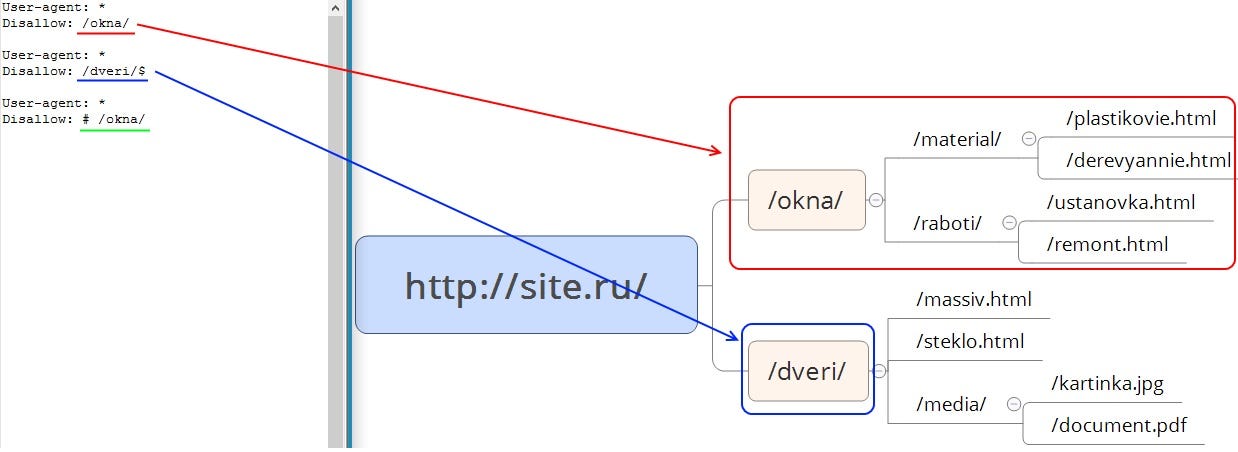
Clean-param Пам-Пам или об одном простом способе закрытия страниц от индексации в Яндексе
Если сделать опрос среди вебмастеров/оптимизаторов, слышали ли они про директиву Clean-param (от англ. clean parameters — чистые параметры), то практически все ответят положительно. Но если задать вопрос про ее использование, то ответы будут уже отрицательными. Что же это за такой зверь, которого все боятся и «с чем его едят»?

Для кого будет полезен Clean-param
1. Рекламируются на сторонних площадках, а переходы осуществляются не по прямым ссылкам. Например, при переходе с Яндекс.Маркета открывается URL с параметром frommarket.
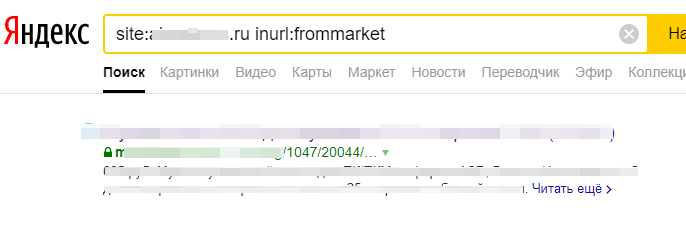
В данном случае в индексе оказывается страница мобильной версии на поддомене. На ней стоИт междоменный rel=»canonical», который не учитывается Яндексом (хотя были случаи, когда учитывался).
Вот другой случай проиндексированных документов с параметрами.
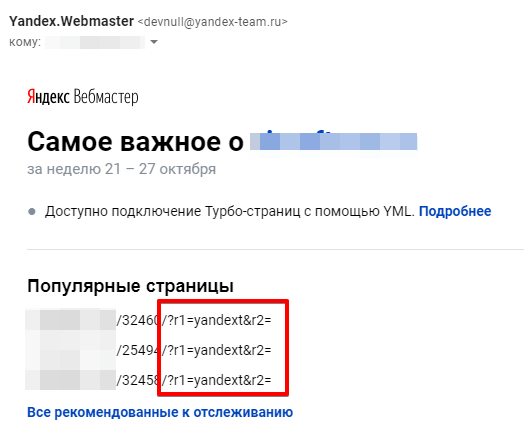
2. Используют UTM-метки во внешних ссылках. Например, таким образом отслеживают эффективность рекламных каналов.
https://sosnovskij.ru/catalog/?utm_source=yandex&utm_medium=cpc&utm_campaign=audit
3. Содержат в URL параметры, не меняющие содержание страницы, например, идентификаторы сессий.
https://sosnovskij.ru/index.php?sessionID=jf1d3ks2fj7dss3fs33
4. Имеют большие масштабы — от нескольких десятков тысяч документов.
