Автоматизация workflow небольшой команды разработки (Часть 2)
В предыдущей публикации я описывал список продуктов и их настройки, которые необходимы для работы нашей организации.
В этой статье я постараюсь описать, как мы это всё используем в ежедневной работе всего коллектива разработки.
Работа в основном в стиле стартапа, когда нет конкретной и подробной постановки. Очень часто эксперименты вроде “а давайте попробуем так, посмотрим что получится” или “вы классно все сделали, но теперь надо все совсем по-другому”.
За эти годы концепцию нашей работы можно описать одной фразой — это “стремительная смена концепции”.
Понятное дело, что применить в таких условиях различные методологии никак не удавалось.
Начинал в этой системе я как программист, потом Team lead, ну а теперь PM (DM). Т.е. руковожу, полностью участвую в проектировании и иногда даже пописываю. Во времена моего программирования у меня был замечательный ПМ (выходец из тестировщиков), которая поддерживала все мои идеи по автоматизации workflow. Даже более того, концептуально этот процесс придуман ей, а я уже смог его технически реализовать и в некоторых местах усовершенствовать.
Перейдем к сути.
Постановка задачи
Все задачи появляются у нас либо после совещания с высшим руководством, либо пожелания от заказчика, либо придумываем что-то сами (или находим баги).
В случаях, когда задача не односложная, собирается мини-совещание из ПМ, тимлида, QA-лида и аналитика. После обсуждения и придумывания, что и как будем разрабатывать, обычно сразу дробим это на логически завершенные небольшие задачки (не дольше работы 1-го дня программиста) и грубо прикидываем сроки на реализацию (для планов для высшего руководства).
Аналитик садится и вдумчиво излагает постановку в Confluence. После этого данную постановку согласовывает с ПМ, а тот при необходимости с высшим руководством.
Затем на основании этой постановки создается задача в Jira.
Часто задачи сразу появляются в Jira минуя этап с Confluence.
Ревизия постановки
При переходе на этот шаг триггеры Jira автоматом меняют ответственного задачи на ПМ-а.
Этот шаг предназначен для того, чтобы ПМ перечитал описание задачи и убедился, что автор правильно понял постановку и корректно описал задание для программиста. Очень часто из-за недостаточного взаимопонимания задача делается и тестируется до самого конца и только уже при релизе видно, что сделали совсем не то, что изначально требовалось.
Также на этом шаге ПМ принимает решение нужно ли реализовывать вообще данную задачу. Или нужно ли ее реализовывать именно в эту версию.
На этом этапе есть два варианта workflow: вернуть назад на постановку (доработку описания) или продвинуть дальше в работу.
Также я часто на этом шаге назначаю ответственного тимлида для того, чтобы он сам определил исполнителя
Ожидание работ

При выборе этого шага я настроил экран, в котором надо задавать исполнителя, поле “Программист” и планируемое время.
Этот шаг — пул задач программиста, который надо выполнить за версию в порядке, указанном в поле приоритет или в порядке любом удобном, если приоритет одинаковый.
Так уж получается, что во время работы над версией частенько этот список пополняется.
В работе
У нас в команде договоренность, что мелкие правки типа подвинуть кнопку правее или раскрасить зелёный зеленее, можно сразу бросать на сборку. Иначе — ОБЯЗАТЕЛЬНО на ревизию кода.
Итак, бросаем задачу на ревизию кода, и при этом ответственным назначаем тимлида.
Ревизия кода
На этом шаге тимлид в специальной секции Development в Jira смотрит какой именно комит был сделан программистом и нажимает специальную кнопку “Code Review”.

После нажатия автоматически открывается Crucible и создается ревью на указанный комит (или несколько комитов).
Тимлид может видеть дерево файлов, которые правил программист ну и соответственно диференсы. Может оставить комментарий к любой строке кода или общий к ревизии. Crucible позволяет даже указать степень критичности проезда программиста.
После мук изучения чужого гуанокода, тимлид либо проталкивает задачу на шаг сборки, либо возвращает программисту в ожидание работ.
Программист в этом случае в секции Development видит Code Review и его статус. При переходе на этот Code Review опять же открывается Crucible, где программист может наглядно увидеть, где именно он налажал.
При переводе на шаг “Ожидание сборки”, тимлид выбирает ответственным тестировщика, который указан в спец поле, либо если оно не заполнено, то QA-лида.
Ожидание сборки
Так как сервер тестирования у нас один общий, то сборка по расписанию не годится. Нельзя подменять сайт во время его тестирования.
Поэтому обычно у нас тестировщики договариваются и, если никто не против, собирают себе свежую версию ресурса.
Делают они это с помощью Jenkins. В нем созданы по три сборки на каждый проект: сборка для тестов, сборка для разработки, сборка БД.
Ожидание тестирования
На этом шаге могут быть задачи, которые уже были в тесте, а могут быть и в первый раз. Если задача уже в тесте была, то тимлид уже ответственным ставит именно того тестировщика, который вернул задачу в работу.
Иначе все задачи скапливаются у QA-лида. Он смотрит на пул задач и нагрузку каждого тестировщика, и определяет кому назначить задачу на тест. Более того, сразу же определяет и тестировщика для парного тестирования.
