В подтверждающем факторном анализе исследователь сначала вырабатывает гипотезу о том, какие факторы, по его мнению, лежат в основе используемых показателей (например, « Депрессия » является фактором, лежащим в основе инвентаризации депрессии Бека и шкалы оценки депрессии Гамильтона ), и могут налагать ограничения на модель. исходя из этих априорных гипотез. Налагая эти ограничения, исследователь заставляет модель соответствовать своей теории. Например, если предполагается, что существует два фактора, влияющих на ковариацию в измерениях, и что эти факторы не связаны друг с другом, исследователь может создать модель, в которой корреляция между фактором A и фактором B ограничена нулем. Затем можно получить показатели соответствия модели, чтобы оценить, насколько хорошо предложенная модель отражает ковариацию между всеми элементами или показателями модели. Если ограничения, наложенные исследователем на модель, несовместимы с данными выборки, то результаты статистических тестов соответствия модели будут указывать на плохое соответствие, и модель будет отклонена. Если посадка плохая, это может быть связано с тем, что некоторые предметы измеряют несколько факторов. Также может быть, что некоторые элементы внутри фактора больше связаны друг с другом, чем другие.
Для некоторых приложений требование «нулевых нагрузок» (для индикаторов, которые не должны нагружать определенный фактор) было сочтено слишком строгим. Недавно разработанный метод анализа, «исследовательское моделирование структурным уравнением», определяет гипотезы о связи между наблюдаемыми показателями и их предполагаемыми первичными скрытыми факторами, а также позволяет оценить нагрузки с другими скрытыми факторами.
СОДЕРЖАНИЕ
Статистическая модель
Альтернативные стратегии оценки
Хотя для оценки моделей CFA использовались многочисленные алгоритмы, метод максимального правдоподобия (ML) остается основной процедурой оценки. При этом модели CFA часто применяются к условиям данных, которые отклоняются от нормальных теоретических требований для достоверной оценки ML. Например, социологи часто оценивают модели CFA с ненормальными данными и показателями, масштабируемыми с использованием дискретных упорядоченных категорий. Соответственно, были разработаны альтернативные алгоритмы, учитывающие различные условия данных, с которыми сталкиваются прикладные исследователи. Альтернативные оценки были охарактеризованы в два основных типа: (1) робастные и (2) ограниченные информации оценки.
Когда ML реализуется с данными, которые отклоняются от предположений нормальной теории, модели CFA могут давать смещенные оценки параметров и вводящие в заблуждение выводы. Робастная оценка обычно пытается исправить проблему путем корректировки нормальной теоретической модели χ 2 и стандартных ошибок. Например, Саторра и Бентлер (1994) рекомендовали использовать оценку машинного обучения обычным способом с последующим делением модели χ 2 на меру степени многомерного эксцесса. Дополнительным преимуществом надежных оценщиков машинного обучения является их доступность в общем программном обеспечении SEM (например, LAVAAN).
Исследовательский факторный анализ
И исследовательский факторный анализ (EFA), и подтверждающий факторный анализ (CFA) используются для понимания общей дисперсии измеряемых переменных, которая, как полагают, связана с фактором или латентной конструкцией. Однако, несмотря на это сходство, EFA и CFA представляют собой концептуально и статистически разные анализы.
EFA часто считается более подходящим, чем CFA, на ранних этапах разработки шкалы, потому что CFA не показывает, насколько хорошо ваши элементы влияют на негипотетические факторы. Еще один веский аргумент в пользу первоначального использования ОДВ заключается в том, что неверное указание количества факторов на ранней стадии разработки шкалы, как правило, не будет обнаружено подтверждающим факторным анализом. На более поздних стадиях разработки шкалы подтверждающие методы могут предоставить больше информации за счет явного противопоставления конкурирующих структур факторов.
ОДВ иногда указывается в исследованиях, когда CFA может быть лучшим статистическим подходом. Утверждалось, что CFA может быть ограничительным и неуместным при использовании в исследовательских целях. Однако идея о том, что CFA является исключительно «подтверждающим» анализом, иногда может вводить в заблуждение, поскольку индексы модификации, используемые в CFA, носят в некоторой степени исследовательский характер. Индексы модификации показывают улучшение соответствия модели, если конкретный коэффициент не ограничивается. Точно так же EFA и CFA не обязательно должны быть взаимоисключающими анализами; Утверждалось, что EFA является разумным продолжением плохо подходящей модели CFA.
Структурное моделирование уравнение
Оценка соответствия модели
Индексы абсолютной пригодности
Индексы абсолютного соответствия определяют, насколько хорошо априорная модель соответствует или воспроизводит данные. Индексы абсолютного соответствия включают, помимо прочего, критерий хи-квадрат, RMSEA, GFI, AGFI, RMR и SRMR.
Критерий хи-квадрат
Среднеквадратичная ошибка аппроксимации
Среднеквадратичная ошибка аппроксимации (RMSEA) позволяет избежать проблем, связанных с размером выборки, путем анализа несоответствия между гипотетической моделью с оптимально выбранными оценками параметров и ковариационной матрицей совокупности. RMSEA находится в диапазоне от 0 до 1, причем меньшие значения указывают на лучшее соответствие модели. Значение 0,06 или меньше указывает на приемлемую подгонку модели.
Среднеквадратичный остаток и стандартизованный среднеквадратичный остаток
Индекс согласия и скорректированный индекс согласия
Индексы относительной подгонки
Индексы относительного соответствия (также называемые «индексами возрастающего соответствия» и «индексами сравнительного соответствия») сравнивают хи-квадрат для гипотетической модели с одним из «нулевой» или «базовой» модели. Эта нулевая модель почти всегда содержит модель, в которой все переменные не коррелированы, и, как следствие, имеет очень большой хи-квадрат (что указывает на плохое соответствие). Индексы относительного соответствия включают нормированный индекс соответствия и сравнительный индекс соответствия.
