Что выражается в так называемых лингвистических переменных т е без задания числовых функций
4.3. Нечеткие и лингвистические переменные
Способность человека оценивать информацию играет существенную роль в определении сложных явлений. По своей природе оценка является приближением. Во многих случаях достаточна весьма приближенная характеристика набора данных, поскольку в большинстве задач, решаемых человеком, не требуется высокая точность [98].
Если рассматривать цвет объекта как некоторую переменную, то ее значения: красный, синий, зеленый и т.д. можно интерпретировать как символы нечетких подмножеств полного множества. В этом смысле определенный цвет предмета является нечеткой переменной, т.е. переменной значениями которой являются символы нечетких множеств.
Предположим, что Х =1+2+. +10.
Тогда нечеткое подмножество, описываемое понятием несколько, можно записать, например, в виде:
несколько = 0,5/3 + 0,8/4 + 1/5 + 1/6 + 0,8/7 + 0,5/8.
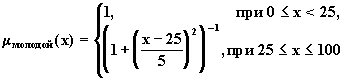 (4.19)
(4.19)
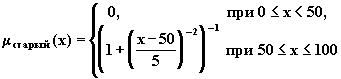 (4.20)
(4.20)
Лингвистическая переменная является переменной более высокого порядка, чем нечеткая переменная, в том смысле, что значениями лингвистической переменной являются нечеткие переменные. Лингвистические переменные предназначены в основном для анализа сложных или плохо определенных явлений. Использование словесных описаний типа тех, которыми оперирует человек, делает возможным анализ систем настолько сложных, что они недоступны обычному математическому анализу.
Значениями лингвистической переменной являются нечеткие множества, символами которых являются слова и предложения в естественном или формальном языке, служащие, как правило, некоторой элементарной характеристикой явления.
Более сложные понятия могут характеризоваться составной лингвистической переменной. Например, понятие «человек» может рассматриваться как название составной лингвистической переменной, компонентами которой являются лингвистические переменные Возраст, Рост, Вес, Внешность и т.п.
Для лингвистической переменной Возраст соответствующая базовая переменная является по своей природе числовой переменной. С другой стороны, для лингвистической переменной Внешность мы не имеем четко определенной базовой переменной. В этом случае функцию принадлежности определяют не на множестве математически точно определенных объектов, а на множестве обозначенных некими символами впечатлений.
Следует отметить, что благодаря использованию принципа обобщения большая часть существующего математического аппарата, применяющегося для анализа систем, может быть адаптирована к нечетким и лингвистическим переменным с числовой базовой переменной. Во втором случае способ обращения с лингвистическими переменными носит более качественный характер.
4.4. Лингвистические неопределенности и вычисление значений лингвистической переменной
В общем случае значение лингвистической переменной есть составной терм 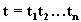 , который представляет собой сочетание элементарных термов
, который представляет собой сочетание элементарных термов 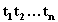 . Эти элементарные термы можно разбить на 4 категории:
. Эти элементарные термы можно разбить на 4 категории:
1. первичные термы, которые являются символами нечетких подмножеств области рассуждения (например, молодой, старый );
2. отрицание не и союзы и, или ;
3. лингвистические неопределенности типа очень, много, слабо, более или менее и т.д., которые дают возможность модифицировать значения элементарных и составных терминов и служат для увеличения области значений лингвистической переменной;
4. маркеры, такие, как скобки, вводные слова.
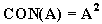
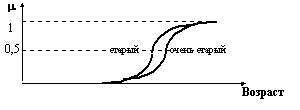
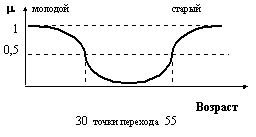
Рис. 4.7. Графическое представление терминов старый и очень старый.
Например, если терм старый определен как (4.20 ), то
очень старый = 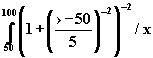 ,
,
Другой простой пример:
если терм маленький = 1/1 + 0,8/2 + 0,6/3 + 0,4/4 + 0,2/5,
то очень маленький = ( маленький ) 2 = 1/1 + 0,64/2 + 0,36/3 + 0,16/4 + 0,04/5.
