Понимание джойнов сломано. Это точно не пересечение кругов, честно
Так получилось, что я провожу довольно много собеседований на должность веб-программиста. Один из обязательных вопросов, который я задаю — это чем отличается INNER JOIN от LEFT JOIN.
Чаще всего ответ примерно такой: «inner join — это как бы пересечение множеств, т.е. остается только то, что есть в обеих таблицах, а left join — это когда левая таблица остается без изменений, а от правой добавляется пересечение множеств. Для всех остальных строк добавляется null». Еще, бывает, рисуют пересекающиеся круги.
Я так устал от этих ответов с пересечениями множеств и кругов, что даже перестал поправлять людей.
Дело в том, что этот ответ в общем случае неверен. Ну или, как минимум, не точен.
Давайте рассмотрим почему, и заодно затронем еще парочку тонкостей join-ов.
Во-первых, таблица — это вообще не множество. По математическому определению, во множестве все элементы уникальны, не повторяются, а в таблицах в общем случае это вообще-то не так. Вторая беда, что термин «пересечение» только путает.
(Update. В комментах идут жаркие споры о теории множеств и уникальности. Очень интересно, много нового узнал, спасибо)
INNER JOIN
Давайте сразу пример.
Итак, создадим две одинаковых таблицы с одной колонкой id, в каждой из этих таблиц пусть будет по две строки со значением 1 и еще что-нибудь.
Давайте, их, что ли, поджойним
Если бы это было «пересечение множеств», или хотя бы «пересечение таблиц», то мы бы увидели две строки с единицами.