Нормированный индекс соответствия и ненормированный индекс соответствия
Нормированный индекс соответствия (NFI) анализирует несоответствие между значением хи-квадрат гипотетической модели и значением хи-квадрат нулевой модели. Тем не менее, NFI имеет тенденцию к отрицательной предвзятости. Ненормированный индекс соответствия (NNFI; также известный как индекс Такера – Льюиса, поскольку он был построен на индексе, сформированном Такером и Льюисом в 1973 году) решает некоторые проблемы отрицательного смещения, хотя значения NNFI могут иногда выходить за рамки диапазон от 0 до 1. Значения как для NFI, так и для NNFI должны находиться в диапазоне от 0 до 1, с порогом 0,95 или больше, указывающим на хорошее соответствие модели.
Сравнительный индекс соответствия
Индекс сравнительного соответствия (CFI) анализирует соответствие модели, исследуя несоответствие между данными и гипотетической моделью, при этом корректируя проблемы размера выборки, присущие критерию соответствия модели хи-квадрат и нормированному индексу соответствия. Значения CFI варьируются от 0 до 1, причем большие значения указывают на лучшее соответствие. Раньше считалось, что значение CFI 0,90 или больше указывает на приемлемое соответствие модели. Однако недавние исследования показали, что необходимо значение больше 0,90, чтобы гарантировать, что неправильно указанные модели не будут считаться приемлемыми. Таким образом, значение CFI 0,95 или выше в настоящее время считается показателем хорошего соответствия.
Идентификация и недооценка
Чтобы оценить параметры модели, модель должна быть правильно идентифицирована. То есть количество оцененных (неизвестных) параметров ( q ) должно быть меньше или равно количеству уникальных дисперсий и ковариаций среди измеряемых переменных; р ( р + 1) / 2. Это уравнение известно как «правило t». Если имеется слишком мало информации, на которой можно основывать оценки параметров, модель считается недооцененной, и параметры модели не могут быть оценены надлежащим образом.
Confirmatory Factor Analysis (CFA) in R with lavaan
Purpose
The third seminar goes over intermediate topics in CFA including latent growth modeling and measurement invariance.
Outline
Proceed through the seminar in order or click on the hyperlinks below to go to a particular section:
Back to Launch Page
Requirements
Before beginning the seminar, please make sure you have R and RStudio installed.
Please also make sure to have the following R packages installed, and if not, run these commands in R (RStudio).
Once you’ve installed the packages, you can load them via the following
Download files here
You may download the complete R code here: cfa.r
After clicking on the link, you can copy and paste the entire code into R or RStudio.
PowerPoint slides for the seminar given on 05/17/2021 are here: PowerPoint Slides for Intro to CFA
The corresponding code for the exercises are included here: R Code for Intro to CFA (Supplementary Exercises)
Introduction
Motivating example: SPSS Anxiety Questionnaire (SAQ-8)
Suppose you are tasked with evaluating a hypothetical but real world example of a questionnaire which Andy Field terms the SPSS Anxiety Questionnaire (SAQ). The first eight items consist of the following (note the actual items have been modified slightly from the original data set):
Now that we have imported the data set, the first step besides looking at the data itself is to look a the correlation table of all 8 variables. The function cor specifies a the correlation and round with the option 2 specifies that we want to round the numbers to the second digit.
In psychology and the social sciences, the magnitude of a correlation above 0.30 is considered a medium effect size. Due to relatively high correlations among many of the items, this would be a good candidate for factor analysis. The goal of factor analysis is to model the interrelationships between many items with fewer unobserved or latent variables. Before we move on, let’s understand the confirmatory factor analysis model.
The factor analysis model
The factor analysis or measurement model is essentially a linear regression model where the main predictor, the factor, is latent or unobserved. For a single subject, the simple linear regression equation is defined as:
$$y = b_0 + b_1 x + \epsilon$$
where \(b_0\) is the intercept and \(b_1\) is the coefficient and \(x\) is an observed predictor. Similarly, for a single item, the factor analysis model is:
$$y_ <1>= \tau_1 + \lambda_1 \eta + \epsilon_ <1>$$
We can represent this multivariate model (i.e., multiple outcomes, items, or indicators) as a matrix equation:
$$ \begin
Let’s define each of the terms in the model
The model-implied covariance matrix
The following describes each parameter, defined as a term in the model to be estimated:
In the three item one-factor case,
$$ \Sigma(\theta) = \begin
The path diagram
Equations can be intimidating. The path diagram can assist us in understanding our CFA model because it is a symbolic one-to-one visualization of the measurement model and the model-implied covariance. Before we present the actual path diagram, the table below defines the symbols we will be using. Circles represent latent variables, squares represent observed indicators, triangles represent intercept or means, one-way arrows represent paths and two-way arrows represent either variances or covariances.
