Осваиваем компьютерное зрение — 8 основных шагов
Для тебя уже не является новостью тот факт, что все на себе попробовали маски старения через приложение Face App. В свою очередь для компьютерного зрения есть задачи и поинтереснее этой. Ниже представлю 8 шагов, которые помогут освоить принципы компьютерного зрения.

Прежде, чем начать с этапов давайте поймём, какие задачи мы с вами сможем решать с помощью компьютерного зрения. Примеры задач могут быть следующими:
Минимальные знания, необходимые для освоения компьютерного зрения
Шаг 1 — Базовые методики работы с изображениями
Этот шаг посвящен техническим основам.
Прочтите — третью главу книги Ричарда Шелиски «Компьютерное зрение: Алгоритмы и приложения».

Закрепите знания — попробуйте себя в преобразовании изображений с помощью OpenCV. На сайте есть много пошаговых электронных пособий, руководствуясь которыми можно во всём разобраться.
Шаг 2 — Отслеживание движения и анализ оптического потока
Оптический поток — это последовательность изображений объектов, получаемая в результате перемещения наблюдателя или предметов относительно сцены.
Пройдите курс — курс по компьютерному зрению на Udacity, в особенности урок 6.
Посмотрите — 8-ое видео в YouTube-списке и лекцию об оптическом потоке и трекинге.
Прочтите — разделы 10.5 и 8.4 учебника Шелиски.

В качестве учебного проекта разберитесь с тем, как с помощью OpenCV отслеживать объект в видеофрейме.
Шаг 3 — Базовая сегментация
В компьютерном зрении, сегментация — это процесс разделения цифрового изображения на несколько сегментов (суперпиксели). Цель сегментации заключается в упрощении и/или изменении представления изображения, чтобы его было проще и легче анализировать.
Так, преобразование Хафа позволяет найти круги и линии.
Computer Vision для iOS, Android, Web
Привет, я Денис Соколов, руковожу R&D в Zenia — это платформа для йоги и фитнеса, которая использует ИИ для трекинга поз человека (подробнее об этом — в другой моей статье). Наша система распознавания работает на трёх платформах — iOS, Android, Web. В этой статье поговорим о ключевых отличиях между ними. Расскажу, как устроена подготовка моделей компьютерного зрения к использованию, какими фреймворками пользуемся для запуска на устройствах клиентов, какие сложности решали и чем остались довольны. Если вы занимаетесь запуском нейронных сетей на мобильных устройствах или вебе, статья для вас.

Обучение модели
Цикл жизни модели состоит из двух этапов — обучения и ее исполнения на устройстве. Для Zenia мы обучаем модели на серверах, а запускаем на устройствах пользователей. Это очень разные условия как с точки зрения окружения — операционных систем и железа, так и с точки зрения требований: необходимой функциональности и размера библиотек. Различия настолько большие, что фреймворки разделяются по назначению даже в пределах одной экосистемы — PyTorch и PyTorch Mobile, TensorFlow и TensorFlow Lite. Существуют отдельные решения, максимально эффективно использующие особенности платформ: CoreML и SNPE для мобильных устройств, TensorRT и OpenVino для серверов и десктопов.
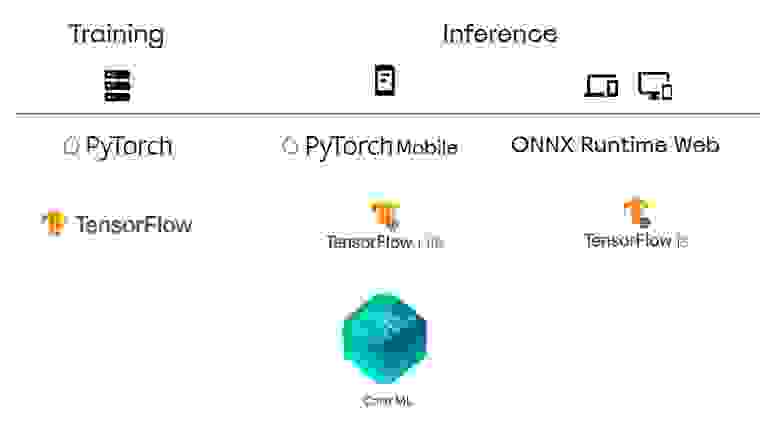
Для обучения моделей мы используем фреймворк PyTorch. В основе PyTorch лежит динамический граф вычислений. Это значит, что работу модели мы описываем императивно: явно задаем последовательность операций и даже можем менять операции «на лету». У этого подхода есть преимущества — простота и скорость разработки: последовательность операций задаётся явно, можно легко и быстро получить доступ к промежуточным выходам модели.
