При подключении 2-го HDD перестает загружаться CentOS
Установил CentOS 7 на 1 HDD, настроил, решил подключить 2-ой HDD, но после подключения система перестает загружаться. В Bios выбран в качестве загрузочного 1-ый HDD
Со вторым винтом загрузка выглядит так:
После ожидания несколько минут далее появляется:
После отключения 2-го HDD система грузится в штатном режиме. Подскажите, где искать причину, чтобы можно было подключить 2-ой HDD? На 2-ой HDD я пытался установить CentOS с разделами LVM, возможно связано с этим? 1 HDD также в LVM

Возможно у вас одинаковые имена у LVM. Загрузитесь с флешки или ещё чего с подключенным вторым винтом и почистите его.
Раньше в редхатах ещё была проблема с одинаковыми метками корневых файловых систем, но, вроде, сейчас это не критично.

grub.cfg надо посмотреть


Сейчас и в fstab и в grub диски прописываются по UID
Так было в линуксах лет 15-20 назад. Потом повсеместно пришёл initramfs и disk-by-uuid.
Сейчас диски по имени устройства прописываются только в самых маргинально-замшелых дистрибутивах. И то вряд ли. Почитай уже про uuid и прекрати писать про дистрибутивы, об устройстве которых не имеешь ни малейшего понятия.
Так было в линуксах лет 15-20 назад

Для более быстрого нахождения решения проблемы следовало бы набросить про systemd и скастовать его фанатов.
ипользовать готовые решения, самому не о чем не задумываться
Я использую готовые решения, потому что они хорошо работают. И я знаю, как они работают. А ты вводишь людей в заблуждение, оправдывая это собственной некомпетентностью.
правлю grub и fstab по старинке без всяких uuid
за то 100 пудов все работает и не выносит мозг
А потом рассказываешь на форумах о том, как у тебя ломается загрузка от вставленной флешки.
продиктуй мне умник свой uuid, что не помнишь

я правлю grub и fstab по старинке без всяких uuid
Дело твое, конечно, но зачем?
100 пудов все работает и не выносит мозг
Слова человека, чуть выше сказавшего ровно обратное.
продиктуй мне умник свой uuid
мне проще запомнить 3 буквы и одну цифру.
Для чего запоминать то, что в любой момент можно спросить у findmnt(1), blkid(1) и lsblk(1)?
7 распространенных ошибок, которые нужно проверить при отладке DAG-файлов Airflow
Задачи не выполняются? DAG не работает? Журналы не находятся? У нас были те же самые проблемы. Вот список распространенных ошибок и некоторые соответствующие исправления, которые следует учитывать при отладке развертывания Airflow.
Apache Airflow стал ведущим планировщиком задач с открытым исходным кодом практически для любого вида работы, от обучения модели машинного обучения до общей оркестровки ETL. Это невероятно гибкий инструмент, который, как мы можем сказать по опыту, поддерживает критически важные проекты как для стартапов из пяти человек, так и для команд из списка Fortune 50.
С учетом сказанного, тот самый инструмент, который многие считают мощным «чистым холстом», может быстро стать обоюдоострым мечом, если вы только начинаете. И, к сожалению, нет особенно огромного богатства ресурсов и лучших практик на шаг или два выше базовых основ Apache Airflow.
Стремясь максимально заполнить этот пробел, мы собрали некоторые из наиболее распространенных проблем, с которыми сталкивается почти каждый пользователь, независимо от того, насколько опытна и многочисленна его команда. Независимо от того, являетесь ли вы новичком в Airflow или опытным пользователем, ознакомьтесь с этим списком распространенных ошибок и некоторыми соответствующими исправлениями, которые следует учитывать.
1. Ваш DAG не работает в необходимое время
Вы написали новый DAG, который должен запускаться каждый час. Вы устанавливаете почасовой интервал, начинающийся сегодня в 14:00, и устанавливаете напоминание, чтобы проверить его через пару часов. Вы проверяете его в 15:30 и обнаруживаете, что хотя ваш DAG действительно работал, в ваших журналах указано, что существует только одна записанная дата выполнения на 14:00. А что происходило в 3 часа дня?