На практике ответ будет такой:
Для начала рассмотрим, что такое CROSS JOIN. Вдруг кто-то не в курсе.
CROSS JOIN — это просто все возможные комбинации соединения строк двух таблиц. Например, есть две таблицы, в одной из них 3 строки, в другой — 2:
Тогда CROSS JOIN будет порождать 6 строк.
Так вот, вернемся к нашим баранам.
Конструкция
— это, можно сказать, всего лишь синтаксический сахар к
Небольшой disclaimer: хотя inner join логически эквивалентен cross join с фильтром, это не значит, что база будет делать именно так, в тупую: генерить все комбинации и фильтровать. На самом деле там более интересные алгоритмы.
LEFT JOIN
Если вы считаете, что левая таблица всегда остается неизменной, а к ней присоединяется или значение из правой таблицы или null, то это в общем случае не так, а именно в случае когда есть повторы данных.
Опять же, создадим две таблицы:
Теперь сделаем LEFT JOIN:
Результат будет содержать 5 строк, а не по количеству строк в левой таблице, как думают очень многие.
Так что, LEFT JOIN — это тоже самое что и INNER JOIN (т.е. все комбинации соединений строк, отфильтрованных по какому-то условию), и плюс еще записи из левой таблицы, для которых в правой по этому фильтру ничего не совпало.
LEFT JOIN можно переформулировать так:
Сложноватое объяснение, но что поделать, зато оно правдивее, чем круги с пересечениями и т.д.
Условие ON
Удивительно, но по моим ощущениям 99% разработчиков считают, что в условии ON должен быть id из одной таблицы и id из второй. На самом деле там любое булево выражение.
Например, есть таблица со статистикой юзеров users_stats, и таблица с ip адресами городов.
Тогда к статистике можно прибавить город
где && — оператор пересечения (см. расширение посгреса ip4r)
Если в условии ON поставить true, то это будет полный аналог CROSS JOIN
Производительность
Есть люди, которые боятся join-ов как огня. Потому что «они тормозят». Знаю таких, где есть полный запрет join-ов по проекту. Т.е. люди скачивают две-три таблицы себе в код и джойнят вручную в каком-нибудь php.
Это, прямо скажем, странно.
Если джойнов немного, и правильно сделаны индексы, то всё будет работать быстро. Проблемы будут возникать скорее всего лишь тогда, когда у вас таблиц будет с десяток в одном запросе. Дело в том, что планировщику нужно определить, в какой последовательности осуществлять джойны, как выгоднее это сделать.
Сложность этой задачи O(n!), где n — количество объединяемых таблиц. Поэтому для большого количества таблиц, потратив некоторое время на поиски оптимальной последовательности, планировщик прекращает эти поиски и делает такой план, какой успел придумать. В этом случае иногда бывает выгодно вынести часть запроса в подзапрос CTE; например, если вы точно знаете, что, поджойнив две таблицы, мы получим очень мало записей, и остальные джойны будут стоить копейки.
Кстати, Еще маленький совет по производительности. Если нужно просто найти элементы в таблице, которых нет в другой таблице, то лучше использовать не ‘LEFT JOIN… WHERE… IS NULL’, а конструкцию EXISTS. Это и читабельнее, и быстрее.
Выводы
Как мне кажется, не стоит использовать диаграммы Венна для объяснения джойнов. Также, похоже, нужно избегать термина «пересечение».
Как объяснить на картинке джойны корректно, я, честно говоря, не представляю. Если вы знаете — расскажите, плиз, и киньте в коменты. А мы обсудим это в одном из ближайших выпусков подкаста «Цинковый прод». Не забудьте подписаться.
Russian (Pусский) translation by Yuri Yuriev (you can also view the original English article)
Сегодня мы продолжаем наше путешествие в мир SQL и связанных баз данных. В третьей части этой серии мы узнаем, как работать с несколькими таблицами, которые имеют отношения друг с другом. Во-первых, мы рассмотрим некоторые базовые концепции, а затем начнем работать с JOIN queries в SQL.
Вы также можете увидеть базы данных SQL в действии, просмотрев SQL scripts, apps and add-ons на рынке Envato.
Напоминание
Введение
При создании базы данных здравый смысл подсказывает, что мы используем отдельные таблицы для разных типов сущностей. Например: клиенты, заказы, предметы, сообщения. Но нам также нужно иметь отношения между этими таблицами. Например, клиенты делают заказы, а заказы содержат предметы. Эти отношения должны быть представлены в базе данных. Кроме того, при получении данных с помощью SQL нам нужно использовать определённые типы запросов JOIN, чтобы получить то, что нам нужно.
Существует несколько типов отношений базы данных. Сегодня мы рассмотрим следующее:
При выборе данных из нескольких таблиц с отношениями мы будем использовать запрос JOIN. Существует несколько типов JOIN, и мы собираемся узнать следующее:
Мы также узнаем об оговорках ON и USING.
Отношения один к одному
Предположим, у вас есть таблица для клиентов:


Мы можем поместить информацию об адресе клиента в отдельную таблицу:


Теперь мы имеем отношение между таблицей Customers и таблицей Addresses. Если каждый адрес может принадлежать только одному клиенту, это отношение «Один к одному». Имейте в виду, что такого рода отношения не очень распространены. Наша начальная таблица, которая включала адрес вместе с клиентом, в большинстве случаев могла работать нормально.
Обратите внимание: теперь в таблице Customers есть поле с именем «address_id», которое ссылается на запись соответствия в таблице Address. Это называется «Foreign Key» и используется для всех видов отношений баз данных. Мы рассмотрим этот вопрос позже.
Мы можем показать отношения между клиентскими и адресными записями следующим образом:


Обратите внимание, что существование отношений может быть необязательным, например, есть запись клиента, у которой нет связанной записи адреса.
Отношения «один ко многим» и «многие к одному»
Это наиболее часто используемый тип отношений. Рассмотрим веб-сайт e-commerce со следующим:
В этих случаях нам необходимо создать отношения «один ко многим». Вот пример:

У каждого клиента может быть ноль, один или несколько заказов. Но заказ может принадлежать только одному клиенту.


