Edge computing заменит Cloud computing?

Мы с коллегами не так давно обсуждали динамичность развития технологий и перспективы развития облачных вычислений. И как раз наткнулась на статью.
Каждая новая технология приходит на смену старой. Иногда, как и в случае с облаком, проводится ребрендинг старых технологий, чтобы сделать их более привлекательными для потребителей и, тем самым, создать иллюзию нового продукта. Облачные вычисления ранее существовали в той или иной форме. На одном из этапов они назывались «on demand computing» (компьютерные ресурсы по требованию), а затем преобразовались в «application service provider» (ASP).
Теперь существует edge computing (прим. устоявшегося русского термина еще нет, но можно перевести, как «концепция граничных вычислений» или «периферийные вычисления»). которому отраслевые обозреватели и эксперты пророчат способность заменить облако. Но вот вопрос: произойдет ли это на самом деле? Ведь тоже самое говорили о радио, когда было изобретено телевидение. Тем не менее, миллионы людей каждый день включают радиоприемники, но оно изменило формат, теперь его слушают в основном в машине.
Конечно, есть некоторые технологии, которые действительно осуществляют переворот в том, что меняют привычки людей и их образ мышления. Когда-то люди слушали музыку с Sony Walkmans, а сегодня мы повсеместно используем для этого смартфон.
Пророчество Левина
Так почему же люди думают, что edge computing победит облако? Это утверждение было заявлено во многих статьях. Например, Клинт Бултон в марте этого года пишет об этом в статье «edge computing заменит облако». Он ссылается на венчурного капиталиста Эндрю Левина, генерального партнера Andreessen Horowitz, который считает, что больше вычислительных ресурсов будут двигаться в направлении оконечных устройств — таких, как беспилотный автомобиль и дроны, — которые составляют, по меньшей мере, часть Интернета вещей. Левин прогнозирует, что это будет означать то, что облаку пришел конец, т.к. процесс обработки данных будет двигаться назад по направлению к edge computing.
Другими словами, сейчас идет тенденция централизации вычислений в ЦОДах, в то время, как в прошлом они часто были децентрализованы или находились ближе к месту использования. Левин видит беспилотный автомобиль, как центр обработки данных: они имеют более чем 200 процессоров, способных обеспечить полную отказоустойчивость, чтобы не привести к несчастному случаю на дороге. Характер автономных транспортных средств означает, что их вычислительные мощности должны быть независимыми и для того, чтобы обеспечить безопасность нужно свести к минимуму любую связь, которую они имеют с облаком. Тем не менее, они не смогут полностью обойтись без него.
Взаимодополняющие модели
Эти два подхода могут дополнять друг друга. Часть аргументов за edge computing просто отпадает, когда речь заходит об увеличении объемов данных, которые приводят к еще более удручающей и медленной сети. Задержка – виновник. Данных становится все больше: увеличивается количество данных на одну транзакцию, «тяжелые» видео и много данных разных датчиков. Виртуальная и дополненная реальность будет играть все большую роль в его росте. При таком росте объема данных, решить проблемы задержки представляется более сложной задачей, чем это было раньше. Сейчас имеет смысл размещать данные ближе к устройствам типа беспилотного автомобиля для того, чтобы устранить задержку, но тем не менее большая часть данных всё-еще находится удаленно в облаке. Облако по-прежнему будет использоваться в качестве поставщика сервисов, таких как СМИ и развлечения. Оно также может быть использовано для резервного копирования данных и для обмена данными, исходящих от транспортного средства.
Немного отойдем от автономных транспортных средств и вернемся к более привычному бизнесу. Создание ряда небольших ЦОДов или площадок аварийного восстановления может уменьшить эффект масштаба, как следствие, увеличить затраты и сделать работу менее эффективной. Да, задержка может быть уменьшена, но в случае катастрофы последствия будут не менее плачевными; поэтому для обеспечения непрерывности бизнеса некоторые данные следует хранить и обрабатывать в другом месте – в облаке. В случае беспилотных машин, в частности, потому что они должны работать независимо от того, есть сетевое соединение или его нет, имеет смысл, чтобы определенные типы вычислений и анализа были совершены самим транспортным средством. Однако эти данные по-прежнему будут бэкапиться в облако, когда соединение доступно. Подход будет гибридным: edge и cloud computing будут взаимодополнять друг друга, а не использоваться по одиночке.