Но есть и недостатки такой динамичности: результатом обучения, который можно «опубликовать» для исполнения, является комбинация из кода, описывающего последовательность операций, и обученных весов. Он сильно привязан к конкретной среде исполнения — интерпретатору Python и полноценной сборке PyTorch. Такой формат плохо переносим (для исполнения требуется портирование и сборка большого объёма кода) и его сложно совмещать с другими компонентами системы (по сравнению, например, с библиотеками на C).
Также, если мы хотим исполнять модель с максимальной эффективностью, нужно иметь возможность заранее проанализировать используемые в ней операции. Выбрать для них наиболее оптимальные реализации и тип железа для исполнения, рассчитать размеры буферов памяти, чтобы не выделять её во время работы, и так далее.
Далее коротко обсудим, как перевести модель из одного формата в другой, зачем это нужно и как устроен этот процесс.
Конвертация модели
Чтобы выжать максимальную пользу от оптимизаторов, динамичность из модели нужно убрать, то есть скомпилировать её. В PyTorch эту роль выполняет модуль torch.jit. Он отдает низкоуровневое представление модели в виде статической последовательности операций, которая лучше подходит для оптимизации (TorchScript).

Универсальным решением конвертационных вопросов должен был стать ONNX — промежуточный формат, работу над которым начали Microsoft и Facebook в 2017 году. К сожалению, даже в 2021 году далеко не все фреймворки умеют работать с ним напрямую. А это значит, что приходится переживать конвертацию дважды.
Любая конвертация модели потенциально несёт проблемы. Не поддерживается какой-нибудь слой, не совмещаются версии исходного и целевого фреймворка с конкретной версией ONNX. Даже если конвертация технически удалась, это ещё не гарантирует успех: из одного слоя может получиться пять. Или реализация какой-нибудь операции будет не такой, как вы хотели. И даже если подобрать правильную комбинацию параметров и версий, нет гарантии, что при обновлениях фреймворков что-нибудь не сломается.
А если вы используете кастомные слои, то возможностей для приключений становится ещё больше.
Что можно сделать, чтобы облегчить себе жизнь:
Обложиться инженерными практиками — фиксировать версии библиотек, запускать конвертер в докере
Тестировать модель до и после конвертации, в том числе на скорость работы
С помощью netron отсматривать получившийся после конвертации граф на предмет аномалий
Использовать только базовые слои — никаких channel shuffle, если вы можете себе это позволить
Альтернатива — использовать TensorFlow и страдать во время разработки. С точки зрения удобства исполнения на конечных устройствах TensorFlow, безусловно, выигрывает: большинство inference-фреймворков понимают его формат.
Отличия между платформами, на которых исполняется модель
Apple сделал свою платформу очень дружелюбной к машинному обучению. Есть 2 стандартных API — высокоуровневый Core ML и низкоуровневый MPS (Metal Performance Shaders). Они доступны на всех актуальных версиях iOS, поэтому о поддержке можно не беспокоиться.
Android
Есть много фреймворков для запуска нейронных сетей на Android-устройствах. От производителей железа и телефонов: MACE (Xiaomi), HiAI (Huawei), SNPE (Qualcomm), ncnn (Tencent), MNN (Alibaba), а также версии популярных фреймворков, адаптированные для мобильных устройств — PyTorch Mobile, TensorFlow Lite.
Google занимается стандартизацией API для нейронных сетей — NNAPI. Он призван облегчить жизнь разработчикам фреймворков и библиотек в поддержке GPU и NPU (сопроцессоров для ускорения работы нейронных сетей) и должен работать, начиная с Android 8.1. К сожалению, эта прекрасная идея пока не очень хорошо работает на практике и фактически поддерживается не на всех устройствах. Попытка запустить модель с использованием NNAPI запросто может привести к тому, что на самом деле работать она будет на CPU.
