше ядра не была найдена запрошенная информация и приходится обращаться к более медленной памяти. Также существуют и другие причины, заставляющие прерывать выполнение операции ядром, что негативно сказывается на производительности.
Данный конвейер можно представить, как настоящую сборочную линию на заводе — рабочий (ядро) выполняет работу, поступающую к нему на ленту. И если необходимо взять нужный инструмент, работник отходит, оставляя конвейер простаивать без работы. То есть, исполняемая задача прерывается. Инструментом, за которым пошел рабочий, в данном случае является информация из оперативной памяти или же L3 кэша. Поскольку L1 и L2 кэш намного быстрее, чем любая другая память в компьютере, работа с вычислениями теряет в скорости.
На конвейере с одним потоком не могут выполняться одновременно несколько процессов. Ядро постоянно прерывает выполнение одной операции для другой, более приоритетной. Если появятся две одинаково приоритетные задачи, одна из них обязательно будет остановлена, ведь ядро не сможет работать над ними одновременно. И чем больше поступает задач одновременно, тем больше прерываний происходит.
Способы увеличения производительности процессоров
Разгон
При увеличении частоты ядра повышается количество исполняемых операций за секунду. Казалось бы, с возрастанием производительности процессора проблемы должны исчезнуть. Но все не так просто, как хотелось бы думать. Прирост от увеличения частоты ЦП нелинейный. Множество процессов все еще делят одно ядро между собой и обращаются к памяти. Кроме того, не решается проблема с кэш-промахами и прерываниями операций, поскольку объем кэша от разгона не изменяется. Разгон — не самый лучший способ решения проблемы нехватки потоков. В пример можно привести всю ту же сборочную линию: рабочий увеличивает темп работы, но по-прежнему не умеет собирать два и более заказа одновременно.
Увеличение количества потоков на ядро
В процессорах Intel данная технология носит название Hyper-Threading, а в процессорах от Amd — SMT. Производители добавляют еще один регистр для работы со вторым конвейером. Пока один поток простаивает, ожидая нужные данные, свободная вычислительная мощность может быть использована вторым потоком. На кристалл же добавлен еще один контроллер прерываний и набор регистров.
Появляется возможность избавиться от последствий прерывания операций и сокращения времени простоя процессорной мощности. Благодаря чему ядро с двумя потоками выполняет больше работы за одинаковый отрезок времени, нежели в случае с однопотоком. На примере с рабочим: у конвейера появляется вторая сборочная линия, на которую выкладываются заказы. Пока производство на первой ленте простаивает в ожидании нужных инструментов, рабочий приступает к работе на второй ленте, сокращая время перерыва.

Стоит учитывать, что логический поток это не второе ядро, как может показаться с первого взгляда. Это лишь дополнительная «линия производства», чтобы более эффективно использовать доступную мощность. Из минусов технологии Hyper-Threading или SMT можно выделить увеличение тепловыделения, недостаток кэша (кэш на два потока по-прежнему общий), и проблемы с оптимизацией некоторых программ или игр, не способных отличать настоящее ядро от логического потока.
Именно по этой причине процессоры серии i7 «горячее» и имеют больше кэша по сравнению с i5. Использование технологии многопоточности может принести примерно до 30 % прироста производительности. Все это применимо как к Intel Hyper-Threading, так и к AMD SMT, поскольку технологии во многом схожи. Может возникнуть вопрос: «Если можно добавить второй поток, то почему бы не добавить третий и четвертый?» Это реализуемо, но не имеет смысла, поскольку кэш одного ядра достаточно мал для большего количества потоков и прироста производительности практически не будет.
Увеличение количества ядер
Это самый действенный способ решения проблемы, поскольку каждый конвейер теперь располагает своим FPU, ALU и кэшем, который не придется делить с другим потоком. Разные процессы используют разные ядра, из-за чего реже происходят кэш-промахи и конфликты приоритетных задач. Способ, разумеется, несет в себе некоторые издержки для производителей: дороговизна разработки и производства, увеличение тепловыделения и размера кристалла, и, как результат, повышается итоговая стоимость процессора.

