Как браузер работает с адресом сайта?
Адрес любого сайта в сети Интернет (URL), содержит множество данных в своей строке. Но как же наш браузер использует URL, чтобы выдать нам желаемую страницу?
Существует последовательность шагов, которые делает браузер когда ищет и выдает нам желаемый сайт в Интернете.

1. В первую очередь браузер выясняет на каком веб-сервере лежит искомая нами страница. Определяет он это по доменному имени сайта. Как только браузер определил веб-сервер он вступает с ним в контакт.
2. Любой компьютер и сервер в Интернете имеет свой IP адрес IP адрес это набор из четырех чисел разделенных периодами (точками) пример IP адреса 75.342.34.191
3. Используя доменное имя с адресной строки сайта, браузер преобразовывает его в IP адрес.
4. Далее браузер посылает запрос на IP адрес сервера.
5. Получивший запрос веб-сервер используя путь и имя файла находит запрашиваемый файл и отсылает назад браузеру. Если сервер не найдет запрашиваемый файл, он посылает браузеру сообщение об ошибке.
6. Как только браузер получает от сервера веб-станицу, он показывает ее на компьютере пользователя.
Если в строке адреса не указано имя файла, то браузер делает запрос серверу как есть, а сервер как правило отсылает индексную страницу сайта index.html
На этом все, на связи был Кравченко Роман. Удачи!
Как работает DNS
В предыдущих статьях мы рассказали, как придумали доменные имена и кто контролирует их работу. Сегодня узнаем, как браузер понимает, где находится сайт, когда мы вводим в адресной строке домен.

Из статьи вы узнаете:
Что такое DNS
DNS — это технология, которая помогает браузеру найти правильный сайт по доменному имени.
Вы уже знаете, что компьютеры находят друг друга в интернете по IP-адресам. Чтобы подключиться к серверу с конкретным сайтом, нужно знать его IP-адрес. Похожим образом устроена мобильная связь: чтобы позвонить конкретному человеку, нужно знать его номер.
Людям неудобно использовать длинные комбинации цифр, поэтому IP-адреса придумали связывать с понятными текстовыми именами — доменами. Всё-таки запомнить google.com проще, чем 216.58.209.14.
По такой же логике мы сохраняем важные номера в контакты смартфона. Только в случае с доменами, ничего сохранять не нужно. Мы просто вводим в адресной строке домен, а браузер сам находит IP-адрес нужного сервера и открывает сайт.
ВИДЕО ПО ТЕМЕ:
Прочитать статью — хорошо, а прочитать статью
и посмотреть видео — еще лучше!
Смотрите наше видео о том, что такое домен и IP-адрес сайта
Как это работало раньше
В первые годы интернета доменам присваивали IP-адреса вручную. Их записывали в текстовый файл hosts.txt в таком формате:
216.58.209.14 google.com
По сути это и был список контактов, как в смартфоне. Когда пользователь вводил в адресной строке домен, браузер проверял файл и брал из него IP-адрес.
Главным файлом управлял Стэнфордский исследовательский институт. Чтобы добавить в список новый сайт, нужно было звонить в институт по телефону. После этого все компьютеры в сети должны были скачать обновлённый файл.
Со временем такой подход стал отнимать много времени, так как требовалось вносить всё больше и больше данных, и технологию решили усовершенствовать. Новую систему придумали Пол Мокапетрис и Джон Постел в 1984 и назвали её DNS-протокол. Аббревиатура означала Domain Name System, по-русски — Система доменных имён.
1212 доменных зон для любых проектов!
.com .com.ua .info .online .in.ua .net .kiev.ua .site .pl .ORG .pro .ru .org.ua .eu

Что такое DNS-сервер
Настройки каждого домена в интернете хранятся в текстовых файлах на DNS-серверах.
DNS-сервер — это специальный компьютер, который хранит IP-адреса сайтов. Основные функции сервера DNS — выдавать браузеру адрес сайта по доменному имени и кэшировать DNS-записи домена. То есть сервер DNS простыми словами — это всё та же «книга контактов», тот же файл hosts.txt, только больших масштабов.
Когда вы открываете в браузере сайт, в поиске IP-адреса домена обычно участвуют несколько DNS-серверов:
Локальный DNS-сервер вашего интернет-провайдера. Браузеры используют DNS-сервер провайдера, чтобы с его помощью узнать IP-адрес сервера, где находится сайт. Для этого в каждом браузере есть специальная программа — DNS-клиент. Вместо серверов вашего провайдера может быть любой другой публичный DNS-сервер, если вы укажете его в сетевых настройках. Например, вместо DNS-серверов интернет-провайдера можно использовать публичные серверы DNS от Google.
DNS-сервер верхнего уровня. DNS-серверы верхнего уровня содержат информацию о DNS-зоне и называются корневыми. Они выдают по запросу DNS-серверы доменов первого уровня, например, COM, UA, ORG, NET, ONLINE. Корневыми серверами управляют разные организации. Впервые такие DNS-серверы появились в Северной Америке, но со временем их количество росло и они появлялись в других странах. Сейчас есть 13 основных DNS-серверов верхнего уровня и множество реплик.
