ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Как архивировать и распаковывать файлы с помощью PowerShell
Формат файла ZIP уменьшает размер файлов, сжимая их в один файл. Этот процесс экономит дисковое пространство, шифрует данные и позволяет легко обмениваться файлами с другими. Вот как можно сжать и разархивировать файлы с помощью PowerShell.


Как архивировать файлы с помощью PowerShell
Сначала откройте PowerShell, выполнив поиск в меню «Пуск», а затем введите следующую команду, заменив PathToFiles и PathToDestination на путь к файлам, которые вы хотите сжать, а также на имя и папку, в которую вы хотите перейти, соответственно:
Примечание. Кавычки вокруг пути необходимы только в том случае, если путь к файлу содержит пробел.
В качестве альтернативы, чтобы сжать все содержимое папки и все ее подпапки, вы можете использовать следующую команду, заменив PathToFolder и PathToDestination на путь к файлам, которые вы хотите сжать, а также на имя и папку, которую вы хотите. чтобы перейти соответственно:
В предыдущем примере мы указали путь к каталогу с несколькими файлами и папками без указания отдельных файлов. PowerShell берет все внутри корневого каталога и сжимает его, а также все подпапки.
Выше мы рассмотрели, как включить корневой каталог и все его файлы и подкаталоги при создании архивного файла. Однако, если вы хотите исключить корневую папку из Zip-файла, вы можете использовать подстановочный знак, чтобы исключить ее из архива. Добавляя звездочку (*) в конец пути к файлу, вы указываете PowerShell только захватить то, что находится внутри корневого каталога. Это должно выглядеть примерно так:
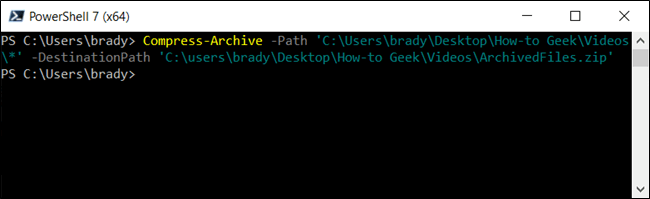
Примечание. Подкаталоги и файлы корневой папки не включаются в архив этим методом.
Наконец, если вам нужен архив, который сжимает файлы только в корневом каталоге и во всех его подкаталогах, вы должны использовать подстановочный знак «звезда-точка-звезда» (*. *) Для их сжатия. Это будет выглядеть примерно так:
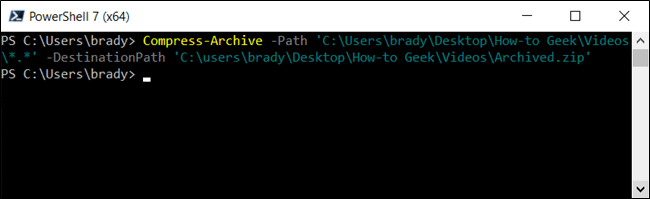
Примечание. Подкаталоги и файлы корневой папки не включаются в архив этим методом.
Как распаковать файлы с помощью PowerShell
Помимо возможности архивировать файлы и папки, PowerShell имеет возможность разархивировать архивы. Процесс даже проще, чем их сжатие; все, что вам нужно, это исходный файл и место для данных, готовых к распаковке.
Откройте PowerShell и введите следующую команду, заменив PathToZipFile и PathToDestination на путь к файлам, которые вы хотите сжать, а также на имя и папку, в которую вы хотите перейти, соответственно:
Папка назначения, указанная для извлечения файлов, будет заполнена содержимым архива. Если папка не существовала до разархивирования, PowerShell создаст папку и поместит содержимое в нее перед разархивированием.
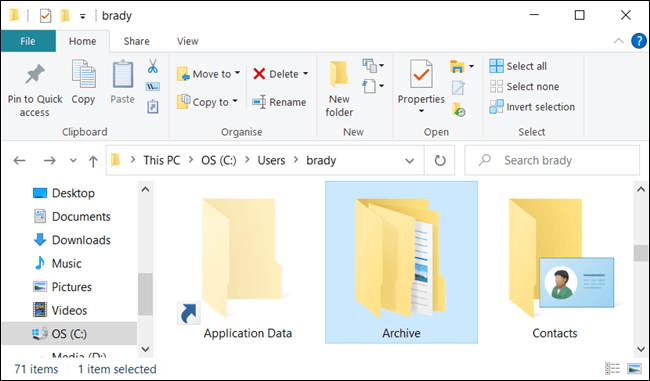
Архивирование и распаковка ZIP архивов в PowerShell
В модуле Microsoft.PowerShell.Archive (C:\Windows\System32\WindowsPowerShell\v1.0\Modules\Microsoft.PowerShell.Archive) есть всего два командлета:
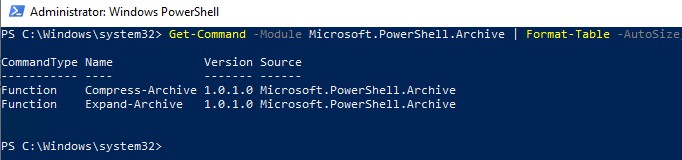
Рассмотрим примеры использования этих командлетов для создания и распаковки ZIP архивов в ваших PowerShell скриптах.