Рассмотрим, например, вычисление составного терма t = не очень маленький. Учитывая, что операция дополнения соответствует отрицанию, получаем:
не очень маленький = u ( не очень маленький ) = 0,36/2 + 0,64/3 + 0,84/4 + 0,96/5
Возьмем для примера более сложный терм:
Если терм большой = 0,2/1 + 0,4/2 + 0,6/3 + 0,8/4 + 1/5,
то очень большой = ( большой ) 2 = 0,04/1 + 0,16/2 + 0,36/3 + 0,64/4 + 1/5
и не очень большой = u ( не очень большой ) = 0,96/1+ 0,84/2 + 0,64/3 + 0,36/4.
Следовательно, не очень большой и не очень маленький =
= (0,96/1+ 0,84/2 + 0,64/3 + 0,36/4) C (0,36/2 + 0,64/3 + 0,84/4 + 0,96/5)=
При вычислении значения составного терма используются обычные правила предшествования, действующие при преобразовании булевских выражений. С добавлением неопределенностей эти правила выражаются следующим образом:
Для изменения порядка предшествования можно использовать скобки.
Рассматриваемый подход можно применять к вычислению значений лингвистической переменной, при условии, что составные термы, представляющие эти значения, могут быть генерированы лишенной контекста грамматикой.
В общем случае число элементов множества Т может быть бесконечным, и тогда как для порождения элементов множества Т, так и для вычисления их смысла необходимо применять некоторый алгоритм. Говорят, что лингвистическая переменная N структурирована, если ее терм-множество Т и функцию М, которая ставит в соответствие каждому элементу терм-множества его смысл, можно задать алгоритмически.
В качестве простого примера рассмотрим лингвистическую переменную Возраст. Допустим, что терм-множество этой переменной можно записать в виде:
Данное уравнение (4.21) можно решать итеративным способом, используя рекуррентное соотношение
Взяв пустое множество  в качестве начального значения, получаем
в качестве начального значения, получаем
Т 0 =,
Т.е. решение уравнения (4.21) имеет вид
Таким образом, для данного примера синтаксическое правило выражается уравнением (4.21) и его решением (4.23). Эквивалентное представление для синтаксического правила можно охарактеризовать следующей системой подстановок:
Аналогично терм очень очень старый можно получить из Т по следующей цепочке подстановок:
Обращаясь к семантическому правилу, отметим, что для вычисления смысла такого терма требуется знать смысл терма старый и модификатора очень. Терм старый играет роль первичного терма, т.е. терма, смысл которого должен быть задан заранее с тем, чтобы можно было вычислять смысл составных термов в Т. Терм очень действует как лингвистическая неопределенность, т.е. как модификатор смысла следующего за ним терма.
Пусть теперь лингвистическая переменная Возраст имеет терм-множество вида:
Т ( Возраст ) = молодой + старый + не молодой + не старый +
М ( не очень молодой ) =  ( молодой 2 ), (4.27)
( молодой 2 ), (4.27)
М ( не очень молодой и не очень старый ) = ( молодой 2 ) C ( старый 2 ).
Эти уравнения выражают, по сути дела, смысл составного терма как функцию смысла составляющих его первичных термов.
Более общий подход базируется на определении семантики контекстно-свободных языков. Например, можно проверить, что терм-множество (4.26) порождается контекстно-свободной грамматикой 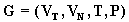 , в которой нетерминальные символы ( синтаксические категории) обозначаются
, в которой нетерминальные символы ( синтаксические категории) обозначаются
в то время как множество терминальных символов (компоненты термов в Т) выражаются в виде
а система подстановок P имеет вид
Систему P можно представить алгебраически в виде следующей системы уравнений:
Решение этой системы уравнений относительно Т является терм-множество Т, описываемое выражением (4.26). Решение системы (4.31) можно получить итеративно, используя соответствующие рекуррентные соотношения. Итерирование порождает все больше и больше термов в каждой из синтаксических категорий ( T,A,B,C,D,E).
Семантическое правило для переменной Возраст индуцируется описанным выше синтаксическим правилом, так как смысл терма в Т частично определяется его синтаксическим деревом.
В частности, каждому правилу подстановки ставится в соответствие некоторое отношение между нечеткими множествами, обозначенные определенными терминальными и нетерминальными символами. Эта двойственная система подстановок и связанных с ней уравнений типа (4.27) используется для вычисления смысла составных термов из Т следующим образом.
