Exceltip
Блог о программе Microsoft Excel: приемы, хитрости, секреты, трюки
Что такое стандартное отклонение — использование функции СТАНДОТКЛОН для расчета стандартного отклонения в Excel

Стандартное отклонение является одним из тех статистических терминов в корпоративном мире, которое позволяет поднять авторитет людей, сумевших удачно ввернуть его в ходе беседы или презентации, и оставляет смутное недопонимание тех, кто не знает, что это такое, но стесняется спросить. На самом деле большинство менеджеров не понимают концепцию стандартного отклонения и, если вы один из них, вам пора перестать жить во лжи. В сегодняшней статье я расскажу вам, как эта недооцененная статистическая мера позволит лучше понять данные, с которыми вы работаете.
Что измеряет стандартное отклонение?
Представьте, что вы владелец двух магазинов. И чтобы избежать потерь, важно, чтобы был четкий контроль остатков на складе. В попытке выяснить, кто из менеджеров лучше управляет запасами, вы решили проанализировать стоки последних шести недель. Средняя недельная стоимость стока обоих магазинов примерно одинакова и составляет около 32 условных единиц. На первый взгляд среднее значение стока показывает, что оба менеджера работают одинаково.
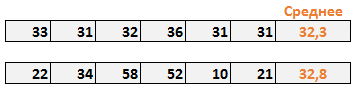
Но если внимательнее изучить деятельность второго магазина, можно убедится, что хотя среднее значение корректно, вариабельность стока очень высокая (от 10 до 58 у.е.). Таким образом, можно сделать вывод, что среднее значение не всегда правильно оценивает данные. Вот где на выручку приходит стандартное отклонение.
Стандартное отклонение показывает, как распределены значения относительно среднего в нашей выборке. Другими словами, можно понять на сколько велик разброс величины стока от недели к неделе.
В нашем примере, мы воспользовались функцией Excel СТАНДОТКЛОН, чтобы рассчитать показатель стандартного отклонения вместе со средним.
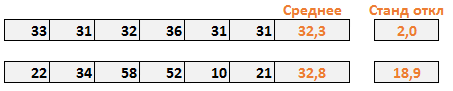
В случае с первым менеджером, стандартное отклонение составило 2. Это говорит нам о том, что каждое значение в выборке в среднем откланяется на 2 от среднего значения. Хорошо ли это? Давайте рассмотрим вопрос под другим углом – стандартное отклонение равное 0, говорит нам о том, что каждое значение в выборке равно его среднему значению (в нашем случае, 32,2). Так, стандартное отклонение 2 ненамного отличается от 0, и указывает на то, что большинство значений находятся рядом со средним значением. Чем ближе стандартное отклонение к 0, тем надежнее среднее. Более того, стандартное отклонение близкое к 0, говорит о маленькой вариабельности данных. То есть, величина стока со стандартным отклонением 2, указывает на невероятную последовательность первого менеджера.
В случае со вторым магазином, стандартное отклонение составило 18,9. То есть стоимость стока в среднем отклоняется на величину 18,9 от среднего значения от недели к неделе. Сумасшедший разброс! Чем дальше стандартное отклонение от 0, тем менее точно среднее значение. В нашем случае, цифра 18,9 указывает на то, что среднему значению (32,8 у.е. в неделю) просто нельзя доверять. Оно также говорит нам о том, что еженедельная величина стока обладает большой вариабельностью.
Такова концепция стандартного отклонения в двух словах. Хотя оно не дает представление о других важных статистических измерениях (Мода, Медиана…), фактически стандартное отклонение играет решающую роль в большинстве статистических расчетов. Понимание принципов стандартного отклонения прольет свет на суть многих процессов вашей деятельности.
Как рассчитать стандартное отклонение?
Итак, теперь мы знаем, о чем говорит цифра стандартного отклонения. Давайте разберемся, как она считается.
Рассмотрим набор данных от 10 до 70 с шагом 10. Как видите, я уже рассчитал для них значение стандартного отклонения с помощью функции СТАНДОТКЛОН в ячейке H2 (оранжевым).
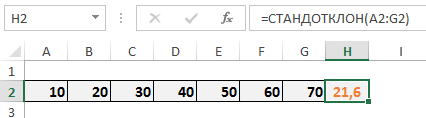
Ниже описаны шаги, которые предпринимает Excel, чтобы прийти к цифре 21,6.
Обратите внимание, что все расчеты визуализированы, для лучшего понимания. На самом деле в Excel расчет происходит мгновенно, оставляя все шаги за кулисами.
Для начала Excel находит среднее значение выборки. В нашем случае, среднее получилось равным 40, которое на следующем шаге отнимают от каждого значения выборки. Каждую полученную разницу возводят в квадрат и суммируют. У нас получилась сумма равная 2800, которую необходимо разделить на количество элементов выборки минус 1. Так как у нас 7 элементов, получается необходимо 2800 разделить на 6. Из полученного результата находим квадратный корень, это цифра будет стандартным отклонением.