Как создать ZIP архив в PowerShell с помощью Compress-Archive?
Команда Compress-Archive имеет следующий синтаксис:
Compress-Archive [-Path] String[] [-DestinationPath] String [-CompressionLevel String ] [-Update]
Чтобы заархивировать один файл, выполните:
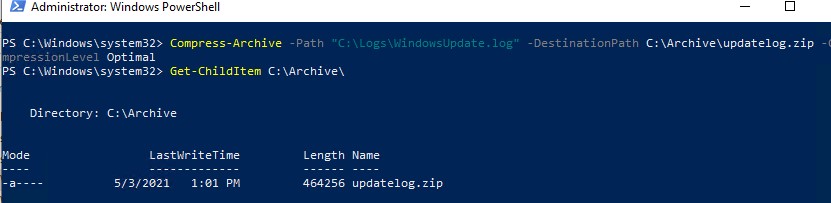
Можно заархивировать все содержимое нескольких каталогов (все файлы и подкаталоги):
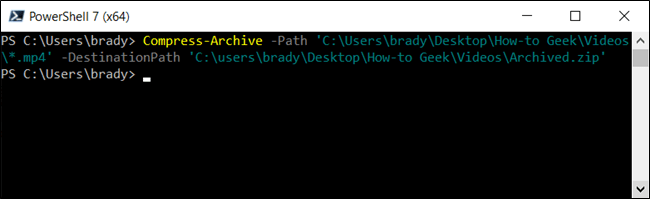
Можно добавить в ZIP архив только файлы с определенной маской. Например, следующая команда запакует только файлы с расширением *.txt.
С помощью Get-ChildItem можно использовать более сложные фильтры. Например, следующий скрипт позволит найти на диске топ 10 самых больших файлов с расширением *.docx или *.xlsx и добавит их в архив:
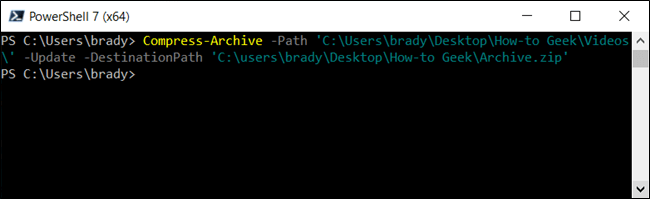
Чтобы добавить в существующий zip архив новые файлы, используйте ключ Update:

Как распаковать ZIP архив в PowerShell с Expand-Archive?
Для разархивирования ZIP файлов можно использовать командлет Expand—Archive.
Синтаксис командлета аналогичный:
Expand-Archive [-Path] String [-DestinationPath] String [-Force] [-Confirm]
Например, чтобы распаковать созданный нами ранее ZIP-архив в указанный каталог с перезаписью файлов, выполните:

Из недостатков модуля архивирования PowerShell стоит отметить:
Архивирование в PowerShell с помощью класса ZipFile
Чтобы заархивировать каталог, используйте такой скрипт:

Чтобы обновить ZIP архив и указать степень сжатия, используйте такой код PowerShell:
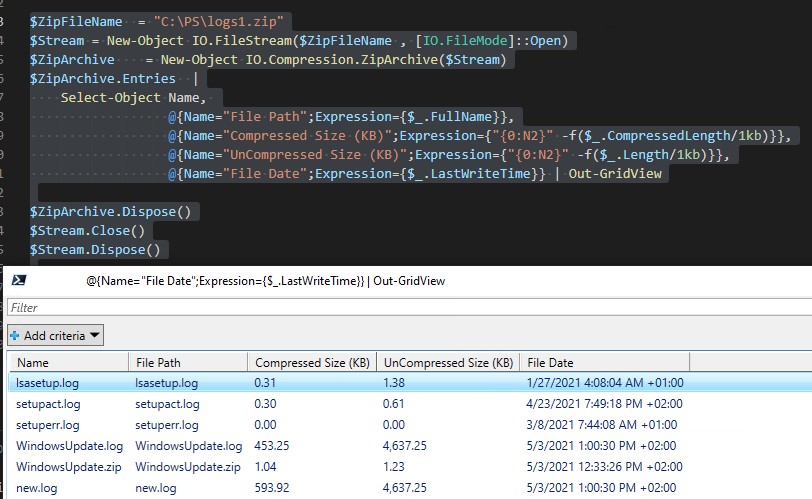
Можно вывести содержимое ZIP архива:

Или можно вывести содержимое zip архива в виде таблицы Out-GridView с указанием степени сжатия:
Для разархивирования ZIP архива в каталог C:\Logs, используйте следующие команды:
Как работает сжатие GZIP
 В жизни каждого мужчины наступает момент, когда трафик растёт и
В жизни каждого мужчины наступает момент, когда трафик растёт и сервак умирает необходимо задуматься об оптимизации. В последнем дайджесте PHP (№ 40) была упомянута ссылкой статья «How GZIP Compression Works». Исходя из статистики, 56% веб-сайтов используют GZIP. Я надеюсь, эта статья раскроет перед читателем достоинства этой технологии.