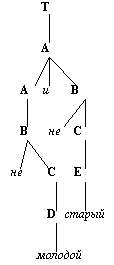
1. Рассматриваемый терм подвергается грамматическому разбору, в результате чего получается синтаксическое дерево. Конечными вершинами этого дерева являются:
а) первичные термы, смысл которых определяется априори,
б) названия модификаторов (т.е. лингвистических неопределенностей, союзов, отрицания и т.п.),
в) маркеры, такие, как скобки, которые облегчают грамматический разбор.
2. Первичным термам на конечных вершинах дерева назначается их смысл и затем с помощью системы подстановок Р и соответствующих уравнений вычисляется смысл ближайших к ним нетерминальных символов.
3. После этого дерево урезают так, чтобы вычисленные терминальные символы оказались конечными вершинами оставшегося поддерева.
лингвистическая переменная. Лекция_Лингвистическая переменная_нечеткий_вывод_семантические с. Основы нечеткой логики Лингвистическая переменная
Основы нечеткой логики
Лингвистическая переменная Лингвистической называется переменная, принимающая значения из множества слов или словосочетаний некоторого естественного или искусственного языка. Множество допустимых значений лингвистической переменной называется терм-множеством. Термом (term) называется любой элемент терм–множества. В теории нечетких множеств терм формализуется нечетким множеством с помощью функции принадлежности.
Значениями лингвистической переменной являются нечеткие множества, символами которых являются слова и предложения в естественном или формальном языке,
1) универсальное множество ;
2) терм-множество T= <"холодно", "комфортно", "жарко">с такими функциями принадлежностями:

4) М будет являться процедурой, ставящей каждому новому терму в соответствие нечёткое множество из Х по правилам: если термы А и В имели функции принадлежности μА(u) и μB(u) соответственно, то новые термы будут иметь следующие функции принадлежности, заданные в таблице:
| Квантификатор | Функция принадлежности () |
| А и В | max(μA(x), μB(x)) |
| А или В | min(μA(x), μB(x)) |
Четкая переменная
Пример: x-наименование переменной, X=R, А=[0,100]. ]100,0[∈x
Нечеткая переменная
определённая на X, говорящая о степени уверенности в том, что х является значением нечёткой переменной.
Нечеткое множество (fuzzy set)
Основным положением теории нечетких множеств является расширение классического понятия множества. В случае классического канторовского множества, о любом элементе из глобального множества можно сказать только то, что оно принадлежит или не принадлежит данному множеству. То есть характеристическая функция множества (функция, определяющая принадлежность некоторого элемента глобального множества данному множеству) принимает значения 0 либо 1. В случае расширенного понятия множества функция принадлежности может принимать любые значения из отрезка [0,1] – такое множество Л. Заде назвал нечетким множеством (fuzzy set). Таким образом, нечеткое множество А представляет собой множество упорядоченных пар вида (μ, х), где  , а
, а  , где G – глобальное множество элементов или
, где G – глобальное множество элементов или
А = <(μ, х): , >
Характеристическая функция F определяет отображение элементов глобального множества на отрезок [0,1] действительной оси: F: G → [0,1].
Функцию принадлежности нечеткого множества (характеристическая функция) можно задать несколькими способами.
Первый способ табличный – для каждого элемента глобального множества задается значение функции принадлежности элемента данному нечеткому множеству.

Для задания любой физической величины или понятия, существенного для описания системы, в нечеткой логике используется лингвистическая переменная. Лингвистическая переменная обычно обозначается словом или фразой на естественном языке, например, “скорость”, “красота”, “надежность”.
Значение, которое может принимать лингвистическая переменная, называется термом. Терм также обозначается словом или группой слов, которые характеризуют различные состояния системы относительно понятия, определяемого лингвистической переменной. Например, “надежность” может быть “высокой”, “средней”, “низкой”. Каждому терму лингвистической переменной соответствует нечеткое множество, что позволяет говорить о степени принадлежности каждого элемента глобального множества данному терму. Например, значение скорости 10 км/ч для лингвистической переменной “скорость” относится к терму “высокая” со степенью принадлежности 0.1, а к терму “низкая” со степенью 0.9. Это отражает тот факт, что скорость 10 км/ч скорее можно назвать низкой скоростью, чем высокой.