Прежде чем вы перейдете в режим debug (вы не будете первым), будьте уверены, что это вполне ожидаемое поведение. Функциональность планировщика Airflow немного противоречит здравому смыслу (и вызывает некоторые разногласия в сообществе Airflow), но вы освоитесь. Две вещи:
2. Одна из ваших DAG не работает
Если рабочие процессы в вашем развертывании обычно выполняются без сбоев, но вы обнаруживаете, что один конкретный DAG не планирует задачи и не запускается вообще, это может иметь какое-то отношение к тому, как вы настроили ее для расписания.
Для выполнения DAG start_date должен быть временем в прошлом, иначе Airflow будет считать, что он еще не готов к выполнению. Когда Airflow оценивает ваш DAG, он интерпретирует datetime.now() как текущую метку времени (т.е. НЕ время в прошлом) и решает, что он не готов к запуску. Поскольку это будет происходить каждый раз, когда пульс Airflow будет оценивать ваш DAG каждые 5-10 секунд, он никогда не запустится.
Чтобы правильно запустить DAG, обязательно ставьте фиксированное время в прошлом (например, datetime(2019,1,1) ) и установите catchup=False (если вы не хотите запускать обратную засыпку).
3. Вы видите ошибку 503 при развертывании
Если вы переходите к развертыванию Airflow только для того, чтобы понять, что ваш экземпляр полностью недоступен через веб-браузер, скорее всего, это как-то связано с вашим веб-сервером.
Если вы уже обновили страницу один или два раза и продолжаете видеть ошибку 503, прочтите ниже некоторые рекомендации, связанные с веб-сервером.
Ваш веб-сервер может дать сбой
Ошибка 503 обычно указывает на проблему веб-сервера (или проблему deployment в kubernetes), основным компонентом Airflow, отвечающим за отображение состояния задачи и журналов выполнения задач в интерфейсе Airflow. Если по какой-либо причине у него недостаточно мощности или иным образом возникла проблема, это может повлиять на время загрузки пользовательского интерфейса или доступность веб-браузера.
По нашему опыту, ошибка 503 часто указывает на то, что ваш веб-сервер дает сбой (например, в Astronomer в kubernetes это называется состоянием CrashLoopBackOff ). Если вы запускаете deployment в kubernetes, и вашему веб-серверу по какой-либо причине требуется больше нескольких секунд для запуска, он может не достичь периода ожидания (10 секунд по умолчанию), в котором он вылетит, прежде чем он успеет развернуться. Это вызывает повторную попытку, которая снова дает сбой и так далее.
Если ваше deployment находится в этом состоянии, возможно, ваш веб-сервер достигает предела памяти при загрузке ваших DAG (даже если ваши рабочие и планировщик продолжают выполнять задачи, как ожидалось).
Несколько замечаний
Вы пытались увеличить ресурсы своего веб-сервера?
Airflow 1.10 немного жаднее, чем Airflow 1.9, в отношении ЦП (использования памяти), поэтому мы видели недавний всплеск количества пользователей, сообщающих о 503-х ошибках. Помогает быстрое увеличение ресурсов, выделенных вашему веб-серверу.
Если вы используете Astronomer, мы рекомендуем поддерживать размер веб-сервера на отметке минимум 5 AU (Astronomer Units).
Вы делаете запросы вне оператора?
Если вы выполняете вызовы API, запросы JSON или запросы к базе данных за пределами оператора с высокой частотой, вероятность тайм-аута вашего веб-сервера гораздо выше.
Когда Airflow интерпретирует файл для поиска любых допустимых DAG, он сначала немедленно запускает весь код на верхнем уровне (то есть вне операторов). Даже если сам оператор выполняется только во время выполнения, все, что вызывается вне оператора, вызывается при каждом такте, что может быть довольно утомительным.
Мы бы порекомендовали взять логику, которую вы в настоящее время выполняете вне оператора, и по возможности переместить ее внутрь оператора Python.