Отношения «многие ко многим»
В некоторых случаях вам может потребоваться несколько экземпляров с обеих сторон. Например, каждый заказ может содержать несколько элементов. И каждый элемент также может быть в нескольких заказах.
Для этих отношений нам нужно создать дополнительную таблицу:


Таблица Items_Orders имеет только одну цель, а именно, чтобы создать отношение «многие ко многим» между элементами и заказами.
Вот картинка таких отношений:


Если вы хотите включить записи items_orders в график, это может выглядеть так:


Самостоятельные ссылки
Это используется, когда таблица должна иметь отношения с самой собой. Например, у вас есть реферальная программа. Клиенты могут направлять других клиентов на ваш веб-сайт. Таблица может выглядеть так:


Клиенты 102 и 103 были переданы клиентом 101.
На самом деле это может быть похоже на отношение «один ко многим», поскольку один клиент может ссылаться на нескольких клиентов. Также он может выглядеть, как древовидная структура:


Один клиент может ссылаться на ноль, одного или несколько клиентов. К каждому клиенту может обращаться только один клиент, или вообще никто.
Если вы хотите создать самостоятельную ссылку «многие ко многим», вам понадобится дополнительная таблица, вроде той, что мы говорили в предыдущем разделе.
Foreign Keys
До сих пор мы узнали только о некоторых концепциях. Теперь пришло время воплотить их в жизнь с помощью SQL. Для этой части нам нужно понять, что такое Foreign Keys.
В приведённых выше примерах отношений мы всегда имели эти поля «**** _ id», которые ссылались на столбец в другой таблице. В этом примере столбец customer_id в таблице Orders является столбцом Foreign Key:
В базе данных типа MySQL есть два способа создания столбцов внешних ключей:
Чёткое определение Foreign Key
Давайте создадим простую таблицу клиентов:
Теперь таблицу заказов, в которой будет Foreign Key:
Оба столбца (customers.customer_id и orders.customer_id) должны иметь одинаковую структуру данных. Если один является INT, другой не должен быть BIGINT, например.
Обратите внимание, что в MySQL только механизм InnoDB имеет полную поддержку Foreign Keys. Но другие механизмы хранения данных по-прежнему позволят вам указывать их без каких-либо ошибок. Кроме того, столбец Foreign Key индексируется автоматически, если не указать для него другой индекс.
Без явной декларации
Та же таблица заказов может быть создана без явного объявления столбца customer_id как Foreign Key:
Далее мы собираемся узнать о JOIN-запросах.
Визуализация отношений
Моим любимым программным обеспечением для проектирования баз данных и визуализации отношений Foreign Key является MySQL Workbench.


После разработки базы данных вы можете экспортировать SQL и запустить его на своем сервере. Это очень удобно для больших и сложных баз данных.


JOIN Queries
Для извлечения данных из базы, имеющей отношения, нам часто приходится использовать JOIN queries.
Прежде чем начать, давайте создадим таблицы и некоторые образцы данных для работы.
У нас 4 клиента. У одного клиента два заказа, у двух клиентов по одному заказу, а у одного клиента нет заказа. Теперь давайте посмотрим различные виды JOIN queries, которые мы можем запустить в этих таблицах.
Перекрестное соединение
Это тип JOIN query по умолчанию, если условие не указано.


Результатом является так называемый «Cartesian product» таблиц. Это означает, что каждая строка из первой таблицы сопоставляется с каждой строкой второй таблицы. Так как каждая таблица имела 4 строки, мы получили результат из 16 строк.
Ключевое слово JOIN может быть опционально заменено запятой.


Конечно, такой результат не очень полезен. Давайте посмотрим на другие типы соединений.
Обычное соединение
При таком типе JOIN query таблицы должны иметь имя соответствующего столбца. В нашем случае обе таблицы имеют столбец customer_id. Таким образом, MySQL будет присоединяться к записям только тогда, когда значение этого столбца соответствует двум записям.


Внутреннее соединение
Когда указано условие соединения, выполняется Inner Join. В этом случае было бы неплохо иметь поле customer_id в обеих таблицах. Результаты должны быть похожими на Natural Join.