Сферы применения многопоточных процессоров
С развитием компьютерных технологий перечень программ, использующих многопоточность, неуклонно растет. Это дает огромный простор разработчикам для создания нового софта и игр. Например, сейчас каждый современный triple-A проект оптимизирован для многопоточных процессоров, что позволяет наслаждаться игрой, получая высокий уровень fps на многоядерном CPU.
Еще больше распространены многоядерные системы в среде разработчиков. Программы для 3D-моделирования, монтажа видео и создания музыки требуют параллельного выполнения большого количества задач, с чем хорошо справляются системы с Hyper-Threading или SMT. В операционных системах мощность одного потока может тратиться на фоновые задачи (Skype, браузер, мессенджер), в то время как остальные задействуются для тяжелой игры или программы.
Но далеко не всегда увеличение количества потоков означает увеличение общей производительности. Почему же SMT процессоры порой уступают немногопоточным собратьям? Дело в программной поддержке. Иногда плохо оптимизированные программы не могут отличать логический поток от настоящего ядра, из-за чего на одно ядро может попасть две тяжелых задачи и замедлить работу. Тем не менее, подобные технологии имеют огромный потенциал, главное — грамотно реализовать его на программном уровне.
Еще раз о Hyper Threading
Некоторое время назад автор позволил себе «слегка поворчать» по поводу новой парадигмы от Intel Hyper Threading. К чести корпорации Intel, недоумение автора не осталось ею незамеченной. А посему автору предложили помощь в выяснении (как деликатно дали оценку менеджеры корпорации) «настоящей» ситуации с технологией Hyper Threading. Ну что же желание выяснить истину можно только похвалить. Не так ли, уважаемый читатель? По крайней мере, именно так звучит одна из прописных истин: правда это хорошо. Что ж, будем стараться действовать в соответствии с данной фразой. Тем более, что действительно появилось некоторое количество новых сведений.
Для начала сформулируем, что же именно мы знаем про технологию Hyper Threading:
1. Данная технология предназначена для увеличения эффективности работы процессора. Дело в том, что, по оценкам Intel, большую часть времени работает всего 30% (кстати, достаточно спорная цифра подробности ее вычисления неизвестны) всех исполнительных устройств в процессоре. Согласитесь, это достаточно обидно. И то, что возникла идея каким-то образом «догрузить» остальные 70% выглядит вполне логично (тем более что сам по себе процессор Pentium 4, в котором и внедрят эту технологию, отнюдь не страдает от избыточной производительности на мегагерц). Так что эту идею автор вынужден признать вполне здравой.
2. Суть технологии Hyper Threading состоит в том, что во время исполнения одной «нити» программы простаивающие исполнительные устройства могут заняться исполнением другой «нити» программы (или «нити» другой программы). Или, например, исполняя одну последовательность команд, ожидать данных из памяти для исполнения другой последовательности.
3. Естественно, выполняя различные «нити», процессор должен каким-либо образом отличать, какие команды к какой «нити» относятся. Значит, есть какой-то механизм (некая метка), благодаря которой процессор отличает, к какой «нити» относятся команды.
5. Также известно, что в случае, когда несколько «нитей» претендуют на одни и те же ресурсы, либо одна из «нитей» ждет данных во избежание падения производительности программисту необходимо вставлять специальную команду «pause». Естественно, это потребует очередной перекомпиляции программ.
6. Также понятно, что возможны ситуации, когда попытки одновременного исполнения нескольких «нитей» приведут к падению производительности. Например, из-за того, что размер кэша L2 не бесконечный, а активные «нити» будут пытаться загрузить кэш возможна ситуация, когда такая «борьба за кэш» приведет к постоянной очистке и перезагрузке данных в кэше второго уровня.
7. Intel утверждает, что при оптимизации программ под данную технологию выигрыш будет составлять до 30%. (Вернее, Intel утверждает, что на сегодняшних серверных приложениях и сегодняшних системах измеренный выигрыш до 30%) Гм…. Это более чем достаточный стимул для оптимизации.
