Cloudera manager что это
Cloudera CDH (Cloudera’s Distribution including Apache Hadoop) — дистрибутив Apache Hadoop с набором программ, библиотек и утилит, разработанных компанией Cloudera для больших данных (Big Data) и машинного обучения (Machine Learning), бесплатно распространяемый и коммерчески поддерживаемый для некоторых Linux-систем (Red Hat, CentOS, Ubuntu, SuSE SLES, Debian) [1].
Состав и архитектура Клаудера CDH
Помимо классического Hadoop от Apache Software Foundation, состоящего из 4-х основных модулей (HDFS, MapReduce, Yarn и Hadoop Common), CDH также содержит дополнительные решения Apache для работы с большими данными и машинным обучением:
Cloudera Enterprise Manager: чем CDH отличается от других дистрибутивов Apache Hadoop
Уникальным отличием CDH от других дистрибутивов Big Data инфраструктуры на основе Apache Hadoop является Cloudera Manager — собственная специализированная подсистема управления кластером. Она включает сценарии развёртывания Hadoop-инфраструктуры и средства Apache Maven, что позволяет автоматизировать создание и модификацию локальных и облачных Hadoop-сред, отслеживать и анализировать эффективность выполнения заданий, настраивать оповещения о наступлении событий, связанных с эксплуатацией инфраструктуры распределённой обработки данных [1].
Платный вариант CDH называется Enterprise и включает Cloudera Manager — инструмент для развертывания, мониторинга и управления кластером, а также Cloudera Support – профессиональная поддержка от компании-разработчика по вопросам CDH и Cloudera Manager [2].
 Модули Cloudera Enterprise
Модули Cloudera Enterprise
Помимо техподдержки, CDH Enterprise 4.0 включает следующие полезные компоненты [3]:
История появления и развития
CDH является продуктом американской компании Cloudera, поэтому далее мы приведем основные вехи ее становления [1]:
2008 – год основания компании, приход основателей проекта Hadoop – Дуга Каттинга и Майкла Кафарелла;
2009 – оказание услуг технических консультаций по Hadoop;
2010 – разработка и поставка тиражируемого корпоративного программного обеспечения;
2012 – выпуск CDH4 с 3-мя новыми продуктами – Impala (SQL-решение для Big Data), Hue (браузерный интерфейс управления Hadoop-кластером) и Search (полнотекстовый и фасетный поиск в средах HDFS и HBase);
2014 – приобретение фирмы-разработчика технологии шифрования данных Gazzang;
2017 – поглощение нью-йоркской фирмы-разработчикы алгоритмов машинного обучения Fast Forward Labs;
2018 – выпуск CDH6 c поддержкой помехоустойчивого кодирования для HDFS, существенно снижающей физические размеры кластеров;
2019 – слияние с фирмой-конкурентом Hortonworks, которая реализовывала свой коммерческий дистрибутив Hadoop.
 CDH – отличное инфраструктурное решение для проектов Big Data
CDH – отличное инфраструктурное решение для проектов Big Data
Как установить, настроить, обслуживать и успешно использовать Cloudera Hadoop для больших данных и машинного обучения узнайте на наших компьютерных курсах обучения различных категорий пользователей, от «чайников» до профессионалов – клаудера хадуп для инженеров, администраторов и аналитиков Big Data и Machine Learning в Москве:
Hadoop, часть 1: развертывание кластера