Тестирование
Ожидание парного тестирования
Этот шаг был придуман по нескольким причинам. Многие не понимали его целесообразности, но в итоге спустя какие-то время соглашались, что он необходим.
Суть его заключается в том, что есть основной тестировщик по задаче, который очень глубоко и усиленно ковыряет задачу со всевозможных аспектов и есть парный тестировщик, который поверхностно просматривает задачу только после полностью завершенных тестов первого. Это очень похоже на ревизию кода у программистов.
В итоге получаем то, что не только один тестировщик знает как устроена та или иная функциональность. Если задача футболялась 10 раз между программистом и тестировщиком, то свежий взгляд парного тестировщика может заметить что-то пропущенное. Ну и самое важное, то что каждый тестировщик работает по-своему и привыкает использовать софт определенным образом (логинится не используя мышь, аплоадить файлы драг-н-дропом, вместо фильтров использовать сортировки, при вводе данных копипастить тексты и т.д.). Очень часто бывает, что одни и те же функции можно использовать по-разному, и парный тестировщик натыкается на ошибки, которые были проверены основным, но немного по-своему.
Парное тестирование
Если на этом шаге обычно уже можно считать, что задача почти закончена. И очень часто, когда поторапливают с выпуском версии, его можно пройти формально.
ReadMe
После успешно проведенных тестирований уже окончательно определена функциональность и ее реализация. И вот теперь этой задачей занимается техпис. Обычно все задачи, кроме совсем незначительных или тех, которые сами сломали в процессе работы над версией, мы помечаем меткой “ReadMe”.
Парный тестировщик, если видит эту метку отправляет задачу на шаг “ReadMe” и назначает на техписа.
Техпис в специальном поле описывает очень кратко Release notes по этой задаче. Обычно это оповещение пользователя об изменении функциональности или исправлении ошибки, или о появлении новой функциональности и как ей пользоваться.
На этом же шаге техпис исправляет или дополняет справку ресурса в Confluence.
После проделанной работы, задача отправляется на финальный шаг “Ревизия функциональности”.
Ревизия функциональности
При переходе задачи на этот шаг, триггеры Jira автоматом назначают ответственным ПМ-а.
На этом шаге ПМ проверяет работу всей команды в целом. Было ли реализовано то что хотели, именно так как хотели, нормальное ли описание в ReadMe и т.д.
Бывает, что на этом шаге оказывалось, что программист с тестировщиком что-то между собой порешали и отрезали “ненужную функциональность” или изменили ее потому что посчитали так лучше, и именно эта функциональность требовалась высшим руководством и именно в таком виде. Тогда задача опять идет на “Ожидание работ”.
Ценность данного шага заключается в том, что хороший ПМ или ДМ после выпуска и звонка заказчика с фразой “что вы наделали?”, должен знать как именно реализовали задачу, как назвали кнопки, тексты сообщений, нюансы алгоритмов и смело ответить “сам дурак”. А не мяться и гадать, а как же они сделали ту форму и чего в ней кнопка задизейблена…
Закрыто
Ну тут все и так понятно. Задача закрывается после удачно прошедшей ревизии функциональности.
Или задача в любой момент может оказаться никому не нужной, потому переход на этот шаг возможен с любого другого шага.
Рабочий стол
Выпуск версии
При выпуске версии, мы выгружаем из Jira все задачи версии в виде двух колонок: компонент и поле ReadMe. Вот и получается у нас ReadMe сгруппированное по разделам.
С помощью “Scroll HTML Exporter” мы экспортируем страницу хелпа в Confluence и все ее дочерние страницы в набор html файлов, которые внутри выглядят так же красиво как в Confluence и ссылаются друг на друга.
Итоги
Вот по такому workflow мы уже работаем несколько лет, иногда его дорабатывая и дотачивая.
Но в целом он очень удобен.
Для ПМ тем, что в любой момент времени видно, кто именно и на каком шаге держит задачу.
Для разработчиков удобно видеть только свой объем работ.
Ну и, конечно же, автоматизация на всех шагах. Т.е. нет такого человека, без которого рабочий процесс может остановиться.
Confluence в жизни аналитика — Часть 2
 Всех с наступившим 2015 Годом! В прошлом году мы с вами познакомились с базовыми возможностями Confluence и немного рассмотрели его с позиции “просто пользователя”.
Всех с наступившим 2015 Годом! В прошлом году мы с вами познакомились с базовыми возможностями Confluence и немного рассмотрели его с позиции “просто пользователя”.
Сегодня приготовим теплый напиток, устроимся удобнее у камина после праздничной суеты и, наслаждаясь спокойствием долгожданных выходных, рассмотрим Confluence в работе бизнес-аналитика, чтобы ты, дорогой читатель, мог начать первую рабочую неделю с прочтения этой самой статьи.
Трассировка требований в работе аналитика
Если провести опрос, то наверняка большинство наших с вами коллег знают, что такое матрица трассируемости, и при этом большинство не использует её на практике. Причины понятны: если в проекте несколько тысяч требований, не так просто осилить матрицу такой размерности. Никого не хочу обидеть, но для меня матрица трассируемости так и осталась академическим понятием. Однако это совсем не означает, что не нужно решать проблему взаимного влияния одних требований на другие. Ещё как надо! Чем больше проект и чем вы ленивее, тем более остро может стоять такая задача.