В тексте возможны ошибки (делал вычитку несколько раз, но всё же вдруг), поэтому заранее прошу прощения и прошу сообщать мне обо всех проблемах через личные сообщения, если какая-то часть перевода покажется вам некорректной.
Даже в современном мире, со скоростным интернет соединением и неограниченными хранилищами информации, сжатие данных по-прежнему актуально, особенно для мобильных устройств и стран с медленным интернет-соединением. Этот пост описывает метод де-факто сжатия без потерь для сжатия текстовых данных на веб-сайтах: GZIP.
GZIP compression
GZIP обеспечивает сжатие без потерь, иными словами, исходные данные можно полностью восстановить при распаковке. Он основан на алгоритме DEFLATE, который использует комбинацию алгоритма LZ77 и алгоритма Хаффмана.
Алгоритм LZ77
Алгоритм LZ77 заменяет повторные вхождения данных на «ссылки». Т.е. если в имеющихся данных какая-то цепочка элементов встречается более одного раза, то все последующие её вхождения заменяются «ссылками» на её первый экземпляр. Алгоритм прекрасно рассмотрен horror_x и описан здесь. Каждая такая ссылка имеет два значения: смещение и длина.
Давайте рассмотрим пример:
Original text: «ServerGrove, the PHP hosting company, provides hosting solutions for PHP projects» (81 bytes)
LZ77: «ServerGrove, the PHP hosting company, p ides solutions for jects» (73 bytes, assuming that each reference is 3 bytes)
Как вы могли заметить, слова «hosting» и «PHP» повторяются, поэтому во второй раз, когда подстрока найдена, она будет заменена ссылкой. Есть и другие совпадения, такие как «er», но т.к. это незначительно (в данном случае — «er» отсутствует в других словах), остается оригинальный текст.
Кодирование Хаффмана
Кодирование Хаффмана является методом кодирования с переменной длиной, которая назначает более короткие коды к более частым «символам». Проблема с переменной длиной кода, как правило в том, что нам нужен способ узнать, когда код закончился и начался новый, чтобы расшифровать его.
Кодирование Хаффмана решает эту проблему, создав код префикса, где ни одно кодовое слово не является префиксом другого. Это может быть более понятно на примере:
>Original text: «ServerGrove»
ASCII codification: «01010011 01100101 01110010 01110110 01100101 01110010 01000111 01110010 01101111 01110110 01100101» (88 bits)
ASCII представляет собой систему кодировки символов с фиксированной длиной, так что буква «е», которая повторяется три раза, а также является наиболее часто встречаемой буквой в английском языке, имеет такой же размер как буква «G», которая появляется только один раз. Используя эту статистическую информацию, Хаффман может создать наиболее оптимизированную систему
Huffman: «1110 00 01 10 00 01 1111 01 110 10 00» (27 bits)
Метод Хаффмана позволяет нам получить более короткие коды для «e», «r» и «v», в то время как «S» и «G» получаются более длинными. Объяснения, как использовать метод Хаффмана, выходят за рамки этого поста, но если вы заинтересовались, я рекомендую вам ознакомиться с отличным видео на Computerphile (или статьей на Хабре).
DEFLATE как алгоритм, который используется в GZIP сжатии, является комбинацией обоих этих алгоритмов.
Является ли GZIP лучшим метод сжатия?
Ответ — нет. Есть другие методы, которые дают более высокие показатели сжатия, но существует несколько хороших причин использовать этот.
Во-первых, даже при том что GZIP не самый лучший метод сжатия, он обеспечивает хороший компромисс между скоростью и степенью сжатия. Сжатие и распаковка у GZIP происходят быстро и степень сжатия на высоком уровне.
Во-вторых, нелегко внедрить новый глобальный метод сжатия данных, который смогут использовать все. Браузерам потребуется обновление, что на сегодняшний день гораздо проще за счёт автообновления. Как бы то ни было, браузеры — не единственная проблема. Chromium пытался добавить поддержку BZIP2, более лучшего метода основанного на преобразовании Барроуза-Уилера, но от него пришлось отказаться, т.к. некоторые промежуточные прокси-серверы искажали данные, т.к. не могли распознать заголовки bzip2 и пытались обработать gzip контент. Баг-репорт доступен здесь.