DNS-сервер, который отвечает за домен и где хранятся записи доменного имени. Адреса DNS-серверов владельцу домена обычно приходится указывать вручную — их присылает хостинг-провайдер. Например, наши публичные DNS-серверы — dns1.hostiq.ua и dns2.hostiq.ua.
Как браузер находит IP-адрес домена
Разберёмся пошагово, как браузер понимает, где находится сайт, когда мы вводим в адресной строке домен:
Шаг 1 Вы вводите в адресной строке доменное имя, например, google.com. Сначала браузер проверяет файл hosts.txt на компьютере. Если там не оказывается нужного IP-адреса, он обращается к локальному DNS-серверу вашего интернет-провайдера. Его IP-адрес браузер находит в настройках подключения к интернету.
Шаг 3 Локальный DNS-сервер получает IP-адрес одного из этих DNS-серверов и задаёт тот же вопрос ему. Этот DNS-сервер тоже не знает IP-адрес Гугла, но знает IP-адреса DNS-серверов, которые использует google.com.
Шаг 4 Локальный DNS-сервер получает IP-адрес одного из этих DNS-серверов и обращается к нему. Этот DNS-сервер знает нужный IP-адрес и отправляет его локальному DNS-серверу.
Шаг 5 Локальный DNS-сервер получает нужный IP-адрес и отправляет его браузеру.
Что стоит за простой загрузкой веб-странички в браузере
На собеседованиях мы часто просим кандидата рассказать настолько подробно, насколько он может, что происходит, когда вводишь в адресной строке браузера адрес сайта и нажимаешь кнопку “Ввод”. В зависимости от того, кого собеседуем — фронтендщика или бекендщика — мы ожидаем разные ответы. А как бы выглядел идеальный ответ на этот вопрос? Ниже мой вариант ответа.
Итак, пользователь вводит в адресной строке браузера адрес сайта и нажимает кнопку “Ввод”.
Браузер состоит из нескольких компонентов, одним из которых является User Interface. Адресная строка как раз является одной из частей этого компонента.
User Interface после ввода URL в адресной строке передаёт управление компоненту Browser Engine, который отвечает за взаимодействие различных компонентов браузера.
Чтобы сделать запрос по указанному URL, браузеру нужно знать IP сервера. Первым делом он смотрим в свой локальный кэш DNS.Компонент Browser Engine как раз имеет доступ к этому кэшу.
Если там нет соответствующей записи, то браузер передаёт управление операционной системе, которая проверяет свой кэш DNS. Если и там отсутствует соответствующая запись, то ОС смотрит в локальные хосты (файл /etc/hosts в Unix-системах). Если запись о хосте отсутствует, то операционная система обращается к интернет провайдеру, у которого тоже есть свой кэш DNS на своих рекурсивных серверах DNS. В случае отсутствия записи в кэше на серверах DNS провайдера, запрос идёт на корневой DNS. У корневого DNS тоже есть кэш. Если соответствующей записи в кэше корневого DNS нет, запрос идёт дальше по цепочке серверов DNS.
Если на любом из этапов находится нужная запись, то она сохраняется во всех кэшах и управление возвращается браузеру, который уже знает IP нужного сервера.
Процесс получения IP адреса называется DNS lookup.
Далее Browser Engine смотрит в локальном кэше, нет ли запрашиваемой страницы. Если страницы в кэше нет, то Browser Engine передаёт управление компоненту Rendering Engine, который обращается к компоненту Networking Component, чтобы тот сделал запрос GET на указанный IP на порт 80 по протоколу HTTP или на порт 443 по протоколу HTTPS (в зависимости от указанного протокола в URL) со своими стандартными HTTP заголовками. Среди стандартных заголовков есть заголовок host, в котором передаётся хост запрашиваемого сайта (в нашем примере site.com.ua). Если в браузере хранятся куки к этому домену, то он отправляет их в заголовке cookie. Запрос будет выполнен, если соответствующий порт на пользовательском компьютере открыт.
На сервере запрос принимает веб-сервер (например, nginx или apache).
В конфигурационных файлах веб-сервера прописаны обслуживаемые хосты. Веб-сервер достаёт хост из заголовка запроса host и сопоставляет с теми, которые указаны в конфигурации. Если есть совпадение, то веб-сервер находит в конфигурационном файле правила обработки такого запроса и выполняет их. Дальнейшее поведение сервера зависит от технологии и особенностей приложения. Здесь может происходить работа с базами данных, кэшами, запросы к другим серверам и сервисам, выполнение различных скриптов. Для простоты представим, что приложение сгенерировало файл HTML, и веб-сервер отдал его браузеру.
Браузер получил файл HTML с соответствующими HTTP заголовками от сервера, в которых указана длина контента (заголовок Content-Length), тип контента (заголовок Content-Type со значением “text/html; charset=UTF-8” для файлов HTML), заголовки для кэширования. Если присутствуют кэширующие заголовки, то браузер сохраняет файл в локальный кэш.
Заголовки ответа сервера можно увидеть в Chrome DevTools на вкладке Networking, выбрав нужный запрос
Если DOCTYPE отсутствует, то браузер переключится в режим quirks mode и попытается разобрать документ HTML, однако многие элементы будут проигнорированы. Если указан корректный DOCTYPE, то браузер будет работать в standards mode и будет разбирать документ в соответствии с правилами той версии, которая указана в DOCTYPE.
