committed information rate
гарантированная скорость
Минимальная пропускная способность, гарантируемая для каждого PVC и SVC. CIR обычно составляет половину скорости порта в коммутаторе frame relay. Если сеть не занята, данные могут передаваться с использованием полной скорости порта без дополнительной оплаты.
[http://www.lexikon.ru/dict/net/index.html]
Тематики
гарантированная скорость передачи данных
Это скорость передачи информации, которую сеть обязуется поддерживать для передачи данных при нормальных условиях по конкретному виртуальному каналу. Значения этого параметра могут быть различными для разных направлений передачи. (МСЭ-Т Х.7, МСЭ-Т Х.76, МСЭ-Т Х.84, МСЭ-Т Х.144, МСЭ-Т Х.145, МСЭ-Т Х.147, МСЭ-Т Х.148, МСЭ-Т Х.151).
[http://www.iks-media.ru/glossary/index.html?glossid=2400324]
Тематики
Смотреть что такое «committed information rate» в других словарях:
Committed information rate — or CIR in a Frame relay network is the average bandwidth for a virtual circuit guaranteed by an ISP to work under normal conditions. At any given time, the bandwidth should not fall below this committed figure. The bandwidth is usually expressed… … Wikipedia
Committed Information Rate — or CIR in a Frame relay network is the average bandwidth for a virtual circuit guaranteed by an ISP to work under normal conditions. At any given time the bandwidth should not fall below this committed figure. It is usually expressed in kilobits… … Wikipedia
committed information rate — (CIR) The guaranteed theshold that will be maintained by the frame relay service provider when data is being sent over the carrier s network … IT glossary of terms, acronyms and abbreviations
Peak information rate — is a burstable rate set on routers and/or switches that allows throughput overhead. Related to Committed Information Rate which is a committed rate speed guaranteed/capped. For example, a CIR of 10 Mbit/s PIR of 12 Mbit/s allows you access to 10… … Wikipedia
Peak Information Rate — The Peak Information Rate is a Burstable Rate Set on Routers and/or Switches that allow Throughput Overhead. Related to Committed Information Rate which is a Committed Rate Speed Guaranteed/Capped. Ex: CIR of 10 Mbit/s PIR of 12 Mbit/s. Allowing… … Wikipedia
European Public Hearing on Crimes Committed by Totalitarian Regimes — Crimes Committed by Totalitarian Regimes are reports and proceedings of the European public hearing organised by the Slovenian Presidency [1] of the Council of the European Union (January–June 2008) and the European Commission.[2] The Hearing was … Wikipedia
Indian Institutes of Information Technology — IIIT is the generic name for several Institutes of Information Technology in India, each a mini university in itself. Many of these institutions have been subsequently renamed to better identify their affiliations and goals. The IIITs were… … Wikipedia
CIR — Committed Information Rate (Computing » Networking) Committed Information Rate (Computing » Telecom) Committed Information Rate (Computing » General) Commissioner Of Internal Revenue (Governmental » US Government) ** Cosmetic Ingredient Review… … Abbreviations dictionary
CIR — • Committed Information Rate (u.a. ATM) • Cargo Integration Review NASA • Cairo, IL, USA internationale Flughafen Kennung • Cir Circinus Dividers Zirkel Sternbild in der südl. Halbkugel Astronomie … Acronyms
Frame relay — In the context of computer networking, frame relay consists of an efficient data transmission technique used to send digital information. It is a message forwarding relay race like system in which data packets, called frames, are passed from one… … Wikipedia
Frame relay — У этого термина существуют и другие значения, см. Fr. Frame relay (англ. «ретрансляция кадров», FR) протокол канального уровня сетевой модели OSI. Служба коммутации пакетов Frame Relay в настоящее время широко распространена во всём… … Википедия
Качество обслуживания (QoS)
Контроль полосы пропускания

Основным средством, используемым для ограничения трафика, является хорошо известный алгоритм «корзина маркеров» (token bucket). Этот алгоритм предполагает наличие следующих параметров:
Размер стандартной корзины маркеров (максимальное число маркеров, которое она может вместить) равен согласованному размеру всплеска ( CBS ). Маркеры генерируются и помещаются в корзину с определенной скоростью ( CIR ). Если корзина полна, то поступающие избыточные маркеры отбрасываются. Для того чтобы передать пакет из корзины вынимается число маркеров, равное размеру пакета в битах. Если маркеров в корзине достаточно, то пакет передается. Если размер пакета оказался больше, чем маркеров в корзине, то маркеры из корзины не извлекаются, а пакет рассматривается как не удовлетворяющий (non-conform) заданному профилю или избыточный. Для избыточных пакетов могут применяться различные способы обработки: они могут отбрасываться или перемаркировываться.