Непрерывный рост данных и увеличение скорости их генерации порождают проблему их обработки и хранения. Неудивительно, что тема «больших данных» (Big Data) является одной из самых обсуждаемых в современном ИТ-сообществе.
Материалов по теории «больших данных» в специализированных журналах и на сайтах сегодня публикуется довольно много. Но из теоретических публикаций далеко не всегда ясно, как можно использовать соответствующие технологии для решения конкретных практических задач.
Одним из самых известных и обсуждаемых проектов в области распределенных вычислений является Hadoop — разрабатываемый фондом Apache Software Foundation свободно распространяемый набор из утилит, библиотек и фреймворк для разработки и выполнения программ распределенных вычислений.
Мы уже давно используем Hadoop для решения собственных практических задач. Результаты нашей работы в этой области стоят того, чтобы рассказать о них широкой публике. Эта статья — первая в цикле о Hadoop. Сегодня мы расскажем об истории и структуре проекта Hadoop, а также покажем на примере дистрибутива Hadoop Cloudera, как осуществляется развертывание и настройка кластера.
Немного истории
Автор Hadoop — Дуг Каттинг, создатель известной библиотеки текстового поиска Apache Lucene. Название проекта представляет собой имя, которое сын Дуга придумал для своего плюшевого желтого слона.
Каттинг создал Hadoop, работая над проектом Nutch — системой веб-поиска с открытым кодом. Проект Nutch был запущен в 2002 году, но очень скоро его разработчики поняли, что имеющуюся архитектуру вряд ли удастся масштабировать на миллиарды веб-страниц. В 2003 году была опубликована статья с описанием распределенной файловой системы GFS (Google File System), использовавшейся в проектах Google. Такая система вполне могла бы справиться с задачей хранения больших файлов, генерируемых при обходе и индексировании сайтов. В 2004 году команда разработчиков Nutch взялась за реализацию такой системы c открытым кодом — NDFS (Nutch Distributed File System).
В 2004 году компания Google представила широкой аудитории технологию MapReduce. Разработчики Nutch уже в начале 2005 года создали полноценную реализацию MapReduce на базе Nutch; вскоре после этого все основные алгоритмы Nutch были адаптированы для использования MapReduce и NDFS.
В 2006 году Hadoop был выделен в независимый подпроект в рамках проекта Lucene.
В 2008 году Hadoop стал одним из ведущих проектов Apache. К тому времени он уже успешно использовался в таких компаниях, как Yahoo!, Facebook и Last.Fm.
Сегодня Hadoop широко используется как в коммерческих компаниях, так и в научных и образовательных учреждениях.
Структура проекта Hadoop
В состав проекта Hadoop входят следующие подпроекты:
Ранее в Hadoop входили другие подпроекты, которые теперь являются самостоятельными продуктами Apache Software Foundation:
Дистрибутивы Hadoop
Сегодня Hadoop представляет собой сложную систему, состоящую из большого числа компонентов. Установить и настроить такую систему самостоятельно — весьма непростая задача. Поэтому многие компании сегодня предлагают готовые дистрибутивы Hadoop, включающие инструменты развертывания, администрирования и мониторинга.
Дистрибутивы Hadoop распространяются как под коммерческими (продукты таких компаний, как Intel, IBM, EMC, Oracle), так и под свободными (продукты компаний Cloudera, Hortonworks и MapR) лицензиями. О дистрибутиве Cloudera Hadoop мы расскажем более подробно.