Робот Яндекса не будет каждый раз перезагружать страницы с множеством параметров (указанные в директиве параметры будут «опускаться» или не учитываться, как будто их и нет — объединяться в рамках одного URL). Тем самым краулинговый бюджет будет направлен на по-настоящему важные страницы. Дополнительно улучшится индексация сайта (ускорится переиндексация), в индекс будут быстрее попадать новые материалы, уменьшится нагрузка на сервер.
Как применять директиву?
Директива прописывается в robots.txt в любом месте файла. В примерах официальной инструкции clean-param всегда указывался после User-agent: Yandex.
Я уточнил, обязательно ли указывать директиву именно для Yandex (я сторонник не плодить лишних юзер-агентов в роботсе, если на то нет объективных причин). Ответили следующее:
Например, необходимо, чтобы все приведенные примеры не попадали в индекс (+ добавлю openstat):
Добавляем в robots.txt в любое место под User-Agent: * или под User-Agent: Yandex (если есть оба, то под User-Agent: Yandex) следующие правила:
Clean-param: frommarket /catalog*/magazin/
Clean-param: yandext /catalog-old/
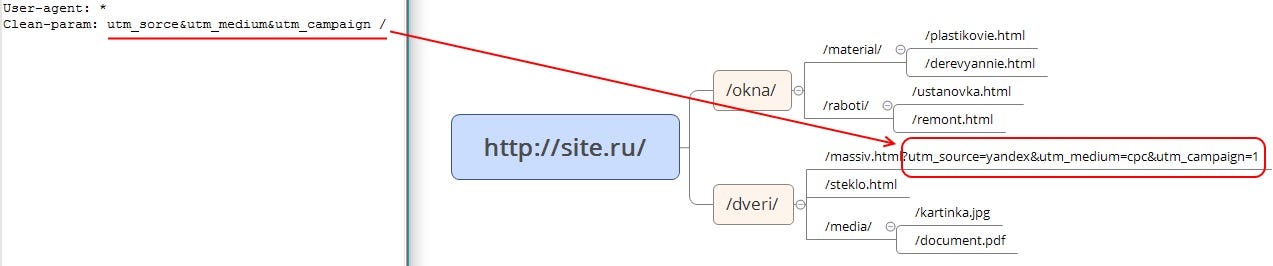
Clean-param: utm_source&utm_medium&utm_campaign /catalog/
Clean-param: sessionID /index.php
Clean-param: _openstat /page.php
Директива состоит из 2-х важных частей (с пробелом между ними):
1. Параметр. Здесь указываются параметры, которые необходимо игнорировать поисковому роботу (в примере «frommarket», «sessionID» и т.д). На 3-й строчке вы можете видеть конструкцию со знаком «&». Амперсанд используется в качестве аналога логического союза «и», объединяя параметры в одну строку. Этот момент я также уточнял у службы поддержки Яндекса. Мой вопрос:
Здравствуйте! Подскажите, пожалуйста, по использованию &» в директиве clean-param. Оно трактуется как «и» или «или»? То есть, например, имеются следующие URL:
— /category/1/?page_count=12 (только параметр page_count)
— /category/1/?pgen=3 (только параметр pgen)
— /category/1/?page_count=12&pgen=3 (и page_count, и pgen).
Если директива будет указана следующим образом:
Clean-param: page_count&pgen /category/
То она затронет все URL или только последний? Если последний, то корректнее будет следующий вариант?
Clean-param: page_count /category/
Clean-param: pgen /category/
Ответили достаточно быстро:
Воспринимается как «и». Вы вполне можете использовать директиву Clean-param: page_count&pgen, хотя и второй вариант ошибкой не будет.
В общем, советую использовать «&» только тогда, когда указанные через амперсанд параметры используются в URL всегда вместе. В остальных случаях лучше написать дополнительное правило.
2. Префикс. Путь до URL с параметром. Здесь указываем маску урлов, как при стандартном закрытии страниц в rotobs.txt. Можно использовать знак звездочки «*» в качестве замены любого количества символов. По умолчанию «*» неявно проставляется в конце префикса (в конце дополнительно звездочку ставить не нужно).