Rendering Engine начинает разбор документа HTML.
Создаётся DOM (Document Object Model). В браузере этот объект доступен по ссылке, которая хранится в переменной document. У документа есть несколько состояний. Первое состояние — loading. Оно означает, что документ только начал формироваться.
Состояние документа хранится в переменной document.readyState.
Также создаётся объект styleSheets, который будет хранить все стили.
Все стили на странице доступны по ссылке, которая хранится в переменной document.styleSheets.
Любой файл — это набор байтов. Браузер берёт полученный набор байтов и преобразует их в символы по таблице символов в соответствии с кодировкой, которая была передана в заголовке Content-Type. В нашем примере это кодировка UTF-8.
Далее токены собираются в узлы (nodes). Эти узлы и сохраняются в DOM со всеми взаимными связями.
Во время разбора, если Rendering Engine встречает ссылку на внешний ресурс, то он передаёт команду загрузить этот ресурс компоненту Networking Component. Это может быть ссылка на стили, скрипты, картинки и т.п. Networking Component ставит все ресурсы в очередь на загрузку. Каждому ресурсу Networking Component присваивает приоритет.
Приоритеты ресурсов можно посмотреть в Chrome DevTools на вкладке Networking в колонке Priority.
Так, у HTML, CSS и шрифтов самый высокий приоритет. У изображений приоритет изначально низкий, но если Rendering Engine обнаружит, что изображение попадает в поле видимости (view port) пользователя, то повысит приоритет до среднего. Приоритет скрипта зависит от положения на странице и способа загрузки. У асинхронных скриптов (async/defer) низкий приоритет. У скриптов, которые в документе перед изображениями — высокий, у тех, что после хотя бы одного изображение — средний.
По возможности браузер пытается загружать ресурсы параллельно. Однако, он не может загружать параллельно более 6 ресурсов с одного домена.
Кроме того, когда Rendering Engine отдаёт команду компоненту Networking Component на синхронную загрузку стиля или скрипта, он останавливает разбор документа.
Во многих современных браузерах во время исполнения JavaScript в отдельном потоке продолжается сканирование документа на наличие ссылок на другие ресурсы и постановка ресурсов в очередь на скачивание (Speculative parsing).
Каждый этап разбора HTML, CSS и JS можно увидеть в Chrome DevTools во вкладке Performance
Если при загрузке скрипта Rendering Engine видит у скрипта атрибут async, то он не останавливает разбор документа во время загрузки скрипта. Скрипт также станет в очередь на исполнение, дожидаясь, когда CSSOM будет готова.
Если при загрузке скрипта Rendering Engine видит у скрипта атрибут defer, то он не останавливает разбор документа во время загрузки скрипта, но когда скрипт загрузится, он станет в очередь на исполнение, которая заработает при возникновении события DOMContentLoaded. К этому моменту CSSOM будет уже готова.
Когда Rendering Engine заканчивает разбор документа, он вызывает событие DOMContentLoaded, и состояние документа меняется на interactive. При этом ресурсы (например, картинки) могут продолжать загружаться.
Когда все ресурсы загрузились, вызывается событие load, а состояние документа меняется на complete.
После того, как документ полностью разобран и сформированы DOM и CSSOM, Rendering Engine начинает построение Render Tree. В него попадут все элементы, которые нужно отрисовать. Некоторые элементы изначально могут быть невидимыми — их не нужно рисовать. Для каждого элемента, который “выпадает” из потока (например, используется position: absolute), будет создаваться отдельная ветка в Render Tree.
Во время Rendering Tree происходит сопоставление узлов из DOM и узлов CSSOM.
Свойства узла можно получить с помощью функции window.getComputedStyles(узел).
Когда Rendering Tree готов, Rendering Engine запускает процесс layout. Он заключается в вычислении размеров и позиций каждого элемента на странице.
Следующий этап — paint. Rendering Engine вычисляет цвет каждого пикселя.
И, наконец, последний этап — composite. Компонент UI Backend слой за слоем отрисовывает элементы на странице. При этом, если требуется отрисовать изображение, которое ещё не загрузилось, во время процесса layout, Rendering Engine зарезервирует место для изображения, если у него указаны ширина и высота. Rendering Engine вынесет на отдельный слой те элементы, стили которых содержат правила opacity, transform или will-change. Более того, эти слои Rendering Engine передаст для обработки GPU.
Если требуется отобразить текст, для которого используется нестандартный шрифт, то современные браузеры скроют текст до момента загрузки шрифта (flash of invisible text).
В современных браузерах скачивание документа, его разбор и отрисовка происходят по кускам, частями.
В документе HTML могут присутствовать некоторые мета-теги, которые могут менять порядок загрузки ресурсов, а также их приоритет.
К примеру, мета-тег dns-prefetch вынуждает Rendering Engine обратиться к Networking Component и получить IP нужного домена ещё до того, как Rendering Engine встретить его в документе.
Мета-тег prefetch вынудит Networking Component поставить указанный ресурс в очередь на загрузку с низким приоритетом.