Cloudera Hadoop
Cloudera Hadoop представляет собой полностью открытый дистрибутив, созданный при активном участии разработчиков Apache Hadoop Дуга Каттинга и Майка Кафареллы. Он распространяется как в бесплатном, так и в платном варианте, известном под названием Cloudera Enterprise.
На тот момент, когда мы заинтересовались проектом Hadoop, Cloudera предоставляла наиболее законченное и комплексное решение среди открытых дистрибутивов Hadoop. За все время работы не было ни одной значительной неполадки, и кластер благополучно пережил несколько мажорных обновлений, прошедших полностью автоматически. И вот спустя почти год экспериментов можем сказать, что довольны сделанным выбором.
Cloudera Hadoop включает следующие основные компоненты:
Аппаратные требования
Требования к аппаратному обеспечению для развертывания Hadoop — достаточно сложная тема. К разным узлам в составе кластера предъявляются разные требования. Более подробно об этом можно прочитать, например, в рекомендациях компании Intel или в блоге компании Cloudera. Общее правило: больше памяти и дисков! В RAID-контроллерах и прочих enterprise радостях нет необходимости в силу самой архитектуры Hadoop и HDFS, рассчитанных на работу на типовых простых серверах. Использование 10Гб сетевых карт оправдано при объемах данных более 12ТБ на ноду.
В блоге Cloudera приводится следующий список аппаратных конфигураций для различных вариантов загрузки:
Отметим, что в случае аренды серверов потери от неудачно выбранной конфигурации не так страшны, как при покупке своих серверов. При необходимости вы сможете модифицировать арендуемые серверы или заменить их на более подходящие для ваших задач.
Перейдем непосредственно к установке нашего кластера.
Установка и настройка ОС
Для всех серверов мы будем использовать CentOS 6.4 в минимальной установке, но можно использовать и другие дистрибутивы: Debian, Ubuntu, RHEL, etc. Необходимые пакеты имеются в открытом доступе на archive.cloudera.com и устанавливаются стандартными пакетными менеджерами.
На сервере Cloudera Мanager рекомендуем использовать программный или аппаратный RAID1 и один корневой раздел, можно вынести на отдельный раздел /var/log/. На серверах, которые будут добавлены в hadoop-кластер, рекомендуем создать два раздела:
На всех серверах, включая сервер Cloudera Manager, необходимо отключить SELinux и фаервол. Можно, конечно, этого не делать, но тогда придется потратить много времени и сил на тонкую настройку политик безопасности. Для обеспечения безопасности рекомендуется максимально изолировать кластер от внешнего мира на уровне сети, например, используя аппаратный фаервол или изолированный VLAN (доступ к зеркалам организовать через локальный прокси).
Предлагаем примеры готовых kickstart файлов для автоматической установки серверов Cloudera Manager и нод кластера.
Установка Cloudera Manager
Начнем с установки Cloudera Manager, который затем сам развернет и настроит наш будущий Hadoop-кластер на серверах.
Перед установкой нужно обязательно убедиться в том, что:
Добавим зеркало Cloudera и установим необходимые пакеты:
По окончанию установки запускаем стандартную БД (для простоты будем использовать её, хотя можно подключить любую стороннюю) и сам сервис CM:
Развертывание кластера Cloudera Hadoop
После установки Cloudera Manager можно забыть о консоли, всё дальнейшее взаимодействие с кластером мы будем осуществлять, используя веб-интерфейс Cloudera Manager. По умолчанию Cloudera Manager использует 7180 порт. Можно использовать как DNS-имя, так и IP-адрес сервера. Введем этот адрес в строку браузера.
На экране появится окно входа в систему. Логин и пароль для входа — стандартные (admin, admin). Конечно же, их нужно незамедлительно поменять.
Откроется окно с предложением выбрать версию Cloudera Hadoop: бесплатную, пробную на 60 дней или платную лицензию:
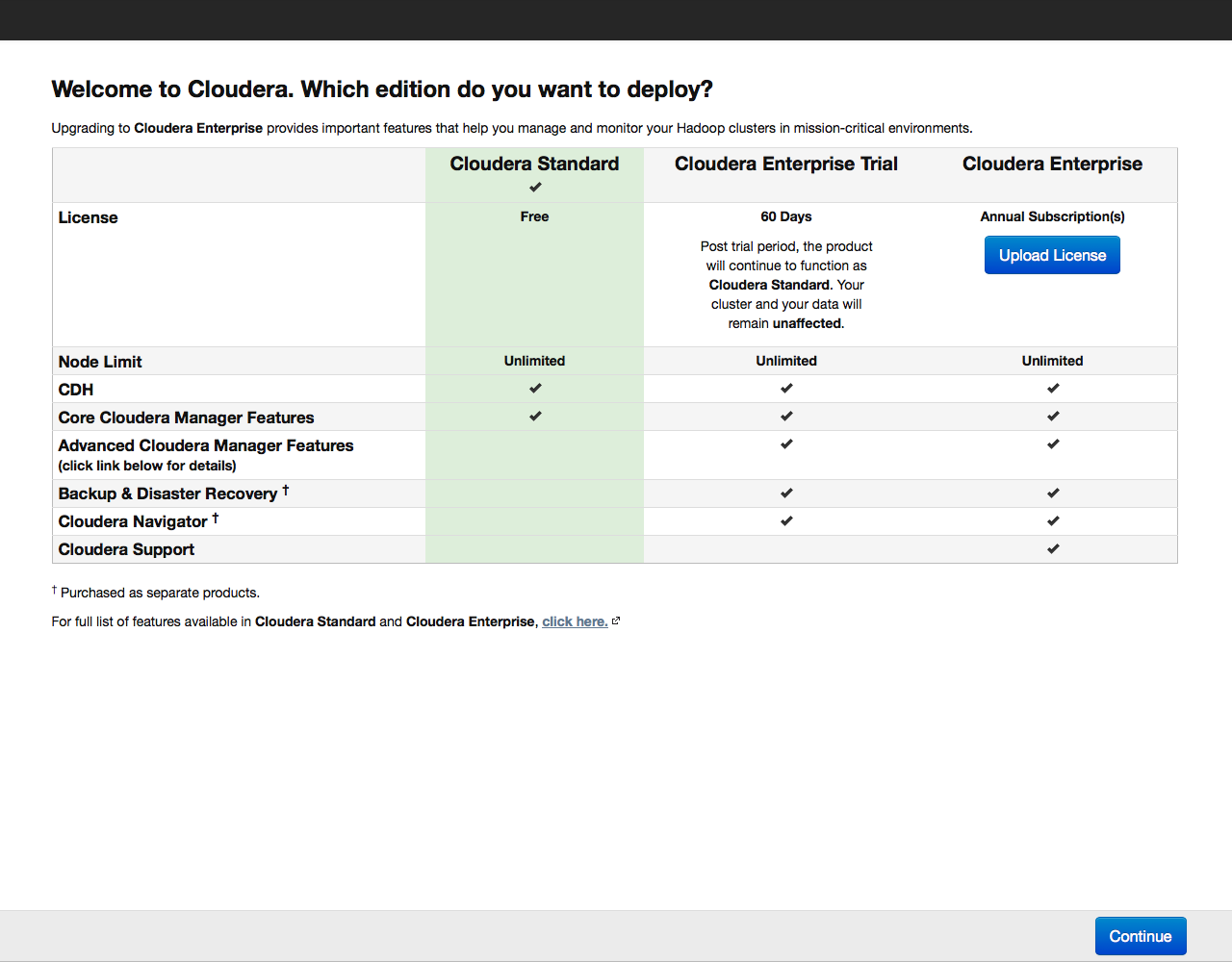
Выбираем бесплатную (Cloudera Standard) версию. Триал или платную лицензию можно будет активировать позже в любой момент, когда вы уже освоитесь с работой с кластером.
Во время установки сервис Cloudera Manager будет подключаться по SSH к серверам, входящим в кластер; все действия на серверах он выполняет от имени пользователя, указанного в меню, по умолчанию используется root.
Далее Cloudera Manager попросит указать адреса хостов, где будет установлен Cloudera Hadoop:
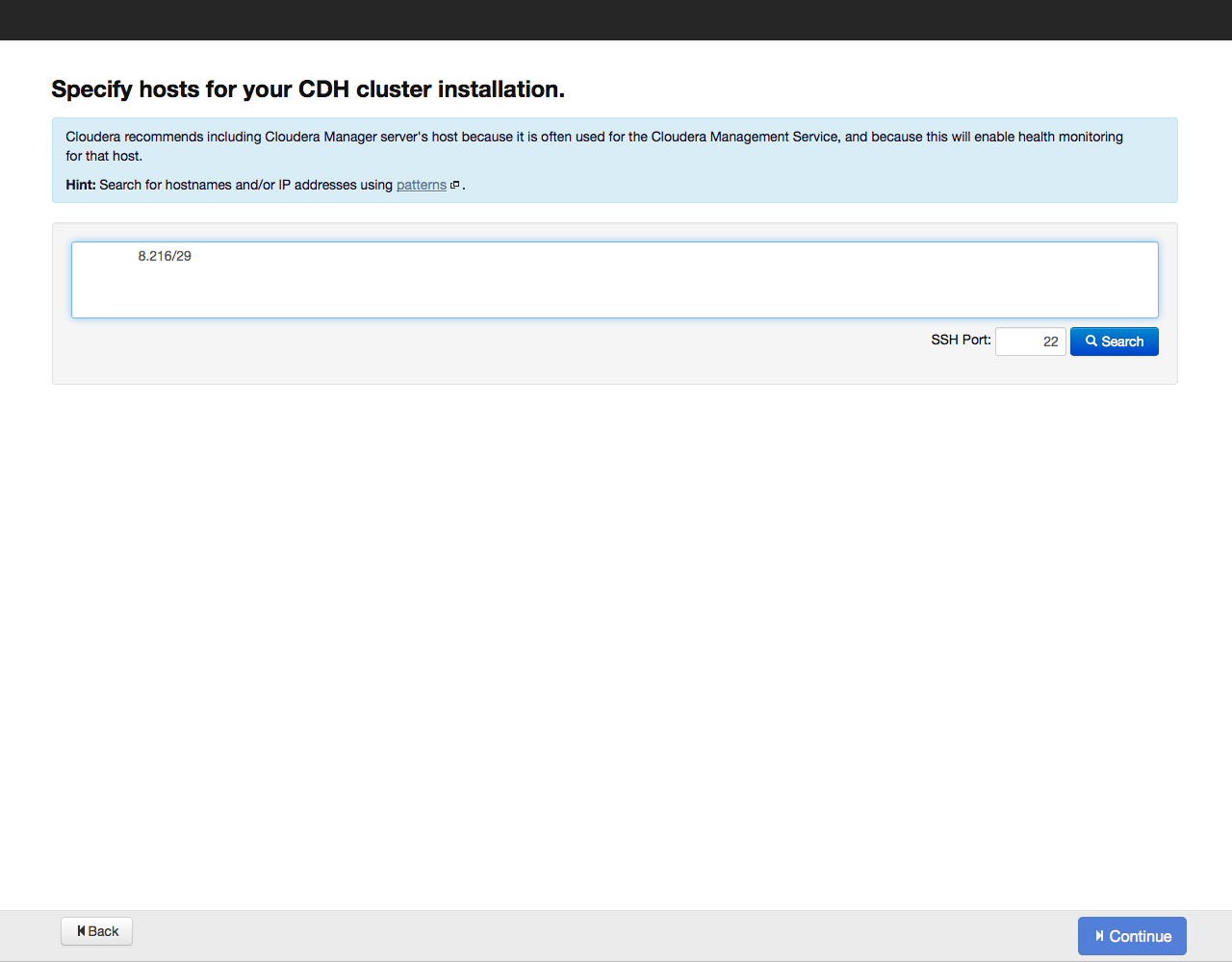
Адреса можно указать списком и по маске, например так:
После этого нажимаем на кнопку Search. Cloudera Manager обнаружит указанные хосты, и на экране будет отображен их список:
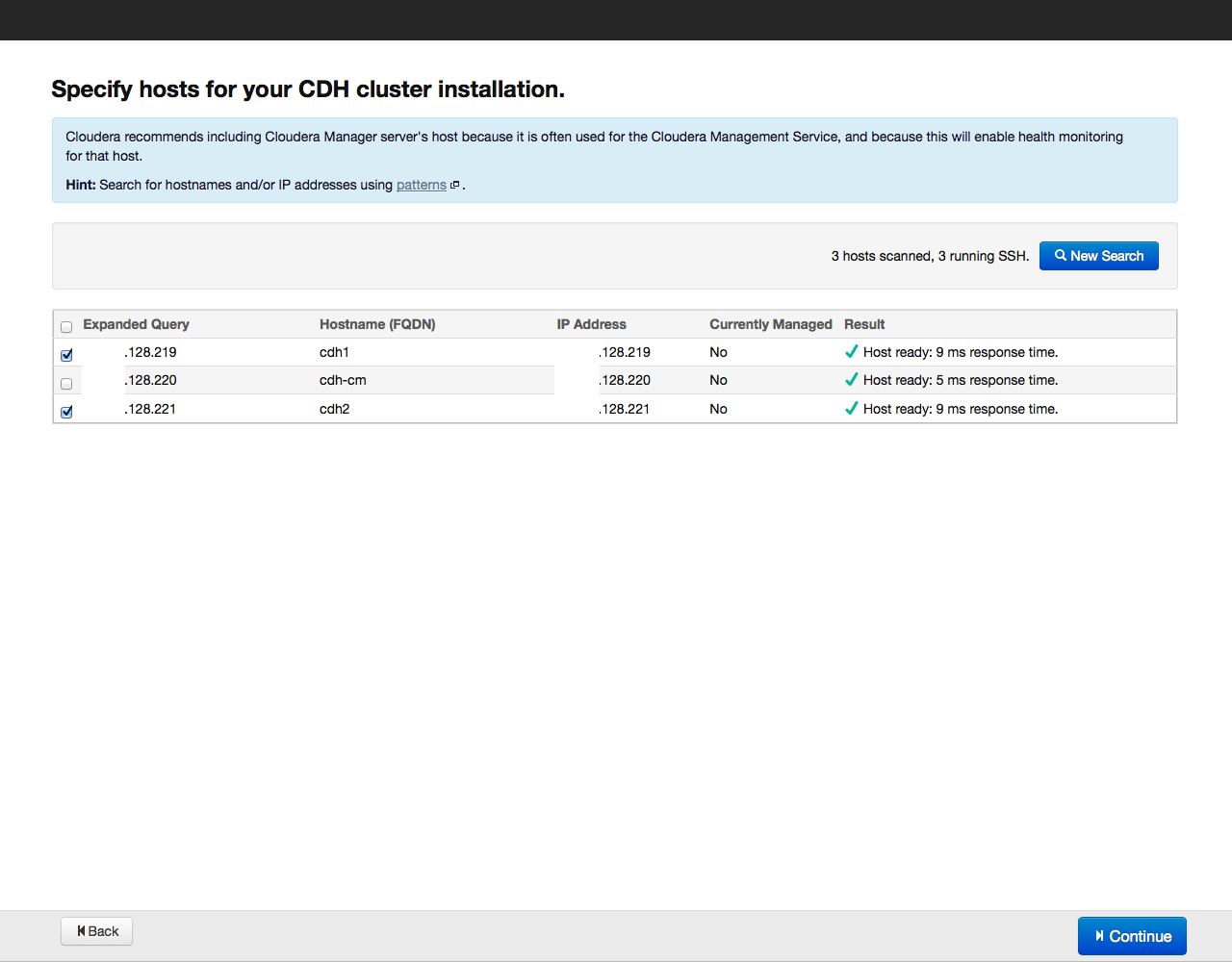
Еще раз проверяем, включены ли в этот список все нужные хосты (добавить новые хосты можно, нажав на кнопку New Search). Затем нажимаем на кнопку Continue. Откроется окно выбора репозитория:
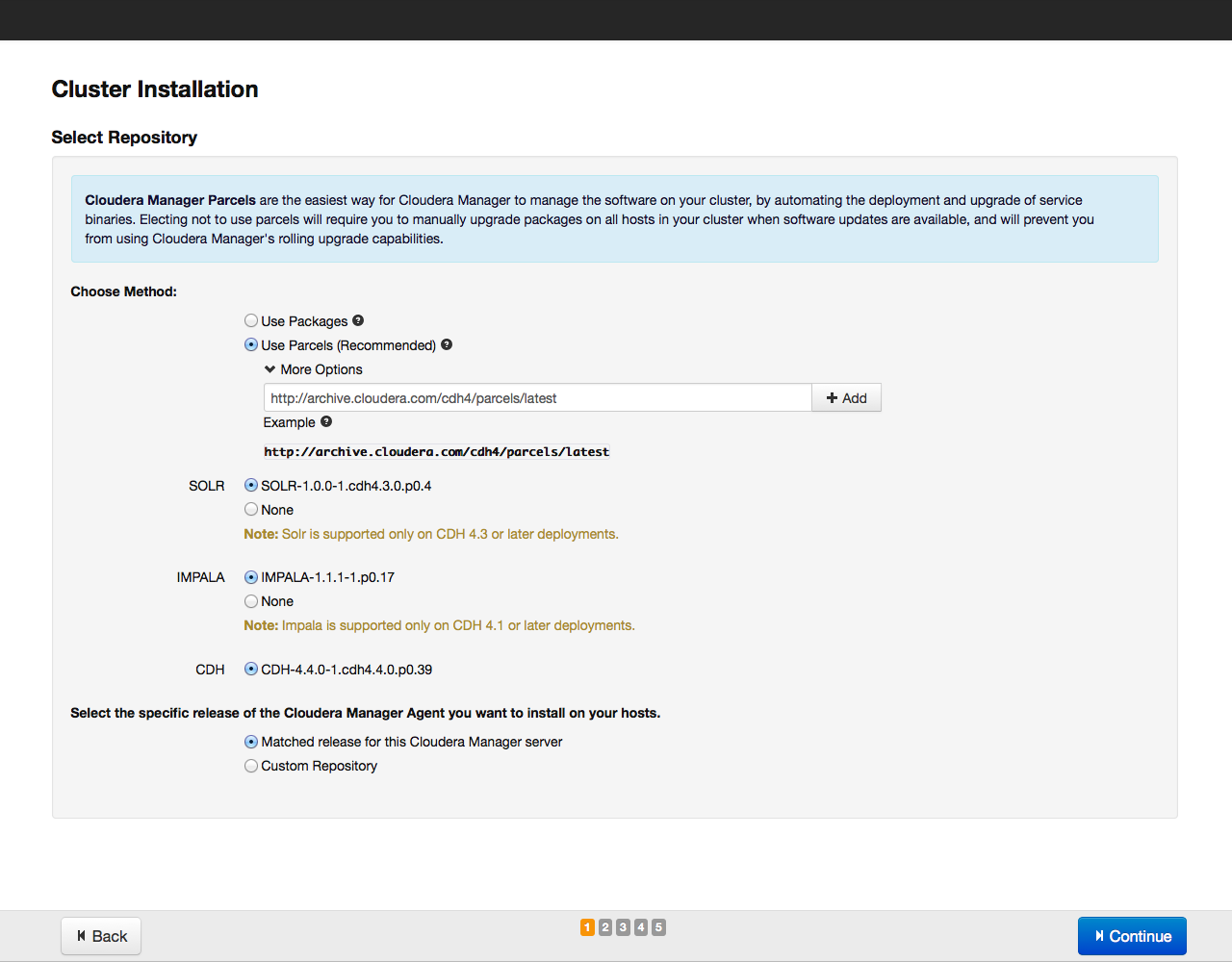
В качестве метода установки рекомендуем выбрать установку парселами, об их преимуществах мы уже рассказали ранее. Парселы устанавливаются из репозитория archive.cloudera.org. Помимо парсела CDH, из этого же репозитория можно установить поисковый инструмент SOLR и базу данных на основе Hadoop IMPALA.
Выбрав парселы для установки, нажимаем на кнопку Continue. В следующем окне указываем параметры для доступа по SSH (логин, пароль или закрытый ключ, номер порта для подключения):
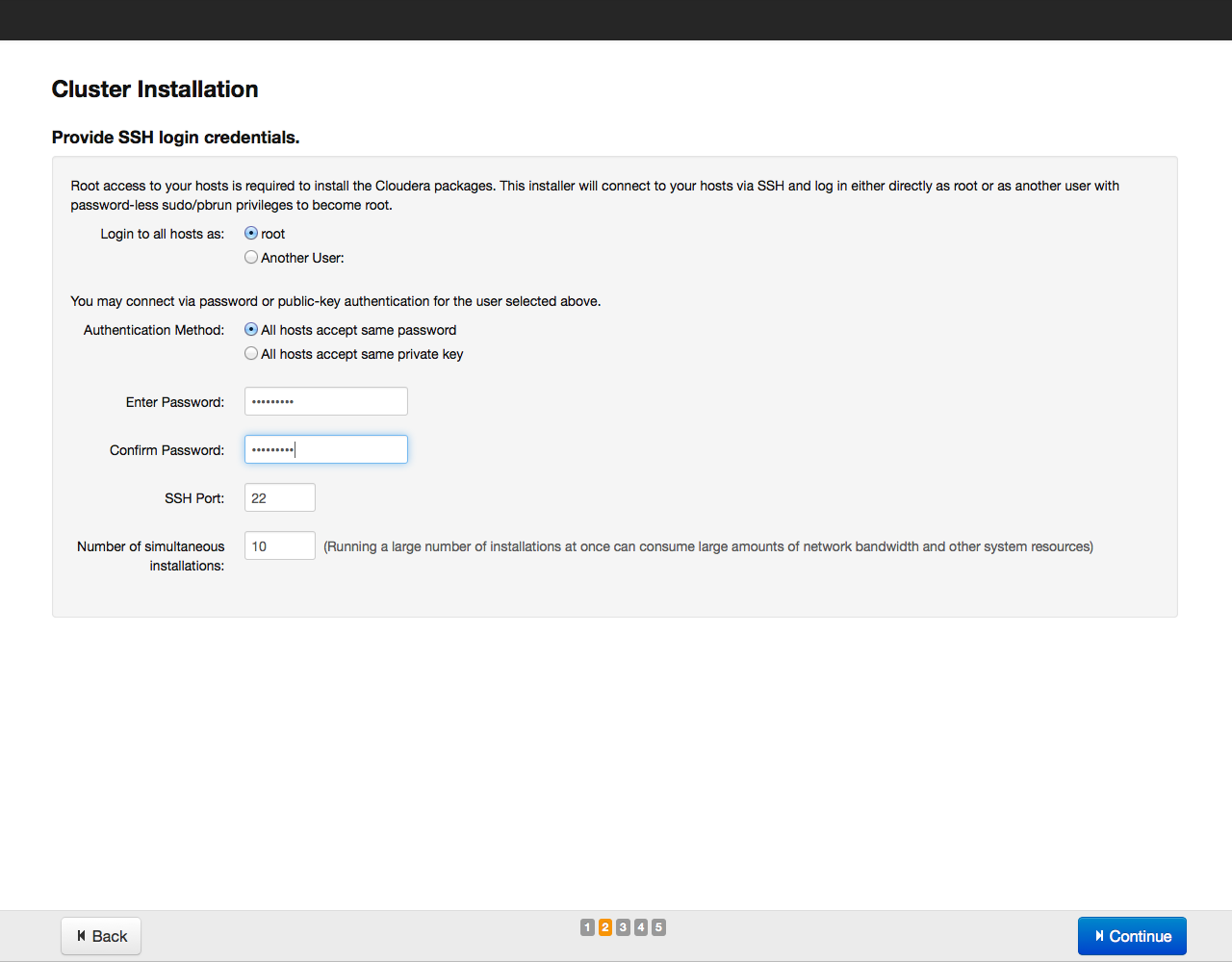
После этого нажимаем на кнопку Continue. Начнется процесс установки:
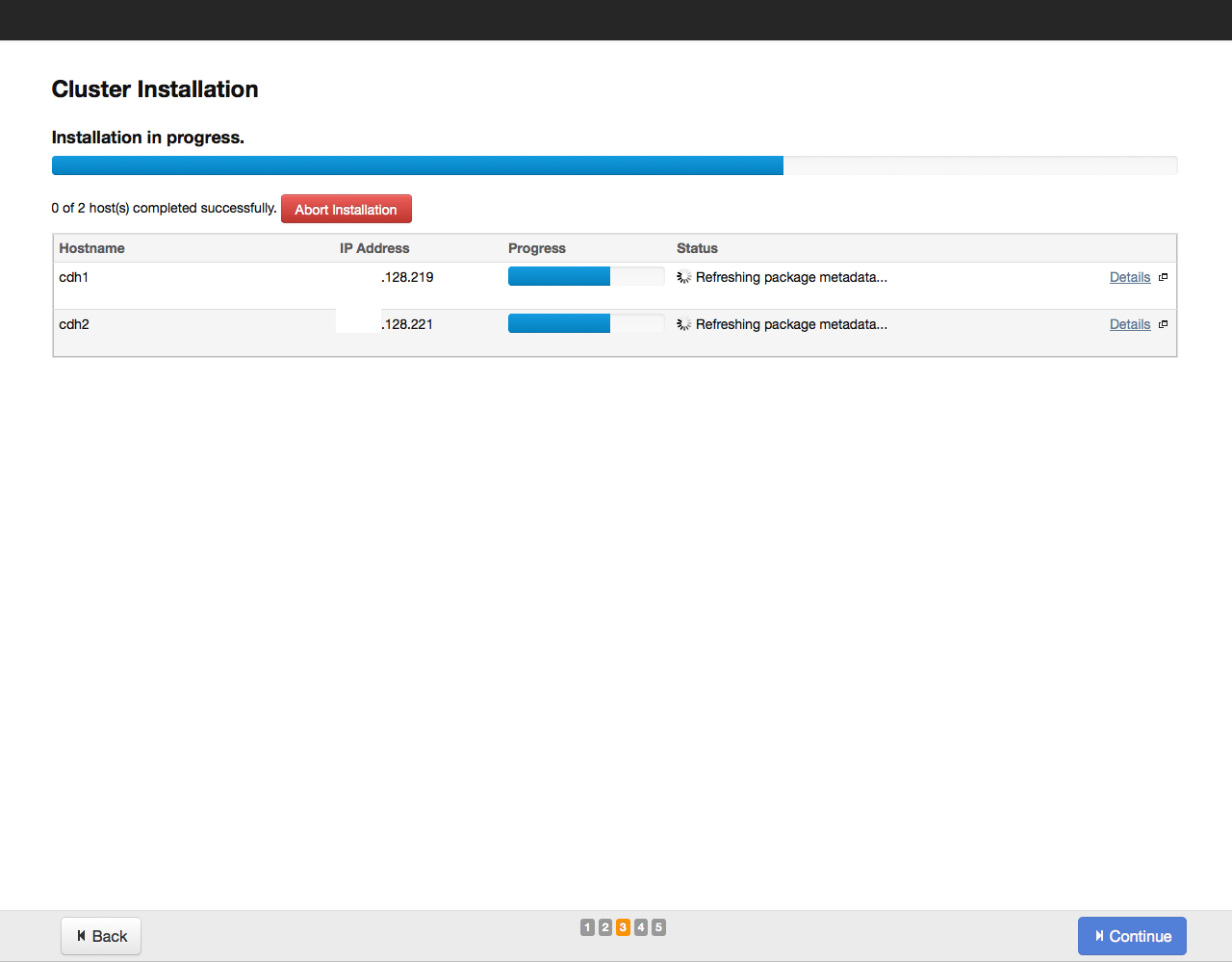
По завершении установки на экране отобразится таблица со сводной информацией об установленных компонентах и их версии:
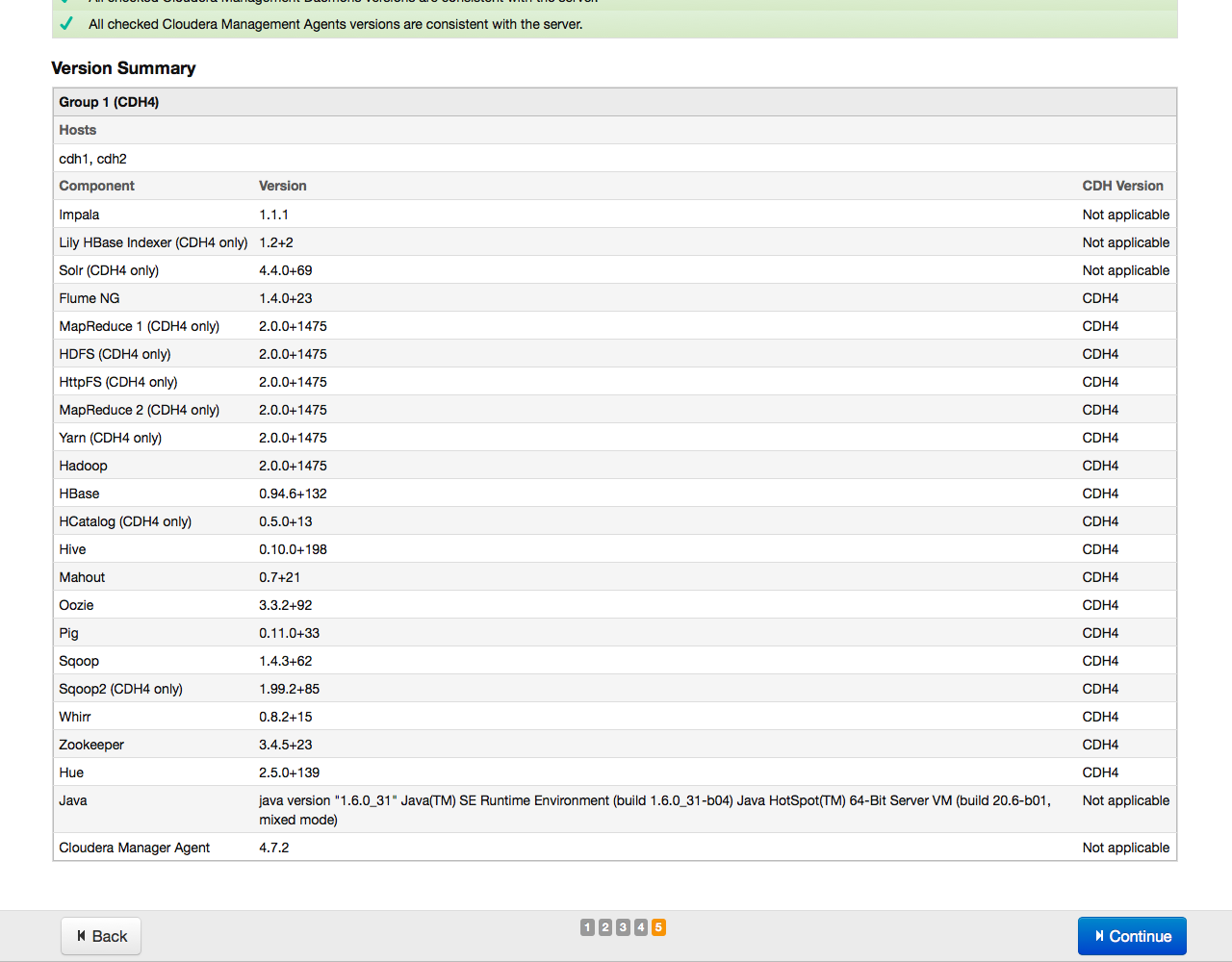
В очередной раз проверяем, все ли в порядке, и нажимаем на кнопку Continue. На экране появится окно с предложением выбрать компоненты и службы Cloudera Hadoop для установки:
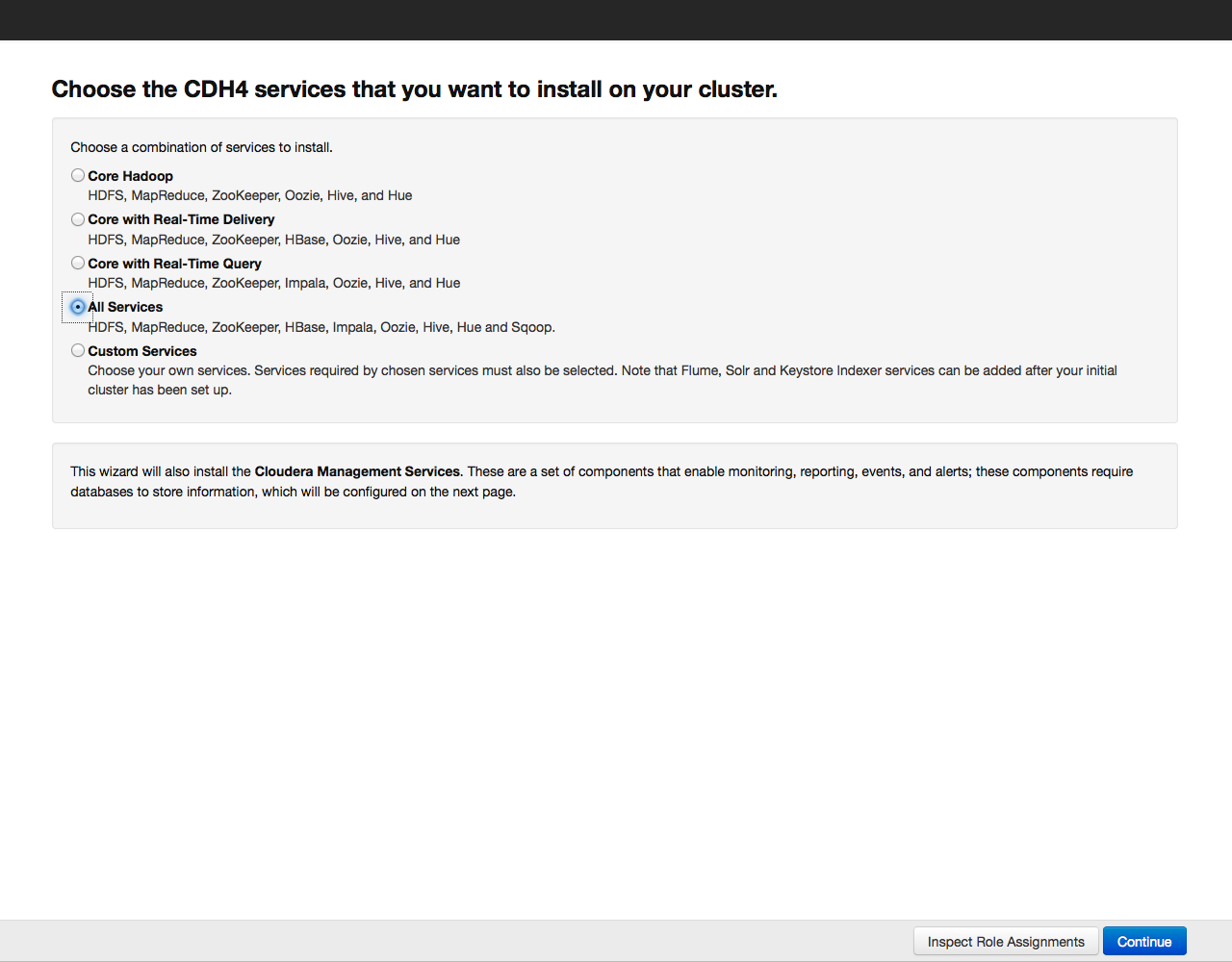
Для примера установим все компоненты, выбрав вариант «All Services», позже можно будет доустановить или удалить любые сервисы. Теперь необходимо указать, какие компоненты Cloudera Hadoop будут установлены на конкретных хостах. Рекомендуем довериться выбору по умолчанию, более подробно рекомендации по разположению ролей на нодах можно почитать в документации к конкретному сервису.
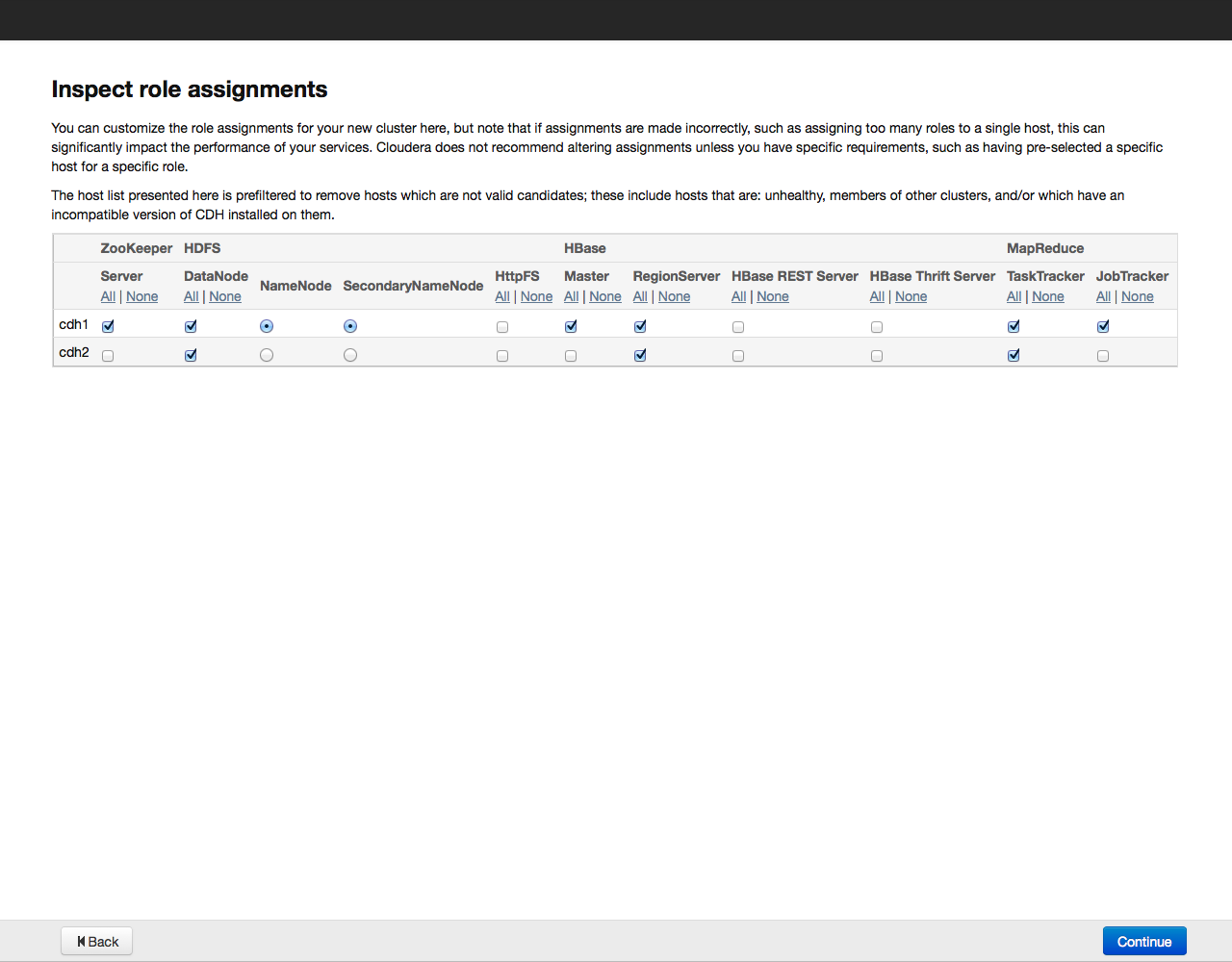
Нажимаем на кнопку Continue и переходим к следующему этапу — настройке базы данных:
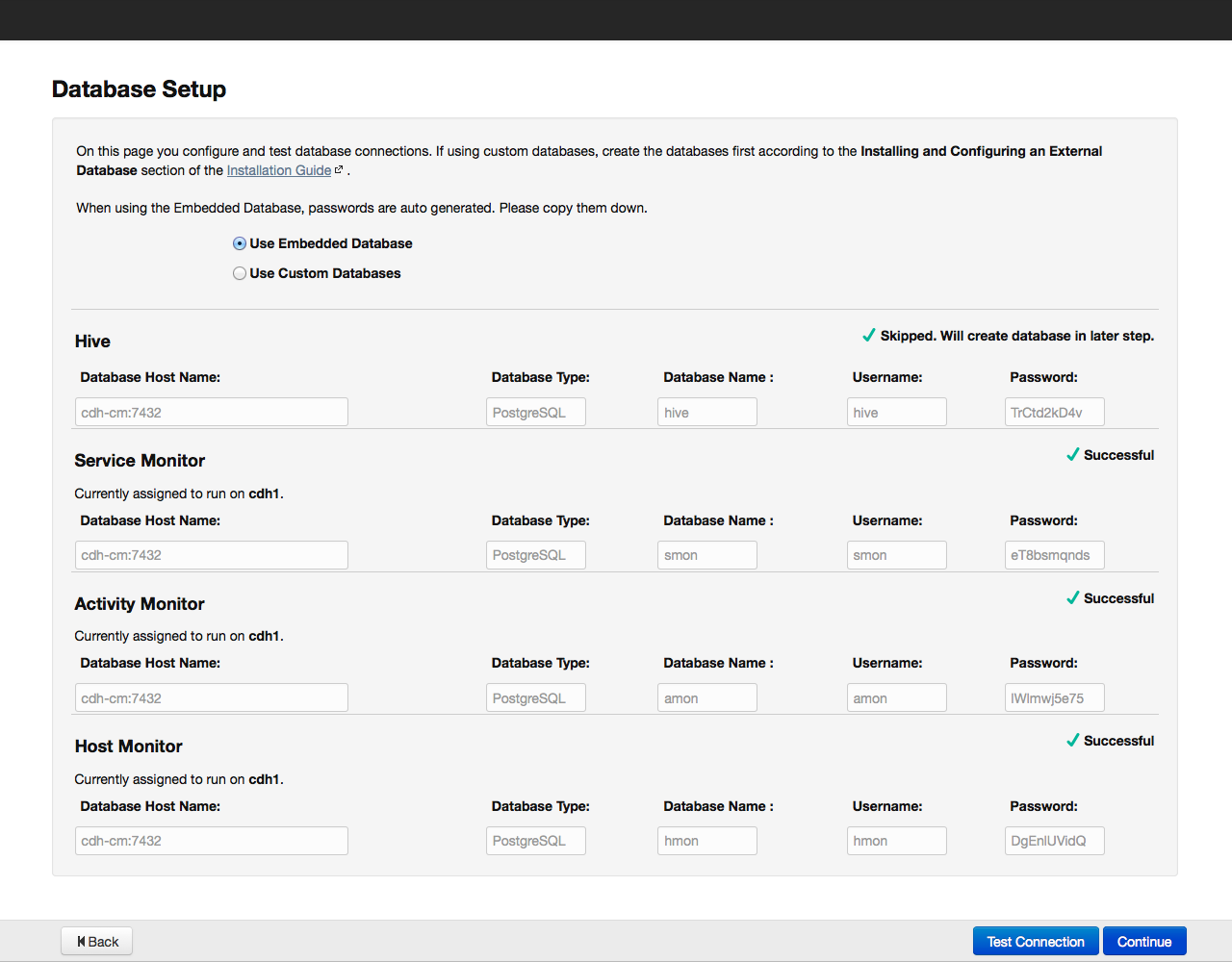