GZIP + HTTP
Процесс получения сжатого контента между клиентом (браузером) и сервером достаточно прост. Если у браузера есть поддержка GZIP/DEFLATE, он даёт серверу понять это благодаря заголовку “Accept-Encoding”. Тогда, сервер может выбрать — отправлять содержимое в сжатом или оригинальном виде.
Реализация
Спецификация DEFLATE обеспечивает некоторую свободу разработчикам реализовать алгоритм с использованием различных подходов, пока полученный поток совместим со спецификацией.
GNU GZIP
7-zip так же доступен для Windows и обеспечивает реализацию для других методов сжатия, таких как 7z, xz, bzip2, zip и прочих.
Zopfli
Zopfli идеально подходит для одноразового сжатия, например в ситуациях, когда файл единажды сжимается и многоразово используется. Он в 100 раз медленнее, но сжатие на 5% лучше, чем у других. Хабрапост.
Включение GZIP
Apache
AddOutputFilterByType DEFLATE text/plain
AddOutputFilterByType DEFLATE text/html
AddOutputFilterByType DEFLATE text/xml
AddOutputFilterByType DEFLATE text/css
AddOutputFilterByType DEFLATE application/xml
AddOutputFilterByType DEFLATE application/xhtml+xml
AddOutputFilterByType DEFLATE application/rss+xml
AddOutputFilterByType DEFLATE application/javascript
AddOutputFilterByType DEFLATE application/x-javascript
Существует несколько известных багов в некоторых версиях браузеров, поэтому рекомендуется* также добавить:
*это решение на текущий момент уже потеряло актуальность, как и вышеуказанные браузеры, поэтому данную информацию можно воспринимать в ознакомительных целях
Кроме того, можно использовать предварительно сжатые файлы вместо того, чтобы сжимать их каждый раз. Это особенно удобно для файлов, которые не меняются при каждом запросе, например CSS и JavaScript, которые могут быть сжаты с использованием медленных алгоритмов. Для этого:
Nginx
gzip on;
gzip_min_length 1000;
gzip_types text/plain application/xml;
Compress-Archive
Creates a compressed archive, or zipped file, from specified files and directories.
Syntax
Description
The Compress-Archive cmdlet creates a compressed, or zipped, archive file from one or more specified files or directories. An archive packages multiple files, with optional compression, into a single zipped file for easier distribution and storage. An archive file can be compressed by using the compression algorithm specified by the CompressionLevel parameter.
Some examples use splatting to reduce the line length of the code samples. For more information, see about_Splatting.
Examples
Example 1: Compress files to create an archive file
This example compresses files from different directories and creates an archive file. A wildcard is used to get all files with a particular file extension. There’s no directory structure in the archive file because the Path only specifies file names.
Example 2: Compress files using a LiteralPath
This example compresses specific named files and creates a new archive file. There’s no directory structure in the archive file because the Path only specifies file names.
Example 3: Compress a directory that includes the root directory
This example compresses a directory and creates an archive file that includes the root directory, and all its files and subdirectories. The archive file has a directory structure because the Path specifies a root directory.
Example 4: Compress a directory that excludes the root directory
This example compresses a directory and creates an archive file that excludes the root directory because the Path uses an asterisk ( * ) wildcard. The archive contains a directory structure that contains the root directory’s files and subdirectories.
Compress-Archive uses the Path parameter to specify the root directory, C:\Reference with an asterisk ( * ) wildcard. The DestinationPath parameter specifies the location for the archive file. The Draft.zip archive contains the root directory’s files and subdirectories. The Reference root directory is excluded from the archive.
Example 5: Compress only the files in a root directory
This example compresses only the files in a root directory and creates an archive file. There’s no directory structure in the archive because only files are compressed.
Compress-Archive uses the Path parameter to specify the root directory, C:\Reference with a star-dot-star ( *.* ) wildcard. The DestinationPath parameter specifies the location for the archive file. The Draft.zip archive only contains the Reference root directory’s files and the root directory is excluded.
Example 6: Use the pipeline to archive files
This example sends files down the pipeline to create an archive. There’s no directory structure in the archive file because the Path only specifies file names.
Example 7: Use the pipeline to archive a directory
This example sends a directory down the pipeline to create an archive. Files are sent as FileInfo objects and directories as DirectoryInfo objects. The archive’s directory structure doesn’t include the root directory, but its files and subdirectories are included in the archive.
Get-ChildItem uses the Path parameter to specify the C:\LogFiles root directory. Each FileInfo and DirectoryInfo object is sent down the pipeline.
Compress-Archive adds each object to the PipelineDir.zip archive. The Path parameter isn’t specified because the pipeline objects are received into parameter position 0.
Example 8: How recursion can affect archives
This example shows how recursion can duplicate files in your archive. For example, if you use Get-ChildItem with the Recurse parameter. As recursion processes, each FileInfo and DirectoryInfo object is sent down the pipeline and added to the archive.
The C:\TestLog directory doesn’t contain any files. It does contain a subdirectory named testsub that contains the testlog.txt file.