Мета-тег preload вынудит Networking Component поставить указанный ресурс в очередь на загрузку с высоким приоритетом.
Мета-тег preconnect вынудит Networking Component заранее подключиться к другом хосту, то есть пройти нужные этапы: DNS lookup, redirects, hand shakes.
Браузер: общие принципы работы программы по отображению сайтов

Когда дело доходит до мощного и универсального программного обеспечения, ничто не может сравниться с веб-браузером. Будь то машина Intel с архитектурой x86 или смартфон, использующий микрокод ARM; веб-браузеры предлагают феноменальную производительность на любом используемом вами оборудовании. Они настолько мощны, что могут заменить полноценную операционную систему, и Chrome OS — яркий тому пример.
Браузеры — это произведение искусства, но задумывались ли вы, что происходит за кулисами; весь процесс ввода запроса и возврата результата браузером? Что ж, в этой статье мы рассмотрим, как работает браузер и как он отображает веб-страницы за считанные секунды.
Все начинается с запросов и сетевого уровня.
Когда вы посещаете веб-сайт в Интернете, ваш браузер только подключается к удаленному компьютеру (веб-серверу) и запрашивает ресурсы для раскраски страницы. Это может показаться тривиальным, но под капотом ваш браузер обрабатывает миллионы чисел, чтобы найти и отобразить веб-сайт на вашем экране.
Чтобы отобразить веб-страницу, первое, что нужно сделать вашему браузеру, — это найти удаленный сервер, на котором размещен веб-сайт. Для этого он пытается найти IP-адрес URL-адреса, введенного вами в адресной строке. Этот IP-адрес может однозначно идентифицировать веб-сервер, и как только браузер получит этот адрес, он сможет отправлять запросы на сервер для получения данных.
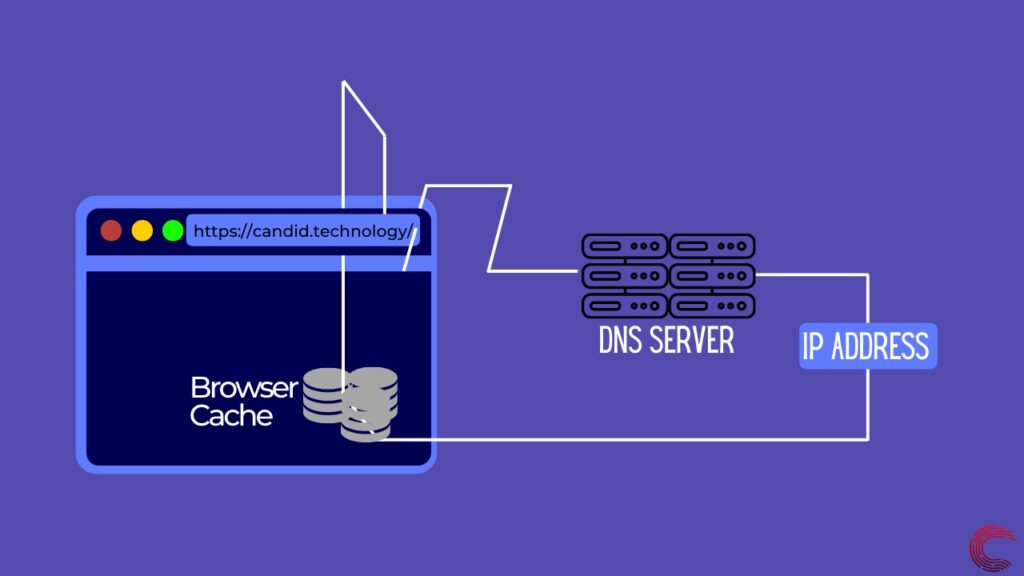
Чтобы найти IP-адрес, браузер выполняет разрешение DNS, которое можно сделать только двумя способами. Он может либо заглянуть в кеш-память вашего браузера, которая может содержать IP-адрес URL-адреса, если вы посещали сайт в прошлом. Если это не так, он запрашивает у вашего интернет-провайдера, Google или Cloudflare IP-адрес определенного веб-сайта, используя их DNS-серверы.
Как только ваш браузер получит IP-адрес веб-сайта, который вы ищете, сетевой уровень вашего браузера начнет работать. Он пытается установить соединение между вашим устройством и сервером, чтобы данные могли передаваться между двумя устройствами. Для создания этого соединения сетевой уровень использует сокеты, которые представляют собой способ соединения двух устройств в сети с использованием их IP-адреса и назначенного порта на каждом устройстве.
Теперь, когда сетевой уровень соединил два устройства и пакеты данных могут передаваться между ними, сетевой уровень начинает выполнять следующую по важности задачу в любой коммуникации в Интернете — шифрование.
Чтобы зашифровать данные, сетевой уровень выполняет рукопожатие TLS между двумя взаимодействующими устройствами. После завершения рукопожатия все данные, передаваемые между устройствами, зашифровываются и не могут быть прочитаны третьими лицами.