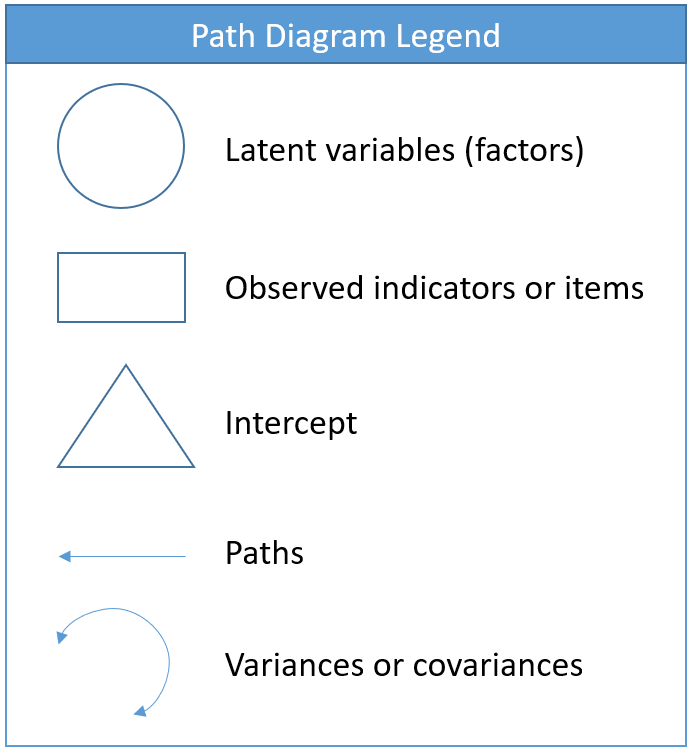
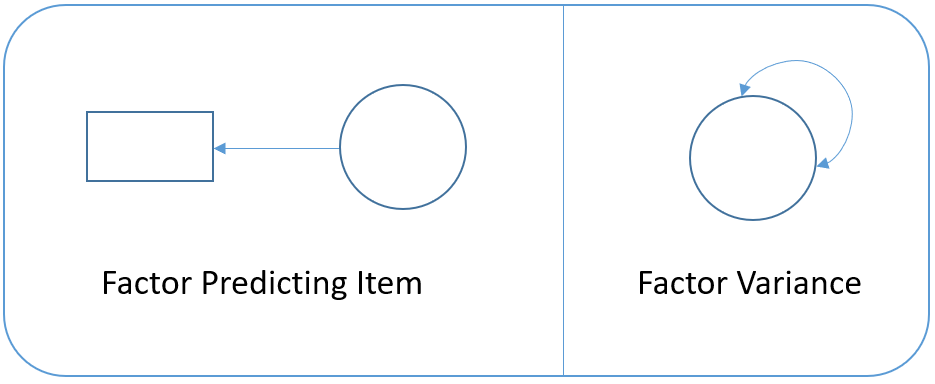
For example in the figure below, the diagram on the left depicts the regression of a factor on an item (essentially a measurement model) and the diagram on the right depicts the variance of the factor (a two-way arrow pointing to an latent variable).
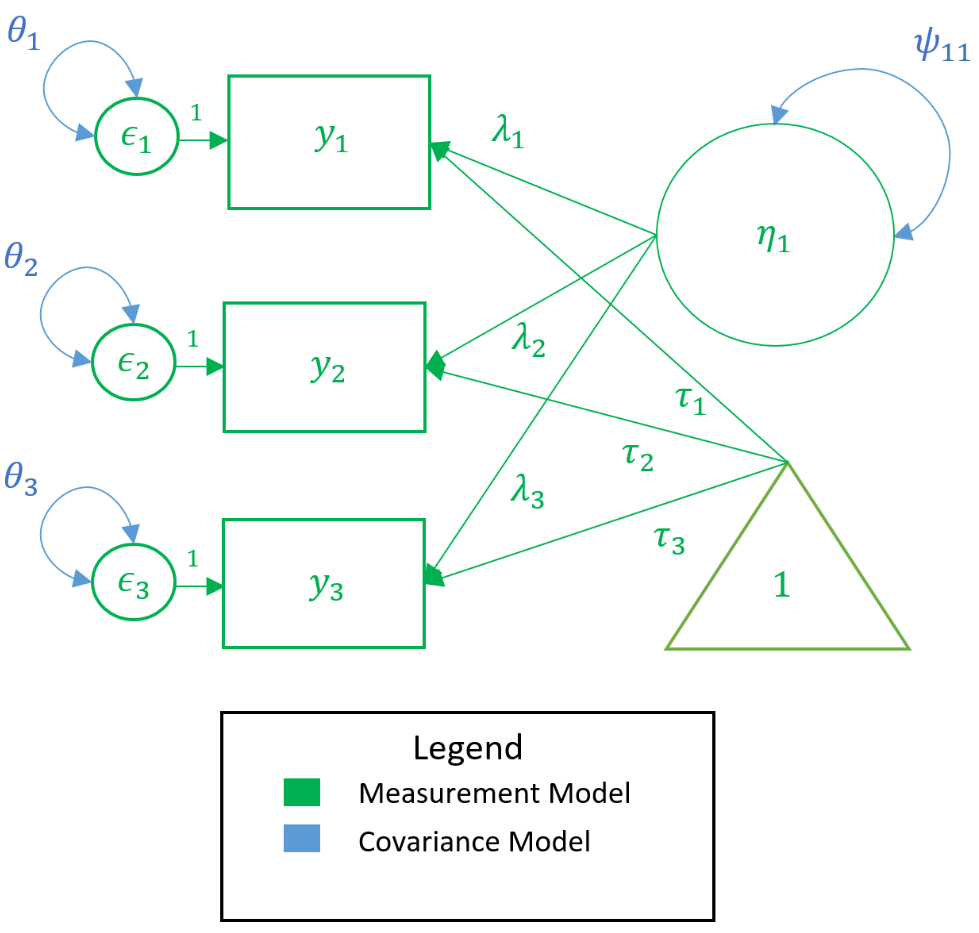
$$ \begin
$$ \Sigma(\theta) = \begin
Answer
One factor confirmatory factor analysis
Known values, parameters, and degrees of freedom
$$ \Sigma(\theta)= \begin
$$ \Sigma(\theta)= \begin
How many total (unique) parameters have we fixed here? (Answer: 10) The number of free parameters is defined as
Quiz
Three-item (one) factor analysis
For edification purposes, let’s suppose that due to budget constraints, only three items were collected from the SAQ-8. The following simplified path diagram depicts the SPSS Anxiety factor indicated by Items 3, 4 and 5 (note what’s missing from the complex diagram introduced in previous sections).