Поскольку Confluence изначально не является инструментом управления требованиями, он не предлагает готовое решение, как, например, готовая матрица трассируемости. Зато у него есть кое-что получше… 😉
Итак, как же упростить поддержку требований? Как работать так, чтобы описание можно было использовать повторно, не копируя каждый раз и не исправляя одно и то же в куче мест в спецификации?
Признаюсь, то что предлагает для этого Confluence – одна из моих любимых особенностей работы с этим инструментом.
Прежде чем рассказать о трассируемости, хочется сказать про возможность встроить одну страницу в другую с помощью макроса
Так вот, есть и другое решение для упрощения поддержки требований, которое позволяет разместить все нужное в одном месте без нанесения ущерба структуре документа.
Представьте себе ситуацию классического изменения требования: спонсор продукта захотел, чтобы дата создания заказа в системе управления заказами повсюду отображалась не просто датой, как раньше, а датой со временем. Более того: в специально указанном формате!
Положим, у вас на проекте принят такой стиль описания требований, который предполагает, что каждый экран интерфейса пользователя и элементы управления имеют подробное текстовое описание каждого поля. У вас же:
100500 страниц системы работы с заказами.
вы хотите обновить требование к одному из важнейших полей заказа.
здоровая аналитическая лень отбивает всякое желание обновлять 100500 страниц спецификации, где упоминается дата заказа.
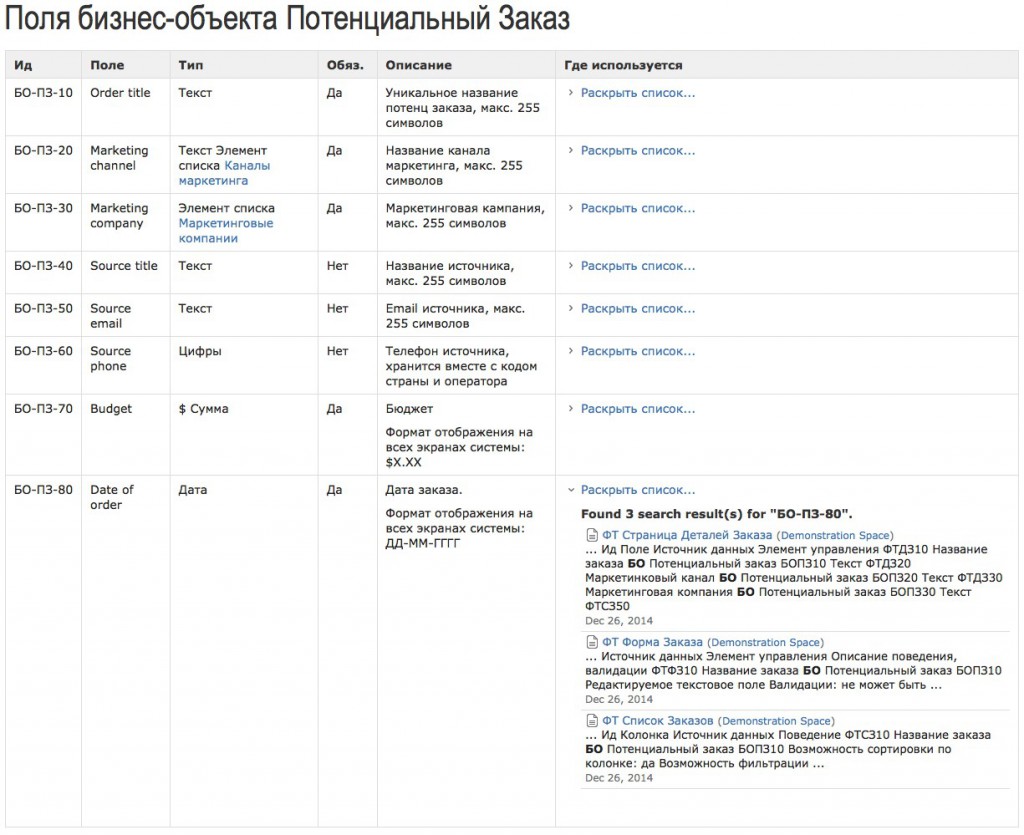
Создадим страницу для описания объекта “Заказ”. Тут опишем все поля объекта, включая поле “Дата заказа”. Каждому полю присвоим уникальный идентификатор (для даты заказа у нас будет идентификатор БО-ПЗ-80),
Во всех местах спецификации, где используется Дата Заказа, делаем ссылку на описание данного поля с указанием придуманного выше идентификатора БО-ПЗ-80, обозвав его, например, “Источник данных” – намекнем тем самым на структуру базы, что особо оценят программисты.
И немного волшебства: добавим колонку “Где Используется”, которая динамически отобразит список страниц, в которых упомянута наша дата (поле БО-ПЗ-80), решив тем самым проблему трассировки!