4. Задачи тасков периодически не работают
Это подводит нас к общей передовой практике, которую мы начали применять.
Будьте осторожны при использовании Sensors
Если вы используете Airflow 1.10.1 или более раннюю версию, датчики работают непрерывно и постоянно занимают слот для задач, пока не найдут то, что ищут, поэтому они имеют тенденцию вызывать проблемы с параллелизмом. Если у вас действительно никогда не бывает более нескольких задач, выполняемых одновременно, мы рекомендуем избегать их, если вы не знаете, что они не займут слишком много времени для выхода.
Например, если работник может одновременно запускать только X задач, а у вас работает три датчика (sensors?), то вы сможете запускать только X-3 задачи в любой заданный момент. Имейте в виду, что если вы постоянно используете датчик (sensors?), это ограничивает то, как и когда может произойти перезапуск планировщика (иначе датчик (sensors?) выйдет из строя).
В зависимости от вашего варианта использования мы предлагаем рассмотреть следующее:
Создайте DAG, который запускается с более частым интервалом.
Возможно, что задан тычок — и пропускает последующие задачи, если файл не найден.
2. Триггер лямбда-функции
5. Задачи выполняются, но становятся бутылочным горлышком
Если все выглядит так, как ожидалось, но вы обнаруживаете, что ваши задачи становятся бутылочным горлышком, мы рекомендуем внимательнее присмотреться к двум вещам: Ваши переменные Env и конфигурации, связанные с параллелизмом + ваши ресурсы Worker и Scheduler.
1. Проверьте свои переменные Env и связанные с параллелизмом (Concurrency) конфигурации
Какие именно эти значения должны быть установлены (и что может стать потенциальным узким местом), зависит от вашей настройки — например, вы запускаете несколько DAG одновременно или один DAG с сотнями одновременных задач? С учетом сказанного, их точная настройка, безусловно, может помочь решить проблемы с производительностью. Вот список того, что вы можете найти:
1. Параллелизм (параллелизм)
Это определяет, сколько экземпляров задач может активно выполняться параллельно (parallel) в нескольких DAG с учетом ресурсов, доступных в любой момент времени на уровне развертывания. Думайте об этом как о «максимально активных задачах в любом месте».
2. Concurrency DAG (dag_concurrency)
Это определяет, сколько экземпляров задач ваш планировщик может запланировать одновременно для каждой DAG. Думайте об этом как о «максимальном количестве задач, которые можно запланировать за один раз для каждой DAG».
3. Количество слотов задач без пула (Nonpooledtaskslotcount)
Когда пулы не используются, задачи запускаются в «пуле по умолчанию», размер которого определяется этим элементом конфигурации.
4. Максимальное количество активных запусков на DAG (maxactiverunsperdag)
Это говорит само за себя, но он определяет максимальное количество активных запусков DAG на DAG.
5. Concurrency воркеров (worker_concurrency)
Это определяет, сколько задач каждый воркер может запускать в любой момент времени. Например, CeleryExecutor по умолчанию будет одновременно выполнять не более 16 задач. Думайте об этом как о «Сколько задач каждый из моих воркеров может взять на себя в любой момент времени».
6. Параллелизм (параллелизм)
Совет от профессионала: если вы рассматриваете возможность установить низкое число конфигураций параллелизма на уровне DAG или развертывания для защиты от ограничений скорости API, мы рекомендуем вместо этого использовать «пулы» — они позволят вам ограничить параллелизм на уровне задачи и выиграть t, ограничивать планирование или выполнение за пределами задач, которые в этом нуждаются.
2. Попробуйте увеличить масштаб планировщика или добавить воркера
Если задачи становятся узкими местами и все ваши конфигурации concurrency выглядят нормально, возможно, ваш Планировщик недостаточно мощный или ваше развертывание (deployment) может использовать другого воркера. Если вы используете Astronomer, мы обычно рекомендуем 5 AU в качестве минимума по умолчанию для Scheduler и 10 AU для ваших рабочих Celery, если они у вас есть.