Результаты те же, за исключением небольшой разницы. Столбец customer_id повторяется дважды, один раз для каждой таблицы. Причина в том, что мы просто попросили базу данных соответствовать значениям этих двух столбцов. Но сами они не знают, что представляют одну и ту же информацию.
Давайте добавим еще несколько условий в запрос.


ON Clause
Прежде чем перейти к другим типам соединений, нам нужно посмотреть ON clause. Это полезно для помещения условий JOIN в отдельное предложение.


Теперь мы можем отличить условие JOIN от условий WHERE. Но есть и небольшая разница в функциональности. Мы увидим это в примерах LEFT JOIN.
USING Clause
USING clause похоже на предложение ON, но оно короче. Если столбец имеет одинаковое имя в обеих таблицах, мы можем указать его здесь.


На самом деле это похоже на NATURAL JOIN, поэтому столбец join (customer_id) не повторяется дважды в результатах.
Левое (внешнее) соединение


Хотя у Энди нет заказов, его запись все ещё отображается. Значения под столбцами второй таблицы имеют значение NULL.
Это полезно для поиска записей, которые не имеют отношений. Например, мы можем искать клиентов, которые не разместили какие-либо заказы.


Всё, что мы сделали, это нашли NULL для order_id.
Также обратите внимание, что ключевое слово OUTER является необязательным. Вы можете просто использовать LEFT JOIN вместо LEFT OUTER JOIN.
Условия
Теперь давайте рассмотрим запрос с условием.


Так что случилось с Энди и Сэнди? LEFT JOIN должен был вернуть клиентов без соответствующих заказов. Проблема в том, что предложение WHERE блокирует эти результаты. Чтобы их получить, мы можем попытаться включить условие NULL.


У нас Энди, но нет Сэнди. Тем не менее это выглядит не так. Чтобы получить то, что мы хотим, нам нужно использовать ON clause.


Правое (внешнее) соединение
RIGHT OUTER JOIN работает точно так же, но порядок таблиц обратный.


На этот раз у нас нет результатов NULL, потому что каждый заказ имеет соответствующую запись клиента. Мы можем изменить порядок таблиц и получить те же результаты, что и в LEFT OUTER JOIN.