По умолчанию вся информация, имеющая отношение к мониторингу и управлению системой, хранится в базе данных PostgreSQL, которую мы установили вместе с Cloudera Manager. Можно использовать и другие базы данных — в этом случае выбираем в меню пункт Use Custom Database. Установив необходимые параметры, проверяем соединение с базой «Test Connection», и в случае успеха, нажимаем на кнопку «Continue» для перехода к настройке элементов в составе кластера:
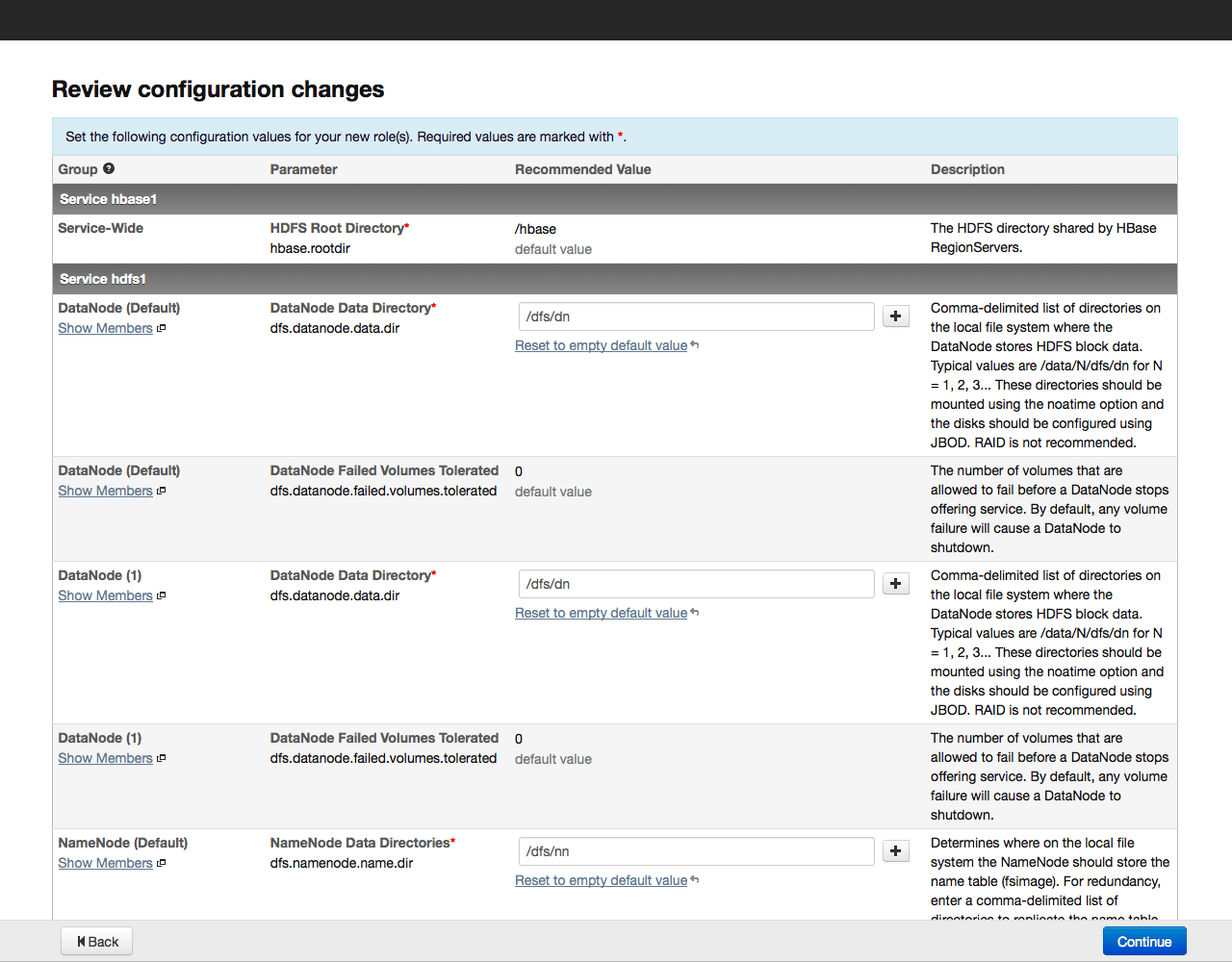
Нажимаем на кнопку Continue и запускаем тем самым процесс настройки кластера. Ход настройки отображается на экране:
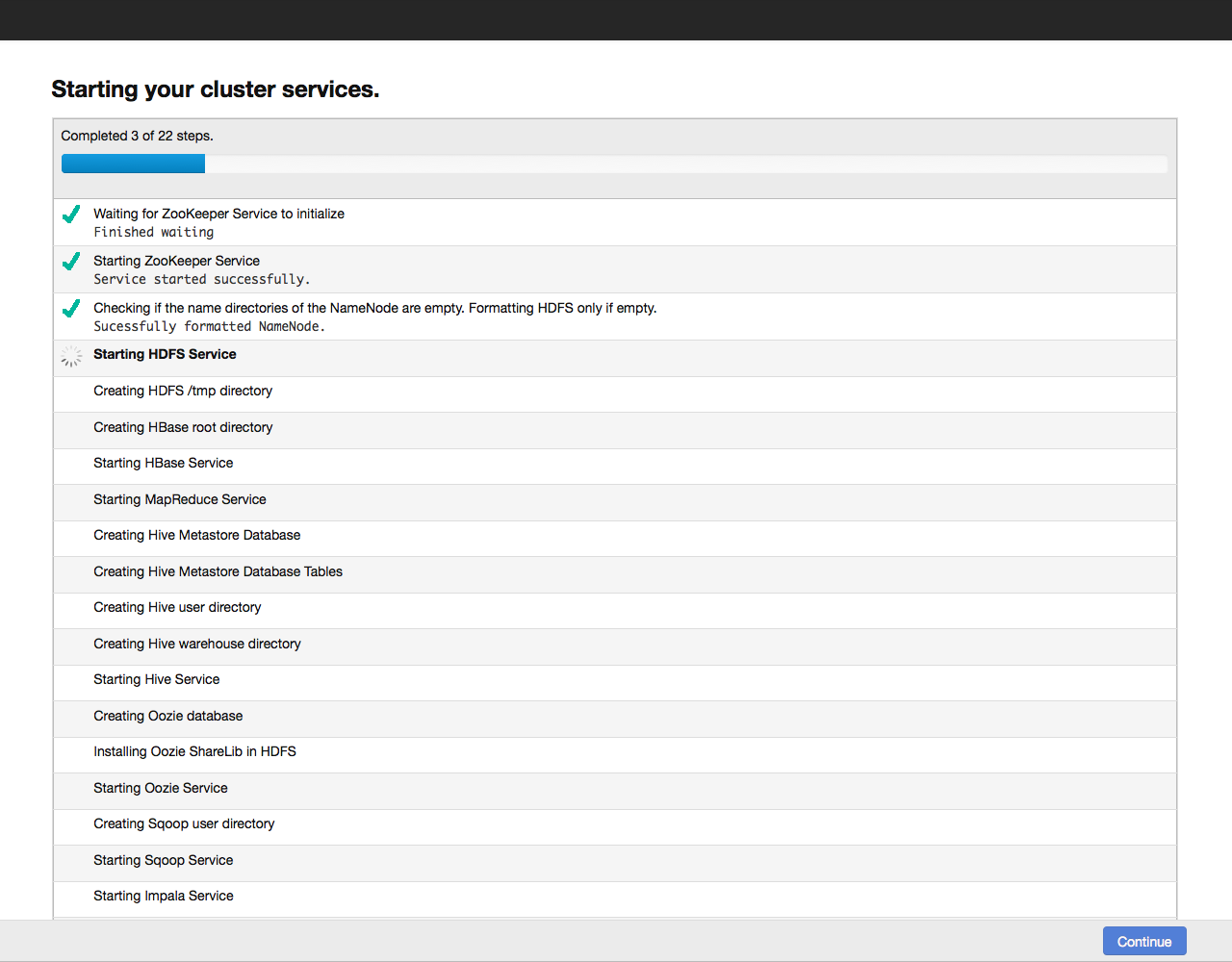
Когда настройка всех компонентов завершится, переходим к дашборду нашего кластера. Для примера вот так выглядит дашборд нашего тестового кластера:
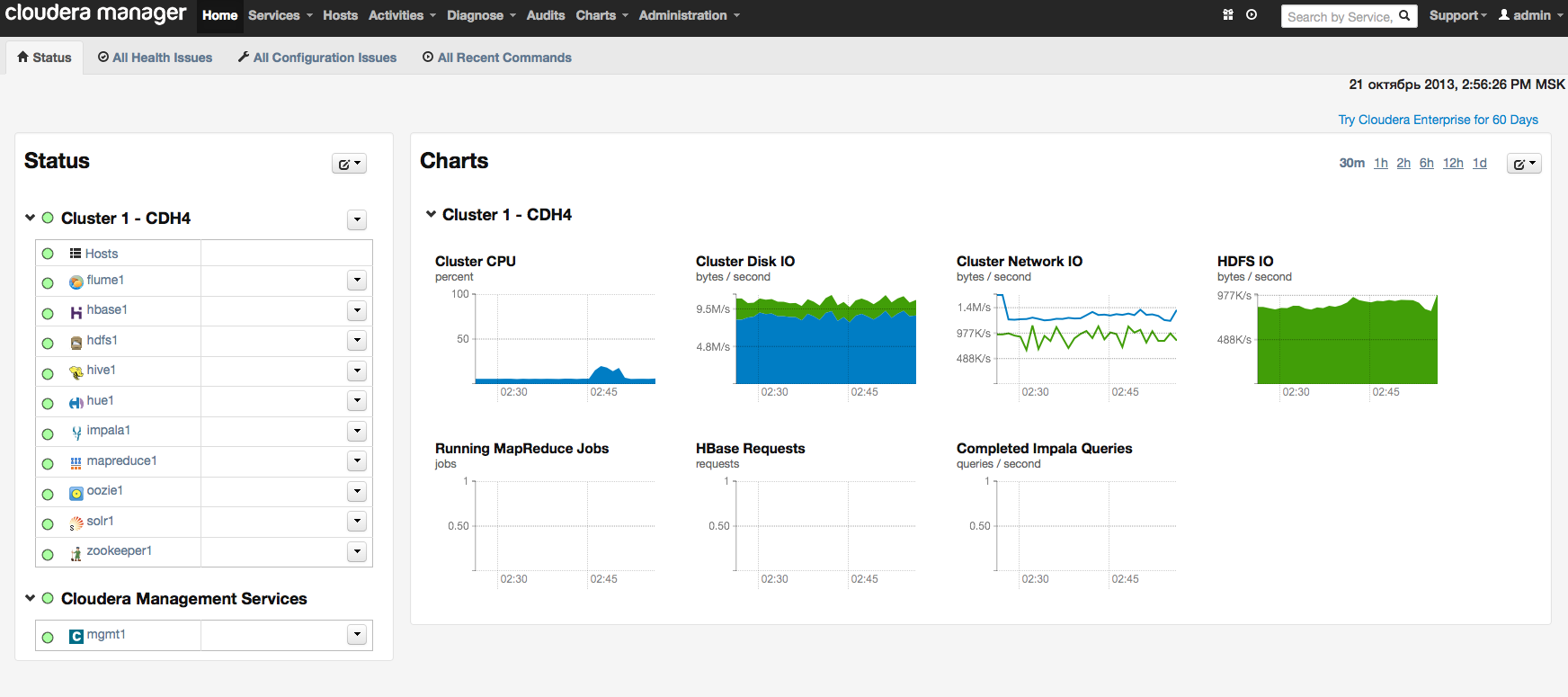
Вместо заключения
В этой статье мы постарались познакомить вас с установкой Hadoop кластера и показать, что при использовании готовых дистрибутивов, таких как Cloudera Hadoop это занимает совсем немного времени и сил. Продолжить знакомство с Hadoop я рекомендую с книгой Тома Уайта «Hadoop: The Definitive Guide», есть издание на русском языке.
Работа с Cloudera Hadoop на примере конкретных сценариев использования будет рассмотрена в следующих статьях цикла. Ближайшая публикация будет посвящена Flume — универсальному инструменту для сбора логов и других данных.
UPD: Адрес DNS — 109.234.159.91 более не поддерживается. Используйте адреса 188.93.16.19 и 188.93.17.19.
Simple administration for Apache Hadoop
Cloudera Manager is the industry’s trusted tool for managing Hadoop in production.
Cloudera Manager — making Hadoop easy
Automated deployment and configuration. The fastest way to get up and running with Hadoop and Cloudera Enterprise. Automated wizards let you quickly deploy your cluster, no matter what the scale or the deployment environment, complete with intelligent default settings based on your system. Ensure consistency as you move from testing to production, or across environments with portable cluster configuration templates. Through a centralized interface, your operations team can easily tune configurations and resourcing; manage a wide range of user roles for cross-departmental self-service access; and even manage multiple clusters for multi-tenant environments.
Customizable monitoring and reporting. Get complete visibility into your cluster with hundreds of built-in health checks and alerts that you can configure based on what matters most to you. Not only can you monitor all components across all clusters (including Cloudera Manager itself), you can also easily monitor jobs and query performance. Cloudera Manager has the industry’s only customizable dashboard, with the ability to create advanced charts for historical monitoring and custom triggers and thresholds for your environment.
Effortless, robust troubleshooting. The only centralized log management aggregates logs across all services and hosts, and makes them searchable for simple troubleshooting, including integrated, custom alerting for the errors you care about. Historical views and metrics let you see exactly what happened when, and allow you to quickly see anomalistic behavior. Cloudera Support is also directly integrated with Cloudera Manager, for proactive support and issue resolution based on your system and logs.