Некоторые особенности
Описание и настройка директивы Clean-param
Clean-param — директива файла robots.txt, которую поддерживают роботы «Яндекса». Она позволяет сообщить динамические параметры, которые присутствуют в URL страницы, но не изменяют её содержание. Это могут быть идентификаторы пользователя, сессии, параметры сортировки товаров и другие элементы.
Например, имеются страницы:
Все они содержат одинаковый контент, но имеют в своих URL-адресах параметры sort_field и order, которые определяют сортировку товаров на этой странице, но формально не меняют ее содержание. В результате у нас получается 3 страницы-дубликата.
Правильно настроить обработку таких страниц нам поможет директива Clean-param. Необходимо прописать её в файле robots.txt следующим образом:
После этого индексироваться роботом Яндекса будет только одна страница: site.ru/catalog/category/, параметры sort_field и order учитываться не будут.
Данная настройка позволит снизить нагрузку на сервер, т.к. робот не будет загружать страницы с указанными параметрами, повысится эффективность обхода сайта роботом, и убережет Вас от появления в индексе дубликатов страниц.
Поле p — это динамические параметры, влияние которых на индексацию необходимо устранить. Если таких несколько, их нужно перечислить через амперсанд, например, sort&price.
Поле path — префикс, указывающий путь применения директивы. Если его не указывать, Clean-param применится для всего сайта.
Файл robots.txt не имеет ограничений на количество указываемых директив Clean-param. В любом месте файла и количестве они будут учтены. В написании директивы учитывается регистр, а также длина правила ограничена 500 символами.
Допустим у нас имеется страница с такими get-параметрами:
Директива Clean-param должна иметь следующее содержание:
Clean-param: sort&order /catalog/kompressionnyi-trikotazh/golfy/
Директива Clean-param для Яндекса: как правильно использовать с примерами
Clean-param – это директива, описывающая в файле Robots.txt динамические параметры страниц, которые отдают одинаковое их содержимое при разных УРЛ-адресах. Данная директива используется только для роботов Яндекса.
Динамическими параметрами могут выступать:
Из-за дублей основная страница не сможет высоко ранжироваться в поисковой выдаче, но благодаря robots.txt можно исключить все GET-параметры или UTM-метки, используя указание Clean-param. Поисковики перестанут индексировать дублирующийся контент по множеству раз, а обход сайта станет более эффективным, снизится нагрузка на сервер, увеличится краулинговый бюджет.
Пример использования Clean-param в robots.txt
Допустим, на вашем сайте есть 3 страницы с одинаковым содержанием:
Все эти страницы одинаковые по содержимому, но они имеют в своем URL разный параметр get=, который в данном случае применяется для отслеживания сайта, с которого пользователь сделал запрос и перешел на страницу. Получается, что он меняет URL, но содержимое остается таким же, поэтому все три URL-адреса ведут на ту же страницу http://site.ru/folder/page.php?r_id=985.
Во избежание обхода роботов всех трех страниц, в robots.txt нужно прописать Clean-param:
Данные инструкции указывают всем роботам поисковых систем объединить все URL страницы к единой ссылке:
Если на веб-ресурсе есть доступ к данной странице, то робот проиндексирует именно ее.
Синтаксис директивы Clean-param
В поле [&p1&p2&..&pn] идет перечисление параметров через символ &, которые роботу не стоит индексировать. В поле [path] прописывается префикс пути страниц, для которых используется директива.
На заметку. Правило Clean-param межсекционное и нет разницы, где именно его прописывать в robots.txt. Если вы укажите несколько правил, поисковый бот учтет каждую из них.
Допускается в префиксе содержание регулярного выражения в формате, схожем с файлом robots. Но у него есть некоторые ограничения. Допускается написание лишь таких символов: A-Za-z0-9.-/*_.
Учтите, что символ “*” интерпретируется аналогично, как и в файле Robots: в конце префикса дописывают *.
Пример:
Указание выше сообщает, что параметр s ничего не значит для УРЛ-адресов, начинающихся с /forum/showthread.php. Если не указать второе поле, а только s, директива используется для всех страниц веб-ресурса.
Отмечу, что регистр учитывается. Также есть лимит на объем директивы: 500 символов – максимально допустимая длина.