Увеличите ли вы свои текущие ресурсы или добавите дополнительного работника, во многом зависит от вашего варианта использования, но мы обычно рекомендуем следующее:
Для получения дополнительной информации о различиях между Executors ознакомьтесь с нашим Airflow Executors: Explained Guide.
6. У вас отсутствуют журналы
Вообще говоря, журналы не отображаются из-за процесса, который умер на одном из ваших рабочих процессов.
Вы можете увидеть что-то вроде следующего:
Несколько действий, которые стоит попробовать:
Повторите (удалите) задачу, если это возможно, чтобы увидеть, появляются ли журналы.
Это очистит / сбросит задачи и предложит снова их запустить
Измените log_fetch_timeout_sec на значение более 5 секунд (по умолчанию).
Это количество времени (в секундах), в течение которого веб-сервер будет ожидать начального рукопожатия (handshake) при получении журналов от других воркеров.
Дайте вашим воркерам немного больше прав
Если вы используете Astronomer, вы можете сделать это на вкладке Configure пользовательского интерфейса Astronomer.
Вы ищете журнал, сделанный более 15 дней назад?
Если вы используете Astronomer, период хранения журнала — это переменная среды, которую мы жестко запрограммировали на нашей платформе. На данный момент у вас не будет доступа к журналам, которым более 15 дней.
Вы можете выполнить команду в одном из своих воркеров Celery, чтобы найти там файлы журнала.
Эта функция предназначена только для корпоративных клиентов или людей, использующих Kubernetes.
Файлы журнала должны быть в
Задачи медленно планируются или вообще перестали планироваться.
Если ваши задачи выполняются медленнее, чем обычно, вы захотите проверить, как часто вы устанавливаете свой планировщик для перезапуска. К сожалению, у Airflow есть хорошо известная проблема, из-за которой производительность планировщика со временем ухудшается и требуется быстрый перезапуск для обеспечения оптимальной производительности.
Если вы используете Astronomer, вы можете перезапустить планировщик следующим образом:
Этот список основан на нашем опыте оказания помощи клиентам Astronomer в решении основных проблем с Airflow, но мы хотим услышать ваше мнение. Не стесняйтесь обращаться к нам по адресу people@astronomer.io, если мы пропустили что-то, что, по вашему мнению, было бы полезно включить.
Если у вас есть дополнительные вопросы или вы ищете поддержку Airflow от нашей команды, свяжитесь с нами здесь.
Copyaudiohaldumpservice is running что это
Что значит сообщение System is running low on RAM?
System is running low on RAM значит, что оперативная память заполнилась (не путать с жестким диском). Варианта тут два: либо ее мало установлено в ваш компьютер, либо сцена слишком сложная.
Сначала разберемся с тем, что потребляет память в сцене больше всего:
Для прочих объектов, если прокси применять неудобно, лучше использовать инстансы. Все одинаковые объекты, естественно, тоже делаем инстансами. Инстансы и прокси потребляют память почти как один объект. Еще можно посоветовать во время рендера закрыть браузер, фотошоп и прочие ненужные программы.
Сколько оперативной памяти нужно для работы?
Для изучения 3dsmax хватит почти любого объема, так что в этом случае сразу бежать в магазин не стоит 🙂 У меня в начале не было и половины гигабайта 🙂
А вот для серьезной регулярной работы сейчас хороший комфортный объем — это 32 или более гигабайт. Конечно, вначале можно работать и с 24, и даже 16 гигабайтами, но уже не так комфортно, и мысли об апгрейде придут, рано или поздно. Если памяти 8 гигабайт или меньше Corona, будет писать про RAM довольно часто, но можно это игнорировать. Но рендер будет дольше, иногда будут вылеты.
Как правильно увеличить объем оперативной памяти?
PS. Для моделирования памяти нужно гораздо меньше, чем во время рендера. Поэтому для работы, в которой не нужен рендеринг (для разработкм игр, например), памяти может понадобиться значительно меньше.
Как устранить неполадки репликации AD с помощью Repadmin
Что такое Repadmin?
Repadmin — это cmd-приложение для диагностики проблем с репликацией AD. С помощью Repadmin можно легко просмотреть топологию репликации для каждого контроллера домена и использовать эти знания, чтобы вручную изменить ее и инициировать репликацию между контроллерами. С помощью Repadmin можно легко проверить метаданные репликации и векторы релевантности (up-to-dateness (UTDVEC)).
Repadmin.exe является встроенной функцией в среде Windows Server, начиная с версии 2008. Она поставляется с ролью AD Directory Services, а также может быть настроена в клиентских ОС, таких как Windows 10 с RSAT.
Список команд


Repadmin.exe имеет множество команд, давайте остановимся на самых популярных:
Как просмотреть общее состояние репликации
Для того чтобы смотреть состояние репликации у вас она должна быть настроена, как минимум, между двумя доменными контроллерами. Начнем с общего состояния репликации, запустите cmd.exe (start->run->cmd.exe) и введите следующую команду:
В результате вы увидите все сбои репликации, которые существуют в вашей среде AD.
Как принудительно выполнить репликацию
Предположим, у вас есть сбои в репликации, и вам нужно принудительно выполнить репликацию после устранения сбоя в сети. В командной строке (cmd.exe) с админскими правами на любом DC запустите:
repadmin.exe /syncall /Aped
В дополнение к команде /syncall у нас есть несколько флагов, которые позволят синхронизировать все разделы (/A), использовать push-уведомления для того, чтобы админ мог прервать выполнение команды на каждом этапе (/p), через все сайты Active Directory (/e) используя имена хостов (/d).
Как управлять входящей и исходящей репликацией
Вы можете отключить входящую и/или исходящую репликацию с возможностью повторного включения позже. Для этого выполните следующие команды в командной строке, запущенной под администратором (cmd.exe):
repadmin.exe /options DC01 +DISABLE_INBOUND_REPL
Отключает входящую репликацию на контроллере домена DC01
repadmin.exe /options DC01 +DISABLE_OUTBOUND_REPL
Отключает исходящую репликацию на контроллере домена DC01
Включает входящую репликацию на контроллере домена DC01
Включает исходящую репликацию на контроллере домена DC01.
Например, опция отключения исходящей репликации — это хороший способ выполнить обновление схемы без необходимости перестраивать весь лес Active Directory.
A start job is running for File System Check
Столкнулся на днях с очень неприятной ситуацией, сопровождающейся тем, что сервер долго не мог запуститься. Причиной этому была плановая проверка диска на ошибки. Сам диск был на 3 Тб, поэтому проверка сильно затянулась. В итоге, банальная установка обновлений и reboot чуть превратились в серьезную проблему.
Force fsck on reboot
Удивительно, но на за все время своей работы системным администратором Linux, с подобной проблемой я столкнулся впервые. Как говорится, ничто не предвещало беды. Выбрал наиболее подходящее время для обновления системы и сделал его. После этого решил перезагрузить сервер. Операция была запланированная и до этого я уже обновил с десяток серверов. Но с этим последним что-то пошло не так. Долго не возвращается в мониторинг. Решил сходить на гипервизор и посмотреть, что с ним. А там такая картинка.