Zero downtime maintenance. Never worry about system downtime with comprehensive automations for rolling upgrades and rollbacks, so you always get the latest advancements without the hassle. High availability across components and built in backup and disaster recovery means you can run even your most critical workloads risk-free.
Инвестидея: Cloudera, потому что большие данные недооценены
Сегодня у нас крайне спекулятивная идея: взять акции облачного бизнеса Cloudera (NYSE: CLDR) после их недавнего падения в надежде на отскок.
Потенциал роста и срок действия: 33% за 20 месяцев; 12% годовых на протяжении 15 лет.
Почему акции могут вырасти: как говорил Клеанф, «желающего судьба ведет, нежелающего — тащит» — акции сильно упали, но фундамент бизнеса компании и перспективность сегмента облачных вычислений подтянут акции вверх.
Без гарантий
Наши размышления основаны на анализе бизнеса компании и личном опыте наших инвесторов, но помните: не факт, что инвестидея сработает так, как мы ожидаем. Все, что мы пишем, — это прогнозы и гипотезы, а не призыв к действию. Полагаться на наши размышления или нет — решать вам.
Если хотите первыми узнавать, сработала ли инвестидея, подпишитесь на Т—Ж в «Телеграме»: как только это станет известно, мы сообщим.
И что там с прогнозами автора
Исследования, например вот это и вот это, говорят о том, что точность предсказаний целевых цен невелика. И это нормально: на бирже всегда слишком много неожиданностей и точные прогнозы реализовываются редко. Если бы ситуация была обратная, то фонды на основе компьютерных алгоритмов показывали бы результаты лучше людей, но увы, работают они хуже.
Поэтому мы не пытаемся строить сложные модели. Прогноз доходности в статье — это ожидания автора. Этот прогноз мы указываем для ориентира: как и с инвестидеей в целом, читатели решают сами, стоит доверять автору и ориентироваться на прогноз или нет.
На чем компания зарабатывает
Это облачное ПО для обработки и аналитики данных. У компании есть довольно информативный ютуб-канал, где много рассказывается об этом бизнесе. Если суммировать всю эту информацию, то описание работы Cloudera выглядит так: программы для оптимизации сбора и анализа больших данных и организации корректной работы облачных вычислений.
Согласно годовому отчету, структура выручки выглядит следующим образом.
Подписка — 84% от выручки. Это использование ПО компании платными подписчиками. Валовая маржа сегмента — 82,37% от его выручки.
Услуги — 16% от выручки. Услуги настройки ПО, а также консультирования и обучения клиентов компании. Валовая маржа сегмента — 9,19% от его выручки.
Клиенты к компании приходят из очень разных отраслей: финансовый сектор, промышленность, государство, здравоохранение — да много откуда. На США приходится 62%, остальное — в других, неназванных странах.
Как победить выгорание
Аргументы в пользу компании
Сектор перспективный. Как и в других наших «облачных» идеях, например Appian и New Relic, здесь мы делаем ставку на возрастание объема обрабатываемых в интернете данных и рост спроса на сопутствующие услуги.
Благодаря пандемии потребление трафика в США в 2020 выросло в целом на 18%, и оно будет расти и дальше. В странах ОЭСР власти постепенно учатся вводить карантин, минимизируя последствия для падения экономики настолько, насколько это вообще возможно. А получается это только благодаря развитию облачных технологий, так что, учитывая последние тенденции — появление новых штаммов коронавируса, — повышенные темпы потребления трафика и нагрузка на вычислительные мощности только сохранятся. Впрочем, все было бы хорошо и без карантина, но пандемия, конечно, придала ускорение бизнесу Cloudera.