Примеры:
Дополнительные примеры использования Clean-param
Robots будет содержать:
Robots будет содержать:
Если таких параметров несколько:
Robots будет содержать:
Если параметр используется в нескольких скриптах:
Robots.txt будет содержать:
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Как создать правильный robots.txt для Google, Яндекс и других поисковых систем

Mar 3, 2017 · 10 min read
В 2016 году для портала SEONews я написал статью о том как правильно состаить robots.txt для поисковых систем. Статья получилась интересная и, по-моему, одна из самых подробных и основательных на эту тему в рунете. И более 20 тысяч просмотров статьи только подтвреждают мои слова.
Думаю, никто не будет в обиде, если я перенесу эту статью сюда.
Энциклопедия интернет-маркетинга: составляем корректный robots.txt своими руками
SEOnews запустил проект для специалистов и клиентов «Энциклопедия интернет-маркетинга», в рамках которого редакция пуб…
Введение
Если попросить SEO-специалиста оценить важность правильно составленного robots.txt для сайта, хороший SEOшник оценит ее на 5 баллов из 5.
Кривой robots.txt, не учитывающий всех тонкостей сайта, может сильно навредить его индексации.
Одна неучтенн а я директива, и поисковики тут же вывалят в свой индекс всю подноготную сайта, например, как это было в 2011 году с утечкой SMS пользователей Мегафона.
Или одна лишняя или неправильно составленная директива, и часть сайта, или даже весь сайт, вылетит из индекса поисковых систем, а значит, потеряет весь поисковый трафик.
Структура статьи
Что такое robots.txt
Для начала определимся что из себя представляет этот файл и зачем он нужен.
В справке Яндекса дано следующее определение:
Robots.txt — текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем…
Сессия (робота поисковой системы) начинается с загрузки файла robots.txt. Если файл отсутствует, не является текстовым или на запрос робота возвращается HTTP-статус отличный от 200 OK, робот считает, что доступ к документам (страницам сайта) не ограничен.
То есть, другими словами, robots.txt — набор директив, которым однозначно подчиняются роботы поисковых систем при индексировании сайта.
Сказано «индексировать» страницу или раздел, будет индексировать. Сказано «не индексировать», не будет.
Но, несмотря на всю важность данного файла, подавляющее большинство сайтов в русском сегменте интернета не имеют правильно составленного robots.txt.
Директивы и спецсимволы robots.txt
Порядок включения директив:
Для начала стоит сказать о том, какие директивы могут использоваться в файле robots.txt.
User-agent — указание робота, для которого составлен список директив ниже. Обязательная для robots.txt директива, которая указывается в начале файла.
Disallow — директива запрета индексации документов. Можно указывать как каталог, так и часть названия документа, так и полный путь документа.
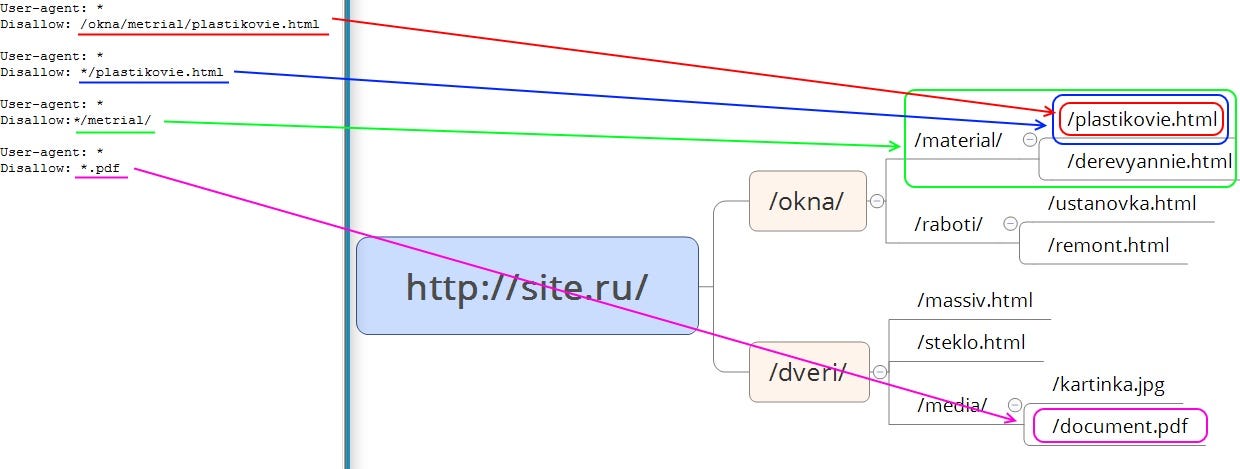
Allow — директива разрешения индексации документов. Является директивой по умолчанию для всех документов на сайте, если не указано другое.