От периферии до облака
Сейджу Скария, старший директор консалтинговой фирмы TCS, предлагает несколько примеров, где edge computing может оказаться полезным. В своей статье на LinkedIn Pulse, «Edge computing vs. Облачные вычисления: за кем будущее?». Он не считает, что с облаком будет покончено.
«Edge computing не заменит облачные вычисления… на самом деле, аналитическая модель или правила могут быть созданы в облаке и затем применяться оконечными устройствами… и некоторые [из них] способны делать анализ». Затем он продолжает говорить о fog computing (туманные вычисления), которая включает в себя обработку данных от периферии до облака. Он считает, что люди не должны забывать о хранилищах данных, так как они используется для «медленных аналитических запросов и массивного хранения данных».
Edge победит облако
Несмотря на этот аргумент, аналитик компании Gartner Томас Битман считает, что «Edge computing «съест» облако». «Сегодня облачные вычисления пожирают центры обработки данных предприятий, все больше и больше нагрузок приходится на облако, а некоторые преобразовываются и перемещаются в облако… но есть еще одна тенденция, которая переместит рабочие нагрузки, данные и стоимость бизнеса далеко от облака… И тенденция перехода к edge computing еще более важная и сильная, чем когда-то была тенденция облачных вычислений.
Позже в своем блоге Битман пишет: «Не хватает одной только быстроты облачных решений. Массивная централизация, экономия от масштаба, самообслуживание и полная автоматизации преодолевает только полпути — но все это не преодолеет физику — вес данных, скорость света. Как люди должны взаимодействовать с цифровой реальностью в режиме реального времени, если происходит задержка от центра обработки данных, расположенного за тысячи километров. Задержка имеет большое значение. Я существую здесь и прямо сейчас. Воспроизвести правильную рекламу, прежде чем я не отвернулся, указать на магазин, который я ищу, когда я за рулём, помочь моему беспилотному автомобилю выбрать верный путь через оживленный перекресток. И все это мне нужно получить СЕЙЧАС».
Ускорение данных
Битман делает некоторые справедливые замечания, но он употребляет аргумент, который часто используется в отношении задержек и ЦОДов: они должны быть расположены близко друг к другу. Истина заключается в том, что глобальные сети всегда будут фундаментом edge computing и облачных вычислений. Во-вторых, Битману явно не попадались инструменты ускорения данных, такие, как PORTrockIT и WANrockIT. В то время как физика, безусловно, является ограничивающим и сложным фактором, который всегда будет иметь место в сетях всех видов – включая WANs, сегодня можно разместить свои центры обработки данных на расстоянии друг от друга. Задержка может быть уменьшена, и его воздействие может быть нивелировано, независимо от того, где происходит обработка данных, и независимо от того, где хранятся данные.
Поэтому, edge computing это не новое прорывное решение. Это лишь одно из решений, как и облако. Вместе эти две технологии могут поддержать друг друга. Различие между edge computing и облачными вычислениями, в том, что «edge являются методом ускорения и повышения производительности облачных вычислений для мобильных пользователей». Таким образом, аргумент, что edge computing заменит облачные вычисления является очень неубедительным. По маркетинговым соображениям, облачные вычисления могут быть переименованы, но суть останется та же.
Edge-ик в тумане и другие приключения периферийных вычислений
Меня зовут Игорь Хапов. Я руководитель разработки в Научно-техническом центре IBM. И сегодня я хотел бы вам помочь окунуться в мир периферийных вычислений, или edge computing, как его ещё называют. Я расскажу о том, что же такое edge computing и как он может повлиять на наш с вами мир. Также хотелось бы пояснить различия между edge computing и fog computing, какие преимущества даёт этот подход. В статье я также описал референсную архитектуру приложения на edge computing. И под конец немного расскажу о проекте с открытым исходным кодом Open Horizon, который совсем недавно присоединился к Linux Foundation.

Что же такое edge computing
Согласно определению Гартнера, edge computing — это подвид распределенных вычислений, в котором обработка информации происходит в непосредственной близости к месту, где данные были получены и будут потребляться. Это основное отличие edge computing от облачных вычислений, при которых информация собирается и обрабатывается в публичных или частных датацентрах. Основным отличием от локальных вычислений является то, что обычно edge computing — это часть большей системы, которая включает в себя сбор статистики, централизованное управление и удаленное обновление приложений на edge устройствах.