Ну что же, некоторые особенности мы сформулировали. Теперь давайте попробуем обдумать некоторые следствия (по возможности опираясь на известные нам сведения). Что же можно сказать? Ну, во-первых, необходимо тщательнее разобраться, что же именно нам предлагают. Так ли «бесплатен» этот сыр? Для начала разберемся, как именно будет происходить «одновременная» обработка нескольких «нитей». Кстати, что подразумевает корпорация Intel под словом «нить»?
У автора сложилось впечатление (возможно, ошибочное), что в данном случае имеется ввиду программный фрагмент, который мультизадачная операционная система назначает на исполнение одному из процессоров мультипроцессорной аппаратной системы. «Постойте!» заявит внимательный читатель «это же одно из определений! Что тут нового?». А ничего в данном вопросе автор на оригинальность не претендует. Разобраться бы, что «наоригинальничала» Intel :-). Ну что же примем в качестве рабочей гипотезы.
Далее исполняется некоторая нить. Тем временем декодер команд (кстати, полностью асинхронный и не входящий в пресловутые 20 стадий Net Burst) осуществляет выборку и дешифрацию (со всеми взаимозависимостями) в микроинструкции. Здесь надо пояснить, что автор подразумевает под словом «асинхронный» дело в том, что результат «разваливания» х86 команд в микроинструкции происходит в блоке дешифрации. Каждая команда х86 может быть декодирована в одну, две, или более микроинструкций. При этом на стадии обработки выясняются взаимозависимости, доставляются необходимые данные по системной шине. Соответственно, скорость работы этого блока часто будет зависеть от скорости доступа данных из памяти и в худшем случае определяется именно ею. Было бы логично «отвязать» его от того конвейера, в котором, собственно, и происходит выполнение микроопераций. Это было сделано путем помещения блока дешифрации перед trace cache. Чего мы этим добиваемся? А добиваемся мы при помощи такой «перестановки блоков» местами простой вещи если в trace cache есть микроинструкции для исполнения процессор работает более эффективно. Естественно, этот блок работает на частоте процессора в отличие от Rapid Engine. Кстати, у автора сложилось впечатление, что данный декодер представляет собой нечто вроде конвейера длиной до 10–15 стадий. Таким образом, от выборки данных из кэша до получения результата проходит, по всей видимости, порядка 30 35 стадий (включая конвейер Net Burst, см. Microdesign Resources August2000 Microprocessor report Volume14 Archive8, page12).
Полученный набор микроинструкций вместе со всеми взаимозависимостями накапливается в trace cache в том самом, который приблизительно 12 000 микроопераций. По приблизительным оценкам источник такой оценки строение микроинструкции P6; дело в том, что принципиально длина инструкций вряд ли кардинально поменялась (считая длину микроинструкции вместе со служебными полями порядка 100 бит) размер trace cache получается от 96 КБ до 120 КБ. Однако! На фоне этого кэш данных размером 8 КБ выглядит как-то несимметрично :-)… и бледно. Конечно, при увеличении размера увеличиваются задержки доступа (к примеру, при увеличении до 32КБ задержки вместо двух тактов составят 4). Но неужели так важна скорость доступа в этот самый кэш данных, что увеличение задержки на 2 такта (на фоне общей длины всего конвейера) делает такое увеличение объема невыгодным? Или дело просто в нежелании увеличивать размер кристалла? Но тогда при переходе на 0.13 мкм первым делом стоило увеличить именно этот кэш (а не кэш второго уровня). Сомневающимся в данном тезисе стоило бы припомнить переход с Pentium на Pentium MMX благодаря увеличению кэша первого уровня вдвое практически все программы получали 10 15% прироста производительности. Что же говорить об увеличении вчетверо (особенно учитывая, что скорости процессоров выросли до 2ГГц, а коэффициент умножения с 2.5 до 20)? По неподтвержденным данным, в следующей модификации ядра Pentium4 (Prescott) кэш первого уровня таки увеличат до 16 или 32 КБ. Также увеличится кэш второго уровня. Впрочем, на сегодняшний момент все это не более чем слухи. Откровенно говоря, слегка непонятная ситуация. Хотя оговоримся автор вполне допускает, что подобной идее мешает некая конкретная причина. Как пример подойдут некие требования по геометрии расположения блоков или банальная нехватка свободного места вблизи конвейера (ясно ведь, что необходимо расположить кэш данных поближе к ALU).