Для тех, кому не совсем ясен принцип расчета стандартного отклонения с помощью визуализации, привожу математическую интерпретацию нахождения данного значения.
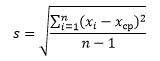
Функции расчета стандартного отклонения в Excel
В Excel присутствует несколько разновидностей формул стандартного отклонения. Вам достаточно набрать =СТАНДОТКЛОН и вы сами в этом убедитесь.

Стоит отметить, что функции СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г (первая и вторая функция в списке) дублируют функции СТАНДОТКЛОН и СТАНДОТКЛОНП (пятая и шестая функция в списке), соответственно, которые были оставлены для совместимости с более ранними версиями Excel.
Особенностью функций СТАНДОТКЛОНА и СТАНДОТКЛОНПА (третья и четвертая функция в списке), является то, что при расчете стандартного отклонения массива в расчет принимаются логические и текстовые значения. Текстовые и истинные логические значения равняются 1, а ложные логические значения равняются 0. Мне трудно представить ситуацию, когда бы мне могли понадобится эти две функции, поэтому, думаю, что их можно игнорировать.
Вам также могут быть интересны следующие статьи
32 комментария
Ренат, добрый день.
Мне нравится статья, а главное способ подачи материала. Визуализация расчёта также порадовала новизной подхода, хотя и времени потребовала больше для понимания (классическое советское образование). Согласен, что про стандартное отклонение никто толком не знает, а зря…
Добрый день.
В формуле ошибка: под знаком корня необходимо суммировать квадраты отклонений
Стандартное отклонение
Стандартное отклонение (англ. Standard Deviation) — простыми словами это мера того, насколько разбросан набор данных.
Вычисляя его, можно узнать, являются ли числа близкими к среднему значению или далеки от него. Если точки данных находятся далеко от среднего значения, то в наборе данных имеется большое отклонение; таким образом, чем больше разброс данных, тем выше стандартное отклонение.
Стандартное отклонение обозначается буквой σ (греческая буква сигма).
Стандартное отклонение также называется:
Использование и интерпретация величины среднеквадратического отклонения
Стандартное отклонение используется:
Рассмотрим два малых предприятия, у нас есть данные о запасе какого-то товара на их складах.
| День 1 | День 2 | День 3 | День 4 | |
|---|---|---|---|---|
| Пред.А | 19 | 21 | 19 | 21 |
| Пред.Б | 15 | 26 | 15 | 24 |
В обеих компаниях среднее количество товара составляет 20 единиц:
Однако, глядя на цифры, можно заметить:
Если рассчитать стандартное отклонение каждой компании, оно покажет, что
Стандартное отклонение показывает эту волатильность данных — то, с каким размахом они меняются; т.е. как сильно этот запас товара на складах компаний колеблется (поднимается и опускается).
Расчет среднеквадратичного (стандартного) отклонения
Формулы вычисления стандартного отклонения
Разница между формулами S и σ («n» и «n–1»)
Состоит в том, что мы анализируем — всю выборку или только её часть:
Как рассчитать стандартное отклонение?
Пример 1 (с σ)
Рассмотрим данные о запасе какого-то товара на складах Предприятия Б.
| День 1 | День 2 | День 3 | День 4 | |
| Пред.Б | 15 | 26 | 15 | 24 |
Если значений выборки немного (небольшое n, здесь он равен 4) и анализируются все значения, то применяется эта формула:

Применяем эти шаги:
1. Найти среднее арифметическое выборки:
μ = (15 + 26 + 15+ 24) / 4 = 20
2. От каждого значения выборки отнять среднее арифметическое:
3. Каждую полученную разницу возвести в квадрат:
4. Сделать сумму полученных значений:
5. Поделить на размер выборки (т.е. на n):
6. Найти квадратный корень:
Пример 2 (с S)
Задача усложняется, когда существуют сотни, тысячи или даже миллионы данных. В этом случае берётся только часть этих данных и анализируется методом выборки.
У Андрея 20 яблонь, но он посчитал яблоки только на 6 из них.
Популяция — это все 20 яблонь, а выборка — 6 яблонь, это деревья, которые Андрей посчитал.
| Яблоня 1 | Яблоня 2 | Яблоня 3 | Яблоня 4 | Яблоня 5 | Яблоня 6 |
| 9 | 2 | 5 | 4 | 12 | 7 |
Так как мы используем только выборку в качестве оценки всей популяции, то нужно применить эту формулу:

Математически она отличается от предыдущей формулы только тем, что от n нужно будет вычесть 1. Формально нужно будет также вместо μ (среднее арифметическое) написать X ср.
Применяем практически те же шаги:
1. Найти среднее арифметическое выборки:
Xср = (9 + 2 + 5 + 4 + 12 + 7) / 6 = 39 / 6 = 6,5
2. От каждого значения выборки отнять среднее арифметическое:
X1 – Xср = 9 – 6,5 = 2,5
X2 – Xср = 2 – 6,5 = –4,5
X3 – Xср = 5 – 6,5 = –1,5
X4 – Xср = 4 – 6,5 = –2,5
X5 – Xср = 12 – 6,5 = 5,5
X6 – Xср = 7 – 6,5 = 0,5
3. Каждую полученную разницу возвести в квадрат:
4. Сделать сумму полученных значений:
Σ (Xi – Xср)² = 6,25 + 20,25+ 2,25+ 6,25 + 30,25 + 0,25 = 65,5
5. Поделить на размер выборки, вычитав перед этим 1 (т.е. на n–1):
(Σ (Xi – Xср)²)/(n-1) = 65,5 / (6 – 1) = 13,1
6. Найти квадратный корень:
S = √((Σ (Xi – Xср)²)/(n–1)) = √ 13,1 ≈ 3,6193
Дисперсия и стандартное отклонение
Стандартное отклонение равно квадратному корню из дисперсии (S = √D). То есть, если у вас уже есть стандартное отклонение и нужно рассчитать дисперсию, нужно лишь возвести стандартное отклонение в квадрат (S² = D).
Дисперсия — в статистике это «среднее квадратов отклонений от среднего». Чтобы её вычислить нужно:
Ещё расчёт дисперсии можно сделать по этой формуле:
Правило трёх сигм
Это правило гласит: вероятность того, что случайная величина отклонится от своего математического ожидания более чем на три стандартных отклонения (на три сигмы), почти равна нулю.

Глядя на рисунок нормального распределения случайной величины, можно понять, что в пределах:
Это означает, что за пределами остаются лишь 0,28% — это вероятность того, что случайная величина примет значение, которое отклоняется от среднего более чем на 3 сигмы.
Стандартное отклонение в excel
Вычисление стандартного отклонения с «n – 1» в знаменателе (случай выборки из генеральной совокупности):
1. Занесите все данные в документ Excel.

2. Выберите поле, в котором вы хотите отобразить результат.
3. Введите в этом поле «=СТАНДОТКЛОНА(«
4. Выделите поля, где находятся данные, потом закройте скобки.

5. Нажмите Ввод (Enter).

В случае если данные представляют всю генеральную совокупность (n в знаменателе), то нужно использовать функцию СТАНДОТКЛОНПА.