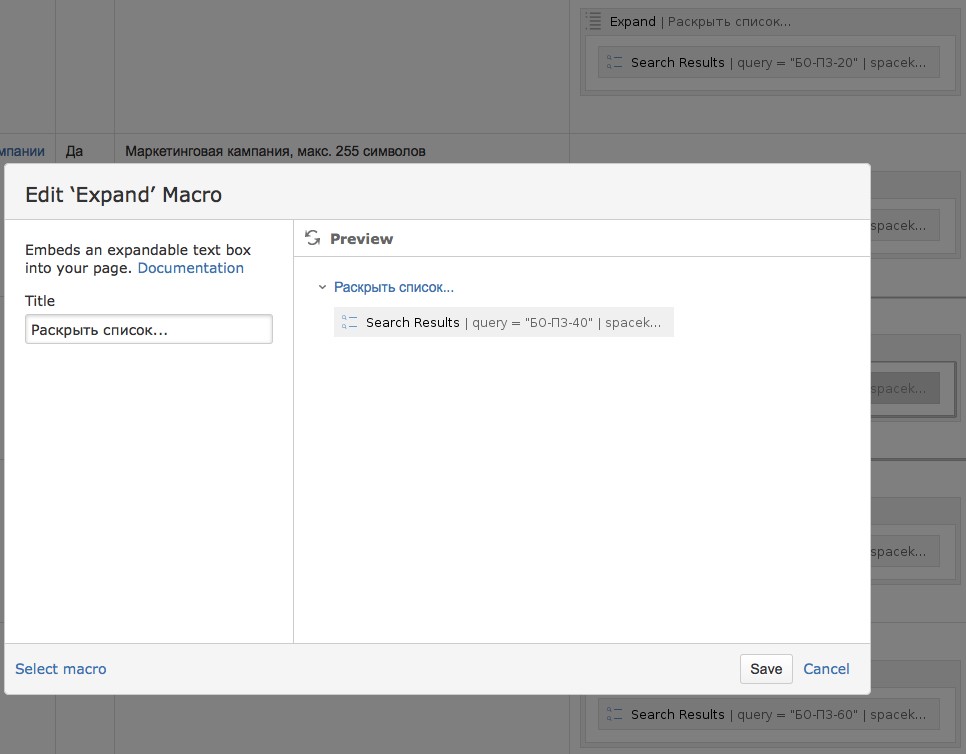
Страница описания объекта может выглядеть примерно так (на иллюстрации смотрим нижнюю строчку и колонку “Где используется”):
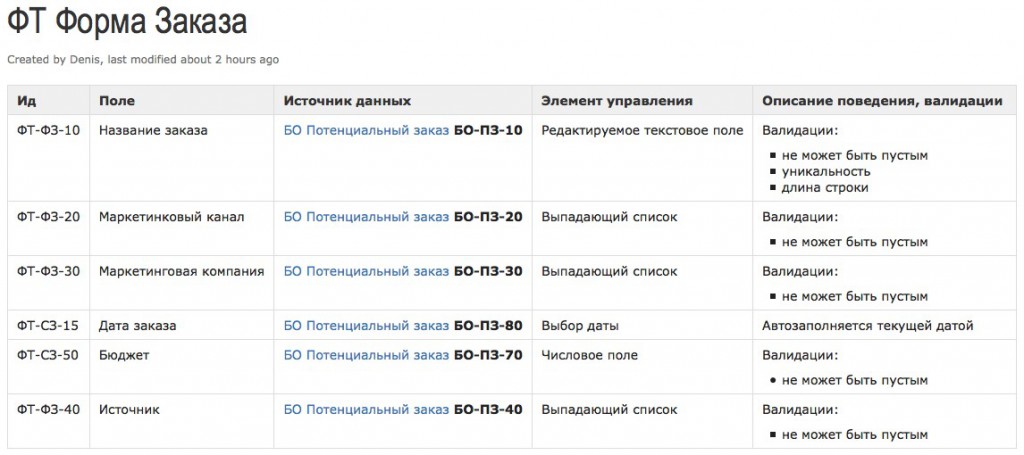
А так выглядит страница описания экрана со ссылками на описание полей бизнес-объекта (на иллюстрации смотрим колонку “Источник данных” и ищем строчку про дату заказа):
Таким образом, в последней колонке “Где используется” у вас всегда найдётся список страниц, который можно смело отдавать в тестирование для проверки того, что новый формат даты успешно изменён везде, как и требовалось в нашей задаче.
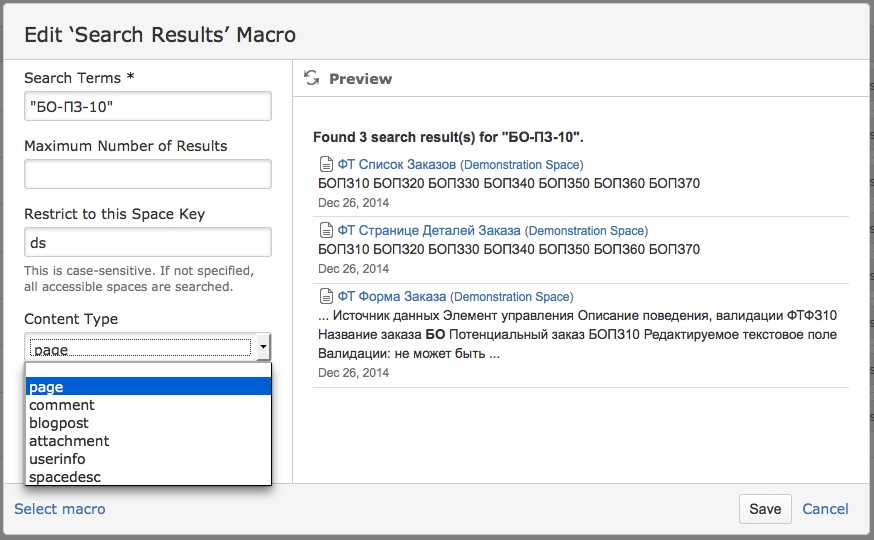
Чтобы овладеть магией, вам понадобятся только два макроса:
Справедливости ради надо отметить, что интересный способ связи требований предлагают автоты плагина Requirement Yogi (видео 2:15 https://www.youtube.com/watch?v=mHC13NVg3KA).