Рукопожатие TLS выполняется только тогда, когда данные передаются с использованием протокола HTTPS, а в случае HTTP выполняется только рукопожатие TCP. Это не шифрует данные; поэтому вы никогда не должны отправлять конфиденциальные данные через HTTP-соединение, поскольку любой злонамеренный объект может видеть ваши данные
После настройки канала связи между двумя устройствами сетевой уровень отправляет запрос на сервер для ресурсов. В случае веб-страницы это HTTPS/HTTP-запрос, который просит веб-сервер отправить HTML-файл, содержащий всю информацию, необходимую браузеру для отображения веб-страницы. Как только сервер получает запрос, он отправляет HTML-документ браузеру в виде единиц и нулей по каналу связи, установленному сетевым уровнем.
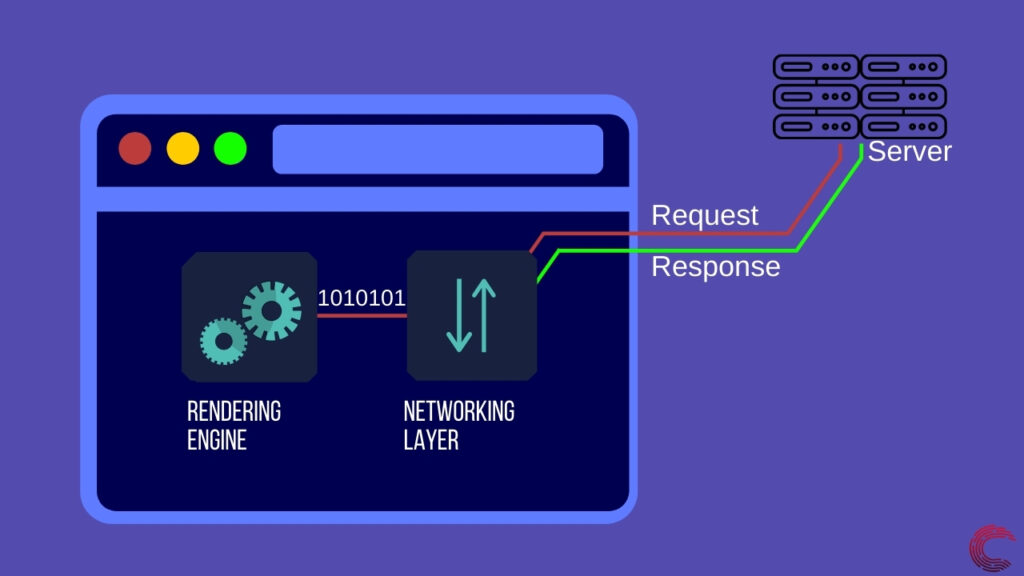
Наконец, в браузере есть ресурсы, необходимые для отображения веб-страницы, но они представлены в виде байтов и должны быть преобразованы в формат, который выглядит как веб-страница. Для этого браузер использует свой механизм рендеринга.
Получение смысла из битов с помощью механизма рендеринга
Теперь, когда сетевой уровень сделал запросы к веб-серверу и получил все данные, необходимые браузеру, на сцену выходит механизм визуализации.
Основная задача механизма рендеринга — преобразовать биты данных в форму, которая может быть использована браузером для создания веб-страницы. Чтобы понять, как работает механизм рендеринга, важно понимать все части, из которых состоит веб-сайт.
Механизм визуализации использует синтаксические анализаторы для преобразования битов данных в значимую информацию, которая может использоваться браузером для визуализации веб-страницы. Механизм рендеринга имеет два разных парсера: один для HTML и один для CSS. Давайте посмотрим, как работает анализатор HTML, чтобы получить представление о процессе синтаксического анализа.
Разбор HTML
Анализатор HTML принимает биты данных в качестве входных данных и создает логическое представление документа HTML в памяти устройства. Это логическое представление данных известно как структура DOM и представляет данные HTML в иерархическом порядке.
Чтобы создать структуру DOM, парсер HTML выполняет несколько шагов, которые можно описать следующим образом.
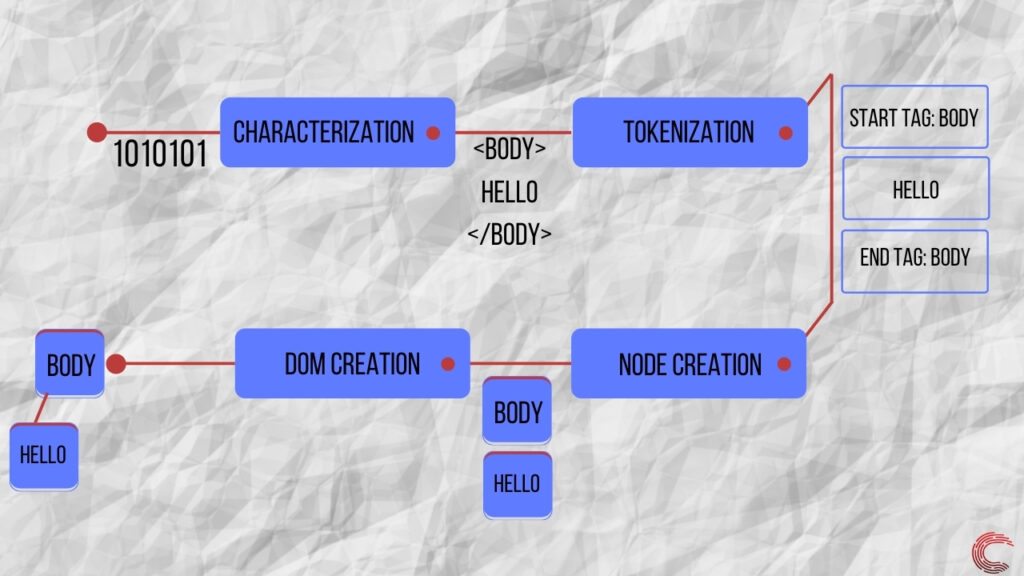
HTML-документ, который получает браузер, содержит ссылки на файлы CSS. Эти ссылки обрабатываются сетевым уровнем и отправляются синтаксическому анализатору CSS. Этот синтаксический анализатор создает вывод CSSOM (объектная модель CSS), который определяет, как должен быть стилизован каждый элемент в DOM.