Библиотека для запуска модели — это лишь часть пайплайна, который проходит изображение от камеры до получения результата, видимого пользователю. Если вы хотите оптимизировать процесс, нужно глубоко разбираться с Camera API (которых на Android уже 3) и OpenGL. Или воспользоваться готовым решением — MediaPipe.
Отдельно стоит упомянуть MLKit: высокоуровневый набор готовых решений, использующих машинное обучение для мобильных устройств.
Вместе со сложностями поддержка Android несёт и важное бизнес-преимущество. Android — это не только мобильные телефоны, но и телевизоры, и другие умные устройства. Поддержка Android позволила нам быстро портировать приложение на SberPortal и SberBoxTop.
В последнее время всё переезжает в браузеры или браузерные технологии. Машинное обучение — не исключение. Ситуация с GPU и браузерами сложная: браузеры сейчас — это почти операционная система, которая добавляет ещё один уровень абстракции над железом.
С одной стороны, это круто: код для WebGL может работать как на встроенных, так и на дискретных GPU. С другой стороны, он будет работать не так эффективно из-за дополнительного посредника. Стандарты WebAssembly и WebGPU, которые сейчас разрабатывают, должны побороть этот недостаток и дать более низкоуровневый доступ к возможностям железа. Есть и «стандартный» API для нейронных сетей в браузере — WebNN.
Использование нейронных сетей в браузере осложняется тем, что пока что нет стандартных способов построения эффективного пайплайна. Приходится изобретать свои решения — например, с использованием web workers, чтобы снять нагрузку с основного потока. Браузер часто ведёт себя непредсказуемо, перераспределяя лимиты по использованию железа на своё усмотрение. Это сильно осложняет профилирование и поиск проблем с производительностью.
Для поддержки максимального количество устройств с наилучшим пользовательским опытом применяют подстройку системы распознавания под конкретное устройство. С помощью бенчмарка определяется «мощность» платформы. В зависимости от этого регулируются целевой fps и разрешение входного изображения или выбирается более лёгкая версия модели.
Обвязка модели
Прогонка модели — это лишь один из этапов пайплайна, состоящего из множества шагов. С точки зрения кода это одна строка, которую окружают тысячи строк пре- и пост-процессинга разного уровня абстракции. С таким кодом начинают работать правила, актуальные для любой бизнес-логики, которую хочется переиспользовать между платформами.

Можно написать её несколько раз на каждой платформе, но тогда с каждой новой платформой скорость разработки замедляется и повышается вероятность ошибок. Также появляются сложности со стороны организации разработки: на каждой из платформ свой язык программирования, свои инструменты и подходы к разработке. Приходится выбирать: развивать экспертизу по каждой из платформ в отделе R&D или иметь один источник правды (эталонную систему) и передавать работу по интеграции в соответствующие команды.
Мы пошли по первому пути. Во многом из-за того, что наша компания начиналась с R&D, и другого выбора у нас не было. До того, как в компании стали появляться отделы, отвечающие за конкретную платформу, наш R&D-отдел отвечал за полный цикл доставки, от набора данных и обучения моделей до интеграции системы в конкретную платформу.
Когда количество платформ растёт, а код пре- и пост-процессинга становится всё более сложным, хочется иметь возможность писать его только один раз. До недавнего времени единственным выбором для создания кросс-платформенных модулей был C/C++. Ситуацию поменял не так давно появившийся Kotlin Multiplatform.
Мы начали Android проект на Kotlin с расчётом на то, что Kotlin Multiplatform станет шагом в сторону переиспользования кода между платформами. Нам повезло, и мы попали в момент, когда KMM (Kotlin Multiplatform Mobile) уже был достаточно зрелым для реальных проектов.
Впервые мы попробовали возможности Kotlin Native, когда писали собственные модули для MediaPipe. Несмотря на то, что интерфейс библиотеки, генерируемый Kotlin Native не совсем удобный, многословный и требует некоторых ритуалов для преобразования данных в нужный формат, цель была достигнута. Мы начали использовать единую кодовую базу.