Теперь у нас есть эти значения NULL, потому что таблица Customers находится на правой стороне соединения.
Заключение
Спасибо, что прочитали статью. Надеюсь, вам понравилось! Пожалуйста, оставляйте свои комментарии и вопросы, и хорошего дня!
Не забудьте проверить SQL scripts, apps and add-ons на рынке Envato. Вы получите представление о возможностях баз данных SQL, и сможете найти идеальное решение, которое поможет вам в текущем проекте разработки.
Следуйте за нами на Twitter или подпишитесь на Nettuts + RSS Feed для получения лучших обучающих материалов по веб-разработке в Интернете.
Объяснение SQL объединений JOIN: LEFT/RIGHT/INNER/OUTER
Разберем пример. Имеем две таблицы: пользователи и отделы.
В результате отсутствуют:
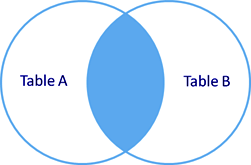
Внутреннее объединение INNER JOIN (синоним JOIN, ключевое слово INNER можно опустить).
Выбираются только совпадающие данные из объединяемых таблиц.
Чтобы получить данные, которые подходят по условию частично, необходимо использовать
Такое объединение вернет данные из обеих таблиц (совпадающие по условию объединения) ПЛЮС дополнит выборку оставшимися данными из внешней таблицы, которые по условию не подходят, заполнив недостающие данные значением NULL.
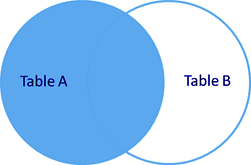
Получаем полный список пользователей и сопоставленные департаменты.
в выборке останется только 3#Александр, так как у него не назначен департамент.
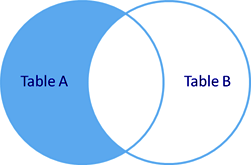
рис. Left outer join с фильтрацией по полю
RIGHT OUTER JOIN вернет полный список департаментов (правая таблица) и сопоставленных пользователей.
Дополнительно можно отфильтровать данные, проверяя их на NULL.
В нашем примере указав WHERE u.id IS null, мы выберем департаменты, в которых не числятся пользователи. (3#Финансы)
Все примеры вы можете протестировать здесь:
Cross/Full Join
FULL JOIN возвращает `объединение` объединений LEFT и RIGHT таблиц, комбинируя результат двух запросов.
CROSS JOIN возвращает перекрестное (декартово) объединение двух таблиц. Результатом будет выборка всех записей первой таблицы объединенная с каждой строкой второй таблицы. Важным моментом является то, что для кросса не нужно указывать условие объединения.
Дублирование строк при использовании JOIN
При использовании объединения новички часто забывают что результирующая выборка может содержать дублирующиеся данные!
Если вам нужна одна запись, делайте объединение с подзапросом
Self Join
Выборка из одной и той же таблицы для нескольких условий.
Рассмотрим задачку от яндекса:
Есть таблица товаров.
Она содержит следующие значения.
Напишите запрос, выбирающий уникальные пары `id` товаров с одинаковыми `name`, например:
При решении задачи необходимо учесть, что пары (x,y) и (y,x) — одинаковы.
— или без группировки (быстрее)
Объединяем таблицы ya_goods по одинаковому полю `name`, группируем по уникальным idентификаторам и получаем результат.
Множественное объединение multi join
Пригодится нам, если необходимо выбрать более одного значения из таблиц для нескольких условий.
Пример: выбрать товары,
добавленные после 17/01/2009 в следующих вариантах:
— вес=310, объем=300
— вес=35, объем=15
— вес=45, объем=25
— вес=200, объем=250
INNER JOIN product2options p2o1 ON p.id = p2o1.product_id
INNER JOIN product_options po1 ON po1.id = p2o1.option_id
INNER JOIN product2options p2o2 ON p.id = p2o2.product_id
INNER JOIN product_options po2 ON po2.id = p2o2.option_id
id title created_at P1 value P2 value
2 Ложка 2009-01-18 20:00:00 Вес 35 Объем 15
3 Тарелка 2009-01-19 20:00:00 Вес 310 Объем 300
2 Ложка 2009-01-18 20:00:00 Вес 45 Объем 25
— не попадает по дате
1 Кружка 2009-01-17 20:00:00 Объем 250 Вес 200
UPDATE и JOIN
Объединение можно использовать совместно с UPDATE.
Например, имеем таблицу houses (id, title, area). Нужно выбрать title, если в нем встречается `число м2`, заменить поле area, если оно меньше. Т.к. в mysql отстутсутствует поддержка регулярных выражений, нужно немного поколдовать с locate и substr.
В подзапросе выбираем интересующие нас данные, и в финальной стадии осуществляем обновление данных подходящий по критерию (p5 > area).
FROM ga_pageviews
WHERE title like ‘ % м2 % ‘
) calc USING ( `id` )
SET base. area = calc.p5
WHERE base. area calc.p5
DELETE и JOIN
Рассмотрим пример с удалением дубликатов. Есть таблица tableWithDups (id, email). Нужно удалить строки с одинаковыми email:
Последние два примера не совместимы с ANSI SQL, но работают в mySQL.
За бортом статьи остались смежные объединениям (а также специфичные для определенных базданных темы):
SELF JOIN, FULL OUTER JOIN, CROSS JOIN (CROSS [OUTER] APPLY), операции над множествами UNION [ALL], INTERSECT, EXCEPT и т.д.
@tags: sql, mysql, sql server, oracle, sqlite, postgresql