Создание дерева отрисовки и макета для веб-страницы
После создания модели DOM и завершения синтаксического анализа CSS-файла механизм визуализации использует механизм стилей для объединения как CSSOM, так и DOM. Это создает дерево визуализации, которое содержит информацию о структуре и стиле веб-страницы, которая должна отображаться. Дерево рендеринга состоит только из видимых узлов и не имеет узлов, невидимых для пользователя на экране.
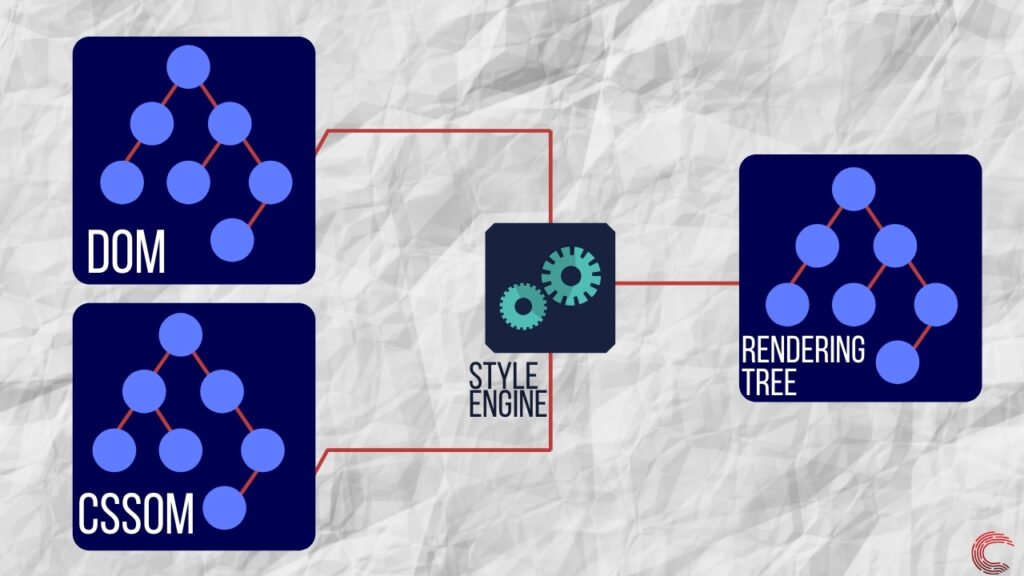
После создания дерева рендеринга механизм рендеринга запускает процесс компоновки. Этот процесс учитывает разрешение экрана и то, как каждый элемент должен быть размещен на устройстве. Он также вычисляет размер каждого элемента, который будет отображаться на экране, и его относительное положение по отношению к другим элементам.
Теперь, когда движок рендеринга имеет всю информацию о веб-странице в формате, понятном нашей системе, мы можем начать рендеринг страницы в браузере.
Рисование холста и компоновка веб-страницы на экране
Операция рисования происходит в многоуровневом формате, и механизм визуализации создает несколько слоев элементов для создания веб-страницы. Эта многоуровневая структура помогает браузеру быстрее вносить изменения, когда пользователь взаимодействует с веб-страницей.
После того, как все слои созданы, механизм визуализации отправляет эту информацию в пользовательский интерфейс, отображая веб-страницу на экране. Этот процесс известен как создание веб-страницы и является последним шагом, выполняемым механизмом рендеринга.