Когда мы решили портировать Zenia в Web, то уже неплохо знали особенности работы с KMM и решили использовать Kotlin/JS, чтобы переиспользовать бОльшую часть логики. И это сработало, причём без больших проблем.
Скорее всего, полученный результат не так эффективен и производителен, как если бы мы написали кросс-платформенную библиотеку на C++. Но работа с Kotlin многократно проще и приятнее. А главное — позволяет быстрее и с меньшими усилиями получить желаемый результат, что очень важно для стартапа.
Резюме и советы практикам
В этой статье мы совсем не касались способов оптимизации запуска моделей на серверах, десктопах и специализированных устройствах, таких, как NVIDIA Jetson и Intel Movidius.
Если планируете запускать модель на устройствах пользователей, с самого начала разработки стоит запланировать, какими фреймворками будете пользоваться, и накидать базовый пайплайн. Если для вашей задачи уже есть готовые решения, ознакомьтесь сначала с ними, позапускайте на ваших устройствах. Так вы лучше поймёте возможности платформ. Сейчас я бы выбрал CoreML на iOS, Camera X ImageAnalysis на Android c переходом на MediaPipe для более сложных пайплайнов, tf.js для браузеров. Но если вы попробуете PyTorch Mobile и расскажете об этом — буду благодарен 🙂
Не бойтесь Андроида: сейчас запускать на этих устройствах аппаратно ускоренные модели машинного обучения с хорошей производительностью вполне реально. Плохая новость заключается в том, что даже примеры Гугла на некоторых телефонах запускаются через раз.
Не откладывайте сборку пайплайна на последний момент. Конечному пользователю не интересна производительность вашей модели в вакууме — важен опыт использования системы целиком. Рекомендую как можно раньше собрать и протестировать базовую версию модели. Так вы лучше оцените требования по производительности, пройдёте через круги ада конвертеров (часто практичнее поменять архитектуру модели, чем бороться с ними) и снимете большое количество рисков.
Один вовремя написанный юнит или интеграционный тест поможет вам сэкономить кучу времени на отладке сломанного пайплайна. Работа с мобилками не такая привычная, но вооружившись Streamlit, Flask/FastAPI и вебсокетами, можно за пару дней соорудить из телефона сервер и гонять кусочки пайплайна, перетаскивая картинки в браузере.
Компьютерное зрение. Лекция для Малого ШАДа Яндекса
Область применения компьютерного зрения очень широка: от считывателей штрихкодов в супермаркетах до дополненной реальности. Из этой лекции вы узнаете, где используется и как работает компьютерное зрение, как выглядят изображения в цифрах, какие задачи в этой области решаются относительно легко, какие трудно, и почему.
Лекция рассчитана на старшеклассников – студентов Малого ШАДа, но и взрослые смогут почерпнуть из нее много полезного.
Возможность видеть и распознавать объекты – естественная и привычная возможность для человека. Однако для компьютера пока что – это чрезвычайно сложная задача. Сейчас предпринимаются попытки научить компьютер хотя бы толике того, что человек использует каждый день, даже не замечая того.
Наверное, чаще всего обычный человек встречается с компьютерным зрением на кассе в супермаркете. Конечно, речь идет о считывании штрихкодов. Они были разработаны специально именно таким образом, чтобы максимально упростить компьютеру процесс считывания. Но есть и более сложные задачи: считывание номеров автомобилей, анализ медицинских снимков, дефектоскопия на производстве, распознавание лиц и т.д. Активно развивается применение компьютерного зрения для создания систем дополненной реальности.
Разница между зрением человека и компьютера
Ребенок учится распознавать объекты постепенно. Он начинает осознавать, как меняется форма объекта в зависимости от его положения и освещения. В дальнейшем при распознавании объектов человек ориентируется на предыдущий опыт. За свою жизнь человек накапливает огромное количество информации, процесс обучения нейронной сети не останавливается ни на секунду. Для человека не представляет особой сложности по плоской картинке восстановить перспективу и представить себе, как бы все это выглядело в трех измерениях.