Не отвлекаясь, смотрим на процесс дальше. Конвейер работает пусть нынешние команды задействуют ALU. Ясно, что FPU, SSE, SSE2 и прочие при этом простаивают. Не тут-то было вступает в действие Hyper Threading. Заметив, что готовы микроинструкции вместе с данными для новой нити, блок переименования регистров выделяет новой нити порцию физических регистров. Кстати, возможны два варианта блок физических регистров общий для всех нитей, или же отдельный для каждого. Судя по тому, что в презентации Hyper Threading от Intel в качестве блоков, которые надо изменять, блок переименования регистров не указан выбран первый вариант. Это хорошо или плохо? С точки зрения технологов явно хорошо, ибо экономит транзисторы. С точки зрения программистов пока неясно. Если количество физических регистров действительно 128, то при любом разумном количестве нитей ситуации «нехватка регистров» возникнуть не может. Затем они (микроинструкции) отправляются в планировщик, который, собственно, направляет их на исполнительное устройство (если оно не занято) или «в очередь», если данное исполнительное устройство сейчас недоступно. Таким образом, в идеале достигается более эффективное спользование имеющихся исполнительных устройств. В это время сам процессор с точки зрения ОС выглядит как два «логических» процессора. Гм… Неужели все так безоблачно? Давайте присмотримся к ситуации: часть оборудования (как-то кэши, Rapid Engine, модуль предсказания переходов) являются общими для обоих процессоров. Кстати, точность предсказания переходов от этого, скорее всего, слегка пострадает. Особенно, если исполняемые одновременно нити не связаны друг с другом. А часть (например, MIS [Microcode Instruction Sequencer] планировщик последовательности микрокоманд подобие ПЗУ, содержащее набор заранее запрограммированных последовательностей обычных операций и RAT [Register Alias Table] таблица переименования [псевдонимов] регистров) блоков должна отличать различные нити, запущенные на «разных» процессорах. Попутно (из общности кэша) следует, что, если две нити являются «жадными» к кэшу (то есть увеличение кэша дает большой эффект), то применение Hyper Threading способно даже снизить скорость. Это происходит потому, что на сегодняшний момент реализован «конкурентный» механизм борьбы за кэш «активная» в данный момент нить вытесняет «неактивную». Впрочем, механизм кэширования, по-видимому, может измениться. Также понятно, что скорость (по крайней мере, на текущий момент) будет снижаться в тех приложениях, в которых она снижалась и в честном SMP. Как пример SPEC ViewPerf обычно на однопроцессорных системах показывает более высокие результаты. А посему наверняка на системе с Hyper Threading результаты будут меньше, чем без нее. Собственно, результаты практического тестирования Hyper Threading можно посмотреть по этому адресу.
1. Ясно, что конвейер «шириной» 16 разрядов разгонять легче, чем шириной 32 разряда просто по причине наличия перекрестных помех и К о
2. По-видимому, Интел счел операции целочисленного вычисления достаточно часто встречающимися, чтобы ускорять именно ALU, а не, скажем, FPU. Вероятно, при вычислении результатов целочисленных операций используются либо таблицы, либо схемы «с накоплением переноса». Для сравнения, одна 32-битная таблица это 2E32 адресов, т.е. 4гигабайта. Две 16-разрядные таблицы это 2х64кб или 128 килобайт почувствуйте разницу! Да и накопление переносов в двух 16-разрядных порциях происходит быстрее, чем в одной 32-разрядной.