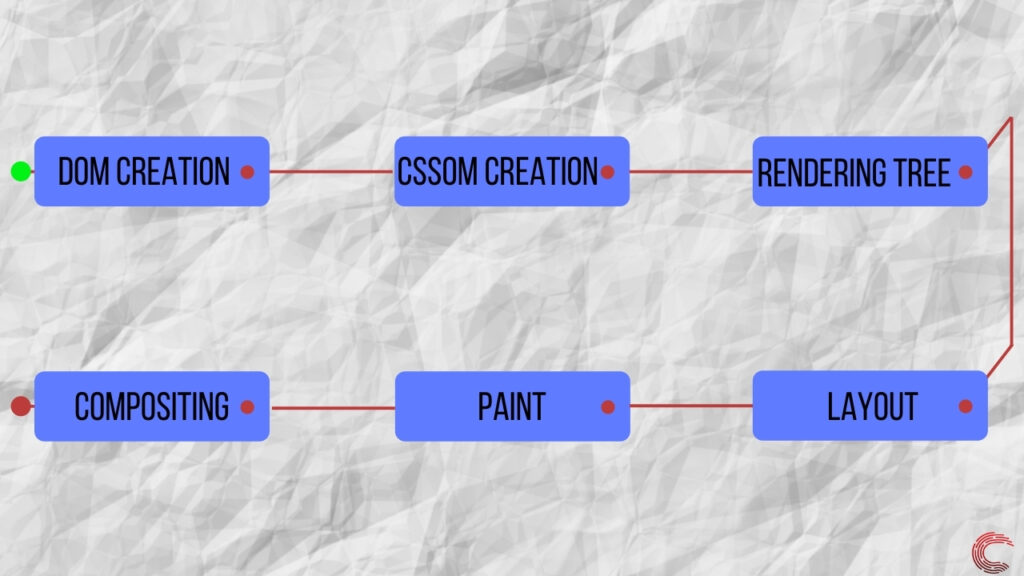
Этот процесс создания веб-страницы из битов данных известен как критический путь отрисовки и является основным фактором, определяющим производительность любой веб-страницы, которую вы посещаете в Интернете.
Теперь, когда механизм рендеринга отрисовал веб-сайт в браузере, вам может быть интересно, что мы нигде не использовали Javascript. Это связано с тем, что Javascript является независимым объектом, который отвечает за внесение изменений в структуру DOM, которая добавляет интерактивности веб-сайту.
Добавление интерактивности на веб-сайты с помощью Javascript
После того, как механизм рендеринга завершил рендеринг веб-сайта в пользовательском интерфейсе, пользователь может видеть веб-сайт, но он еще не является интерактивным. Это означает, что если на веб-странице есть кнопка, которая показывает пользователю подсказку, она не будет работать, а Javascript появится на картинке.
Javascript также может вносить изменения в структуру DOM, созданную механизмом рендеринга, и даже создавать новые узлы DOM и подключать их к структуре DOM. Этот код Javascript запускается виртуальной машиной в браузере, известной как механизм Javascript.

Механизм Javascript и структура DOM не используют одну и ту же память и являются независимыми объектами. Тем не менее, движок Javascript может взаимодействовать со структурой DOM и запускаться, когда на странице происходит определенное событие. Это различие между двумя пробелами помогает браузеру отображать страницы с помощью механизма Javascript и отображать их при возникновении события.
Javascript лежит в основе каждого используемого вами веб-сайта и отвечает за обработку вводимых пользователем данных и их отправку на удаленный сервер, на котором работает веб-сайт. Скриптовый характер Javascript — это то, что делает браузеры чрезвычайно универсальными, позволяя веб-сайтам работать одинаково как на смартфоне, так и на настольных компьютерах, поскольку браузер может интерпретировать код Javascript в механизме Javascript.
В те дни, когда был изобретен Интернет, все браузеры отображали веб-страницы, и при этом не было задействовано много Javascript. Удаленный сервер выполнял большую часть обработки, а движок Javascript мало что делал на веб-странице. Из-за этого большой объем информации должен был передаваться между сервером и браузером, и такая архитектура подходила для Интернета, когда страницы не были такими сложными и интерактивными.
Тем не менее, современный Интернет не может работать на той же архитектуре, поскольку это сильно замедляет работу веб-сайтов. Следовательно, и браузер, и удаленный сервер должны работать симбиотически, чтобы обеспечить лучший пользовательский интерфейс. Это означает, что браузер больше не отвечает только за отображение веб-страниц, но также за обработку большого количества данных, и все это делает движок Javascript.
Расшифровка движка Javascript
Javascript дебютировал в 1996 году и был создан Бренданом Эйхом всего за 10 дней. Он был частью Netscape Navigator версии 3 и был создан как язык сценариев, который можно было интерпретировать в самом браузере.
Поскольку Javascript был создан как язык, который мог обрабатываться интерпретатором в веб-браузере, он не создавал машинный код для работы на ЦП, что делало язык чрезвычайно универсальным.
Тем не менее, эта универсальная природа Javascript имела компромисс; низкая производительность. Чтобы решить эту проблему, JIT-компиляторы пришли к Javascript, что сделало их очень быстрыми. Использование JIT-компиляторов сделало Javascript настолько быстрым, что он работает на сервере, на котором размещены ваши веб-сайты.
Теперь, когда мы знакомы с ролью Javascript в работе веб-сайта, мы можем подробно разобраться в том, как работает механизм Javascript.
Как работает движок Javascript?
Точно так же, как сетевой уровень извлекает HTML и CSS в виде байтов для механизма рендеринга, он также извлекает код Javascript и передает его механизму Javascript.