Для представления знаний, правил, по которым функционирует система, в теории нечеткой логики используются продукционные правила. Каждое продукционное правило состоит из одной или нескольких посылок и заключения. В случае нескольких посылок они соединяются связками “И” и “ИЛИ”. Левая часть правила, в которой находятся условия, носит название антецедент. Правая часть, в которой содержится результат, называется консеквент. Лингвистическую переменную, входящую в консеквент, будем называть выходной переменной. Лингвистическую переменную, которой соответствует параметр системы, для которого необходимо выработать управляющее воздействие, будем называть выводимой переменной, а сам параметр выходным параметром. Все лингвистические переменные, соответствующие параметрам, на основе которых вычисляется состояние системы в следующий момент времени, будем называть входными переменными, а такие параметры – входными параметрами.
Посылка и заключение сходны по своей структуре и содержат лингвистическую переменную и принимаемое переменной значение – терм.
Пример: ЕСЛИ (“Известность столицы” = “Популярна”) ТО (“Отпуск” = “Хороший”).
Для того чтобы реализовать необходимое управление системой необходимо уметь преобразовывать имеющиеся текущие сведения о системе и внешних факторах в точное управляющее воздействие, поскольку механизм, вырабатывающий воздействие требует указания точного численного значения, которое должно быть приложено к системе. Например, системе рулевого управления самолетом нельзя давать указания в виде “повернуть руль немного левее” – система управления потребует указания точного числа градусов, на которое нужно повернуть руль. Для этого необходимо имеющиеся точные значения входных параметров (например, отклонение от заданной траектории полета, текущий крен самолета и т.п.) преобразовать к нечетким лингвистическим переменным, затем на основе имеющихся правил сделать соответствующие заключения для выходных переменных, далее необходимо объединить результаты выводов для выводимой переменной и получить четкое значение для выработки управляющего воздействия. Этот процесс получения четкого значения для управляющего воздействия называют процессом нечеткого вывода.
Основные операции над нечеткими множествами
Основные операции над четкими множествами:
Пересечение множеств ; BACI=Объединение множеств C = A U B ;
Отрицание (дополнение) множества АC=.
Заде предложил набор аналогичных операций над НМ через операции с функциями принадлежности:
Нечеткий вывод
Нечетким логическим выводом(fuzzy logic inference) называется аппроксимация зависимости Y = f(X1,X2…Xn) каждой выходной лингвистической переменной от входных лингвистических переменных и получение заключения в виде нечеткого множества, соответствующего текущим значениях входов, с использованием нечеткой базы знаний и нечетких операций. Основу нечеткого логического вывода составляет композиционное правило Заде.
В общем случае нечеткий вывод решения происходит за три (или четыре) шага:
1) Этап фаззификации. С помощью функций принадлежности всех термов входных лингвистических переменных и на основании задаваемых четких значений из универсов входных лингвистических переменных определяются степени уверенности в том, что выходная лингвистическая переменная принимает значение – конкретный терм. Эта степень уверенности есть ордината точки пересечения графика функции принадлежности терма и прямой x = четкое значение ЛП.
2) Этап непосредственного нечеткого вывода. На основании набора правил – нечеткой базы знаний – вычисляется значение истинности для предпосылки каждого правила на основании конкретных нечетких операций, соответствующих конъюнкции или дизъюнкции термов в левой части правил. В большинстве случаев это либо максимум, либо минимум из степеней уверенности термов, вычисленных на этапе фаззификации. которое применяется к заключению каждого правила. Используя один из способов построения нечёткой импликации мы получим нечёткую нечеткую переменную, соответствующую вычисленному значению степени уверенности в левой части правила и нечеткому множеству в правой части правила.
Обычно в качестве для вывода используется минимизация или правила продукции. При минимизирующем логическом выводе, выходная функция принадлежности ограничена сверху в соответствии с вычисленной степенью истинности посылки правила(нечеткое логическое И). В логическом выводе с использованием продукций, выходная функция принадлежности масштабируется с помощью вычисленной степенью истинности предпосылки правила.
В теории нечетких множеств процедура дефаззификации аналогична нахождения характеристик положения (математического ожидания, моды, медианы) случайных величин в теории вероятности. Простейшим способом выполнения процедуры дефаззификации является выбор четкого числа, соответствующего максимуму функции принадлежности. Однако пригодность этого способа ограничивается лишь одноэкстремальными функциями принадлежности. Для многоэкстремальных функций принадлежности часто используются следующие методы дефаззификации:
1) COG (center of gravity) – «центр тяжести». Физическим аналогом этой формулы является нахождение центра тяжести плоской фигуры, ограниченной осями координат и графиком функции принадлежности нечеткого множества.
3) First Maximum («первый максимум»). Это максимум функции принадлежности с наименьшей абсциссой.
Функциональная схема процесса нечеткого вывода в упрощенном виде представлена на рисунке. На этой схеме выполнение первого этапа нечеткого вывода – фаззификации – осуществляет фаззификатор. За процедуру непосредственно нечеткого вывода ответственна машина нечеткого логического вывода, которая производит второй этап процесса вывода на основании задаваемой нечеткой базы знаний (набора правил), и этап композиции. Дефаззификатор производит последний этап нечеткого вывода – дефаззификацию.

Нечеткий логический вывод
Рассмотрим алгоритм нечеткого вывода на конкретном примере: работы автопилота при движении автомобиля по дороге.
Рассмотрим процесс нечеткого вывода на примере движения автомобиля по дороге. Будем считать, что маршрут движения автомобиля задан, и необходимо выработать управляющее воздействие на скорость автомобиля, для того, чтобы не врезаться в движущийся впереди автотранспорт, одновременно с этим необходимо как можно скорее добраться до конечной точки назначения. Для описанной ситуации параметром, влияющим на состояние системы (скорость автомобиля), очевидно, является дистанция до находящегося впереди препятствия. Поскольку необходимо выработать управляющее воздействие на скорость автомобиля то выводимой переменной является лингвистическая переменная СКОРОСТЬ. Параметр, влияющий на состояние системы – это расстояние до препятствия, которому поставим в соответствие лингвистическую переменную ДИСТАНЦИЯ. Определим значения, которые могут принимать лингвистические переменные так, как показано на Рис 
Зададимся тремя правилами, регулирующими понятие скорости:
ЕСЛИ (ДИСТАНЦИЯ = ДАЛЕКО) ТО (СКОРОСТЬ = ВЫСОКАЯ)
ЕСЛИ (ДИСТАНЦИЯ= СРЕДНЕ) ТО (СКОРОСТЬ = СРЕДНЯЯ)
ЕСЛИ (ДИСТАНЦИЯ = БЛИЗКО) ТО (СКОРОСТЬ = НИЗКАЯ)
Процесс фаззификации заключается в том, чтобы все имеющиеся точные значения входных параметров преобразовать к значениям соответствующих лингвистических переменных. Дословно фаззификация означает переход к нечеткости. В нашем случае входным параметром является дистанция до препятствия. Предположим, что значение дистанции равно 25 метров. Для каждого значения терма переменной ДИСТАНЦИЯ по имеющимся функциям принадлежности вычислим степень принадлежности значения 25 метров. Для термов БЛИЗКО, СРЕДНЕ, ДАЛЕКО значения функции принадлежности равны соответственно 0, 1, 1/6. Таким образом, четкое значение 25 метров преобразовано к нечетким значениям БЛИЗКО, СРЕДНЕ, ДАЛЕКО.
Второй этап нечеткого вывода состоит в логическом выводе выводимой переменной посредством построения цепочки правил, у которой в левой части первого правила находятся входные переменные, а в правой части последнего правила цепочки находится выводимая переменная. Промежуточные правила цепочки строятся таким образом, что в антецеденте промежуточного правила находится переменная, стоящая в консеквенте предшествующего правила. В нашем случае имеется 3 цепочки, обеспечивающие вывод для выводимой переменной. Цепочки состоят из одного правила. В левой части каждого правила находится входная переменная – ДИСТАНЦИЯ, а в правой части – выводимая переменная СКОРОСТЬ
Цель логического вывода (второго этапа нечеткого вывода) – получить степень принадлежности параметра системы, для которого формируется управляющее воздействие, к соответствующей лингвистической переменной. Если в антецеденте параметр системы принадлежит соответствующей лингвистической переменной со степенью принадлежности μ, то полагают, что параметр системы, соответствующий лингвистической переменной консеквента этого правила, также имеет степень принадлежности μ.