Стандартная корзина маркеров не поддерживает экстренное увеличение размера всплеска, поэтому в такой реализации расширенный размер всплеска ( EBS ) равен согласованному размеру всплеска ( CBS ).
В корзине маркеров с возможностью экстренного увеличения размера всплеска расширенный размер всплеска ( EBS ) больше согласованного размера всплеска ( CBS ). Объем трафика (в битах), на который может быть превышен размер корзины, рассчитывается по формуле:
При такой реализации корзины маркеров, в случае нехватки маркеров, необходимых для передачи пакета, учитывается расширенный размер всплеска.
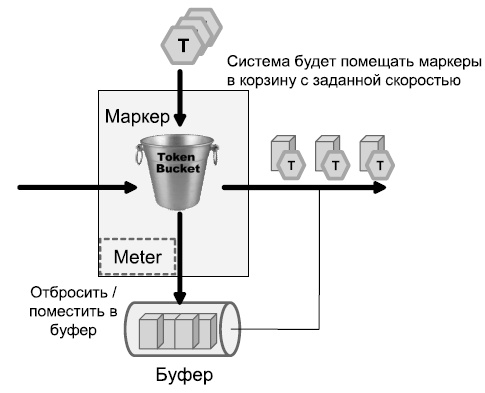
В качестве средства выравнивания трафика механизм Traffic Shaping также использует алгоритм » корзина маркеров». В соответствии с механизмом Traffic Shaping из корзины вынимается число маркеров, равное размеру пакета в битах. Если в корзине имелось достаточное количество маркеров, то пакет передается. В противном случае пакет маркируется как неудовлетворяющий заданному профилю и ставится в очередь (буферизируется) для последующей передачи. Как только в корзине накопится количество маркеров, достаточное для передачи пакета, он будет передан.
В качестве примера приведем настройку ограничения скорости до 128 Кбит/с для трафика, передаваемого с интерфейса 5 коммутатора.
Пример настройки QoS
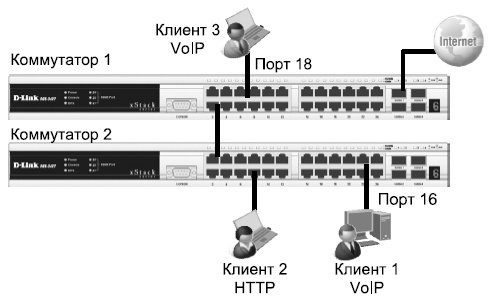
Настройка коммутатора 1
Настройка коммутатора 2
Карта привязки приоритетов 802.1р к очередям и механизм обслуживания очередей не изменяются и используют параметры, настроенные по умолчанию.
Базовые принципы полисеров и шейперов
Одними из инструментов обеспечения качества обслуживания в сетях передачи данных являются механизмы полисинга и шейпинга и, может быть, это самые часто используемые инструменты. Ваш Интернет провайдер, наверняка, ограничил вам скорость именно этим.
Тема качества обслуживания не самая простая для понимания, а если вы когда-нибудь интересовались именно полисерами и шейперами, то скорее всего встречали однотипные графики, отображающие зависимость скорости от времени, слышали термины «корзина», «токены» и «burst», может быть даже видели формулы для расчёта каких-то параметров. Хороший и типичный пример есть в СДСМ — глава про QoS и ограничение скорости.
В этой статье попробуем зайти чуть с другой стороны, опираясь на учебник Cisco, RFC 2697 и RFC 2698 — самые базовые понятия.
Первое в чём надо разобраться и на чём строится весь механизм управления скоростью — это понятие самой скорости. Скорость — величина производная, вычисляемая, нигде и ни в каком месте мы не видим её напрямую. Устройства оперируют только данными и их количеством. Про скорость мы говорим в контексте наблюдения и мониторинга, зная объём переданных данных за 5 минут или за 5 секунд и получая разные значения средней скорости.
Второе, количество данных пропускаемое интерфейсом за отрезок времени — константа, абсолют. Его нельзя ни уменьшить ни увеличить. Через 100Мбит/c интерфейс 90Мбит будут пропущены всегда за 0,9 секунды, а оставшуюся 0,1 секунду интерфейс будет простаивать. Но с учётом того что скорость вычисляемое значение, получим что данные были переданы со средней скоростью 90Мбит/c. Это мало похоже на дорожный трафик, у нас всегда либо 100% загруженность, либо полный простой. В контексте сетевого трафика, загруженность интерфейса — это сколько свободных промежутков времени у него остаётся из общего измеряемого интервала. Дальше продолжим употреблять размерность Мбит и секунды, для лучшего понимания, хотя это и не имеет никакого значения.
Отсюда вытекает основная задача и способ ограничения пропуска трафика — передать не больше заданного количества данных за единицу времени. Если у нас есть 100Мбит, а мы хотим ограничить скорость 50Мбит/c, то за эту секунду нам надо передать не больше 50Мбит, а оставшиеся данные передать в следующую секунду. При этом у нас есть только один способ это сделать — включить интерфейс, который всегда работает с постоянной скоростью, или выключить его. Выбор только в том, как часто мы будем включать и выключать.
Burst
Посмотрим на график скорости из учебника 5 класса по физике. Здесь показана зависимость объёма переданных данных по оси Y, от времени по оси X. Чем круче наклон прямой, тем больше скорость. Передать 50Мбит за секунду можно разными способами:

В случае burst=25, получим 25/50 или 0,5 секунды между передачей каждых 25Мбит. С учётом скорости интерфейса на передачу 25Мбит будет затрачено 25/100=0,25 секунды и следующие 0,25 секунды интерфейс будет простаивать. В каждом случае мы 1/2 = CIR / Interface rate времени тратим на передачу и 1/2 на простой. Если увеличить CIR до 75Мбит/c, то соответственно 75/100=3/4 периода займёт передача и 1/4 пауза.
Обратите внимание что наклон прямых, показывающих объём переданных данных, всегда одинаков. Потому что скорость интерфейса константа (синие точки) и мы физически не можем передавать с другой скоростью.
В большинстве случаев при конфигурации оборудования используются именно burst, хотя могут использоваться и временные интервалы. На графике хорошо видны отличия, меньший burst даёт более строгое следование заданному ограничению — график не убегает далеко от СIR, даже на меньшем измеряемом промежутке и при этом обеспечивает короткие паузы между моментами передачи. А больший burst не ограничивает трафик на коротких отрезках. Если измерять скорость только за первые 0,5 секунды, то получилось бы 50/0,5 = 100Мбит/c. А долгая пауза после такой передачи может негативно сказаться на механизмах управления трафиком за границами нашего устройства, или привести к потере логического соединения.
Если быть ближе к реальности, сетевой трафик, как правило, не передаётся непрерывно, а имеет разную интенсивность в разные моменты времени (зелёный пунктир):
На этом графике видно, что за 1 секунду мы хотим передать 55Мбит при ограничении 50Мбит. То есть, реальный трафик практически не выходит за границы которые мы установили к концу измеряемого интервала. При этом механизмы ограничения приводят к тому, что передаётся меньший объём данных чем мы ожидаем. И здесь больший burst выглядит лучше, так как захватываются интервалы где трафик действительно передаётся, а меньший burst и желание строго ограничивать трафик на всём участке, выливается в большие потери.
Шейпер
Будем ещё ближе к реальности, в которой всегда имеется буфер для передачи данных. С учётом того что интерфейс у нас или занят на 100% или простаивает, а данные могут поступать одновременно из нескольких источников быстрее чем интерфейс может их передавать, то даже простейший буфер формирует очередь, позволяя данным дождаться момента передачи. Он также позволяет компенсировать те потери которые у нас могут возникнуть из-за введённых ограничений:
Policer это график Burst 5 с предыдущего изображения. Shaper тот же график Burst 5, но с учётом буфера, в котором задерживаются не успевшие передаться данные и которые могут быть переданы чуть позже.
В результате, мы полностью обеспечили наши требования по ограничению трафика «сгладив» пики источника и не потеряв данные. Трафик по-прежнему имеет пульсирующую форму: чередующиеся периоды передачи и паузы — потому что мы не можем повлиять на скорость интерфейса и управляем только объёмом передаваемых за раз данных. Это тот самый график сравнения шейпера и полисера из СДСМ QoS, но с другой стороны:
Какой ценой мы этого достигли? Ценой буфера, который не может быть бесконечным и который вносит задержку в передаче данных. Пик на графике буфера приходится на 15Мбит, это те данные которые теряются полисером, но задерживаются шейпером. При заданном ограничении 50Мбит/c — это 15/50=300 миллисекунд, что для многих сетевых приложений уже за гранью дозволенного.
А теперь посмотрим когда эта цена играет роль, достаточно лишь чуть большей интенсивности трафика — 60Мбит/c, при ограничении 50Мбит/c:
Количество переданных данных шейпером и полисером совпали. Полисер, конечно, теряет данные, а шейпер копит в буфере, занятое место в котором непрерывно растёт, то есть растёт задержка. Когда место в буфере кончится, данные шейпером также начнут теряться, но с поправкой на размер буфера, с задержкой.
Поэтому, выбирая шейпер или полисер стоит отталкиваться от того, насколько критична дополнительная задержка, которая выше, чем больше скорость и чем интенсивнее трафик. Или стоит пожертвовать данными и потерять часть из них, учитывая что на следующем логическом уровне почти наверняка сработают механизмы восстанавливающие целостность передачи и реагирующие на заторы и потери.
Корзина
Для учёта объёма трафика переданного через интерфейс используется понятие и термин корзина. Фактически, это счётчик от максимального значения burst до 0, который уменьшается с передачей каждого кванта данных — токена. Соответственно, есть два процесса — один наполняет корзину, второй из неё забирает.
Корзина наполняется до величины burst каждый заданный интервал, при известном CIR. Для burst 5 и CIR 50, каждые 0,1 секунду, как было рассчитано чуть ранее. Но объём трафика за интервал времени может быть меньше чем заданный нами burst, так как условие ограничения — «не больше». Значит этот счётчик может не доходить до 0 и в корзине остаются токены. Тогда в следующий интервал, при заполнении корзины, неиспользуемый объём данных (токенов) будет потерян.
Такая ситуация видна на графике Policer выше, каждые 0,05 секунд мы в состоянии передать 5Мбит на скорости интерфейса, но количества данных которые у нас есть всего 3Мбит, так как скорость поступления данных всего 60Мбит/c. Именно поэтому график почти сливается с CIR, что не совсем корректно. Передача в любом случае осуществляется на скорости интерфейса и 3Мбит будут переданы за 0,03 секунды, а оставшиеся 0,02 будет пауза. Это давало бы нам характерную лесенку, которую мы видим на графике Shaper. Здесь, как раз, пример средней скорости и сглаживания точности измерения, что обычно показывают системы мониторинга оперирующие даже не секундами, а минутами.
Улучшим подход, зная что трафик спонтанен и больший burst может помочь не потерять данные. Введём ещё одну корзину, куда будем складывать неиспользованные на предыдущем интервале токены. Таким образом, в случае отсутствия трафика от источника, будет частично компенсироваться этот простой, как если бы у нас был больший burst. Для каждой корзины задаётся собственный burst, для основной — Committed Burst, CBS, Bc. А для второй — Excess Burst, EBS, Be. Таким образом максимальный объём данных который может быть непрерывно передан равен CBS+EBS.
Shaper Exs (жёлтый) — график с учётом двух корзин, каждая объёмом burst в 5Мбит. Shaper — график с предыдущего изображения. Теперь максимальный burst=EBS+CBS=10 и первые 0,1 секунду мы используем его. Основную корзину мы пополняем каждые 5/50=0,1 секунду. Соответственно, в момент времени 0,1 опять есть возможность передавать данные и период непрерывной передачи длится 0,15 секунды. В результате длительного простоя, когда трафика с источника не было и все данные из буфера мы передали, в момент времени 0,6 секунд, добавляем неиспользуемый объём данных во вторую корзину. Таким образом, получаем возможность снова вести непрерывный пропуск трафика в течение 0,15 секунд, что позволяет вовсе не использовать буфер. В итоге, получили удачный компромисс точности нарезки полосы, в случае интенсивного трафика, и лояльности в отношении всплесков при использовании большего burst.
Сделаем ещё одно улучшение касающееся времени. Избавимся от периодического процесса пополнения корзины и заменив его на пополнение только в те моменты, в которые к нам поступают данные. В большинстве случаев, меньше чем одним, целым пакетом за раз никто не оперирует. Поэтому можно посчитать период между приходами последовательных пакетов и пополнять корзину тем объёмом данных, которые соответствуют данному периоду. Это, во первых, исключит необходимость держать отдельный таймер для временных интервалов связанных с burst периодами, а во вторых, сократит периоды между возможными пропусками трафика.
Полисер: 1 скорость, 2 корзины, 3 цвета
До этого речь шла, в основном, о шейперах, хотя понятия и термины аналогичны тем что применимы и для полисеров. Полисер, однако, как это определено в RFC 2697 это не механизм ограничения трафика, это механизм его классификации. Каждый проходящий пакет, в соответствии с заданным CIR, CBS и EBS относится к одной из категорий (цвету): conform (green), exceed (yellow), violate (red). На устройствах можно сразу настроить в каком случае трафик стоит блокировать, но в общем случае, это именно назначение метки или покраска.
Для каждого пакета происходит проверка по следующему алгоритму:
Используем те же параметры что и раньше CIR=50, CBS=5, EBS=5. Количество токенов в корзинах теперь показано отдельно: основная Bucket C (голубой) и дополнительная Bucket E (фиолетовый). Теперь у нас не непрерывный поток битовых данных, а пакеты по 5Мбит. Что не совсем реально, трафик, в общем случае, состоит из разных по размеру пакетов приходящих в разные интервалы времени, и это очень сильно может изменить картину происходящего. Но для демонстрации базовых принципов и удобства подсчёта используем такой вариант. Также, отражён процесс пополнения корзины с приходом каждого пакета.
В первые 0,05 секунд передаём пакет в 5Мбит, опустошая основную корзину. С приходом второго пакета мы пополняем её, но на величину 2,5Мбит, что соответствует заданному CIR 0,05*50. Этих токенов не хватает для передачи следующего пакета в 5Мбит, поэтому мы опустошаем вторую корзину, но пакет помечается по другому. Через 0,05 секунд опять приходит пакет, и мы опять пополняем основную корзину на 2,5Мбит и этого объёма хватает для его передачи в зелёной категории. Следующему пакету, несмотря на то что корзина пополняется, уже не хватает токенов и он попадает в красную категорию. Красный сплошной график отражает ситуацию, если отбрасываются только пакеты помеченные красным.
Во время простоя корзины не пополняются, как это было видно на предыдущем графике, но в момент времени 0,6, при получении следующей порции данных высчитывается интервал между пакетами: 0,6-0,3=0,3 секунды, следовательно у нас есть 0,3*50=15Мбит для того чтобы пополнить основную корзину. Максимальный её объём CBS=5Мбит, остатком пополняется вторая корзина, тоже объёмом EBS=5Мбит. Оставшиеся 5Мбит мы не используем, тем самым трафик с очень длинными паузами всё равно ограничивается, чтобы не допустить ситуации: час бездействия — час без ограничений.
В итоге, на графике 6 зелёных участков или 30Мбит переданных за секунду — средняя скорость 30Мбит/c, что соответствует использованию только одной корзины и двух цветов. 3 жёлтых участка и в сумме с первым графиком 45Мбит/c, с учётом красных участков 55Мбит/c — две корзины, три цвета.
2 скорости, 3 цвета
Существует ещё один подход RFC 2698, в котором задаётся параметр пиковой скорости PIR — Peak Information Rate. И в этом случае используются две корзины, но каждая из которых заполняется независимо от другой — одна в соответствии с CIR, другая с PIR:
Трафик, как и в предыдущем случае, классифицируется на 3 категории следующим образом:
Вспомним для чего нам вторая корзина и больший burst, чтобы компенсировать периоды простоя трафика за счёт менее строго ограничения за больший период. Подход с двумя условиями даёт нам ту же возможность. Сформируем PIR и CIR равными 50Мбит/c, размер первой корзины 5, а второй PBS 10. Почему 10? Потому что это независимое ограничение, что возвращает нас к самому первому графику показывающему разницу burst. То есть, мы хотим добиться среднего результата между burst 5 и burst 10 и задаём эти условия напрямую.
Получили такой же график для полисера, что и при использовании предыдущего метода. При burst=10 получаем больше свободы, а вторым условием burst=5 добавляем точности. Обратите внимание как ведут себя корзины, каждая сама по себе.
Два отдельных условия, каждое из которых выполняется для одних и тех же входящих значений. Более строгое — классифицирует трафик, который гарантированно попадает под него, а менее строгое расширяет эти границы. В случае равных CIR и PIR, получаем взаимозаменяемый с предыдущим метод.
А устанавливая PIR скорость увеличиваем количество степеней свободы. Можно отдельно проверить разные burst при разных профилях трафика с разными CIR, а потом совместить всё вместе с использованием этого метода:
CIR=50, PIR=75, CBS=5, PBS=7,5. CBS и PBS выбраны таким образом, чтобы укладываться в одинаковый интервал. Но, конечно, можно исходить из других условий, например для PIR сделать меньший burst, чтобы увеличить гарантию не выхода за обозначенные границы, а для CIR наоборот, более лояльный.
В принципе, при интенсивном трафике нет причин ставить маленький burst ни в каком случае, ни для какой из корзин. Несколько десятков секунд и несколько лишних мегабайт не сделают погоды на продолжительных временных интервалах, но частые блокировки из-за небольшого burst, могут сломать незаметные для нас механизмы регулировки потока. Для трафика 80Мбит/c, в зелёную зону уложилось 40Мбит/c. Учитывая жёлтую как раз вписались между CIR и PIR — 60МБит/c. Ещё раз, механизмы ограничения пытаются гарантировать не выход за верхние границы, про нижние они ничего не знают. И как видно в примерах, результирующий трафик всегда меньше заданных ограничений, иногда сильно меньше, даже если он сам попадал в них без посторонней помощи.
Описанные выше подходы сформировались в RFC уже больше 20 лет назад, но на свалку истории пока не торопятся, и часто применяются именно как ограничивающий инструмент ухудшающий качество, а не как классификатор, или как компенсирующий механизм. Даже в самых современных реализациях вы обязательно встретите если не эти алгоритмы, но эти термины обязательно и, конечно, сложность применения понятия скорости в сетях передачи данных. Может быть с ещё одной статьёй разобраться во всём этом станет чуть проще.
Committed information rate что это
Вместо приоритезации трафика используется процедура заказа качества обслуживания при установлении соединения. Такая процедура отсутствует в сетях Х.25. В технологии Frame Relay процедура заказа и поддержания качества обслуживания встроена в технологию.
Для каждого виртуального соединения существует несколько параметров, влияющих на качество обслуживания.
Если заранее задать эти величины, то время Т будет определяться формулой:
Можно т задать значения CIR и Т, тогда производной величиной станет величина всплеска трафика Вс.

Надо отметить, что гарантий по задержкам передачи кадров технология Frame Relay не дает.
Как правило, основным параметром, по которому абонент и сеть заключают соглашение при установлении виртуального соединения, является согласованная скорость передачи данных. Для постоянных виртуальных каналов это соглашение является частью контракта на пользование услугами сети.
При установлении коммутируемого виртуального канала соглашение о качестве обслуживания заключается автоматически с помощью протокола Q.931/933. Для этого требуемые параметры CIR, Вс и Be просто передаются в пакете запроса на установление соединения. В общем случае нужно обеспечить такой режим, при котором пользователь не должен за интервал времени T передать в сеть данные со средней скоростью, которая превосходит согласованную скорость CIR. Если же пользователь нарушит соглашение и превысит скорость, то сеть не гарантирует доставку его кадра, мало того, она даже удалит его в том случае, если коммутаторы сети испытывают перегрузки. Пометка о том, что кадр надлежит удаления «ставится» с помощью бита DE кадра протокола LAP-F
В нашем примере, изображен случай, когда за интервал времени Т в сеть по виртуальному каналу поступило 5 кадров.
Механизм заказа средней пропускной способности и максимальной пульсации является основным механизмом управления потоками кадров в сетях Frame Relay.
В технологии Frame Relay определен еще один дополнительный (необязательный) механизм управления кадрами. Это механизм оповещения конечных пользователей о том, что в коммутаторах сети возникли перегрузки (переполнение необработанными кадрами). При создании коммутируемого виртуального канала параметры качества обслуживания передаются в сеть с помощью протокола Q.931. Этот протокол устанавливает виртуальное соединение с помощью нескольких служебных пакетов.