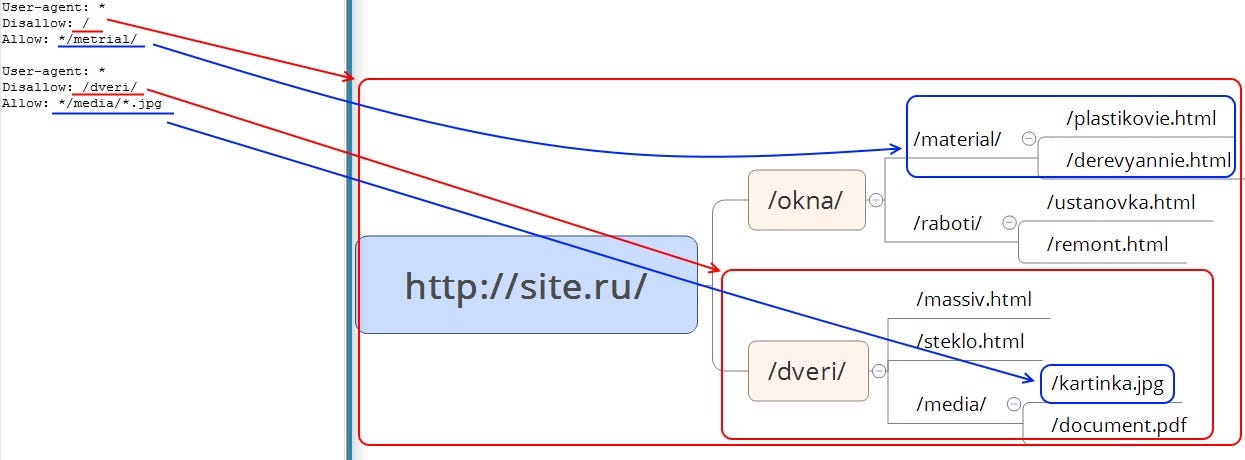
Sitemap — директива для указания пути к файлу xml-карты сайта.
Спецсимволы
Host — директива указания главного зеркала сайта. Учитывается только роботами Яндекса.
Crawl-delay — директива указания минимального времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Учитывается только роботами Яндекса. Директива используется, чтоб роботы поисковых систем не перегружали сайт.
Clean-param — директива используется для удаления параметров из url-адресов сайта. Учитывается только роботами Яндекса.
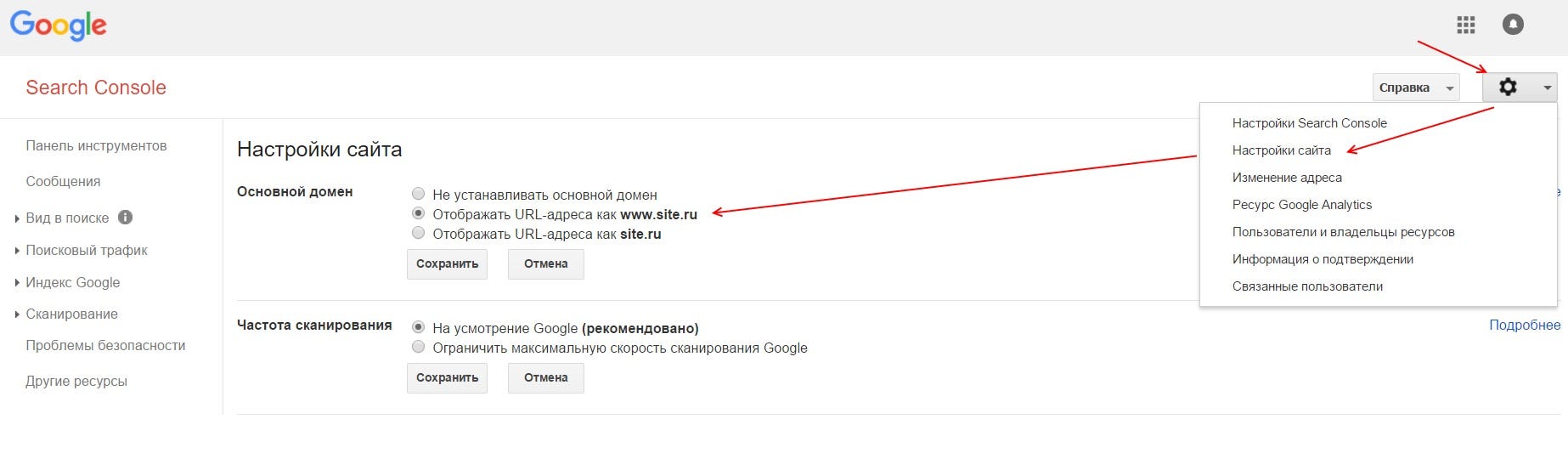
Настройка Google Search Consloe (GSC)
Как говорилось ранее, часть функций, которые можно указать для роботов Яндекса в robots.txt, для роботов Google надо указывать в Google Search Console.
Чтобы указать главное зеркало в Google необходимо подтвердить оба зеркала (www.site.ru и site.ru) в GSC. Зайти в настройки сайта (знак шестеренки), там выбрать ссылку «Настройка сайта» и в блоке «Основной домен» выбрать главное зеркало и сохранить изменения.
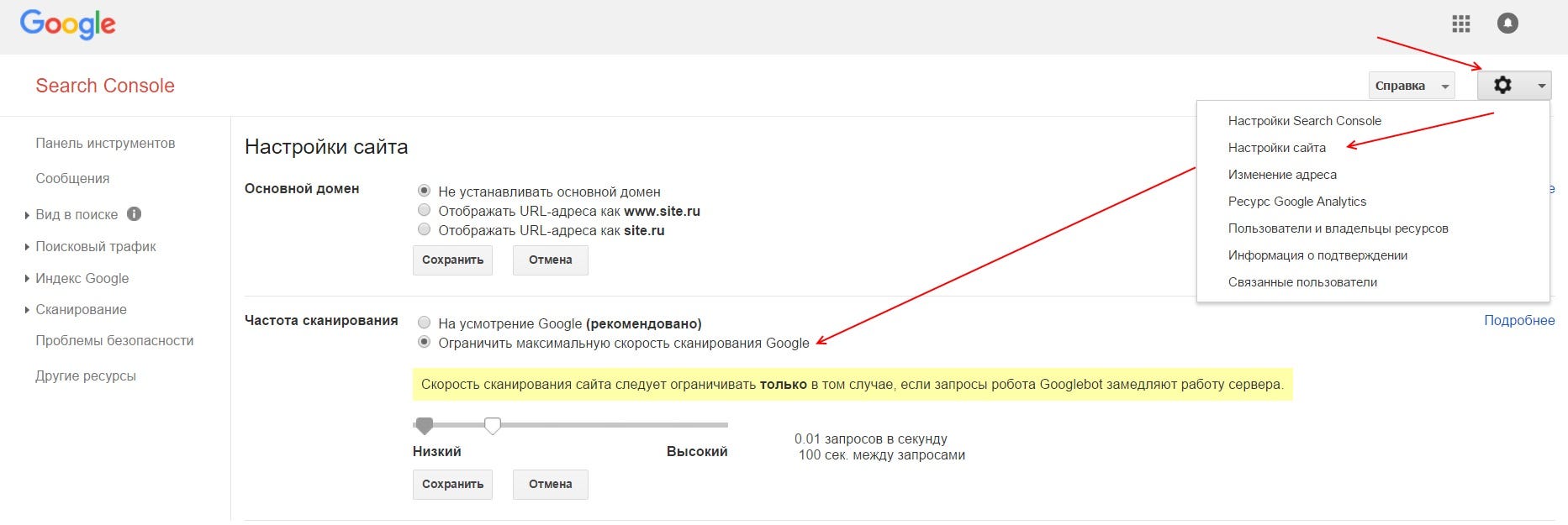
Чтобы ограничить скорость сканирования сайта роботами Google необходимо подтвердить сайт в GSC. Зайти в настройки сайта (знак шестеренки), там выбрать ссылку «Настройка сайта», в блоке «Частота сканирования» выбрать пункт «Ограничить максимальную скорость сканирования Google» и выставить приемлемое значение, после чего сохранить изменения.
Для того чтобы задать, как Google будет обрабатывать параметры в url-адресах сайта необходимо подтвердить сайт в GSC. Зайти в раздел «Сканирование» — «Параметры URL», нажать на кнопку «Добавление параметра», заполнить соответствующие поля и сохранить изменения.

Если робот Google уже нашел какие-либо параметры на сайте, то вы увидите список этих параметров в таблице и сможете посмотреть примеры таких страниц.
Как составить правильный robots.txt самостоятельно
Рассмотрев основные директивы для работы с файлом robots.txt перейдем к составлению robots.txt для сайта.
Во-первых, мы не рекомендуем брать и в слепую использовать шаблонные robots.txt, которые можно найти в интернете, так как они просто не могут учитывать всех тонкостей работы вашего сайта.
1. Первым делом добавим в robots.txt три User-Agent с одной пустой строкой между каждой директивой
Третий User-Agent добавляется по причине того, что для роботов каждой поисковой системы наборы директив будут различаться.
2. Каждому User-agent’у рекомендуется добавить директивы запрета индексации самых распространенных форматов документов
Документы закрываются от индексации по той причине, что они могут «перетянуть» на себя релевантность и попадать в выдачу вместо продвигаемых целевых страниц.
Даже если сейчас на вашем сайте пока нет документов в вышеперечисленных форматах, рекомендуем не удалять эти строки, а оставить их на перспективу.
3. Каждому User-agent’у добавляем директиву разрешения индексации JS и CSS файлов
JS и CSS файлы открываются для индексации, так как часто они находятся в каталогах системных папок, но они требуются для правильного индексирования сайта роботами поисковых систем.
4. Каждому User-agent’у добавляем директиву разрешения индексации самых распространенных форматов изображений
Картинки открываем для исключения возможности случайного запрета их для индексации.
Так же как и с документами, если сейчас у вас на сайте нет графических изображений в каком-либо из перечисленных форматах, все равно лучше оставить эти строки.
5. Для User-agent’а Yandex добавляем директиву удаления меток отслеживания, чтобы исключить возможность появления дублей страниц в индексе поисковых систем
6. Эти же параметры закрываем в GSC в разделе «Параметры URL»
Внимание! Если закрыть от индексации роботами Google метки при помощи директивы запрета, есть вероятность того, что вы не сможете запустить на такие страницы рекламу в Google Adwords.
7. Для User-agent’а «*» закрываем метки отслеживания стандартной директивой запрета
8. Далее задача закрыть от индексации все служебные документы, документы бесполезные для поиска и дубли других страниц. Директивы запрета копируются для каждого User-agent’а. Пример таких страниц:
9. Последней директивой для User-agent’а Yandex указывается главное зеркало
10. Последней директивой, после всех директив, через пустую строку указываются директивы xml-карт сайта, если таковые используются на сайте
После всех манипуляций должен получится готовый файл robots.txt, который можно использовать на сайте.
Шаблон, который можно взять за основу при составлении robots.txt
# Наиболее часто встречаемые расширения документов
# Требуется для правильно обработки ПС
# Наиболее часто встречаемые метки для отслеживания рекламы
# При наличии фильтров и параметров добавляем и их в Clean-param
# У google метки, фильтры и параметры закрываются в GSC-Сканирование-Параметры URL
# Метки, фильтры и параметры для других ПС закрываем по классическому стандарту
* Напомним, что в указанном шаблоне присутствует спецсимвол комментария «#», и все что находится справа от него предназначается не для роботов, а является подсказками для людей.
Важно! Когда копируете шаблон в текстовый файл, не забудьте убрать лишние пустые строки.
Пустые строки в robots.txt должны быть только:
Но прежде чем добавлять его на сайт, мы рекомендуем проверить его в сервисах анализа, например, для Яндекса, нет ли в нем ошибок. А заодно проверить несколько документов из каталогов, которые запрещены к индексации, и несколько документов, которые должны быть открыты для индексации, и проверить, нет ли каких-либо ошибок.
Распространенные ошибки при составлении robots.txt
Хоть составление правильного robots.txt задача не самая сложная, но есть распространенные ошибки, которые многие допускают, и от которых мы хотим вас предупредить.
4.1. Полное закрытие сайта от индексации
Такая ошибка приводит к исключению всех страниц из индекса поисковых систем и полной потери поискового трафика.
