Что делает метод reset в классе objectoutputstream java
Only objects that support the java.io.Serializable interface can be written to streams. The class of each serializable object is encoded including the class name and signature of the class, the values of the object’s fields and arrays, and the closure of any other objects referenced from the initial objects.
The method writeObject is used to write an object to the stream. Any object, including Strings and arrays, is written with writeObject. Multiple objects or primitives can be written to the stream. The objects must be read back from the corresponding ObjectInputstream with the same types and in the same order as they were written.
Primitive data types can also be written to the stream using the appropriate methods from DataOutput. Strings can also be written using the writeUTF method.
The default serialization mechanism for an object writes the class of the object, the class signature, and the values of all non-transient and non-static fields. References to other objects (except in transient or static fields) cause those objects to be written also. Multiple references to a single object are encoded using a reference sharing mechanism so that graphs of objects can be restored to the same shape as when the original was written.
For example to write an object that can be read by the example in ObjectInputStream:
Classes that require special handling during the serialization and deserialization process must implement special methods with these exact signatures:
The writeObject method is responsible for writing the state of the object for its particular class so that the corresponding readObject method can restore it. The method does not need to concern itself with the state belonging to the object’s superclasses or subclasses. State is saved by writing the individual fields to the ObjectOutputStream using the writeObject method or by using the methods for primitive data types supported by DataOutput.
Serialization does not write out the fields of any object that does not implement the java.io.Serializable interface. Subclasses of Objects that are not serializable can be serializable. In this case the non-serializable class must have a no-arg constructor to allow its fields to be initialized. In this case it is the responsibility of the subclass to save and restore the state of the non-serializable class. It is frequently the case that the fields of that class are accessible (public, package, or protected) or that there are get and set methods that can be used to restore the state.
Serialization of an object can be prevented by implementing writeObject and readObject methods that throw the NotSerializableException. The exception will be caught by the ObjectOutputStream and abort the serialization process.
Implementing the Externalizable interface allows the object to assume complete control over the contents and format of the object’s serialized form. The methods of the Externalizable interface, writeExternal and readExternal, are called to save and restore the objects state. When implemented by a class they can write and read their own state using all of the methods of ObjectOutput and ObjectInput. It is the responsibility of the objects to handle any versioning that occurs.
Enum constants are serialized differently than ordinary serializable or externalizable objects. The serialized form of an enum constant consists solely of its name; field values of the constant are not transmitted. To serialize an enum constant, ObjectOutputStream writes the string returned by the constant’s name method. Like other serializable or externalizable objects, enum constants can function as the targets of back references appearing subsequently in the serialization stream. The process by which enum constants are serialized cannot be customized; any class-specific writeObject and writeReplace methods defined by enum types are ignored during serialization. Similarly, any serialPersistentFields or serialVersionUID field declarations are also ignored—all enum types have a fixed serialVersionUID of 0L.
Primitive data, excluding serializable fields and externalizable data, is written to the ObjectOutputStream in block-data records. A block data record is composed of a header and data. The block data header consists of a marker and the number of bytes to follow the header. Consecutive primitive data writes are merged into one block-data record. The blocking factor used for a block-data record will be 1024 bytes. Each block-data record will be filled up to 1024 bytes, or be written whenever there is a termination of block-data mode. Calls to the ObjectOutputStream methods writeObject, defaultWriteObject and writeFields initially terminate any existing block-data record.
Что делает метод reset в классе objectoutputstream java
Only objects that support the java.io.Serializable interface can be written to streams. The class of each serializable object is encoded including the class name and signature of the class, the values of the object’s fields and arrays, and the closure of any other objects referenced from the initial objects.
The method writeObject is used to write an object to the stream. Any object, including Strings and arrays, is written with writeObject. Multiple objects or primitives can be written to the stream. The objects must be read back from the corresponding ObjectInputstream with the same types and in the same order as they were written.
Primitive data types can also be written to the stream using the appropriate methods from DataOutput. Strings can also be written using the writeUTF method.
The default serialization mechanism for an object writes the class of the object, the class signature, and the values of all non-transient and non-static fields. References to other objects (except in transient or static fields) cause those objects to be written also. Multiple references to a single object are encoded using a reference sharing mechanism so that graphs of objects can be restored to the same shape as when the original was written.