The following summary describes the PipelineRecurse.zip archive’s contents that contains a duplicate file:
Example 9: Update an existing archive file
The command updates Draft.Zip with newer versions of existing files in the C:\Reference directory and its subdirectories. And, new files that were added to C:\Reference or its subdirectories are included in the updated Draft.Zip archive.
Parameters
Specifies how much compression to apply when you’re creating the archive file. Faster compression requires less time to create the file, but can result in larger file sizes.
If this parameter isn’t specified, the command uses the default value, Optimal.
The following are the acceptable values for this parameter:
Prompts you for confirmation before running the cmdlet.
| Type: | SwitchParameter |
| Aliases: | cf |
| Position: | Named |
| Default value: | False |
| Accept pipeline input: | False |
| Accept wildcard characters: | False |
This parameter is required and specifies the path to the archive output file. The DestinationPath should include the name of the zipped file, and either the absolute or relative path to the zipped file.
| Type: | String |
| Position: | 1 |
| Default value: | None |
| Accept pipeline input: | False |
| Accept wildcard characters: | False |
Forces the command to run without asking for user confirmation.
| Type: | SwitchParameter |
| Position: | Named |
| Default value: | False |
| Accept pipeline input: | False |
| Accept wildcard characters: | False |
Specifies the path or paths to the files that you want to add to the archive zipped file. Unlike the Path parameter, the value of LiteralPath is used exactly as it’s typed. No characters are interpreted as wildcards. If the path includes escape characters, enclose each escape character in single quotation marks, to instruct PowerShell not to interpret any characters as escape sequences. To specify multiple paths, and include files in multiple locations in your output zipped file, use commas to separate the paths.
| Type: | String [ ] |
| Aliases: | PSPath |
| Position: | Named |
| Default value: | None |
| Accept pipeline input: | True |
| Accept wildcard characters: | False |
Causes the cmdlet to output a file object representing the archive file created.
This parameter was introduced in PowerShell 6.0.
| Type: | SwitchParameter |
| Position: | Named |
| Default value: | False |
| Accept pipeline input: | False |
| Accept wildcard characters: | False |
Specifies the path or paths to the files that you want to add to the archive zipped file. To specify multiple paths, and include files in multiple locations, use commas to separate the paths.
This parameter accepts wildcard characters. Wildcard characters allow you to add all files in a directory to your archive file.
Using wildcards with a root directory affects the archive’s contents:
Updates the specified archive by replacing older file versions in the archive with newer file versions that have the same names. You can also add this parameter to add files to an existing archive.
| Type: | SwitchParameter |
| Position: | Named |
| Default value: | False |
| Accept pipeline input: | False |
| Accept wildcard characters: | False |
Shows what would happen if the cmdlet runs. The cmdlet isn’t run.
| Type: | SwitchParameter |
| Aliases: | wi |
| Position: | Named |
| Default value: | False |
| Accept pipeline input: | False |
| Accept wildcard characters: | False |
Inputs
You can pipe a string that contains a path to one or more files.
Outputs
The cmdlet only returns a FileInfo object when you use the PassThru parameter.
Notes
Using recursion and sending objects down the pipeline can duplicate files in your archive. For example, if you use Get-ChildItem with the Recurse parameter, each FileInfo and DirectoryInfo object that’s sent down the pipeline is added to the archive.
The ZIP file specification does not specify a standard way of encoding filenames that contain non-ASCII characters. The Compress-Archive cmdlet uses UTF-8 encoding. Other ZIP archive tools may use a different encoding scheme. When extracting files with filenames not stored using UTF-8 encoding, Expand-Archive uses the raw value found in the archive. This can result in a filename that is different than the source filename stored in the archive.
Архивация и компрессия файлов. Часть 2
Многие файлы содержат сколь-нибудь повторяющуюся, лишнюю информацию. Поэтому технически возможно преобразовывать её так, чтобы уменьшить общий размер. Это и есть компрЕссия (compression, «компрЕшэн»), или сжатие, данных.
Шаблоны имён здесь раскрывает оболочка. Расширение имени здесь добавляется, а не заменяет исходное.
Понятие «степень сжатия» (compression ratio) толкуется по-разному: 1) «какую долю от размера исходного файла составляет размер сжатого файла» либо 2) «какую долю удалось убрать». Обычно выражается в процентах.
Вот вывод компрессором информации об архиве, в том числе степени сжатия в смысле (2):
compressed uncompressed ratio uncompressed_name
29806 102400 70.9% file3.txt
Нередко алгоритм допускает несколько степеней сжатия. По умолчанию программа обычно выбирает нечто среднее. За более сильное сжатие (меньше размер) приходится платить увеличенными временем упаковки и расходом оперативной памяти. Нередко выигрыш в степени сжатия оказывается незначителен. Скорость распаковки остаётся прежней.