4.2. Не закрытие от индексации меток отслеживания
Эта ошибка может привести к появлению большого количества дублей страниц, что негативно скажется на продвижении сайта
4.3. Неправильное зеркало сайта
Host: site.ru # В то время, как правильное зеркало sub.site.ru
Скорее всего в большинстве случаев Яндекс просто проигнорирует эту директиву, но если, например, у вас есть несколько судбоменов для разных регионов, то есть вероятность того, что зеркала просто «склеятся».
«Вкалывают роботы»: что такое robots.txt и как его настроить

Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Пример:
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Даем рекомендацию, чтобы индексировались категории.
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
Sitemap
Пример:
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
Переходим в инструмент, вводим домен и содержимое вашего файла.

Нажимаем « Проверить » и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
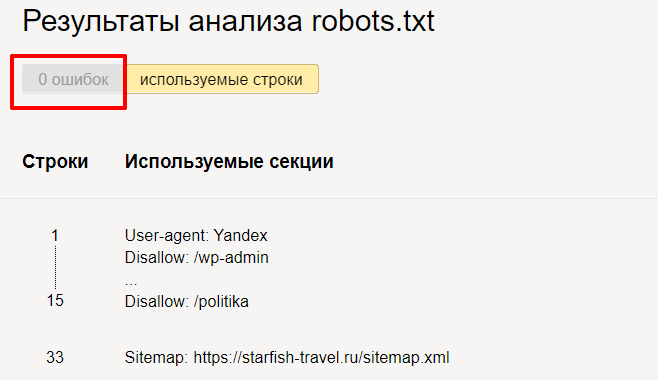
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
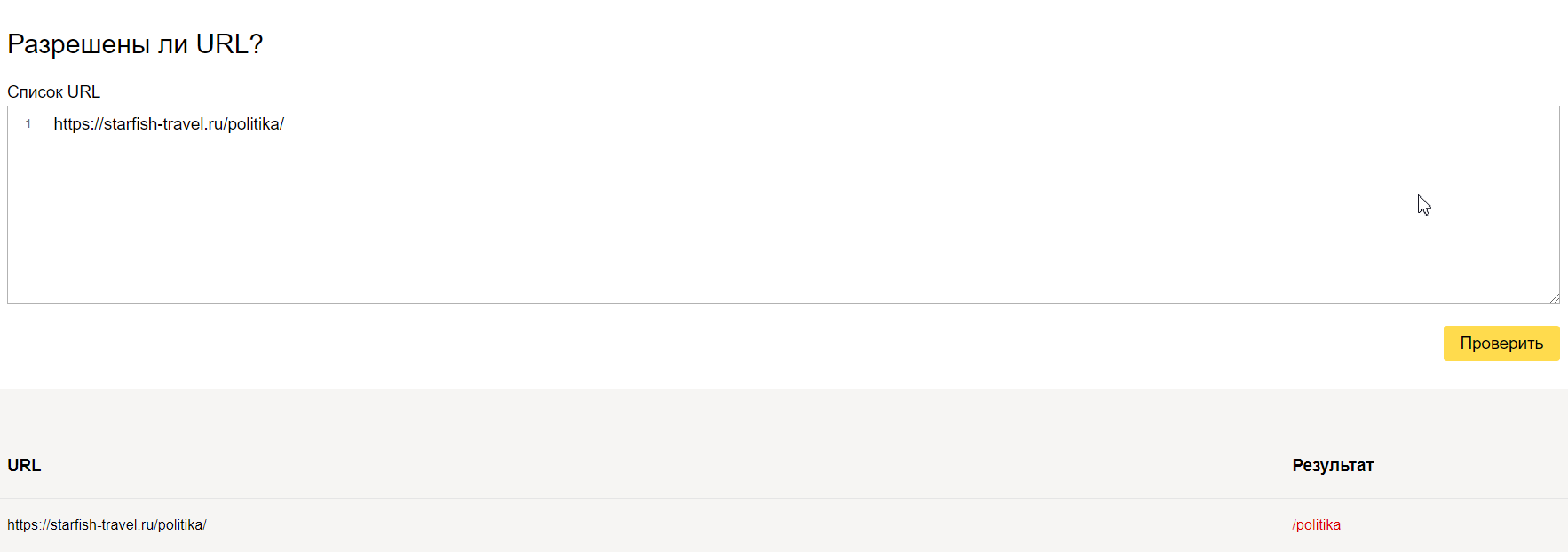
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
Правильный robots.txt для Joomla
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.