For example to write an object that can be read by the example in ObjectInputStream:
Classes that require special handling during the serialization and deserialization process must implement special methods with these exact signatures:
The writeObject method is responsible for writing the state of the object for its particular class so that the corresponding readObject method can restore it. The method does not need to concern itself with the state belonging to the object’s superclasses or subclasses. State is saved by writing the individual fields to the ObjectOutputStream using the writeObject method or by using the methods for primitive data types supported by DataOutput.
Serialization does not write out the fields of any object that does not implement the java.io.Serializable interface. Subclasses of Objects that are not serializable can be serializable. In this case the non-serializable class must have a no-arg constructor to allow its fields to be initialized. In this case it is the responsibility of the subclass to save and restore the state of the non-serializable class. It is frequently the case that the fields of that class are accessible (public, package, or protected) or that there are get and set methods that can be used to restore the state.
Serialization of an object can be prevented by implementing writeObject and readObject methods that throw the NotSerializableException. The exception will be caught by the ObjectOutputStream and abort the serialization process.
Implementing the Externalizable interface allows the object to assume complete control over the contents and format of the object’s serialized form. The methods of the Externalizable interface, writeExternal and readExternal, are called to save and restore the objects state. When implemented by a class they can write and read their own state using all of the methods of ObjectOutput and ObjectInput. It is the responsibility of the objects to handle any versioning that occurs.
Enum constants are serialized differently than ordinary serializable or externalizable objects. The serialized form of an enum constant consists solely of its name; field values of the constant are not transmitted. To serialize an enum constant, ObjectOutputStream writes the string returned by the constant’s name method. Like other serializable or externalizable objects, enum constants can function as the targets of back references appearing subsequently in the serialization stream. The process by which enum constants are serialized cannot be customized; any class-specific writeObject and writeReplace methods defined by enum types are ignored during serialization. Similarly, any serialPersistentFields or serialVersionUID field declarations are also ignored—all enum types have a fixed serialVersionUID of 0L.
Primitive data, excluding serializable fields and externalizable data, is written to the ObjectOutputStream in block-data records. A block data record is composed of a header and data. The block data header consists of a marker and the number of bytes to follow the header. Consecutive primitive data writes are merged into one block-data record. The blocking factor used for a block-data record will be 1024 bytes. Each block-data record will be filled up to 1024 bytes, or be written whenever there is a termination of block-data mode. Calls to the ObjectOutputStream methods writeObject, defaultWriteObject and writeFields initially terminate any existing block-data record.
Потоки вывода, OutputStream
Стандартная библиотека Java имеет весьма развитые средства вывода данных. Все возможности вывода данных сосредоточены в пакете java.io.
Существуют две параллельные иерархии классов вывода : OutputStream и Writer. Класс Writer введен в последних версиях Java.
В данной статье рассматривается вопрос использования потоков для вывода данных в файл. Иерархии выходных OutputStream потоков представлена на следующем рисунке.
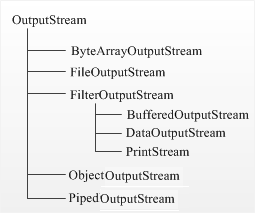
Поток Stream— это абстрактное значение источника или приёмника данных, которые способны обрабатывать информацию. Есть два типа потоков: байтовые и символьные. В некоторых ситуациях символьные потоки более эффективны, чем байтовые. Классы, производные от классов OutputStream или Writer, имеют методы с именами write() для записи одиночных байтов или массива байтов (отвечают за вывод данных).
Выходной поток OutputStream
Методы класса OutputStream :
Класс ByteArrayOutputStream
Класс ByteArrayOutputStream представляет поток вывода, использующий массив байтов в качестве места вывода. Чтобы создать объект данного класса, можно использовать один из его конструкторов :
Первый конструктор создает массив данных для хранения байтов длиной в 32 байта, а второй конструктор создает массив длиной size.
Примеры использования класса ByteArrayOutputStream :
В классе ByteArrayOutputStream метод write записывает в поток некоторые данные (массив байтов). Этот массив байтов записывается в объекте ByteArrayOutputStream в защищенное поле buf, которое представляет также массив байтов (protected byte[] buf). Так как метод write может вызвать исключение, то вызов этого метода помещается в блок try..catch.
Используя методы toString() и toByteArray(), можно получить массив байтов buf в виде текста или непосредственно в виде массива байт.
С помощью метода writeTo можно перенаправить массив байт в другой поток. Данный метод в качестве параметра принимает объект OutputStream, в который производится запись массива байт :
Для ByteArrayOutputStream не надо явным образом закрывать поток с помощью метода close.