Коэффициент вариации
Коэффициент вариации — отношение стандартного отклонения к среднему значению, т.е. Cv = (S/μ) × 100% или V = (σ/X̅) × 100%.
Стандартное отклонение делится на среднее и умножается на 100%.
Можно классифицировать вариабельность выборки по коэффициенту вариации:
Как найти среднеквадратическое отклонение
В данной статье я расскажу о том, как найти среднеквадратическое отклонение. Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом 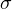 (греческая буква «сигма»).
(греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
| Порода собаки | Рост в миллиметрах |
| Ротвейлер | 600 |
| Бульдог | 470 |
| Такса | 170 |
| Пудель | 430 |
| Мопс | 300 |
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение. Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее 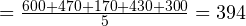 мм.
мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего:
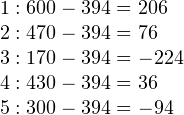
Наконец, чтобы вычислить дисперсию, каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
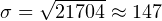 мм (округлено до ближайшего целого значения в мм).
мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть 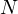 значений, то:
значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
При этом стандартное отклонение по выборке равно 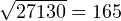 мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
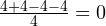 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
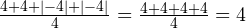 .
.
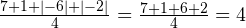 .
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
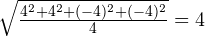 .
.
Для второго примера получится:
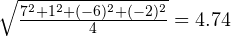 .
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал репетитор по математике в Москве, Сергей Валерьевич
Объясняем p-значения для начинающих Data Scientist’ов
Я помню, когда я проходил свою первую зарубежную стажировку в CERN в качестве практиканта, большинство людей все еще говорили об открытии бозона Хиггса после подтверждения того, что он соответствует порогу «пять сигм» (что означает наличие p-значения 0,0000003).

Тогда я ничего не знал о p-значении, проверке гипотез или даже статистической значимости.
Я решил загуглить слово — «p-значение», и то, что я нашел в Википедии, заставило меня еще больше запутаться…
При проверке статистических гипотез p-значение или значение вероятности для данной статистической модели — это вероятность того, что при истинности нулевой гипотезы статистическая сводка (например, абсолютное значение выборочной средней разницы между двумя сравниваемыми группами) будет больше или равна фактическим наблюдаемым результатам.
— Wikipedia
Хорошая работа, Википедия.
Ладно. Я не понял, что на самом деле означает р-значение.
Углубившись в область науки о данных, я наконец начал понимать смысл p-значения и то, где его можно использовать как часть инструментов принятия решений в определенных экспериментах.
Поэтому я решил объяснить р-значение в этой статье, а также то, как его можно использовать при проверке гипотез, чтобы дать вам лучшее и интуитивное понимание р-значений.
Также мы не можем пропустить фундаментальное понимание других концепций и определение p-значения, я обещаю, что сделаю это объяснение интуитивно понятным, не подвергая вас всеми техническими терминами, с которыми я столкнулся.
Всего в этой статье четыре раздела, чтобы дать вам полную картину от построения проверки гипотезы до понимания р-значения и использования его в процессе принятия решений. Я настоятельно рекомендую вам пройтись по всем из них, чтобы получить подробное понимание р-значений:
1. Проверка гипотез