Каждое из правил представляет из себя нечёткую импликацию. Степень уверенности посылки мы вычислили, а степень уверенности заключения задаётся функцией принадлежности соответствующего терма. Поэтому используя один из способов построения нечёткой импликации мы получим новую нечёткую переменную, соответствующую степени уверенности о значении выходного значения при применении к заданным входным соответствующего правила. Используя определение нечёткой импликации как минимума левой и правой частей, имеем:
Предположим, что найдена цепочка правил вида
Третий этап нечеткого вывода – композиция. На этом этапе из полученных цепочек логических выводов необходимо выработать единое значение степени принадлежности выходного параметра к выводимой переменной.
 Для этого можно сгруппировать найденные цепочки по значению терма выводимой переменной в последнем правиле цепочки. Для каждой группы можно найти среднее значение степени принадлежности управляющего воздействия к выводимой переменной. В нашем случае у выводимой переменной существует 3 терма, поэтому все цепочки разбиваются на 3 группы – по одной цепочке в одной группе. То есть управляющее воздействие – скорость – принадлежит терму НИЗКАЯ со степенью принадлежности 0, СРЕДНЯЯ – со степенью 1, ВЫСОКАЯ – со степенью 1/6.
Для этого можно сгруппировать найденные цепочки по значению терма выводимой переменной в последнем правиле цепочки. Для каждой группы можно найти среднее значение степени принадлежности управляющего воздействия к выводимой переменной. В нашем случае у выводимой переменной существует 3 терма, поэтому все цепочки разбиваются на 3 группы – по одной цепочке в одной группе. То есть управляющее воздействие – скорость – принадлежит терму НИЗКАЯ со степенью принадлежности 0, СРЕДНЯЯ – со степенью 1, ВЫСОКАЯ – со степенью 1/6.
П  оследний этап нечеткого вывода – дефаззификация, то есть переход к четкости. Имея значения степени принадлежности выходного параметра к термам выводимой переменной, можно рассчитать четкое значение.
оследний этап нечеткого вывода – дефаззификация, то есть переход к четкости. Имея значения степени принадлежности выходного параметра к термам выводимой переменной, можно рассчитать четкое значение.
Одним из способов осуществить дефаззификацию является метод центроида. Необходимо найти центр массы фигуры, построенной как объединение фигур полученных от каждого терма выводимой переменной. Фигура терма ограничивается графиком функции принадлежности и линией уровня, определяющего степень принадлежности выходного параметра выводимой переменной.
Семантическая сеть, этот метод представления знаний позволяет описывать объекты, явления и понятия предметной области с помощью теории графов
Семантическая сеть представляет собой ориентированный граф, где узлы представляют понятия предметной области, а связи – отношения между понятиями. В качестве понятий обычно выступают абстрактные или конкретные объекты, концепты или события, а отношения – это связи следующих видов:
1. связи, определяющие тип объектов («это есть» или «класс-
подкласс», «иметь частью» или «часть-целое», «принадлежать» или
«элемент-множество» и т.п.);
2. функциональные связи (определяемые обычно глаголами
3. количественные («больше», «меньше», «равно» …);
5. временные («раньше», «позже», «в течение» …);
6. атрибутивные связи (иметь свойство, иметь значение. );
7. логические связи («и», «или», «не») и др.
Характерной особенностью семантических сетей является обязательное наличие в одной сети трех типов отношений:
_ экземпляр элемента класса.
Поиск решения в базе знаний типа семантической сети сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, отвечающей поставленному вопросу используя методы теории графов.
ЗАО1 поставило Клиенту1 Компьютер1 с требуемыми характеристиками. Клиент1 находится в Санкт-Петербурге, а ЗАО1 в Москве. Отобразим отношения между сущностями с помощью семантической сети.

Построения семантической сети
Для построения СС необходимо выполнить следующие шаги:
5. Проверить правильность установленных отношений (вершины
и отношения при правильном построении образуют предложение).
Пример. Построить сетевую модель представления знаний в предметной области «Автозаправка» (посещение автозаправки). Решение.
Для получения ответа на какой-либо вопрос по этой задаче, необходимо найти соответствующий участок сети и, используя отношения, получить результат.