Класс FileOutputStream
Класс FileOutputStream создаёт объект класса OutputStream, который можно использовать для записи байтов в файл. Это основной класс для работы с файлами. Создание нового объекта не зависит от того, существует ли заданный файл или нет. Если файл отсутствует, то будет создан новый файл. В случае попытки открытия файла, доступного только для чтения, будет вызвано исключение.
FileOutputStream имеет следующий конструкторы:
Смысл конструкторов последнего понятен из их описания. Но имеется несколько нюансов :
Какой-либо дополнительной функциональности по сравнению с базовым классом FileOutputStream не добавляет.
Класс BufferedOutputStream
Класс BufferedOutputStream создает буфер для потоков вывода. Этот буфер накапливает выводимые байты без постоянного обращения к устройству. И когда буфер заполнен, производится запись данных.
BufferedOutputStream не добавляет много новой функциональности, он просто оптимизирует действие потока выводаи его следует использовать для организации более эффективного буферизованного вывода в поток.
Класс DataOutputStream
Класс DataOutputStream позволяет писать данные в поток через интерфейс DataOutput, который определяет методы, преобразующие элементарные значения в форму последовательности байтов. Такие потоки облегчают сохранение в файле двоичных данных.
Для записи каждого из примитивных типов предназначен свой метод класса DataOutputStream:
Класс PrintStream
Но PrintStream можно использовать для записи информации в поток вывода. Например, запишем информацию в файл:
В данном примере используется конструктор PrintStream, который в качестве параметра принимает поток вывода FileOutputStream. Можно было бы также использовать конструктор с указанием названия файла для записи: PrintStream (String filename).
Для вывода информации в выходной поток PrintStream использует следующие методы:
Следующий код показывает возможности использования форматированного вывода класса PrintStream :
Класс ObjectOutputStream
Класс ObjectOutputStream используется для сериализации объектов в поток. Сериализация представляет процесс записи состояния объекта в поток, соответственно процесс извлечения или восстановления состояния объекта из потока называется десериализацией. Сериализация очень удобна, когда идет работа со сложными объектами.
Для создания объекта ObjectOutputStream необходимо в конструктор передать поток, в который будет производится запись объектов.
Для записи данных ObjectOutputStream использует ряд методов, среди которых можно выделить следующие:
| Метод | Описание |
|---|---|
| void close() | закрывает поток |
| void flush() | сбрасывает содержимое буфера в выходной поток и очищает его |
| void write(byte[] buf) | записывает в поток массив байтов |
| void write(int val) | записывает в поток один младший байт из val |
| void writeBoolean(boolean val) | записывает в поток значение boolean |
| void writeByte(int val) | записывает в поток один младший байт из val |
| void writeChar(int val) | записывает в поток значение типа char, представленное целочисленным значением |
| void writeDouble(double val) | записывает в поток значение типа double |
| void writeFloat(float val) | записывает в поток значение типа float |
| void writeInt(int val) | записывает целочисленное значение |
| void writeLong(long val) | записывает значение типа long |
| void writeShort(int val) | записывает значение типа short |
| void writeUTF(String str) | записывает в поток строку в кодировке UTF-8 |
| void writeObject(Object obj) | записывает в поток отдельный объект |
Представленные методы охватывают весь спектр данных, которые можно сериализовать.
Пример использования класса ObjectOutputStream :
Необходимо принимать во внимание, что сериализовать можно только те объекты, которые реализуют интерфейс Serializable.
Класс PipedOutputStream
Пакет java.io содержит класс PipedOutputStream, который может быть подключен к PipedInputStream, используемый для установления связи между двумя каналами. Данные в PipedOutputStream передаются в потоке Thread, который отправляет их в подключенный PipedInputStream, где данные также читаются, но в другом потоке.
То есть, класс PipedOutputStream предназначен для передачи информации между программами через каналы (pipes).
Наиболее часто используемые методы класса PipedOutputStream :
Все методы класса могут вызвать исключение IOException.
Пример использования класса PipedOutputStream :
Разница между flush () и reset () в JAVA
3 ответа
Почему используется метод сброса, если кэш памяти очищается методом очистки?
Сброс будет игнорировать состояние любых объектов, уже записанных в поток.
Объекты, ранее записанные в поток, не будут упоминаться как уже находящиеся в потоке. Они будут снова записаны в поток.
Эти детали важны, поскольку ObjectOutputStream использует механизм совместного использования ссылок.
Поэтому запись в поток несколько раз одного и того же объекта, но с другим состоянием, приведет к записи объекта с исходным состоянием несколько раз.