Компьютеру все это дается гораздо сложнее. И в первую очередь из-за проблемы накопления опыта. Нужно собрать огромное количество примеров, что пока что не очень получается.
Кроме того, человек при распознавании объекта всегда учитывает окружение. Если выдернуть объект из привычного окружения, узнать его станет заметно труднее. Тут тоже играет роль накопленный за жизнь опыт, которого у компьютера нет.
Мальчик или девочка?
Представим, что нам нужно научиться с одного взгляда определять пол человека (одетого!) по фотографии. Для начала нужно определить факторы, которые могут указывать на принадлежность к тому или иному объекту. Кроме того, нужно собрать обучающее множество. Желательно, чтобы оно было репрезентативным. В нашем случае возьмем в качестве обучающей выборки всех присутствующих в аудитории. И попробуем на их основе найти отличительные факторы: например, длина волос, наличие бороды, макияжа и одежда (юбка или брюки). Зная, у какого процента представителей одного пола встречались те или иные факторы, мы сможем создать достаточно четкие правила: наличие тез или иных комбинаций факторов с некоей вероятностью позволит нам сказать, человек какого пола на фотографии.
Машинное обучение
Конечно, это очень простой и условный пример с небольшим количеством верхнеуровневых факторов. В реальных задачах, которые ставятся перед системами компьютерного зрения, факторов гораздо больше. Определять их вручную и просчитывать зависимости – непосильная для человека задача. Поэтому в таких случаях без машинного обучения не обойтись никак. Например, можно определить несколько десятков первоначальных факторов, а также задать положительные и отрицательные примеры. А уже зависимости между этими факторами подбираются автоматически, составляется формула, которая позволяет принимать решения. Достаточно часто и сами факторы выделяются автоматически.
Изображение в цифрах
Чаще всего для хранения цифровых изображений используется цветовое пространство RGB. В нем каждой из трех осей (каналов) присваивается свой цвет: красный, зеленый и синий. На каждый канал выделяется по 8 бит информации, соответственно, интенсивность цвета на каждой оси может принимать значения в диапазоне от 0 до 255. Все цвета в цифровом пространстве RGB получаются путем смешивания трех основных цветов.
К сожалению, RGB не всегда хорошо подходит для анализа информации. Эксперименты показывают, что геометрическая близость цветов достаточно далека от того, как человек воспринимает близость тех или иных цветов друг к другу.
Но существуют и другие цветовые пространства. Весьма интересно в нашем контексте пространство HSV (Hue, Saturation, Value). В нем присутствует ось Value, обозначающая количество света. На него выделен отдельный канал, в отличие от RGB, где это значение нужно вычислять каждый раз. Фактически, это черно-белая версия изображения, с которой уже можно работать. Hue представляется в виде угла и отвечает за основной тон. От значения Saturation (расстояние от центра к краю) зависит насыщенность цвета.
HSV гораздо ближе к тому, как мы представляем себе цвета. Если показать человеку в темноте красный и зеленый объект, он не сможет различить цвета. В HSV происходит то же самое. Чем ниже по оси V мы продвигаемся, тем меньше становится разница между оттенками, так как снижается диапазон значений насыщенности. На схеме это выглядит как конус, на вершине которого предельно черная точка.
Цвет и свет
Почему так важно иметь данные о количестве света? В большинстве случаев в компьютерном зрении цвет не имеет никакого значения, так как не несет никакой важной информации. Посмотрим на две картинки: цветную и черно-белую. Узнать все объекты на черно-белой версии не намного сложнее, чем на цветной. Дополнительной нагрузки для нас цвет в данном случае не несет никакой, а вычислительных проблем создает великое множество. Когда мы работаем с цветной версией изображения, объем данных, грубо говоря, возводится в степень куба.

Цвет используется лишь в редких случаях, когда это наоборот позволяет упростить вычисления. Например, когда нужно детектировать лицо: проще сначала найти его возможное расположение на картинке, ориентируясь на диапазон телесных оттенков. Благодаря этому отпадает необходимость анализировать изображение целиком.