Прежде чем мы поговорим о том, что означает р-значение, давайте начнем с разбора проверки гипотез, где р-значение используется для определения статистической значимости наших результатов.
Наша конечная цель — определить статистическую значимость наших результатов.
И статистическая значимость построена на этих 3 простых идеях:
Другими словами, мы создадим утверждение (нулевая гипотеза) и используем пример данных, чтобы проверить, является ли утверждение действительным. Если утверждение не соответствует действительности, мы выберем альтернативную гипотезу. Все очень просто.
Чтобы узнать, является ли утверждение обоснованным или нет, мы будем использовать p-значение для взвешивания силы доказательств, чтобы увидеть, является ли оно статистически значимым. Если доказательства подтверждают альтернативную гипотезу, то мы отвергнем нулевую гипотезу и примем альтернативную гипотезу. Это будет объяснено в следующем разделе.
Давайте воспользуемся примером, чтобы сделать эту концепцию более ясной, и этот пример будет использоваться на протяжении всей этой статьи для других концепций.
Пример. Предположим, что в пиццерии заявлено, что время их доставки составляет в среднем 30 минут или меньше, но вы думаете, что оно больше чем заявленное. Таким образом, вы проводите проверку гипотезы и случайным образом выбираете время доставки для проверки утверждения:
Одним из распространенных способов проверки гипотез является использование Z-критерия. Здесь мы не будем вдаваться в подробности, так как хотим лучше понять, что происходит на поверхности, прежде чем погрузиться глубже.
2. Нормальное распределение
Нормальное распределение — это функция плотности вероятности, используемая для просмотра распределения данных.
Нормальное распределение имеет два параметра — среднее (μ) и стандартное отклонение, также называемое сигма (σ).
Среднее — это центральная тенденция распределения. Оно определяет местоположение пика для нормальных распределений. Стандартное отклонение — это мера изменчивости. Оно определяет, насколько далеко от среднего значения склонны падать значения.
Нормальное распределение обычно связано с правилом 68-95-99.7 (изображение выше).
Классно. Теперь вы можете задаться вопросом: «Как нормальное распределение относится к нашей предыдущей проверке гипотез?»
Поскольку мы использовали Z-тест для проверки нашей гипотезы, нам нужно вычислить Z-баллы (которые будут использоваться в нашей тестовой статистике), которые представляют собой число стандартных отклонений от среднего значения точки данных. В нашем случае каждая точка данных — это время доставки пиццы, которое мы получили.
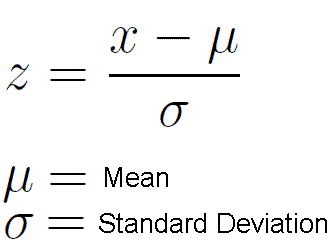
Обратите внимание, что когда мы рассчитали все Z-баллы для каждого времени доставки пиццы и построили стандартную кривую нормального распределения, как показано ниже, единица измерения на оси X изменится с минут на единицу стандартного отклонения, так как мы стандартизировали переменную, вычитая среднее и деля его на стандартное отклонение (см. формулу выше).
Изучение стандартной кривой нормального распределения полезно, потому что мы можем сравнить результаты теста с ”нормальной» популяцией со стандартизированной единицей в стандартном отклонении, особенно когда у нас есть переменная, которая поставляется с различными единицами.
Z-оценка может сказать нам, где лежат общие данные по сравнению со средней популяцией.
Мне нравится, как Уилл Кёрсен выразился: чем выше или ниже Z-показатель, тем менее вероятным будет случайный результат и тем более вероятным будет значимый результат.
Но насколько высокий (или низкий) показатель считается достаточно убедительным, чтобы количественно оценить, насколько значимы наши результаты?
Кульминация
Здесь нам нужен последний элемент для решения головоломки — p-значение, и проверить, являются ли наши результаты статистически значимыми на основе уровня значимости (также известного как альфа), который мы установили перед началом нашего эксперимента.
3. Что такое P-значение?
Наконец… Здесь мы говорим о р-значении!
Все предыдущие объяснения предназначены для того, чтобы подготовить почву и привести нас к этому P-значению. Нам нужен предыдущий контекст и шаги, чтобы понять это таинственное (на самом деле не столь таинственное) р-значение и то, как оно может привести к нашим решениям для проверки гипотезы.
Если вы зашли так далеко, продолжайте читать. Потому что этот раздел — самая захватывающая часть из всех!
Вместо того чтобы объяснять p-значения, используя определение, данное Википедией (извини Википедия), давайте объясним это в нашем контексте — время доставки пиццы!