Что же такое edge устройство? Многие считают, что edge computing — это когда приложение работает на Raspberry Pi или других микрокомпьютерах. На самом деле edge computing может быть и на мобильных устройствах, персональных ноутбуках, умных камерах и других устройствах, на которых можно запустить приложение по обработке данных.
Edge computing и IoT
Довольно часто звучит вопрос — «Чем же отличается edge computing от IoT». IoT можно назвать дедушкой edge computing. IoT — это множество устройств, связанных между собой, и способных передавать информацию друг другу. А edge computing это скорее подход к организации вычислений и управлению edge устройствами. Как вы отлично понимаете, любое приложение необходимо обновлять, мониторить и осуществлять прочие обслуживающие функции. В результате edge computing подразумевает использование определенных подходов и фреймворков, о которых я расскажу чуть позже.
edge computing vs fog computing
Когда я однажды рассказал коллеге про edge computing, он ответил — ”так это же fog computing”. Давайте попробуем разобраться, в чём же разница. С одной стороны, edge computing и fog computing часто используются как синонимы, однако fog computing, или «туманные вычисления», все-таки немного отличаются.
И edge computing, и fog computing — это вычисления, которые находятся в непосредственной близости к получаемым данным. Различие заключается в том, что при туманных вычислениях обработка осуществляется на устройствах, которые постоянно подключены к сети. В edge computing вычисления осуществляются как на сенсорах, умных устройствах – без передачи на уровень gateway, так и на уровне gateway и на микрокластерах.
Для меня было открытием, что edge computing может работать в кластерах Kubernetes или OpenShift. Оказывается, что существует достаточно много задач, где кроме оконечных устройств необходимо выполнять обработку информации в локальном кластере и передавать в централизованные дата центры только результирующие данные. И такие вычисления — тоже edge computing.
Преимущества и недостатки edge computing
При выборе технологий для своего проекта я в первую очередь основываюсь на двух критериях — «Что я от этого получу?» и «Какие проблемы я от этого получу?».
Начнём с преимуществ:
Хотя, конечно, проектируя систему с edge computing, не стоит забывать, что как и любую другую технологию её стоит использовать в зависимости от требований к системе, которую вам необходимо реализовать.
Среди недостатков edge computing можно выделить следующие:
С одной стороны, последний пункт является наиболее критичным, но, к счастью, консорциум Linux Foundation Edge (LF EDGE) включает в себя всё больше и больше проектов с открытым исходным кодом, а их зрелость стремительно растет.
Принципы компании IBM при создании платформы edge computing
Компания IBM, являясь одним из лидеров в области гибридных облаков, использует определённые принципы при разработке решений для edge computing:
IBM применяет эти принципы при декомпозиции задачи построения фреймворка edge computing.

Как вы можете видеть, всё решение разбито на 4 сегмента использования:
Помимо основных принципов и подходов, IBM разработала референсную архитектуру для решений, основанных на edge computing. Референсная архитектура — это шаблон, показывающий основные элементы системы и детализированный настолько, чтобы иметь возможность адаптировать его под конкретное решение для заказчика. Давайте рассмотрим такую архитектуру более подробно.
Референсная архитектура edge computing
Edge devices
В первую очередь, у нас есть какое-либо встроенное или дискретное edge-устройство, к которому подключены сенсоры, датчики или управляющие механизмы, например, для координации движения роборуки. Из сервисов/данных на таком устройстве могут находиться:
Hybrid multicloud
Если мы говорим об использовании ML-модели, которая будет запускаться на десятках или тысячах устройств, то нам необходимо облако, которое сможет отвечать за обучение такой модели, обработку статистики, отображение сводной информации (правая часть архитектуры).
Edge server and Edge micro data center
Как мы уже говорили, можно встретить промежуточные (близкие) кластеры обработки данных на уровне шлюзов или микро-датацентров с установленной поддержкой кластерных технологий.
Edge framework
Когда мы осознаем, что есть необходимость в управлении большим количеством сервисов на тысячах устройств и сотнями приложений в разных кластерах, наступает понимание, что надо бы использовать какой-то фреймворк для управления всем этим зоопарком и синхронизации между устройствами.
Именно наличие данного фреймворка раскрывает преимущества edge computing перед разнородными разнесёнными вычислениями.
Как мы видим, кроме центральной части по управлению сервисами и моделями в данном фреймворке присутствуют агенты, обеспечивающие контроль за управлением жизненным циклом сервисов на устройствах/кластерах на каждом из уровней использования.
Open Horizon и IBM Edge Application Manager
Именно для решения задач в области edge computing IBM разработала и выложила в open-source проект Open Horizon. Если вы помните, один из принципов, которые IBM заложила в edge computing – все компоненты должны быть основаны на open source технологиях. В мае 2020 года проект Open Horizon вошел в Linux Foundation Edge — Международный фонд open-source технологий для созданий edge-решений. Также Open Horizon является ядром нового продукта от RedHat и IBM — IBM Edge Application Manager, решения для управления приложениями на всех устройствах edge computing: от Raspberry Pi до промежуточных кластеров обработки данных.
Несмотря на то, что проект Open Horizon вошел в консорциум только в мае, он уже достаточно давно развивается как open-source проект. И мы в Научно-техническом центре IBM не только успели его попробовать, но и довести свое решение до промышленного использования. О том, как мы разрабатывали проект с использованием edge computing, и что у нас получилось — будет отдельная статья, которая выйдет в ближайшие несколько недель.
Сценарии использования
С одной стороны, edge computing framework — это специализированное решение для определённого круга задач, но оно нашло применение во многих индустриях.
В своё время, когда я изучал работу московских камер “Стрелка”, я понял, что это в чистом виде edge computing, с вычислениями «прямо на столбе» и промежуточной обработкой данных в раздельных вычислительных кластерах у различных ведомств.
Сценарии нашлись в финансовом секторе, в продажах при самообслуживании, в медицине и секторе страхования, торговле и конечно при производстве. Именно в создании решения для автоматизации и оценки качества произведённого оборудования, основанного на edge computing, мне с коллегами из Научно-технического центра IBM и посчастливилось принять участие. И на своем опыте попробовать, как создаются решения edge computing.
Если Вас заинтересовала данная тематика, следите за обновлениями в хабраблоге компании IBM и смотрите видео в разделе Ссылки. Наши зарубежные коллеги к настоящему моменту уже осветили многие технические вопросы и описали, какие сценарии уже работают и применяются в различных отраслях.
Edge vs. Cloud: в чем разница?
Являются ли периферийные вычисления (Edge computing) своего рода ребрендингом облачных вычислений (Cloud computing) или это действительно что-то новое? Портал Enterprisers Project рассказывает о том, как работает Edge computing, для каких целей его применяют и как он сосуществует с облаком.
Перевод корпоративных операций в облако больше не является новой концепцией, чего не скажешь о периферийных вычислениях. О них часто упоминают в контексте 5G и Интернета вещей (IoT), так что это — разновидность облачных вычислений или отдельная технология?
Как правило, на передовом рубеже технологий всегда открывается простор для дискуссий по поводу того, что из себя представляет та или иная новинка, а также спектра ее применения. Edge computing — не исключение. Что подразумевается под периферийными вычислениями? «Периферийные вычисления могут применяться ко всему, что подводит обслуживание, данные и информацию ближе к пользователям и устройствам», — говорит технологический евангелист Red Hat Гордон Хафф. Другими словами, термин «периферийные вычисления» охватывает слишком большое пространство.
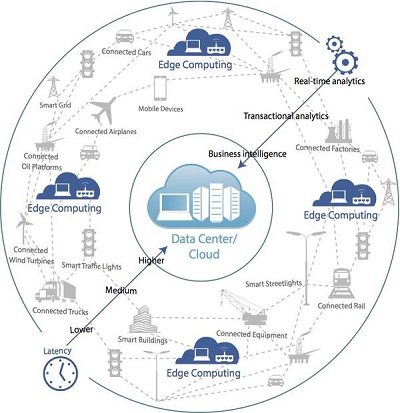
Предназначение Edge computing — перемещение вычислительных ресурсов из гипермасштабируемого облачного ЦОДа, который может находиться на значительном удалении (в «ядре» сети) ближе к пользователю или устройству, к «краю» сети. Этот подход акцентирует внимание на снижении задержек в сети и аккумуляции вычислительных мощностей для обработки данных вблизи их источника. Работая с помощью периферийной сети, мобильные приложения могли бы в большей степени задействовать алгоритмы искусственного интеллекта и машинного обучения, тогда как сейчас они полностью зависят от вычислительных возможностей мобильных процессоров. Помимо этого требующие интенсивных вычислений задачи гораздо быстрее разряжают аккумуляторы телефона.
Edge computing также связывают с такими областями, как автономные автомобили, дополненная реальность, промышленная автоматизация, прогнозное обслуживание и видеонаблюдение.
Где важна производительность вычислений
Для начала можно рассмотреть пример с автономными автомобилями и сетевыми системами, которые требуются для их поддержки. Обновление навигационного ПО одновременно для всего автомобильного парка, как это уже делают Tesla и другие автопроизводители, идеально подходит для облачных вычислений. С другой стороны, решение о том, следует ли повернуть налево или направо, чтобы избежать столкновения с перебегающим улицу пешеходом, должно приниматься незамедлительно, поэтому у бортового компьютера, безусловно, не будет времени ждать ответа от сервера в удаленном ЦОДе. Таким образом, между ними должна быть какая-то связующая технология, чтобы ускорить реакцию бортового компьютера.
В качестве промежуточного решения между сервером и дата-центром может выступать подключенная транспортная система, вычислительные узлы которой располагались бы на границе сети — в светофорах и вышках сотовой связи. Например, если один водитель движется навстречу другому по встречной полосе, второму нужно отдать указание своей машине, в какую сторону свернуть с дороги, чтобы избежать столкновения. Излишне говорить, что реакция на нетипичное поведение на дороге должна исчисляться миллисекундами. С учетом того, что гипотетическая автономная транспортная система работает в мобильных сетях 5G, пропускная способность и низкая задержка этой сетевой технологии ускорят подключение к транспортным средствам и датчикам на дорогах.
Вопрос заключается том, куда дальше пойдет сигнал после того, как он достигнет ближайшего узла мобильной сети? В ситуациях, когда речь идет о жизни или смерти, требуется, чтобы данные обрабатывались возле обочины или как можно ближе к ней — это позволит получить уведомление о назревающей опасности столкновения в нужное время, когда еще имеется возможность сохранить жизнь. «Сигнал с вышки сотовой связи передается по оптоволокну. Это происходит молниеносно, но даже у скорости света есть физические пределы, и если вам нужно связаться с центром обработки данных, который отстоит от вас на 2000 миль, то это чревато большой задержкой», — говорит председатель совета директоров OpenTechWorks и член технологического консультативного комитета FCC Адам Дробот, один из соавторов справочника FCC по 5G, периферийным вычислениям и IoT.
«Решения, которым требуется производительность в режиме реального времени, будут выполняться на периферии сети», — отмечает Дробот. По его словам, Edge computing займет свое место в спектре вычислительных и коммуникационных технологий как еще одна технология, с помощью которой системные архитекторы смогут размещать вычислительные рабочие нагрузки не локально или в облаке, а на периферии сети. Дробот добавляет, что возможности играть важную роль в будущем компьютерных вычислений особенно рады мобильные операторы: «За каждой вышкой сотовой связи закреплена „собачья будка“, что является особым поводом для радости». На жаргоне операторов «собачьими будками» называют укрытия для телеком-оборудования. Расчет строится на том, что когда-то они смогут превратить их в миниЦОДы, предоставляющие периферийные услуги.
Телекоммуникационные компании сегодня активно обсуждают потенциал 5G, но, как и мобильные операторы, они также нуждаются в периферийных вычислениях, говорит главный консультант и руководитель практики периферийных вычислений консалтинговой компании STL Partners Далия Адиб. «Целевые значения задержек для 5G практически невозможно получить без Edge», — отмечает она, добавляя, что эти две технологии взаимозависимые и будут нуждаться друг в друге для достижения зрелости.
Наглядный пример промышленного применения периферийных вычислений для прогнозного обслуживания оборудования в заводских цехах предлагает Siemens. В этом примере робот забирает с конвейера электронные компоненты и укладывает их в упаковку для отправки. В случае, когда робот ломается, продукты падают на пол, и линия останавливается для экстренного ремонта. Чтобы избежать дорогостоящей остановки оборудования и заблаговременно запланировать техническое обслуживание, его мониторинг проводит периферийное устройство, обладающее большей вычислительной мощностью, чем некоторые роботы. Считывая данные их датчиков, которые используются для прогнозирования сбоя отдельных компонентов, оно может установить точное время выхода из строя таких деталей, как, например, втягивающий захват робота. Приложение на периферийном устройстве передает данные в еще более мощные системы машинного обучения в облаке, которые улучшают алгоритмы прогнозирования и обновляют его данные.
Edge не заменяет публичные облака
На заре облачных вычислений бытовало мнение, что однажды они будут предоставляться в виде традиционных коммунальных услуг, к примеру, как поставки электричества, напоминает Хафф. «На самом деле централизованная доставка компьютерных вычислений никогда не выглядела реалистичной затеей. К тому же публичные облака сами по себе эволюционировали в ключе, который скорее нацелен на предложение дифференцированных услуг клиентам, поэтому поставщики облачных услуг всегда конкурировали друг с другом, а не с компаниями, которые предоставляют коммунальные услуги, — отмечает он. — Edge computing в более широком смысле — это понимание того, что по своей природе корпоративные вычисления гетерогенны и не терпят упрощенных подходов и шаблонов. Таким образом, они могут заменить публичные облака только в воображаемом мире, где последние бы замкнули на себе все рабочие нагрузки. Но в реальном есть место и для Edge computing».
Открытые возможности
Что касается распределения вычислений по периферийным точкам, то эта миссия будет возложена на некоторые контейнерные технологии, которые сегодня применяются для перемещения рабочих нагрузок между корпоративными системами и облаком. По словам Дробота, даже если системы для подсчета трафика и выставления счетов клиентам будут проприетарными, эра облачных вычислений преподнесла урок, который заключается в том, что наиболее успешные операции с вычислительными услугами связаны с ПО на базе Open Source и открытыми спецификациями.
Адиб говорит, что в прошлом многие из клиентов его компании, которые представляют промышленную, нефтегазовую и телекоммуникационную отрасли, уже обожглись на проприетарных устаревших технологиях. «Они стараются не повторять ошибок прошлого, — отмечает она. — Кроме того, они еще толком не знают, с кем будут работать, но им точно не понравится, если их попытаются замкнуть на каком-либо приложении или системе, из которых они при желании не смогут выбраться».
Производительность в реальном времени является одной из основных причин использования архитектуры периферийных вычислений, но не единственной. Помимо этого Edge computing позволяет предотвратить перегрузку сетевых магистралей за счет обработки значительной части данных локально, отправляя в облако только обязательный минимум. Еще одно преимущество — хранение данных вблизи источника позволяет лучше обеспечить их безопасность, конфиденциальность и суверенитет, чего сложнее добиться при их отправке в централизованную локацию.
Тем не менее, на пути продвижения периферийных вычислений стоит множество задач. В недавнем отчете Gartner «How to Overcome Four Major Challenges in Edge Computing» говорится, что «в 2022 г. 50% Edge-решений, которые сегодня существуют на уровне проверки концепции, не смогут масштабироваться для производственного использования». В отсутствие лучших рыночных практик в области управления периферийными системами, компаниям нужно быть готовыми к решению базовых задач, возникающих при внедрении новых технологий.
Периферия и облако: параллельное существование
Существует мнение, что периферийные вычисления заменят облако. Оно ошибочно. Согласно FCC, многие отраслевые эксперты отрицают, что облачные и периферийные вычисления конкурируют друг с другом. Более того, проницательные организации и даже многие поставщики публичных облачных услуг начинают задумываться о том, как избирательно использовать обе технологии. Другими словами, та часть функций, которая лучше всего «чувствует» себя между конечным устройством и локальными сетевыми ресурсами, будет выполняться на периферии сети, тогда как приложения для работы с большими данными, которые агрегируют данные отовсюду, чтобы просеять их с помощью аналитических и машинных алгоритмов обучения, и которые экономически целесообразно держать в гипермасштабируемых ЦОДах, так и останутся в облаке.
Системным архитекторам предстоит много работы, чтобы научиться использовать все эти возможности с максимальной пользой для всей системы. «Думаю, что ситуации, когда приложение будет работать только на периферии сети, окажутся довольно редкими, — говорит Адиб. — Это связано с тем, что ему необходимо будет общаться и взаимодействовать с другими рабочими нагрузками, которые находятся в облаке, в ЦОДе предприятия или на другом устройстве».