Локальные и глобальные признаки
Признаки, при помощи которых мы анализируем изображение, бывают локальными и глобальными. Глядя на эту картинку, большинство скажет, что на ней изображена красная машина:

Такой ответ подразумевает, что человек выделил на изображении объект, а значит, описал локальный признак цвета. По большому счету на картинке изображен лес, дорога и немного автомобиля. По площади автомобиль занимает меньшую часть. Но мы понимаем, что машина на этой картинке – самый важный объект. Если человеку предложить найти картинки похожие на эту, он будет в первую очередь отбирать изображения, на которых присутствует красная машина.
Детектирование и сегментация
В компьютерном зрении этот процесс называется детектированием и сегментацией. Сегментация – это разделение изображения на множество частей, связанных друг с другом визуально, либо семантически. А детектирование – это обнаружение объектов на изображении. Детектирование нужно четко отличать от распознавания. Допустим, на той же картинке с автомобилем можно детектировать дорожный знак. Но распознать его невозможно, так как он повернут к нам обратной стороной. Так же при распознавании лиц детектор может определить расположение лица, а «распознаватель» уже скажет, чье это лицо.

Дескрипторы и визуальные слова
Существует много разных подходов к распознаванию.
Например, такой: на изображении сначала нужно выделить интересные точки или интересные места. Что-то отличное от фона: яркие пятна, переходы и т.д. Есть несколько алгоритмов, позволяющих это сделать.
Один из наиболее распространенных способов называется Difference of Gaussians (DoG). Размывая картинку с разным радиусом и сравнивая получившиеся результаты, можно находить наиболее контрастные фрагменты. Области вокруг этих фрагментов и являются наиболее интересными.
Далее эти области описываются в цифровом виде. Области разбиваются на небольшие участки, определяется, в какую сторону направлены градиенты, получаются векторы.
На картинке ниже изображено, как это примерно выглядит. Полученные данные записываются в дескрипторы.
Чтобы одинаковые дескрипторы признавались таковыми независимо от поворотов в плоскости, они разворачиваются так, чтобы самые большие векторы были повернуты в одну сторону. Делается это далеко не всегда. Но если нужно обнаружить два одинаковых объекта, расположенных в разных плоскостях.
Дескрипторы можно записывать в числовом виде. Дескриптор можно представить в виде точки в многомерном массиве. У нас на иллюстрации двумерный массив. В него попали наши дескрипторы. И мы можем их кластеризовать – разбить на группы.
Дальше мы для каждого кластера описываем область в пространстве. Когда дескриптор попадает в эту область, для нас становится важным не то, каким он был, а то, в какую из областей он попал. И дальше мы можем сравнивать изображения, определяя, сколько дескрипторов одного изображения оказались в тех же кластерах, что и дескрипторы другого изображения. Такие кластеры можно называть визуальными словами.
Чтобы находить не просто одинаковые картинки, а изображения похожих объектов, требуется взять множество изображений этого объекта и множество картинок, на которых его нет. Затем выделить из них дескрипторы и кластеризовать их. Далее нужно выяснить, в какие кластеры попали дескрипторы с изображений, на которых присутствовал нужный нам объект. Теперь мы знаем, что если дескрипторы с нового изображения попадают в те же кластеры, значит, на нем присутствует искомый объект.
Совпадение дескрипторов – еще не гарантия идентичности содержащих их объектов. Один из способов дополнительной проверки – геометрическая валидация. В этом случае проводится сравнение расположения дескрипторов относительно друг друга.
Распознавание и классификация
Для простоты представим, что мы можем разбить все изображения на три класса: архитектура, природа и портрет. В свою очередь, природу мы можем разбить на растения животных и птиц. А уже поняв, что это птица, мы можем сказать, какая именно: сова, чайка или ворона.
Разница между распознаванием и классификацией достаточно условна. Если мы нашли на картинке сову, то это скорее распознавание. Если просто птицу, то это некий промежуточный вариант. А если только природу – это определенно классификация. Т.е. разница между распознаванием и классификацией заключается в том, насколько глубоко мы прошли по дереву. И чем дальше будет продвигаться компьютерное зрение, тем ниже будет сползать граница между классификацией и распознаванием.