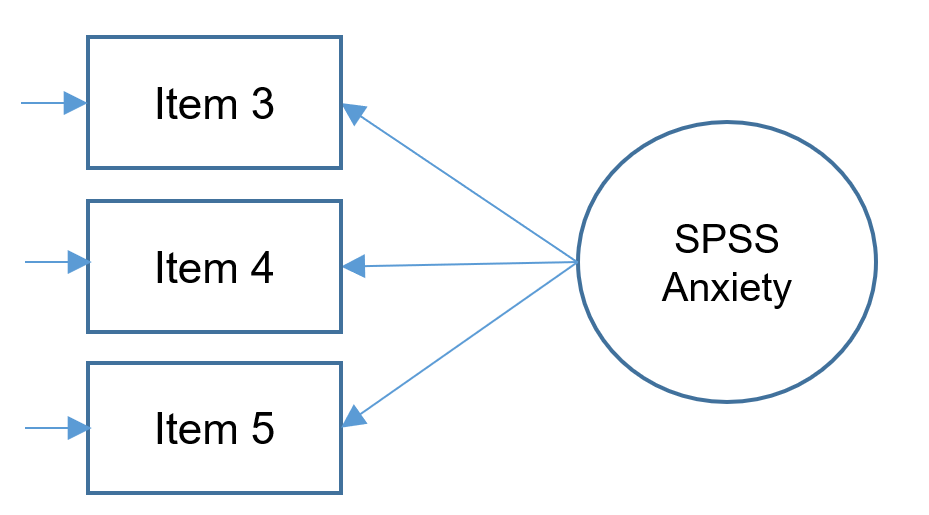
Thankfully for us, we have just the right amount of items to fit a CFA because a three-item one factor CFA is just-identified, meaning it has zero degrees of freedom. Because this model is on the brink of being under-identified, it is a good model for introducing identification, which is the process of ensuring each free parameter in the CFA has a unique solution and making surer the degrees of freedom is at least zero. There are many rules for proper identification, but for the casual analyst identification helps us avoid the following message in lavaan :
Identification of a three-item one factor CFA
In matrix notation, the marker method (Option 1) can be shown as
$$ \Sigma(\theta)= \psi_ <11>\begin
In matrix notation, the variance standardization method (Option 2) looks like
$$ \Sigma(\theta)= (1) \begin
Notice in both models that the residual covariances stay freely estimated.
For the variance standardization method, go through the process of calculating the degrees of freedom. If we have six known values is this model just-identified, over-identified or under-identified?
Running a one-factor CFA in lavaan
Before running our first factor analysis, let us introduce some of the most frequently used syntax in lavaan
indicator, used for latent variable to observed indicator in factor analysis measurement models
covariance
1 intercept or mean (e.g., q01
Now that we are familiar with some syntax rules, let’s see how we can run a one-factor CFA in lavaan with Items 3, 4 and 5 as indicators of your SPSS Anxiety factor.
The first line is the model statement. Recall that =
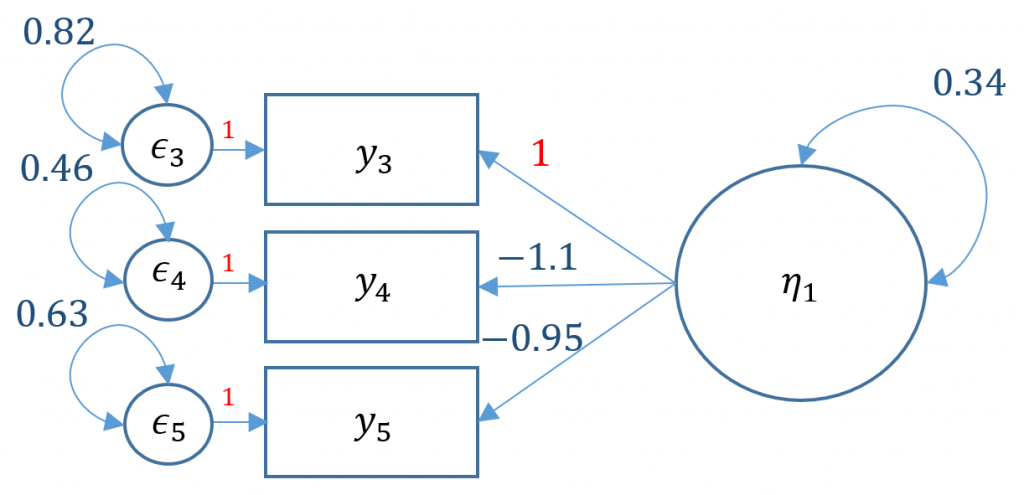
By default, lavaan chooses the marker method (Option 1) if nothing else is specified. In order to free a parameter, put NA* in front of the parameter to be freed, to fix a parameter to 1, put 1* in front of the parameter to be fixed. The syntax NA*q03 frees the loading of the first item because by default marker method fixes it to one, and f
1*f means to fix the variance of the factor to one.
Alternatively you can use std.lv=TRUE and obtain the same results
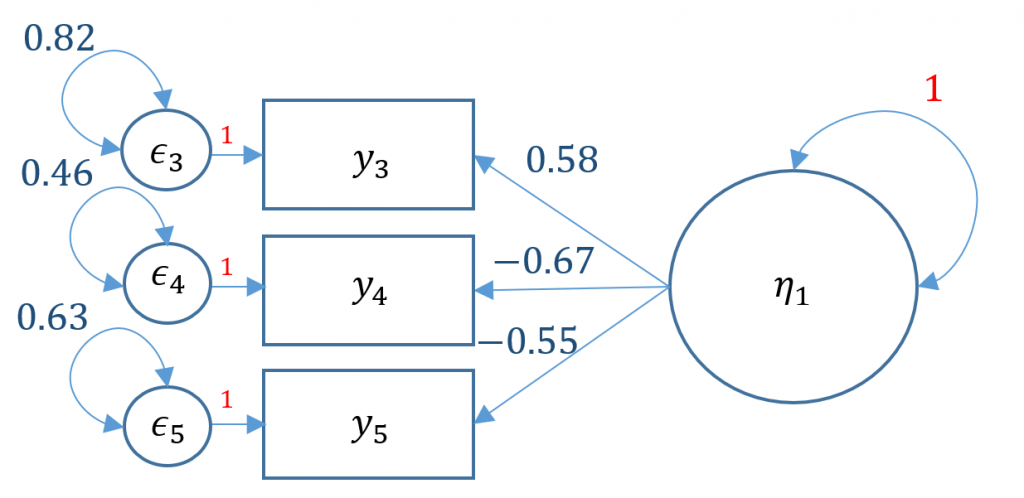
(Optional) How to manually obtain the standardized solution
To convert from Std.lv (which standardizes the X or the latent variable) to Std.all we need to divide by the implied standard deviation of each corresponding item. Recall from the variance covariance matrix that the diagonals are the variances of each variable. Similarly, we can obtain the implied variance from the diagonals of the implied variance-covariance matrix. The specification cov.ov stands for “observed covariance”.
(Optional) Degrees of freedom with means
Traditionally, CFA was only concerned with the covariance matrix and only the summary statistic in the form of the covariance matrix was supplied as the raw data due to computer memory constraints. In modern CFA and structural equation modeling (SEM) however, the full data is often available and easily stored in memory, and as a byproduct, the intercepts or means are can be estimated in what is known as Full Information Maximum Likelihood. With the full data, the total number of parameters is calculated accordingly:
1 means that we want to estimate the intercept for Item 3.
Notice that the number of free parameters is now 9 instead of 6, however, our degrees of freedom is still zero. Count the total parameters and explain why using the formula for degrees of freedom.
Then the degrees of freedom is calculated as
Therefore, our degrees of freedom is zero and we have a saturated or just-identified model! The conclusion is that adding in intercepts does not actually change the degrees of freedom of the model.
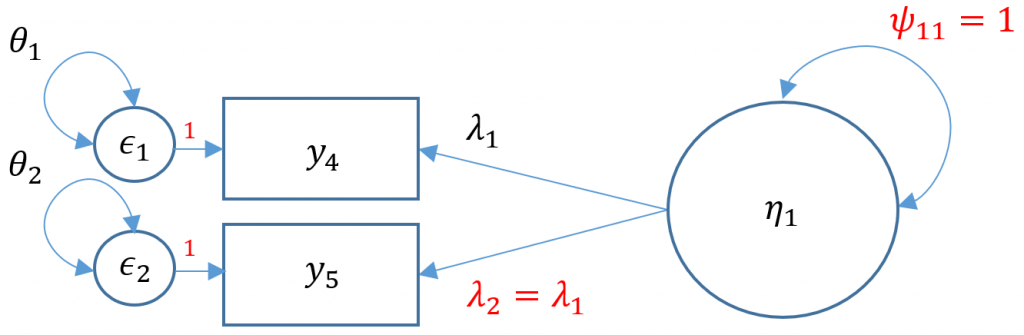
One factor CFA with two items
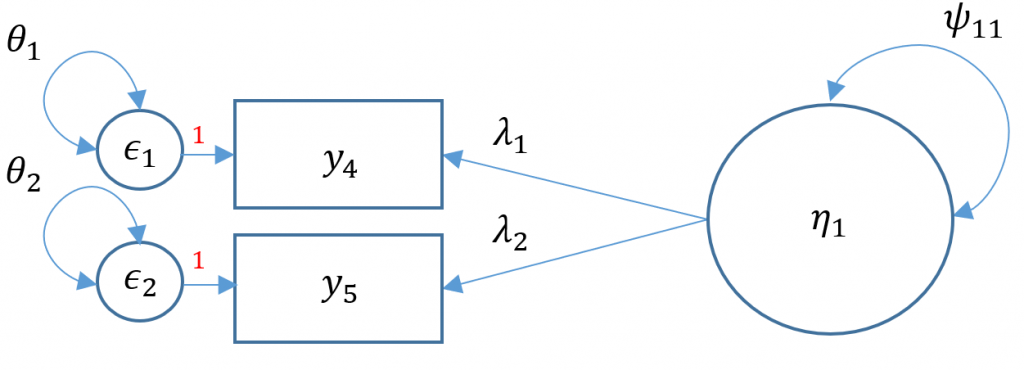
If you simply ran the CFA mode as is you will get the following error
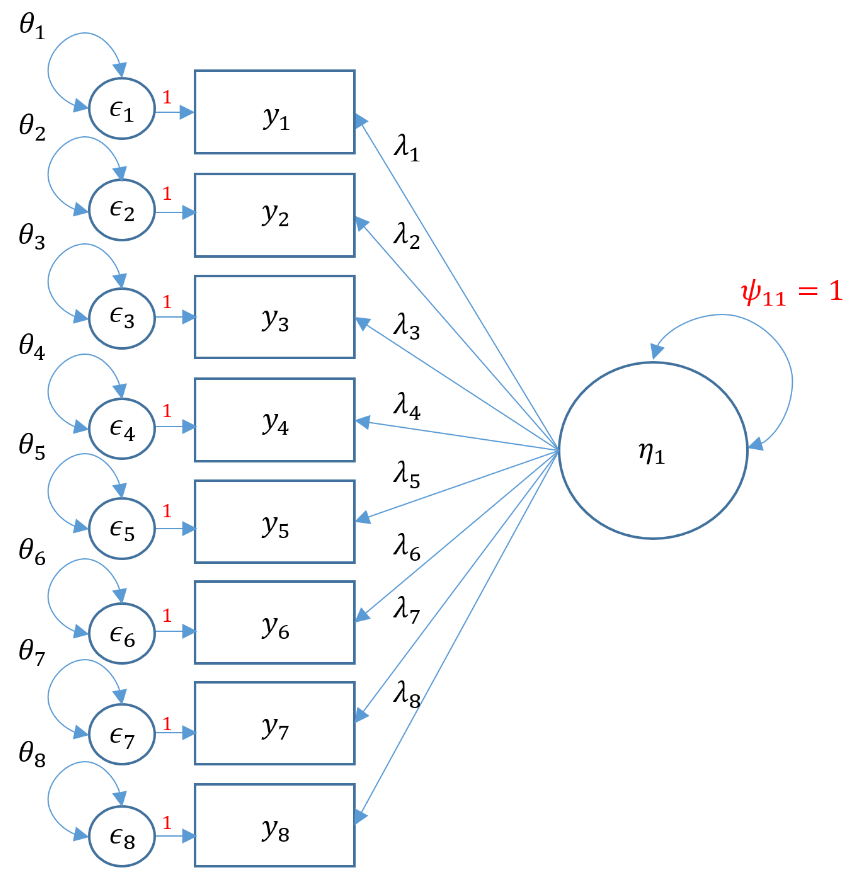
One factor CFA with more than three items (SAQ-8)
The benefit of performing a one-factor CFA with more than three items is that a) your model is automatically identified because there will be more than 6 free parameters, and b) you model will not be saturated meaning you will have degrees of freedom left over to assess model fit.
Model Fit Statistics
Typically, rejecting the null hypothesis is a good thing, but if we reject the CFA null hypothesis then we would reject our user model (which is bad). Failing to reject the model is good for our model because we have failed to disprove that our model is bad. Note that based on the logic of hypothesis testing, failing to reject the null hypothesis does not prove that our model is the true model, nor can we say it is the best model, as there may be many other competing models that can also fail to reject the null hypothesis. However, we can certainly say it it isn’t a bad model, and it is the best model we can find at the moment. Think of a jury where it has failed to prove the criminal guilty, but it doesn’t necessarily mean he is innocent. Can you think of a famous person from the 90’s who fits this criteria?
When fit measures are requested, lavaan outputs a plethora of statistics, but we will focus on the four commonly used ones:
TLI (Tucker Lewis Index)
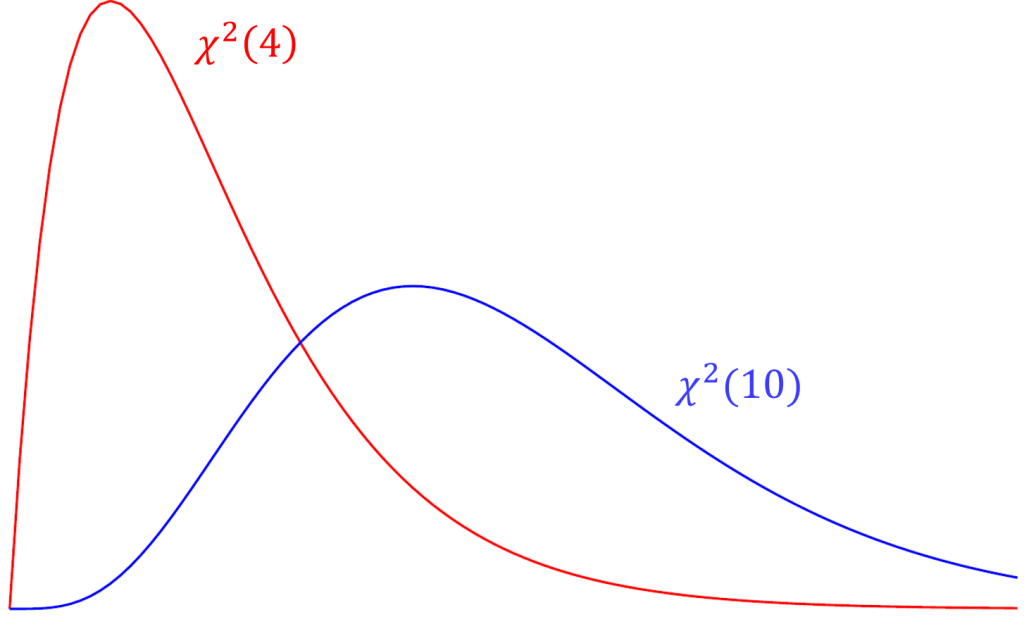
Suppose you ran a CFA with 20 degrees of freedom. What would be the acceptable range of chi-square values based on the criteria that the relative chi-square greater than 2 indicates poor fit?
Answer
The range of acceptable chi-square values ranges between 20 (indicating perfect fit) and 40, since 40/20 = 2.
The TLI is defined as
We can confirm our answers for both the TLI and CFI which are reported together in lavaan
RMSEA
Given that the p-value of the model chi-square was less than 0.05, the CFI = 0.871 and the RMSEA = 0.102, and looking at the standardized loadings we report to the Principal Investigator that the SAQ-8 as it stands does not possess good psychometric properties. Perhaps SPSS Anxiety is a more complex measure that we first assume.
Two Factor Confirmatory Factor Analysis
Although the results from the one-factor CFA suggest that a one factor solution may capture much of the variance in these items, the model fit suggests that this model can be improved. From the exploratory factor analysis, we found that Items 6 and 7 “hang” together. Let’s take a look at Items 6 and 7 more carefully.
Uncorrelated factors
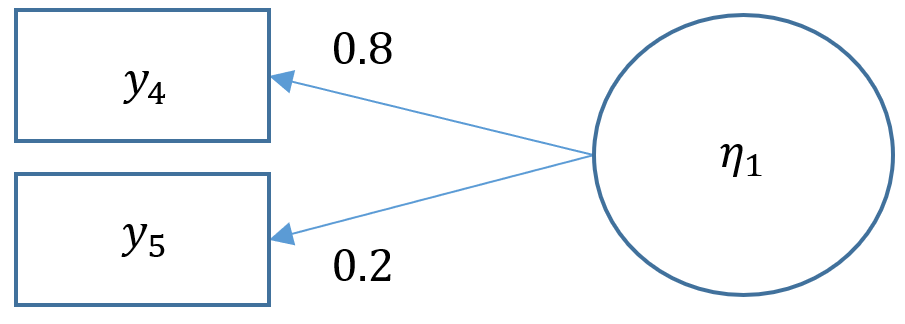
We will now proceed with a two-factor CFA where we assume uncorrelated (or orthogonal) factors. Having a two-item factor presents a special problem for identification. In order to identify a two-item factor there are two options:
Since we are doing an uncorrelated two-factor solution here, we are relegated to the first option.
Here’s what the model looks like graphically:
Since we picked Option 1, we set the loadings to be equal to each other:
We know the factors are uncorrelated because the estimate of f1
Looking at the model fit
We can see that the uncorrelated two factor CFA solution gives us a higher chi-square (lower is better), higher RMSEA and lower CFI/TLI, which means overall it’s a poorer fitting model. We talk to the Principal Investigator and decide to go with a correlated (oblique) two factor model.
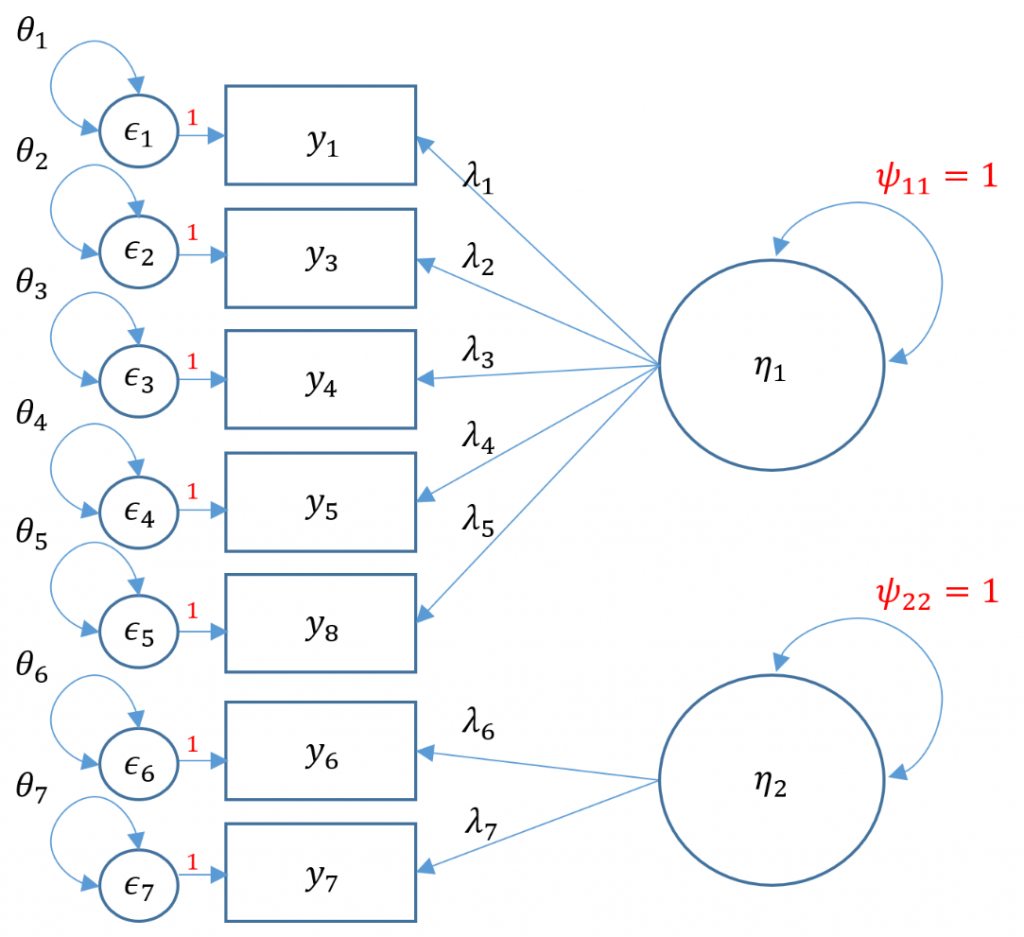
Correlated factors
We proceed with a correlated two-factor CFA. We still have the issue of that two-item factor; recall that for identification we can either equate the loadings and set the variance to 1 or we can covary the two-item factor with another factor and use the marker method. Taking advantage of our correlated factors, let’s use the second option.
Although lavaan defaults to the marker method, by specifying standardized=TRUE we then implement the variance standardization method.
Notice that compared to the uncorrelated two-factor solution, the chi-square and RMSEA are both lower. The test of RMSEA is not significant which means that we do not reject the null hypothesis that the RMSEA is less than or equal to 0.05. Additionally the CFI and TLI are both higher and pass the 0.95 threshold. This is even better fitting than the one-factor solution. After talking with the Principal Investigator, we choose the final two correlated factor CFA model as shown below.