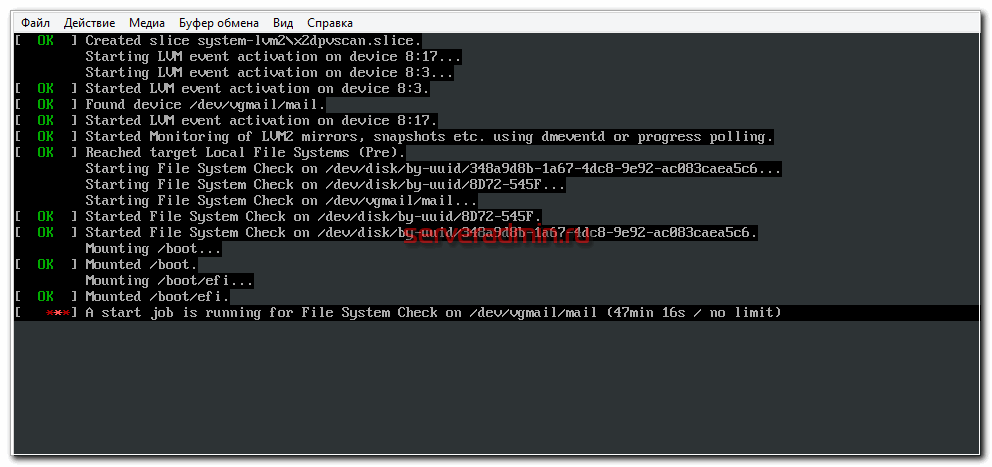
A start job is running for File System Check on /dev/vgmail/mail
Идет проверка раздела на ошибки. При чем этот lvm раздел размером в 3Tb, на нем хранится почтовый архив. Нет никакой индикации и не понятно, с чем вообще все это связано и сколько времени продлится. Сервер в работе, подключается куча людей. Я вижу, что операция вроде как плановая, так как никаких ошибок нет. Но то, что сервер не работает, уже ошибка. Самое главное, не понятно, сколько эта проверка может длиться. И еще всегда остается шанс, что это внештатная ситуация и с разделом какие-то проблемы. Это самый плохой расклад.
Я терпеливо подождал где-то час и не выдержал. В первую очередь хотел понять, происходил ли вообще что-то с диском. Пошел на гипервизор и проверил. Реально идет активное чтение с диска. Записи нет. Из этого сделал вывод, что можно безопасно сбросить виртуалку. К слову, весь тот час, что я ждал, прогуглил весь буржунет, чтобы понять, как принудительно прервать эту проверку. Перепробовал все, что только можно. Не помогло ничего. Прервать или отложить проверку не смог.
Параллельно сходил и проверил бэкап. Он был, свежий, все в порядке. Но сколько времени займет восстановление, если забирать эти данные по сети? Я так прикинул, никак не меньше суток, скорее ближе к двум. Надо было бы ехать и забирать локально. Сначала в один цод, потом во второй. Везде надо договариваться о приезде, оформлять пропуск и т.д. Сидеть ждать, пока локально скопируется файлы. Как-то еще внешний диск надо подключить и найти подходящего объема. В общем, та еще проблема. Одно наличие актуального бэкапа вообще не решает проблему восстановления данных.
В итоге сбросил виртуалку и при загрузке выбрал режим Rescue.
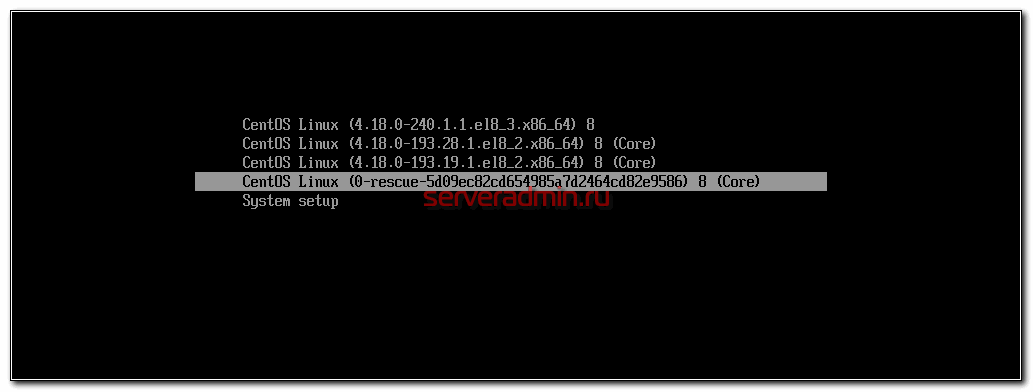
Я рассчитывал, что в этом режиме проверка диска не будет запускаться. По факту ошибся, проверка тоже запустилась, но в этот раз периодически в строке проскакивала индикация выполнения и было видно, что она продолжается. Так же, по изменению статуса, я прикинул, что проверка будет длиться около двух часов. Я посчитал, что для меня это время приемлемо в данной ситуации и решил больше не дергать виртуалку, чтобы не сделать хуже. Дождался окончания процесса.
В итоге, все завершилось и операционная система штатно загрузилась. В логах увидел подробности:
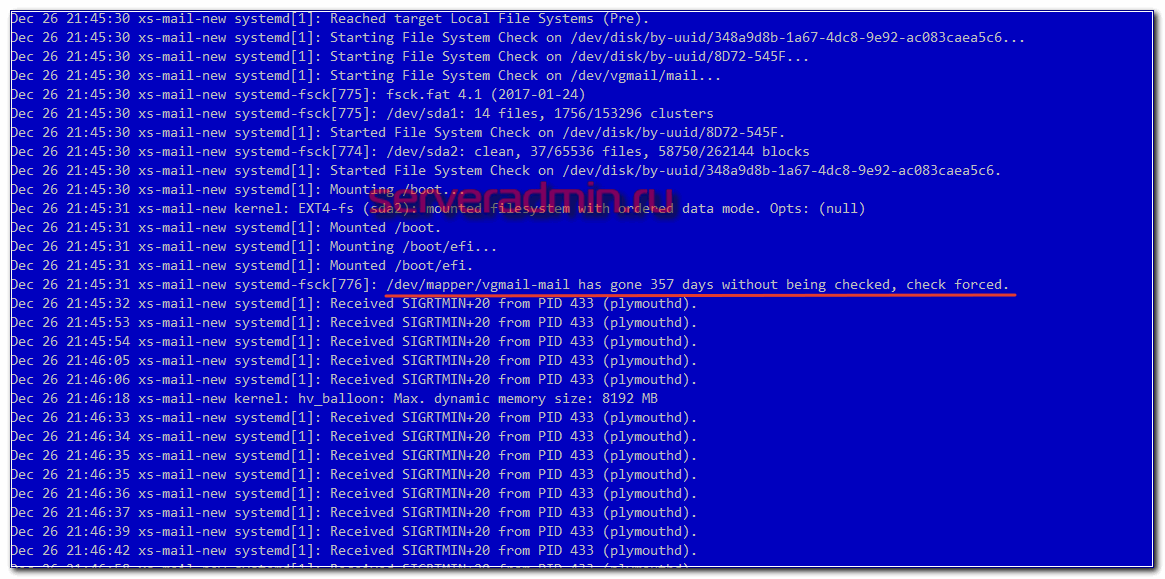
systemd-fsck: /dev/mapper/vgmail-mail has gone 357 days without beign checked, check forced.
Система в системе в виде systemd решила, что диск давно не проверяли на ошибки, поэтому принудительно инициировала этот процесс, который длился в итоге 1,5 часа. Первый раз немного не дождался окончания.
Как отключить fsck при загрузки системы
По идее, чтобы подобные проверки не запускались автоматически, достаточно в fstab, в последнем столбце написать 0. Напомню, что это за параметр. Формат файла fstab следующий:
Последняя строка как раз для fsck, может принимать следующие значения:
У меня стояла цифра 2. Я не знаю, чем руководствовался, когда настраивал fstab. Скорее всего на автомате указал или скопировал. Не подумал о последствиях. Есть только один момент, который меня беспокоит. Не факт, что systemd руководствуется этим параметром, а не каким-то своим. Она давно уже живет своей жизнью и требует отдельных настроек и внимания к себе. Нужно будет разобраться с этим моментом повнимательнее.
Заключение
Ранее неоднократно сталкивался с принудительной проверкой массива mdadm на ошибки. Это очень сильно нагружает диски и катастрофически снижает производительность системы. Всегда слежу за этим и отключаю проверку. Какая-то бестолковая затея инициировать подобные проверки автоматически, без согласования с администратором, либо ручным выбором условий запуска. Причем в разных дистрибутивах это может быть реализовано по-разному. Проверки надо делать при подозрении на ошибки, а не просто так, чтобы было.
На практике не проверял. Узнал об это уже по факту разбора данной ситуации.