Можно попробовать другой компрессор/формат, например bzip2 (Bzip2, «.bz2»):
Нет простого способа узнать, насколько сильным будет сжатие. Тексты часто сжимаются со степенью (1) ниже 50%. Хуже всего сжимаются хаотичные (случайные, шум) данные.
Для удобства можно считать, что для файлов средних размеров сжатие уместно, если степень (1) составляет 60% и ниже (то есть сэкономлено 40% места и больше). Если файл большой (1 ГиБ и выше), то даже небольшая экономия при сжатии может быть уместна. Уже сжатый файл обычно бесполезно сжимать ещё раз. Файлы размером ниже 3 КиБ сжимать тоже бесполезно.
Файлы /bin/bunzip2 и /bin/bzip2 идентичны
Чтобы задействовать содержимое оригинального (несжатого файла), обычно нужно явным способом распаковать сжатый. На это тратится процессорное время; в мобильном компьютере может быть повышенный расход заряда аккумулятора. Кроме того, степень сжатия непредсказуема или даже (1) выше 100%, поэтому при массовых правках файлов свободное место на диске может внезапно закончиться.
Чтобы задействовать содержимое оригинального (несжатого файла), обычно нужно явным способом распаковать сжатый. На это тратится процессорное время; в мобильном компьютере может быть повышенный расход заряда аккумулятора. Кроме того, степень сжатия непредсказуема или даже (1) выше 100%, поэтому при массовых правках файлов свободное место на диске может внезапно закончиться.
Есть несколько форматов файловых систем, где файлы сжимаются/распаковываются автоматически (говорят: «на лету» (on-the-fly) или «прозрачная (transparent) распаковка»).
Есть аналоги привычных утилит с именами, начинающимися на bz (для BZip2), xz или z (GZip): bzcat, bzless, bzgrep и другие. Делают то же, что оригиналы, но со сжатыми файлами.
# Архив tar внутри сжатого файла Gzip одной командой.
archive.tar.gz: gzip compressed data
# Архив tar внутри сжатого файла Bzip2 одной командой.
archive.tar.bz2: bzip2 compressed data, block size = 900k
# Архив tar внутри сжатого файла LZMA одной командой.
archive.tar.lzma: LZMA compressed data, streamed
# Примеры распаковки сжатых архивов одной командой:
Набор программ p7zip (в том числе 7z, 7za) является вариантом 7-Zip для командной строки UNIX и Linux. Формат 7z может давать более сильное сжатие, чем Gzip и Bzip2.
В Linux может быть проблема с форматом ZIP для файловых имён, содержащих не-латиницу. У ZIP есть свой внутренний формат хранения имён. Если создать архив в Windows, а потом попытаться распаковать в Linux, имена превратятся в наборы кракозябров. В последнее время дистрибутивы обычно поставляют исправленные программы unzip и zip. Или придётся пробовать перекодировать имена программой iconv или convmv.
Возможные (ненадёжно) варианты перекодировки имени (предполагаемый в примере файл сохранил расширение «.pdf» на латинице, поэтому файл можно как-то задействовать через шаблон оболочки):
# Или другой вариант:
# После каждого варианта просмотреть
# содержимое переменной N для перекодированного имени.
# И если имя выглядит разумно, то:
Программы для Windows часто поставляются в виде особых архивов, в том числе формата Microsoft Cabinet («.cab»). Такие архивы по лицензионным соглашениям запрещено распаковывать вручную. Для Linux есть программа cabextract.
Иногда в России встречаются старые форматы архивов с внутренней компрессией: ARJ, HA, LHA и другие. Для Linux могут найтись программы: arj, ha, unar. Иначе может понадобиться устанавливать FreeDOS/Wine или иную среду выполнения DOS/Windows-программ, а потом искать соответствующие декомпрессоры.
В некоторых форматах архивов и/или сжатых файлов предусмотрено шифрование с паролем: 7z, RAR, ZIP и другие.
Компрессия данных может встретиться и на системном уровне. Например, в некоторых файловых системах нулевые фрагменты (пустые блоки) внутри файлов не хранятся и не копируются (это называется «разреженные файлы», sparse files).
Программы для GUI: Archive Manager (File Roller) для GNOME, Ark для KDE, Engrampa для MATE, PeaZip, Xarchiver. Они отображают содержимое архивов, подобно тому как диспетчеры файлов отображают содержимое каталогов; предоставляют меню команд создания/распаковки архивов. Но сами не содержат программного кода архиваторов/компрессоров, поэтому требуют установки библиотек (libarchive, liblzma, unrar и других) и самих архиваторов/компрессоров для командной строки.
В файлах мультимедиа (изображения, звук, видео) часто применяют алгоритмы «несимметричного» сжатия, то есть с частичной потерей информации. Это позволяет сжать данные ещё сильнее (в десятки или больше раз). Некоторые потери в деталях изображений или в звуковых волнах уместны, если средний человек эти оттенки/детали/шумы и прочее не различает. Такие алгоритмы обычно имеют широкий набор настроек, поэтому нужно следить за тем, чтобы качество мультимедиа не стало плохим, явно заметным.