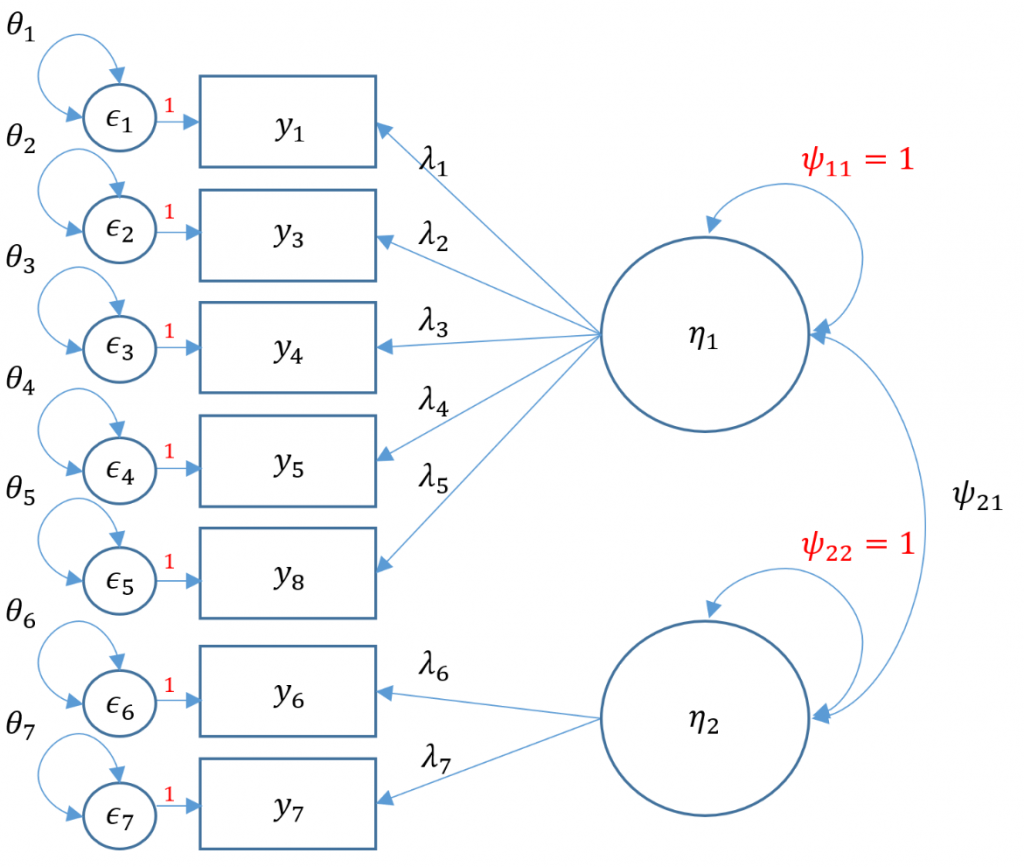
Second-Order CFA
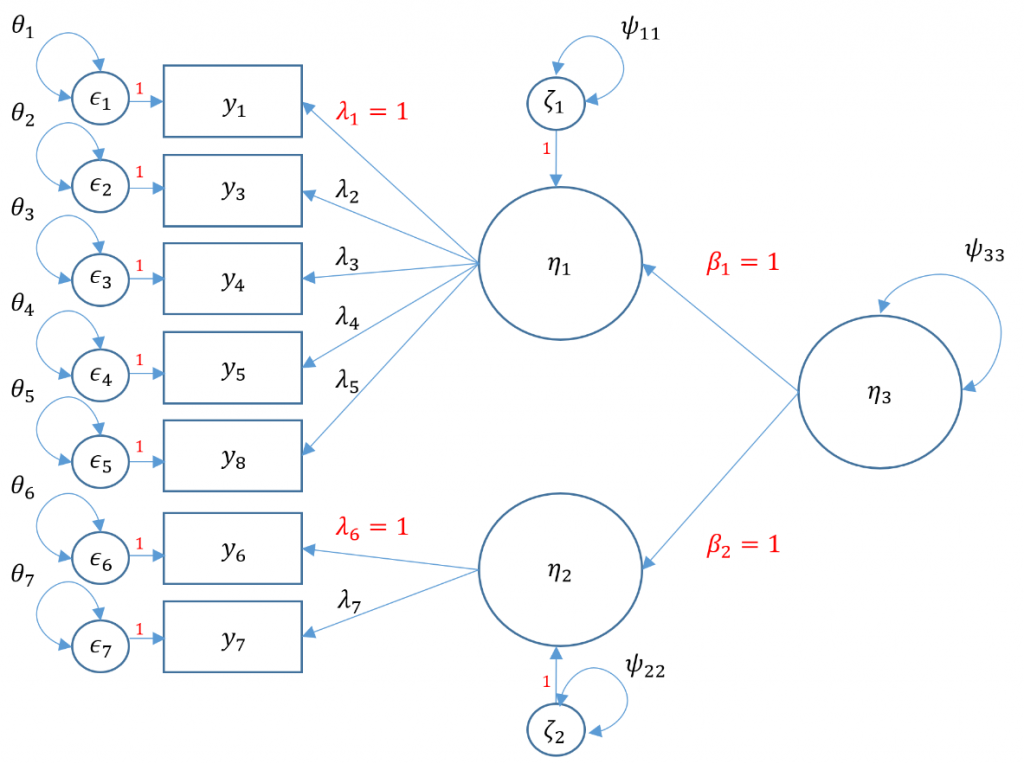
Note that there is no perfect way to specify a second order factor when you only have two first order factors. You either have to assume The variance standardization method assumes that the residual variance of the two first order factors is one which means that you assume homogeneous residual variance. The marker method assumes that both loadings from the second order factor to the first factor is 1. To make sure you fit an equivalent method though, the degrees of freedom for the User model must be the same. NOTE: changing the standardization method should not change the degrees of freedom and chi-square value. If you standardize it one way and get a different degrees of freedom, then you have identified it incorrectly. Even though the chi-square fit is the same however, you will get different standardized variances and loadings depending on the the assumptions you make (to set the loadings to 1 for the two first order factors and freely estimate the variance or to freely estimate but equate the loadings and set the residual variance of the first order factors to 1).
(Optional) Warning message with second-order CFA
The warning message is an indication that your model is not identified rather than a problem with the data.
Note the following marker method below is the correct identification. The syntax NA*f1 means to free the first loading because by default the marker method fixes the loading to 1, and equal(«f3=
f1″)*f2 fixes the loading of the second factor on the third to be the same as the first factor.
(Optional) Obtaining the parameter table
Conclusion
Primary Sidebar
Click here to report an error on this page or leave a comment