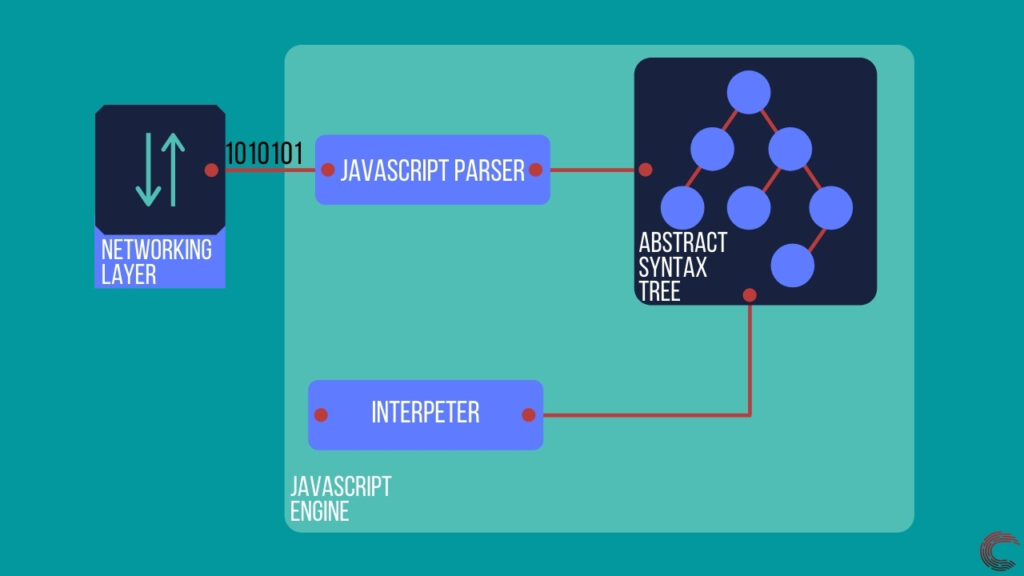
Как только движок получает код Javascript, он отправляет его синтаксическому анализатору, который создает абстрактное синтаксическое дерево (AST). Это дерево является логическим представлением кода Javascript, который может быть запущен компилятором. Компилятор преобразует дерево в промежуточный язык (байт-код), который может выполняться интерпретатором построчно.
Это выполнение Javascript используется, когда код в скрипте не выполняет повторяющиеся задачи (например, цикл). Если в коде Javascript есть обширные циклы, то движок пытается оптимизировать этот код и запускать его на ЦП устройства. Поскольку код выполняется на ЦП машины, он работает намного быстрее по сравнению с интерпретируемой версией.
Для создания машинного кода механизм Javascript использует оптимизирующий компилятор. Этот компилятор принимает байт-код, сгенерированный компилятором, и преобразует его в машинный код для конкретного устройства.
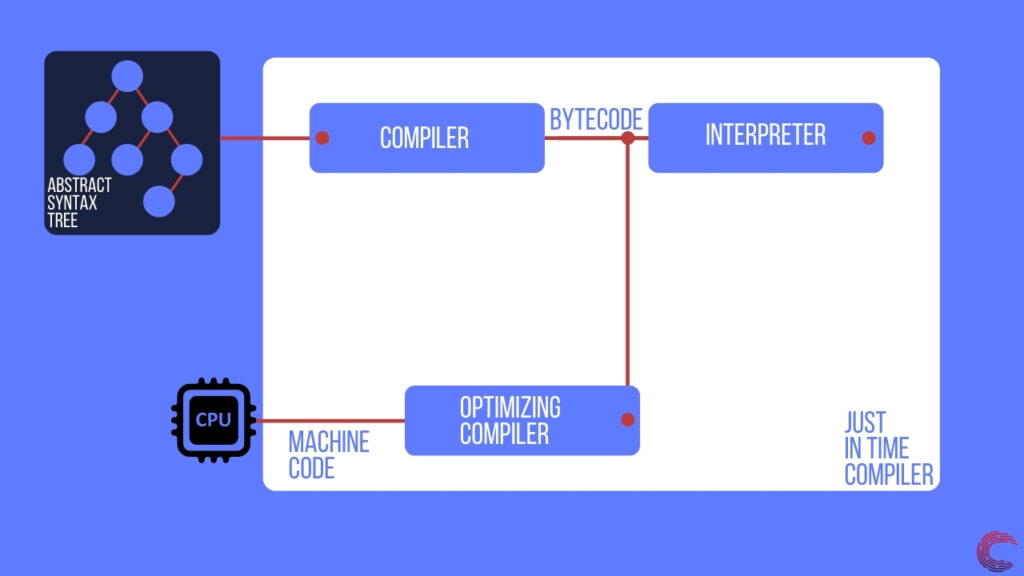
Как только у движка есть оптимизированный машинный код, он может запускать скрипт на невероятно высокой скорости, используя как процессор, так и интерпретатор Javascript.
Заглядывая в будущее
Хотя браузеры сейчас супер мощные, постоянно появляются инновации, которые еще больше ускоряют просмотр. Одним из таких нововведений является веб-сборка, которая используется с Javascript, чтобы сделать выполнение кода еще быстрее за счет использования кода уровня сборки.
Мало того, браузеры догоняют достижения в области машинного обучения и искусственного интеллекта. С такими библиотеками, как Tensorflow, переход на Javascript означает только то, что браузеры обязательно станут умнее в будущем; дальнейшее улучшение пользовательского опыта, который они предлагают.