3. Экономит транзисторы и… тепло. Ведь ни для кого не секрет, что все эти архитектурные ухищрения греются. По видимому, это была достаточно большая (а, возможно, и главная) проблема чего стоит, к примеру, Thermal Monitor как технология! Ведь необходимости в подобной технологии как таковой не очень много то есть, конечно, приятно, что она есть. Но давайте говорить честно простой блокировки хватило бы для достаточной надежности. Раз такая сложная технология была предусмотрена значит, всерьез рассматривался вариант, когда подобные изменения частоты на ходу были одним из штатных режимов работы. А, может, основным? Ведь не зря ходили слухи, что Pentium 4 задумывался с гораздо большим количеством исполнительных устройств. Тогда проблема тепла должна была стать просто основной. Вернее, по тем же слухам, тепловыделение должно было составить до 150 Вт. А тогда очень логично принять меры к тому, чтобы процессор работал «в полную силу» только в таких системах, где обеспечено нормальное охлаждение. Тем более, что большинство корпусов «китайского» происхождения продуманностью конструкции с точки зрения охлаждения отнюдь не блещут. Гм…. Далековато забрались 🙂
Но все это теоретизирования. Есть ли сегодня процессоры, в которых применяется эта технология? Есть. Это Xeon (Prestonia) и XeonMP. Причем, интересно, что XeonМР от Xeon отличается поддержкой до 4 процессоров (чипсеты типа IBM Summit поддерживают до 16 процессоров, методика приблизительно такая же, как и в чипсете ProFusion) и наличием кэша третьего уровня объемом 512 КБ и 1 МБ, интегрированного в ядро. Кстати, а почему интегрировали кэш именно третьего уровня? Почему не увеличен кэш первого уровня? Должна же быть какая-то разумная причина…. Почему не увеличили кэш второго уровня? Возможно, причина в том, что Advanced Transfer Cache нуждается в относительно небольших задержках. А увеличение объема кэша приводит к увеличению задержек. Посему кэш третьего уровня для ядра и кэша второго уровня вообще «представляется» как шина. Просто шина :-). Так что прогресс налицо сделано все, чтобы данные подавались в ядро как можно быстрее (а, попутно, поменьше загружалась шина памяти).
Естественно, всегда можно обратиться к операционным системам других производителей. Да только будем откровенными это не очень хороший выход из текущей ситуации…. Так что можно понять колебания Интел, которая довольно долго думала использовать эту технологию, или нет.
Интересно, будет ли развиваться идея Hyper Threading? Дело в том, что в количественном отношении ей развиваться особо некуда понятно, что два физических процессора лучше трех логических. Да и позиционировать будет нелегко…. Интересно, что Hyper Threading может пригодиться и при интегрировании двух (или более) процессоров на кристалл. Ну а под качественными изменениями автор имеет ввиду, что наличие такой технологии в обычных десктопах приведет к тому, что фактически большинство пользователей будут работать на [почти] двухпроцессорных машинах что очень хорошо. Хорошо потому, что подобные машины работают не в пример «плавнее» и «отзывчивее» на действия пользователя даже под большой нагрузкой. Сие, с точки зрения автора, есть весьма хорошо.
Вместо послесловия
Автор должен признаться, что в течение работы над статьей его отношение к Hyper Threading неоднократно менялось. По мере того, как собиралась и обрабатывалась информация отношение становилось то в целом положительным, то наоборот :-). На сегодняшний момент можно написать следующее:
есть только два способа повышать производительность повышать частоту, и повышать производительность за такт. И, если вся архитектура Pentium4 рассчитана на первый путь, то Hyper Threading как раз второй. Уже с этой точки зрения ее можно только приветствовать. Так же Hyper Threading несет несколько интересных следствий, как-то: изменение парадигмы программирования, привнесение многопроцессорности в массы, увеличение производительности процессоров. Однако, на этом пути есть несколько «больших кочек», на которых важно не «застрять»: отсутствие нормальной поддержки со стороны операционных систем и, самое главное, необходимость перекомпиляции (а в некоторых случаях и смены алгоритма) приложений, чтобы они в полной мере смогли воспользоваться преимуществами Hyper Threading. К тому же, наличие Hyper Threading сделало бы возможной действительно параллельную работу операционной системы и приложений а не «кусками» по очереди, как сейчас. Конечно, при условии, что хватит свободных исполнительных устройств.