GNU/Linux
717 постов 13.3K подписчика
Правила сообщества
Все дистрибутивы хороши.
@balaev84av, ТС, добрый день.
Есть небольшой вопрос, очень надеюсь на Вашу помощь.
Система Альт Линукс. Сделал ярлык своего bash- файла. а система пишет что ярлык не доверенный, и не отображает его картинку. пусть и запускает.
как можно исправить это?
Вскользь упомянул о прозрачном сжатии на уровне ФС, а ведь это благодатнейшая тема.
Еще нет про squashfs. А это тоже годная весч.
LZMA заменён XZ, лучше про него и не вспоминать. Ну и сейчас команда lzma это алиас к xz, просто он включает автоматом первый (старый) формат.
Сравнивать на 100-а байтах бесполезно, хотябы мегабайт (у некоторых из блок 32к).
Еще не сказали о быстрых алгоритмах, lzo, lz4. Жмут они конечно слабее, но в разы быстрее.
ТС, вопрос на засыпку тебе: может ли такое быть, что содержимое файлов валидного zip-архива при разархивации 7-zip и через проводник Windows будет разным?
Архивация и компрессия файлов. Часть 1
(НЕ является руководством по резервному копированию. Во второй части используется тот же тестовый каталог с теми же файлами.)
Традиционные и/или стандартные сейчас либо ранее (в POSIX) программы-архиваторы: cpio, pax, tar. Менее известные: dar, star.
Примеры действий с архивами tar:
# Создать тестовый каталог с содержимым.
# Файл из случайно сгенерированных байтов.
$ dd if=/dev/urandom bs=1k count=100 of=works/old/file2.rnd
# Текстовый файл. Аргумент iflag=fullblock нужен,
# чтобы dd дождалась достаточного объёма данных от col,
# не завершаясь раньше этого.
| dd bs=1k count=100 iflag=fullblock \
# Вот итоговый вид поддерева works от программы tree.
# (Она не стандартная, устанавливают отдельно.)
Предполагается заархивировать старые файлы, т. е. в old/.
# Посмотреть свойства архива:
archive.tar: POSIX tar archive (GNU)
# Содержимое (список файлов).
# Освободить место, занятое старыми файлами.
# Извлечь содержимое архива.
# Сам архив останется прежним.
# Однобуквенные опции можно набрать слитно с общим дефисом.
Файлы извлекаются вместе с путями, так что каталог old со всем содержимым мог быть восстановлен в любом другом подходящем рабочем каталоге.
Архив можно пополнить. Пополнение архивов бывает «добавлением» (append) или «обновлением» (update).
$ mv today/file3.txt old/
# Всё равно этот файл состоял только из нулей.
# Здесь путь к файлу не выводится.
И ещё много разных опций, например:
Документация: man tar, info tar.
Благодаря сохранению метаданных, архиваторы иногда применяют для аккуратного копирования по конвейеру, например:
Следите за тем, чтобы правильно строить пути (чтобы, например, не получилось в итоге works/old/today/file3.txt вместо works/old/file3.txt). Для начала стоит запустить только find.
Формат tar имеет проблемы с хранением специальных файлов, со скоростью поиска файла в архиве, с хранением некоторых метаданных. Если это критично, то следует применять архиватор dar.
Шрифты в Linux
(НЕ является инструкцией по руссификации интерфейса.)
Файл шрифта (font file) содержит наборы изображений (рисунков) символов и соответствующие символам коды. Технически шрифты могут быть растровыми (bitmap fonts) или векторными (outline/vector fonts).
Пример того, как может выглядеть буква А в растровом шрифте с глифами размером 16×8 точек. Пустые/фоновые пикселы показаны символом
Основную графическую идею (стиль) шрифта называют «гарнитУрой» (typeface, или font face). Символы одной гарнитуры схожи примерно так же, как инструменты из одного набора или предметы посуды из одного сервиза.
Шрифты в текстовой консоли
CyrSlav-Fixed16.psf.gz: Linux/i386 PC Screen Font v1 data, 256 characters, Unicode directory, 8×16 (gzip compressed data, last modified: Wed Feb 1 12:35:37 2017, max compression, from Unix)
Вспомогательные программы для правки шрифтов: nafe ( https://sourceforge.net/projects/nafe/ ), psftools ( https://tset.de/psftools/index.html ), rw-psf ( https://github.com/talamus/rw-psf ). Они конвертируют символы в ascii-art (вроде вышеуказанного примера буквы А) или растровые изображения. После правки в текстовом или графическом редакторе можно конвертировать файл обратно в шрифт.
Применить настройки на текущей консоли:
Пакеты программ: kbd, console-setup. Документация: man-страницы console-setup, setfont, setupcon. В инсталляциях с systemd может быть файл настроек /etc/vconsole.conf и сервис systemd-vconsole-setup.service. Документация: man-страницы systemd-vconsole-setup.service, vconsole.conf.