А что если он захочет подписать документ?
Все скептики говорят примерно одно и то же: “Ваша вики это, конечно, модно и молодёжно, но мой заказчик требует пачку бумаги на стол, которую можно полистать и подписать”. На самом деле, этого же зачастую желают и руководители наших коллег, так что посыл, как говорят, понятен 🙂
Что касается темы подписи, то можно заморочиться и предложить рассмотреть дополнения, призванные настроить процесс работы с каждой страницей, процесс её утверждения и публикации. Примеры таких плагинов:
Однако понятно, что на самом деле вопрос о подписании документов задают не для того чтобы поговорить о реализации процессов жизненного цикла требований, а о возможности представить требования в старом добром и понятном виде документа, который можно пролистать от начала и до конца. Так вот, Confluence предлагает ряд возможностей для получения документов в удобном для печати олдскульном виде.
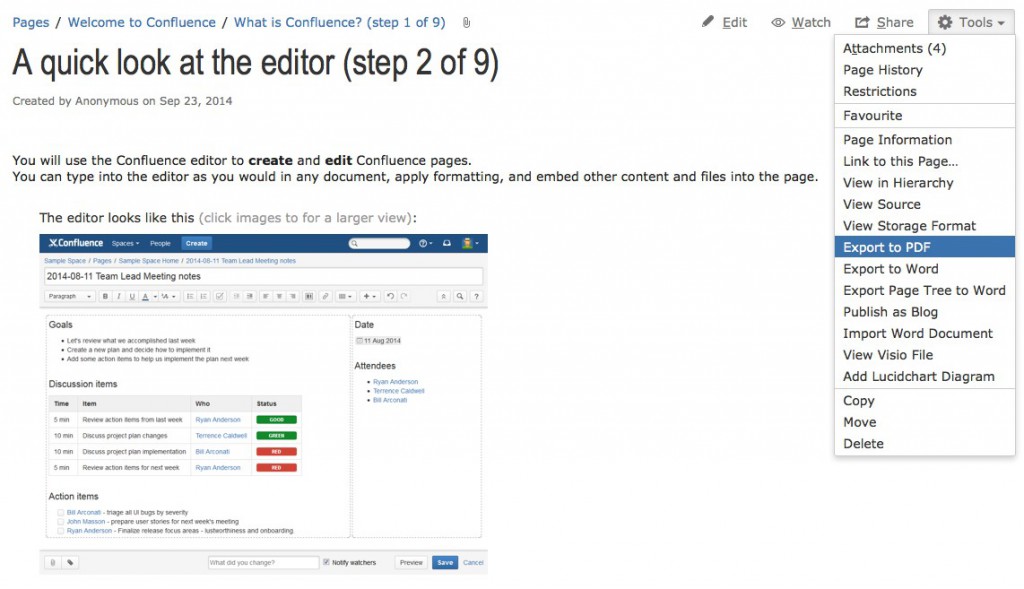
Опции для экспорта контента доступны из меню пользователя Tools:
Export to PDF – сохранить текущую страницу как PDF.
Export to Word – сохранить текущую страницу как Word-документ.
Export Page Tree to Word – сохранить дерево страниц как Word-документ – самая популярная возможность, когда нужно подписать целую спецификацию, состоящую не из одной, а из множества страниц вики.
А такие опции доступны администраторам:
Организация требований, и какие бывают правила
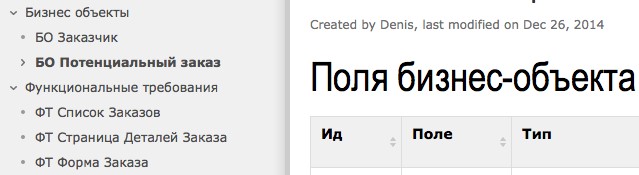
Так вот, Confluence не навязывает никаких правил. Немного выше мы с вами создали страничку для описания бизнес-объекта и несколько страниц для функциональных требований, просто потому что нам с вами так захотелось, исходя из целесообразности в конкретной задаче.
Если вам не понравилась получившаяся иерархия страниц, то страницы можно легко отсортировать, как вам нравится: например, отделить Бизнес-Объекты от Функциональных Требований.