Также у компании очень небольшая капитализация — чуть меньше 4 млрд долларов, и это создает дополнительные возможности для ее акций. Очень вероятен вариант с их накачиванием руками розничных инвесторов, которые очень любят перспективные бизнесы. Еще покупка компании вполне посильна для какой-нибудь Google или Amazon.
Цена Cloudera относительно умеренная: общий объем целевого рынка компании составляет примерно 26 млрд долларов — доля Cloudera составляет около 3,34%. Капитализация компании, эквивалентная 15,3% рынка, на этом фоне выглядит неадекватно, но стоит помнить о двух вещах:
Акции упали, но зря. В этом месяце акции компании подешевели почти на треть как из-за биржевых обвалов, так и из-за отчетности: компания — ужас-ужас! — предсказывает в 2021 году рост выручки на 2% ниже того что ожидали аналитики. Более серьезное прегрешение: прогноз прибыли, рассчитанной не по GAAP, на 2021 сильно ниже ожиданий аналитиков — почти на 19%. Но такое падение стоимости акций несправедливо, поскольку компания постепенно снижает убытки и уже может быть недалек тот день, когда она станет прибыльной.
Учитывая перспективность сегмента облачных вычислений, компания выглядит хорошим вложением с потенциалом отскока, поскольку маржинальность ее бизнеса постепенно растет. Последний факт — это не секретная информация. Поэтому на основании этого акции могут начать брать розничные инвесторы, а какая-нибудь Amazon вполне может решить купить Cloudera. Ведь недавнее падение акций предоставляет редкую возможность приобрести перспективный актив по приемлемой цене.
Русские Блоги
Используйте Cloudera для развертывания и управления кластером Hadoop
1. Введение в Cloudera
В соответствии с потребностями использования, в кластере Hadoop должно быть установлено много компонентов, что затрудняет установку и настройку одного за другим, и необходимо учитывать HA, мониторинг и т. Д.
С Cloudera вы можете легко развернуть кластер, установить необходимые компоненты, а также отслеживать и управлять кластером.
Есть две версии Cloudera:
Cloudera Express версия бесплатна
Cloudera Enterprise (60-дневный пробный период) требует покупки регистрационного кода
2. Установите Cloudrea Manager и разверните кластер Hadoop
2.1 Способ установки
Сначала установите Cloudrea Manager, а затем установите клиент Cloudrea Manager, CDH и инструменты управления на узлах через Cloudrea Manager.
Официальная документация:
Требования к окружающей среде:
1. Закройте selinux
2. Каждый узел может войти через SSH
3. Добавьте имя хоста каждого узла в / etc / hosts
2.2 Установите Cloudrea Manager
Вы можете установить пакет через официальный клик или установить через yum или rpm.
Далее описывается установка с использованием официального установочного пакета в один клик.
test165 (cloudera manager server)
test166 (cloudera manager agent)
test167 (cloudera manager agent)
2.2.1 Скачать установочный пакет одним щелчком
Загрузите последнюю версию: cloudera-manager-installer.bin
2.2.2 Установить менеджер Cloudera
Установите сервер Cloudera Manager на test165, запустите мастер установки
# chmod a+x cloudera-manager-installer.bin
Появится следующий экран