Шрифты в графической консоли
Форматы шрифтов для GUI:
Portable Compiled Font (PCF, «.pcf» или сжатый «.pcf.gz»), растровый;
Bitmap Distribution Format (BDF, «.bdf» или сжатый «.bdf.gz»), растровый;
TrueType Font (TTF, «.ttf»), векторный;
OpenType Font (OTF, «.otf»), векторный;
Type 1 PostScript font ASCII (PFA, «.pfa»), векторный;
Type 1 PostScript font binary (PFB, «.pfb»), векторный;
и ещё несколько более редких.
NotoSans-Regular.ttf: TrueType font data
Графическая подсистема X Window System задействует шрифты сама или через библиотеки. X-программа (клиент сервера X Window) может запросить отрисовку шрифта по записи формата X Logical Font Description (XLFD). Запись состоит из 14 полей через дефисы. Пример:
Значения можно подбирать GUI-программой xfontsel. Кнопка select копирует запись в буфер X, откуда её можно вставить в редактор средней кнопкой мыши (колёсиком).
Настройки применения шрифтов в общем файле /etc/X11/xorg.conf:
# Прочие параметры этой секции.
В указанных каталогах следует запустить программы mkfontscale и mkfontdir. В результате должны появиться файлы encodings.dir, fonts.alias, fonts.dir.
Шрифт можно подключить временно, вручную:
xset +fp /usr/share/fonts/X11/misc
# Перечитать списки шрифтов.
К библиотеке прилагается семейство программ fc-*, в том числе:
# Показать установленные шрифты, имеющие символы русской кириллицы.
DejaVu Sans,DejaVu Sans Light
Nimbus Roman No9 L
NotoSans-Regular.ttf:0 Satisfy the coverage for ru language
NotoSans-Regular.ttf:0 Satisfy the coverage for en language
NotoKufiArabic-Regular.ttf:0 Missing 66 glyph(s) to satisfy the coverage for ru language
NotoKufiArabic-Regular.ttf:0 Missing 72 glyph(s) to satisfy the coverage for en language
NotoKufiArabic-Regular.ttf:0 Satisfy the coverage for ar language
То есть в основном файле есть символы для русского, английского языков; в файле для арабского языка есть только арабица.
Каталоги для хранения шрифтов: общий /usr/share/fonts/, пользовательский
/.fonts/). В fonts.conf можно указать другие.
Желательно иметь в GUI: пропорциональные шрифты с засечками и без них (для большинства виджетов), моноширинный шрифт (для эмулятора терминала), шрифт со вспомогательными символами (для офисного текстового процессора).
Семейства свободно доступных шрифтов, которые считают приятными для глаз: Cantarell, Droid, Noto, Ubuntu. Шрифты со вспомогательными символами: OpenSymbol, Symbola; или Dingbats и Wingdings из Windows.
Для установки шрифта, поддерживаемого Fontconfig, нужно скопировать его файлы в один из каталогов хранения (можно во вложенный каталог). Желательно правильно установить целевые права, например 444 для файлов и 555 для каталогов. Потом запустить fc-cache (может сработать автоматически).
Для офисных документов популярны семейства шрифты из Windows: Arial, Courier New, Times и другие (форматы TTF, OTF).
Их можно скопировать из инсталляции Windows (каталог Windows\Fonts\).
В дистрибутивах могут быть пакеты, копирующие файлы шрифтов из Интернета. Помещать сами эти шрифты в пакет запрещено лицензионным соглашением.
Можно скопировать их из Интернета самостоятельно и распаковать программой cabextract. Ищите в репозиториях сервиса SourceForge.net по выражению «Microsoft core fonts».
Для подстановки можно применять шрифты семейства Liberation (соответственно Sans, Mono, Serif). Они, насколько возможно, «метрически совместимы» (metrically compatible) со шрифтами из Windows, то есть глифы сходных размеров. Другие метрически совместимые шрифты:
семейство Croscore (соответственно Arimo, Cousine, Tinos);
[Astra] Sans, [Astra] Serif и Mono от фирмы Paratype;
семейство XO Fonts (Oriel, Courser, Thames, символьные шрифты Symbol и Windy).
В графической подсистеме X Window System растеризацией занимается своя библиотека Xft. В последние годы операции растеризации передаются внешним библиотекам: Cairo, FreeType, Pango. Графическая подсистема Wayland сама никак не взаимодействует со шрифтами, все программы обращаются к внешним библиотекам.
В шрифтах TrueType могут быть дополнительные встроенные данные (hints) по отрисовке; их применение называется «хИнтинг» (hinting). В библиотеке FreeType наилучший алгоритм отрисовки (TrueType Bytecode Interpreter) был запрещён патентами примерно до 2010 года/версии 2.4.