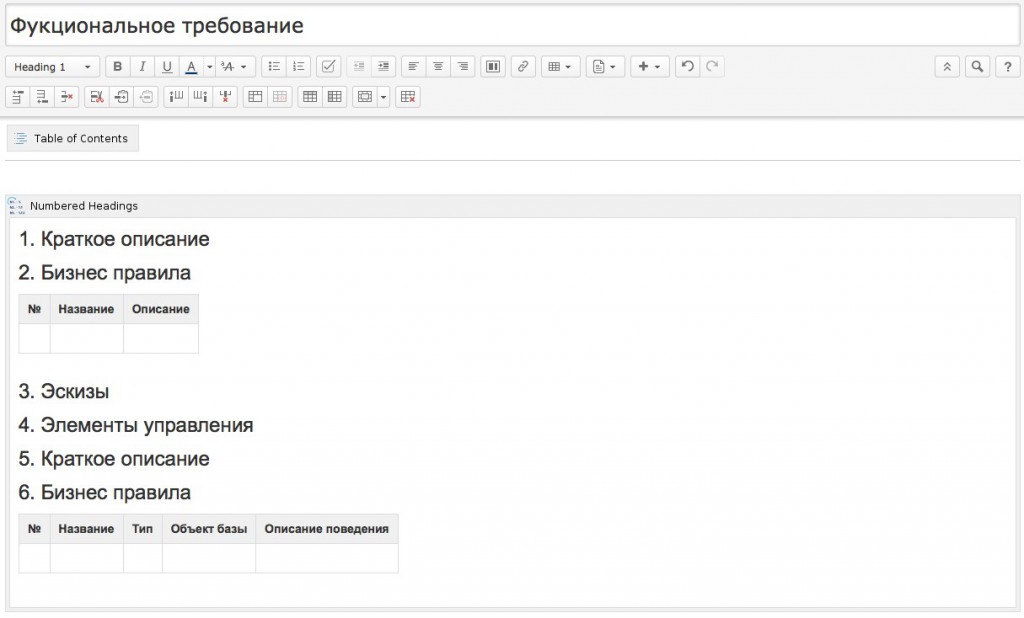
Кроме создания иерархии требований бывает необходимо унифицировать структуру самих страниц. Например, вы хотите, чтобы все страницы, описывающие функциональные требования, содержали секцию с кратким описанием, секцию с макетом или эскизом экрана, секцию с бизнес-правилами, описание элементов управления, которые присутствуют на странице, и, возможно, тексты сообщения для пользователя, которые могут встретиться при работе с описываемым на странице экраном.
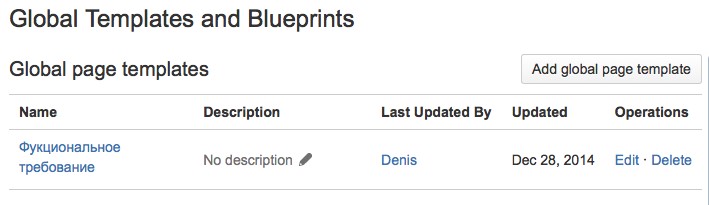
Для этого постройте шаблон страницы, и впоследствии вы не только сэкономите себе время, создавая новую страницу с использованием этого шаблона, но и облегчите задачу начинающим коллегам.
Шаблон можно настроить в рамках вашего проекта или глобально для всех проектов, если вы администратор.
Впоследствии ваш шаблон будет отображён в списке выбора, который появляется при попытке создания страницы.
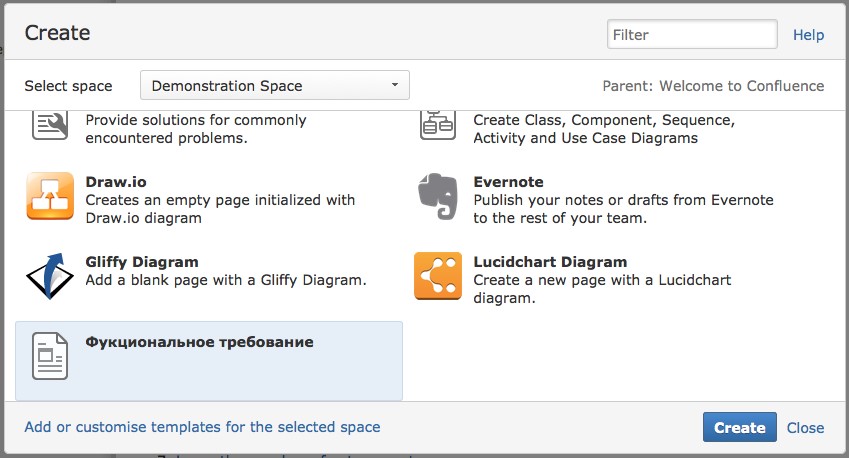
В Atlassian Market можно найти массу существующих бесплатных шаблонов. Начиная с некоторого времени, они стали называться Blueprint. Подробнее об этом пишут на сайта документации от Atlassian:
Таким образом, используя Confluence, вы в праве сами определять правила оформления требований. В тоже время для неприхотливой аналитики, можно вполне обойтись и готовым решением от Confluence “из коробки”.
Про работу с Jira и заморозку версий спецификации
Приходилось ли вам сталкиваться с жалобами команды на то, что они запутались и не могут разобраться в спецификации, а именно: непонятно, что из написанного нужно читать и кому именно это нужно, а что следует проигнорировать. Например, с точки зрения специалистов по контролю качества, может быть неочевидно как подойти к написанным требованиям, когда часть задокументированного функционала уже реализована и должна быть проверена, а другая часть ещё в разработке.
Если такой вопрос поднялся, то это не что иное, как увесистый камень в чудесный сад управления процессами на проекте. Часто случается, что именно аналитик отвечает если и не за все процессы, то, как минимум, за процесс управления требованиями. И действительно, коллеги, ввиду особенностей нашей с вами профессии мы склонны генерировать много контента, не всё из которого предназначено для немедленного прочтения каждым участником команды. Как известно, один из признаков эффективного стиля работы – умение беречь время своих коллег.
Так вот, если вернуться к тому, что от нас требуют, простыми словами, то от нас требуется понятно обозначить нужное и ненужное, важное и неважное, сделать это с учётом актуальной ситуации, особенностей проекта и роли на нём каждого отдельно взятого читателя проектной документации.
Для решения такой задачи можно традиционно предложить два подхода, как минимум. Один краше другого — выбирайте любой или комбинируйте, смотря чего вы на самом деле добиваетесь 🙂
Вариант “внедрить и задействовать систему управления задачами”.
Вариант “задействовать версионность, которая присутствует в арсенале Confluence”.
Рассмотрим оба подхода.
В первом случае нам нужна система управления задачами, коей Confluence не является. Конечно, можно написать строчку текста, сказать, что эта строчка – на самом деле, задача, назначить ей дату исполнения и ответственного. Действительно, если это можно сделать в Excel, то почему это делать в Confluence?
Однако я настаиваю на том, что Confluence – это инструмент для совместной работы, но никак не система управления задачами. Поэтому в первом подходе мы предположим, что на вашем проекте задействована некая система управления задачами, которая позволяет контролировать сроки, назначать виновных и в целом, отслеживать прогресс на проекте. Jira – одна из таких систем, но если у вас TFS, IBM Rational, Mantis, Bugzilla, Redmine или что-нибудь ещё, что позволяет управлять задачами – это всё равно отлично сработает.
Идея в том, чтобы в Confluence держать подробное описание требований, а в системе управления задачами вести задачу со всеми её атрибутами и контролировать статус её выполнения в пределах жизненного цикла задачи в указанной системе. Простыми словами, в Jira мы указываем, что в рамках задачи Задача-Х100500 нужно добавить дату и указываем тут же, в подробностях задачи, ссылки на описание соответствующих страниц в Confluence с идентификаторами требований, касающихся даты:
Затем задача Задача-Х100500 в состоянии “Назначена” уходит к своему счастливому обладателю.
С другой стороны, в Confluence в каждом из указанных требований мы укажем идентификатор задачи, в рамках которой она должна быть выполнена (на иллюстрации смотрим колонку “Задача”).
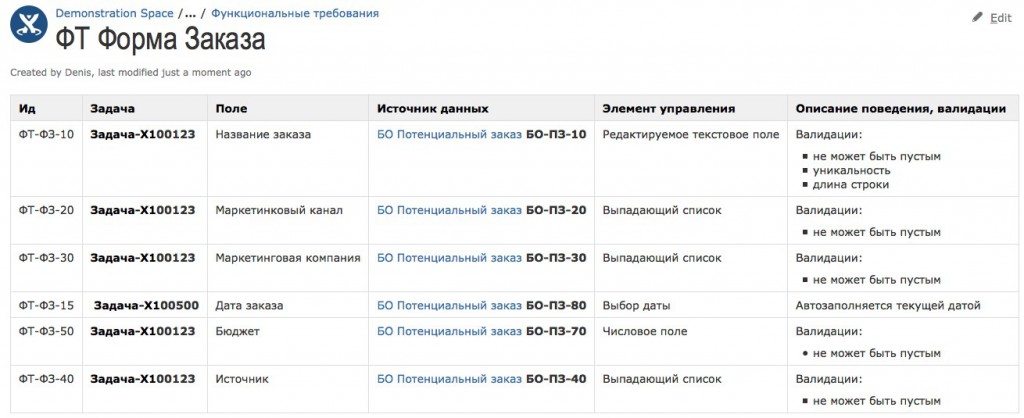
Теперь для того, чтобы понять, реализовано ли поле “Дата”, будет достаточно взглянуть на статус соответствующей задачи в системе управления задачами. Статус задачи может быть, допустим, “Назначена”, “Выполнена”, “Закрыта” или, скажем, “Переоткрыта” – в зависимости от внедрённой системы управления задач и настроенного в ней процесса со статусами. Таким образом, пометка идентификатора задачи напротив требования позволяет нам судить о том, как относиться к каждому требованию: как к реализованному или, например, только как к запланированному пока что.
Всё-таки нужно упомянуть дополнительно Jira за особо глубокую интеграцию, которая позволяет не только создавать Jira Issues из Confluence, но также с помощью макроса

Второй подход, про версионность – это примерно то, что делает сам Atlassian в своей документации. Каждый раз, когда выходит новая версия продукта, документация для предыдущей версии остаётся, но волшебным образом появляется и новая, очень похожая на старую, только более актуальная документация к последней выпущенной версии продукта!
На одном из проектов в моей практике накопилось слишком много разных цветных замечаний к каждому требованию. Особенность того проекта была такова, что для одних и тех же требований создавалось очень много изменений, которые в конце концов сильно засоряли документацию. Действительно, когда напротив описания требования к дате вы встретите более 2-х задач (где первая задача была на создание поля, а вторая – на его изменение), то становится проблематично определить, какова же судьба этого требования сейчас. Тогда было принято решение скопировать всю проектную документацию в новое пространство, очистить в скопированной версии все упоминания о будущем функционале и заморозить получившуюся копию, присвоив ей соответствующий номер релиза. Таким образом, у нас получилась документация, актуальная для определённого релиза нашего проекта.
В текущей версии мы удалили упоминание всех “устаревших” выполненных и закрытых задач, обеспечив тем самым “чистоту” описания и читабельность. У нас была “активная” версия документации, которая развивалась вместе с проектом и было несколько замороженных версий.
Если вы откроете любую статью документации Confluence (для примера, https://confluence.atlassian.com/display/DOC/Start+your+trial), то вверху страницы вы обнаружите текст о том, к какой версии продукта относится статья, которую вы сейчас смотрите. Там же вы найдёте ссылку на все имеющиеся версии.


В нашем случае мы сделали даже интереснее: добавили в аналогичный блок ещё ссылку на эту же страницу в самой последней версии. Такая ссылка “Открыть это требование для последней версии продукта” у нас была доступна из старых “замороженных” версий документации. Вы тоже можете её сделать с помощью макроса
Такой процесс “Cрез версии” достигается копированием всего пространства в момент заморозки кода, а все описанные ссылки на другие версии настраиваются администратором как разметка страницы на уровне пространства вашего проекта. Таким образом, пояснение про версию отображается динамически на каждой странице пространства, и никому не нужно писать об этом, каждый раз создавая нужную страницу.
Так работает дополнение “Copy Space”:
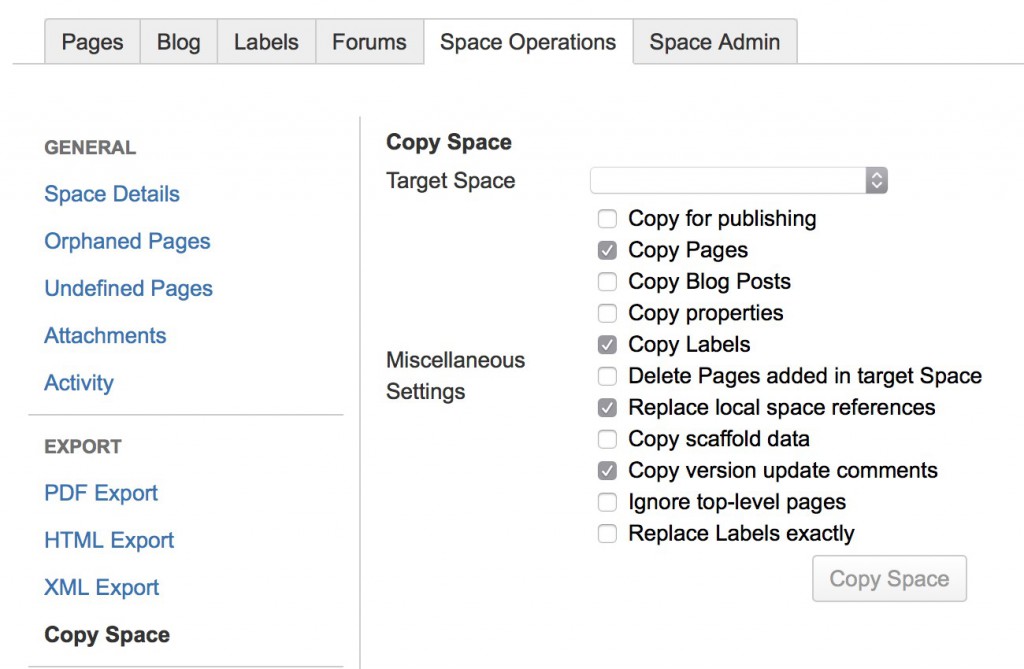
Настройка разметки страницы:


К сожалению, последняя версия Confluence не поддерживает дополнение Copy Space Plugin, однако вероятно, что это только вопрос времени, когда выйдет обновление для плагина: https://marketplace.atlassian.com/plugins/com.atlassian.confluence.plugin.copyspace/versions#b22
А если не выйдет, то же самое можно попробовать сделать через экспорт и импорт всего пространства.
Идеологически мне очень нравится этот подход, но только при условии чтобы НЕ мне пришлось заниматься “зачистками” после каждой “заморозки” документации 🙂
Всё-таки описанный процесс предполагает существенные временные затраты на поддержание чистоты в момент поставки каждой новой версии документации.
Кажется, мы рассмотрели всё самое популярное из того, что мне нравится в работе с Confluence.
В качестве заключения надо сказать, что Confluence следует рассматривать, в первую очередь, как к средство совместной работы над контентом, коим являются в нашем случае требования. Прочие функции, такие, как управление задачами, планирование и контроль работ на проекте, разумно оставить специально предназначенным для этого другим инструментам, многие из которых могут быть успешно интегрированы с Confluence.
Наряду с таким пониманием, самым главным преимуществом Confluence для меня является свобода организации контента. Вы сами решаете, какой будет структура документации на вашем проекте или у вас в организации.
Таким образом, научившись “правильно готовить контент” так, как это нравится именно вам, Confluence сослужит вам отличную службу.

Было бы интересно увидеть ваши примеры использования Confluence в работе BA и в любой другой работе 🙂
Автор:
 Денис Ардабацкий
Денис Ардабацкий