Документация верхнего уровня ObjectOutputStream объясняет, что и еще (акцент мой):
Пример, иллюстрирующий проблему с кешем ObjectOutputStream :
Выполните этот класс, который пишет 10 раз один и тот же объект, но с другим состоянием i nan ObjectOutputStream без вызова reset() между записями:
С Foo определяется как:
По мере ознакомления с содержанием ЛС вы получите:
Раскомментируйте reset() и вы увидите изменения:
Сброс () будет игнорировать состояние любых объектов, уже записанных в поток. Состояние сбрасывается, чтобы быть таким же, как новый ObjectOutputStream. Текущая точка в потоке помечена как сброшенная, поэтому соответствующий ObjectInputStream будет сброшен в той же точке. Объекты, ранее записанные в поток, не будут считаться уже находящимися в потоке. Они будут снова записаны в поток.
Метод flush () очищает поток. Это записывает любые буферизованные выходные байты и сбрасывает их в основной поток.
Метод flush() будет очищать буфер и записывать в поток, а reset() будет использоваться для изменения объектов, которые уже были записаны в поток.
reset() сделает недействительными все отправленные объекты. При повторной отправке неизмененных объектов передается только ссылка, позволяющая повторно использовать кэшированную версию уже переданного объекта. Это гораздо эффективнее, чем всегда отправлять весь объект.
С другой стороны, flush() будет только следить за тем, чтобы данные действительно записывались в поток. Операция записи только помещает данные в буфер и может записывать их в поток в зависимости от размера буфера. Вызов flush() гарантирует, что данные будут записаны в поток. Но flush не очистит кэшированные объекты.
Пакет java.io
Сериализация объектов (serialization)
Стандартная сериализация
А чтобы восстановить объект, его нужно десериализовать из этого массива:
Теперь можно убедиться, что восстановленный объект идентичен исходному:
Результатом выполнения приведенного выше кода будет:
Как мы видим, восстановленный объект не совпадает с исходным (что очевидно – ведь восстановление могло происходить и на другой машине), но равен сериализованному по значению.
Восстановление состояния
Итак, сериализация объекта заключается в сохранении и восстановлении состояния объекта. В Java в большинстве случаев состояние описывается значениями полей объекта. Причем, что важно, не только тех полей, которые были явно объявлены в классе, от которого порожден объект, но и унаследованных полей.
С другой стороны, не меньшей проблемой является восстановление объекта. Как говорилось раньше, объект может быть создан только вызовом его конструктора. У класса, от которого порожден десериализуемый объект, может быть несколько конструкторов, причем, некоторые из них, или все, могут иметь аргументы. Какой из них вызвать? Какие значения передать в качестве аргументов?
Результат выполнения примера:
Некоторые поля хранят значения, которые не будут иметь смысла при пересылке объекта на другую машину, или при воссоздании его спустя какое-то время. Например, сетевое соединение, или подключение к базе данных, в таких случаях нужно устанавливать заново.
Затем, в объекте может храниться конфиденциальная информация, например, пароль. Если такое поле будет сериализовано и передано по сети, его значение может быть перехвачено и прочитано, или даже подменено.
У такого класса поле password в сериализации участвовать не будет и при восстановлении оно получит значение по умолчанию (в данном случае null ).
Граф сериализации
Для организации такого процесса стандартный механизм сериализации строит граф, включающий в себя все участвующие объекты и ссылки между ними. Если очередная ссылка указывает на некоторый объект, сначала проверяется – нет ли такого объекта в графе. Если есть – объект второй раз не сериализуется. Если нет – новый объект добавляется в граф.
Выполнение этой программы приведет к выводу на экран примерно следующего:
Из примера видно, что после восстановления у линий сохраняется общая точка, описываемая одним и тем же объектом (хеш-код 386e ).
Если теперь запустить программу, то можно увидеть, что третий объект получит номер 3.
Однако это будет уже новый объект, ссылка на который отличается от первой считанной линии. Более того, обе точки будут также описываться новыми объектами. То есть в новом сеансе все объекты были записаны, а затем восстановлены заново.
Расширение стандартной сериализации
В свою очередь, при десериализации метод readObject должен считать данные из потока in (также полученного в качестве аргумента) и восстановить значения полей класса. При реализации этого метода можно обратиться к стандартному механизму с помощью метода:
Этот метод считывает описание объекта из потока и присваивает значения соответствующих полей в текущем объекте.
Метод writeExternal имеет сигнатуру:
эти значения должны быть считаны в том же самом порядке.