Выберите и полностью, чтобы начать установку.

Необходимо скачать JAVA и Cloudrea Manager, в общей сложности более 600 МБ, в зависимости от ситуации в сети, это займет некоторое время.
Появится следующая страница, и установка завершена.

http: // IP или имя хоста: 7180 /

2.2.3 Установка агента управления Cloudera
Войдите на страницу Cloudrea Manager и выберите версию для установки. На этот раз Cloudera Express установлена
Выберите хост для установки CDH, выполните поиск по имени хоста или IP, на этот раз установите CDH на три узла

Выберите установку с помощью Parcel, выберите версию CDH

Выберите для установки JDK

Предоставьте информацию для входа в SSH

Начните установку JDK и агента управления Cloudera

Если загрузка и установка jdk или cloudera-manager-agent завершается неудачно в процессе установки, вы можете вручную установить его на узле, а затем продолжить установку в Cloudrea Manager.
Загрузите Parcel и назначьте Parcel каждому узлу

Стоимость пакета составляет около 1,5 г, это занимает некоторое время. Чтобы повысить скорость установки, вы можете загрузить пакет локально в Cloudrea Manager и настроить локальный источник.
Адрес загрузки посылки:
Скопируйте следующие файлы в папку / opt / cloudera / parcel-repo /
После завершения установки нажмите «Продолжить» на странице результатов проверки.

При проверке правильности работы хоста, предупреждение «Cloudera рекомендует установить / proc / sys / vm / swappiness на 0. Текущее значение равно 30.», предупреждение устанавливается следующим образом
При проверке правильности хоста появляется предупреждение «Прозрачная большая страница, это может привести к серьезным проблемам с производительностью», устанавливается следующим образом.
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
2.3 Установите кластер, включая Hadoop, YARN, Hive и т. Д.
После проверки правильности хоста, нажмите Finish, чтобы войти в конфигурацию кластера.
Выберите сервис для установки, вы можете выбрать комбинацию или пользовательские

Настроить, как распределить между узлами

Примечание: как минимум 3 узла данных HDFS.
Проверьте соединение с базой данных


3. Подтвердите, протестируйте
Убедитесь, что состояние кластера нормальное, а работа нормальная.
1. Подтвердите на странице кластера, что все службы работают нормально

2. Подтвердите на странице хоста, что состояние сердцебиения каждого узла нормальное и время составляет менее 15 секунд.

3. Запустите задачу для проверки
Войдите на любой хост в кластере и выполните следующие задачи (вычислите значение PI и число пи с помощью Hadoop)
Значение следующих двух числовых параметров: 10 относится к 10 задачам карты, которые нужно запустить, 10000 относится к тому, сколько раз было выброшено каждое задание карты, произведение двух параметров представляет собой общее количество бросков.

Результаты приведены ниже:

Статус выполнения задания можно подтвердить на странице YARN.

4. Другое
На странице Cloudrea Manager вы можете добавлять / удалять хосты в кластере, добавлять сервисы в кластер и т. Д.
На странице Cloudrea Manager открыта Google-Analytics, так как доступ из дома очень медленный, вы можете отключить Google-Analytics

5. Постскриптум
Интеллектуальная рекомендация
Генерация аудио PCM-данных в файлы WAV и MP3 с использованием FFMpeg
Справочник статей 1. Получить кодировщик и создать контекст декодера 2. Создайте аудио поток и выведите контекст обертки 3. Записать необработанные данные в файл Формат упаковки аудио WAV может хранит.

3. Wu Weida Machine Учебное примечание Полные сухие товары (глава 3: Линейный регрессионный обзор)

1053 Путь равного веса (30 очков)
1053 Путь равного веса (30 очков) Given a non-empty tree with root R, and with weight Wi assigned to each tree node Ti. The weight of a path from R to L&n.

1020 Tree Traversals
Главная мысль: Укажите количество узлов двоичного дерева, а также пост-порядок, результат прохождения среднего порядка и результат прохождения уровня. Идеи решения проблем: Подзадача о бинарном древе.

[OpenStack] Neenron Добавить ICMP и SSH правила (веб-интерфейс)
Вам нужно подготовить правила группы безопасности перед конфигурацией. Поскольку группа безопасности по умолчанию не позволяет Ping ICMP-пакеты и SSH удаленного входа в систему. Вам необходимо вручную.