Напомним, что мы произвольно отобрали некоторые сроки доставки пиццы, и цель состоит в том, чтобы проверить, превышает ли время доставки 30 минут. Если окончательные доказательства подтверждают утверждение пиццерии (среднее время доставки составляет 30 минут или меньше), то мы не будем отвергать нулевую гипотезу. В противном случае мы опровергаем нулевую гипотезу.
Поэтому задача p-значения — ответить на этот вопрос:
Если я живу в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), насколько неожиданными являются мои доказательства в реальной жизни?
Р-значение отвечает на этот вопрос числом — вероятностью.
Чем ниже значение p, тем более неожиданными являются доказательства, тем более нелепой выглядит наша нулевая гипотеза.
И что мы делаем, когда чувствуем себя нелепо с нашей нулевой гипотезой? Мы отвергаем ее и выбираем нашу альтернативную гипотезу.
Если р-значение ниже заданного уровня значимости (люди называют его альфа, я называю это порогом нелепости — не спрашивайте, почему, мне просто легче понять), тогда мы отвергаем нулевую гипотезу.
Теперь мы понимаем, что означает p-значение. Давайте применим это в нашем случае.
P-значение в расчете времени доставки пиццы
Теперь, когда мы собрали несколько выборочных данных о времени доставки, мы выполнили расчет и обнаружили, что среднее время доставки больше на 10 минут с p-значением 0,03.
Это означает, что в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), есть 3% шанс, что мы увидим, что среднее время доставки, по крайней мере, на 10 минут больше, из-за случайного шума.
Чем меньше p-значение, тем более значимым будет результат, потому что он с меньшей вероятностью будет вызван шумом.
В нашем случае большинство людей неправильно понимают р-значение:
Р-значение 0,03 означает, что есть 3% (вероятность в процентах), что результат обусловлен случайностью — что не соответствует действительности.
Р-значение ничего не *доказывает*. Это просто способ использовать неожиданность в качестве основы для принятия разумного решения.
— Кэсси Козырков
Вот как мы можем использовать p-значение 0,03, чтобы помочь нам принять разумное решение (ВАЖНО):
По моему мнению, p-значения используются в качестве инструмента для оспаривания нашего первоначального убеждения (нулевая гипотеза), когда результат является статистически значимым. В тот момент, когда мы чувствуем себя нелепо с нашим собственным убеждением (при условии, что р-значение показывает, что результат статистически значим), мы отбрасываем наше первоначальное убеждение (отвергаем нулевую гипотезу) и принимаем разумное решение.
4. Статистическая значимость
Наконец, это последний этап, когда мы собираем все вместе и проверяем, является ли результат статистически значимым.
Недостаточно иметь только р-значение, нам нужно установить порог (уровень значимости — альфа). Альфа всегда должна быть установлена перед экспериментом, чтобы избежать смещения. Если наблюдаемое р-значение ниже, чем альфа, то мы заключаем, что результат является статистически значимым.
Основное правило — установить альфа равным 0,05 или 0,01 (опять же, значение зависит от вашей задачи).
Как упоминалось ранее, предположим, что мы установили альфа равным 0,05, прежде чем мы начали эксперимент, полученный результат является статистически значимым, поскольку р-значение 0,03 ниже, чем альфа.
Для справки ниже приведены основные этапы всего эксперимента:
Если вы хотите узнать больше о статистической значимости, не стесняйтесь посмотреть эту статью — Объяснение статистической значимости, написанная Уиллом Керсеном.
Последующие размышления
Здесь много чего нужно переваривать, не так ли?
Я не могу отрицать, что p-значения по своей сути сбивают с толку многих людей, и мне потребовалось довольно много времени, чтобы по-настоящему понять и оценить значение p-значений и то, как они могут быть применены в рамках нашего процесса принятия решений в качестве специалистов по данным.
Но не слишком полагайтесь на p-значения, поскольку они помогают только в небольшой части всего процесса принятия решений.
Я надеюсь, что мое объяснение p-значений стало интуитивно понятным и полезным в вашем понимании того, что в действительности означают p-значения и как их можно использовать при проверке ваших гипотез.
Сам по себе расчет р-значений прост. Трудная часть возникает, когда мы хотим интерпретировать p-значения в проверке гипотез. Надеюсь, что теперь трудная часть станет для вас немного легче.
Если вы хотите узнать больше о статистике, я настоятельно рекомендую вам прочитать эту книгу (которую я сейчас читаю!) — Практическая статистика для специалистов по данным, специально написанная для data scientists, чтобы разобраться с фундаментальными концепциями статистики.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:



